Waters Empower Software关于分离度计算
- 格式:pdf
- 大小:124.41 KB
- 文档页数:3


药品研究色谱数据工作站及色谱数据管理要求(一)引言概述:药品研究色谱数据工作站及色谱数据管理是药品研究中非常重要的一项工作。
通过建立一个高效的色谱数据工作站和严格的色谱数据管理要求,可以提高药品研究的效率和准确性。
本文将从五个方面详细阐述药品研究色谱数据工作站及色谱数据管理的要求。
一、色谱数据工作站的要求:1.1 软件平台选择:选择适合药品研究的色谱数据处理软件平台,如Agilent OpenLAB、Waters Empower等,确保软件具备良好的数据处理和管理功能。
1.2 硬件设备配置:配置高性能的计算机、高分辨率的显示器和稳定的网络连接,以确保色谱数据的高效处理和传输。
1.3 数据备份与恢复:建立数据备份和恢复机制,定期对色谱数据进行备份,并确保能够及时恢复数据,以防止数据丢失或损坏。
二、色谱数据管理的要求:2.1 数据命名规范:制定统一的数据命名规范,包括样品编号、分析方法、日期等信息,以便于数据的查找和管理。
2.2 数据存储结构:建立合理的数据存储结构,按照项目、样品等进行分类存储,方便数据的管理和检索。
2.3 数据权限管理:设置不同的用户权限,确保只有授权人员才能查看、修改和删除数据,保护数据的安全性和完整性。
三、数据采集与导入要求:3.1 仪器参数设置:在进行色谱分析前,正确设置仪器参数,包括流速、温度、检测器类型等,以确保数据的准确性和可比性。
3.2 样品信息记录:记录样品的详细信息,包括样品来源、制备方法等,以便于后续数据的分析和解释。
3.3 数据导入与校验:导入色谱数据前,进行数据校验,确保数据的完整性和准确性,并进行数据质量控制,如峰形、峰面积等参数的计算和校正。
四、数据处理与分析要求:4.1 峰识别与峰面积计算:使用合适的峰识别算法,对色谱数据进行峰识别和峰面积计算,以获取样品中目标成分的含量。
4.2 数据校正与修正:对数据进行校正和修正,如背景噪声的去除、峰形的修正等,以提高数据的准确性和可靠性。


Empower
一、配置管理器
二、仪器方法和方法组
三、数据采集
四、处理方法的建立
五、查看结果及报告生成
选中“项目(Projects)”
选择父项目选择父项目,,然后按“下一步”。
输入项目的容量输入项目的容量,,如果不要审计追踪如果不要审计追踪,,将“支持‘全面审计追踪’前的勾去掉前的勾去掉,,然后按“下一步”。
注意注意::推荐将表空间改为
100M
选择访问权
限后限后,,点“下
一步”
选择从其它项目要拷贝的内容(一般选默认Defaults),按“下一步”
命名项目后命名项目后,,按
“完成”
新建的项目出现
在列表上在列表上。
一、配置管理器
二、仪器方法和方法组
三、数据采集
四、处理方法的建立
五、查看结果及报告生成
一、配置管理器
二、仪器方法和方法组
三、数据采集
四、处理方法的建立
五、查看结果及报告生成
一、配置管理器
二、仪器方法和方法组
三、数据采集
四、处理方法的建立
五、查看结果及报告生成
2D 通道峰
用鼠标选定一段基线以设定检测峰起
点和落点的阈值点和落点的阈值,,点击“下一步”
用鼠标选定积分区间用鼠标选定积分区间,,点击“下一步”
如有必要可设定最小峰面积和最小峰高如有必要可设定最小峰面积和最小峰高,,然后按“下一步”
按“下一步”
更正样品信息错误
输入采集数据时缺少的信息。
贵州旱情简介:2011年7月以来,持续的高温少雨天气导致贵州部分地区发生较为严重旱情,至8月16日贵州干旱监测显示,全省30余个县市出现特旱和重旱。
全省各地多云到晴,赤水河谷、遵义东部、铜仁地区、黔东南大部、黔南南部、黔西南东南部午后有35℃以上的高温。
