SPSS数据分析教程-12_因子分析
- 格式:ppt
- 大小:241.50 KB
- 文档页数:39

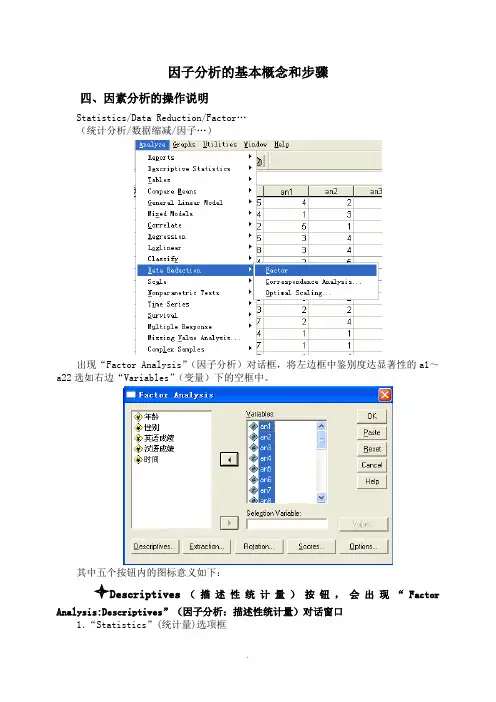
因子分析的基本概念和步骤四、因素分析的操作说明Statistics/Data Reduction/Factor…(统计分析/数据缩减/因子…)出现“Factor Analysis”(因子分析)对话框,将左边框中鉴别度达显著性的a1~a22选如右边“Variables”(变量)下的空框中。
其中五个按钮内的图标意义如下:Descriptives(描述性统计量)按钮,会出现“Factor Analysis:Descriptives”(因子分析:描述性统计量)对话窗口1.“Statistics”(统计量)选项框(1)“ Univariate descriptives”(单变量描述性统计量):显示每一题项的平均数、标准差。
(2)“ Initial solution”(未转轴之统计量):显示因素分析未转轴前之共同性(communality)、特征值(eigenvalues)、变异数百分比与累积百分比。
2.“Correlation Matric”(相关矩阵)选项框(1)“ Coefficients”(系数):显示题项的相关矩阵;(2)“ Significance levels”(显著水准):求出前述矩阵的显著水准;(3)“ Determinant”(行列式):求出前述相关矩阵的行列式值;(4)“ KMO and Bartlett’s test of sphericity”(KMO与Bartlett的球形检定):显示KMO抽样适当性参数与Bartlett的球形检定;(5)“ Inverse”(倒数模式):求出相关矩阵的反矩阵;(6)“ Reproduced”(重制的):显示重制相关矩阵,上三角形矩阵代表残差值;而主对角线与下三角形代表相关系数;(7)“ Anti-image”(反映象):求出反映象的共变量与相关矩阵;在“Factor Analysis:Descriptives”对话窗口中,选取“ Initial solution”、“ KMO and Bartlett’s test of sphericity”二项。

因子分析因子分析一、基础理论知识1 概念因子分析(Factor analysis):就是用少数几个因子来描述许多指标或因素之间的联系,以较少几个因子来反映原资料的大部分信息的统计学分析方法.从数学角度来看,主成分分析是一种化繁为简的降维处理技术。
主成分分析(Principal component analysis):是因子分析的一个特例,是使用最多的因子提取方法.它通过坐标变换手段,将原有的多个相关变量,做线性变化,转换为另外一组不相关的变量。
选取前面几个方差最大的主成分,这样达到了因子分析较少变量个数的目的,同时又能与较少的变量反映原有变量的绝大部分的信息。
两者关系:主成分分析(PCA)和因子分析(FA)是两种把变量维数降低以便于描述、理解和分析的方法,而实际上主成分分析可以说是因子分析的一个特例.2 特点(1)因子变量的数量远少于原有的指标变量的数量,因而对因子变量的分析能够减少分析中的工作量。
(2)因子变量不是对原始变量的取舍,而是根据原始变量的信息进行重新组构,它能够反映原有变量大部分的信息。
(3)因子变量之间不存在显著的线性相关关系,对变量的分析比较方便,但原始部分变量之间多存在较显著的相关关系。
(4)因子变量具有命名解释性,即该变量是对某些原始变量信息的综合和反映。
在保证数据信息丢失最少的原则下,对高维变量空间进行降维处理(即通过因子分析或主成分分析)。
