一元线性回归,方差分析,显著性分析
- 格式:doc
- 大小:145.00 KB
- 文档页数:5


方差分析与回归分析的原理方差分析和回归分析是统计学中常用的两种数据分析方法,它们都用于研究变量之间的相互关系,但是基于不同的背景和目的,其原理和应用也有所不同。
首先,我们来了解一下方差分析。
方差分析是一种用于比较两个或多个群体均值差异的统计方法。
它基于对总体方差的分解来分析不同因素对群体之间差异的贡献程度。
具体来说,方差分析将总体方差分解为组内变异和组间变异两部分,然后通过计算F统计量来判断组间变异是否显著大于组内变异。
方差分析可以用于很多场景,比如医疗研究中分析不同药物对疾病治疗效果的差异、教育研究中比较不同教学方法对学生成绩的影响等。
在进行方差分析时,需要明确一个自变量(也称为因素或处理)和一个因变量(也称为响应变量)。
自变量是被研究者主动操作或选择的变量,而因变量是根据自变量的不同取值而发生变化的变量。
方差分析的基本原理是通过对不同组之间的变异进行比较,来判断组间是否存在统计显著差异。
方差分析的核心思想是使用F统计量来判断组间变异与组内变异的比例是否显著大于1。
通过计算F值并与临界值进行比较,可以得出结论是否存在显著差异。
如果F值大于临界值,则可以拒绝原假设,表明不同组之间存在显著差异;如果F值小于临界值,则接受原假设,认为组间差异不显著。
接下来,我们来了解一下回归分析。
回归分析是统计学中用于研究变量之间关系的一种方法。
它研究的是一个或多个自变量对因变量的影响程度和方向。
回归分析可以用于预测未来趋势、解释变量之间的关系、探究因果关系以及确定主要影响因素等。
回归分析分为线性回归和非线性回归两种。
线性回归是最常用的一种回归方法,它假设自变量与因变量之间存在线性关系。
以一元线性回归为例,我们假设因变量Y可以用一个自变量X的线性函数来表示,即Y = β0 + β1X + ε,其中β0和β1是回归系数,ε是误差项,代表了未被自变量解释的因素。
通常,回归分析的目标是估计出回归系数的值,并利用这些系数来解释因变量与自变量之间的关系。


方差分析与回归分析在统计学中,方差分析(ANOVA)和回归分析(Regression Analysis)都是常见的统计分析方法。
它们广泛应用于数据分析和实证研究中,有助于揭示变量之间的关系和影响。
本文将对方差分析和回归分析进行介绍和比较,让读者更好地理解它们的应用和区别。
一、方差分析方差分析是一种统计方法,用于比较两个或更多组别的均值是否存在显著差异。
它通过计算组内变异和组间变异的比值来判断不同组别间的差异是否具有统计显著性。
在方差分析中,通常有三种不同的情形:单因素方差分析、双因素方差分析和多因素方差分析。
单因素方差分析适用于只有一个自变量的情况。
例如,我们想要比较不同教育水平对收入的影响,可以将教育水平作为自变量分为高中、本科和研究生三个组别,然后进行方差分析来检验组别之间的收入差异是否显著。
双因素方差分析适用于有两个自变量的情况。
例如,我们想要比较不同教育水平和不同工作经验对收入的影响,可以将教育水平和工作经验作为自变量,进行方差分析来研究其对收入的影响程度和相互作用效应。
多因素方差分析适用于有多个自变量的情况。
例如,我们想要比较不同教育水平、工作经验和职位对收入的影响,可以将教育水平、工作经验和职位作为自变量,进行方差分析来探究它们对收入的联合影响。
方差分析的基本原理是计算组内变异和组间变异之间的比值,即F 值。
通过与临界F值比较,可以确定差异是否显著。
方差分析的结果通常会报告组间平均差异的显著性水平,以及可能存在的交互作用。
二、回归分析回归分析是一种统计方法,用于研究自变量与因变量之间的关系。
它通过建立一个数学模型来描述自变量对因变量的影响程度和方向。
