一步一步写算法(之循环单向链表)
- 格式:doc
- 大小:50.00 KB
- 文档页数:3

2022年三峡大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、若需在O(nlog2n)的时间内完成对数组的排序,且要求排序是稳定的,则可选择的排序方法是()。
A.快速排序B.堆排序C.归并排序D.直接插入排序2、n个结点的完全有向图含有边的数目()。
A.n*nB.n(n+1)C.n/2D.n*(n-1)3、若线性表最常用的操作是存取第i个元素及其前驱和后继元素的值,为节省时间应采用的存储方式()。
A.单链表B.双向链表C.单循环链表D.顺序表4、下面关于串的叙述中,不正确的是()。
A.串是字符的有限序列B.空串是由空格构成的串C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储5、已知串S='aaab',其next数组值为()。
A.0123B.1123C.1231D.12116、已知字符串S为“abaabaabacacaabaabcc”,模式串t为“abaabc”,采用KMP算法进行匹配,第一次出现“失配”(s!=t)时,i=j=5,则下次开始匹配时,i和j的值分别()。
A.i=1,j=0 B.i=5,j=0 C.i=5,j=2 D.i=6,j=27、下列选项中,不能构成折半查找中关键字比较序列的是()。
A.500,200,450,180 B.500,450,200,180C.180,500,200,450 D.180,200,500,4508、在下述结论中,正确的有()。
①只有一个结点的二叉树的度为0。
②二叉树的度为2。
③二叉树的左右子树可任意交换。
④深度为K的完全二叉树的结点个数小于或等于深度相同的满二叉树。
A.①②③B.⑦③④C.②④D.①④9、一棵非空的二叉树的前序序列和后序序列正好相反,则该二叉树一定满足()。
A.其中任意一个结点均无左孩子B.其中任意一个结点均无右孩子C.其中只有一个叶结点D.其中度为2的结点最多为一个10、分别以下列序列构造二叉排序树,与用其他三个序列所构造的结果不同的是()。

第4章 数据结构与算法本章介绍数据结构与算法,内容包括算法和数据结构的基本概念、栈及线性链表、树与二叉树、排序技术、查找技术。
●了解数据结构与算法的基本概念。
●了解栈与线性链表的操作。
●了解树与二叉树。
●了解数据结构中的排序技术和查找技术。
4.1 算法的概念4.1.1 算法的基本概念程序是算法用某种程序设计语言的具体实现。
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。
也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。
如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。
不同的算法可能用不同的时间、空间或效率来完成同样的任务。
一个算法的优劣可以用空间复杂度和时间复杂度来衡量。
算法中的指令描述的是一个计算,当其运行时能从一个初始状态和(可能为空的)初始输入开始,经过一系列有限而清晰定义的状态,最终产生输出并停止于一个终态。
一个状态到另一个状态的转移不一定是确定的。
随机化算法在内的一些算法包含了一些随机输入。
算法具有的一些重要特性:(1)有限性。
算法在执行有限步之后必须终止。
(2)确定性。
算法的每一个步骤都是有精确的定义的。
执行的每一步都是清晰的、无二义的。
大学计算机基础84(3)输入。
一个算法具有任意个输入,它是由外部提供的,作为算法执行前的初始状态。
(4)输出。
算法一定有输出结果。
(5)可行性。
算法中的运算都必须是可以实现的。
4.1.2 算法的复杂度1.时间复杂度算法的时间复杂度采用算法执行过程中其基本操作的执行次数,即计算量来度量。
算法中基本操作的执行次数一般是与问题的规模有关的,对于节点个数为n的数据处理问题,用T(n)表示算法基本操作的执行次数。
当比较不同算法的时间性能时,主要标准是看不同算法时间复杂度所处的数量级如何。
例如:以上算法中,循环体中的代码执行了n次,因此算法的时间复杂度为O(n)。


单向链表单向链表的基本操作,创建一个由6个节点组成的单向链表,显示链表中每个节点的数据,并且做增加、删除、查找节点以及计算单链表的长度等处理。
➢需求分析:1.功能(1)用尾插法创建一带头结点的由6个节点组成的单向链表:从键盘读入一组整数,作为单链表中的元素,输入完第6个结点后结束;将创建好的单链表元素依次输出到屏幕上。
(2)显示链表中每个节点的数据(3)从键盘输入一个数,查找在以上创建的单链表中是否存在该数;如果存在,显示它的位置,即第几个元素;如果不存在,给出相应提示如“No found node!”。
(4)在上述的单链表中的指定位置插入指定数据,并输出单链表中所有数据。
(5)删除上述单链表中指定位置的结点,并输出单链表中所有数据。
(6)求单链表的长度并输出.2.输入要求先输入单链表中结点个数n,再输入单链表中所有数据,在单链表中需查找的数据,需插入的数据元素的位置、值,要删除的数据元素的位置。
3。
测试数据单链表中所有数据:12,23,56,21,8,10在单链表中需查找的数据:56;24插入的数据元素的位置、值:1,28;7,28;0,28要删除的数据元素的位置:6➢概要设计:1.算法思想:由于在操作过程中要进行插入、删除等操作,为运算方便,选用带头结点的单链表作数据元素的存储结构.对每个数据元素,由一个数据域和一个指针域组成,数据域放输入的数据值,指针域指向下一个结点。
2.数据结构:单链表结点类型:typedef struct Liistnode {int data;struct Listnode *next;}NODE;3.模块划分:a)用尾插法建立带头结点的单链表*CreateList函数;b)显示链表中每个结点的数据PrintList函数;c)从键盘输入一个数,查找单链表中是否存在该数FoundList函数;d)在单链表中指定位置插入指定数据并输出单链表中所有数据InsertList函数;e)删除单链表中指定位置的结点并输出单链表中所有数据DeleteList函数;f)计算单链表的长度并在屏幕上输出LengthList函数;g)主函数main(),功能是给出测试数据值,建立测试数据值的带头结点的单链表,调用PrintList函数、FoundList函数、InsertList函数、DeleteList函数、LengthList函数实现问题要求。
第二部分数据结构概述数据结构是计算机专业基础课程之一,是十分重要的核心课程。
计算机的所有系统软件和应用软件都要用到各种类型的数据结构。
要想更好运用计算机来解决实际问题,仅仅学习计算机语言而缺乏数据结构知识是远远不够的,瑞士著名的计算机专家沃思(N.Writh)曾经说过:“算法+数据结构=程序”。
