计量经济学多元线性回归、多重共线性、异方差实验报告概要
- 格式:doc
- 大小:505.00 KB
- 文档页数:17

实验二__多元线性回归模型和多重共线性范文多元线性回归是一种常用的统计分析方法,用于研究多个自变量与一个因变量之间的关系。
在进行多元线性回归分析时,一个重要的问题是多重共线性。
多重共线性是指多个自变量之间存在高度相关性,这会导致回归模型的不稳定性,参数估计的不准确性,以及对自变量的解释能力下降等问题。
在进行多元线性回归分析之前,首先需要对自变量之间的相关性进行检验。
常用的方法有相关系数、方差膨胀因子(VIF)等。
相关系数用于衡量两个变量之间的线性关系,其值介于-1和1之间,接近于1表示高度正相关,接近于-1表示高度负相关。
VIF用于衡量一个自变量与其他自变量之间的相关性,其值大于1且越接近于1,表示相关性越强。
如果发现多个自变量之间存在高度相关性,即相关系数接近于1或VIF接近于1,就需采取措施来解决多重共线性问题。
一种常用的方法是通过增加样本量来消除多重共线性。
增加样本量可以提高模型的稳定性,减小参数估计的方差。
但是,增加样本量并不能彻底解决多重共线性问题,只能部分缓解。
另一种常用的方法是通过变量选择来解决多重共线性问题。
变量选择可以将高度相关的自变量从模型中剔除,保留与因变量高度相关的自变量。
常用的变量选择方法包括前向选择、逐步回归和岭回归等。
这些方法都是根据一定的准则逐步筛选变量,直到得到最佳模型为止。
在变量选择中,需要注意在变量剔除的过程中,要确保剩余变量之间的相关性尽可能小,以提高模型的稳定性和准确性。
此外,还可以通过变换变量来解决多重共线性问题。
变换变量可以通过对自变量进行平方项、交互项等操作,以减小相关性。
变换变量的方法需要根据实际情况来选择,具体操作可以参考相关的统计学方法教材。
总之,多元线性回归模型在实际应用中经常遇到多重共线性问题。
通过检验自变量之间的相关性,选择合适的变量和适当的变量变换方法,可以有效解决多重共线性问题,提高模型的稳定性和准确性。
在具体的研究中,应根据实际情况选择适合的方法来解决多重共线性问题,以确保回归分析结果的可靠性和有效性。

计量经济学实验报告实验1.异方差检验及修正一、 实验目的影响各地居民人均年消费支出的因素有多种,其中最主要的影响因素应当为收入,对于农村居民来说,收入包括从事农业经营的纯收入和其他来源的纯收入。
本题研究的是内地2006年各地区农村居民家庭人均纯收入与消费支出消费支出之间的关系是否存在异方差,如存在异方差并做出修正。
数据来源为《中国农村住户调查年鉴(2007)》、《中国统计年鉴(2007)》。
二、 实验步骤 1、建立模型01122Y X X u βββ=+++其中,Y 表示人均消费支出,X1表示从事农业经营的纯收入,X2表示其他来源的纯收入,单位为元。
2、从excel 中将数据导入EViews 中,得到图1。
图13、在EViews 命令框中直接键入“ls y c x1 x2”,按回车,即出现回归结果,如表2。
表2Dependent Variable: Y Method: Least Squares Date: 12/04/13 Time: 17:20 Sample: 1 31Included observations: 31Coefficient Std. Error t-Statistic Prob.C 728.1402 328.1558 2.218886 0.0348 X1 0.402097 0.164894 2.438514 0.0213 X20.7090300.041710 16.999110.0000R-squared0.922173 Mean dependent var 2981.623 Adjusted R-squared 0.916614 S.D. dependent var 1368.763 S.E. of regression 395.2538 Akaike info criterion 14.88870 Sum squared resid 4374316. Schwarz criterion 15.02747 Log likelihood -227.7748 Hannan-Quinn criter. 14.93394 F-statistic 165.8853 Durbin-Watson stat 1.428986Prob(F-statistic)0.000000由表可以得到:12728.14020.4020970.70903i Y X X =++(328.1558)(0.164894) (0.041710) t= (2.218886) (2.438514) (16.99911)220.922173,0.916614,165.8853R R F ===4、模型检验在显著性为0.05时,P 值都小于0.05,通过显著性检验,认为X1、X2显著。

