生物信息学实验报告3(三)蛋白质序列分析
- 格式:doc
- 大小:158.50 KB
- 文档页数:3

一、实训背景随着生物科学和信息技术的发展,生物信息学作为一门新兴交叉学科,已成为生物科学研究的重要组成部分。
为了提高学生对生物信息学理论与实践的结合能力,我们学院特开设了生物信息学实训课程。
本次实训旨在通过实际操作,让学生深入了解生物信息学的基本原理、常用工具和数据分析方法,培养学生的实验技能和科研思维。
二、实训目标1. 理解生物信息学的基本概念、研究内容和应用领域。
2. 掌握生物信息学常用工具的使用方法,如BLAST、Clustal Omega、MEGA等。
3. 学会利用生物信息学方法进行基因序列分析、蛋白质结构预测和功能注释。
4. 提高实验操作技能和科研思维能力。
三、实训内容本次实训共分为三个部分:理论学习、实验操作和项目实践。
(一)理论学习1. 生物信息学基础:介绍生物信息学的定义、发展历程、研究内容和方法。
2. 生物序列分析:讲解基因序列、蛋白质序列的基本概念,以及序列比对、序列聚类等分析方法。
3. 蛋白质结构预测:介绍蛋白质结构预测的基本原理和方法,如同源建模、折叠识别等。
4. 功能注释:讲解基因和蛋白质的功能注释方法,如基于序列的注释、基于结构的注释等。
(二)实验操作1. 序列比对:使用BLAST工具进行序列比对,分析序列的同源性。
2. 序列聚类:使用Clustal Omega工具进行序列聚类,分析序列的进化关系。
3. 蛋白质结构预测:使用MEGA工具进行蛋白质结构预测,分析蛋白质的三维结构。
4. 功能注释:使用Gene Ontology(GO)数据库进行基因和蛋白质的功能注释。
(三)项目实践1. 基因组注释:以某物种基因组为研究对象,进行基因预测和功能注释。
2. 蛋白质相互作用网络构建:以某物种蛋白质组为研究对象,构建蛋白质相互作用网络,分析蛋白质之间的相互作用关系。
四、实训过程1. 准备阶段:学生通过查阅资料、阅读文献,了解实训内容,并提前学习相关软件的使用方法。
2. 实验阶段:在教师的指导下,学生进行实验操作,完成实训任务。

生物信息学中的蛋白质序列分析与预测研究蛋白质是生命体中至关重要的分子,它们在细胞功能和结构的调控中发挥着重要的作用。
蛋白质的序列决定了其结构和功能,因此蛋白质序列的分析和预测成为生物信息学研究的重要方向之一。
本文将重点介绍蛋白质序列分析和预测的方法与技术,以及在生物学研究中的应用。
蛋白质序列的分析是指根据蛋白质的氨基酸序列,通过一系列的计算和分析方法,对其结构和功能进行研究的过程。
蛋白质序列分析的方法有很多,其中最常用的包括:比对分析、同源建模、序列特征分析和亚细胞定位预测。
首先,比对分析是蛋白质序列分析的基础方法之一。
通过将待分析的蛋白质序列与已知的蛋白质序列数据库进行比对,可以找到与之相似的序列,进而推测蛋白质的结构和功能。
比对分析常用的工具有BLAST和PSI-BLAST等,它们通过比较序列之间的相似性和一致性,确定序列的保守区域和结构域,从而揭示蛋白质的功能。
其次,同源建模是一种根据已知蛋白质的结构来预测未知蛋白质的结构的方法。
在同源建模中,通过比对已知蛋白质的结构与待预测蛋白质的序列,找到与之相似的蛋白质结构作为模板,并利用模板的结构信息,预测待预测蛋白质的结构。
同源建模的常用工具有SWISS-MODEL和Phyre2等。
同源建模不仅可以预测蛋白质的三维结构,还可以提供结构功能的启示,从而推测其功能。
另外,序列特征分析也是蛋白质序列分析的重要方向之一。
序列特征分析通过对蛋白质序列中的特定模式、保守区域和功能位点进行分析,揭示蛋白质的结构和功能。
常用的序列特征分析方法包括信号肽预测、跨膜区域识别、功能位点预测和蛋白质域识别等。
这些方法通过分析蛋白质序列中的特定特征,揭示蛋白质的功能和结构。
最后,亚细胞定位预测是蛋白质序列分析的一个重要方向。
蛋白质在细胞中的定位决定了其在细胞内发挥的功能,因此准确预测蛋白质的亚细胞定位对于理解其功能至关重要。
亚细胞定位预测通过分析蛋白质序列中的亚细胞定位信号和保守区域,预测蛋白质的亚细胞定位位置。

一、实验目的1. 了解蛋白质序列的基本概念和绘制方法。
2. 掌握蛋白质序列绘制的实验操作流程。
3. 分析蛋白质序列的保守区和功能域,为后续研究提供依据。
二、实验原理蛋白质序列是由氨基酸按照一定的顺序排列而成的。
蛋白质序列的绘制方法有直接法和间接法。
直接法是通过分离纯化蛋白质,然后使用氨基酸分析技术测定氨基酸序列;间接法是通过蛋白质的生物信息学分析,预测蛋白质的氨基酸序列。
本实验采用间接法绘制蛋白质序列。
三、实验材料1. 蛋白质样本:小鼠肝脏组织。
2. 试剂:蛋白酶、SDS-PAGE凝胶、考马斯亮蓝R-250染色剂、凝胶成像系统等。
3. 仪器:高速离心机、电泳仪、凝胶成像系统等。
四、实验步骤1. 提取蛋白质:取小鼠肝脏组织,加入细胞裂解液,匀浆,离心取上清液,即得到蛋白质溶液。
2. 蛋白质分离:将蛋白质溶液进行SDS-PAGE电泳分离,得到蛋白质条带。
3. 蛋白质鉴定:对分离得到的蛋白质条带进行考马斯亮蓝R-250染色,观察蛋白质条带。
4. 蛋白质酶解:将蛋白质条带进行酶解,得到蛋白质肽段。
5. 肽段分析:使用质谱仪对肽段进行质谱分析,得到肽段的质量和序列信息。
6. 蛋白质序列绘制:根据肽段信息,绘制蛋白质序列。
五、实验结果1. SDS-PAGE电泳结果:蛋白质条带清晰,表明蛋白质分离成功。
2. 考马斯亮蓝R-250染色结果:蛋白质条带颜色均匀,表明蛋白质纯度较高。
3. 肽段分析结果:质谱仪成功鉴定出肽段的质量和序列信息。
4. 蛋白质序列绘制结果:根据肽段信息,成功绘制出蛋白质序列。
六、实验讨论1. 蛋白质序列的绘制对于研究蛋白质结构和功能具有重要意义。
本实验通过间接法成功绘制了小鼠肝脏组织的蛋白质序列,为后续研究提供了重要依据。
2. 在实验过程中,蛋白质的提取、分离和鉴定是关键步骤。
本实验采用SDS-PAGE 电泳分离蛋白质,考马斯亮蓝R-250染色鉴定蛋白质,成功实现了蛋白质的分离和鉴定。
3. 肽段分析是蛋白质序列绘制的重要环节。

实习报告一、实习背景与目的随着生物信息学在生物科学、医学、农业等领域的广泛应用,我意识到掌握生物信息学技能对于我未来的职业发展至关重要。
因此,我参加了为期两周的生物信息学实习,以提高我的生物信息学技能并深入了解该领域的实际应用。
二、实习内容与过程在实习的第一周,我主要学习了生物信息学的基础知识,包括生物信息学的基本概念、生物数据库的使用、序列比对和分子进化分析等。
通过查阅资料和参与讨论,我了解了生物信息学在基因组学、蛋白质学和代谢组学等领域的应用,并掌握了相关软件和工具的使用方法。
在实习的第二周,我参与了一个实际项目,对某个基因家族进行进化分析。
首先,我使用序列比对工具对基因家族的成员进行比对,识别出保守区域和变异区域。
然后,我使用分子进化分析工具对序列进行 phylogenetic 分析,构建进化树并分析基因家族的进化关系。
最后,我使用代谢组学数据分析工具对实验数据进行分析,识别出与基因家族进化相关的代谢物。
三、实习成果与反思通过这次实习,我不仅掌握了生物信息学的基本知识和技能,还了解了生物信息学在实际研究中的应用。
我能够独立完成基因家族的进化分析,并能够使用相关软件和工具进行数据分析。
然而,我也意识到生物信息学是一个不断发展的领域,需要不断学习和更新知识。
在实习过程中,我遇到了一些挑战,例如数据分析工具的使用困难和生物信息学概念的理解。
这使我意识到理论与实践之间的差距,并激发了我进一步学习的动力。
四、实习总结通过这次生物信息学实习,我对生物信息学有了更深入的了解,并提高了我的实际操作能力。
我认识到生物信息学在现代生物学研究中的重要性,并决心在未来的学习和工作中不断努力,成为一名优秀的生物信息学专家。

一、实训背景随着生命科学和信息技术的飞速发展,生物信息学作为一门新兴的交叉学科,越来越受到广泛关注。
为了提高我们对生物信息学理论知识的理解和实际应用能力,学校组织了为期两周的生物信息学实训课程。
本次实训旨在通过实践操作,使我们掌握生物信息学的基本原理、方法和工具,提高我们的科研素养和团队协作能力。
二、实训内容本次实训主要围绕以下几个方面展开:1. 生物信息学基础理论实训期间,我们学习了生物信息学的基本概念、发展历程、研究方法和应用领域。
通过讲解和讨论,我们对生物信息学有了更为全面和深入的了解。
2. 生物信息学工具使用实训过程中,我们学习了多种生物信息学工具的使用,如BLAST、Clustal Omega、MAFFT、MEGA等。
这些工具在生物序列比对、基因预测、蛋白质结构分析等方面发挥着重要作用。
3. 生物信息学数据库查询实训中,我们学会了如何使用NCBI、GenBank、UniProt等生物信息学数据库进行查询。
通过查询,我们可以获取大量的生物学数据,为后续研究提供有力支持。
4. 生物信息学项目实践实训期间,我们以小组为单位,完成了两个生物信息学项目。
项目一:利用BLAST进行基因序列比对,分析基因的功能和进化关系;项目二:利用MEGA进行系统发育分析,探讨物种间的进化历程。
三、实训收获1. 理论知识与实践相结合通过本次实训,我们深刻体会到理论知识与实践操作的重要性。
在实训过程中,我们不仅学习了生物信息学的基本理论,还掌握了多种实用工具和方法,为今后的学习和研究打下了坚实基础。
2. 提高科研素养实训过程中,我们学会了如何查阅文献、设计实验、分析数据,提高了自己的科研素养。
同时,我们还学会了如何与他人合作,培养了自己的团队协作能力。
3. 拓宽知识面实训期间,我们接触到了许多生物信息学领域的最新研究成果,拓宽了自己的知识面。
这有助于我们更好地了解生物信息学的发展趋势,为今后的学习和研究提供方向。
4. 增强动手能力实训过程中,我们亲自操作生物信息学工具,分析生物学数据,增强了动手能力。

.第九章蛋白质序列分析与结构预测一种生物体的基因组规定了所有构成该生物体的蛋白质,基因规定了组成蛋白质的氨基酸序列。
虽然蛋白质由氨基酸的线性序列组成,但是,它们只有折叠成特定的空间构象才能具有相应的活性和相应的生物学功能。
了解蛋白质的空间结构不仅有利于认识蛋白质的功能,也有利于认识蛋白质是如何执行其功能的。
确定蛋白质的结构对于生物学研究是非常重要的。
目前,蛋白质序列数据库的数据积累的速度非常快,但是,已知结构的蛋白质相对比较少。
尽管蛋白质结构测定技术有了较为显著的进展,但是,通过实验方法确定蛋白质结构的过程仍然非常复杂,代价较高。
因此,实验测定的蛋白质结构比已知的蛋白质序列要少得多。
另一方面,随着DNA测序技术的发展,人类基因组及更多的模式生物基因组已经或将要被完全测序,DNA序列数量将会急增,而由于DNA序列分析技术和基因识别方法的进步,我们可以从DNA推导出大量的蛋白质序列。
这意味着已知序列的蛋白质数量和已测定结构的蛋白质数量(如蛋白质结构数据库PDB中的数据)的差距将会越来越大。
人们希望产生蛋白质结构的速度能够跟上产生蛋白质序列的速度,或者减小两者的差距。
那么如何缩小这种差距呢?我们不能完全依赖现有的结构测定技术,需要发展理论分析方法,这对蛋白质结构预测提出了极大的挑战。
20世纪60年代后期,Anfinsen首先发现去折叠蛋白或者说变性(denatured)蛋白质在允许重新折叠的实验条件下可以重新折叠到原来的结构,这种天然结构(native structure)对于蛋白质行使生物功能具有重要作用,大多数蛋白质只有在折叠成其天然结构的时候才能具有完全的生物活性。
自从Anfinsen提出蛋白质折叠的信息隐含在蛋白质的一级结构中,科学家们对蛋白质结构的预测进行了大量的研究,分子生物学家将有可能直接运用适当的算法,从氨基酸序列出发,预测蛋白质的结构。
本章主要着重介绍蛋白质二级结构及空间结构预测的方法。
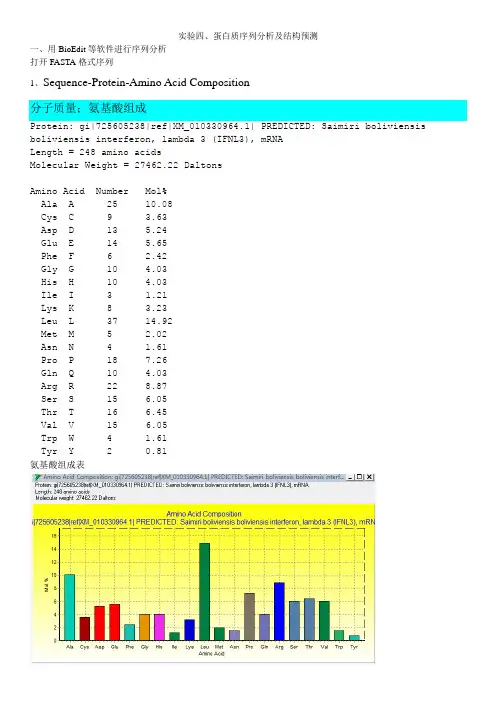
实验四、蛋白质序列分析及结构预测一、用BioEdit等软件进行序列分析打开FASTA格式序列1、Sequence-Protein-Amino Acid Composition分子质量;氨基酸组成Protein: gi|725605238|ref|XM_010330964.1| PREDICTED: Saimiri boliviensis boliviensis interferon, lambda 3 (IFNL3), mRNALength = 248 amino acidsMolecular Weight = 27462.22 DaltonsAmino Acid Number Mol%Ala A 25 10.08Cys C 9 3.63Asp D 13 5.24Glu E 14 5.65Phe F 6 2.42Gly G 10 4.03His H 10 4.03Ile I 3 1.21Lys K 8 3.23Leu L 37 14.92Met M 5 2.02Asn N 4 1.61Pro P 18 7.26Gln Q 10 4.03Arg R 22 8.87Ser S 15 6.05Thr T 16 6.45Val V 15 6.05Trp W 4 1.61Tyr Y 2 0.81氨基酸组成表2、helical wheel diagram3、Hydrophobic Moment matrix with Eisenberg consensus scale 疏水性4、Kyte&Doolittle Mean Hydrophobicity Profile5、Eisenberg Scale Mean Hydrophobicity Profile6、Cornette Scale Mean Hydrophobicity Profile7、Parker HPLC Scale Mean Hydrophobicity Profile8、Boyko Scale Mean Hydrophilicity Profile9、Hopp%Woods Scale Mean Hydrophilicity10、ProtParam tool /protparam/ProtParam (References / Documentation) is a tool which allows the computation of various physical and chemical parameters for a given protein stored in Swiss-Prot or TrEMBL or for a user entered sequence. The computed parameters include the molecular weight, theoretical pI, amino acid composition, atomic composition, extinction coefficient, estimated half-life, instability index, aliphatic index and grand average of hydropathicity (GRA VY) (Disclaimer).