单因素实验设计表
- 格式:doc
- 大小:142.50 KB
- 文档页数:6




单因素项目间实验设计
实验目的:为了研究规则字与不规则字两种字之间平均命名反应时的差异。
实验假设:不规则字的平均命名反应时明显长于对于规则字的平均命名反应时。
自变量:汉字的规则性(两个水平——规则,不规则)
操作性定义:汉语的规则性是来源于整字与声旁读音是否相同。
与声旁读音相同的称之为规则字(如骑);与声旁读音不同的称为不规则字(如倚)。
因变量:被试对于汉字的命名反应时。
被试:被试为20名大学大三本科非语言专业学生,男女各半,全部视力和矫正视力正常,普通话水平均达国家二级以上标准。
控制变量:环境(温度、噪音、光线)
被试(受教育程度、视力、专业、年龄)
主试(指导语)
任务变量(字频、笔画数、)
实验材料:词频为30次/百万以上的汉字40个,其中规则字20个,不规则字20个。
实验程序:实验在计算机上进行,全套仪器由一台IBM—XT计算机、录音机、话筒及一些自制的外部接口组成。
实验过程如下:首先,计算机屏幕中央呈现一个注视点1秒,然后注视点消失。
20毫秒间隔后,随机呈现一个汉字,同时计算机开始计时,被试开始读音,语音开关立即切断电源,电脑停止计时。
计算机记录被试反应时,录音机录下被试反应内容。
屏幕上呈现的汉字为IBM机标准汉字, 全部字对随机呈现。
实验结果:
统计结果:规则字组
不规则字组是一样表格。


单因素三水平表1. 任务背景在实验设计中,单因素三水平表是一种常用的实验设计方法。
通过对单个因素进行不同水平的设定,并观察其对实验结果的影响,可以得到关于该因素的信息。
2. 实验设计原理单因素三水平表是一种完全随机化设计。
在这种设计中,研究人员将研究对象随机分为若干组,每组分别设定不同水平的因素,并观察其对实验结果的影响。
通过比较不同水平之间的差异,可以得出结论。
3. 实验步骤步骤一:确定研究目标和因素首先要明确研究目标和所要研究的因素。
例如,我们想要研究某种肥料对植物生长的影响,那么肥料就是我们要研究的因素。
步骤二:确定水平和重复次数根据实际情况,确定所要设置的水平和每个水平需要重复的次数。
在单因素三水平表中,通常会选择3个不同水平,并重复每个水平3次。
步骤三:随机分组将研究对象随机分为若干组,每组分别设定不同水平的因素。
确保每个水平在不同组中的分配是随机的,以排除其他因素对实验结果的影响。
步骤四:进行实验观察在每个组中进行实验观察,并记录相应的数据。
例如,在我们研究肥料对植物生长的影响时,可以记录植物的生长高度、叶片数量等指标。
步骤五:数据分析和结果判断通过对实验数据进行统计分析,比较不同水平之间的差异。
可以使用方差分析等方法来判断是否存在显著差异,并进一步得出结论。
4. 实验示例为了更好地理解单因素三水平表的实验设计方法,我们以一个具体的实验示例来说明。
假设我们想要研究不同浓度的某种溶液对细胞存活率的影响。
我们选择了3个不同浓度的溶液作为三个水平(低浓度、中浓度和高浓度),并重复每个水平3次。
首先,在实验开始前,我们需要准备好所需材料和设备,并确保实验条件相同。
然后,将待处理的细胞分为9组,每组分别加入不同浓度的溶液。
接下来,我们在适当的时间点观察细胞的存活情况,并记录下来。
可以使用显微镜观察细胞形态,或者使用染色剂来检测细胞存活率。
最后,通过对实验数据进行统计分析,比较不同水平之间的差异。



单因素随机区组实验设计一、单因素随机区组实验设计的基本特点心理和教育科学研究中,被试的个体差异是误差变异的重要来源。
它常常会混淆实验处理的效应,因此是无关变异。
随机区组设计使用区组方法减小误差变异,即用区组方法分离出由无关变量引起的变异,使它不出现在处理效应和误差变异中。