第1篇一、实验目的本次实验旨在通过多元线性回归模型,分析多个自变量与因变量之间的关系,掌握多元线性回归模型的基本原理、建模方法、参数估计以及模型检验等技能,提高运用计量经济学方法解决实际问题的能力。
二、实验背景随着经济的发展和社会的进步,影响一个变量的因素越来越多。
在经济学、管理学等领域,多元线性回归模型被广泛应用于分析多个变量之间的关系。
本实验以某地区居民消费支出为例,探讨影响居民消费支出的因素。
三、实验数据本实验数据来源于某地区统计局,包括以下变量:1. 消费支出(Y):表示居民年消费支出,单位为元;2. 家庭收入(X1):表示居民家庭年收入,单位为元;3. 房产价值(X2):表示居民家庭房产价值,单位为万元;4. 教育水平(X3):表示居民受教育程度,分为小学、初中、高中、大专及以上四个等级;5. 通货膨胀率(X4):表示居民消费价格指数,单位为百分比。
四、实验步骤1. 数据预处理:对数据进行清洗、缺失值处理和异常值处理,确保数据质量。
2. 模型设定:根据理论知识和实际情况,建立多元线性回归模型:Y = β0 + β1X1 + β2X2 + β3X3 + β4X4 + ε其中,Y为因变量,X1、X2、X3、X4为自变量,β0为截距项,β1、β2、β3、β4为回归系数,ε为误差项。
3. 模型估计:利用统计软件(如SPSS、R等)对模型进行参数估计,得到回归系数的估计值。
4. 模型检验:对估计得到的模型进行检验,包括以下内容:(1)拟合优度检验:通过计算R²、F统计量等指标,判断模型的整体拟合效果;(2)t检验:对回归系数进行显著性检验,判断各变量对因变量的影响是否显著;(3)方差膨胀因子(VIF)检验:检验模型是否存在多重共线性问题。
5. 结果分析:根据模型检验结果,分析各变量对因变量的影响程度和显著性,得出结论。
五、实验结果与分析1. 拟合优度检验:根据计算结果,R²为0.812,F统计量为30.456,P值为0.000,说明模型整体拟合效果较好。

《计量经济学》上机实验报告一题目:多元回归模型和多重共线性实验日期和时间:2013年4月18日班级:学号:姓名:实验室:实验楼104实验环境:Windows XP ; EViews 3.1实验目的:利用相关数据建立多元回归模型,分析在不同的经济条件下一定的要素对某个经济体发展的影响程度并建立一定的关系模型。
检验设定的模型是否存在多重共线性,分析产生多重共线性的原因及作用因素,并对存在多重共线性的模型进行必要的修正。
实验内容:1、中国进出口额Y、国内生产总值GDP、居民消费价格指数CPI,根据提供的模型估计参数,判断多重共线性是否存在,表述多重共线性的性质。
2、检验能源消费需求总量Y的影响因素,选取国民总收入X1、国内生产总值X2、工业增加值X3、建筑业增加值X4、交通运输邮电业增加值X5、人均生活电力消费X6和能源加工转换效率X7七个变量,模拟回归,检验修正多重共线性。
3、为什么会产生“农业的发展反而会减少财政收入”的异常结果,如何解决这种异常。
实验步骤:一、中国进出口额Y、国内生产总值GDP、居民消费价格指数CPI(一)建立多元回归模型,估计参数在命令窗口依次键入以下命令:1、建立工作文件:CREATE A 1985 20072:输入统计资料:DATA Y GDP CPI3、生成变量:GENR LNY=LOG(Y)GENR LNGDP=LOG(GDP)GENR LNCPI=LOG(CPI)4、建立回归模型:LS LNY C LNGDP LNCPI得出回归结果为:由此可见,该模型的参数形式为:LNŶt=-3.06+1.66LNGDP t-1.06LNCPI t,其中该模型R2=0.9922,R2=0.9914可决系数很高,F检验值1275.093,明显显著,且T检验的临界概率均非常小,回归效果较好。
(二)检验多重共线性利用简单相关系数法进行检验,输入命令COR LNY LNGDP LNCPI,得到相关系数矩阵:由相关系数矩阵可以看出,各解释变量相互之间的相关系数均很高,说明数据中存在严重的多重共线性。

