统计分析与SPSS的应用课后练习答案
- 格式:doc
- 大小:104.50 KB
- 文档页数:3

《统计分析与SPSS的应用》课后练习答案在学习《统计分析与 SPSS 的应用》这门课程后,通过课后练习能够帮助我们更好地掌握所学知识,并将其应用到实际的数据分析中。
以下是针对部分课后练习的答案及解析。
一、选择题1、在 SPSS 中,用于描述数据集中变量分布特征的统计量是()A 均值B 标准差C 中位数D 众数答案:ABCD解析:均值、标准差、中位数和众数都是描述数据分布特征的常用统计量。
均值反映了数据的集中趋势;标准差反映了数据的离散程度;中位数是将数据排序后位于中间位置的数值;众数则是数据集中出现次数最多的数值。
2、进行独立样本 t 检验时,需要满足的前提条件是()A 样本来自正态分布总体B 两样本方差相等C 两样本相互独立D 以上都是答案:D解析:独立样本 t 检验要求样本来自正态分布总体、两样本方差相等以及两样本相互独立。
只有在这些条件满足的情况下,t 检验的结果才是可靠的。
3、以下哪种方法适用于多组数据的比较()A 单因素方差分析B 配对样本 t 检验C 相关分析D 回归分析答案:A解析:单因素方差分析用于比较三个或三个以上组别的数据是否存在显著差异。
配对样本 t 检验适用于配对数据的比较;相关分析用于研究变量之间的线性关系;回归分析用于建立变量之间的预测模型。
二、简答题1、请简述 SPSS 中数据录入的基本步骤。
答:SPSS 中数据录入的基本步骤如下:(1)打开 SPSS 软件,选择“新建数据文件”。
(2)在变量视图中定义变量的名称、类型、宽度、小数位数等属性。
(3)切换到数据视图,按照定义好的变量逐行录入数据。
(4)录入完成后,保存数据文件。
2、解释相关分析和回归分析的区别。
答:相关分析主要用于研究两个或多个变量之间的线性关系程度和方向,但它并不确定变量之间的因果关系。
相关分析的结果通常用相关系数来表示,如皮尔逊相关系数。
回归分析则不仅可以确定变量之间的关系,还可以建立数学模型来预测因变量的值。

《统计分析与SPSS的应用(第五版)》课后练习答案第2章SPSS数据文件的建立和管理1、S PSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?问:在S P S S中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Miss ing Value )和系统缺失值(System Miss ingValue )。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0” “9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“?”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
如何在SPSS 中指定变量的计算尺度?变量类型包括:数值型(身高)、定序型(受教育程度)以及定类型(性别)。

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第1章SPSS统计分析软件概述1、SPSS的中文全名和英文全名是什么SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(StatisticalProduct and Service Soluti ons)2、SPSS有哪两个主要窗口它们的作用和特点各是什么SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、什么是SPSS的数据集什么是SPSS的活动数据集SPSS的数据集:SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS有哪三种主要使用方式各自的特点是什么SPSS的三种基本运行方式:完全窗口菜单方式、程序运行方式、混合运行方式。
完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
混合运行方式:是前两者的综合。
5、.sav、.spo、.sps分别是SPSS哪类文件的扩展名•sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps 是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在哪些菜单中统计绘图和分析功能主要集中在哪些菜单中SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立和管理1、SPSS中有哪两种基本的数据组织形式各自的特点和应用场合是什么SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案什么SPSS的变量个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么如果希望增强SPSS 统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料问:在SPSS中应如何组织该数据数据文件如图所示:5、什么是SPSS的用户缺失值为什么要对用户缺失值进行定义如何在SPSS中指定用户缺失值缺失值分为用户缺失值(User Missing Value)和系统缺失值(System Missing Value)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型请各举出一个相应的实际数据。
如何在SPSS中指定变量的计算尺度变量类型包括:数值型(身高)、定序型(受教育程度)以及定类型(性别)。
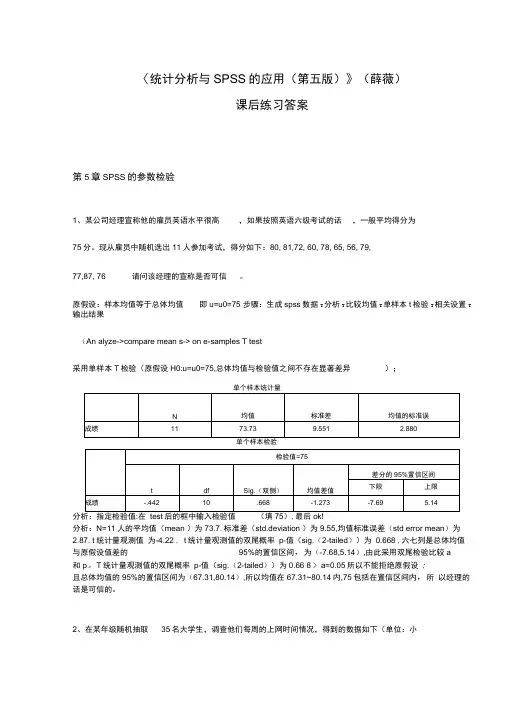
〈统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81,72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75 步骤:生成spss数据T分析T比较均值T单样本t检验T相关设置T 输出结果(An alyze->compare mean s-> on e-samples T test采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);分析:N=11人的平均值(mean )为73.7,标准差(std.deviation )为9.55,均值标准误差(std error mean)为2.87. t统计量观测值为-4.22 , t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668 ,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.66 8 > a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小(1) 请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
(2)基于上表数据,请利用SPSS 给出大学生每周上网时间平均值的 9 5%的置信区间。
(1)分析描述统计描述、频率 (2)分析 比较均值 单样本T 检验每周上网时间的样本平均值为 27.5 ,标准差为10.7,总体均值95%的置信区间为23.8-31.2.3、经济学家认为决策者是对事实做出反应 ,不是对提出事实的方式做出反应 。