回归分析分为简单线性回归和多元线性回归两种类型。
简单线性回归适用于只有一个自变量和一个因变量的情况。
例如,我们想要研究体重与身高之间的关系,可以将身高作为自变量、体重作为因变量,通过拟合一条直线来描述二者之间的关系。
多元线性回归适用于有多个自变量和一个因变量的情况。



回归方程的显著性检验回归方程的显著性检验的目的是对回归方程拟合优度的检验。
F检验法是英国统计学家Fisher提出的,主要通过比较两组数据的方差S2,以确定他们的精密度是否有显著性差异。
回归方程显著性检验具体方法为:由于y的偏差是由两个因素造成的,一是x变化所引起反应在S回中,二是各种偶然因素干扰所致S残中。
将回归方程离差平方和S回同剩余离差平方和S残加以比较,应用F检验来分析两者之间的差别是否显著。
如果是显著的,两个变量之间存在线性关系;如果不显著,两个变量不存在线性相关关系。
n个观测值之间存在着差异,我们用观测值yi与其平均值的偏差平方和来表示这种差异程度,称其为总离差平方和,记为由于所以式中称为回归平方和,记为S回。
称为残差平方和,记为。
不难证明,最后一项。
因此S总=S回+S残上式表明,y的偏差是由两个因素造成的,一是x变化所引起,二是各种偶然因素干扰所致。
事实上,S回和S残可用下面更简单的关系式来计算。
具体检验可在方差分析表上进行。
这里要注意S回的自由度为1,S残的自由度为n-2,S总的自由度为n-1。
如果x与y有线性关系,则其中,F(1,n-2)表示第一自由度为1,第二自由度为n-2的分布。
在F表中显著性水平用表示,一般取0.10,0.05,0.01,1-表示检验的可靠程度。
在进行检验时,F值应大于F表中的临界值Fα。
若F<0.05(1,n-2),则称x与y 没有明显的线性关系,若F0.05(1,n-2)<F<F0.01(1,n-2),则称x与y有显著的线性关系;若F>F0.01(1,n-2),则称x与y有十分显著的线性关系。
当x与y有显著的线性关系时,在表2-1-2的显著性栏中标以〝*〞;当x与y有十分显著的线性关系时,标以〝**〞。


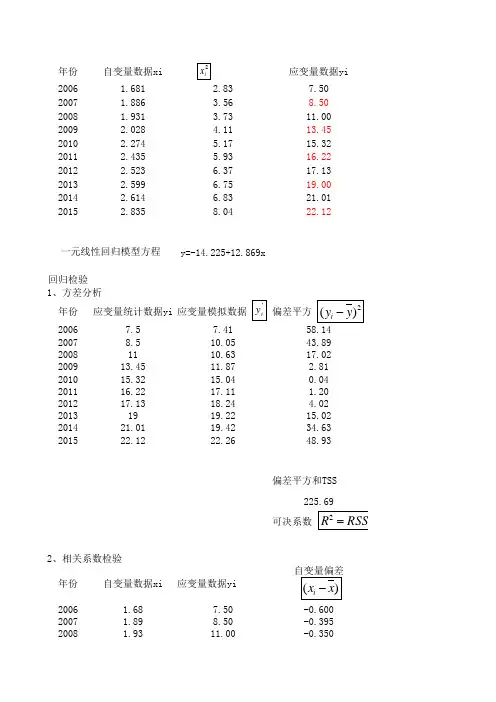
年份自变量数据xi应变量数据yi2006 1.681 2.837.502007 1.886 3.568.502008 1.931 3.7311.002009 2.028 4.1113.452010 2.274 5.1715.322011 2.435 5.9316.222012 2.523 6.3717.132013 2.599 6.7519.002014 2.614 6.8321.0120152.8358.0422.12y=-14.225+12.869x回归检验年份应变量统计数据yi 应变量模拟数据偏差平方20067.57.4158.1420078.510.0543.8920081110.6317.02200913.4511.87 2.81201015.3215.040.04201116.2217.11 1.20201217.1318.24 4.022*******.2215.02201421.0119.4234.63201522.1222.2648.93偏差平方和TSS225.69可决系数年份自变量数据xi应变量数据yi2006 1.687.50-0.6002007 1.898.50-0.39520081.9311.00-0.350一元线性回归模型方程1、方差分析2、相关系数检验2009 2.0313.45-0.2532010 2.2715.32-0.0072011 2.4416.220.1542012 2.5217.130.2422013 2.6019.000.3182014 2.6121.010.3332015 