第6章 分布式路由算法
- 格式:ppt
- 大小:422.50 KB
- 文档页数:52

计算机网络中的路由算法路由算法在计算机网络中起着关键的作用,它用于确定数据包在网络中的传输路径。
根据不同的网络拓扑和需求,有多种不同的路由算法被应用。
本文将介绍几种常见的路由算法。
1. 距离矢量算法(Distance Vector Algorithm)距离矢量算法是一种分布式的路由算法,每个节点在路由表中记录到达目的节点的距离向量。
节点之间通过交换距离向量信息来更新路由表,并且通过Bellman-Ford算法来计算最短路径。
该算法简单易实现,但是在大型网络中容易产生计数到无穷大的问题,即由于链路故障等原因产生的无限循环。
2. 链路状态算法(Link State Algorithm)链路状态算法是一种集中式的路由算法,每个节点都会收集与自身相连的链路状态信息,并通过最短路径算法(如Dijkstra算法)计算出到达其他节点的最短路径。
然后,每个节点都将自己的链路状态信息广播给所有其他节点,使得每个节点都有完整的网络拓扑和链路状态信息。
该算法需要节点之间频繁的广播和计算,但是能够保证收敛,即要么找到最短路径,要么不进行路由。
3. 路径向量算法(Path Vector Algorithm)路径向量算法可以看作是距离矢量算法和链路状态算法的结合,它通过回退进行路径检测和避免计数到无穷大的问题。
每个节点在路由表中记录到达目的节点的路径和向量信息,通过交换路径向量信息来更新路由表。
在计算最短路径时,路径向量算法使用类似链路状态算法的Dijkstra算法,但是在寻找路径时,会检查前面的节点是否已经在路径中出现,以避免产生环路。
4. 队列距离矢量算法(Queue Distance Vector Algorithm)队列距离矢量算法是距离矢量算法的一种改进算法,主要解决计数到无穷大问题。
该算法引入了队列和计数器,通过计数器和链路状态信息来确定数据包是否进入队列。
每个节点在路由表中记录到达目的节点的距离向量和队列的长度。
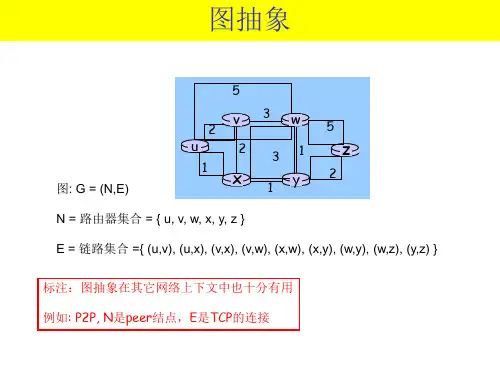

计算机网络网络层路由算法网络层是计算机网络中的一个重要层次,负责提供节点之间的数据传输服务。
网络层的核心任务是进行路由选择,即根据不同的路由算法选择最佳的路径来传输数据包。
本文将介绍常见的几种网络层路由算法,并对其进行分析和比较。
1.静态路由算法静态路由算法是指路由表在网络建立之初静态地配置好,不会随着网络的变化而改变。
常见的静态路由算法有默认路由、固定路由和策略路由等。
静态路由算法的优点是简单易懂,配置方便,适用于网络规模不大且变动较少的场景。
但是缺点是无法适应网络拓扑的变化,不利于负载均衡和故障恢复。
2.距离向量路由算法距离向量路由算法是一种分布式路由算法,具有良好的自适应性和容错性。
每个节点只知道与其相邻节点的距离,通过交换距离向量表来实现路由选择。
常见的距离向量路由算法有RIP(Routing Information Protocol)和IGRP(Interior Gateway Routing Protocol)等。
距离向量路由算法的优点是实现简单,计算量小。
但是缺点是不能解决环路问题和计数到无穷问题,容易产生路由震荡。
3.链路状态路由算法链路状态路由算法是另一种分布式路由算法,采用全局信息来计算最佳路径。
每个节点需要发送链路状态信息给其他节点,并根据收到的信息构建全局拓扑图,再利用迪杰斯特拉算法等来计算最短路径。
常见的链路状态路由算法有OSPF(Open Shortest Path First)和IS-IS(Intermediate System to Intermediate System)等。
链路状态路由算法的优点是计算准确,能够解决路由环路和计数到无穷问题。
但是缺点是占用较大的计算和存储资源,并且对网络中的链路状态信息要求较高。
4.路径向量路由算法路径向量路由算法是一种结合链路状态和距离向量的路由算法。
每个节点维护到其他节点的路径向量表,并通过交换路径向量表来更新路由信息。