可见有了程序设计的基本知识,掌握了一种程序设计语言,并不一定就能设计出比较好的程序,解决比较复杂的实际问题,还必须掌握数据结构及算法设计的基本知识。
数据(Data)数据是信息的载体。
它能够被计算机识别、存储和加工处理,是计算机程序加工的"原料"。
随着计算机应用领域的扩大,数据的范畴包括:整数、实数、字符串、图像和声音等。
数据元素(Data Element)数据元素是数据的基本单位。
数据元素也称元素、结点、顶点、记录。
一个数据元素可以由若干个数据项(也称为字段、域、属性)组成。
数据项是具有独立含义的最小标识单位。
为了增加对数据结构的感性认识,下面举例来说明有关数据结构的概念。
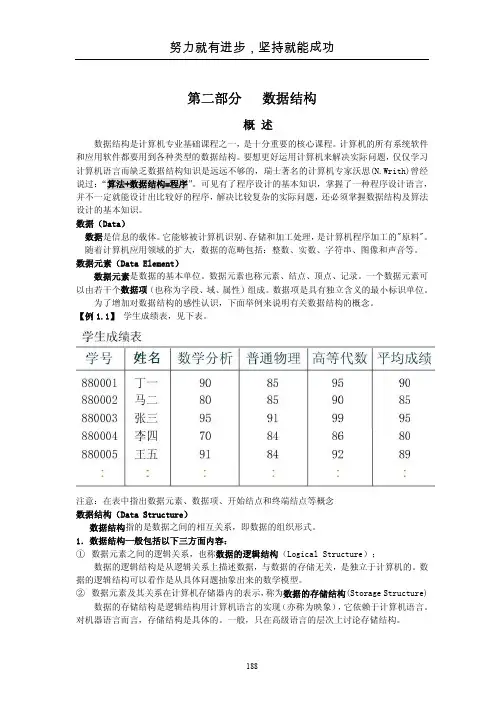
【例1.1】学生成绩表,见下表。
注意:在表中指出数据元素、数据项、开始结点和终端结点等概念数据结构(Data Structure)数据结构指的是数据之间的相互关系,即数据的组织形式。
1.数据结构一般包括以下三方面内容:①数据元素之间的逻辑关系,也称数据的逻辑结构(Logical Structure);数据的逻辑结构是从逻辑关系上描述数据,与数据的存储无关,是独立于计算机的。
数据的逻辑结构可以看作是从具体问题抽象出来的数学模型。
②数据元素及其关系在计算机存储器内的表示,称为数据的存储结构(Storage Structure)数据的存储结构是逻辑结构用计算机语言的实现(亦称为映象),它依赖于计算机语言。
对机器语言而言,存储结构是具体的。
一般,只在高级语言的层次上讨论存储结构。
③数据的运算,即对数据施加的操作。
数据的运算定义在数据的逻辑结构上,每种逻辑结构都有一个运算的集合。

数据结构实验报告T1223-3-21余帅实验一实验题目:仅仅做链表部分难度从上到下1.双向链表,带表头,线性表常规操作。
2.循环表,带表头,线性表常规操作。
3.单链表,带表头,线性表常规操作。
实验目的:了解和掌握线性表的逻辑结构和链式存储结构,掌握单链表的基本算法及相关的时间性能分析。
实验要求:常规操作至少有:1.数据输入或建立2.遍历3.插入4.删除必须能多次反复运行实验主要步骤:1、分析、理解给出的示例程序。
2、调试程序,并设计输入数据,测试程序的如下功能:1.数据输入或建立2.遍历3.插入4.删除单链表示意图:headhead head 创建删除双向循环链表示意图:创建程序代码://单链表#include<iostream.h>#include<windows.h>const MAX=5;enum returninfo{success,fail,overflow,underflow,range_error}; int defaultdata[MAX]={11,22,33,44,55};class node{public:int data;node *next;};class linklist{private:node *headp;protected:int count;public:linklist();~linklist();bool empty();void clearlist();returninfo create(void);returninfo insert(int position,const int &item);returninfo remove(int position) ;returninfo traverse(void);};linklist::linklist(){headp = new node;headp->next = NULL;count=0;}linklist::~linklist(){clearlist();delete headp;}bool linklist::empty(){if(headp->next==NULL)return true;elsereturn false;}void linklist::clearlist(){node *searchp=headp->next,*followp=headp;while(searchp->next!=NULL){followp=searchp;searchp=searchp->next;delete followp;}headp->next = NULL;count = 0;}returninfo linklist::create(){node *searchp=headp,*newnodep;for(int i=0;i<MAX;i++){newnodep = new node;newnodep->data = defaultdata[i];newnodep->next = NULL;searchp->next = newnodep;searchp = searchp->next;count++;}searchp->next = NULL;traverse();return success;}returninfo linklist::insert(int position,const int &item) //插入一个结点{if(position<=0 || position>=count)return range_error;node *newnodep=new node,*searchp=headp->next,*followp=headp;for(int i=1; i<position && searchp!=NULL;i++){followp=searchp;searchp=searchp->next;}newnodep->data=item; //给数据赋值newnodep->next=followp->next; //注意此处的次序相关性followp->next=newnodep;count++; //计数器加一return success;}returninfo linklist::remove(int position) //删除一个结点{if(empty())return underflow;if(position<=0||position>=count+1)return range_error;node *searchp=headp->next,*followp=headp; //这里两个指针的初始值设计一前一后for(int i=1; i<position && searchp!=NULL;i++){followp=searchp;searchp=searchp->next;}followp->next=searchp->next; //删除结点的实际语句delete searchp; //释放该结点count--; //计数器减一return success;}returninfo linklist::traverse(void){node *searchp;if(empty())return underflow;searchp = headp->next;cout<<"连表中的数据为:"<<endl;while(searchp!