显然,在一个低维空间解释系统要比在高维系统容易的多.3 类型根据研究对象的不同,把因子分析分为R型和Q型两种.当研究对象是变量时,属于R型因子分析;当研究对象是样品时,属于Q型因子分析.但有的因子分析方法兼有R型和Q型因子分析的一些特点,如因子分析中的对应分析方法,有的学者称之为双重型因子分析,以示与其他两类的区别。
4分析原理假定:有n 个地理样本,每个样本共有p 个变量,构成一个n ×p 阶的地理数据矩阵 :当p 较大时,在p 维空间中考察问题比较麻烦。

spss数据分析因子分析法
随着硬件技术的发展,每年被记录和存储下来的数据是非常庞大的,如何从庞大的数据堆中筛选出目标数据并分析得到有用的结论是现今重要的领域---数据挖掘。
为了能够充分有效的利用数据,化繁为简是一项必做的工作,希望将原来繁多的描述变量浓缩成少数几个新指标,同时尽可能多的保存旧变量的信息,这些分析过程被称为数据降维。
主成分分析和因子分析是数据降维分析的主要手段。
因子分析:
因子分析模型中,假定每个原始变量由两部分组成:共同因子和唯一因子。
共同因子是各个原始变量所共有的因子,解释变量之间的相关关系。
唯一因子顾名思义是每个原始变量所特有的因子,表示该变量不能被共同因子解释的部分。
举个例子:现在一个数据表有10个变量,因子分析可以将这10个变量通过特定的算法变为3个,4个,5个等等因子,而每个因子都能表达一种涵义,从而达到了降维的效果,方便接下来的数据分析。
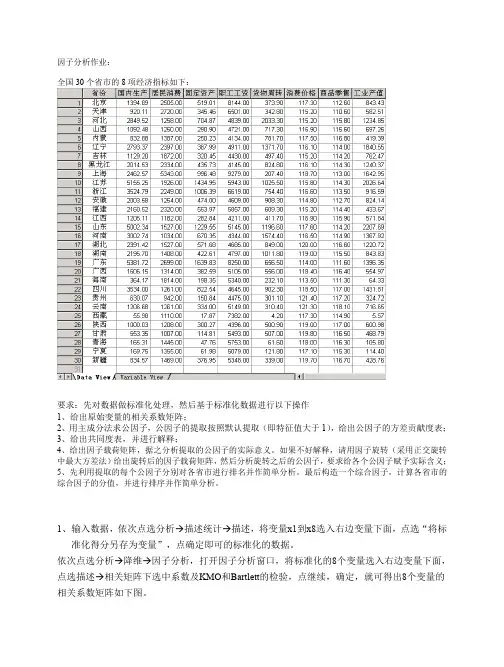
因子分析作业:全国30个省市的8项经济指标如下:要求:先对数据做标准化处理,然后基于标准化数据进行以下操作1、给出原始变量的相关系数矩阵;2、用主成分法求公因子,公因子的提取按照默认提取(即特征值大于1),给出公因子的方差贡献度表;3、给出共同度表,并进行解释;4、给出因子载荷矩阵,据之分析提取的公因子的实际意义。
如果不好解释,请用因子旋转(采用正交旋转中最大方差法)给出旋转后的因子载荷矩阵,然后分析旋转之后的公因子,要求给各个公因子赋予实际含义;5、先利用提取的每个公因子分别对各省市进行排名并作简单分析。
最后构造一个综合因子,计算各省市的综合因子的分值,并进行排序并作简单分析。
1、输入数据,依次点选分析→描述统计→描述,将变量x1到x8选入右边变量下面,点选“将标准化得分另存为变量”,点确定即可的标准化的数据。
依次点选分析→降维→因子分析,打开因子分析窗口,将标准化的8个变量选入右边变量下面,点选描述→相关矩阵下选中系数及KMO和Bartlett的检验,点继续,确定,就可得出8个变量的相关系数矩阵如下图。
由表中数据可以看出大部分数据的绝对值都在0.3以上,说明变量间有较强的相关性。
由上图看出,sig.值为0,所以拒绝相关系数为0(变量相互独立)的原假设,即说明变量间存在相关性。
2、依次点选在因子分析窗口点选抽取 方法:主成分;分析:相关性矩阵;输出:未旋转的因3个图。
表看出前3个主成分的累计贡献率就达到了89.599%>85%,所以选取主成分个数为3。
选y1为第一主成分,y2为第二主成分,y3为第三主成分。
且这三个主成分的方差和占全部方差的89.599%,即基本上保留了原来指标的信息。
这样由原来的8个指标变为了3个指标。
3。
与按累计贡献率确定的主成分个数是一致的。
80%以上的信息。
由上表数据第一列表明:第一主成分与各个变量之间的相关性;第二列表明:第二主成分与各个变量之间的相关性;第三列表明:第三主成分与各个变量之间的相关性。


实验课:因子分析实验目的理解主成分〔因子〕分析的根本原理,熟悉并掌握SPSS中的主成分〔因子〕分析方法及其主要应用。
