应用回归分析-第2章课后习题参考答案
- 格式:doc
- 大小:1.02 MB
- 文档页数:19

《使用回归分析》部分课后习题答案第一章回归分析概述变量间统计关系和函数关系的区别是什么答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。
回归分析和相关分析的联系和区别是什么答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有 a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。
在相关分析中,变量x和变量y处于平等的地位,即研究变量y和变量x的密切程度和研究变量x 和变量y的密切程度是一回事。
b.相关分析中所涉及的变量y和变量x全是随机变量。
而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
回归模型中随机误差项ε的意义是什么答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y和x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
线性回归模型的基本假设是什么答:线性回归模型的基本假设有:1.解释变量….xp是非随机的,观测值…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^2《3.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.回归变量的设置理论根据是什么在回归变量设置时应注意哪些问题答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。

第二章 一元線性回歸分析思考與練習參考答案2.1 一元線性回歸有哪些基本假定?答: 假設1、解釋變數X 是確定性變數,Y 是隨機變數;假設2、隨機誤差項ε具有零均值、同方差和不序列相關性: E(εi )=0 i=1,2, …,n Var (εi )=σ2 i=1,2, …,n Cov(εi, εj )=0 i≠j i,j= 1,2, …,n 假設3、隨機誤差項ε與解釋變數X 之間不相關: Cov(X i , εi )=0 i=1,2, …,n假設4、ε服從零均值、同方差、零協方差の正態分佈 εi ~N(0, σ2 ) i=1,2, …,n 2.2 考慮過原點の線性回歸模型 Y i =β1X i +εi i=1,2, …,n誤差εi (i=1,2, …,n )仍滿足基本假定。
求β1の最小二乘估計 解: 得:2.3 證明(2.27式),∑e i =0 ,∑e i X i =0 。
證明:∑∑+-=-=nii i ni X Y Y Y Q 121021))ˆˆ(()ˆ(ββ其中:即: ∑e i =0 ,∑e i X i =021112)ˆ()ˆ(ini i ni i i e X Y Y Y Q β∑∑==-=-=01ˆˆˆˆi ii i iY X e Y Y ββ=+=-0100ˆˆQQββ∂∂==∂∂2.4回歸方程E (Y )=β0+β1X の參數β0,β1の最小二乘估計與最大似然估計在什麼條件下等價?給出證明。
答:由於εi ~N(0, σ2 ) i=1,2, …,n所以Y i =β0 + β1X i + εi ~N (β0+β1X i , σ2 ) 最大似然函數:使得Ln (L )最大の0ˆβ,1ˆβ就是β0,β1の最大似然估計值。
同時發現使得Ln (L )最大就是使得下式最小,∑∑+-=-=nii i n i X Y Y Y Q 121021))ˆˆ(()ˆ(ββ上式恰好就是最小二乘估計の目標函數相同。
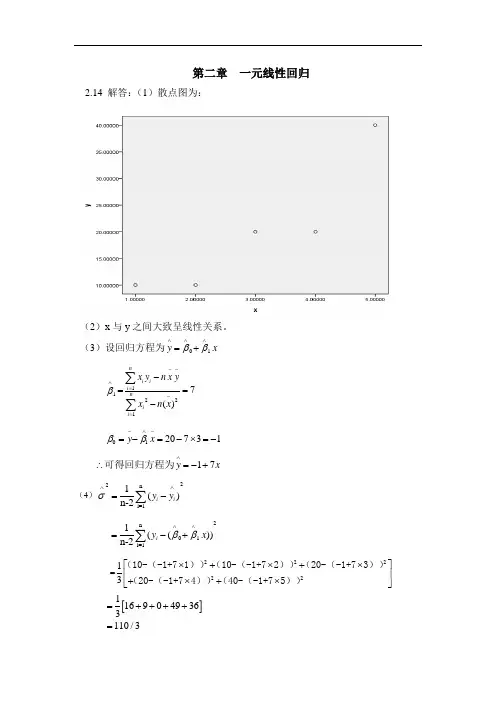
第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑ 2n 01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=(5)由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2||(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353 即为:(2.49,11.5)2201()(,())xxx Nn L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()ni i nii y y r y y ∧-=-=-==≈-∑∑(7)由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
(8)t σ∧==其中2221111()22n ni i i i i e y y n n σ∧∧====---∑∑ 7 3.661==≈/2 2.353t α= /23.66t t α=>∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。


《使用回归分析》部分课后习题答案第一章回归分析概述1.1变量间统计关系和函数关系的区别是什么?答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。
1.2回归分析和相关分析的联系和区别是什么?答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有 a.在回归分析中,变量y 称为因变量,处在被解释的特殊地位。