常见的路径向量路由算法有BGP(Border Gateway Protocol)等。

第6章路由算法总结路由算法是网络中的核心算法之一,它决定了数据包在网络中的传输路径。
路由算法的设计和优化对于网络的性能和稳定性具有重要影响。
在本章中,我们将总结一些常见的路由算法,并介绍它们的优缺点。
1.静态路由算法:静态路由算法是最简单的路由算法,它通过人工配置将目的地和下一跳地址映射起来。
静态路由算法的优点是简单、易于实现和维护,适用于小型网络。
然而,静态路由算法的缺点是无法适应网络拓扑的变化,对于大型和复杂网络不可行。
2.距离向量路由算法:距离向量路由算法是一种基于邻居节点交换信息的分布式算法。
每个节点维护一个路由表,其中包含到达各个目的地的距离和下一跳节点信息。
节点周期性地将路由表广播给邻居节点,并根据收到的更新信息更新自身路由表。
距离向量路由算法的优点是简单、分布式,适用于小型网络。
然而,它的缺点是收敛速度慢和计算复杂度高,容易出现路由环路和计数问题。
3.链路状态路由算法:链路状态路由算法是一种基于全局网络状态信息的算法。
每个节点通过发送链路状态信息到整个网络,使得每个节点都具有完整的网络拓扑信息。
节点根据收到的链路状态信息计算最短路径,并构建路由表。
链路状态路由算法的优点是收敛速度快、计算复杂度低和稳定性好。
然而,它的缺点是需要消耗大量的带宽和存储资源,并且对于网络规模较大的情况下,算法的效率会下降。
4.链路状态路由算法的改进算法:为了优化链路状态路由算法,人们提出了一些改进算法,如OSPF (开放式最短路径优先)、IS-IS(中间系统间路由)等。
这些算法使用了一些技术,如分层、区域划分和链路优化等,以提高算法的性能和可扩展性。
5.BGP(边界网关协议):BGP是用于互联网的一种路径向量路由协议。
它是一种自治系统之间的路由协议,用于实现互联网的路由选择。
BGP通过交换路由信息和策略来确定数据包的最佳路径。
BGP的优点是具有高度的灵活性和可配置性,可以根据策略调整路由。
然而,BGP的缺点是配置复杂和收敛速度较慢。

第六章广域网6-01 试从多方面比较虚电路和数据报这两种服务的优缺点答:答:(1)在传输方式上,虚电路服务在源、目的主机通信之前,应先建立一条虚电路,然后才能进行通信,通信结束应将虚电路拆除。
而数据报服务,网络层从运输层接收报文,将其装上报头(源、目的地址等信息)后,作为一个独立的信息单位传送,不需建立和释放连接,目标结点收到数据后也不需发送确认,因而是一种开销较小的通信方式。
但发方不能确切地知道对方是否准备好接收,是否正在忙碌,因而数据报服务的可靠性不是很高。
(2)关于全网地址:虚电路服务仅在源主机发出呼叫分组中需要填上源和目的主机的全网地址,在数据传输阶段,都只需填上虚电路号。
而数据报服务,由于每个数据报都单独传送,因此,在每个数据报中都必须具有源和目的主机的全网地址,以便网络结点根据所带地址向目的主机转发,这对频繁的人—机交互通信每次都附上源、目的主机的全网地址不仅累赘,也降低了信道利用率。
(3)关于路由选择:虚电路服务沿途各结点只在呼叫请求分组在网中传输时,进行路径选择,以后便不需要了。
可是在数据报服务时,每个数据每经过一个网络结点都要进行一次路由选择。
当有一个很长的报文需要传输时,必须先把它分成若干个具有定长的分组,若采用数据报服务,势必增加网络开销。
(4)关于分组顺序:对虚电路服务,由于从源主机发出的所有分组都是通过事先建立好的一条虚电路进行传输,所以能保证分组按发送顺序到达目的主机。
但是,当把一份长报文分成若干个短的数据报时,由于它们被独立传送,可能各自通过不同的路径到达目的主机,因而数据报服务不能保证这些数据报按序列到达目的主机。
(5)可靠性与适应性:虚电路服务在通信之前双方已进行过连接,而且每发完一定数量的分组后,对方也都给予确认,故虚电路服务比数据报服务的可靠性高。
但是,当传输途中的某个结点或链路发生故障时,数据报服务可以绕开这些故障地区,而另选其他路径,把数据传至目的地,而虚电路服务则必须重新建立虚电路才能进行通信。