计量经济学实验报告四
[实验名称] 多重共线性
[实验目的] 用Eviews 软件检验模型的多重共线性.
[实验内容] (1)根据表列出的家庭消费支出Y与可支配收入X1和个人财富X2的统计数据,在Eviews软件下,OLS的估计结果为
所以模型为Yˆ=245.52+0.57X1-0.0058X2
(3.53)(0.79)(-0.08)
R2=0.962 F=88.845 D.W.=2.708
由拟合优度知,收入和财富一起解释了消费支出的96%.然而两者的t检验都在5%的显著性水平下是不显著的.不仅如此,财富变量的符号也与经济理论不相符合.但从F的检验值看,对收入与财富的参数同时为零的假设显然是拒绝的.因此,显著的F检验值与不显著t检验值,说明了收入与财富存在较高的相关性,使得无法分辨二者各自对消费的影响.只作消费支出关于收入的一元回归模型.如下
所以模型为Yˆ=244.55+0.509X1
(3.813)(14.24)
R2=0.962 F=202.87 D.W.=2.68
我们将上面模型与之相比,新引入的变量并没有带来拟合优度的显著变化,所以该引入的变量不是一个独立的解释变量.因此应该只作消费支出关于收入或财富的一元回归模型来对二元模型进行修正.。

实验报告课程名称金融计量学实验项目名称多元线性回归模型班级与班级代码实验室名称(或课室)专业任课教师xxx学号: xxx姓名: xxx实验日期: 2012年 5 月3日广东商学院教务处制姓名 xxx 实验报告成绩评语:指导教师(签名)年月日说明:指导教师评分后,实验报告交院(系)办公室保存多元线性回归模型一、实验目的通过上机实验,使学生能够使用 Eviews 软件估计可化为线性回归模型的非线性模型,并对线性回归模型的参数线性约束条件进行检验。
二、实验内容(一)根据中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y,资产合计K及职工人数L进行回归分析。
(二)掌握可化为线性多元非线性回归模型的估计和多元线性回归模型的线性约束条件的检验方法(三)根据实验结果判断中国该年制造业总体的规模报酬状态如何?三、实验步骤(一)收集数据下表列示出来中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y,资产合计K及职工人数L。
序号工业总产值Y(亿元)资产合计K(亿元)职工人数L(万人)序号工业总产值Y(亿元)资产合计K(亿元)职工人数L(万人)13722.73078.2211317812.71118.814321442.521684.4367181899.72052.1661 31752.372742.7784193692.856113.11240 41451.291973.8227204732.99228.25222 55149.35917.01327212180.232866.6580 62291.161758.77120222539.762545.6396 71345.17939.158233046.954787.9222 8656.77694.9431242192.633255.29163 9370.18363.4816255364.838129.68244 101590.362511.9966264834.685260.2145 11616.71973.7358277549.587518.79138 12617.94516.012828867.91984.5246134429.193785.9161294611.3918626.94218 145749.028688.0325430170.3610.9119 151781.372798.98331325.531523.1945 161243.071808.4433表1(二)创建工作文件(Workfile)。