因子分析一、根底理论知识1 概念因子分析〔Factor analysis〕:就是用少数几个因子来描述许多指标或因素之间的联系,以较少几个因子来反映原资料的大局部信息的统计学分析方法。
从数学角度来看,主成分分析是一种化繁为简的降维处理技术。
主成分分析〔Principal ponent analysis〕:是因子分析的一个特例,是使用最多的因子提取方法。
它通过坐标变换手段,将原有的多个相关变量,做线性变化,转换为另外一组不相关的变量。
选取前面几个方差最大的主成分,这样到达了因子分析较少变量个数的目的,同时又能与较少的变量反映原有变量的绝大局部的信息。
两者关系:主成分分析〔PCA〕和因子分析〔FA〕是两种把变量维数降低以便于描述、理解和分析的方法,而实际上主成分分析可以说是因子分析的一个特例。
2 特点〔1〕因子变量的数量远少于原有的指标变量的数量,因而对因子变量的分析能够减少分析中的工作量。
〔2〕因子变量不是对原始变量的取舍,而是根据原始变量的信息进展重新组构,它能够反映原有变量大局部的信息。
〔3〕因子变量之间不存在显著的线性相关关系,对变量的分析比拟方便,但原始局部变量之间多存在较显著的相关关系。
〔4〕因子变量具有命名解释性,即该变量是对某些原始变量信息的综合和反映。
在保证数据信息丧失最少的原那么下,对高维变量空间进展降维处理〔即通过因子分析或主成分分析〕。
显然,在一个低维空间解释系统要比在高维系统容易的多。
3 类型根据研究对象的不同,把因子分析分为R 型和Q 型两种。
当研究对象是变量时,属于R 型因子分析;当研究对象是样品时,属于Q 型因子分析。
但有的因子分析方法兼有R 型和Q 型因子分析的一些特点,如因子分析中的对应分析方法,有的学者称之为双重型因子分析,以示与其他两类的区别。
4分析原理假定:有n 个地理样本,每个样本共有p 个变量,构成一个n ×p 阶的地理数据矩阵 :当p 较大时,在p 维空间中考察问题比拟麻烦。

因子分析因子分析一、基础理论知识1 概念因子分析(Factor analysis):就是用少数几个因子来描述许多指标或因素之间的联系,以较少几个因子来反映原资料的大部分信息的统计学分析方法。
从数学角度来看,主成分分析是一种化繁为简的降维处理技术。
主成分分析(Principal component analysis):是因子分析的一个特例,是使用最多的因子提取方法。
它通过坐标变换手段,将原有的多个相关变量,做线性变化,转换为另外一组不相关的变量。
选取前面几个方差最大的主成分,这样达到了因子分析较少变量个数的目的,同时又能与较少的变量反映原有变量的绝大部分的信息。
两者关系:主成分分析(PCA)和因子分析(FA)是两种把变量维数降低以便于描述、理解和分析的方法,而实际上主成分分析可以说是因子分析的一个特例。
2 特点(1)因子变量的数量远少于原有的指标变量的数量,因而对因子变量的分析能够减少分析中的工作量。
(2)因子变量不是对原始变量的取舍,而是根据原始变量的信息进行重新组构,它能够反映原有变量大部分的信息。
(3)因子变量之间不存在显著的线性相关关系,对变量的分析比较方便,但原始部分变量之间多存在较显著的相关关系。
(4)因子变量具有命名解释性,即该变量是对某些原始变量信息的综合和反映。
在保证数据信息丢失最少的原则下,对高维变量空间进行降维处理(即通过因子分析或主成分分析)。
显然,在一个低维空间解释系统要比在高维系统容易的多。
3 类型根据研究对象的不同,把因子分析分为R型和Q型两种。
当研究对象是变量时,属于R型因子分析;当研究对象是样品时,属于Q型因子分析。