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立与管理1、SPSS中有哪两种基本的数据组织形式?各自的特点与应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式与计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名与变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签与变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?问:在SPSS中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Missing Value)与系统缺失值(System MissingValue)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“•”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
如何在SPSS中指定变量的计算尺度?变量类型包括:数值型(身高)、定序型(受教育程度)以及定类型(性别)。

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立和管理1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS 统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?问:在SPSS中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Missing Value)和系统缺失值(System Missing Value)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“?”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
如何在SPSS中指定变量的计算尺度?变量类型包括:数值型(身高)、定序型(受教育程度)以及定类型(性别)。

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第6章SPSS的方差分析1、入户推销有五种方法。
某大公司想比较这五种方法有无显著的效果差异,设计了一项实验。
从应聘人员中尚无推销经验的人员中随机挑选一部分人,并随机地将他们分为五个组,每组用一种推销方法培训。
一段时期后得到他们在一个月内的推销额,如下表所示:第一组20.0 16.8 17.9 21.2 23.9 26.8 22.4 第二组24.9 21.3 22.6 30.2 29.9 22.5 20.7 第三组16.0 20.1 17.3 20.9 22.0 26.8 20.8 第四组17.5 18.2 20.2 17.7 19.1 18.4 16.5 第五组25.2 26.2 26.9 29.3 30.4 29.7 28.2 1)请利用单因素方差分析方法分析这五种推销方式是否存在显著差异。
2)绘制各组的均值对比图,并利用LSD方法进行多重比较检验。
(1)分析比较均值单因素ANOV A 因变量:销售额;因子:组别确定。
ANOVA销售额平方和df 均方 F 显著性组之间405.534 4 101.384 11.276 .000组内269.737 30 8.991总计675.271 34概率P-值接近于0,应拒绝原假设,认为 5 种推销方法有显著差异。
(2)均值图:在上面步骤基础上,点选项均值图;事后多重比较LSD多重比较因变量: 销售额LSD(L)95% 置信区间平均差(I) 组别(J) 组别(I-J) 标准错误显著性下限值上限第一组第二组-3.30000 * 1.60279 .048 -6.5733 -.0267 第三组.72857 1.60279 .653 -2.5448 4.0019第四组 3.05714 1.60279 .066 -.2162 6.3305第五组-6.70000 * 1.60279 .000 -9.9733 -3.4267 * 1.60279 .048 .0267 6.5733 第二组第一组 3.30000 第三组 4.02857 * 1.60279 .018 .7552 7.3019* 1.60279 .000 3.0838 9.6305 第四组 6.35714*第五组-3.40000 1.60279 .042 -6.6733 -.1267 第三组第一组-.72857 1.60279 .653 -4.0019 2.5448 第二组-4.02857 * 1.60279 .018 -7.3019 -.7552第四组 2.32857 1.60279 .157 -.9448 5.6019第五组-7.42857 * 1.60279 .000 -10.7019 -4.1552 第四组第一组-3.05714 1.60279 .066 -6.3305 .2162第二组-6.35714 * 1.60279 .000 -9.6305 -3.0838第三组-2.32857 1.60279 .157 -5.6019 .9448第五组-9.75714 * 1.60279 .000 -13.0305 -6.4838* 1.60279 .000 3.4267 9.9733 第五组第一组 6.70000 * 1.60279 .042 .1267 6.6733 第二组 3.40000* 1.60279 .000 4.1552 10.7019 第三组7.42857* 1.60279 .000 6.4838 13.0305 第四组9.75714*. 均值差的显著性水平为0.05 。

