《应用回归分析》课后题答案解析
- 格式:doc
- 大小:1.67 MB
- 文档页数:41

第4章违背根本假设的情况思考及练习参考答案4.1 试举例说明产生异方差的原因。
答:例:截面资料下研究居民家庭的储蓄行为Y i=β0+β1X i+εi其中:Y i表示第i个家庭的储蓄额,X i表示第i个家庭的可支配收入。
由于高收入家庭储蓄额的差异较大,低收入家庭的储蓄额那么更有规律性,差异较小,所以εi的方差呈现单调递增型变化。
例4.2:以某一行业的企业为样本建立企业生产函数模型Y i=A iβ1K iβ2L iβ3eεi被解释变量:产出量Y,解释变量:资本K、劳动L、技术A,那么每个企业所处的外部环境对产出量的影响被包含在随机误差项中。
由于每个企业所处的外部环境对产出量的影响程度不同,造成了随机误差项的异方差性。
这时,随机误差项ε的方差并不随某一个解释变量观测值的变化而呈规律性变化,呈现复杂型。
4.2 异方差带来的后果有哪些?答:回归模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生以下不良后果:1、参数估计量非有效2、变量的显著性检验失去意义3、回归方程的应用效果极不理想总的来说,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。
4.3 简述用加权最小二乘法消除一元线性回归中异方差性的思想及方法。
答:普通最小二乘估计就是寻找参数的估计值使离差平方和达极小。
其中每个平方项的权数一样,是普通最小二乘回归参数估计方法。
在误差项等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。
然而在异方差的条件下,平方和中的每一项的地位是不一样的,误差项的方差大的项,在残差平方和中的取值就偏大,作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。
由OLS 求出的仍然是的无偏估计,但不再是最小方差线性无偏估计。
所以就是:对较大的残差平方赋予较小的权数,对较小的残差平方赋予较大的权数。

《应用回归分析》部分课后习题答案第一章回归分析概述1.1 变量间统计关系和函数关系的区别是什么?答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。
1.2 回归分析与相关分析的联系与区别是什么?答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有 a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。
在相关分析中,变量x和变量y处于平等的地位,即研究变量y与变量x的密切程度与研究变量x与变量y的密切程度是一回事。
b.相关分析中所涉及的变量y与变量x全是随机变量。
而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
1.3 回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.1.5 回归变量的设置理论根据是什么?在回归变量设置时应注意哪些问题?答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。
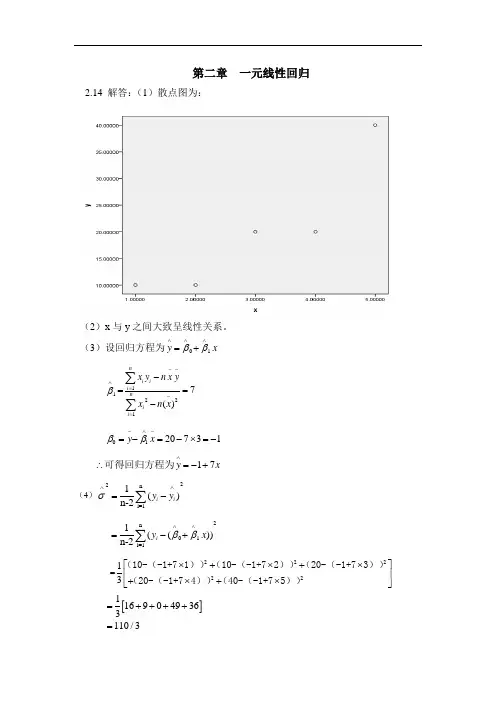
第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑ 2n 01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=(5)由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2||(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353 即为:(2.49,11.5)2201()(,())xxx Nn L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()ni i nii y y r y y ∧-=-=-==≈-∑∑(7)由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
(8)t σ∧==其中2221111()22n ni i i i i e y y n n σ∧∧====---∑∑ 7 3.661==≈/2 2.353t α= /23.66t t α=>∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。



《应用回归分析》部分课后习题答案第一章回归分析概述1.1 变量间统计关系和函数关系的区别是什么?答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。
1.2 回归分析与相关分析的联系与区别是什么?答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有 a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。
在相关分析中,变量x和变量y处于平等的地位,即研究变量y与变量x的密切程度与研究变量x与变量y的密切程度是一回事。
b.相关分析中所涉及的变量y与变量x全是随机变量。
而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
1.3 回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.1.5 回归变量的设置理论根据是什么?在回归变量设置时应注意哪些问题?答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。