输入FASTA格式序列等电点11、跨膜区分析进入CBS 依次进入TMHMMWelcome to CBS http://www.cbs.dtu.dk/index.shtml CBS Prediction Servers http://www.cbs.dtu.dk/services/ TMHMM /protparam/输入FASTA格式序列结果Data 部分数据# WEBSEQUENCE# AA inside membr outside 1 A 0.00271 0.00000 0.99729 2 T 0.00267 0.00004 0.99729 3 G 0.00265 0.00006 0.99729 4 A 0.00265 0.00008 0.99727 5 A 0.00252 0.00022 0.99726 6 A 0.00252 0.00023 0.99726 7 C0.001720.001020.997268 T 0.001720.001020.99726………… ………… 1403 C 0.00059 0.00002 0.99939 1404 G 0.00059 0.00002 0.99939 1405 C 0.00059 0.00002 0.99939 1406 G 0.00059 0.00002 0.99939 1407 A0.000590.000020.999391408 G 0.00059 0.00002 0.99939 1409 A 0.00059 0.00002 0.99939 1410 C 0.00059 0.00002 0.99939 1411 C 0.00059 0.00002 0.99938 1412 T 0.00060 0.00005 0.99935 1413 G 0.00060 0.00009 0.99932 1414 A 0.00060 0.00012 0.99928 1415 A 0.00060 0.00014 0.99926 1416 T 0.00060 0.00016 0.99924 1417 T 0.00060 0.00018 0.99922 1418 G 0.00060 0.00019 0.9992 1419 T 0.00060 0.00023 0.99917 1420 G 0.00060 0.00023 0.99917 1421 T 0.00060 0.00023 0.99918 1422 T 0.00060 0.00023 0.99918 1423 G 0.00059 0.00024 0.99917 1424 C 0.00059 0.00024 0.99917 1425 C 0.00059 0.00024 0.99917 1426 A 0.00059 0.00024 0.99917 1427 G 0.00059 0.00024 0.99917 1428 C 0.00060 0.00024 0.99917 1429 G 0.00060 0.00024 0.99917 1430 G 0.00060 0.00024 0.99917 1431 G 0.00060 0.00023 0.99917 1432 G 0.00060 0.00023 0.99917 1433 A 0.00061 0.00023 0.99917 1434 C 0.00062 0.00021 0.99917 1435 C 0.00066 0.00017 0.99917 1436 T 0.00070 0.00013 0.99917 1437 G 0.00072 0.00011 0.99917 1438 T 0.00075 0.00009 0.99917 1439 G 0.00076 0.00008 0.99917 1440 T 0.00078 0.00006 0.99917 1441 G 0.00079 0.00004 0.99917 1442 T 0.00082 0.00001 0.99917 1443 C 0.00082 0.00001 0.99917 1444 T 0.00082 0.00001 0.99917 1445 G 0.00083 0.00000 0.99917 1446 A 0.00083 0.00000 0.9991712、信号肽及亚细胞定位进入SignalP 4.1 Server http://www.cbs.dtu.dk/services/SignalP/输入FASTA格式序列结果:亚细胞定位: 进入:TargetP 1.1 Server http://www.cbs.dtu.dk/services/TargetP/ 输入序列提交:结果:13、功能分析1)基于序列同源性分析的蛋白质功能预测NCBI----blast 找到吻合相对高的序列查看详情序列同源性蛋白质功能分析NCBI---GENE进入相关文献了解功能2)基于motif、结构位点、结构功能域数据库的蛋白质功能预测Motif:PROSITE//cgi-bin/prosite/ScanView.cgi?scanfile=806498321699.scan.gz结构域基序My Hits:http://hits.isb-sib.ch/cgi-bin/PFSCAN 输入序列结果:http://smart.embl-heidelberg.de/二、蛋白质二级结构预测1)NetTurnP - Prediction of Beta-turns in proteinsNetTurnP 1.0 - Prediction of Beta-turn regions in protein sequenceshttp://www.cbs.dtu.dk/services/NetTurnP/输入序列结果:NetTurnP - Prediction of Beta-turns in proteinsTechnical University of Denmark# For publication of results, please cite:# NetTurnP - Neural Network Prediction of Beta-turns by Use of Evolutionary Information and Predicted Protein Sequence Features.# Petersen B, Lundegaard C, Petersen TN (2010)# PLoS ONE 5(11):e15079 doi:10.1371/journal.pone.0015079## Column 1: Amino acid# Column 2: Sequence name# Column 3: Amino acid number# Column 4: Prediction for Beta-turn# Column 5: Class assignment - "T" for Beta-turn#V Sequence 1 0.287 .T Sequence 2 0.363 .A Sequence 3 0.403 .S Sequence 4 0.482 .E Sequence 5 0.495 .W Sequence 6 0.493 .G Sequence 7 0.552 TP Sequence 8 0.527 TS Sequence 9 0.564 TA Sequence 10 0.572 TD Sequence 11 0.643 TE Sequence 12 0.631 TD Sequence 13 0.620 TQ Sequence 14 0.612 TR Sequence 15 0.497 .S Sequence 16 0.518 TE Sequence 17 0.515 TM Sequence 18 0.557 TK Sequence 19 0.582 TR Sequence 20 0.555 TG Sequence 21 0.561 TM Sequence 22 0.552 TS Sequence 23 0.559 TR Sequence 24 0.560 TG Sequence 25 0.533 TC Sequence 26 0.486 .L Sequence 32 0.179 . M Sequence 33 0.184 .A Sequence 34 0.210 . T Sequence 35 0.236 . V Sequence 36 0.269 . L Sequence 37 0.319 . T Sequence 38 0.396 . V Sequence 39 0.448 . T Sequence 40 0.475 .G Sequence 41 0.505 T A Sequence 42 0.480 . V Sequence 43 0.449 . P Sequence 44 0.455 . V Sequence 45 0.463 . T Sequence 46 0.456 . R Sequence 47 0.467 . P Sequence 48 0.523 T P Sequence 49 0.504 T R Sequence 50 0.492 .A Sequence 51 0.488 . L Sequence 52 0.526 T P Sequence 53 0.568 T D Sequence 54 0.612 T A Sequence 55 0.650 T R Sequence 56 0.585 T G Sequence 57 0.497 .C Sequence 58 0.452 .H Sequence 59 0.380 .I Sequence 60 0.425 .A Sequence 61 0.452 . Q Sequence 62 0.457 .F Sequence 63 0.558 T K Sequence 64 0.524 T S Sequence 65 0.494 . L Sequence 66 0.482 . S Sequence 67 0.347 . P Sequence 68 0.280 . Q Sequence 69 0.259 .E Sequence 70 0.254 . L Sequence 71 0.181 . Q Sequence 72 0.153 .A Sequence 73 0.152 .F Sequence 74 0.167 . K Sequence 75 0.187 .L Sequence 81 0.362 .E Sequence 82 0.382 .E Sequence 83 0.373 . S Sequence 84 0.401 . L Sequence 85 0.373 . L Sequence 86 0.414 . L Sequence 87 0.555 T K Sequence 88 0.547 T D Sequence 89 0.559 T C Sequence 90 0.576 T R Sequence 91 0.414 .C Sequence 92 0.424 . R Sequence 93 0.443 . S Sequence 94 0.442 . R Sequence 95 0.522 T L Sequence 96 0.531 T F Sequence 97 0.572 T P Sequence 98 0.632 T R Sequence 99 0.596 T T Sequence 100 0.572 T W Sequence 101 0.535 TD Sequence 102 0.394 . L Sequence 103 0.416 . R Sequence 104 0.404 . Q Sequence 105 0.398 . L Sequence 106 0.414 . Q Sequence 107 0.371 . V Sequence 108 0.453 . R Sequence 109 0.475 .E Sequence 110 0.472 . R Sequence 111 0.481 . P Sequence 112 0.371 . V Sequence 113 0.271 .A Sequence 114 0.240 . L Sequence 115 0.188 .E Sequence 116 0.182 .A Sequence 117 0.175 .E Sequence 118 0.164 . L Sequence 119 0.168 .A Sequence 120 0.150 . L Sequence 121 0.141 . T Sequence 122 0.142 . L Sequence 123 0.143 .E Sequence 124 0.151 .A Sequence 130 0.479 .D Sequence 131 0.576 T N Sequence 132 0.572 T D Sequence 133 0.541 T M Sequence 134 0.512 T A Sequence 135 0.329 . L Sequence 136 0.275 .G Sequence 137 0.255 .D Sequence 138 0.253 . V Sequence 139 0.278 . L Sequence 140 0.373 .D Sequence 141 0.400 . R Sequence 142 0.395 . P Sequence 143 0.383 . L Sequence 144 0.308 .H Sequence 145 0.244 . T Sequence 146 0.202 . L Sequence 147 0.173 .H Sequence 148 0.152 .H Sequence 149 0.151 . V Sequence 150 0.149 . L Sequence 151 0.152 . S Sequence 152 0.162 . Q Sequence 153 0.173 . L Sequence 154 0.233 . R Sequence 155 0.280 .A Sequence 156 0.306 .C Sequence 157 0.354 . V Sequence 158 0.366 . Q Sequence 159 0.405 . P Sequence 160 0.406 . Q Sequence 161 0.403 . P Sequence 162 0.466 . T Sequence 163 0.517 T A Sequence 164 0.541 T G Sequence 165 0.588 T P Sequence 166 0.540 T R Sequence 167 0.493 . P Sequence 168 0.503 T W Sequence 169 0.433 .G Sequence 170 0.397 . R Sequence 171 0.341 . L Sequence 172 0.232 .H Sequence 173 0.198 .L Sequence 179 0.253 . Q Sequence 180 0.273 .E Sequence 181 0.290 .A Sequence 182 0.447 . P Sequence 183 0.494 . K Sequence 184 0.517 T K Sequence 185 0.554 T E Sequence 186 0.472 . S Sequence 187 0.628 T S Sequence 188 0.604 T G Sequence 189 0.595 T C Sequence 190 0.593 T L Sequence 191 0.334 .E Sequence 192 0.306 .A Sequence 193 0.286 . S Sequence 194 0.243 . V Sequence 195 0.230 . T Sequence 196 0.194 .F Sequence 197 0.177 . N Sequence 198 0.185 . L Sequence 199 0.180 .F Sequence 200 0.181 . R Sequence 201 0.199 . L Sequence 202 0.191 . L Sequence 203 0.249 . T Sequence 204 0.462 . R Sequence 205 0.469 .D Sequence 206 0.466 . L Sequence 207 0.491 . K Sequence 208 0.304 .C Sequence 209 0.311 . V Sequence 210 0.393 .A Sequence 211 0.467 . S Sequence 212 0.554 T G Sequence 213 0.630 T D Sequence 214 0.634 T L Sequence 215 0.593 T C Sequence 216 0.566 T A Sequence 217 0.554 T P Sequence 218 0.579 T S Sequence 219 0.573 T H Sequence 220 0.577 T L Sequence 221 0.544 T P Sequence 222 0.483 .I Sequence 228 0.362 .D Sequence 229 0.326 .F Sequence 230 0.303 .I Sequence 231 0.312 .Y Sequence 232 0.343 .T Sequence 233 0.420 .S Sequence 234 0.480 .T Sequence 235 0.499 .T Sequence 236 0.491 .C Sequence 237 0.509 TL Sequence 238 0.459 .N Sequence 239 0.472 .L Sequence 240 0.475 .L Sequence 241 0.412 .P Sequence 242 0.594 TP Sequence 243 0.599 TN Sequence 244 0.612 TR Sequence 245 0.650 TY Sequence 246 0.368 .Explain the output. Go back.2)GOR - Garnier et al, 1996NPS@ : GOR4 secondary structure predictionhttps://npsa-prabi.ibcp.fr/cgi-bin/npsa_automat.pl?page=npsa_gor4.html结果:3)NetSurfP-1.1 - Protein secondary structure and surface accessibility server http://www.cbs.dtu.dk/services/NetSurfP/结果:NetSurfP - Protein Surface Accessibility andSecondary Structure PredictionsTechnical University of Denmark# For publication of results, please cite:# A generic method for assignment of reliability scores applied to solvent accessibility predictions.# Bent Petersen, Thomas Nordahl Petersen, Pernille Andersen, Morten Nielsen and Claus Lundegaard# BMC Structural Biology 2009, 9:51 doi:10.1186/1472-6807-9-51## Column 1: Class assignment - B for buried or E for Exposed - Threshold: 25% exposure, but not based on RSA# Column 2: Amino acid# Column 3: Sequence name# Column 4: Amino acid number# Column 5: Relative Surface Accessibility - RSA# Column 6: Absolute Surface Accessibility# Column 7: Z-fit score for RSA prediction# Column 8: Probability for Alpha-Helix# Column 9: Probability for Beta-strand# Column 10: Probability for CoilE A Sequence 3 0.434 47.882 -1.297 0.113 0.087 0.800 E S Sequence 4 0.585 68.527 -0.812 0.113 0.087 0.800 E E Sequence 5 0.613 107.109 0.159 0.113 0.087 0.800 B W Sequence 6 0.249 59.981 -0.639 0.052 0.084 0.864 E G Sequence 7 0.338 26.577 -0.814 0.053 0.043 0.903 E P Sequence 8 0.410 58.207 -1.117 0.053 0.043 0.903 E S Sequence 9 0.584 68.410 -1.020 0.053 0.043 0.903 E A Sequence 10 0.367 40.388 -1.062 0.058 0.017 0.925 E D Sequence 11 0.536 77.238 -0.648 0.053 0.043 0.903 E E Sequence 12 0.644 112.542 -0.710 0.184 0.043 0.773 E D Sequence 13 0.581 83.708 -1.977 0.184 0.043 0.773 E Q Sequence 14 0.508 90.693 -0.589 0.268 0.043 0.689 E R Sequence 15 0.464 106.302 -0.355 0.354 0.048 0.598 E S Sequence 16 0.414 48.533 -1.835 0.354 0.048 0.598 E E Sequence 17 0.592 103.370 -0.492 0.354 0.048 0.598 E M Sequence 18 0.400 80.020 -1.980 0.354 0.048 0.598 E K Sequence 19 0.526 108.198 -0.605 0.278 0.093 0.628 E R Sequence 20 0.472 108.180 -0.949 0.113 0.087 0.800 B G Sequence 21 0.272 21.391 -2.226 0.113 0.087 0.800 B M Sequence 22 0.197 39.440 -0.962 0.118 0.150 0.732 B S Sequence 23 0.281 32.875 -1.279 0.118 0.150 0.732 E R Sequence 24 0.291 66.593 -1.665 0.191 0.086 0.723 B G Sequence 25 0.158 12.458 -1.360 0.268 0.043 0.689 B C Sequence 26 0.026 3.678 -0.098 0.502 0.102 0.396 B M Sequence 27 0.143 28.634 0.257 0.725 0.163 0.112 B A Sequence 28 0.104 11.483 -0.200 0.725 0.163 0.112 B V Sequence 29 0.048 7.454 0.791 0.807 0.137 0.056 B L Sequence 30 0.041 7.507 0.219 0.870 0.077 0.053 B V Sequence 31 0.081 12.465 -0.059 0.886 0.090 0.024 B L Sequence 32 0.067 12.213 0.544 0.870 0.077 0.053 B M Sequence 33 0.073 14.667 0.432 0.870 0.077 0.053 B A Sequence 34 0.072 7.901 -0.058 0.831 0.044 0.125 B T Sequence 35 0.115 16.020 -0.434 0.831 0.044 0.125 B V Sequence 36 0.128 19.735 -0.312 0.831 0.044 0.125 B L Sequence 37 0.130 23.730 0.063 0.751 0.050 0.199 B T Sequence 38 0.266 36.964 -0.231 0.660 0.049 0.291 E V Sequence 39 0.339 52.104 -1.218 0.354 0.048 0.598 E T Sequence 40 0.409 56.770 -2.017 0.184 0.043 0.773 B G Sequence 41 0.313 24.625 -1.553 0.053 0.043 0.903 E A Sequence 42 0.370 40.752 -2.039 0.018 0.088 0.893 B V Sequence 43 0.186 28.542 -0.494 0.020 0.205 0.775 E P Sequence 44 0.337 47.806 -1.325 0.020 0.205 0.775 B V Sequence 45 0.170 26.206 -1.051 0.018 0.088 0.893 E T Sequence 46 0.381 52.803 -1.502 0.018 0.047 0.935 E R Sequence 47 0.526 120.362 -0.292 0.018 0.019 0.964 B P Sequence 48 0.241 34.127 -1.181 0.018 0.019 0.964 E P Sequence 49 0.395 56.079 -1.454 0.018 0.019 0.964E L Sequence 52 0.335 61.265 -0.180 0.018 0.047 0.935 E P Sequence 53 0.340 48.232 -0.691 0.018 0.047 0.935 E D Sequence 54 0.732 105.424 0.275 0.018 0.019 0.964 E A Sequence 55 0.475 52.301 -1.315 0.018 0.019 0.964 E R Sequence 56 0.514 117.660 -0.150 0.018 0.047 0.935 E G Sequence 57 0.466 36.698 -0.497 0.019 0.141 0.840 B C Sequence 58 0.061 8.578 -0.417 0.021 0.279 0.699 E H Sequence 59 0.342 62.283 0.151 0.022 0.359 0.619 B I Sequence 60 0.110 20.368 -0.560 0.022 0.359 0.619 E A Sequence 61 0.325 35.848 -1.172 0.020 0.205 0.775 E Q Sequence 62 0.503 89.872 0.409 0.019 0.141 0.840 BF Sequence 63 0.126 25.348 -0.199 0.018 0.088 0.893 E K Sequence 64 0.564 116.077 0.135 0.018 0.088 0.893 E S Sequence 65 0.482 56.444 -1.479 0.018 0.047 0.935 B L Sequence 66 0.207 37.902 -0.776 0.018 0.019 0.964 E S Sequence 67 0.392 45.966 0.122 0.018 0.019 0.964 E P Sequence 68 0.386 54.802 -1.124 0.858 0.002 0.139 E Q Sequence 69 0.509 90.872 -0.427 0.923 0.002 0.076 B E Sequence 70 0.213 37.159 -0.370 0.923 0.002 0.076 B L Sequence 71 0.196 35.961 0.420 0.970 0.001 0.030 E Q Sequence 72 0.476 84.960 0.319 0.970 0.001 0.030 B A Sequence 73 0.118 13.048 -0.154 0.970 0.001 0.030 B F Sequence 74 0.061 12.263 0.168 0.970 0.001 0.030 E K Sequence 75 0.402 82.630 1.003 0.923 0.002 0.076 E R Sequence 76 0.407 93.249 1.034 0.923 0.002 0.076 B A Sequence 77 0.046 5.047 0.102 0.858 0.002 0.139 E K Sequence 78 0.339 69.732 0.957 0.858 0.002 0.139 E D Sequence 79 0.535 77.122 