在相关分析中,变量x 和变量 y 处于平等的地位,即研究变量 y 和变量 x 的密切程度和研究变量 x 和变量 y 的密切程度是一回事。
b. 相关分析中所涉及的变量 y 和变量 x 全是随机变量。
而在回归分析中,因变量 y 是随机变量,自变量 x 可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量 x 对变量 y 的影响大小,还可以由回归方程进行预测和控制。
1.3回归模型中随机误差项ε的意义是什么?答:ε 为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究 y 和 x1,x2 ⋯..xp 的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4线性回归模型的基本假设是什么?答:线性回归模型的基本假设有: 1. 解释变量 x1.x2 ⋯.xp 是非随机的,观测值xi1.xi2 ⋯..xip 是常数。
2. 等方差及不相关的假定条件为 {E( εi)=0 i=1,2 ⋯. Cov(εi,εj)= {σ^23.正态分布的假定条件为相互独立。
4. 样本容量的个数要多于解释变量的个数,即 n>p.1.5 回归变量的设置理论根据是什么?在回归变量设置时应注意哪些问题?答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。

实用回归分析第四版 第一章 回归分析概述1.3 回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y 与x1,x2…..xp 的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp 是非随机的,观测值xi1.xi2…..xip 是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.第二章 一元线性回归分析思考与练习参考答案2.1 一元线性回归有哪些基本假定?答: 假设1、解释变量X 是确定性变量,Y 是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性: E(εi )=0 i=1,2, …,n Var (εi )=σ2 i=1,2, …,n Cov(εi, εj )=0 i≠j i,j= 1,2, …,n 假设3、随机误差项ε与解释变量X 之间不相关: Cov(X i , εi )=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布 εi ~N(0, σ2 ) i=1,2, …,n 2.3 证明(2.27式),∑e i =0 ,∑e i X i =0 。
证明:其中:∑∑+-=-=nii i n i X Y Y Y Q 121021))ˆˆ(()ˆ(ββ01ˆˆˆˆi i i i iY X e Y Y ββ=+=-0100ˆˆQQββ∂∂==∂∂即: ∑e i =0 ,∑e i X i =02.5 证明0ˆβ是β0的无偏估计。

《使用回归分析》部分课后习题答案第一章回归分析概述变量间统计关系和函数关系的区别是什么答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。
回归分析和相关分析的联系和区别是什么答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有 a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。
在相关分析中,变量x和变量y处于平等的地位,即研究变量y和变量x的密切程度和研究变量x和变量y的密切程度是一回事。
b.相关分析中所涉及的变量y和变量x全是随机变量。
而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
回归模型中随机误差项ε的意义是什么答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y和x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
—线性回归模型的基本假设是什么答:线性回归模型的基本假设有:1.解释变量….xp是非随机的,观测值…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.回归变量的设置理论根据是什么在回归变量设置时应注意哪些问题答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。


实用回归分析第四版第一章回归分析概述1.3回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.第二章一元线性回归分析思考与练习参考答案2.1一元线性回归有哪些基本假定?答:假设1、解释变量X是确定性变量,Y是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(εi)=0 i=1,2, …,nVar (εi)=σ2i=1,2, …,nCov(εi,εj)=0 i≠j i,j= 1,2, …,n假设3、随机误差项ε与解释变量X之间不相关:Cov(X i, εi)=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布εi~N(0, σ2) i=1,2, …,n2.3 证明(2.27式),∑e i =0 ,∑e i X i=0 。