但有的因子分析方法兼有R型和Q型因子分析的一些特点,如因子分析中的对应分析方法,有的学者称之为双重型因子分析,以示与其他两类的区别。
4分析原理假定:有n 个地理样本,每个样本共有p 个变量,构成一个n ×p 阶的地理数据矩阵 :当p 较大时,在p 维空间中考察问题比较麻烦。


利用SPSS进行因子分析(R型)【例】与主成分分析的数据相同:全国30个省市的8项经济指标。
因子模型是一个封闭方程,通常采用主成分求解,称为“主因解”。
上次讲述的“利用SPSS进行主成分分析”的过程,实际上是因子分析的第一步。
在主成分分析基础上,加上因子旋转,就可完成基于主成分分析的所谓因子分析。
当然也可通过另外的途径进行因子分析,在此暂不涉及。
第一步:录入或调入数据(见图1)。
图1 录入工作表中的原始数据第二步,进行主成分分析(参见主成分分析部分,在此从略)。
第三步,因子正交旋转的系统设置。
沿着主菜单的“Analyze→Data Reduction→Factor…”路径打开因子分析选项框(图2),完成主成分分析的设置或过程以后,单击Rotation(旋转)按钮,打开“Factor Analysis: Rotation”(因子分析:旋转)选项单(图3),在Method(方法)栏中选中Varimax(方差极大正交旋转)复选项,此时Display(展示)栏中的Rotated Solution(旋转解)将被激活为系统默认态,选中Loading Plot(s)(载荷图)复选项,将会在输出结果中给出因子载荷图式。
注意此时的Maximum Iterations for Convergence(迭代收敛的最大次数)为系统默认的25次,如果数据变量较多或样本较大,经过25次迭代可能计算过程仍然未能收敛,需要改为50次、100次乃至更多,否则SPSS无法给出计算结果。
迭代次数越多,计算时间也就越长。
在多数情况下,不足25次迭代计算过程就会收敛。
图2 因子分析选项框图3 因子旋转对话框注意:与上述Maximum Iterations for Convergence(迭代收敛的最大次数)有关的设置是Extraction(提取)对话框中的迭代次数设置(图4),如果今后工作中修改了图3所示的迭代次数仍然未能给出结果,那就意味着图4所示的迭代次数设置没有增加;反过来也是一样。
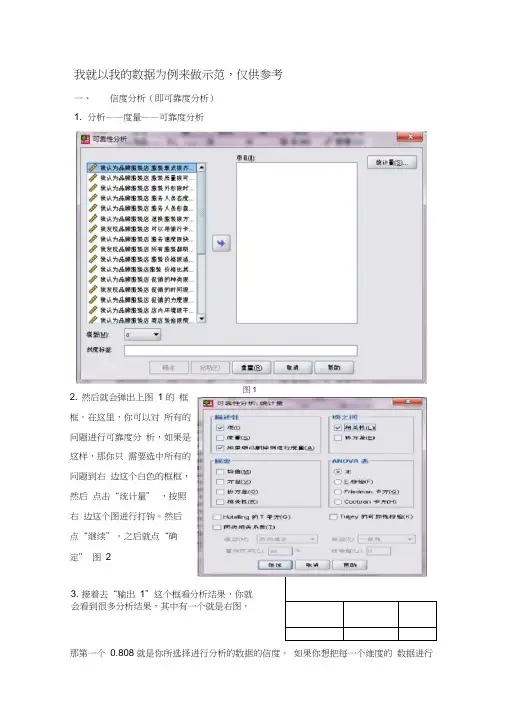
我就以我的数据为例来做示范,仅供参考一、信度分析(即可靠度分析)1. 分析——度量——可靠度分析2. 然后就会弹出上图 1 的 框框。
在这里,你可以对 所有的问题进行可靠度分 析,如果是这样,那你只 需要选中所有的问题到右 边这个白色的框框,然后 点击“统计量” ,按照右 边这个图进行打钩。
然后 点“继续”。
之后就点“确 定” 图 23.接着去“输出 1”这个框看分析结果,你就会看到很多分析结果,其中有一个就是右图,那第一个 0.808 就是你所选择进行分析的数据的信度。
如果你想把每一个维度的 数据进行图1独立的信度分析,那道理也是一样的。
二、因子分析在做因子分析之前首先要判断这些数据是否适合做因子分析,那这里就需要进行效度检验,不过总共效度检验是和因子分析的操作同步的,意思就是说你在做因子分析的时候也可以做效度检验。
具体示范如下:1. 分析——降维——因子分析图2一般来说,咱们做因子分析的时候是为了把那些具有共同属性的因子归类成一类,说的简单点就是要验证咱们所选取的每一个维度下面的题目是属于这个维度,而非其他维度的。
那一般来说,因子分析做出来的结果就是你原本有几个维度,最终分析结果就会归类成几个公因子。
2. 一般来说,自变量的题目和因变量的题目是要独立分析的。