=NULL){cout<<searchp->data<<" ";searchp = searchp->next;}cout<<endl;return success;}class interfacebase{public:linklist listface; //定义一个对象Cskillstudyonfacevoid clearscreen(void);void showmenu(void);void processmenu(void);};void interfacebase::clearscreen(void){system("cls");}void interfacebase::showmenu(void){cout<<"================================"<<endl;cout<<" 功能菜单 "<<endl;cout<<" 1.创建链表 "<<endl;cout<<" 2.增加结点 "<<endl;cout<<" 3.删除结点 "<<endl;cout<<" 4.遍历链表 "<<endl;cout<<" 0.结束程序 "<<endl;cout<<"======================================"<<endl;cout<<"请输入您的选择:";}void interfacebase::processmenu(void){int returnvalue,item,position;char menuchoice;cin >>menuchoice;switch(menuchoice) //根据用户的选择进行相应的操作{case '1':returnvalue=listface.create();if(returnvalue==success)cout<<"链表创建已完成"<<endl;break;case '2':cout<<"请输入插入位置:"<<endl;cin>>position;cout<<"请输入插入数据:"<<endl;cin>>item;returnvalue = listface.insert(position,item);if(returnvalue==range_error)cout<<"数据个数超出范围"<<endl;elsecout<<"操作成功!!!"<<endl;break;case '3':cout<<"输入你要删除的位置:"<<endl;cin>>position;returnvalue = listface.remove(position);if(returnvalue==underflow)cout<<"链表已空"<<endl;else if(returnvalue==range_error)cout<<"删除的数据位置超区范围"<<endl;elsecout<<"操作成功!!!"<<endl;break;case '4':listface.traverse();break;case '0':cout<<endl<<endl<<"您已经成功退出本系统,欢迎再次使用!!!"<<endl;system("pause");exit(1);default:cout<<"对不起,您输入的功能编号有错!请重新输入!!!"<<endl;break;}}void main(){interfacebase interfacenow;linklist listnow;system("color f0");interfacenow.clearscreen();while(1){interfacenow.showmenu();interfacenow.processmenu();system("pause");interfacenow.clearscreen();}}/* 功能:用双向循环链表存储数据1.创建链表2.增加结点3.删除结点4.遍历链表制作人:余帅内容:239行*/#include<iostream.h>#include<windows.h>const MAX=5;enum returninfo{success,fail,overflow,underflow,range_error}; int defaultdata[MAX]={11,22,33,44,55};class node{public:int data;node * next; //指向后续节点node * pre; //指向前面的节点};class linklist{private:node *headp;protected:int count;public:linklist();~linklist();bool empty();void clearlist();returninfo create(void);returninfo insert(int position,const int &item);returninfo remove(int position) ;returninfo traverse(void);};linklist::linklist(){headp = new node;headp->next = NULL;headp->pre = NULL;count=0;}linklist::~linklist(){clearlist();delete headp;}bool linklist::empty(){if(headp->next==NULL)return true;elsereturn false;}void linklist::clearlist(){node *searchp=headp->next,*followp=headp;while(searchp->next!=NULL){followp=searchp;searchp=searchp->next;delete followp;}headp->next = NULL;headp->pre = NULL;count = 0;}returninfo linklist::create(){node *searchp=headp,*newnodep;for(int i=0;i<MAX;i++){newnodep = new node;newnodep->data = defaultdata[i];newnodep->next = NULL;searchp->next = newnodep;newnodep->pre = searchp;searchp = searchp->next;count++;}searchp->next = headp;headp->pre = searchp;traverse();return success;}returninfo linklist::insert(int position,const int &item) //插入一个结点{if(position<=0 || position>count+1)return range_error;node *newnodep=new node;node *searchp=headp->next,*followp=headp;for(int i=1; i<position && searchp!