计量经济学实验报告多元线性回归、多重共线性、异方差实验报告一、研究目的和要求:随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。
旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。
尤其是假日旅游,有力刺激了居民消费而拉动内需。
2012年,我国全年国内旅游人数达到亿人次,同比增长%,国内旅游收入万亿元,同比增长%。
旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。
为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。
影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。
旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。
因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。
二、模型设定根据以上的分析,建立以下模型Y=β0+β1X1+β2X2+β3X3+β4X4+Ut参数说明:Y ——旅游景区营业收入/万元X1——旅游业从业人员/人X2——旅游景区固定资产/万元X3——旅游外汇收入/万美元X4——城镇居民可支配收入/元收集到的数据如下(见表):表 2011年全国旅游景区营业收入及相关数据(按地区分)数据来源:1.中国统计年鉴2012,2.中国旅游年鉴2012。
三、参数估计利用做多元线性回归分析步骤如下:1、创建工作文件双击图标,进入其主页。
在主菜单中依次点击“File\New\Workfile”,出现对话框“Workfile Range”。

多元线性回归计量经济学实验报告
标题:多元线性回归在计量经济学实验中的应用及分析
摘要:本实验旨在利用多元线性回归方法探究不同因素对经济增长的影响。
通过选择适当的自变量,运用OLS(普通最小二乘法)估计模型,得到回归系数,并验证其显著性。
结果表明,在经济增长中,投资、劳动力和科技发展是重要的影响因素。
本实验的结果为制定经济政策提供了理论依据。
一、引言
计量经济学中的多元线性回归是一种常用的经济模型分析方法,可以用于解释和预测经济现象。
在本实验中,我们采用多元线性回归模型,考察了投资、劳动力和科技发展对经济增长的影响,并验证其显著性。

计量经济学实验报告一、实验目的:1、熟悉和掌握Eviews在多重共线性模型中的应用,如何判断和解决多重共线性问题。
2、加深对课程理论知识的理解和应用。
二、实验问题:农村居民各种不同类型的收入对消费支出影响(2006年)农村居民收入(Y)主要来源于4项:即农业经营收入(X1)、工资性收入(X2)、财产性收入(X3)及转移性收入(X4)。
(1)利用线性模型或双对数模型进行分析。
(2)回归模型中存在多重共线性吗?三、实验数据:由老师提供(本实验报告截取从北京到新疆共31组数据)四、实验步骤:1、建立新的工作文件,输入数据,分别保存为Y(农村居民收入),X1(农业经营收入)、X2(工资性收入)、X3(财产性收入)、及X4(转移性收入)。
2、建立线性模型:Y = a1*X1 + a2*X2 +a3*X3 + a4*X4 + u得到方程:Y = 0.6268809567*X1 + 0.481134931*X2 - 0.255544644*X3 + 2.683018467*X4 + 479.30109493、分析由图中数据可以看出,在最小二乘法下,模型的R平方和F值较大,表明模型中各解释变量对Y的联合线性作用显著;但是X3(财产性收入)的系数是负的,这不符合经济学意义,财产性收入应当与消费支出正相关,故怀疑模型存在多重共线性。
4、检验:计算解释变量之间的简单相关系数:在“quick”菜单中选“group statistics”项中的“correlation”命令。
在出现“serieslist”对话框时,直接输入X1,X2,X3,X4出现如下结果从表中可以看出,解释变量X1、X3、X4之间存在高度线性相关。
4、修正第一步:运用OLS方法逐一求Y对各个解释变量的回归。
(1)Y = 0.8997862236*X1 + 1541.033294t值 15.32947 12.29913prob.值 0.0000 0.0000R2=0.890148 F=234.9925(2)Y = 0.2487123305*X2 + 2505.747921t值 0.527219 2.676297prob.值 0.6021 0.0121R2= 0.009494 F=0.277960(3)Y = 8.049228785*X3 + 1943.170851t值 9.28666 11.56389prob.值 0.0000 0.0000R2=0.748356 F= 86.24206(4)Y = 5.928884198*X4 + 1631.299987t值 9.212266 8.434353prob.值 0.0000 0.0000R2= 0.745314 F=84.86584结合经济意义和统计检验结果分析,在4个一元回归模型中消费支出Y对X1工资性收入线性关系最强,拟合程度较好,与经验相符,因此选(1)为初始的回归模型。