2.8422.120.554相关系数临界值年份自变量数据xi应变量数据yi应变量模拟数据2006 1.687.507.412007 1.898.5010.052008 1.9311.0010.632009 2.0313.4511.872010 2.2715.3215.042011 2.4416.2217.112012 2.5217.1318.242013 2.6019.0019.222014 2.6121.0119.4220152.8422.1222.26显著性检验参数回归标准差Sy3、t检验参数b的标准差Sb判断参数年份自变量数据xi 应变量数据yi2006 1.687.502007 1.898.502008 1.9311.002009 2.0313.452010 2.2715.322011 2.4416.222012 2.5217.132013 2.6019.002014 2.6121.012015 2.8422.12自变量变化条件2016 3.032017 3.252018 3.472019 3.7220203.9836.945y=-14.225+12.869x区间预测32.317查t分布表的显著性水平的数值t(a/2,n-2)4、点预测与区间预测12.6122.806151.25053.31516.0321.2427.2834.8439.50 2.28143.2249.3854.9262.7159.540.00825.79 2.39220.240.14010.57 2.4830.010.0783.950.7969.73 1.24216.790.05018.412.54250.910.020回归平方和RSS残差平方和ESS215.949.750.0095.68%应变量偏差自变量与应变量偏差应变量偏差平方4.5720.36058.141-6.625 2.6140.15643.891-4.1251.4420.12217.016应变量y可以用自变量x来解释的百分-1.6750.4230.064 2.8060.195-0.0010.0000.0381.0950.1690.024 1.1992.0050.4860.059 4.0203.875 1.2340.10115.0165.885 1.9620.11134.6336.995 3.8780.30748.93016.779 1.304225.6880.978判断结果0.6320.010.3602.390.1560.140.1222.480.0640.080.0000.800.0241.240.0590.050.1012.540.1110.020.307n a 9.75 1.30100.0513.310判断结果1.219表明回归系数显著性不条件:自由度(n-2)和显著性水平a(一般取a-0.05)下的查表值变量x与y之间的0.96702.306年增长速度为7%2.87541.574结论有95%的可能性在(32.32,41.57)的区间内2.0072.306性水平为a,自由度为n-2的数值t(a/2,n-2)361.72012.869-14.225的百分比为95.68%变量x和y正相关之间的线性关系成立著性不为0,参数t通过检验。

从统计学看线性回归(2)——⼀元线性回归⽅程的显著性检验⽬录1. σ2 的估计2. 回归⽅程的显著性检验 t 检验(回归系数的检验) F 检验(回归⽅程的检验) 相关系数的显著性检验 样本决定系数 三种检验的关系⼀、σ2 的估计 因为假设检验以及构造与回归模型有关的区间估计都需要σ2的估计量,所以先对σ2作估计。
通过残差平⽅和(误差平⽅和)(1)(⽤到和,其中)⼜∵(2)∴(3)其中为响应变量观测值的校正平⽅和。
残差平⽅和有n-2 个⾃由度,因为两个⾃由度与得到的估计值与相关。