=NULL;i++){followp=searchp;searchp=searchp->next;}newnodep->data=item; //给数据赋值newnodep->next = searchp;searchp->pre = newnodep;followp->next = newnodep;newnodep->pre = followp;count++; //计数器加一return success;}returninfo linklist::remove(int position) //删除一个结点{if(empty())return underflow;if(position<=0||position>=count+1)return range_error;node *searchp=headp->next,*followp=headp; //这里两个指针的初始值设计一前一后for(int i=1; i<position && searchp!=NULL;i++){followp=searchp;searchp=searchp->next;}followp->next=searchp->next; //删除结点的实际语句searchp->next->pre = followp;delete searchp; //释放该结点count--; //计数器减一return success;}returninfo linklist::traverse(void){node *searchp1,*searchp2;if(empty())return underflow;searchp1 = headp;searchp2 = headp;cout<<"连表中的数据为:"<<endl;cout<<"从左至右读取:";while (searchp1->next!=headp ) {searchp1 = searchp1 ->next;cout << searchp1->data<<" ";}cout<<endl;cout<<"从右至左读取:";while (searchp2->pre!=headp ) {searchp2 = searchp2 ->pre;cout << searchp2->data<<" ";}cout<<endl;return success;}class interfacebase{public:linklist listface; //定义一个对象Cskillstudyonface void clearscreen(void);void showmenu(void);void processmenu(void);};void interfacebase::clearscreen(void){system("cls");}void interfacebase::showmenu(void){cout<<"================================"<<endl;cout<<" 功能菜单 "<<endl;cout<<" 1.创建链表 "<<endl;cout<<" 2.增加结点 "<<endl;cout<<" 3.删除结点 "<<endl;cout<<" 4.遍历链表 "<<endl;cout<<" 0.结束程序 "<<endl;cout<<"======================================"<<endl;cout<<"请输入您的选择:";}void interfacebase::processmenu(void){int returnvalue,item,position;char menuchoice;cin >>menuchoice;switch(menuchoice) //根据用户的选择进行相应的操作{case '1':returnvalue=listface.create();if(returnvalue==success)cout<<"链表创建已完成"<<endl;break;case '2':cout<<"请输入插入位置:"<<endl;cin>>position;cout<<"请输入插入数据:"<<endl;cin>>item;returnvalue = listface.insert(position,item);if(returnvalue==range_error)cout<<"数据个数超出范围"<<endl;elsecout<<"操作成功!!!"<<endl;break;case '3':cout<<"输入你要删除的位置:"<<endl;cin>>position;returnvalue = listface.remove(position);if(returnvalue==underflow)cout<<"链表已空"<<endl;else if(returnvalue==range_error)cout<<"删除的数据位置超区范围"<<endl;elsecout<<"操作成功!!!"<<endl;break;case '4':listface.traverse();break;case '0':cout<<endl<<endl<<"您已经成功退出本系统,欢迎再次使用!!!"<<endl;system("pause");exit(1);default:cout<<"对不起,您输入的功能编号有错!请重新输入!!!"<<endl;break;}}void main(){interfacebase interfacenow;linklist listnow;system("color f0");interfacenow.clearscreen();while(1){interfacenow.showmenu();interfacenow.processmenu();system("pause");interfacenow.clearscreen();}}运行结果:1.创建链表:2.增加结点3.删除结点心得体会:本次实验使我们对链表的实质了解更加明确了,对链表的一些基本操作也更加熟练了。


约瑟夫问题实验报告(文章一):约瑟夫问题数据结构实验报告中南民族大学管理学院学生实验报告实验项目: 约瑟夫问题课程名称:数据结构年级:专业:信息管理与信息系统指导教师:实验地点:管理学院综合实验室完成日期:小组成员:学年度第(一)、实验目的(1)掌握线性表表示和实现;(2)学会定义抽象数据类型;(3)学会分析问题,设计适当的解决方案;(二)、实验内容【问题描述】:编号为1,2,…,n 的n 个人按顺时针方向围坐一圈,每人持有一个密码(正整数)。
一开始任选一个正整数作为报数上限值m,从第一个人开始按顺时针方向自 1 开始顺序报数,报到m 时停止报数。
报m 的人出列,将他的密码作为新的m 值,从他在顺时针方向上的下一个人开始重新从1 报数,如此下去,直至所有人全部出列为止。
试设计一个程序求出出列顺序。