证明:∑∑+-=-=niiiniXYYYQ12121))ˆˆ(()ˆ(ββ其中:01ˆˆˆˆi i i i iY X e Y Yββ=+=-0100ˆˆQ Qββ∂∂==∂∂即: ∑e i =0 ,∑e i X i =02.5 证明0ˆβ是β0的无偏估计。
证明:)1[)ˆ()ˆ(1110∑∑==--=-=ni i xx i n i iY L X X X Y n E X Y E E ββ )] )(1([])1([1011i i xx i n i i xx i ni X L X X X n E Y L X X X n E εββ++--=--=∑∑==1010)()1(])1([βεβεβ=--+=--+=∑∑==i xx i ni i xx i ni E L X X X nL X X X n E 2.6 证明 证明:)] ()1([])1([)ˆ(102110i i xx i ni i xx i ni X Var L X X X nY L X X X n Var Var εβββ++--=--=∑∑== 222212]1[])(2)1[(σσxxxx i xx i ni L X n L X X X nL X X X n +=-+--=∑=2.7证明平方和分解公式:SST=SSE+SSR证明:2.8 验证三种检验的关系,即验证: (1)21)2(r r n t --=;(2)2221ˆˆ)2/(1/t L n SSE SSR F xx ==-=σβ 证明:(1)())1()1()ˆ(222122xx ni iL X n X XX nVar +=-+=∑=σσβ()()∑∑==-+-=-=n i ii i n i i Y Y Y Y Y Y SST 1212]ˆ()ˆ[()()()∑∑∑===-+--+-=ni ii ni i i i ni iY Y Y Y Y Y Y Y 12112)ˆˆ)(ˆ2ˆ()()SSESSR )Y ˆY Y Y ˆn1i 2ii n1i 2i +=-+-=∑∑==ˆt======(2)2222201111 1111ˆˆˆˆˆˆ()()(())(()) n n n ni i i i xxi i i iSSR y y x y y x x y x x Lβββββ=====-=+-=+--=-=∑∑∑∑2212ˆ/1ˆ/(2)xxLSSRF tSSE nβσ∴===-2.9 验证(2.63)式:2211σ)L)xx(n()e(Varxxii---=证明:0112222222ˆˆˆvar()var()var()var()2cov(,)ˆˆˆvar()var()2cov(,())()()11[]2[]()1[1]i i i i i i ii i i ii ixx xxixxe y y y y y yy x y y x xx x x xn L n Lx xn Lβββσσσσ=-=+-=++-+---=++-+-=--其中:222221111))(1()(1))(,()()1,())(ˆ,(),())(ˆ,(σσσββxxixxiniixxiiiniiiiiiiiLxxnLxxnyLxxyCovxxynyCovxxyCovyyCovxxyyCov-+=-+=--+=-+=-+∑∑==2.10 用第9题证明2ˆ22-=∑neiσ是σ2的无偏估计量证明:2221122112211ˆˆ()()()22()111var()[1]221(2)2n ni ii in niii i xxE E y y E en nx xen n n Lnnσσσσ=====-=---==----=-=-∑∑∑∑第三章1.一个回归方程的复相关系数R=0.99,样本决定系数R2=0.9801,我们能判断这个回归方程就很理想吗? 答:不能断定这个回归方程理想。

2.1 一元线性回归模型有哪些基本假定?答:1. 解释变量 1x , ,2x ,p x 是非随机变量,观测值,1i x ,,2 i x ip x 是常数。
2. 等方差及不相关的假定条件为⎪⎪⎩⎪⎪⎨⎧⎪⎩⎪⎨⎧≠=====j i n j i j i n i E j i i ,0),,2,1,(,),cov(,,2,1,0)(2 σεεε 这个条件称为高斯-马尔柯夫(Gauss-Markov)条件,简称G-M 条件。
在此条件下,便可以得到关于回归系数的最小二乘估计及误差项方差2σ估计的一些重要性质,如回归系数的最小二乘估计是回归系数的最小方差线性无偏估计等。
3. 正态分布的假定条件为⎩⎨⎧=相互独立n i n i N εεεσε,,,,,2,1),,0(~212 在此条件下便可得到关于回归系数的最小二乘估计及2σ估计的进一步结果,如它们分别是回归系数的最及2σ的最小方差无偏估计等,并且可以作回归的显著性检验及区间估计。
4. 通常为了便于数学上的处理,还要求,p n >及样本容量的个数要多于解释变量的个数。
在整个回归分析中,线性回归的统计模型最为重要。
一方面是因为线性回归的应用最广泛;另一方面是只有在回归模型为线性的假设下,才能的到比较深入和一般的结果;再就是有许多非线性的回归模型可以通过适当的转化变为线性回归问题进行处理。
因此,线性回归模型的理论和应用是本书研究的重点。
1. 如何根据样本),,2,1)(;,,,(21n i y x x x i ip i i =求出p ββββ,,,,210 及方差2σ的估计;2. 对回归方程及回归系数的种种假设进行检验;3. 如何根据回归方程进行预测和控制,以及如何进行实际问题的结构分析。
2.2 考虑过原点的线性回归模型 n i x y i i i ,,2,1,1 =+=εβ误差n εεε,,,21 仍满足基本假定。
求1β的最小二乘估计。