贵州省干旱监测显示,全省有11个县市出现特旱(兴义、盘县、习水、晴隆、普安、独山、纳雍、贵定、册亨、荔波、余庆),20个县市区出现重旱(施秉、麻江、金沙、石阡、黔西、清镇、贞丰、白云、龙里、赤水、开阳、瓮安、贵阳、都匀、惠水、三都、息烽、安龙、榕江、乌当),30个县市区出现中旱。
较15日,特旱站数增加1个,重旱站数减少1个。
贵州省气象台16日11时和15时继续发布高温黄色预警信号和干旱橙色预警信号,16日白天,赤水河谷、遵义市大部、铜仁地区、黔东南州大部、黔南州南部、黔西南州东南部午后有35℃以上的高温,其中,赤水河谷、遵义市东部、铜仁地区大部、黔东南州北部午后有37℃以上高温。
据贵州省防汛抗旱指挥部统计,进入8月,贵州大部分地区旱情仍维持并呈发展态势,截至12日,全省农作物受灾面积1566万亩,有300多万人、126万头大牲畜发生临时饮水困难。
16日夜间到17日白天,贵州全省各地多云到晴,西部地区有分散阵雨或雷雨,赤水河谷、遵义市东部、铜仁地区、黔东南州大部、黔南州南部、黔西南州东南部午后有35℃以上的高温。
17日夜间到20日,全省各地多云到晴,赤水河谷、遵义东部、铜仁地区、黔东南大部、黔南南部、黔西南东南部午后有35℃以上的高温。
截至8月29日,贵州省出现特旱,23个县市、重旱36个县市区、中旱17个县市。
特旱区域主要分布在铜仁地区西部、黔东南州中西部、黔南州中东部及南部、六盘水市南部、黔西南州西南部、遵义市东部局地。
截至8月25日,贵州省除贵阳市云岩区外的87个县(市、区)均不同程度受灾,因旱受灾人口2000多万,有近550万人、280多万头大牲畜发生临时饮水困难。

WatersHPLC System Basic Teaching Material For Empower Software沃特斯高效能液相層析系統-資料處理軟體基礎操作指引美商沃特斯公司-台灣分公司Version Issue Date Author Comments1.0 Aug / 2003 Waters Taiwan Initial VersionContent一、電腦/層析軟體開機/開始操作畫面說明 (3)二、資料處理系統操作介面/畫面說明 (3)三、Project 之建立 (4)四、層析系統(Chromatographic system)之建立 (8)五、使用者(User)之建立 (11)六、實驗開始/ 儀器方法( Instrument Method )之建立 (13)七、數據處理方法( Processing Method )之建立 (16)八、報表列印說明 (24)一、電腦/層析軟體開機/開始操作畫面說明a.打開電腦電源開關,進入作業系統,連續按兩下”EMPOWER LOGING” 圖像。
b.輸入UserName(例如:System)、Password(例如:Manager),按OK。
c.進入EMPOWER畫面( Pro 或Quick Start介面,可依使用者設定而不同)。
二、資料處理系統操作介面/畫面說明圖像功能描述Run Samples 開始樣品分析。
Browse Project Project 瀏覽、數據處理與列印。
Configure System 層析系統設定。
Process Data 數據處理。
Review Data 數據瀏覽、處理。
Print Data 報表列印。
三、PROJECT 之建立a.打開電腦電源開關,進入作業系統,連續按兩下”EMPOWER LOGING” 圖像。
b.輸入UserName以及Password,按OK。
c.進入EMPOWER Pro畫面,點選”Configure System”。

Empower 3 计算USP、EP 和JP 信噪比1.计算方法2.使用空白值计算信噪比计算方法软件根据最新的美国、欧洲和日本药典计算信噪比,公式如下:s/n = 2h/h n其中:h = 与组分对应的峰高hn = 在等于半高处峰宽的至少五倍(USP) 或20 倍(EP 和JP)的距离内,观测到的最大与最小噪音值之间的差值,并且,此段距离以空白进样的目标峰区域为中心。