(4)(公式(4)在《线性回归分析导论》附录C.3有证明)∴σ2的⽆偏估计量:(5)为残差均⽅,的平⽅根称为回归标准误差,与响应变量y 具有相同的单位。
因为σ2取决于残差平⽅和,所以任何对模型误差假设的违背或对模型形式的误设都可能严重破坏σ2的估计值的实⽤性。
因为由回归模型残差算得,称σ2的估计值是模型依赖的。
⼆、回归⽅程的显著性检验 ⽬的:检验是否真正描述了变量 y 与 x 之间的统计规律性。
假设:正态性假设(⽅便检验计算)1. t 检验 ⽤t 检验来检验回归系数的显著性。
采⽤的假设如下:原假设 H0:β1 = 0 (x 与 y 不存在线性关系)对⽴假设 H1:β1 ≠ 0 回归系数的显著性检验就是要检验⾃变量 x 对因变量 y 的影响程度是否显著。
下⾯我们分析接受和拒绝原假设的意义。
(1)接受 H0:β1 = 0 (x 与 y 不存在线性关系) 此时有两种情况,⼀种是⽆论 x 取值如何, y 都在⼀条⽔平线上下波动,即,如下图1,另⼀种情况为, x 与 y 之间存在关系,但不是线性关系,如图2。
图 1图 2 (2)拒绝 H0:β1 = 0 (x 对解释 y 的⽅差是有⽤的) 拒绝原假设也有两种情况,⼀种是直线模型就是合适的,如图 3,另⼀种情况为存在 x 对 y 的线性影响,也可通过 x 的⾼阶多项式得到更好的结果,如图 4。
线性回归与方差分析线性回归和方差分析是统计学中常用的两种数据分析方法。
虽然它们在数据处理和分析的角度有所不同,但都有助于我们理解变量之间的关系,从而做出科学的推断和预测。
本文将就线性回归和方差分析进行深入探讨。
一、线性回归线性回归是一种用于建立两个或多个变量之间关系的统计模型的方法。
它通过拟合最佳拟合直线,以便预测一个变量(因变量)与一个或多个其他变量(自变量)之间的关系。
对于简单线性回归,我们考虑一个自变量和一个因变量的情况。
我们使用最小二乘法来找到最佳拟合直线,以使预测值与实际观测值的误差平方和最小化。
最佳拟合直线可以通过回归方程来表示,其中自变量和系数之间存在线性关系。
例如,假设我们想研究身高与体重之间的关系。
我们可以收集一组数据,其中身高是自变量,体重是因变量。
通过拟合最佳拟合直线,我们可以预测给定身高的人的体重。
二、方差分析方差分析是一种用于比较三个或更多组之间差异的统计方法。
它将观测值的总变异分解为组内变异和组间变异,以确定组间的差异是否显著。
在方差分析中,我们将一组观测值分成几个组,并计算每个组的观测值的平均值。
然后,我们计算总平均值,以检查组间和组内的差异。
如果组间差异显著大于组内差异,我们可以得出结论认为不同组之间存在显著差异。
例如,假设我们想研究不同施肥处理对植物生长的影响。
我们将植物分成几个组,分别施用不同类型的肥料。
通过测量植物生长的指标(如高度或质量),我们可以使用方差分析来比较各组之间的差异。
三、线性回归与方差分析的联系尽管线性回归和方差分析是两种不同的统计方法,但它们在某些方面也存在联系。
首先,线性回归可以被视为方差分析的特例。
当我们只有一个自变量时,线性回归与方差分析的目标是相同的,即确定因变量与自变量之间的关系。
因此,我们可以将简单线性回归模型看作是方差分析的一种形式。
其次,线性回归和方差分析都涉及到模型建立和参数估计。
线性回归通过拟合回归方程来建立模型,并估计回归系数。
第二节 一元线性回归分析回归是分析变量之间关系类型的方法,按照变量之间的关系,回归分析分为:线性回归分析和非线性回归分析。
本节研究的是线性回归,即如何通过统计模型反映两个变量之间的线性依存关系。
回归分析的主要内容:1. 从样本数据出发,确定变量之间的数学关系式;2. 估计回归模型参数;3. 对确定的关系式进行各种统计检验,并从影响某一特定变量的诸多变量中找出影响显著的变量。