0.100 0.858 0.002 0.139 B A Sequence 80 0.222 24.497 0.325 0.858 0.002 0.139 B L Sequence 81 0.086 15.783 0.088 0.802 0.014 0.185 E E Sequence 82 0.421 73.479 0.113 0.802 0.014 0.185 E E Sequence 83 0.579 101.064 -0.635 0.717 0.014 0.269 B S Sequence 84 0.234 27.437 -1.170 0.622 0.015 0.363 B L Sequence 85 0.140 25.726 -0.141 0.522 0.016 0.462 B L Sequence 86 0.258 47.203 -0.156 0.455 0.046 0.498 B L Sequence 87 0.251 45.976 -0.887 0.268 0.043 0.689 E K Sequence 88 0.591 121.651 -0.038 0.191 0.086 0.723 E D Sequence 89 0.577 83.160 -0.834 0.052 0.084 0.864 B C Sequence 90 0.214 29.989 0.573 0.056 0.142 0.802 E R Sequence 91 0.462 105.752 0.703 0.066 0.296 0.638 B C Sequence 92 0.092 12.945 -0.868 0.066 0.296 0.638 E R Sequence 93 0.441 100.897 -0.588 0.064 0.216 0.721 E S Sequence 94 0.347 40.668 -1.463 0.019 0.141 0.840 E R Sequence 95 0.456 104.538 -0.134 0.020 0.205 0.775 B L Sequence 96 0.213 39.055 -1.115 0.021 0.279 0.699 B F Sequence 97 0.137 27.576 0.398 0.019 0.141 0.840 E P Sequence 98 0.373 52.957 -0.918 0.018 0.088 0.893B W Sequence 101 0.197 47.354 0.333 0.125 0.227 0.648 E D Sequence 102 0.408 58.850 0.628 0.125 0.227 0.648 B L Sequence 103 0.135 24.664 0.252 0.216 0.235 0.548 E R Sequence 104 0.493 112.989 0.612 0.216 0.235 0.548 E Q Sequence 105 0.460 82.102 0.772 0.321 0.252 0.427 B L Sequence 106 0.109 19.995 0.672 0.216 0.235 0.548 E Q Sequence 107 0.423 75.548 0.333 0.199 0.152 0.649 B V Sequence 108 0.126 19.428 0.026 0.307 0.165 0.527 E R Sequence 109 0.384 88.005 0.285 0.278 0.093 0.628 E E Sequence 110 0.570 99.527 -0.787 0.354 0.048 0.598 B R Sequence 111 0.242 55.487 0.547 0.561 0.047 0.393 B P Sequence 112 0.212 30.111 -0.237 0.717 0.014 0.269 E V Sequence 113 0.264 40.608 0.527 0.831 0.044 0.125 B A Sequence 114 0.129 14.216 -0.416 0.911 0.033 0.057 B L Sequence 115 0.071 13.073 0.588 0.911 0.033 0.057 E E Sequence 116 0.312 54.576 0.365 0.938 0.007 0.055 B A Sequence 117 0.118 12.982 -0.203 0.938 0.007 0.055 B E Sequence 118 0.226 39.395 0.183 0.911 0.033 0.057 B L Sequence 119 0.058 10.638 0.730 0.911 0.033 0.057 E A Sequence 120 0.387 42.614 0.935 0.911 0.033 0.057 B L Sequence 121 0.109 20.013 0.598 0.831 0.044 0.125 B T Sequence 122 0.078 10.846 0.183 0.918 0.063 0.019 B L Sequence 123 0.077 14.117 0.561 0.911 0.033 0.057 E E Sequence 124 0.439 76.623 1.894 0.950 0.028 0.022 B V Sequence 125 0.081 12.388 0.564 0.950 0.028 0.022 B L Sequence 126 0.069 12.579 0.437 0.879 0.010 0.111 E E Sequence 127 0.476 83.210 0.447 0.879 0.010 0.111 E A Sequence 128 0.489 53.833 -0.563 0.622 0.015 0.363 B T Sequence 129 0.204 28.281 -0.526 0.339 0.016 0.645 E A Sequence 130 0.424 46.714 -0.865 0.109 0.005 0.886 E D Sequence 131 0.581 83.664 0.009 0.053 0.005 0.942 E N Sequence 132 0.499 73.112 -1.368 0.053 0.005 0.942 E D Sequence 133 0.550 79.255 -1.082 0.176 0.004 0.820 E M Sequence 134 0.529 105.773 0.296 0.502 0.002 0.495 E A Sequence 135 0.313 34.548 0.985 0.802 0.014 0.185 B L Sequence 136 0.053 9.778 0.183 0.923 0.002 0.076 B G Sequence 137 0.212 16.669 -0.022 0.970 0.001 0.030 E D Sequence 138 0.544 78.390 0.415 0.970 0.001 0.030 B V Sequence 139 0.096 14.755 0.975 0.938 0.007 0.055 B L Sequence 140 0.041 7.489 0.162 0.879 0.010 0.111 E D Sequence 141 0.490 70.609 0.135 0.600 0.003 0.397 E R Sequence 142 0.403 92.241 0.602 0.502 0.002 0.495 B P Sequence 143 0.092 12.984 0.209 0.600 0.003 0.397 B L Sequence 144 0.084 15.325 0.131 0.782 0.003 0.216 E H Sequence 145 0.361 65.630 -0.192 0.923 0.002 0.076 B T Sequence 146 0.132 18.336 -0.058 0.923 0.002 0.076 B L Sequence 147 0.038 6.958 0.485 0.970 0.001 0.030 E H Sequence 148 0.348 63.247 0.498 0.970 0.001 0.030 E H Sequence 149 0.331 60.136 0.839 0.970 0.001 0.030B V Sequence 150 0.041 6.348 0.473 0.970 0.001 0.030 B L Sequence 151 0.173 31.676 0.458 0.970 0.001 0.030 E S Sequence 152 0.550 64.472 0.552 0.970 0.001 0.030 B Q Sequence 153 0.280 49.954 0.494 0.970 0.001 0.030 B L Sequence 154 0.060 11.023 0.197 0.923 0.002 0.076 E R Sequence 155 0.443 101.378 1.090 0.858 0.002 0.139 E A Sequence 156 0.519 57.216 0.794 0.694 0.003 0.303 BC Sequence 157 0.076 10.727 -0.397 0.600 0.003 0.397 B V Sequence 158 0.214 32.846 -0.023 0.430 0.016 0.555 E Q Sequence 159 0.581 103.749 0.558 0.181 0.016 0.803 E P Sequence 160 0.372 52.815 -0.699 0.053 0.043 0.903 E Q Sequence 161 0.518 92.479 -0.120 0.018 0.019 0.964 B P Sequence 162 0.229 32.552 -1.009 0.018 0.019 0.964 E T Sequence 163 0.558 77.381 -0.839 0.018 0.019 0.964 E A Sequence 164 0.573 63.101 -1.965 0.018 0.019 0.964 E G Sequence 165 0.501 39.429 -1.447 0.018 0.019 0.964 E P Sequence 166 0.502 71.234 -1.690 0.018 0.019 0.964 E R Sequence 167 0.404 92.424 -0.216 0.018 0.047 0.935 B P Sequence 168 0.281 39.916 -1.411 0.115 0.016 0.868 E W Sequence 169 0.443 106.638 -0.546 0.339 0.016 0.645 E G Sequence 170 0.290 22.847 -2.131 0.522 0.016 0.462 B R Sequence 171 0.219 50.128 0.487 0.802 0.014 0.185 B L Sequence 172 0.041 7.562 -0.568 0.938 0.007 0.055 E H Sequence 173 0.310 56.334 0.581 0.923 0.002 0.076 E H Sequence 174 0.347 63.156 0.424 0.970 0.001 0.030 B W Sequence 175 0.066 15.753 0.456 0.970 0.001 0.030 B L Sequence 176 0.068 12.414 0.160 0.970 0.001 0.030 E H Sequence 177 0.394 71.760 0.246 0.970 0.001 0.030 E R Sequence 178 0.303 69.364 1.450 0.923 0.002 0.076 B L Sequence 179 0.055 10.052 0.711 0.858 0.002 0.139 E Q Sequence 180 0.443 79.120 0.982 0.782 0.003 0.216 E E Sequence 181 0.620 108.314 1.492 0.600 0.003 0.397 B A Sequence 182 0.100 10.998 -0.174 0.176 0.004 0.820 E P Sequence 183 0.519 73.618 0.665 0.109 0.005 0.886 E K Sequence 184 0.729 149.894 0.904 0.181 0.016 0.803 E K Sequence 185 0.619 127.267 0.262 0.115 0.016 0.868 E E Sequence 186 0.510 89.062 -0.518 0.115 0.016 0.868 E S Sequence 187 0.407 47.689 -0.749 0.115 0.016 0.868 E S Sequence 188 0.454 53.185 -0.258 0.257 0.016 0.727 E G Sequence 189 0.289 22.744 -0.967 0.354 0.048 0.598 B C Sequence 190 0.064 9.014 -0.312 0.502 0.102 0.396 B L Sequence 191 0.115 21.075 -0.202 0.649 0.163 0.188 E E Sequence 192 0.325 56.830 0.201 0.701 0.107 0.192 B A Sequence 193 0.086 9.488 -0.828 0.779 0.100 0.120 B S Sequence 194 0.136 15.927 0.029 0.779 0.100 0.120 B V Sequence 195 0.065 9.914 -0.429 0.779 0.100 0.120 B T Sequence 196 0.085 11.817 -0.319 0.870 0.077 0.053 B F Sequence 197 0.072 14.511 0.097 0.911 0.033 0.057 B N Sequence 198 0.150 21.989 -0.346 0.879 0.010 0.111B L Sequence 199 0.057 10.492 0.062 0.938 0.007 0.055B F Sequence 200 0.081 16.176 0.103 0.938 0.007 