【基本要求】:利用单向循环链表存储结构模拟此过程,按照出列的顺序印出各人的编号。
【测试数据】:m 的初值为20;密码:3,1,7,2,4,8,4(正确的结果应为6,1,4,7,2,3,5)。
(三)、实验步骤(一)需求分析对于这个程序来说,首先要确定构造链表时所用的方法。
当数到m 时一个人就出列,也即删除这个节点,同时建立这个节点的前节点与后节点的联系。
由于是循环计数,所以才采用循环列表这个线性表方式。
程序存储结构利用单循环链表存储结构存储约瑟夫数据(即n个人的编码等),模拟约瑟夫的显示过程,按照出列的顺序显示个人的标号。
编号为1,2,?,n 的n 个人按顺时针方向围坐一圈,每人持有一个密码(正整数)。
一开始任选一个正整数作为报数上限值m,从第一个人开始按顺时针方向自1 开始顺序报数,报到m 时停止报数。
报m 的人出列,将他的密码作为新的m 值,从他在顺时针方向上的下一个人开始重新从1 报数,如此下去,直至所有人全部出列为止。
试设计一个程序求出出列顺序。
基本要求是利用单向循环链表存储结构模拟此过程,按照出列的顺序印出各人的编号。
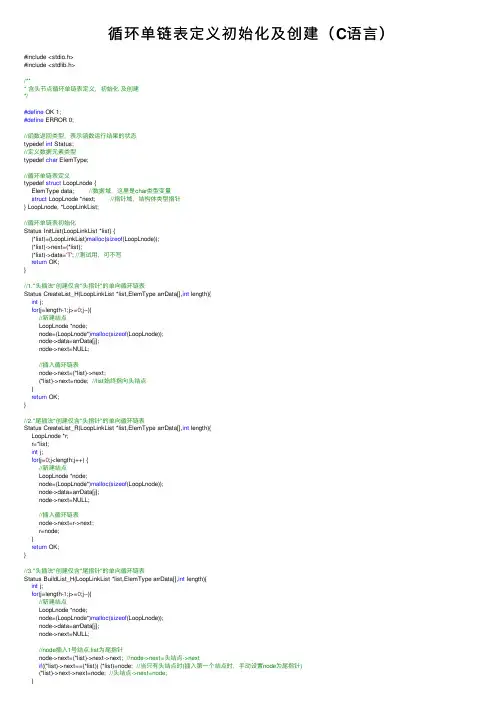
循环单链表定义初始化及创建(C语⾔)#include <stdio.h>#include <stdlib.h>/*** 含头节点循环单链表定义,初始化及创建*/#define OK 1;#define ERROR 0;//函数返回类型,表⽰函数运⾏结果的状态typedef int Status;//定义数据元素类型typedef char ElemType;//循环单链表定义typedef struct LoopLnode {ElemType data; //数据域,这⾥是char类型变量struct LoopLnode *next; //指针域,结构体类型指针} LoopLnode, *LoopLinkList;//循环单链表初始化Status InitList(LoopLinkList *list) {(*list)=(LoopLinkList)malloc(sizeof(LoopLnode));(*list)->next=(*list);(*list)->data='T'; //测试⽤,可不写return OK;}//1."头插法"创建仅含"头指针"的单向循环链表Status CreateList_H(LoopLinkList *list,ElemType arrData[],int length){int j;for(j=length-1;j>=0;j--){//新建结点LoopLnode *node;node=(LoopLnode*)malloc(sizeof(LoopLnode));node->data=arrData[j];node->next=NULL;//插⼊循环链表node->next=(*list)->next;(*list)->next=node; //list始终指向头结点}return OK;}//2."尾插法"创建仅含"头指针"的单向循环链表Status CreateList_R(LoopLinkList *list,ElemType arrData[],int length){LoopLnode *r;r=*list;int j;for(j=0;j<length;j++) {//新建结点LoopLnode *node;node=(LoopLnode*)malloc(sizeof(LoopLnode));node->data=arrData[j];node->next=NULL;//插⼊循环链表node->next=r->next;r=node;}return OK;}//3."头插法"创建仅含"尾指针"的单向循环链表Status BuildList_H(LoopLinkList *list,ElemType arrData[],int length){int j;for(j=length-1;j>=0;j--){//新建结点LoopLnode *node;node=(LoopLnode*)malloc(sizeof(LoopLnode));node->data=arrData[j];node->next=NULL;//node插⼊1号结点,list为尾指针node->next=(*list)->next->next; //node->next=头结点->nextif((*list)->next==(*list)) (*list)=node; //当只有头结点时(插⼊第⼀个结点时,⼿动设置node为尾指针)(*list)->next->next=node; //头结点->next=node;}return OK;}//4."尾插法"创建仅含"尾指针"的单向循环链表Status BuildList_R(LoopLinkList *list,ElemType arrData[],int length) {int j;for(j=0;j<length;j++) {//新建结点LoopLnode *node;node=(LoopLnode*)malloc(sizeof(LoopLnode));node->data=arrData[j];node->next=NULL;node->next=(*list)->next; //node->next=头结点(*list) = node; //尾指针 —> node}return OK;}int main(void){//产⽣待插⼊到链表的数据ElemType data1='A',data2='B',data3='C';ElemType waitInserted[]={data1,data2,data3,};//获得数组长度int arrLength=sizeof(waitInserted)/sizeof(waitInserted[0]);/**1.头插法建⽴只含头指针循环单链表**///定义链表并初始化LoopLinkList list1;InitList(&list1);//按既定数据建⽴链表CreateList_H(&list1,waitInserted,arrLength);//测试printf("%c\n",list1->next->next->next->next->next->next->data); //B/**2.尾插法建⽴只含头指针循环单链表**///定义链表并初始化LoopLinkList list2;InitList(&list2);//按既定数据建⽴链表CreateList_R(&list2,waitInserted,arrLength);//测试printf("%c\n",list1->next->next->next->next->next->next->data); //B/**3.头插法建⽴只含尾指针循环单链表**///定义链表并初始化LoopLinkList list3;InitList(&list3);//按既定数据建⽴链表BuildList_H(&list3,waitInserted,arrLength); //list3指向表尾//测试printf("%c\n",list3->next->next->next->next->next->next->next->next->next->data); //T/**4.尾插法建⽴只含尾指针循环单链表**///定义链表并初始化LoopLinkList list4;InitList(&list4);//按既定数据建⽴链表BuildList_H(&list4,waitInserted,arrLength); //list4指向表尾//测试printf("%c\n",list4->next->next->next->next->next->next->next->next->next->next->data); //A printf("\nEND!");return0;}。