单因素随机区组设计适用于这样的情境:研究中有一个自变量,自变量有两个或多个水平(P ≥2),研究中还有一个无关变量,也有两个或多个水平(n ≥2),并且自变量的水平与无关变量的水平之间没有交互作用。
当无关变量是被试变量时,一般首先将被试在这个无关变量上进行匹配,然后将他们随机分配给不同的实验处理。
这样,区组内的被试在此无关变量上更加同质,他们接受不同的处理水平时,可看作不受无关变量的影响,主要受处理的影响而区组之间的变异反映了无关变量的影响,我们可以利用方差分析技术区分出这一部分变异,以减少误差变异,获得对处理效应的更精确的估价。
另外,环境因素也是潜在可考虑的区组变量,例如,每天的时间、每年的季节、地点、仪器等方面的因素也可以进行区组,以减少误差变异,时间是一个特别有效的区组变量,因为它常常还会带来一些附加的变量,如身体的生理周期、疲劳等等。
单因素随机区组实验设计适合检验的假说有两个: (1)处理水平的总体平均数相等,即:0.1.2.:P H μμμ==⋅⋅⋅⋅⋅⋅⋅=或处理效应等于0,即:0:0j H a =(2)区组的总体平均数相等,即:0.1.2.:n H μμμ==⋅⋅⋅⋅⋅⋅⋅=或区组效应等于0,即:20:0i H π=图中可以看出实验中有一个自变量,自变量有4个水平。
实验中还有一个无关变量,将16个被试在无关变量上进行匹配,分为4个区组,每个区组内4个同质被试,随机分配每个被试接受一个处理水平。
二、单因素随机区组实验设计与计算举例(一)研究的问题与实验设计我们仍然利用第一节中文章的生字密度对阅读理解影响的研究做例子。

单因素完全随机实验设计一、单因素完全随机实验设计的基本特点单因素完全随机实验设计适用于这样的研究:研究中有一个自变量,自变量有两个或多于两个水平(p ≥2)。
它的基本方法是:把被试(实验单元)随机分配给处理(自变量)的各个水平,每个被试只接受一个水平的处理。
完全随机实验设计是用随机化的方式控制误差变异的。
它假设,由于被试是随机分配给各处理水平的,被试之间的变异在各个处理水平之间也应是随机分布、在统计上无差异的,不会只影响某一个或几个处理水平。
图中清楚地显示了单因素完全随机实验设计的特点:实验中有一个自变量,自变量有4个水平,每个处理组有4个被试,每个被试接受一个处理水平,16个被试参加了实验。
二、单因素完全随机实验设计与计算举例(一)研究的问题与实验设计一个研究要探讨文章的生字密度对学生阅读理解的影响。
研究者的假设是:阅读理解随着文章中生字密度的增加而下降。
因此,该实验有一个自变量——生字密度,研究者感兴趣的四种生字密度是:5:1(a1)、10:1(a2)、15:1(a3)、20:1(a4)。
因变量是被试的阅读理解测验分数。
实施实验时,研究者将32名被试随机分为四组,每组被试阅读一种生字密度的文章,并回答阅读理解测验中有关文章内容的问题。
这是一个典型的单因素完全随机设计,虽然研究者不再检验实验中其它因素的影响,但实际上存在着多种可能对因变量产生影响的均在变量,例如:文章的长度、文章的主题熟悉性、文章类型等、通讯被试的年龄、受教育程度、阅读能力等。
这时,控制无关变量可做的工作之一是在选取四篇文章时,使它们在除生字密度以外的其它方面尽量匹配。
(二)实验数据及其计算在本书中,数据的方差分析计算是分步进行的:首先列出计算表,然后利用计算表中的数字进行基本量的计算,最后用基本量计算各种平方和。
其中,计算表包括原始数据表和平均数表,其作用主要是帮助读者了解基本量计算公式中各数字的意义和出处,在多因素方差分析中,基本量计算公式迅速增加,计算表的帮助是特别明显的。
2 结果(一级标题,黑体四号,加粗)2.1 单因素实验(二级标题,黑体小四号)2.1.1 乙醇浓度对杜仲黄酮提取的影响:称取2g杜仲叶干粉于5个烧杯中分别用10%、30%、50%、70%、90%的乙醇浓度以料液比1:10浸泡1h,在超声提取25min,抽滤、定容至50ml容量瓶中,测定提取液的吸光度,作图,结果如图1。