0.055E R Sequence 201 0.258 59.013 1.046 0.938 0.007 0.055B L Sequence 202 0.082 14.959 0.208 0.879 0.010 0.111B L Sequence 203 0.067 12.249 0.337 0.879 0.010 0.111B T Sequence 204 0.240 33.343 0.112 0.717 0.014 0.269E R Sequence 205 0.489 112.050 0.481 0.430 0.016 0.555E D Sequence 206 0.433 62.366 -0.416 0.257 0.016 0.727B L Sequence 207 0.084 15.399 0.517 0.191 0.086 0.723E K Sequence 208 0.501 103.159 1.207 0.231 0.330 0.439B C Sequence 209 0.097 13.675 0.387 0.268 0.505 0.227B V Sequence 210 0.137 21.057 0.261 0.268 0.505 0.227B A Sequence 211 0.306 33.699 -0.976 0.135 0.317 0.548E S Sequence 212 0.529 61.987 -0.462 0.056 0.142 0.802E G Sequence 213 0.427 33.636 -1.328 0.018 0.047 0.935E D Sequence 214 0.636 91.705 -1.310 0.018 0.047 0.935B L Sequence 215 0.288 52.660 -0.493 0.052 0.084 0.864B C Sequence 216 0.088 12.327 -0.952 0.056 0.142 0.802E A Sequence 217 0.282 31.032 -0.158 0.052 0.084 0.864E P Sequence 218 0.369 52.304 -0.980 0.053 0.043 0.903E S Sequence 219 0.571 66.909 -1.224 0.053 0.043 0.903E H Sequence 220 0.419 76.125 -1.162 0.053 0.043 0.903B L Sequence 221 0.149 27.264 0.307 0.053 0.043 0.903E P Sequence 222 0.336 47.622 -0.813 0.113 0.043 0.844B A Sequence 223 0.295 32.520 -1.323 0.113 0.087 0.800E T Sequence 224 0.276 38.309 -0.522 0.191 0.086 0.723B H Sequence 225 0.267 48.640 -0.426 0.199 0.152 0.649B H Sequence 226 0.283 51.514 -0.300 0.216 0.235 0.548B A Sequence 227 0.115 12.695 -0.606 0.231 0.330 0.439B I Sequence 228 0.062 11.507 0.198 0.252 0.423 0.325B D Sequence 229 0.222 32.033 -0.360 0.252 0.423 0.325B F Sequence 230 0.088 17.762 0.207 0.273 0.587 0.140B I Sequence 231 0.071 13.154 -0.244 0.273 0.587 0.140B Y Sequence 232 0.153 32.717 0.494 0.268 0.505 0.227B T Sequence 233 0.215 29.793 -0.735 0.252 0.423 0.325B S Sequence 234 0.254 29.804 -1.090 0.216 0.235 0.548B T Sequence 235 0.277 38.475 -0.682 0.307 0.165 0.527B T Sequence 236 0.258 35.785 -0.222 0.199 0.152 0.649B C Sequence 237 0.072 10.067 -0.863 0.216 0.235 0.548B L Sequence 238 0.158 28.875 -0.255 0.216 0.235 0.548E N Sequence 239 0.462 67.564 -0.902 0.216 0.235 0.548B L Sequence 240 0.189 34.661 -0.397 0.113 0.087 0.800B L Sequence 241 0.210 38.451 0.093 0.053 0.043 0.903E P Sequence 242 0.379 53.752 -0.085 0.018 0.019 0.964E P Sequence 243 0.466 66.125 -1.303 0.018 0.019 0.964E N Sequence 244 0.670 98.132 -2.145 0.018 0.047 0.935E R Sequence 245 0.568 130.095 -0.533 0.018 0.019 0.964E Y Sequence 246 0.734 156.941 -1.908 0.003 0.003 0.994Explain the output. Go back.5)PORTERhttp://distill.ucd.ie/porter/结果:Subject: Porter response toQuery_name:Query_length: 248Prediction: VTASEWGPSADEDQRSEMKRGMSRGCMAVLVLMATVLTVTGAVPVTRPPRALPDARGCHICCCCCCCCCCCHHHHHHHHCCCCCCCHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCHAQFKSLSPQELQAFKRAKDALEESLLLKDCRCRSRLFPRTWDLRQLQVRERPVALEAELA HHHCCCCHHHHHHHHHHHHHHHHHHCECCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHHHLTLEVLEATADNDMALGDVLDRPLHTLHHVLSQLRACVQPQPTAGPRPWGRLHHWLHRLQ HHHHHHHHHHHHCHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHHHHHHHHHHHCEAPKKESSGCLEASVTFNLFRLLTRDLKCVASGDLCAXPSHLPATHHAIXDFIYTSTTCL CCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHCCCHHHNLLPPNRYCCCCCCCCPredictions based on PDB templates (seq. similarity up to 58.5%)Query served in 59 secondsMultiple queries to multiple servers at:http://distill.ucd.ie/distill/Access individually Porter, Porter+, PaleAle, BrownAle, X-Stout , XX-Stout, 3Distill at: http://distill.ucd.ie/porter/http://distill.ucd.ie/porter+/http://distill.ucd.ie/paleale/http://distill.ucd.ie/brownale/http://distill.ucd.ie/xstout/http://distill.ucd.ie/xxstout/Prediction of protein disorder by Spritz:http://distill.ucd.ie/spritz/For an explanation of the output formats, refer to:http://distill.ucd.ie/distill/explanation.html#output_formats Please cite one or more of the following:G.Pollastri, A.McLysaght."Porter: a new, accurate server for protein secondary structure prediction". Bioinformatics, 21(8):1719-1720, 2005./cgi/content/abstract/21/8/1719C.Mooney, Y.Wang, G.Pollastri."SCLpred: Protein Subcellular Localization Prediction by N-to-1 Neural Networks", Bioinformatics, 27 (20), 2812-2819, 2011./content/27/20/2812D.Bau, A.J.M.Martin, C.Mooney, A.Vullo, I.Walsh, G.Pollastri. "Distill: Asuite of web servers for the prediction of one-, two- and three-dimensional structural features of proteins" BMC Bioinformatics, 7:402, 2006./1471-2105/7/402/abstractC. Mooney, G.Pollastri "Beyond the Twilight Zone: Automated prediction of structural properties of proteins by recursive neural networks and remote homology information" Proteins, 77(1), 181-90, 2009. /journal/122274852/abstract G.Pollastri, A.J.M.Martin, C.Mooney, A.Vullo. "Accurate prediction of protein secondary structure and solvent accessibility by consensus combiners of sequence and structure information" BMC Bioinformatics, 8:201, 2007. /1471-2105/8/201/abstract I.Walsh,D.Bau, .M.Martin, C. Mooney, A.Vullo, G.Pollastri "Ab initio and template-based prediction of multi-class distance maps by two-dimensional recursive neural networks" BMC Structural Biology, 9:5, 2009. /1472-6807/9/5A.Vullo, I.Walsh, G.Pollastri."A two-stage approach for improved prediction of residue contact maps"BMC Bioinformatics, 7:180, 2006. /1471-2105/7/180/abstractG. Pollastri, A. Vullo, P . Frasconi, P . Baldi."Modular DAG-RNN Architectures for Assembling Coarse Protein Structures".Journal of Computational Biology, 13:3, 631-650, 2006.A. Vullo, O. Bortolami, G. Pollastri, S. Tosatto."Spritz: a server for the prediction of intrinsically disordered regions in protein sequences using kernel machines"Nucleic Acids Research, 34:W164-W168, 2006. 6)TUAT Kuroda Lab's Programb.tuat.ac.jp/dlpsvm.html结果:部分数据Sequence position Prob. by SVM-ALL Prob. by SVM-Long Prob. by SVM-Short Li 1 0 A2 0 T3 0 G4 0 A5 -0.973539 0 0 A6 -1.086915 0 0 A7 -0.891253 0 0 C8 -0.644379 0 0 T9 -0.378074 0 0 A。

生物信息学实验报告**:__ **____ __ _ 学号:___ *********_ ___ 宋晓峰 _指导老师:__ 宋晓峰南京航空航天大学2013年4月实验一实验一 生物信息数据库的检索生物信息数据库的检索生物信息数据库的检索一.实验目的:一.实验目的:1.1.了解生物信息学的各大门户网站以及其中的主要资源。
了解生物信息学的各大门户网站以及其中的主要资源。
了解生物信息学的各大门户网站以及其中的主要资源。
2.2.了解主要数据库的内容及结构,理解各数据库注释的含义。
了解主要数据库的内容及结构,理解各数据库注释的含义。
了解主要数据库的内容及结构,理解各数据库注释的含义。
3.3.以以PubMed 为例,学会文献数据库的基本查询检索方法。
为例,学会文献数据库的基本查询检索方法。
二.实验内容:二.实验内容:(1)国际与国内的生物信息中心)国际与国内的生物信息中心国际NCBI NCBI、、EBI EBI、、ExPASy ExPASy,,EMBL EMBL、、SIB SIB、、TIGR 以及国内CBI CBI、、BioSino 网站的熟悉及内容的了解。
解。