我的课题是“店面形象对顾客购买意愿的影响”那自变量就是店面形象的那些维度,因变量 就是顾客购买意愿。
3. 将要做分析的题目选择到右边的白框之后,就如下图打钩:看第一行和最后一行的数据,第一行数据为 0.756 ,表明效度较高, sig 为0.000 ,这两个结果显示这份数据完全可以做因子分析。
那就去看因子分析的结果5. 看下面这张图,看“初始特征值”这一项下面的“合计”的数值,有几个数 据是>1,抽取”和“选项”两个不用管他。
然后就点 确定”4. 按照上述步骤操作下来 之后,就可以去“输出 1 看分析结果。
首先看效 度检验的结果:这里要那就表明此次因子分析共提取了几个公因子。
因子分析的基本概念和步骤一、因子分析的意义在研究实际问题时往往希望尽可能多地收集相关变量,以期望能对问题有比较全面、完整的把握和认识。
例如,对高等学校科研状况的评价研究,可能会搜集诸如投入科研活动的人数、立项课题数、项目经费、经费支出、结项课题数、发表论文数、发表专著数、获得奖励数等多项指标;再例如,学生综合评价研究中,可能会搜集诸如基础课成绩、专业基础课成绩、专业课成绩、体育等各类课程的成绩以及累计获得各项奖学金的次数等。
虽然收集这些数据需要投入许多精力,虽然它们能够较为全面精确地描述事物,但在实际数据建模时,这些变量未必能真正发挥预期的作用,“投入”和“产出”并非呈合理的正比,反而会给统计分析带来很多问题,可以表现在:计算量的问题由于收集的变量较多,如果这些变量都参与数据建模,无疑会增加分析过程中的计算工作量。
虽然,现在的计算技术已得到了迅猛发展,但高维变量和海量数据仍是不容忽视的。
变量间的相关性问题收集到的诸多变量之间通常都会存在或多或少的相关性。
例如,高校科研状况评价中的立项课题数与项目经费、经费支出等之间会存在较高的相关性;学生综合评价研究中的专业基础课成绩与专业课成绩、获奖学金次数等之间也会存在较高的相关性。
而变量之间信息的高度重叠和高度相关会给统计方法的应用带来许多障碍。
例如,多元线性回归分析中,如果众多解释变量之间存在较强的相关性,即存在高度的多重共线性,那么会给回归方程的参数估计带来许多麻烦,致使回归方程参数不准确甚至模型不可用等。
类似的问题还有很多。
为了解决这些问题,最简单和最直接的解决方案是削减变量的个数,但这必然又会导致信息丢失和信息不完整等问题的产生。
为此,人们希望探索一种更为有效的解决方法,它既能大大减少参与数据建模的变量个数,同时也不会造成信息的大量丢失。
因子分析正式这样一种能够有效降低变量维数,并已得到广泛应用的分析方法。
因子分析的概念起源于20世纪初Karl Pearson和Charles Spearmen等人关于智力测验的统计分析。
因子分析因子分析一、基础理论知识1概念因子分析(Factoranalysis):就是用少数几个因子来描述许多指标或因素之间的联系,以较少几个因子来反映原资料的大部分信息的统计学分析方法。
从数学角度来看,主成分分析是一种化繁为简的降维处理技术。
主成分分析(Principalcomponentanalysis):是因子分析的一个特例,是使用最多的因子提取方法。
它通过坐标变换手段,将原有的多个相关变量,做线性变化,转换为另外一组不相关的变量。
选取前面几个方差最大的主成分,这样达到了因子分析较少变量个数的目的,同时又能与较少的变量反映原有变量的绝大部分的信息。
两者关系:主成分分析(PCA)和因子分析(FA)是两种把变量维数降低以便于描述、理解和分析的方法,而实际上主成分分析可以说是因子分析的一个特例。
2特点(1)因子变量的数量远少于原有的指标变量的数量,因而对因子变量的分析能够减少分析中的工作量。