可以指定是否使用处理方法的“适应性”选项卡中的“计算USP、EP 和JP s/n”(以前“为计算EP s/n”)复选框计算USP、EP 和JP s/n。
也可以指定是否使用由空白进样中的峰区域计算的噪音值计算USP s/n、EP s/n 和JP s/n。
每个峰的噪音区是唯一的。
通过在各个峰的保留时间处将噪音区居中的相应空白进样来确定噪音区。
指定半高处乘子参数,从而定义噪音区。
USP s/n新的适应性峰字段USP s/n 使用“美国药典”中的信噪比(s/n) 公式计算。
USP s/n 计算公式如下:2 ╳峰高/(噪音/缩放)其中:峰高= 峰高的绝对值噪音= 峰的噪音值(峰到峰噪音)缩放= “缩放到微伏”值缺省情况下,软件将USP s/n 值报告为6 位精度,不采用科学计数法也没有单位。
用于计算USP s/n 的噪音值将根据“使用空白进样中位于峰区域内的噪音”选项的状态来确定:• 选中该选项时,软件用空白进样中所确定的峰到峰噪音计算每个峰的噪音值。
该值针对单个空白进样的相同通道中的区域进行计算。
此区域以峰保留时间为中心,宽度等于半高处峰宽乘以USP 噪音区的半高处乘子值。
软件在结果中将此噪音值报告为USP 噪音。
缺省情况下,软件将该值报告为6 位精度,不采用科学计数法,单位为“图单位”。
• 清除该选项后,软件将使用结果的峰到峰噪音值;不使用空白进样计算噪音。
在处理方法的“噪音和漂移”选项卡中,指定此区域的开始和结束时间。
在处理方法的“适应性”选项卡上,“USP s/n 噪音区的半高处乘子”字段的范围在1 到99 之间,缺省为5。

Empower 2 软件二维数据处理标准曲线定量原理选择相应的“项目(Project)”, 然后点击确定¡数据处理流程—查看数据,并建立处理方法(processing method)—改变样品,输入标准品的浓度/含量—处理数据—查看结果在“通道(Channels)”标签栏下,选择最低浓度标准样品,然后选“查看(Review)”命令,到查看窗口创建处理方法。
选择“新建(New)”,“处理方法(Processing Method)”命令选择“使用处理方法向导(Use Processing Method Wizard)”, 然后按“确定”用鼠标选定一段基线以设定检测峰起用鼠标选定积分区间,点击“下一步”如有必要可设定最小峰面积和最小峰高,然后按“下一步”按“下一步”选择或输入峰(组份)的名字,它们一定要与组点击“下一步”选择“外标校正(External Standard Calibration)”然后点击“下一步”命名处理方法,然后按“完成”回到“查看(Review)”窗口然后选择“退出”命令¡数据处理流程—查看数据,并建立处理方法(processing method)—改变样品,输入标准品的浓度/含量—处理数据—查看结果回到“样品组(sample sets)”窗口填标样含量:选中样品组,选“工具(tools)”菜单,点“改变样品Alter Sample”命令。
对于非样品组进样的样品,则回到“项目(Project)”窗口通道选项卡下,填标样含量:选中所需的标准样的通道,选“工具(tools)”菜单,点“改变样品(Alter Sample)”命令。
在出现的修改样品界面,选“编辑(Edit)”菜单,点“含量(Amounts)”命令。
选择建立好的处理方法的名字,点“打开”如果出现此对话框,单击“是”回到“修改样品”界面,选“文件”菜单, 点“保存”命令后,退出此界面,回到“项目”界面。