答:∑∑==-=-=ni ni i i i x y y E y Q 1121121)())(()(ββ∑∑∑===+-=--=∂∂n i n i ni i i i i i i x y x x x y Q111211122)(2βββ 令,01=∂∂βQ即∑∑===-n i ni i i i x y x 11210β 解得,ˆ1211∑∑===ni ini i i xyx β即1ˆβ的最小二乘估计为.ˆ1211∑∑===ni ini ii xyx β2.3 证明: Q (β,β1)= ∑(y i-β0-β1x i)2因为Q (∧β0,∧β1)=min Q (β0,β1 )而Q (β0,β1) 非负且在R 2上可导,当Q 取得最小值时,有即-2∑(y i -∧β0-∧β1x i )=0 -2∑(y i-∧β0-∧β1x i ) x i=0又∵e i =yi -( ∧β0+∧β1x i )= yi -∧β0-∧β1x i ∴∑e i =0,∑e i x i =0(即残差的期望为0,残差以变量x 的加权平均值为零)2.4 解:参数β0,β1的最小二乘估计与最大似然估计在εi~N(0, 2 ) i=1,2,……n 的条件下等价。

应用回归分析_第2章课后习题参考答案1. 简答题1.1 什么是回归分析?回归分析是一种统计建模方法,用于研究自变量与因变量之间的关系。
它通过建立数学模型,根据已知的自变量和因变量数据,预测因变量与自变量之间的关系,并进行相关的推断和预测。
1.2 什么是简单线性回归和多元线性回归?简单线性回归是指只包含一个自变量和一个因变量的回归模型,通过拟合一条直线来描述两者之间的关系。
多元线性回归是指包含多个自变量和一个因变量的回归模型,通过拟合一个超平面来描述多个自变量和因变量之间的关系。
1.3 什么是残差?残差是指回归模型中,观测值与模型预测值之间的差异。
在回归分析中,我们希望最小化残差,使得模型与观测数据的拟合效果更好。
1.4 什么是拟合优度?拟合优度是用来评估回归模型对观测数据的拟合程度的指标。
一般使用R方(Coefficient of Determination)来表示拟合优度,其值范围为0到1,值越接近1表示模型拟合效果越好。
2. 计算题2.1 简单线性回归假设我们有一组数据,其中X为自变量,Y为因变量,如下所示:X Y13253749511我们想要建立一个简单线性回归模型,计算X与Y之间的线性关系。
首先,我们需要计算拟合直线的斜率和截距。
根据简单线性回归模型的公式Y = β0 + β1*X,我们可以通过最小二乘法计算出斜率和截距的估计值。
首先,计算X和Y的均值:mean_x = (1 + 2 + 3 + 4 + 5) / 5 = 3mean_y = (3 + 5 + 7 + 9 + 11) / 5 = 7然后,计算X和Y的方差:var_x = ((1-3)^2 + (2-3)^2 + (3-3)^2 + (4-3)^2 + (5-3)^2) / 5 = 2var_y = ((3-7)^2 + (5-7)^2 + (7-7)^2 + (9-7)^2 + (11-7)^2) / 5 = 8接下来,计算X和Y的协方差:cov_xy = ((1-3) * (3-7) + (2-3) * (5-7) + (3-3) * (7-7) + (4-3) * (9-7) + (5-3) * (11-7)) / 5 = 4根据最小二乘法的公式:β1 = cov_xy / var_x = 4 / 2 = 2β0 = mean_y - β1 * mean_x = 7 - (2 * 3) = 1因此,拟合直线的方程为:Y = 1 + 2X。
第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑2n01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=≈ (5)由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353 即为:(2.49,11.5)22001()(,())xxx N n L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()nii nii y y r y y ∧-=-=-==≈-∑∑由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
(8)t σ∧==其中2221111()22n ni i i i i e y y n n σ∧∧====---∑∑ 3.66==≈/2 2.353t α= /23.66t t α=>∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。
第二章 一元线性回归分析思考与练习参考答案2.1 一元线性回归有哪些基本假定?答: 假设1、解释变量X 是确定性变量,Y 是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性: E(εi )=0 i=1,2, …,n Var (εi )=σ2 i=1,2, …,n Cov(εi, εj )=0 i≠j i,j= 1,2, …,n 假设3、随机误差项ε与解释变量X 之间不相关: Cov(X i , εi )=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布 εi ~N(0, σ2 ) i=1,2, …,n 2.2 考虑过原点的线性回归模型 Y i =β1X i +εi i=1,2, …,n误差εi (i=1,2, …,n )仍满足基本假定。