核酸序列数据库:核酸序列数据库:genbank/EMBL-bank/DDBJ genbank/EMBL-bank/DDBJNCBI 网址:网址://EBI 网址:网址://EMBL 网址:网址:/embl /embl蛋白质序列数据库:蛋白质序列数据库:Swiss Prot Swiss Prot 、、ExPASy 网址:网址://Uniprot 网址:网址://蛋白质结构数据库:蛋白质结构数据库:PDB 网址:网址:/pdb//pdb/(2)数据库内容、结构与注释的浏览)数据库内容、结构与注释的浏览分别读取The spike protein of SARS-Corona Virus 在NCBI 中的核酸序列、SWISS-PROT 蛋白质序列以及PDB 蛋白质结构序列,熟悉数据库记录的结构,学会看懂其中的注释。

生物信息学中的蛋白质序列分析随着生物技术的不断发展,人们对于生物体内各种蛋白质的研究愈发深入。
而蛋白质序列分析则是生物信息学中重要的一环,可以用于蛋白质结构预测、功能分析、进化研究等方面。
在这篇文章中,我们将探讨蛋白质序列分析在生物信息学中的应用以及涉及到的技术和算法。
一、蛋白质序列的组成蛋白质由氨基酸组成,而蛋白质序列指的是氨基酸连接的线性序列。
氨基酸是构成蛋白质的基本单元,不同的氨基酸组合构成不同的蛋白质。
目前已知的氨基酸有20种,它们由不同的侧链和碳氮骨架组成,这种多样性导致了蛋白质具有丰富多样的结构和功能。
二、蛋白质序列分析的应用1、预测蛋白质结构蛋白质结构与其功能息息相关,因此对于蛋白质结构的预测一直是研究的热点问题。
蛋白质序列是进行蛋白质结构预测的重要依据之一。
一般来说,蛋白质结构预测可分为二级结构和三级结构预测。
二级结构指的是蛋白质中α-螺旋、β-折叠和无规则卷曲等局部的结构。
目前,常用的二级结构预测方法有Chou-Fasman算法、GOR算法等。
而三级结构预测指的是蛋白质整体的三维结构,其预测难度更大,目前还没有完全解决。
但是,针对蛋白质结构的许多研究都是基于蛋白质序列的分析和预测。
2、鉴定蛋白质功能蛋白质的功能与其序列和结构有关,因此通过分析蛋白质序列也可以预测蛋白质的功能。
一般来说,蛋白质的功能可以分为三类:催化、结构和调节。
催化作用指的是酶类蛋白质对化学反应的促进作用。
结构作用指的是蛋白质形成结构,对于细胞和组织的形态和机能具有重要作用。
调节作用指的是蛋白质对细胞、胚胎、发育和免疫系统等的调节作用。
对于蛋白质功能的鉴定,目前的方法主要有以下几种:1)基于序列的比对方法;2)结构基因学方法;3)基于基因组的方法。
三、蛋白质序列分析的技术和算法1、BLAST算法BLAST(Basic Local Alignment Search Tool)算法是常用的序列比对算法之一,它通过比对两条序列后,计算两个序列之间的相似性得分。

(三)蛋白质序列分析实验目的:掌握蛋白质序列检索的操作方法,熟悉蛋白质基本性质分析,了解蛋白质结构分析和预测。
实验内容:1、检索SOX-21蛋白质序列,利用ProParam工具进行蛋白质的氨基酸组成、分子质量、等电点、氨基酸组成、原子总数及疏水性(ProtScale工具)等理化性质的分析。
2、利用PredictProtein、PROF、HNN等软件预测分析蛋白质的二级结构;利用Scan Prosite软件对蛋白质进行结构域分析。
3、利用TMHMM、TMPRED、SOSUI等工具对蛋白质进行跨膜分析;采用PredictNLS进行核定位信号分析;利用PSORT进行蛋白质的亚细胞定位预测;利用CBS(http://www.cbs.dtu.dk/services/ProtFun/)网站工具预测蛋白的功能,将序列用Blocks、SMART、InterProScan、PFSCAN等搜索其保守序列的特征,进行motif 的结构分析。
4、利用Swiss-Model数据库软件预测该蛋白的三级结构,结果用蛋白质三维图象软件Jmol查看。
CPHmodels 也是利用神经网络进行同源模建预测蛋白质结构的方法和网络服务器I-TASSER预测所选蛋白质的空间结构。
5、分析蛋白质的翻译后修饰:分析信号肽及其剪切位点: SignalIP http://www.cbs.dtu.dk/services/SignalP/;分析糖链连接点:分析O-连接糖蛋白, NetOGlyc,http://www.cbs.dtu.dk/services/NetOGlyc/;分析N-连接糖蛋白,NetNGlyc,http://www.cbs.dtu.dk/services/NetNGlyc/。
6、利用检索的序列,进行同源比对,获得并分析比对结果。
实验步骤(一)1、在NCBI 蛋白质数据库中查找SOX-21蛋白质序列分别选择爪蟾(Xenopus laevis)、小家鼠[Mus musculus]、猕猴[Macaca mulatt a]的SOX-21蛋白质序列,并保存其FASTA格式。

生物信息学实验报告姓名:__ 王思____ __ _学号:___03_ ___指导老师:__ 宋晓峰_南京航空航天大学2013年4月ﻬ实验一生物信息数据库的检索一.实验目的:1.了解生物信息学的各大门户网站以及其中的主要资源。
2。
了解主要数据库的内容及结构,理解各数据库注释的含义。
3.以PubMed为例,学会文献数据库的基本查询检索方法。
二.实验内容:(1)国际与国内的生物信息中心国际NCBI、EBI、ExPASy,EMBL、SIB、TIGR以及国内CBI、BioSino网站的熟悉及内容的了解.核酸序列数据库:genbank/EMBL-bank/DDBJNCBI网址:EBI网址:EMBL网址:i。
ac.uk/embl蛋白质序列数据库:Swiss Prot 、ExPASy网址:Uniprot网址:蛋白质结构数据库:PDB网址:csb。
org/pdb/(2)数据库内容、结构与注释的浏览分别读取The spike proteinof SARS—Corona Virus在NCBI中的核酸序列、SWISS—PROT蛋白质序列以及PDB蛋白质结构序列,熟悉数据库记录的结构,学会看懂其中的注释。
核酸序列:SWISS-PROT蛋白质序列:PDB蛋白质结构序列:其PDB文件见附件SARS—Corona Virus。
PDB文件分别读取Heamagglutinin Genes ofH9N2 Subtype Influenza A V iruses(禽流感H9N2亚型HA基因)在NCBI中的核酸序列、SWISS-PROT蛋白质序列以及PDB蛋白质结构序列,熟悉数据库记录的结构,学会看懂其中的注释。
核酸序列:SWISS-PROT蛋白质序列PDB蛋白质结构序列其PDB文件见附件H9N2.PDB文件(3)文献信息的查找与管理有效地使用NCBI PubMed提供的各种主要功能,查询并下载相关课题或研究方向的论文文摘与文献全文。
生物信息学实验报告班级::学号:日期:实验一核酸和蛋白质序列数据的使用实验目的了解常用的序列数据库,掌握基本的序列数据信息的查询方法。
教学基本要求了解和熟悉NCBI 核酸和蛋白质序列数据库,可以使用BLAST进行序列搜索,解读BLAST 搜索结果,可以利用PHI-BLAST 等工具进行蛋白质序列的结构域搜索,解读蛋白质序列信息,可以在蛋白质三维数据库中查询相关结构信息并进行显示。
实验容提要在序列数据库中查找某条基因序列(BRCA1),通过相关一系列数据库的搜索、比对与结果解释,回答以下问题:1. 该基因的基本功能?2. 编码的蛋白质序列是怎样的?3. 该蛋白质有没有保守的功能结构域 (NCBI CD-search)?4. 该蛋白质的功能是怎样的?5. 该蛋白质的三级结构是什么?如果没有的话,和它最相似的同源物的结构是什么样子的?给出示意图。
实验结果及结论1. 该基因的基本功能?This gene encodes a nuclear phosphoprotein that plays a role in maintaining genomic stability, and it also acts as a tumor suppressor. The encoded protein combines with other tumor suppressors, DNA damagesensors, and signal transducers to form a large multi-subunit protein complex known as the BRCA1-associated genome surveillance complex (BASC). This gene product associates with RNA polymerase II, and through the C-terminal domain, also interacts with histone deacetylase complexes. This protein thus plays a role in transcription, DNA repair of double-stranded breaks, and recombination. Mutations in this gene are responsible for approximately 40% of inherited breast cancers and more than 80% of inherited breast and ovarian cancers. Alternative splicing plays a role in modulating the subcellular localization and physiological function of this gene. Many alternatively spliced transcript variants, some of which are disease-associated mutations, have been described for this gene, but the full-length natures of only some of these variants has been described. A related pseudogene, which is also located on chromosome 17, has been identified. [provided by RefSeq, May 2009]2. 编码的蛋白质序列是怎样的?[Homo sapiens]1 mdlsalrvee vqnvinamqk ilecpiclel ikepvstkcd hifckfcmlk llnqkkgpsq61 cplcknditk rslqestrfs qlveellkii cafqldtgle yansynfakk ennspehlkd121 evsiiqsmgy rnrakrllqs epenpslqet slsvqlsnlg tvrtlrtkqr iqpqktsvyi181 elgsdssedt vnkatycsvg dqellqitpq gtrdeislds akkaacefse tdvtntehhq241 psnndlntte kraaerhpek yqgssvsnlh vepcgtntha sslqhenssl lltkdrmnve301 kaefcnkskq pglarsqhnr wagsketcnd rrtpstekkv dlnadplcer kewnkqklpc361 senprdtedv pwitlnssiq kvnewfsrsd ellgsddshd gesesnakva dvldvlnevd421 eysgssekid llasdpheal ickservhsk svesniedki fgktyrkkas lpnlshvten481 liigafvtep qiiqerpltn klkrkrrpts glhpedfikk adlavqktpe minqgtnqte541 qngqvmnitn sghenktkgd siqneknpnp ieslekesaf ktkaepisss isnmelelni601 hnskapkknr lrrksstrhi halelvvsrn lsppnctelq idscssseei kkkkynqmpv661 rhsrnlqlme gkepatgakk snkpneqtsk rhdsdtfpel kltnapgsft kcsntselke721 fvnpslpree keekletvkv snnaedpkdl mlsgervlqt ersvesssis lvpgtdygtq781 esisllevst lgkaktepnk cvsqcaafen pkglihgcsk dnrndtegfk yplghevnhs 841 retsiemees eldaqylqnt fkvskrqsfa pfsnpgnaee ecatfsahsg slkkqspkvt 901 feceqkeenq gknesnikpv qtvnitagfp vvgqkdkpvd nakcsikggs rfclssqfrg 961 netglitpnk hgllqnpyri pplfpiksfv ktkckknlle enfeehsmsp eremgnenip 1021 stvstisrnn irenvfkeas ssninevgss tnevgssine igssdeniqa elgrnrgpkl 1081 namlrlgvlq pevykqslpg snckhpeikk qeyeevvqtv ntdfspylis dnleqpmgss 1141 hasqvcsetp ddllddgeik edtsfaendi kessavfsks vqkgelsrsp spfththlaq 1201 gyrrgakkle sseenlssed eelpcfqhll fgkvnnipsq strhstvate clsknteenl 1261 lslknslndc snqvilakas qehhlseetk csaslfssqc seledltant ntqdpfligs 1321 skqmrhqses qgvglsdkel vsddeergtg leennqeeqs mdsnlgeaas gcesetsvse 1381 dcsglssqsd ilttqqrdtm qhnliklqqe maeleavleq hgsqpsnsyp siisdssale 1441 dlrnpeqsts ekavltsqks seypisqnpe glsadkfevs adsstsknke pgversspsk 1501 cpslddrwym hscsgslqnr nypsqeelik vvdveeqqle esgphdltet sylprqdleg 1561 tpylesgisl fsddpesdps edrapesarv gnipsstsal kvpqlkvaes aqspaaahtt 1621 dtagynamee svsrekpelt astervnkrm smvvsgltpe efmlvykfar khhitltnli 1681 teetthvvmk tdaefvcert lkyflgiagg kwvvsyfwvt qsikerkmln ehdfevrgdv 1741 vngrnhqgpk raresqdrki frgleiccyg pftnmptdql ewmvqlcgas vvkelssftl 1801 gtgvhpivvv qpdawtedng fhaigqmcea pvvtrewvld svalyqcqel dtylipqiph 1861 shy3. 该蛋白质有没有保守的功能结构域 (NCBI CD-search)?有保守的供能结构域。