计算机⽹络课后习题与答案第⼀章计算机⽹络概论第⼆章数据通信技术1、基本概念(1)信号带宽、信道带宽,信号带宽对信道带宽的要求答:信号带宽是信号所占据的频率范围;信道(通频)带宽是信道能够通过的信号的频率范围;信号带宽对信道带宽的要求:信道(通频)带宽>信号带宽。
(2)码元传输速率与数据传输速率概念及其关系?答:码元传输速率(调制速率、波特率)是数据信号经过调制后的传输速率,表⽰每秒传输多少电信号单元,单位是波特;数据传输速率(⽐特率)是每秒传输⼆进制代码的位数,单位是b/s或bps;两者的关系:⽐特率=波特率×log2N,N为电脉冲信号所有可能的状态。
(3)信道容量与数据带宽答:信道容量是信道的最⼤数据传输速率;信道带宽W是信道能够通过的信号的频率范围,由介质的质量、性能决定。
(4)数字信号的传输⽅式、模拟信号的传输⽅式答:数字信号传输:数据通信1)数/模转换-->模拟通信系统-->模/数转换2)直接通过数字通信系统传输模拟信号传输1)模拟通信:直接通过模拟通信系统2)数字通信:模/数转换-->数字通信系统-->数/模转换2、常⽤的多路复⽤技术有哪些?时分复⽤与统计复⽤技术的主要区别是什么?答:常⽤的多路复⽤技术有空分多路复⽤SDM、频分多路复⽤FDM、时分多路复⽤TDM 和波分多路复⽤WDM;时分复⽤与统计复⽤技术的主要区别是:时分多路复⽤:1)时隙固定分配给某⼀端⼝2)线路中存在空闲的时隙统计时分多路复⽤(按排队⽅式分配信道):1)帧的长度固定2)时隙只分配给需要发送的输⼊端3、掌握T1和E1信道的带宽计算⽅法。
答:每⼀个取样值⽤8位⼆进制编码作为⼀个话路,则24路电话复⽤后T1标准的传输⽐特率为多少?8000×(8×24+1)=1544000b/sE1 标准是32路复⽤(欧洲标准)传输⽐特率为多少?8000×(8×32)= 2048000bps 4、⽐较电路交换、报⽂交换、分组交换的数据报服务、分组交换的虚电路服务的优缺点?5、指出下列说法错误在何处:(1)“某信道的信息传输速率是300Baud”;(2)“每秒50Baud的传输速率是很低的”;(3)“600Baud和600bps是⼀个意思”;(4)“每秒传送100个码元,也就是每秒传送100个⽐特”。

分布式路由算法原理分布式路由算法原理是计算机网络和分布式系统中的重要概念,它在互联网的运行中起着至关重要的作用。
这种算法允许网络中的节点(如服务器、路由器等)自主地决定数据包的传输路径,以实现高效、可靠的通信。
本文将深入探讨分布式路由算法的基本原理、类型以及其在实际应用中的挑战。
首先,我们来理解分布式路由算法的基本原理。
分布式路由算法的核心思想是通过网络中的每个节点独立决策数据包的转发方向,而不是依赖于中心化的控制机构。
每个节点根据自身的路由表和网络状态信息,决定数据包的下一步传输目标。
这种算法的优势在于,即使在网络部分节点故障或通信链路中断的情况下,也能保证数据包的传递,提高了网络的健壮性和容错性。
分布式路由算法主要有两种基本类型:距离向量路由算法和链路状态路由算法。
1. 距离向量路由算法,如著名的RIP(Routing Information Protocol)协议,基于“最短路径优先”的原则。
每个节点维护一个到所有其他节点的距离向量,并周期性地与邻居交换这些信息。
当接收到新的距离向量时,节点会更新自己的路由表,选择到达目标的最短路径。
然而,这种算法存在收敛慢、计算复杂度高等问题,适合小型网络。
2. 链路状态路由算法,如OSPF(Open Shortest Path First)和ISIS (Intermediate System to Intermediate System)协议,每个节点都拥有整个网络的拓扑视图。
节点通过泛洪的方式交换链路状态信息,然后使用Dijkstra算法计算到所有节点的最短路径。
这种方法能快速收敛,适用于大型和复杂的网络环境。
然而,分布式路由算法在实际应用中也面临着一些挑战。
首先,由于网络规模的扩大,路由表的维护和更新成为一项巨大的任务,可能导致资源消耗过大。
其次,网络动态性,如链路的频繁变化,可能引发路由振荡,影响网络稳定性。