¡数据处理流程—查看数据,并建立处理方法(processing method)—改变样品,输入标准品的浓度/含量—处理数据—查看结果点击“使用指定的处理方法(Use specified processing method)”然后指定处理方法,按“确定”¡数据处理流程—查看数据,并建立处理方法(processing method)—改变样品,输入标准品的浓度/含量—处理数据—查看结果在“结果组Results sets”或“结果Results”栏点“更新Update”按钮显示最新计算结果。
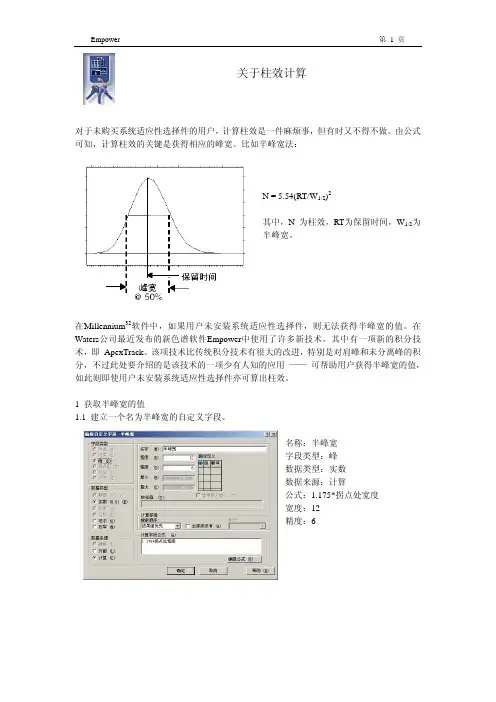
关于柱效计算对于未购买系统适应性选择件的用户,计算柱效是一件麻烦事,但有时又不得不做。
由公式可知,计算柱效的关键是获得相应的峰宽。
比如半峰宽法:N = 5.54(RT/W1/2)2其中,N 为柱效,RT为保留时间,W1/2为半峰宽。
在Millennium32软件中,如果用户未安装系统适应性选择件,则无法获得半峰宽的值。
在Waters公司最近发布的新色谱软件Empower中使用了许多新技术,其中有一项新的积分技术,即 ApexTrack。
该项技术比传统积分技术有很大的改进,特别是对肩峰和未分离峰的积分,不过此处要介绍的是该技术的一项少有人知的应用——可帮助用户获得半峰宽的值,如此则即使用户未安装系统适应性选择件亦可算出柱效。
1 获取半峰宽的值1.1 建立一个名为半峰宽的自定义字段。
名称:半峰宽字段类型:峰数据类型:实数数据来源:计算公式:1.175*拐点处宽度宽度:12精度:61.2 启动ApexTrack积分在处理方法的积分表中,设定积分算法为ApexTrack。
现在积分即可得到半峰宽的值了。
其中,半峰宽的单位为秒。
“峰宽@50%”为系统适应性选择件计算的半峰宽,单位为分钟。
此处该值用作对照,如未安装系统适应性选择件则看不到该值。
2 计算柱效2.1 建立一个名为半峰宽法柱效的自定义字段名称:半峰宽法柱效字段类型:峰数据类型:实数数据来源:计算公式:5.54*(60*保留时间/半峰宽)**2宽度:12精度:62.2 计算柱效处理数据时启动ApexTrack算法,积分后即可得到按半峰宽法计算的柱效。
这种算法系由色谱理论模型导出,因此按此法计算非高斯峰的柱效时可能有误差。

Waters Millennium 32或Empower系统适用性( System Suitability )软件使用说明一、软件安装1、安装系统适用性软件之前,必须确定 Millennium 32或Empower软件已正确安装并且没有运行。
2、将系统适用性软件的安装软盘放入驱动器中。
3、从 Windows 开始菜单选择运行,输入A:\setup.exe,并确定。
4、出现以下对话框时,选择OK。
5、出现以下对话框,软件已安装成功,确定后退出。
6、若出现其它错误信息,请与Waters工程师联系。
二、软件使用1、在Review窗口中打开色谱图,选择处理方法向导(Processing Method Wizard)建立处理方法。
处理方法向导2、处理方法建立后,选择处理方法窗口(Processing Method Window),修改已建立好的处理方法(注:Millennium软件默认不做系统适用性计算,须在建立好的处理方法中进行修改,打开系统适用性计算功能)。
处理方法窗口3、在处理方法窗口中选择适用性标签(Suitability Tab),分别在Calculate Suitability Results 和Calculate Suitability Results for Unknown Peaks选项前打勾选中,在Void Volume Time (min)后输入系统死时间(15cm色谱柱输入1.5, 25cm色谱柱输入2)。
保存方法,重新积分,查看结果。
4、在结果表中,使用鼠标右键,选择Table Properties,选择Show All,确定。
5、左右移动表格,可查看Symmetry Factor (对称因子)、Resolution (分离度)、USP Plate Count (美国药典理论塔板数)、EP Plate Count (欧洲药典理论塔板数)等计算结果。