求β1的最小二乘估计 解: 得:2.3 证明(2.27式),∑e i =0 ,∑e i X i =0 。
证明:∑∑+-=-=nii i ni X Y Y Y Q 121021))ˆˆ(()ˆ(ββ其中: 即: ∑e i =0 ,∑e i X i =02.4回归方程E (Y )=β0+β1X 的参数β0,β1的最小二乘估计与最大似然估计在什么条件下等价?给出证明。
答:由于εi ~N(0, σ2 ) i=1,2, …,n所以Y i =β0 + β1X i + εi ~N (β0+β1X i , σ2 ) 最大似然函数:使得Ln (L )最大的0ˆβ,1ˆβ就是β0,β1的最大似然估计值。
同时发现使得Ln (L )最大就是使得下式最小,上式恰好就是最小二乘估计的目标函数相同。
值得注意的是:最大似然估计是在εi ~N (0, σ2 )21112)ˆ()ˆ(i ni i ni ii e X Y Y Y Q β∑∑==-=-=01ˆˆˆˆi ii i iY X e Y Y ββ=+=-0100ˆˆQQββ∂∂==∂∂的假设下求得,最小二乘估计则不要求分布假设。
实用回归分析第四版第一章回归分析概述1.3回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.第二章一元线性回归分析思考与练习参考答案2.1一元线性回归有哪些基本假定?答:假设1、解释变量X是确定性变量,Y是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(εi)=0 i=1,2, …,nVar (εi)=σ2i=1,2, …,nCov(εi,εj)=0 i≠j i,j= 1,2, …,n假设3、随机误差项ε与解释变量X之间不相关:Cov(X i, εi)=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布εi~N(0, σ2) i=1,2, …,n2.3 证明(2.27式),∑e i =0 ,∑e i X i=0 。
证明:∑∑+-=-=niiiniXYYYQ12121))ˆˆ(()ˆ(ββ其中:即: ∑e i =0 ,∑e i X i =02.5 证明0ˆβ是β0的无偏估计。
证明:)1[)ˆ()ˆ(1110∑∑==--=-=ni i xxi n i i Y L X X X Y n E X Y E E ββ )] )(1([])1([1011i i xx i n i i xx i ni X L X X X n E Y L X X X n E εββ++--=--=∑∑==1010)()1(])1([βεβεβ=--+=--+=∑∑==i xx i ni i xx i ni E L X X X nL X X X n E 2.6 证明 证明:)] ()1([])1([)ˆ(102110i i xxi ni ixx i ni X Var L X X X n Y L X X X n Var Var εβββ++--=--=∑∑== 222212]1[])(2)1[(σσxx xx i xx i ni L X n L X X X nL X X X n +=-+--=∑=2.7 证明平方和分解公式:SST=SSE+SSR证明:2.8 验证三种检验的关系,即验证: (1)21)2(r r n t --=;(2)2221ˆˆ)2/(1/t L n SSE SSR F xx ==-=σβ 01ˆˆˆˆi i i i iY X e Y Y ββ=+=-())1()1()ˆ(222122xx ni iL X n X XX nVar +=-+=∑=σσβ()()∑∑==-+-=-=n i ii i n i i Y Y Y Y Y Y SST 1212]ˆ()ˆ[()()()∑∑∑===-+--+-=ni ii ni i i i ni iY Y Y Y Y Y Y Y 12112)ˆˆ)(ˆ2ˆ()()SSESSR )Y ˆY Y Y ˆn1i 2ii n1i 2i +=-+-=∑∑==0100ˆˆQQββ∂∂==∂∂证明:(1)ˆt======(2)2222201111 1111ˆˆˆˆˆˆ()()(())(()) n n n ni i i i xxi i i iSSR y y x y y x x y x x Lβββββ=====-=+-=+--=-=∑∑∑∑2212ˆ/1ˆ/(2)xxLSSRF tSSE nβσ∴===-2.9 验证(2.63)式:2211σ)L)xx(n()e(Varxxii---=证明:0112222222ˆˆˆvar()var()var()var()2cov(,)ˆˆˆvar()var()2cov(,())()()11[]2[]()1[1]i i i i i i ii i i ii ixx xxixxe y y y y y yy x y y x xx x x xn L n Lx xn Lβββσσσσ=-=+-=++-+---=++-+-=--其中:222221111))(1()(1))(,()()1,())(ˆ,(),())(ˆ,(σσσββxxixxiniixxiiiniiiiiiiiLxxnLxxnyLxxyCovxxynyCovxxyCovyyCovxxyyCov-+=-+=--+=-+=-+∑∑==2.10 用第9题证明是σ2的无偏估计量证明:2221122112211ˆˆ()()()22()111var()[1]221(2)2n ni ii in niii i xxE E y y E en nx xen n n Lnnσσσσ=====-=---==----=-=-∑∑∑∑第三章2ˆ22-=∑neiσ1.一个回归方程的复相关系数R=0.99,样本决定系数R 2=0.9801,我们能判断这个回归方程就很理想吗? 答:不能断定这个回归方程理想。