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立和管理1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?体重变化情况产品类型明显减轻无明显变化第一种产品27 19第二种产品20 33问:在SPSS中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Missing Value)和系统缺失值(System Missing Value)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“•”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。

《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:●SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
●活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:●完全窗口菜单方式、程序运行方式、混合运行方式。
●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
●混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
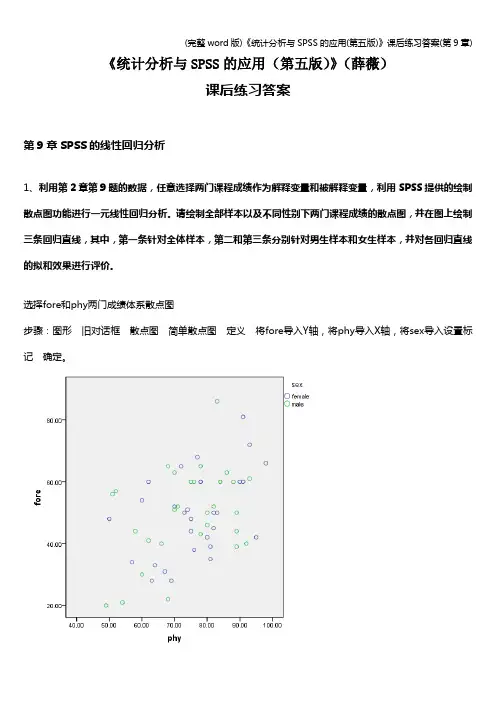
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第9章SPSS的线性回归分析1、利用第2章第9题的数据,任意选择两门课程成绩作为解释变量和被解释变量,利用SPSS提供的绘制散点图功能进行一元线性回归分析。
请绘制全部样本以及不同性别下两门课程成绩的散点图,并在图上绘制三条回归直线,其中,第一条针对全体样本,第二和第三条分别针对男生样本和女生样本,并对各回归直线的拟和效果进行评价。
选择fore和phy两门成绩体系散点图步骤:图形旧对话框散点图简单散点图定义将fore导入Y轴,将phy导入X轴,将sex导入设置标记确定。
接下来在SPSS输出查看器中,双击上图,打开图表编辑在图表编辑器中,选择“元素”菜单选择总计拟合线选择线性应用再选择元素菜单点击子组拟合线选择线性应用。
分析:如上图所示,通过散点图,被解释变量y(即:fore)与解释变量phy有一定的线性关系。
但回归直线的拟合效果都不是很好。
2、请说明线性回归分析与相关分析的关系是怎样的?相关分析是回归分析的基础和前提,回归分析则是相关分析的深入和继续。
相关分析需要依靠回归分析来表现变量之间数量相关的具体形式,而回归分析则需要依靠相关分析来表现变量之间数量变化的相关程度。
只有当变量之间存在高度相关时,进行回归分析寻求其相关的具体形式才有意义。
如果在没有对变量之间是否相关以及相关方向和程度做出正确判断之前,就进行回归分析,很容易造成“虚假回归”。
与此同时,相关分析只研究变量之间相关的方向和程度,不能推断变量之间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况,因此,在具体应用过程中,只有把相关分析和回归分析结合起来,才能达到研究和分析的目的。
线性回归分析是相关性回归分析的一种,研究的是一个变量的增加或减少会不会引起另一个变量的增加或减少。
3、请说明为什么需要对线性回归方程进行统计检验?一般需要对哪些方面进行检验?检验其可信程度并找出哪些变量的影响显著、哪些不显著。
《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:●SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
●活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:●完全窗口菜单方式、程序运行方式、混合运行方式。
●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
●混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
《统计分析与SPSS的应用》课后练习答案在学习《统计分析与 SPSS 的应用》这门课程后,通过课后练习,我们对所学知识有了更深入的理解和掌握。
以下是针对课后练习的详细答案及相关解释。