(注:EP Plate Count 以半峰宽计算,与中国药典相同;USP Plate Count 以切线峰宽计算。
watersempower软件Empower软件⼀.登录1.双击电脑桌⾯上的Empower图标,出现Empower登录窗⼝。
2.单击窗⼝左上⾓的“登录”键,出现登录对话框。
在⽤户名中输⼊“system”,密码为“manager”,然后单击“确定”,进⼊Empower。
⼆.项⽬管理(⼀)新建项⽬1.单击⿏标左键进⼊“配置系统”。
2.在如下界⾯中,选中“项⽬”后,单击⿏标右键,选择“新建”―“项⽬”。
3.出现“新建项⽬向导”。
a. “表空间”中接受默认设置。
如需要,可选择“全⾯系统审计追踪”,单击“下⼀步”。
b. “选项”页中,选择⽤于本项⽬的选项。
单击“下⼀步”。
c. “访问控制”页中,根据需要选择或者接受默认的选项,然后单击“下⼀步”。
d. 在“复制”中,接受默认的选项,然后单击“下⼀步”。
e. 在“输⼊名称”页中,输⼊项⽬的名称,必要时输⼊注释内容。
最后单击“完成”来结束新项⽬的创建。
4.关闭窗⼝。
(⼆)采集服务器1.进⼊“配置系统”2.选中左侧的“采集服务器”,在右⾯出现相应的采集服务器名称。
3.选中右侧的当前采集服务器,单击右键,从快捷菜单中,选择“属性”。
见下图4.出现“采集服务器属性”对话框。
在该对话框中,可以从仪器选项卡中,地址栏中可以查看显⽰的地址是否与仪器的设置相同。
仪器选项卡此外,可以从“仪器”选项卡⾥的“正常?”⼀栏中查看仪器状态,在正常情况下,应显⽰“是”字样。
5.如出现“否”,可单击“扫描仪器”进⾏检查。
如检查后显⽰“是”,即恢复正常。
(三)项⽬的备份1.进⼊“配置系统”。
2.选中欲进⾏备份的项⽬,单击⿏标右键,出现快捷菜单,选择“属性”,出现“项⽬属性”窗⼝。
在“数据⽂件”中查看数据⽂件⼤⼩。
关闭窗⼝。
3.选中欲进⾏备份的项⽬,单击⿏标右键,出现快捷菜单,选择“备份项⽬”。
4.出现“项⽬备份向导”。
a.输⼊备份注释(建议将数据⽂件⼤⼩写⼊此处),然后单击“下⼀步”。
b.在“选择⽬的地”页中,选择备份⽂件存放的路径。
Waters Millennium 32或Empower系统适用性( System Suitability )软件使用说明一、软件安装1、安装系统适用性软件之前,必须确定 Millennium 32或Empower软件已正确安装并且没有运行。
2、将系统适用性软件的安装软盘放入驱动器中。
3、从 Windows 开始菜单选择运行,输入A:\setup.exe,并确定。
4、出现以下对话框时,选择OK。
5、出现以下对话框,软件已安装成功,确定后退出。
6、若出现其它错误信息,请与Waters工程师联系。
二、软件使用1、在Review窗口中打开色谱图,选择处理方法向导(Processing Method Wizard)建立处理方法。
处理方法向导2、处理方法建立后,选择处理方法窗口(Processing Method Window),修改已建立好的处理方法(注:Millennium软件默认不做系统适用性计算,须在建立好的处理方法中进行修改,打开系统适用性计算功能)。
处理方法窗口3、在处理方法窗口中选择适用性标签(Suitability Tab),分别在Calculate Suitability Results 和Calculate Suitability Results for Unknown Peaks选项前打勾选中,在Void Volume Time (min)后输入系统死时间(15cm色谱柱输入1.5, 25cm色谱柱输入2)。
保存方法,重新积分,查看结果。
4、在结果表中,使用鼠标右键,选择Table Properties,选择Show All,确定。