(2)因子变量不是对原始变量的取舍,而是根据原始变量的信息进行重新组构,它能够反映原有变量大部分的信息。
(3)因子变量之间不存在显着的线性相关关系,对变量的分析比较方便,但原始部分变量之间多存在较显着的相关关系。
(4)因子变量具有命名解释性,即该变量是对某些原始变量信息的综合和反映。
在保证数据信息丢失最少的原则下,对高维变量空间进行降维处理(即通过因子分析或主成分分析)。
显然,在一个低维空间解释系统要比在高维系统容易的多。
3类型根据研究对象的不同,把因子分析分为R型和Q型两种。
当研究对象是变量时,属于R型因子分析;当研究对象是样品时,属于Q型因子分析。
但有的因子分析方法兼有R型和Q型因子分析的一些特点,如因子分析中的对应分析方法,有的学者称之为双重型因子分析,以示与其他两类的区别。
4分析原理假定:有n个地理样本,每个样本共有p个变量,构成一个n×p阶的地理数据矩阵:当p较大时,在p维空间中考察问题比较麻烦。
SPSS因子分析(因素分析)——实例分析SPSS因子分析(因素分析)——实例分析SPSS(Statistical Package for the Social Sciences)是一种广泛应用于数据分析的软件工具,其中的因子分析(Factor Analysis)被广泛用于统计学和社会科学领域的研究。
本文将通过一个实例分析来介绍SPSS因子分析的基本原理和步骤。
1.研究背景在实施因子分析之前,首先需要明确研究背景和目的。
假设我们正在研究消费者购物行为,并希望确定出不同因素对于购物偏好的影响。
2.数据收集和准备在进行因子分析前,需要收集并准备相关数据。
假设我们已经收集到了100位消费者的关于购物行为的调查问卷数据,包括10个关于购物偏好的变量。
在SPSS中,我们可以将这些数据输入到一个数据矩阵中,每一行代表一个消费者,每一列代表一个变量。
3.因子分析设置在SPSS中,通过导航菜单选择适当的分析工具来进行因子分析。
在设置选项中,我们可以选择因子提取方法(如主成分分析、极大似然法等)和旋转方法(如方差最大旋转、斜交旋转等)等。
根据实际情况,我们可以调整这些参数以获得最佳结果。
4.因子提取在因子分析的第一步中,SPSS会计算每个变量的因子载荷矩阵,并根据设定的准则提取出主要因子。
因子载荷表示了每个变量与每个因子之间的关联程度,值越大表示关联程度越高。
通过因子载荷矩阵,我们可以判断每个变量对于哪个因子具有较高的影响。
5.因子旋转因子旋转可用于调整因子载荷矩阵,以使其更易于解释。
旋转后的因子载荷矩阵通常会呈现出更简洁、更有意义的结果。
在SPSS中,我们可以选择合适的旋转方法并进行旋转操作。
6.因子解释和命名在完成因子分析后,我们需要对结果进行解释和命名。
根据因子载荷矩阵和旋转结果,我们可以确定每个因子代表了哪些变量,并为每个因子赋予一个描述性的名称,以便于后续的数据分析和报告撰写。
7.结果解读最后,根据因子分析的结果,我们可以进行一系列的统计推断和解读。
因子分析作业:全国30个省市的8项经济指标如下:要求:先对数据做标准化处理,然后基于标准化数据进行以下操作1、给出原始变量的相关系数矩阵;2、用主成分法求公因子,公因子的提取按照默认提取即特征值大于1,给出公因子的方差贡献度表;3、给出共同度表,并进行解释;4、给出因子载荷矩阵,据之分析提取的公因子的实际意义;如果不好解释,请用因子旋转采用正交旋转中最大方差法给出旋转后的因子载荷矩阵,然后分析旋转之后的公因子,要求给各个公因子赋予实际含义;5、先利用提取的每个公因子分别对各省市进行排名并作简单分析;最后构造一个综合因子,计算各省市的综合因子的分值,并进行排序并作简单分析;1、输入数据,依次点选分析描述统计描述,将变量x1到x8选入右边变量下面,点选“将标准化得分另存为变量”,点确定即可的标准化的数据;依次点选分析降维因子分析,打开因子分析窗口,将标准化的8个变量选入右边变量下面,点选描述相关矩阵下选中系数及KMO和Bartlett的检验,点继续,确定,就可得出8个变量的相关系数矩阵如下图;由表中数据可以看出大部分数据的绝对值都在以上,说明变量间有较强的相关性;KMO 