单向链表基本操作的递归实现这几天正在复习一些基本的算法和实现,今天看了看递归的基本原理,发现自己对递归还不是特别清楚,特别是不清楚递归的思想,不能很准确的把握先分解成小事件,在合并的思想,其实也是数学归纳法的程序体现,其实数学归纳法是一种强大的方法,记得高中的时候最喜欢做的题目就是数学归纳方面的证明,现在想过来好多问题我不能采用这种方式思考,可见知识真的是有联系的,只是我们没有找到联系的方式而已。
为了熟悉递归的思想,我尝试了采用递归的方式实现单向链表的基本操作。
单向的链表是C语言课程中接触到的中比较复杂的数据结构,但是他确实其他数据结构的基础,在一般情况下都是采用迭代的形式实现,迭代的形式相比递归要节省时间和空间,但是代码相对来说要复杂,递归往往只是简单的几句代码,我主要是为了熟悉迭代,并不在性能上进行分析。
基本的实现如下所示:#include;#include;typedef struct listnode{int val;struct listnode *next;}List;/*统计节点个数*/int count_listnode(List *head) {static int count = 0;if(NULL != head){count += 1;if(head->;next != NULL){count_listnode(head->;next);}return count;}}/*顺序打印*/void fdprint_listnode(List *head) {if(NULL != head){printf("%d\t",head->;val);if(head->;next != NULL){fdprint_listnode(head->;next);}}}/*反向打印*/void bkprint_listnode(List *head) {if(head != NULL){if(head->;next != NULL){bkprint_listnode(head->;next);}printf("%d\t",head->;val);}}/*删除一个节点的数据为d的节点*/List *delete_node(List * head, int d) {List *temp = head;if(head != NULL){if(head->;val == d){temp = head;head = head->;next;free(temp);temp = NULL;}else{temp = head->;next;if(temp != NULL){temp = delete_node(temp,d); head->;next = temp;}}}return head;}/*删除所有val = d的节点*/List* delete_allnode(List *head, int d) {List *temp = head, *cur = head;if(head != NULL){/*如果第一个就是需要删除的对象*/if(cur->;val == d){temp = cur;cur = cur->;next;free(temp);temp = NULL;temp = delete_allnode(cur, d); head = temp;}else /*不是删除的对象*/{cur = head->;next;temp = delete_allnode(cur, d);/*将得到的链表连接到检测的区域*/ head->;next = temp;}}return head;}/*最大值*/int max_list(List *head){int max = 0;int temp;if(NULL == head){printf("Error: NULL pointer...");}if(NULL != head && head->;next == NULL){return head->;val;}else{temp = max_list(head->;next);max = (head->;val >; temp ? head->;val : temp); return max;}}/*最小值*/int min_list(List *head){int min = 0;int temp;if(NULL == head){printf("Error: NULL pointer...");}if(NULL != head && head->;next == NULL){return head->;val;}else{temp = min_list(head->;next);min = (head->;val ;val : temp); return min;}}/*创建链表*/List* create_list(int val){List *head = (List*)malloc(sizeof(List)/sizeof(char)); if(NULL == head){return NULL;}head->;val = val;head->;next = NULL;return head;}/*插入节点*/List* insert_listnode(List *head, int val) {List *temp;if(NULL == head){return NULL;}temp = (List*)malloc(sizeof(List)/sizeof(char));temp->;val = val;temp->;next = head;head = temp;return head;}/*删除链表*/void delete_list(List *head) {List *temp = NULL;if(head != NULL){temp = head;head = head->;next;free(temp);temp = NULL;delete_list(head);}}int main(){int n = 0;int i = 0;List * head = create_list(10);for(i = 0; i < 10; ++ i){n = 1 + (int)(10.0*rand()/(RAND_MAX + 1.0)); head = insert_listnode(head, n);}fdprint_listnode(head);printf("\n");bkprint_listnode(head);printf("\n%d\n", count_listnode(head));printf("\n");#if 10head = delete_node(head, 10); fdprint_listnode(head);printf("\n");bkprint_listnode(head);printf("\n");#endif#if 10head = delete_allnode(head, 10);fdprint_listnode(head);printf("\n");bkprint_listnode(head);#endifprintf("max = %d\n",max_list(head)); printf("max = %d\n",min_list(head));delete_list(head);head = NULL;if(head == NULL){printf("ERROR:null pointer!...\n"); }return 0;}递归中需要注意的思想我任务就是为了解决当前的问题,我完成最简单的一部操作,其他的由别人去完成,比如汉诺塔中的第一个和尚让第二个和尚把前63个金盘放在B处,而他自己只需要完成从A到C的搬运,实质上他自己完成的只有一部最简答的,但是搬运这种动作有存在非常大的相似性。
《数据结构(高起专)》2020年奥鹏东北师大考核试题标准答案满分100分一、简答题(每小题8分,共40分。
)1.什么是有根的有向图?2.什么是负载因子?3.试分析顺序存储结构的优缺点。
4.算法的时间复杂度仅与问题的规模相关吗?5.举例说明散列表的平均查找长度不随表中结点数目增加而增加,而是随着负载因子增大而增大。
二、图示题(每小题15分,共30分。
)1.设待排序文件的初始排序码序列为 { 32, 38, 10, 53, 80, 69, 32, 05 },写出采用冒泡排序算法排序时,每趟结束时的状态。
2.设有关键字集合为{ 16,05,28,10,09,17 },散列表的长度为8,用除留余数法构造散列函数,用线性探查法解决冲突,并按关键字在集合中的顺序插入,请画出此散列(哈希)表,并求出在等概率情况下查找成功的平均查找长度。
三、算法题(每小题15分,共30分。
)1. 二叉树以二叉链表(lchild-rchild表示法)作为存储结构,试编写计算二叉树中叶结点个数的算法(要求写出存储结构的描述),并分析算法的时间复杂度。
2. 编写一个求单循环链表中结点个数的算法,并分析算法的时间复杂度(要求写出存储结构的描述)。
答一、简答题1.什么是有根的有向图?答:在一个有向图中,若存在一个顶点V0,从该顶点有路经可以到达图中其他所有顶点,则称此有向图为有根的有向图,V0称作图的根。
2.什么是负载因子?答:负载因子(load factor),也称为装填因子,定义为:3.试分析顺序存储结构的优缺点。
答:优点:⑴ 内存的存储密度高(d=1);⑵ 可以随机地存取表中的结点,与i 的大小无关。
缺点:⑴ 进行插入和删除结点的运算时,往往会造成大量结点的移动,效率较低;⑵ 顺序表的存储空间常采用静态分配,在程序运行前存储规模很难预先确定。
估计过大将导致空间浪费,估计小了,随着结点不断插入,所需的存储空间超出了预先分配的存储空间,就会发生空间溢出。
目录课题一 joseph环 41.1 问题的提出1.1.问题的提出41.2 概要设计2.1算法思想51.3流程图根据算法思想,画程序流程图如下:661.4 源代码1.3.详细设计 7 输入m 、nm>0且n>0的整数建立含n 个结点的链表且用head 指向第一个元素,结点数据域包含password 、No 、以及指向下一结点的指head=>pn ≥2(m%n)==0?n:m%n=>1=>i i<mp →next=>pi++输出p →Nop →password=>m删除p 所指向结点n--输出p →No结束开始1.5 结果与分析.4 测试及性能分析10课题二拓扑排序 112.1 问题的提出2.1 问题的提出112. 2 概要设计112.3 流程图2.根据算法思想,画流程图如下:1212 开始设辅助数组indegree 记录图的各顶点的入度值,并将indegree 数组各变量赋初值。
输入图的顶点数、边数建立一个栈,存储图的顶点的序号用邻接表法建图,并计算出indegree 数组中各变量值根据indegree 数组将入度为0的顶点入栈count 对输出顶点计数0=>count栈不空删除栈顶元素,赋给i count++将与第i 个顶点链接的各顶点入度减1输出第i 个顶点值 顶点入度为0 顶点序号入栈count<G.vexnum输出“拓扑排序成功” 输出“拓扑排序不成功” 结束2.4 源代码132.5 结果与分析2.4 测试及性能分析17课题三纸牌游戏 193.1 问题的提出.1 问题的提出193. 2 概要设计191.当每个号码每次遇到是某个数的倍数时,都会相应的翻一次,这样,每张牌会翻的次数就各不一样,可能很多次,也可能只有一两次,结果就只是要输出在经过各个不同次数的翻牌后,正面向上的牌都有哪几个。
举例说明一下,比如24,第一次它是2的倍数时要从正面翻到背面,当进行到3时,就又要从背面翻回来,而到4时还要在翻,同理呢,到6.8.12…它都要来回的翻。
C语言经典算法目录一、单元加.................................... 错误!未定义书签。
1.erre ...................................... 错误!未定义书签。
2. erre2 ................................... 错误!未定义书签。
3. 数组完全单元........................ 错误!未定义书签。
4. 栈单元加.............................. 错误!未定义书签。
二、底层编程 ................................ 错误!未定义书签。
1. asm ..................................... 错误!未定义书签。
2. C标志符命名源程序............... 错误!未定义书签。
3. ping .................................... 错误!未定义书签。
4. winsock2 ............................. 错误!未定义书签。
5. 检测鼠标.............................. 错误!未定义书签。
6. 检出错误.............................. 错误!未定义书签。