第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑ 2n 01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=≈ (5)由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353 即为:(2.49,11.5)2201()(,())xxx Nn L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()nii nii y y r y y ∧-=-=-==≈-∑∑(7)由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
(8)t σ∧==其中2221111()22n ni i i i i e y y n n σ∧∧====---∑∑ 7 3.661==≈ /2 2.353t α= /23.66t t α=>∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。
实用回归分析第四版第一章回归分析概述1.3回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.第二章一元线性回归分析思考与练习参考答案2.1一元线性回归有哪些基本假定?答:假设1、解释变量X是确定性变量,Y是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(εi)=0 i=1,2, …,nVar (εi)=σ2i=1,2, …,nCov(εi,εj)=0 i≠j i,j= 1,2, …,n假设3、随机误差项ε与解释变量X之间不相关:Cov(X i, εi)=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布εi~N(0, σ2) i=1,2, …,n2.3 证明(2.27式),∑e i =0 ,∑e i X i=0 。
证明:∑∑+-=-=niiiniXYYYQ12121))ˆˆ(()ˆ(ββ其中:即: ∑e i =0 ,∑e i X i =02.5 证明0ˆβ是β0的无偏估计。
证明:)1[)ˆ()ˆ(1110∑∑==--=-=ni i xxi n i i Y L X X X Y n E X Y E E ββ )] )(1([])1([1011i i xx i n i i xx i ni X L X X X n E Y L X X X n E εββ++--=--=∑∑==1010)()1(])1([βεβεβ=--+=--+=∑∑==i xx i ni i xx i ni E L X X X nL X X X n E 2.6 证明 证明:)] ()1([])1([)ˆ(102110i i xxi ni ixx i ni X Var L X X X n Y L X X X n Var Var εβββ++--=--=∑∑== 222212]1[])(2)1[(σσxx xx i xx i ni L X n L X X X nL X X X n +=-+--=∑=2.7 证明平方和分解公式:SST=SSE+SSR证明:2.8 验证三种检验的关系,即验证: (1)21)2(r r n t --=;(2)2221ˆˆ)2/(1/t L n SSE SSR F xx ==-=σβ 01ˆˆˆˆi i i i iY X e Y Y ββ=+=-())1()1()ˆ(222122xx ni iL X n X XX nVar +=-+=∑=σσβ()()∑∑==-+-=-=n i ii i n i i Y Y Y Y Y Y SST 1212]ˆ()ˆ[()()()∑∑∑===-+--+-=ni ii ni i i i ni iY Y Y Y Y Y Y Y 12112)ˆˆ)(ˆ2ˆ()()SSESSR )Y ˆY Y Y ˆn1i 2ii n1i 2i +=-+-=∑∑==0100ˆˆQQββ∂∂==∂∂证明:(1)ˆt======(2)2222201111 1111ˆˆˆˆˆˆ()()(())(()) n n n ni i i i xxi i i iSSR y y x y y x x y x x Lβββββ=====-=+-=+--=-=∑∑∑∑2212ˆ/1ˆ/(2)xxLSSRF tSSE nβσ∴===-2.9 验证(2.63)式:2211σ)L)xx(n()e(Varxxii---=证明:0112222222ˆˆˆvar()var()var()var()2cov(,)ˆˆˆvar()var()2cov(,())()()11[]2[]()1[1]i i i i i i ii i i ii ixx xxixxe y y y y y yy x y y x xx x x xn L n Lx xn Lβββσσσσ=-=+-=++-+---=++-+-=--其中:222221111))(1()(1))(,()()1,())(ˆ,(),())(ˆ,(σσσββxxixxiniixxiiiniiiiiiiiLxxnLxxnyLxxyCovxxynyCovxxyCovyyCovxxyyCov-+=-+=--+=-+=-+∑∑==2.10 用第9题证明是σ2的无偏估计量证明:2221122112211ˆˆ()()()22()111var()[1]221(2)2n ni ii in niii i xxE E y y E en nx xen n n Lnnσσσσ=====-=---==----=-=-∑∑∑∑第三章2ˆ22-=∑neiσ1.一个回归方程的复相关系数R=0.99,样本决定系数R 2=0.9801,我们能判断这个回归方程就很理想吗? 答:不能断定这个回归方程理想。