一、单选题1、在 SPSS 中,用于描述数据集中变量分布特征的命令是()A FrequenciesB DescriptivesC ExploreD Crosstabs答案:B解释:Descriptives 命令可以提供变量的集中趋势、离散程度等分布特征的统计量。
2、进行独立样本 t 检验时,需要满足的前提条件是()A 样本来自正态分布总体B 两样本方差相等C 以上都是D 以上都不是答案:C解释:独立样本 t 检验要求样本来自正态分布总体,且两样本方差相等。
3、用于分析两个变量之间线性关系强度的统计量是()A 相关系数B 决定系数C 方差D 标准差答案:A解释:相关系数用于衡量两个变量之间线性关系的密切程度。
二、多选题1、以下哪些是 SPSS 中的数据类型()A 数值型B 字符型C 日期型D 以上都是答案:D解释:SPSS 中的数据类型包括数值型、字符型和日期型。
2、方差分析的基本假定包括()A 正态性B 方差齐性C 独立性D 以上都是答案:D解释:方差分析需要满足正态性、方差齐性和独立性这三个基本假定。
三、简答题1、请简述 SPSS 中数据录入的基本步骤。
答:首先打开 SPSS 软件,在变量视图中定义变量的名称、类型、宽度、小数位数等属性。
然后切换到数据视图,逐行录入数据。
在录入过程中,要注意数据的准确性和完整性。
2、解释均值、中位数和众数的含义及适用情况。
答:均值是所有数据的算术平均值,反映数据的集中趋势,但容易受极端值影响。
适用于数据分布较为对称、不存在极端值的情况。
中位数是将数据从小到大排序后位于中间位置的数值,不受极端值影响,适用于数据分布偏态或存在极端值的情况。
众数是数据中出现次数最多的数值,适用于描述数据的集中趋势,尤其在类别数据中常用。
《统计分析与SPSS的应用(第五版)》(薛薇)
课后练习答案
第8章SPSS的相关分析
1、对15家商业企业进行客户满意度调查,同时聘请相关专家对这15家企业的综合竞争力进行评分,结果如下表。
编号客户满意度得分综合竞争力得分编号客户满意度得分综合竞争力得分1907091060
210080102030 31501501180100 41301401270110 512090133010 6110120145040
74020156050
8140130
请问,这些数据能否说明企业的客户满意度与其综合竞争力存在较强的正相关,为什么
能。
步骤:(1)图形旧对话框散点/点状简单分布进行相应设置确定;(2)再双击图形元素总计拟合线拟合线线性确定
(3)分析相关双变量进行相关项设置确定
相关性
客户满意度得分综合竞争力得分
客户满意度得分Pearson 相关性1.864**
显著性(双尾).000
N1615
综合竞争力得分Pearson 相关性.864**1
显著性(双尾).000
N1515
**. 在置信度(双测)为时,相关性是显著的。
两者的简单相关系数为,说明存在正的强相关性。
2、为研究香烟消耗量与肺癌死亡率的关系,收集下表数据。
(说明:1930年左右几乎极少
绘制上述数据的散点图,并计算相关系数,说明香烟消耗量与肺癌死亡率之间是否存在显著的相关关系。
香烟消耗量与肺癌死亡率的散点图(操作方法与第1题相同)
相关性
人均香烟消耗死于肺癌人数
人均香烟消耗Pearson 相关性1.737**
显著性(双尾).010
N1111
死于肺癌人数Pearson 相关性.737**1
显著性(双尾).010
N1111
**. 在置信度(双测)为时,相关性是显著的。
相关系数为。
因概率P值小于显著性水平(),拒绝原假设,认为两者存在显著关系。
3.
1)绘制销售额、销售价格以及家庭收入两两变量间的散点图。
如果所绘制的图形不能较清晰地展示变量之间的关系,应对数据如何处理后再绘图。
2)选择恰当的统计方法分析销售额与销售价格之间的相关关系。
(1)
如果所绘制的图形不能较清晰地展示变量之间的关系,应对散点图进行调整。
在SPSS
查看器窗口中选中相应的散点图双击鼠标,进入SPSS图形编辑器窗口。
选中【选项】菜单
下的【分箱元素】子菜单进行数据合并。
(2)
分析相关偏相关进行相关项设置确定
相关性
控制变量销售额(万元)销售价格(元)家庭收入(元)-无-a销售额(万元)相关性.880
显著性(双侧)..000.001
df088销售价格(元)相关性
显著性(双侧).000..002
df808家庭收入(元)相关性.880
显著性(双侧).001.002.
df880家庭收入(元)销售额(万元)相关性
显著性(双侧)..026
df07
销售价格(元)相关性
显著性(双侧).026.
df70
a. 单元格包含零阶 (Pearson) 相关。
如表所示,在家庭收入作为控制变量的条件下,销售额和价格的偏相关系数为,呈一定
的负相关关系,且统计关系显著。