和 Bartlett 的检验取样足够度的 Kaiser-Meyer-Olkin 度量; .621Bartlett 的球形度检验近似卡方df 28Sig. .000由上图看出,sig.值为0,所以拒绝相关系数为0变量相互独立的原假设,即说明变量间存在相关性;2、依次点选在因子分析窗口点选抽取方法:主成分;分析:相关性矩阵;输出:未旋转的因子3个图;上表中第一列为特征值主成分的方差,第二列为各个主成分的贡献率,第三列为累积贡献率,由上表看出前3个主成分的累计贡献率就达到了%>85%,所以选取主成分个数为3;选y1为第一主成分,y2为第二主成分,y3为第三主成分;且这三个主成分的方差和占全部方差的%,即基本上保留了原来指标的信息;这样由原来的8个指标变为了3个指标;由上图看出,成分数为3时,特征值的变化曲线趋于平缓,所以由碎石图也可大致确定出主成分个数为3;与按累计贡献率确定的主成分个数是一致的;3、共同度结果如下:公因子方差初始提取Zscore: 国内生产.945Zscore: 居民消费.800Zscore: 固定资产.902Zscore: 职工工资.873Zscore: 货物周转.858Zscore: 消费价格.957Zscore: 商品零售.929Zscore: 工业产值.904提取方法:主成份分析;上表给出了该次分析从每个原始变量中提取的信息;由上表数据可以看出,主成分包含了各个原始变量的80%以上的信息;由上表数据第一列表明:第一主成分与各个变量之间的相关性;第二列表明:第二主成分与各个变量之间的相关性;第三列表明:第三主成分与各个变量之间的相关性;可以得出:x1x3x8主要由第一主成分解释,x4x5主要由第二主成分解释,x6主要由第三主成分解释;但是x2是由第一主成分还是第二主成分解释不好确定,x7是由三个主成分中的哪个解释也不好确定;下面作因子旋转后的因子载荷阵;在因子分析窗口,抽取输出:旋转的因子解,继续;旋转方法:最大方差法,继续;确定;输出结果由上表数据可以得出:x1x3x5x8主要由第一主成分解释,x2x4主要由第二主成分解释,x6x7主要由第三主成分解释;与第一因子关系密切的变量主要是投入投资:固定资产投资与产出产值:国内生产总值、工业总产值方面的变量,货物周转又是投入产出的中介过程,可以命名为投入产出因子;与第二因子关系密切的都是反映民众生活水平的变量,可以命名为消费能力因子;与第三因子关系密切的是价格指由上表可以看出:第二列数据表明,各个主成分的贡献率与旋转前的有变化,但是3个主成分的累积贡献率相同都是%;5、在因子分析窗口,得分因子得分保存为变量f1f2f3;方法:回归;再按三个主成分降序排列:数据排序个案:将f1选入排序依据,排列顺序:降序;同理得出按f2f3排序的结果;结果如下;最后,以各因子的方差贡献率占三个因子总方差贡献率的比重作为权重进行加权汇总,得出各城市的综合得分f;即f=f1+f2+f3/f得分在转换计算变量中的出;最后再按f得分排序;排序结果如下:f1 排序f2 排序f3 排序 f 