生物信息学在蛋白质序列分析中的应用随着生物技术的发展和进步,生物信息学日益受到越来越多的关注和重视。
生物信息学是生物学和计算机科学的交叉学科,是利用计算机技术和信息学方法研究生物学问题的一种新兴学科。
在现代生物学中,生物信息学已经成为一种不可或缺的工具和手段。
而在蛋白质序列分析中,生物信息学的应用更是无处不在。
蛋白质是生命体内最为重要的生物大分子之一,它们在细胞内扮演着极其重要的角色。
在生物学中,蛋白质序列分析是一项非常重要的研究内容。
通过对蛋白质的序列分析,可以揭示蛋白质的结构、功能以及代谢途径等方面的信息。
而生物信息学则为蛋白质序列分析提供了强大的工具和技术支持。
那么,生物信息学在蛋白质序列分析中的具体应用是什么呢?首先,生物信息学可以帮助我们进行蛋白质序列比对。
蛋白质序列比对是指将两个或更多的蛋白质序列进行比较,寻找相同或相似的部分。
通过蛋白质序列比对,我们可以分析出不同物种之间的蛋白质序列差异,从而了解不同物种的遗传关系和进化程度。
同时,在分析新的蛋白质序列时,也可以利用已知的蛋白质序列进行比对,从而推断其可能的结构和功能。
而生物信息学中的序列比对算法和软件工具,如BLAST、ClustalX等则可以帮助我们实现蛋白质序列比对的自动化,大大提高了效率和准确性。
其次,生物信息学也可以帮助我们预测蛋白质的结构和功能。
蛋白质的结构和功能是相互联系的,一个蛋白质的结构通常预示着其功能。
因此,通过预测蛋白质结构和功能,我们可以更好的了解蛋白质的性质和功能,同时也有助于药物研发和治疗疾病。
而在生物信息学中,蛋白质结构预测算法和软件工具如SWISS-MODEL、Rosetta等,以及蛋白质功能预测算法和软件工具如InterProScan、STRING等已经得到了广泛的应用和推广。
通过这些工具,我们可以更加轻松地进行蛋白质结构和功能预测,提高了研究的效率和准确性。
此外,生物信息学还可以帮助我们进行蛋白质序列分析的高级应用。
生物信息学实验教程实验一、基因、蛋白质序列分析【实验目的】1、掌握基因、蛋白质序列检索的操作方法;2、熟悉蛋白质基本性质分析及其电子表达谱3、蛋白基因的引物设计【实验内容】1、使用Entrez或SRS信息查询系统检索人脂联素(adiponectin)蛋白质序列;2、使用网站对上述蛋白质序列进行分子质量、氨基酸组成、和疏水性等基本性质分析;3、蛋白基因的引物设计【实验方法】1、人脂联素基因、蛋白质序列的检索:(1)调用Internet浏览器并在其地址栏输入Entrez网址(/Entrez);(2)在Search后的选择栏中选择nucleartide\protein;(3)在输入栏输入homo sapiens adiponectin;(4)点击go后显示序列接受号及序列名称;(5)点击序列接受号NP_004788 (adiponectin precursor; adipose most abundant genetranscript 1 [Homo sapiens])后显示序列详细信息;(6)将序列转为FASTA格式保存(参考上述步骤使用SRS信息查询系统检索人脂联素蛋白质序列);(7)进入UNIGENE数据库分析其电子表达谱2、进入网站对人脂联素蛋白质序列进行分子质量、氨基酸组成和疏水性等基本性质分析:3、利用prime prime5.0设计此基因PCR引物4、独立完成NYGGF4、LYRM1两个基因的上述操作。
【作业】1、提交使用上述软件对人脂联素、NYGGF4、LYRM1蛋白质序列进行基本性质分析及其电子表达谱蛋白质实验二、序列结构预测【实验目的】1、熟悉基于序列同源性分析的蛋白质功能预测,了解基于motif、结构位点、结构功能域数据库的蛋白质功能预测;2、了解蛋白质结构预测。
【实验内容】1、对人脂联素蛋白质序列进行基于NCBI/Blast软件的蛋白质同源性分析;2、对人脂联素蛋白质序列进行motif结构分析;3、对人脂联素蛋白质序列进行二级结构和三维结构预测。
生物信息学实验报告姓名:__**_______学号:___*********____指导老师:___***____南京航空航天大学2011年11月实验一生物信息数据库的检索一.实验目的:1.了解生物信息学的各大门户网站以及其中的主要资源。
2.了解主要数据库的内容及结构,理解各数据库注释的含义。
3.以PubMed为例,学会文献数据库的基本查询检索方法。
二.实验内容:(1)国际与国内的生物信息中心国际NCBI、EBI、ExPASy,EMBL、SIB、TIGR以及国内CBI、BioSino网站的熟悉及内容的了解。
核酸序列数据库:genbank/EMBL-bank/DDBJNCBI网址:/EBI网址:/EMBL网址:/embl蛋白质序列数据库:Swiss Prot 、ExPASy网址:/Uniprot网址:/蛋白质结构数据库:PDB网址:/pdb/(2)检索练习:The spike protein of SARS-Corona Virus在NCBI中的核酸记录序列:LOCUS CS244439 3897 bp DNA linear PAT 17-JUL-2006DEFINITION Sequence 3 from Patent WO2005118813.ACCESSION CS244439VERSION CS244439.1 GI:84659113KEYWORDS .SOURCE SARS coronavirusORGANISM SARS coronavirusViruses; ssRNA positive-strand viruses, no DNA stage; Nidovirales;Coronaviridae; Coronavirinae; Betacoronavirus.REFERENCE 1AUTHORS Altmeyer,R., Nal-Rogier,B., Chan,C., Kien,F., Kam,Y.W., Siu,Y.L.,Tse,K.S., Staropoli,I. and Manuguerra,J.C.TITLE Nucleic acids, polypeptides, methods of expression, and immunogeniccompositions associated with sars corona virus spike proteinJOURNAL Patent: WO 2005118813-A2 3 15-DEC-2005;INSTITUT PASTEUR (FR); Hong Kong Pasteur Research Centre Limited(CN)FEATURES Location/Qualifierssource 1..3897/organism="SARS coronavirus"/mol_type="unassigned DNA"/db_xref="taxon:227859"CDS 44..3847/note="unnamed protein product"/codon_start=1/protein_id="CAJ56183.1"/db_xref="GI:84659114"/translation="MFIFLLFLTLTSGSDLDRCTTFDDVQAPNYTQHTSSMRGVYYPDEIFRSD TLYLTQDLFLPFYSNVTGFHTINHTFGNPVIPFKDGIYFAATEKSNVVRGWVFGSTMN NKSQSVIIINNSTNVVIRACNFELCDNPFFA VSKPMGTQTHTMIFDNAFNCTFEYISDA FSLDVSEKSGNFKHLREFVFKNKDGFL YVYKGYQPIDVVRDLPSGFNTLKPIFKLPLG INITNFRAILTAFSPAQDIWGTSAAAYFVGYLKPTTFMLKYDENGTITDA VDCSQNPLA ELKCSVKSFEIDKGIYQTSNFRVVPSGDVVRFPNITNLCPFGEVFNATKFPSVY AWERK KISNCVADYSVL YNSTFFSTFKCYGVSATKLNDLCFSNVYADSFVVKGDDVRQIAPG QTGVIADYNYKLPDDFMGCVLAWNTRNIDA TSTGNYNYKYRYLRHGKLRPFERDIS NVPFSPDGKPCTPPALNCYWPLNDYGFYTTTGIGYQPYRVVVLSFELLNAPATVCGP KLSTDLIKNQCVNFNFNGLTGTGVLTPSSKRFQPFQQFGRDVSDFTDSVRDPKTSEIL DISPCSFGGVSVITPGTNASSEV A VL YQDVNCTDVSTAIHADQLTPAWRIYSTGNNVFQ TQAGCLIGAEHVDTSYECDIPIGAGICASYHTVSLLRSTSQKSIV AYTMSLGADSSIAY SNNTIAIPTNFSISITTEVMPVSMAKTSVDCNMYICGDSTECANLLLQYGSFCTQLNR ALSGIAAEQDRNTREVFAQVKQMYKTPTLKYFGGFNFSQILPDPLKPTKRSFIEDLLF NKVTLADAGFMKQYGECLGDINARDLICAQKFNGLTVLPPLLTDDMIAAYTAALVSG TA TAGWTFGAGAALQIPFAMQMAYRFNGIGVTQNVL YENQKQIANQFNKAISQIQES LTTTSTALGKLQDVVNQNAQALNTLVKQLSSNFGAISSVLNDILSRLDKVEAEVQIDR LITGRLQSLQTYVTQQLIRAAEIRASANLAATKMSECVLGQSKRVDFCGKGYHLMSF PQAAPHGVVFLHVTYVPSQERNFTTAPAICHEGKAYFPREGVFVFNGTSWFITQRNFF SPQIITTDNTFVSGNCDVVIGIINNTVYDPLQPELDSFKEELDKYFKNHTSPDVDLGDI SGINASVVNIQKEIDRLNEV AKNLNESLIDLQELGKYEQYIKWPWYVWLGFIAGLIAI VMVTILLCCMTSCCSCLKGACSCGSCCKFDEDDSEPVLKGVKLHYTGPGGDYKDDD DK"ORIGIN1 ctatagggcg aattgggtac cgctagcgga tccgcgcgcc accatgttta ttttcctgct61 gtttctgact ctgaccagcg gcagtgacct ggaccggtgc accacttttg atgatgtgca121 ggctcctaat tacactcagc atacttcctc tatgaggggc gtgtactatc ctgatgaaat181 ttttagatcc gacactctgt atctgactca ggatctgttt ctgccattct attctaatgt241 gacaggcttt catactatta atcatacctt tggcaaccct gtgatccctt ttaaggatgg301 catctatttt gctgccacag agaagtccaa tgtggtgcgg ggatgggtgt tcggctctac361 catgaacaac aagtcccagt ccgtgattat tattaacaat tctactaatg tggtgatccg421 agcctgtaac tttgaactgt gtgacaaccc attctttgct gtgtctaagc ccatgggcac481 acagacacat actatgatct tcgataatgc ctttaattgc actttcgagt acatctctga541 tgccttttcc ctggatgtgt ccgaaaagtc cggcaacttt aagcacctgc gagagtttgt601 gtttaagaat aaggatggct ttctgtatgt gtataagggc tatcagccta tcgacgtggt661 gcgcgatctg ccttctggct ttaacactct gaagcctatt tttaagctgc ctctgggcat721 taacattaca aattttcggg ccattctgac agcctttagc cctgctcagg acatttgggg 781 cacctctgct gccgcctatt ttgtgggcta tctgaagcca actaccttta tgctgaagta 841 tgatgaaaat ggcacaatca cagatgctgt ggattgttct cagaatccac tggctgaact 901 gaagtgctct gtgaagagct ttgagattga caagggaatc taccagacct ctaatttccg 961 cgtggtgccc tctggagatg tggtgagatt ccctaatatt acaaacctgt gtccttttgg 1021 agaagtgttt aatgctacta agttcccttc tgtgtatgcc tgggagagaa agaagatttc 1081 taattgtgtg gctgattact ctgtgctgta caactccaca ttttttagca cctttaagtg1141 ctatggcgtg tctgccacta agctgaatga tctgtgcttc tccaatgtgt atgccgattc 1201 ttttgtggtg aagggagatg atgtgagaca gatcgcccca ggacagactg gcgtgattgc 1261 tgattacaat tataagctgc cagatgattt catgggctgt gtgctggctt ggaatactag 1321 gaacattgat gctacttcca ctggcaatta taattacaag tatcggtatc tgagacatgg 1381 caagctgagg ccctttgaga gagacatctc taacgtgcct ttcagccctg atggcaagcc 1441 ttgcacccca cctgctctga attgttattg gccactgaat gattatggct tttacaccac 1501 tactggcatt ggctaccagc cttacagagt ggtggtgctg tcttttgaac tgctgaatgc 1561 ccctgccaca gtgtgtggac caaagctgtc cactgacctg attaagaacc agtgtgtgaa 1621 ctttaacttt aatggactga ctggcactgg cgtgctgact