5、左右移动表格,可查看Symmetry Factor (对称因子)、Resolution (分离度)、USP Plate Count (美国药典理论塔板数)、EP Plate Count (欧洲药典理论塔板数)等计算结果。
(注:EP Plate Count 以半峰宽计算,与中国药典相同;USP Plate Count 以切线峰宽计算。
对称因子在色谱柱中的应用高斯曲线是正态分布中的一条标准曲线。
色谱实验中的色谱峰在理论上应该符合其分布。
因此理论塔板数也是色谱系统适用性一项重要表征。
不过,实际上由于仪器死体积的存在,以及仪器部件和固定液对样品的吸附效果等因素,色谱实验中的大多数色谱峰都对高斯曲线分布存在一定的偏离,产生峰的不对称现象。
色谱实验中的色谱峰存在前延、对称、拖尾三种形态,因此这种不对称现象更能说明色谱峰形状态。
各国药典对色谱实验中色谱峰的状态一般用不对称因子、拖尾因子、对称因子来衡量。
对于药物分析色谱实验,如果排除溶剂因素和物质吸附或键合相尾部效应等因素,单纯从色谱柱填充效果来看,如果色谱柱前面填的紧密,后面填的疏松,即便有效塔板数合格,那么峰显示处后拖尾,如果色谱柱前面填得疏松,后面紧密,则峰显示前拖。
通常有明确的规定,拖尾因子应处于某一范围内。
高斯曲线拖尾因子拖尾因子是用于评价峰形对称性的一个参数。
美国药典、欧洲药典和中国药典均对拖尾因子作出了规定。
美国药典是从色谱峰的顶点作一条曲线与基线垂直,再于峰高5%处做一条与基线平行的直线,与峰两边的交点和垂线的交点将这条直线分成两条线段,A表示左线段的长度,B表示右线段的长度,如图[南药课件]所示。
USP拖尾因子用T表示,则计算公式为T=(A+B)/2A。
色谱峰USP拖尾因子计算图当A =B时,T=1,此时认为色谱峰是对称的;当A>B时,T<1,此时认为色谱峰是有前延趋势的;当A<B时,T>1,此时认为色谱峰是有拖尾趋势的。
中国药典指从色谱峰的顶点作一条曲线与基线垂直,再于峰高5%处做一条与基线平行的直线,与峰两边的交点和垂线的交点将这条直线分成两条线段,分别叫作前半峰和后半峰,d1表示前半峰的长度,W0.05h是5%峰高处的峰宽,如图所示。
CP拖尾因子用T表示,则计算公式为T=W0.05h/2d1。
色谱峰CP拖尾因子计算图当前半峰长度=后半峰长度时,T=1,此时认为色谱峰是对称的;当前半峰长度<后半峰长度时,T<1,此时认为色谱峰是有前延趋势的;当前半峰长度>后半峰长度时,T>1,此时认为色谱峰是有拖尾趋势的。
关于分离度计算
前者,曾论及未购买系统适应性选
择件的用户如何计算半峰宽法柱
效,其后多有用户问及如何计算分
离度。
由公式可知,计算分离度亦
需半峰宽之值:
其中,R 为分离度,RT为保留时
间,W为半峰宽。
本文简述无系统适应性选择件时
如何计算分离度。
1 获取半峰宽之值
1.1 建立名为半峰宽之自定义字段。
名称:半峰宽
字段类型:峰
数据类型:实数
数据来源:计算
公式:1.175*拐点处宽度
宽度:12
精度:6
1.2 启动ApexTrack积分
于处理方法之积分表中设定积分算法为ApexTrack,此时积分即可得半峰宽之值。
其中,半峰宽之单位为秒。
2 计算分离度
2.1 建立名为分离度之自定义字段
名称:分离度
字段类型:峰
数据类型:实数
数据来源:计算
宽度:12
精度:6
公式:
1.18*60*(CCompRef2[保留时间]-CCompRef1[保留时间])/(CCompRef2[半峰宽]+CCompRef1[半峰宽])
2.2 计算分离度
启动ApexTrack算法,于处理方法中指定欲计算分离度之峰对,即CCompRef1与CcompRef2。
然后积分,校正(标准样品)或定量(未知样品)即可得分离度之值。
此法系由色谱理论模型导出,故以此法计算非高斯峰之分离度或有误差,愿知者识之。