《使用回归分析》部分课后习题答案第一章回归分析概述变量间统计关系和函数关系的区别是什么答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。
回归分析和相关分析的联系和区别是什么答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有 a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。
在相关分析中,变量x和变量y处于平等的地位,即研究变量y和变量x的密切程度和研究变量x和变量y的密切程度是一回事。
b.相关分析中所涉及的变量y和变量x全是随机变量。
而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
回归模型中随机误差项ε的意义是什么答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y和x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
—线性回归模型的基本假设是什么答:线性回归模型的基本假设有:1.解释变量….xp是非随机的,观测值…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.回归变量的设置理论根据是什么在回归变量设置时应注意哪些问题答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。

回归分析作业设计班级:统计0802学号: 1303080513姓名:刘贯春指导老师:胡朝明日期:2011年1月2日实验目的:结合SPSS 软件使用回归分析中的各种方法,比较各种方法的使用条件,并正确解释分析结果。
实验内容:世纪统计学教材应用回归分析(第二版)课后有数据的习题。
详细设计:第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑2n01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=≈ (5)由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353 即为:(2.49,11.5)22001()(,())xxx N n L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()nii nii y y r y y ∧-=-=-==≈-∑∑(7)由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
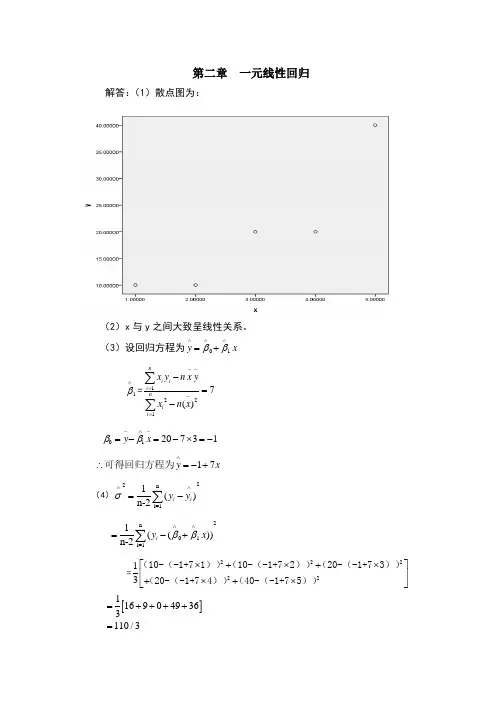
第二章 一元线性回归解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑ 2n 01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=≈(5)由于2 11(,)xxNLσββ∧tσ∧==服从自由度为n-2的t分布。
因而/2|(2)1P t nαασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t tααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353即为:(,)22001()(,())xxxNn Lββσ-∧+t∧∧==服从自由度为n-2的t分布。
因而/2(2)1P t nαα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1pβσββσα∧∧∧∧-<<+=-可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x与y的决定系数22121()490/6000.817()niiniiy yry y∧-=-=-==≈-∑∑(7)ANOVAx平方和df 均方F显著性组间(组合) 2 .100线性项加权的1.056偏差.8331 .833 .326组内2 .500总数4由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
(8)t σ∧==其中2221111()22n ni i i i i e y y n n σ∧∧====---∑∑ 7 3.661==≈/2 2.353t α= /23.66t t α=>∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。
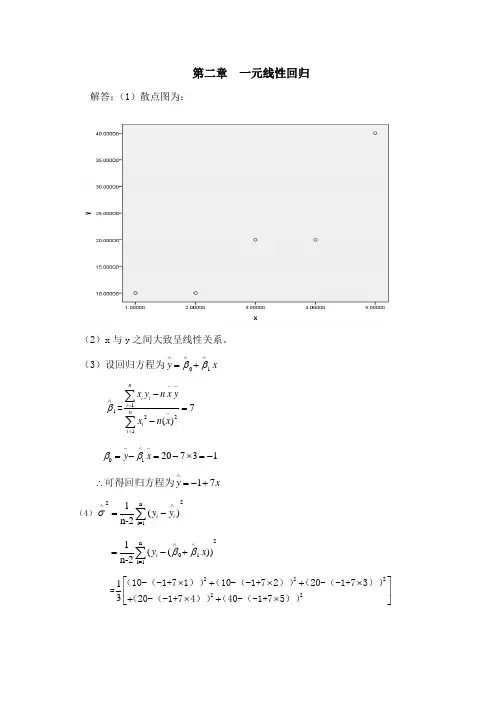
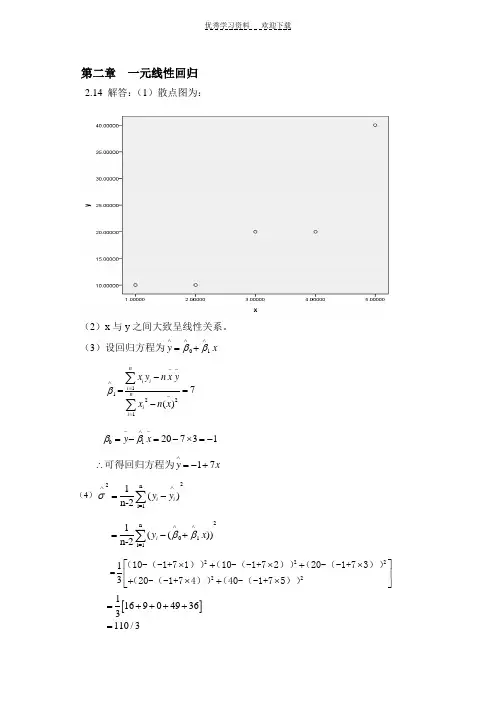
第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑ 2n 01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=≈ (5)由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353 即为:(2.49,11.5)2201()(,())xxx Nn L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()nii nii y y r y y ∧-=-=-==≈-∑∑(7)由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