乙醇浓度对总黄酮提取效果的影响The effect of content of alcohol on the efficiency of extracting flavonoid conpounds图1分析:从图1中得知,随着乙醇浓度的升高其吸光度也增大,但乙醇浓度超过70%后吸光度有所下降,可能是因为高浓度乙醇使细胞内的蛋白质凝固,黄酮不易溶出;同时从提取液外观颜色看出,随着乙醇浓度增加,颜色逐渐由淡黄的转变成浅绿色,说明脂溶性叶绿素叶渐渐被提取出来,对黄酮的纯化带来不便,因此70%的乙醇提取效果最佳。
2.1.2提取次数对杜仲黄酮提取的影响:称取2g杜仲叶干粉于4个烧杯中编上号,以料液比1:10,20ml的70%乙醇浓度浸泡1h,在超声提取10min,抽滤、定容,测定提取液的吸光度,作图,结果如图2 。
提取次数对总黄酮提取效果的影响The effect of different extracting degrees on the efficiency of extracting flavonoid conpounds图2分析:从图2得知,随着次数的增加,之后的吸光度并没有显著增加反而缓慢下降,说明2次提取已经基本提取完全;而且随着提取次数的增加,其他杂质溶出量也会增加,并且增加了溶剂的回收及能源消耗,,综合考虑成本,以超声提取2次为宜。
2.1.3料液比对杜仲黄酮提取的影响:称取2g杜仲叶干粉于5个烧杯中用70%的乙醇浓度,分别以料液比1:5、1:8、1:10、1:20、1:30浸泡1h,在超声提取25min,抽滤、定容,测定提取液的吸光度,作图,结果如图3。
单因素实验设计单因素实验设计是指在实验中只有一个研究因素,即研究者只分析一个因素对效应指标的作用,但单因素实验设计并不是意味着该实验中只有一个因素与效应指标有关联。
单因素实验设计的主要目标之一就是如何控制混杂因素对研究结果的影响。
常用的控制混杂因素的方法有完全随机设计、随机区组设计和拉丁方设计等。
一、完全随机设计1.概念与特点又称单因素设计或成组设计,是医学科研中最常用的一种研究设计方法,它是将同质的受试对象随机地分配到各处理组进行实验观察,或从不同总体中随机抽样进行对比研究。
该设计适用面广,不受组数的限制,且各组的样本含量可以相等,也可以不相等,但在总体样本量不变的情况下,各组样本量相同时的设计效率最高。
例如:为了研究煤矿粉尘作业环境对尘肺的影响,将18只大鼠随机分到甲、乙、丙3组,每组6只,分别在地面办公楼、煤炭仓库和矿井下染尘,12周后测量大鼠全肺湿重(g),通过评价不同环境下大鼠全肺平均湿重推断煤矿粉尘对作用尘肺的影响,具体的随机分组可以如下实施:第一步:将18只大鼠编号:1,2,3, (18)第二步:可任意设置种子数,但应作为实验档案记录保存(本例设置spss11.0软件的种子数为200);第三步:用计算机软件一次产生18个随机数,每个随意数对应一只老鼠(本例用spss11.0软件采用均匀分布最大值为18时产成的18个随机数);第四步:最小的6个随机数对应编号的大鼠为甲组,排序后的第7个至第12个随机数随因编号为乙组,最大的6个随机数对应编号的大鼠为丙组(结果见表1)。
表1 分配结果编号1234567893.758.7516.2911.12 5.49 3.9813.6416.71 1.69随机数组别甲乙丙乙乙甲丙丙甲编号101112131415161718113.6216.36 2.12 4.7411.54 3.980.1317.3516.38随机数组别丙丙甲乙乙甲甲丙丙2.随机数的产生方法(1)随机数字表:如附表13(马斌荣,医学统计学,第4版),这是一个由0~9十个数字组成60行25列的数字表。