一、一元线性回归模型:一元线性模型是指两个变量x 、y 之间的直线因果关系。
(一)理论回归模型:εββ++=x y 10理论回归模型中的参数是未知的,但是在观察中我们通常用样本观察值),(i i y x 估计参数值10,ββ,通常用10,b b 分别表示10,ββ的估计值,即称回归估计模型:x b b y10ˆ+= 二、模型参数估计:用最小二乘法估计10,b b :⎪⎩⎪⎨⎧-=--=∑∑∑∑∑xb y b x x n y x xy n b 10221)( 三.回归系数的含义(2)回归方程中的两个回归系数,其中b0为回归直线的启动值,在相关图上变现为x=0时,纵轴上的一个点,称为y 截距;b1是回归直线的斜率,它是自变量(x )每变动一个单位量时,因变量(y )的平均变化量。
(3)回归系数b1的取值有正负号。
如果b1为正值,则表示两个变量为正相关关系,如果b1为负值,则表示两个变量为负相关关系。
四.回归方程的评价与检验:当我们得到一个实际问题的经验回归方程后,还不能马上就进行分析与预测等应用,在应用之前还需要运用统计方法对回归方程进行评价与检验。
进行评价与检验主要是基于以下理由:第一,在利用样本数据估计回归模型时,首先是假设变量y 与x 之间存在着线性关系,但这种假设是否存在需要进行检验;第二,估计的回归方程是否真正描述了变量y 与x 之间的统计规律性,y 的变化是否通过模型中的解释变量去解释需要进行检验等。
一般进行检验的内容有:1.经济意义的检验:利用相关的经济学原理及我们所积累的丰富的经验,对所估计的回归方程的回归系数进行分析与判断,看其能否得到合理的解释。
一元线性回归分析的结果解释1.基本描述性统计量分析:上表是描述性统计量的结果,显示了变量y和x的均数(Mean)、标准差(Std. Deviation)和例数(N)。
2.相关系数分析:上表是相关系数的结果。
从表中可以看出,Pearson相关系数为0.749,单尾显著性检验的概率p值为0.003,小于0.05,所以体重和肺活量之间具有较强的相关性。
3.引入或剔除变量表分析:上表显示回归分析的方法以及变量被剔除或引入的信息。
表中显示回归方法是用强迫引入法引入变量x的。
对于一元线性回归问题,由于只有一个自变量,所以此表意义不大。
4.模型摘要分析:上表是模型摘要。
表中显示两变量的相关系数(R)为0.749,判定系数(R Square)为0.562,调整判定系数(Adjusted R Square)为0.518,估计值的标准误差(Std. Error of the Estimate)为0.28775。
5.方差分析表分析:上表是回归分析的方差分析表(ANOVA)。
从表中可以看出,回归的均方(Regression Mean Square)为1.061,剩余的均方(Residual Mean Square)为0.083,F检验统计量的观察值为12.817,相应的概率p 值为0.005,小于0.05,可以认为变量x和y之间存在线性关系。
6.回归系数分析:上表给出线性回归方程中的参数(Coefficients)和常数项(Constant)的估计值,其中常数项系数为0(注:若精确到小数点后6位,那么应该是0.000413),回归系数为0.059,线性回归参数的标准误差(Std. Error)为0.016,标准化回归系数(Beta)为0.749,回归系数T检验的t统计量观察值为3.580,T检验的概率p值为0.005,小于0.05,所以可以认为回归系数有显著意义。
由此可得线性回归方程为:y=0.000413+0.059x7.回归诊断分析:上表是对全部观察单位进行回归诊断(CasewiseDiagnostics-all cases)的结果显示。