排序山东上海云南上海江苏广东贵州山东广东北京湖北江苏河北天津新疆广东四川浙江四川四川河南西藏陕西湖北辽宁福建上海浙江浙江江苏甘肃云南上海青海广西北京湖北新疆湖南辽宁湖南云南青海湖南黑龙江海南山东新疆安徽宁夏内蒙贵州福建山东西藏河南云南广西江西广西广西甘肃宁夏陕西山西湖北山西河北北京贵州江苏黑龙江陕西黑龙江北京甘肃内蒙吉林浙江福建吉林辽宁河南山西江西湖南黑龙江青海新疆四川辽宁内蒙甘肃陕西河北江西贵州山西福建天津天津江西吉林西藏青海安徽广东吉林宁夏内蒙安徽安徽海南河南天津宁夏西藏河北海南海南有了对各个公因子的合理的解释,结合各个城市在三个公因子的得分和综合得分,就可对各城市的经济发展水平进行评价了;在投入产出因子f1上得分最高的6个城市是山东、江苏、广东、河北、四川;其中山东得分为,江苏得分为,高于其他城市,说明山东、江苏的工业的投入产出能力最高,工业发展相对较快,从而推动城市发展;而青海、宁夏、海南、西藏的投入产出能力较差,可能由于地理位置的缘故工业发展相对落后;上海、广东、北京、天津在消费能力因子f2上的得分较高,说明它们的消费能力较高,人们的收入也较高,从而生活质量较好,城市发展较快;而河南、河北得分较低,它们的消费能力较低,从而说明人们的收入也相对较低,生活质量相对差一点,城市发展较慢;云南、贵州、湖北、新疆在价格指数因子f3上的得分较高,说明在这些城市物价相对较高,可能以些非本地产的东西由于运输的不方便,使得这些物价相对较高,而广东、安徽、天津、海南的价格指数较低,说明,在这些城市,交通相对便捷,运输方便,或者本地产的东西较多基本满足需求,使得物价相对较低,但从侧面也可看出这些城市与其他城市的联系可能较少,不利于自己的总和发展,从而也说明了这些城市的发展相对较慢;由综合因子f的分就可综合评价城市的经济发展水平,综合得分的前3名上海、山东、江苏,得分最低的3个城市安徽、宁夏、海南;。
实验指导之四因子分析的SPSS操作方法以例13.1为例进行因子分析操作。
1.在SPSS的数据编辑窗口(见图1)点击Analysize →Data Reduction →Factor,打开Factor Analysis对话框如图2.图1 因子分析操作图2 Factor Analysis 对话框将参与因子分析的变量依次选入Variables框中。
例13.1中有8个参与因子分析的变量,故都选入变量框内。
2.单击Descriptives 按钮,打开Descriptives对话框如图3所示。
✧Statistics栏,指定输出的统计量。
图3 Descriptives对话框Univariate descriptives 输出每个变量的基本统计描述;Initial solution 输出初始分析结果。
输出主成分变量的相关或协方差矩阵的对角元素。
(本例选择)✧Correlation Matrix栏指定输出考察因子分析条件和方法。
Coefficients相关系数矩阵;Significance levels 相关系数假设检验的P值;Determinant 相关系数矩阵行列式的值;KMO and Bartlett´s test of Sphericity KMO和巴特利检验(本例选择)巴特利检验是关于研究的变量是否适合进行因子分析的检验. 拒绝原假设意味着适合进行因子分析.KMO值等于变量间单相关系数的平方和与单相关系数平方和加上偏相关系数平方和之比, 值越接近1, 意味着变量间的相关性越强,越适合进行因子分分析, KMO值越接近0, 则变量间的相关性越弱. 越不适合进行因子分析.Inverse 相关系数矩阵的逆矩阵;Reproduced 再生相关阵;Anti-image 反映象相关矩阵。
3.单击Extraction 按钮,打开Extraction对话框选项,见图4。
图4 Extraction对话框✧Method栏,指定因子分析方法。