一、实验目的通过本实验,了解单因素试验在饼干制作中的应用,探究不同因素对饼干酥性和口感的影响,为后续正交试验提供数据支持和理论依据。
二、实验材料与设备1. 材料:- 高筋面粉- 糖- 鸡蛋- 黄油- 茶粉(实验因素)- 泡打粉- 盐2. 设备:- 搅拌机- 面包机- 烤箱- 电子秤- 铝箔纸三、实验方法1. 单因素试验设计:- 实验因素:茶粉配比(0g、1g、2g、3g、4g)- 试验步骤:1) 称取高筋面粉、糖、鸡蛋、黄油、泡打粉、盐等原料;2) 将茶粉按照不同配比分别加入原料中;3) 搅拌均匀,形成面团;4) 将面团放入面包机中进行发酵;5) 发酵完成后,将面团分割成等份;6) 将面团压成饼干形状,放入烤箱中烘烤;7) 烘烤完成后,取出饼干,观察酥性和口感。
2. 正交试验设计:- 根据单因素试验结果,确定影响饼干酥性和口感的三个主要因素:茶粉配比、发酵时间、烘烤温度;- 每个因素设定三个水平,采用L9(3^4)正交表进行试验;- 试验步骤:1) 按照正交表安排试验,分别设置茶粉配比、发酵时间、烘烤温度;2) 重复单因素试验步骤,观察饼干酥性和口感。
四、实验结果与分析1. 单因素试验结果:- 随着茶粉配比的增加,饼干酥性逐渐降低,口感逐渐变差;- 发酵时间对饼干酥性和口感的影响不大;- 烘烤温度对饼干酥性和口感的影响较大,温度越高,饼干酥性越好,口感越酥脆。
2. 正交试验结果:- 根据正交试验结果,确定最佳茶粉配比为2g,发酵时间为1小时,烘烤温度为180℃;- 此时制作的饼干酥性最佳,口感最佳。
五、结论通过本实验,我们了解到单因素试验在饼干制作中的应用,并探究了不同因素对饼干酥性和口感的影响。
实验结果表明,茶粉配比、发酵时间、烘烤温度是影响饼干酥性和口感的主要因素。
在后续研究中,我们可以进一步优化这些因素,以制作出更美味的饼干。
六、注意事项1. 在进行单因素试验时,要确保其他因素保持不变,以免影响实验结果;2. 在进行正交试验时,要按照正交表安排试验,确保试验的全面性和科学性;3. 在制作饼干时,要注意火候和温度的控制,以保证饼干的口感和品质。
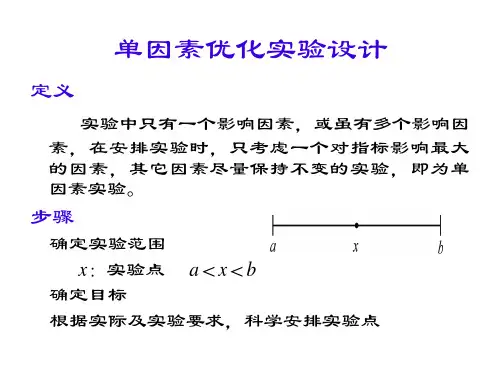
单因素实验设计表
温度对吸光值的影响
络合物吸收波长的确定nm
加热时间对吸光值的影响
显色剂加入量对吸光值的影响
沉淀剂加入量对吸光值的影响
沉淀不完
全0.061 0.061 0.063 0.064 0.064
平均值混浊0.062 0.063 0.063 0.064
乳糖标准曲线
乳糖含量
/mg
0.2 0.4 0.6 0.8 1.0
吸光值0.060 0.104 0.149 0.196 0.241 0.058 0.104 0.145 0.194 0.243 0.059 0.107 0.146 0.195 0.240
平均值0.059 0.105 0.147 0.194 0.242
络合物稳定性实验结果
时间/h 0 1 3 7 17 31
吸光值0.227 0.228 0.227 0.226 0.228 0.218 0.225 0.226 0.228 0.230 0.227 0.220
精密度实验结果
乳糖重复性实验结果
1.4.3 根据测定的吸光度及得到的乳糖标准曲线,按下式计算出乳糖含量。
X(%)=(m1/ m2 )*100
式中:X为试样中乳糖的含量,%;m1为测定用样液中乳糖的质量,mg;m2为测定用样液相当于样品质量,mg。
m2为测定用样液相当于样品质量=1000.2
吸光值=0.067
m1为测定用样液中乳糖的质量=47.3251
X(%)=(m1/ m2 )*100=4.73%
乳糖盲样含量的测定。