此外,安全性也是一个重要问题,恶意节点可能篡改路由信息,导致数据包的误传或丢失。

无线mesh网络中的分布式路由算法与协议一、引言随着物联网技术的飞速发展,将各种设备连接到互联网已经变得越来越容易。
然而,传统的中心化网络设计已经无法满足我们对联网设备的要求。
在很多情况下,这些设备的数量很多,它们分散在不同的地方并且需要同时与其他设备进行通信。
这时,分布式网络的设计就变得至关重要。
而无线mesh网络正是一种用于实现分布式网络的解决方案。
本文将着重介绍无线mesh网络中的分布式路由算法与协议。
二、无线mesh网络概述1. 无线mesh网络定义无线mesh网络,也称为mesh网络或网状网络,是一种分布式网络拓扑结构,其中数据通过多个中间节点进行传输,从而将多个设备连接到互联网。
每个节点可以成为信息的源和目的地,因此该网络结构可以在没有中心节点的情况下实现。
2. 无线mesh网络的特点相对于传统的无线网络,无线mesh网络具有以下特点:(1) 去中心化:无线mesh网络没有固定的中心节点和明确的路由。
数据通过自组织和自适应的方式在网络中传递。
(2) 高可靠性:因为没有固定的中心节点,即使一个节点发生故障,数据依然可以通过其他节点进行传输,从而保证了网络的可靠性。
(3) 省电:无线mesh网络利用多节点进行传输,因此数据可以通过一个节点的转发,从而减少每个设备的功耗。
(4) 高速度:无线mesh网络可以通过多路径传输数据,从而提高数据的传输速度。
(5) 扩展性:因为是分布式网络,节点可以根据需要加入或离开网络,从而实现网络的扩展性。
三、分布式路由算法1. 分类路由算法根据其计算方式和信息交换方式可以被划分为以下几类:(1) 纯分布式算法:每个节点都是平等的,每个节点都可以决定自己的路由表。
(2) 局部信息算法:每个节点只需要维护自己的一部分拓扑信息。
(3) 全局信息算法:每个节点需要维护网络中所有节点的信息。
(4) 混合信息算法:每个节点维护自己的信息和部分邻居节点的信息。
2. 常用的无线mesh网络路由算法(1) Ad-hoc On-demand Distance Vector (AODV):是一种基于距离向量的路由协议,它适用于变化迅速的网络环境。

分布式自适应路由选择算法引言:在计算机网络中,路由选择是指网络中的节点如何选择将数据包从一个节点传输到另一个节点的路径。
传统的路由选择算法常常采用固定的策略,无法适应网络拓扑的变化和负载的波动。
为了解决这个问题,分布式自适应路由选择算法应运而生。
本文将介绍分布式自适应路由选择算法的原理和应用。
一、分布式自适应路由选择算法的原理分布式自适应路由选择算法是指网络中的每个节点根据自身的状态和网络的拓扑结构,自主地选择最优的路径来传输数据包。
该算法的核心思想是节点之间的协作和信息交换,以实现动态的路由选择。
具体来说,分布式自适应路由选择算法包括以下几个步骤:1. 节点状态监测:每个节点通过监测自身的状态,如负载、延迟等指标,来评估自身的性能和可用性。
节点可以周期性地发送心跳消息,以通知其他节点自身的状态。
2. 邻居节点信息交换:每个节点通过与邻居节点进行信息交换,获取网络中其他节点的状态信息。
这些信息可以包括邻居节点的负载、延迟等指标,以及节点之间的链路状态。
3. 路由计算:每个节点根据收集到的状态信息,使用一定的路由计算算法来选择最优的路径。
路由计算算法可以根据不同的指标给出不同的权重,以适应网络的需求。
4. 路由更新:每个节点将计算出的最优路径更新到路由表中,并将更新的路由信息广播给其他节点。
其他节点收到路由更新消息后,更新自己的路由表。
二、分布式自适应路由选择算法的应用分布式自适应路由选择算法在现实网络中有着广泛的应用。
以下是几个典型的应用场景:1. 数据中心网络:在大规模的数据中心网络中,节点之间的负载和链路状态可能会发生频繁的变化。
采用分布式自适应路由选择算法可以使数据中心网络更加稳定和高效。
2. 移动自组织网络:移动自组织网络中的节点具有高度的移动性,网络拓扑结构可能会频繁变化。
分布式自适应路由选择算法可以帮助节点根据自身的位置和邻居节点的状态来选择最优的路径。