2.1 一元线性回归模型有哪些基本假定?答:1. 解释变量 1x , ,2x ,p x 是非随机变量,观测值,1i x ,,2 i x ip x 是常数。
2. 等方差及不相关的假定条件为⎪⎪⎩⎪⎪⎨⎧⎪⎩⎪⎨⎧≠=====j i n j i j i n i E j i i ,0),,2,1,(,),cov(,,2,1,0)(2 σεεε 这个条件称为高斯-马尔柯夫(Ga uss-Mark ov)条件,简称G-M条件。
在此条件下,便可以得到关于回归系数的最小二乘估计及误差项方差2σ估计的一些重要性质,如回归系数的最小二乘估计是回归系数的最小方差线性无偏估计等。
3. 正态分布的假定条件为⎩⎨⎧=相互独立n i n i N εεεσε,,,,,2,1),,0(~212 在此条件下便可得到关于回归系数的最小二乘估计及2σ估计的进一步结果,如它们分别是回归系数的最及2σ的最小方差无偏估计等,并且可以作回归的显著性检验及区间估计。
4. 通常为了便于数学上的处理,还要求,p n >及样本容量的个数要多于解释变量的个数。
在整个回归分析中,线性回归的统计模型最为重要。
一方面是因为线性回归的应用最广泛;另一方面是只有在回归模型为线性的假设下,才能的到比较深入和一般的结果;再就是有许多非线性的回归模型可以通过适当的转化变为线性回归问题进行处理。
因此,线性回归模型的理论和应用是本书研究的重点。
1. 如何根据样本),,2,1)(;,,,(21n i y x x x i ip i i =求出p ββββ,,,,210 及方差2σ的估计;2. 对回归方程及回归系数的种种假设进行检验;3. 如何根据回归方程进行预测和控制,以及如何进行实际问题的结构分析。
2.2 考虑过原点的线性回归模型 n i x y i i i ,,2,1,1 =+=εβ误差n εεε,,,21 仍满足基本假定。
求1β的最小二乘估计。
答:∑∑==-=-=ni ni i i i x y y E y Q 1121121)())(()(ββ∑∑∑===+-=--=∂∂n i n i ni i i i i i i x y x x x y Q111211122)(2βββ 令,01=∂∂βQ即∑∑===-n i ni i i i x y x 11210β 解得,ˆ1211∑∑===ni ini i i xyx β即1ˆβ的最小二乘估计为.ˆ1211∑∑===ni ini ii xyx β2.3 证明:ﻩQ(β0,β1)= ∑(y i-β0-β1x i)2因为Q (∧β0,∧β1)=min Q (β0,β1 )而Q (β0,β1) 非负且在R2上可导,当Q取得最小值时,有 即-2∑(y i-∧β0-∧β1x i)=0-2∑(y i-∧β0-∧β1x i ) x i=0又∵e i =yi -( ∧β0+∧β1x i )= yi -∧β0-∧β1x i ∴∑e i =0,∑e i x i =0(即残差的期望为0,残差以变量x 的加权平均值为零)2.4 解:参数β0,β1的最小二乘估计与最大似然估计在εi~N(0, ﻠ2 ) i=1,2,……n的条件下等价。
证明:因为ni N i ,.....2,1),,0(~2=σε所以),(~2110110σββεββX X Y N i i +++=其最大似然函数为已知使得Ln(L )最大的0ˆβ,1ˆβ就是β0,β1的最大似然估计值。
即使得下式最小 :∑∑+-=-=nii i n i X Y Y Y Q 121021))ˆˆ(()ˆ(ββ ①因为①恰好就是最小二乘估计的目标函数相同。
所以,在ni N i ,.....2,1),,0(~2=σε 的条件下, 参数β0,β1的最小100ˆˆQQββ∂∂==∂∂二乘估计与最大似然估计等价。
2.5.证明0β是0β的无偏估计。
证明:若要证明0β 是0β的无偏估计,则只需证明E(0β)=0β。
因为0β ,1β的最小二乘估计为⎪⎩⎪⎨⎧-==x y L L xxxy 101/βββ 其中∑∑∑∑∑∑∑∑∑-=-=-=-=-=--=22222)(1)(1))((i i i i xx i i i i i i i i xy x nx x n x x x L y x ny x y x n y x y y x x LE(0ˆβ)=E(x y 1ˆβ-)=E(∑∑==--n i i xx i n i i y L x x x y n 111)=E [∑=--ni i xx i y L x x x n 1)1(]=E[∑=++--ni i i xxi x L x x x n 110))(1(εββ]=E (∑=--ni xx i L x x x n 10)1(β)+E(∑=--ni i xx i x L x x x n 11)1(β)+E(∑=--ni i xxi L x x x n 1)1(ε)其中∑=--ni xx i L x x x n 10)1(β=∑=--ni xx i L x x x n 10)1(β=))(1(10∑=--ni ixx x xL x n n β由于∑=-ni i x x 1)(=0,所以∑=--ni xxi L x x x n 10)1(β=0β∑=--ni i xx i x L x x x n 11)1(β=∑=--ni ixx i i x L x x x n x 11)(β=))((11∑=--ni i ixx x x xL x x β=)-)(((11∑=--ni i ixxx x x xL xx β)=)(1x x -β=0又因为一元线性回归模型为⎩⎨⎧++=),0(210σεεββN x y i i i i 独立同分布,其分布为各所以E (iε)=0所以E(∑=--ni xx i L x x x n 10)1(β)+E(∑=--n i i xx i x L x x x n 11)1(β)+E(∑=--ni i xx i L x x x n 1)1(ε=++)0()(0E E β ∑=--ni i xx i E L x x x n 1)()1(ε=0β所以0β是0β的无偏估计。