ccttctagca agagatttca 1681 gccatttcag cagtttggcc gggatgtgtc tgatttcact gattccgtgc gagatcctaa 1741 gacatctgaa atcctggaca tttccccttg ctcttttggc ggcgtgagcg tgattacacc 1801 tggaacaaat gcttcctctg aagtggctgt gctgtatcag gatgtgaact gcactgatgt 1861 gtctacagcc atccatgccg atcagctgac accagcttgg cgcatctatt ctactggaaa 1921 caatgtgttc cagactcagg ccggctgtct gatcggagct gagcatgtgg acacttctta 1981 tgagtgcgac attcctattg gagctggcat ttgtgctagt taccatacag tgtctctgct 2041 gcggagtact agccagaagt ctattgtggc ttatactatg tctctgggcg ctgatagttc 2101 cattgcttac tctaataaca ccattgctat ccctactaac ttttccatta gcattactac2161 agaagtgatg cctgtgtcta tggctaagac ctccgtggat tgtaatatgt acatctgcgg 2221 agattctacc gaatgtgcta atctgctgct gcagtatggc agcttttgca cacagctgaa 2281 tcgggctctg tctggcattg ctgctgaaca ggatcgcaac acacgggaag tgttcgctca 2341 agtgaagcag atgtataaga ccccaactct gaagtatttt ggcggcttta atttttccca 2401 gatcctgcct gaccctctga agcccactaa gcggtctttt attgaggacc tgctgtttaa 2461 caaagtgaca ctggctgatg ctggctttat gaagcagtat ggcgaatgcc tgggcgatat 2521 taatgctaga gatctgattt gtgcccagaa gttcaatggc ctgacagtgc tgcctcctct 2581 gctgactgat gatatgattg ctgcctacac tgctgctctg gtgtctggca ctgccactgc 2641 tggatggaca tttggcgctg gcgctgctct gcagatccct tttgctatgc agatggccta 2701 tcggttcaat ggcattggag tgacccagaa tgtgctgtat gagaaccaga agcagattgc 2761 caaccagttt aacaaggcca ttagtcagat tcaggaatcc ctgacaacaa catccactgc 2821 cctgggcaag ctgcaggacg tggtgaacca gaatgctcag gccctgaaca cactggtgaa 2881 gcagctgagc agcaattttg gcgccatttc cagtgtgctg aatgatatcc tgtcccgact 2941 ggataaagtg gaggccgaag tgcagattga caggctgatt acaggcagac tgcagagcct 3001 gcagacctat gtgacacagc agctgatcag ggctgctgaa atcagggctt ctgccaatct 3061 ggctgctact aagatgtctg agtgtgtgct gggacagtcc aagagagtgg acttttgtgg 3121 aaagggctac cacctgatgt ccttcccaca ggctgcccct catggagtgg tgttcctgca 3181 tgtgacctat gtgccatccc aggagaggaa cttcaccaca gccccagcca tttgtcatga 3241 aggcaaggcc tacttccctc gggaaggcgt gttcgtgttt aatggcactt cttggtttat 3301 tacacagcgg aacttcttta gcccacagat catcactaca gacaatacat ttgtgtccgg3361 aaattgtgat gtggtgattg gcatcattaa caacacagtg tatgatcctc tgcagcctga3421 gctggactcc ttcaaggaag agctggacaa gtacttcaag aatcatacat ccccagatgt3481 ggatctgggc gacatttccg gcattaacgc ttctgtggtg aacattcaga aggaaattga3541 ccgcctgaat gaagtggcta agaatctgaa tgaatccctg attgacctgc aggaactggg3601 caagtatgag cagtatatta agtggccttg gtatgtgtgg ctgggcttca ttgctggact3661 gattgccatc gtgatggtga caatcctgct gtgttgcatg acctcctgtt gcagttgcct3721 gaagggcgct tgctcttgtg gatcttgctg caagtttgat gaggatgact ctgagccagt3781 gctgaagggc gtgaagctgc attacacagg gcccggcggc gactacaagg acgatgacga3841 caagtgatag atcgatgcat ggatccgttt aaaccgagct ccagctttgt tcccttaThe spike protein of SARS-Corona Virus在SWISS-PROT蛋白质序列:The spike protein of SARS-Corona Virus在PDB蛋白质结构序列:(3)文献信息的查找与管理有效地使用NCBI PubMed提供的各种主要功能,查询并下载相关课题或研究方向的论文文摘与文献全文。
实习报告一、实习背景及目的蛋白质组分析是生物科学研究中的重要手段,通过对蛋白质组的深入研究,可以揭示生物体的生理功能、疾病发生机制以及药物研发等关键信息。
本次实习旨在了解蛋白质组分析的基本原理和方法,掌握相关实验技能,提高自己的科研能力。
二、实习内容及过程1. 实习内容本次实习主要涉及以下内容:(1) 蛋白质样品制备:包括细胞裂解、蛋白质提取、蛋白质沉淀等步骤。
(2) 蛋白质分离:利用色谱技术对蛋白质进行分离,如凝胶过滤色谱、离子交换色谱等。
(3) 蛋白质鉴定:采用质谱技术对分离后的蛋白质进行鉴定,如串联质谱、飞行时间质谱等。
(4) 数据处理与分析:利用生物信息学工具对质谱数据进行处理,识别蛋白质序列,分析蛋白质表达水平等。
2. 实习过程(1) 蛋白质样品制备:在实验室老师的指导下,学会了细胞裂解、蛋白质提取和蛋白质沉淀等基本操作。
(2) 蛋白质分离:通过学习,掌握了凝胶过滤色谱、离子交换色谱等蛋白质分离技术,并能够独立操作。
(3) 蛋白质鉴定:在老师的帮助下,学会了串联质谱、飞行时间质谱等蛋白质鉴定技术,并参与实际操作。
(4) 数据处理与分析:学习了生物信息学工具的使用,如Mascot、PeptideShaker 等,能够独立进行质谱数据处理与分析。
三、实习收获及体会通过本次实习,我对蛋白质组分析有了更深入的了解,掌握了相关实验技能,并取得了以下收获:(1) 理论知识:学习了蛋白质组分析的基本原理,如蛋白质样品制备、分离、鉴定等步骤。
(2) 实验技能:掌握了蛋白质样品制备、分离、鉴定等实验操作,能够独立进行实验。
(3) 数据处理与分析:学会了生物信息学工具的使用,能够独立进行质谱数据处理与分析。
同时,我也认识到蛋白质组分析实验需要严谨的实验态度和良好的团队合作精神,这对于我今后的科研工作具有重要的指导意义。
四、实习总结通过本次实习,我对蛋白质组分析的基本原理、实验操作和数据处理有了更深入的了解,收获颇丰。
(三)蛋白质序列分析
实验目的:掌握蛋白质序列检索的操作方法,熟悉蛋白质基本性质分析,了解蛋白质结构分析和预测。
实验内容:
1、检索SOX-21蛋白质序列,利用ProParam工具进行蛋白质的氨基酸组成、分子质量、等电点、氨基酸组成、原子总数及疏水性(ProtScale工具)等理化性质的分析。
2、利用PredictProtein、PROF、HNN等软件预测分析蛋白质的二级结构;利用Scan Prosite软件对蛋白质进行结构域分析。
3、利用TMHMM、TMPRED、SOSUI等工具对蛋白质进行跨膜分析;采用PredictNLS进行核定位信号分析;利用PSORT进行蛋白质的亚细胞定位预测;利用CBS(http://www.cbs.dtu.dk/services/ProtFun/)网站工具预测蛋白的功能,将序列用Blocks、SMART、InterProScan、PFSCAN等搜索其保守序列的特征,进行motif 的结构分析。
4、利用Swiss-Model数据库软件预测该蛋白的三级结构,结果用蛋白质三维图象软件Jmol查看。
CPHmodels 也是利用神经网络进行同源模建预测蛋白质结构的方法和网络服务器I-TASSER预测所选蛋白质的空间结构。
5、分析蛋白质的翻译后修饰:分析信号肽及其剪切位点: SignalIP http://www.cbs.dtu.dk/services/SignalP/;分析糖链连接点:分析O-连接糖蛋白, NetOGlyc,http://www.cbs.dtu.dk/services/NetOGlyc/;分析N-连接糖蛋白,NetNGlyc,http://www.cbs.dtu.dk/services/NetNGlyc/。
6、利用检索的序列,进行同源比对,获得并分析比对结果。
实验步骤
(一)
1、在NCBI 蛋白质数据库中查找SOX-21蛋白质序列分别选择爪蟾(Xenopus laevis)、小家鼠[Mus musculus]、猕猴[Macaca mulatt a]的SOX-21蛋白质序列,并保存其FASTA格式。
2、利用ProParam工具对SOX-21蛋白质序列进行理化性质的分子。
3、利用PredictProtein、PROF、HNN等软件预测分析蛋白质的二级结构;利用Scan Prosite软件对蛋白质进行结构域分析。
4、利用TMHMM、TMPRED、SOSUI等工具对蛋白质进行跨膜分析;采用
PredictNLS进行核定位信号分析;利用PSORT进行蛋白质的亚细胞定位预测;利用CBS(http://www.cbs.dtu.dk/services/ProtFun/)网站工具预测蛋白的功能,将序列用Blocks、SMART、InterProScan、PFSCAN等搜索其保守序列的特征,进行motif 的结构分析。
5、利用Swiss-Model数据库软件预测该蛋白的三级结构,结果用蛋白质三维图象软件Jmol查看。
CPHmodels 也是利用神经网络进行同源模建预测蛋白质结构的方法和网络服务器I-TASSER预测所选蛋白质的空间结构。
6、分析蛋白质的翻译后修饰:分析信号肽及其剪切位点: SignalIP http://www.cbs.dtu.dk/services/SignalP/;分析糖链连接点:分析O-连接糖蛋白, NetOGlyc,http://www.cbs.dtu.dk/services/NetOGlyc/;分析N-连接糖蛋白,NetNGlyc,http://www.cbs.dtu.dk/services/NetNGlyc/。
7、利用检索的序列,进行同源比对,获得并分析比对结果。
实验结果
1、>gi|288557317|ref|NP_001165684.1| transcription factor Sox-21 [Xenopus laevis] MSKPLDHVKRPMNAFMVWSRAQRRKMAQENPKMHNSEISKRLGAEWKLLTEAEKRPFI DEAKRLRAMHMKDHPDYKYRPRRKPKTLLKKDKFAFPMPYSLTGDHDGLKA VSLHGAG VLTDALLCHPEKAAAAAAAAAARVFFQPSAAAAAAAAAAASGSSTNPYSLFDLSSKMAE MTHSSSSIPYTSSIGYPQSSGGAFAGVTGGGHTHSHPSPGNPGYMIPCNCTGWPSPGLQPPL AYILFPGMGKPQLEPYPAAAY AAAL
>gi|29244252|ref|NP_808421.1| transcription factor SOX-21 [Mus musculus] MSKPVDHVKRPMNAFMVWSRAQRRKMAQENPKMHNSEISKRLGAEWKLLTESEKRPFI DEAKRLRAMHMKEHPDYKYRPRRKPKTLLKKDKFAFPVPYGLGSV ADAEHPALKAGAG LHAGAGGGLVPESLLANPEKAAAAAAAAAARVFFPQSAAAAAAAAAAAAAGSPYSLLD LGSKMAEISSSSSGLPYASSLGYPTAGAGAFHGAAAAAAAAAAAAGGHTHSHPSPGNPG YMIPCNCSAWPSPGLQPPLAYILLPGMGKPQLDPYPAAY AAAL
>gi|302565644|ref|NP_001180661.1| transcription factor SOX-21 [Macaca mulatta] MSKPVDHVKRPMNAFMVWSRAQRRKMAQENPKMHNSEISKRLGAEWKLLTESEKRPFI DEAKRLRAMHMKEHPDYKYRPRRKPKTLLKKDKFAFPVPYGLGGV ADAEHPALKAGAG LHAGAGGGLVPESLLANPEKAAAAAAAAAARVFFPQSAAAAAAAAAAAAAGSPYSLLD LGSKMAEISSSSSGLPYASSLGYPTAGAGAFHGAAAAAAAAAAAAGGHTHSHPSPGNPG YMIPCNCSAWPSPGLQPPLAYILLPGMGKPQLDPYPAAYAAAL
2、1~6步骤已经在练习题中做类似分析
3、利用BLAST在线工具对爪蟾(Xenopus laevis)、小家鼠[Mus musculus]、猕猴[Macaca mulatt a]的SOX-21蛋白质序列进行序列同源比对。
其中爪蟾与小家鼠、猕猴的相似性均为74%,E值分别为6e-119、2e-119。
而小家鼠SOX-21蛋白质序列与猕猴的序列的相似性高达99%,E值为0。
说明小家鼠与猕猴的同源的可能性远高于小家鼠与爪蟾。