3. 无线传感器网络:无线传感器网络中的节点资源有限,节点之间的通信也存在不确定性。
基于分布式计算的动态路由算法设计随着计算机网络的不断发展和普及,网络中的数据传输负载不断增加,这对网络路由技术提出了更高的要求。
传统的路由算法已经不能完全满足当前网络的要求,需要一种更加高效的路由算法。
基于分布式计算的动态路由算法就是一种使路由更加智能和高效的算法。
一、动态路由与静态路由的区别在网络通信中,路由是指将源设备发送的数据包传输到目的设备的过程。
路由算法的核心是找到一条最短的路径来保证传输数据的高效性。
在网络建设初期,静态路由算法被广泛应用。
静态路由是一种通过手工配置路由表的算法,其路由表不会随着网络中的变化而自动更新。
然而,静态路由算法仅对网络拓扑结构不变的场景适用。
一旦网络拓扑发生变化,静态路由表将无法适应新的变化。
这就引出了动态路由的概念。
动态路由是指路由表可以根据网络变化进行自动更新的路由算法。
动态路由可以使网络中的路由更加智能、高效,满足网络变化的需求。
二、分布式计算的概念分布式计算是指将一个问题分解为多个子问题,多个计算机同时处理这些子问题,最后将它们组合成完整的问题解决方案。
分布式计算与传统的集中式计算相比,具有更高的性能、可靠性和灵活性。
在分布式计算中,每个计算机都是一个节点,这些节点之间相互交换数据,共同完成计算任务。
分布式计算可以应用于计算机网络、互联网、物联网等领域。
三、基于分布式计算的动态路由算法设计将分布式计算技术应用于动态路由算法,可以使路由表动态调整,从而更好地适应网络变化。
下面将讨论一个基于分布式计算的动态路由算法的设计。
1. 网络拓扑图的建立首先,需要建立网络拓扑图。
这可以通过路由器物理连接和链路信息来获取。
网络拓扑图描述了网络中各个节点之间的关系,对于路由算法的准确性至关重要。
2. 子问题分解在算法设计中,需要将整个路由计算问题分解为多个子问题,这些子问题可以通过分布式计算技术来并行计算。
每个节点需要维护一个路由表,将路由表分布到不同的节点上,节点之间通过协作来获得网络中其他节点的信息。
计算机⽹络-⽹络层-路由算法计算机⽹络-⽹络层-路由算法最优化原则1.最佳路径的每⼀部分也是最佳路径如果路由器J在从路由器I到K的最优路径上,那么从J到K的最优路径必定沿着同样的路由路径2.通往路由器的所有最佳路径的并集是⼀棵称为汇集树3.路由算法的⽬的为所有路由器找出并使⽤汇集树最短路径路由Dijkstra算法1.每个节点⽤从源节点沿已知最佳路径到该节点的距离来标注,标注分为临时性标注和永久性标注2.初始时,所有节点都为临时性标注,标注为⽆穷⼤3.将源节点标注为0,且为永久性标注,并令其为⼯作节点4.检查与⼯作节点相邻的临时性节点,若该节点到⼯作节点的距离与⼯作节点的标注之和⼩于该节点的标注,则⽤新计算得到的和重新标注该节点5.在整个图中查找具有最⼩值的临时性标注节点,将其变为永久性节点,并成为下⼀轮检查的⼯作节点6.重复第四、五步,直到⽬的节点成为⼯作节点泛洪算法描述⼀种将数据包发送到所有⽹络节点的简单⽅法,每个节点通过将其发送到所有其他链接之外来泛洪在传⼊链接上接收到的新数据包,它属于静态算法问题重复的数据包,由于循环可能会⽆限多节点需要跟踪已泛洪的数据包以阻⽌洪泛即使在跳数上使⽤限制也会成倍爆炸两种解决措施每个数据包的头中包含⼀个跳计数器,每经过⼀跳后该计数器减1,为0时则丢弃该数据包记录哪些数据包已经被扩散了,从⽽避免再次发送这些数据包。
⽅法:1.每个数据包头⼀个序号,每次发送新数据包时加12.每个路由器记录下它所看到的所有(源路由器,序号)对3.当⼀个数据包到达时,路由器检查这个数据包,若是重复的,就不再扩散了选择性扩散它是⼀种泛洪⽅法的⼀种改进,将进来的每个数据包仅发送到与正确⽅向接近的线路上扩散法应⽤情况扩散法的⾼度健壮性,可⽤于军事应⽤分布式数据库应⽤中,可⽤于同时更新所有的数据库可⽤于⽆线⽹络中扩散法作为衡量标准,⽤来⽐较其它的路由算法距离⽮量算法描述距离向量是⼀种分布式路由算法,最短路径计算跨节点分配,属于动态算法,被⽤于RIP协议。