(8)t σ∧==其中2221111()22n ni i i i i e y y n n σ∧∧====---∑∑ 7 3.661==≈ /2 2.353t α= /23.66t t α=>∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。
第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑ 2n 01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=≈(5)由于2 11(,)xxNLσββ∧:tσ∧==服从自由度为n-2的t分布。
因而/2|(2)1P t nαασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t tααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353即为:(2.49,11.5)22001()(,())xxxNn Lββσ-∧+:t∧∧==服从自由度为n-2的t分布。
因而/2(2)1P t nαα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1pβσββσα∧∧∧∧-<<+=-可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x与y的决定系数22121()490/6000.817()niiniiy yry y∧-=-=-==≈-∑∑(7)ANOVAx平方和df均方 F显着性组间(组合) 9.000 2 4.500 9.000 .100线性项加权的 8.167 1 8.167 16.333 .056偏差.833 1 .833 1.667.326组内 1.000 2 .500总数10.0004由于(1,3)F F α>,拒绝0H ,说明回归方程显着,x 与y 有显着的线性关系。
第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑2n01i=11(())n-2i y x ββ∧∧=-+∑ =2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=≈(5)由于2 11(,)xxNLσββ∧tσ∧==服从自由度为n-2的t分布。
因而/2||(2)1P t nαασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t tααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353即为:(2.49,11.5)22001()(,())xxxNn Lββσ-∧+t∧∧==服从自由度为n-2的t分布。
因而/2||(2)1P t nαα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1pβσββσα∧∧∧∧-<<+=-可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x与y的决定系数22121()490/6000.817()niiniiy yry y∧-=-=-==≈-∑∑(7)ANOVAx平方和 df均方 F显著性组间(组合) 9.000 2 4.500 9.000 .100线性项加权的 8.167 1 8.167 16.333 .056偏差.833 1 .833 1.667.326组内 1.0002 .500总数10.0004由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑ 2n 01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=1330 6.13σ∧=≈ (5)由于211(,)xxN L σββ∧1112()/xxxxL t L ββσσ∧∧-==服从自由度为n-2的t 分布。
因而1/2()|(2)1xx L P t n αββασ∧⎡⎤-⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(xxxxp t t L L ααβββ∧∧∧∧-<<+=1α-可得11195%333333β∧的置信度为的置信区间为(7-2.353,7+2.353)即为:(2.49,11.5)2201()(,())xxx N n L ββσ-∧+00002221()1()()xxxxt x x n L n L σσ∧∧--∧∧==++服从自由度为n-2的t 分布。
因而00/22(2)11()xx P t n x n L αασ∧-∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥+⎢⎥⎣⎦即220/200/21()1()()1xxxxx x p t t n L n L βσββσα--∧∧∧∧-+<<++=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()nii nii y y r y y ∧-=-=-==≈-∑∑(7)ANOV Ax平方和df均方 F 显著性组间(组合) 9.000 2 4.500 9.000 .100 线性项加权的 8.167 1 8.167 16.333 .056 偏差.833 1 .833 1.667.326组内 1.000 2 .500总数10.0004由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。