2.6 解:因为∑==ni i yn y 11 ①,xy ∧∧-=ββ1②,yLx in i xxix∑=∧-=11β③联立 ①②③式,得到y L x ini xx ix x n ∑=∧--=10)1(β。
])1([)(10y Lx ini xxi x xnVar Var ∑=∧--=β)(1])1[(2y L x x x n i Var ni xx i ∑--==σ2122]2(1[)∑-=--+=ni xxinL x L x x x n x x xx i因为∑-==ni xxx x Li 12)(,)(1=-∑=ni ix x ,所以σβ21212212])(21[)()()(nLx L x x x nxxni ini ni x x xxi Var ∑∑-∑===∧-++=σ22)(1⎪⎪⎪⎭⎫ ⎝⎛+=L x xx n σ2122)()(1⎪⎪⎪⎪⎭⎫ ⎝⎛+=∑-=ni x x x i n2.7 证明平方和分解公式:SS T=SSE +SSR证明:()()∑∑==-+-=-=ni i i n i i y i y yy y y SST 1212]ˆ()ˆ[()()()∑∑∑===-+--+-=ni i i n i i i i n i i y y y y y y y y12112)ˆˆ)(ˆ2ˆ()()SSE SSR y y y yni ii n i i+=-+-=∑∑==1212)ˆˆ2.8 验证三种检验的关系,即验证:(1)21)2(r r n t --=;(2)2221ˆˆ)2/(1/tL n SSE SSR F xx ==-=σβ证明:(1)因为2-n 22SSESSR L xx =∧∧=σβ和,所以SSTSSE SST SSRn SSESSR n n SSE t LLxxxx)()(22222-=-=-∧=∧=∧βσβ又因为SST SSR r=2,所以SST SSE SST SSR SST r =-=-21故21)2(r r n t --=得证。
(2)22222011111111ˆˆˆˆˆˆ()()(())(())nnnni i ii xx i i i i SSR y y x y y x x y x x L βββββ=====-=+-=+--=-=∑∑∑∑2212ˆ/1ˆ/(2)xx L SSR F t SSE n βσ∴===-2.9 验证(2.63)式:()σ2xx2i Lx -x e i-n 1-1var ⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=)( 证明:),()()()()(∧∧∧+==y y y y y y eiiiiiii cov 2-var var -var var))x -y cov 2var var x y x y i1ii1i(,()()(∧∧∧+-++=βββ ⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡+-⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡++=--L x x L xx i n )()(22xx 22212in 1x x σσσ()σ2xx2x -x in 11⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡--=L其中: ()⎪⎪⎭⎫ ⎝⎛-∧+x y cov x y i 1i β,()()⎪⎪⎭⎫ ⎝⎛∧+=x -cov y cov x y y i1i i β,,()()⎪⎪⎭⎫⎝⎛+⎪⎭⎫⎝⎛=∑∑==n 1i i xxii i n 1i i i y x y x y y x -cov x -n 1cov L,, ()σσ222n 1Lx x xxi-+=()σ22n 1⎪⎪⎪⎭⎫ ⎝⎛+=-Lx x xxi注:各个因变量yy y n (2)1,是独立的随机变量),cov()var()var()var(Y X Y X Y X 2++=+2.10 用第9题证明2-n ie 22∑=∧σ是σ2的无偏估计量证明:()∑-=∧∧=⎪⎪⎭⎫ ⎝⎛n 1i 22y y ii2-n 1E E σ∑=⎪⎭⎫⎝⎛=n 1i 2e i 2-n 1E ()∑==ni i e 12-n 1var()σ2n1i xx2Lx -x i-n1-12-n 1∑=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡= ()σ222-n 1-=n σ2= 注:[])()()var(X E X E X 22+=2.11验证22-+=n F Fr证明:)2(*)2(-⎪⎭⎫ ⎝⎛=-=n SSE SSR n SSESSR F 所以有F n SSRSSE )2(-=()2)2(11112-+=⎪⎭⎫ ⎝⎛-+=+=+==n F FF n SSR SSESSE SSR SSR SST SSR r以上表达式说明r ²与F 等价,但我们要分别引入这两个统计量,而不是只引入其中一个。