7. 时间陷阱.............................. 错误!未定义书签。
三、汉诺塔.................................... 错误!未定义书签。
1. 非递归................................. 错误!未定义书签。
2. 汉诺塔................................. 错误!未定义书签。
3. 汉诺塔2 .............................. 错误!未定义书签。
链表1 定义链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。
由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
在计算机科学中,链表作为一种基础的数据结构可以用来生成其它类型的数据结构。
链表通常由一连串节点组成,每个节点包含任意的实例数据(data fields)和一或两个用来指向明上一个或下一个节点的位置的链接("links")。
链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的访问往往要在不同的排列顺序中转换。
而链表是一种自我指示数据类型,因为它包含指向另一个相同类型的数据的指针(链接)。
链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。
链表有很多种不同的类型:单向链表,双向链表以及循环链表。
2 结构2.1 单向链表链表中最简单的一种是单向链表,它包含两个域,一个信息域和一个指针域。
这个链接指向列表中的下一个节点,而最后一个节点则指向一个空值。
一个单向链表的节点被分成两个部分。
第一个部分保存或者显示关于节点的信息,第二个部分存储下一个节点的地址。
单向链表只可向一个方向遍历。
链表最基本的结构是在每个节点保存数据和到下一个节点的地址,在最后一个节点保存一个特殊的结束标记,另外在一个固定的位置保存指向第一个节点的指针,有的时候也会同时储存指向最后一个节点的指针。
一般查找一个节点的时候需要从第一个节点开始每次访问下一个节点,一直访问到需要的位置。
软件英才网软件行业驰名招聘网站
一步一步写算法(之循环单向链表)
前面的博客中,我们曾经有一篇专门讲到单向链表的内容。
那么今天讨论的链表和上次讨论的链表有什么不同呢?重点就在这个"循环"上面。
有了循环,意味着我们可以从任何一个链表节点开始工作,可以把root定在任何链表节点上面,可以从任意一个链表节点访问数据,这就是循环的优势。
那么在实现过程中,循环单向链表有什么不同?
1)打印链表数据
1void print_data(const LINK_NODE* pLinkNode)
2{
3 LINK_NODE* pIndex = NULL;
4if(NULL == pLinkNode)
5return;
6
7 printf("%d\n", pLinkNode->data);
8 pIndex = pLinkNode->next;
9while(pLinkNode != pIndex){
10 printf("%d\n", pIndex->data);
11 pIndex = pIndex ->next;
12 }
13}
以往,我们发现打印数据的结束都是判断指针是否为NULL,这里因为是循环链表所以发生了变化。
原来的条件(NULL != pLinkNode)也修改成了这里的(pLinkNode != pIndex)。
同样需要修改的函数还有find函数、count统计函数。
2)插入数据
14STATUS insert_data(LINK_NODE** ppLinkNode, int data)
15{
16 LINK_NODE* pNode;
17if(NULL == ppLinkNode)
18return FALSE;
19
20if(NULL == *ppLinkNode){
21 pNode = create_link_node(data);
22 assert(NULL != pNode);
软件英才网软件行业驰名招聘网站23
24 pNode->next = pNode;
25 *ppLinkNode = pNode;
26return TRUE;
27 }
28
29if(NULL != find_data(*ppLinkNode, data))
30return FALSE;
31
32 pNode = create_link_node(data);
33 assert(NULL != pNode);
34
35 pNode->next = (*ppLinkNode)->next;
36 (*ppLinkNode)->next = pNode;
37return TRUE;
38}
这里的insert函数在两个地方发生了变化:a)如果原来链表中没有节点,那么链表节点需要自己指向自己
b)如果链表节点原来存在,那么只需要在当前的链表节点后面添加一个数据,同时修改两个方向的指针即可
3)删除数据
39STATUS delete_data(LINK_NODE** ppLinkNode, int data)
40{
41 LINK_NODE* pIndex = NULL;
42 LINK_NODE* prev = NULL;
43if(NULL == ppLinkNode || NULL == *ppLinkNode)
44return FALSE;
45
46 pIndex = find_data(*ppLinkNode, data);
47if(NULL == pIndex)
48return FALSE;
49
50if(pIndex == *ppLinkNode){
51if(pIndex == pIndex->next){
52 *ppLinkNode = NULL;
53 }else{
54 prev = pIndex->next;
软件英才网软件行业驰名招聘网站55while(pIndex != prev->next)
56 prev = prev->next;
57
58 prev->next = pIndex->next;
59 *ppLinkNode = pIndex->next;
60 }
61 }else{
62 prev = pIndex->next;
63while(pIndex != prev->next)
64 prev = prev->next;
65 prev->next = pIndex->next;
66 }
67
68 free(pIndex);
69return TRUE;
70}
和添加数据一样,删除数据也要在两个方面做出改变:a)如果当前链表节点中只剩下一个数据的时候,删除后需要设置为NULL
b)删除数据的时候首先需要当前数据的前一个数据,这个时候就可以从当前删除的数据开始进行遍历
c)删除的时候需要重点判断删除的数据是不是链表的头结点数据
1。