计量经济学》实验报告一、经济学理论概述1、需求是指消费者(家庭)在某一特定时期内,在每一价格水平时愿意而且能够购买的某种商品量。
需求是购买欲望与购买能力的统一。
2、需求定理是说明商品本身价格与其需求量之间关系的理论。
其基本内容是:在其他条件不变的情况下,一种商品的需求量与其本身价格之间成反方向变动,即需求量随着商品本身价格的上升而减少,随商品本身价格的下降而增加。
3、需求量的变动是指其他条件不变的情况下,商品本身价格变动所引起的需求量的变动。
需求量的变动表现为同一条需求曲线上的移动。
二、经济学理论的验证方法在此次试验中,我运用了Eviews和Excel软件对相关数据进行处理和分析。
1、拟合优度检验——可决系数R2统计量回归平方和反应了总离差平方和中可由样本回归线解释的部分,它越大,参差平方和越小,表明样本回归线与样本观测值的拟合程度越高。
2、方程总体线性的显着性检验——F检验(1)方程总体线性的显着性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显着成立作出判断。
(2)给定显着性水平α,查表得到临界值Fα(k,n-k-1),根据样本求出F统计量的数值后,可通过F>Fα(k,n-k-1) (或F ≤Fα(k,n-k-1))来拒绝(或接受)原假设H0,以判定原方程总体上的线性关系是否显着成立。
3、变量的显着性检验——t检验4、异方差性的检验——怀特检验怀特检验不需要排序,对任何形式的异方差都适用。
5、序列相关性的检验——图示法和回归检验法6、多重共线性的检验——逐步回归法以Y为被解释变量,逐个引入解释变量,构成回归模型,进行模型估计。
三、验证步骤1、确定变量(1)被解释变量“货币流通量”在模型中用“Y”表示。
(2)解释变量①“货币贷款额”在模型中用“X”表示;1②“居民消费价格指数”在模型中用“2X ”表示;③把由于各种原因未考虑到和无法度量的因素归入随机误差项,在模型中用“μ”。
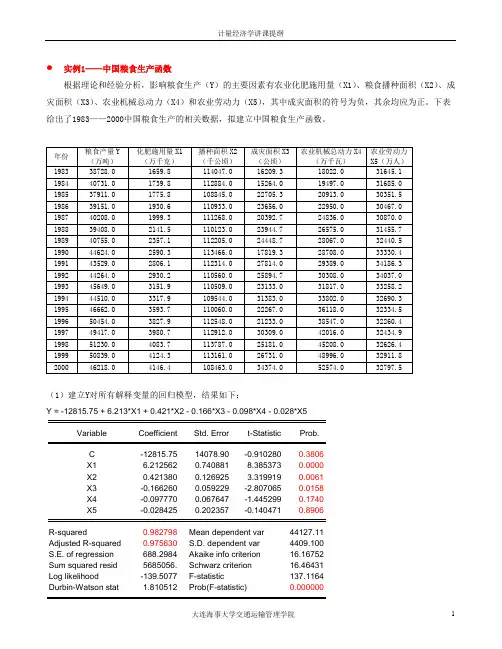
实例1——中国粮食生产函数根据理论和经验分析,影响粮食生产(Y)的主要因素有农业化肥施用量(X1)、粮食播种面积(X2)、成灾面积(X3)、农业机械总动力(X4)和农业劳动力(X5),其中成灾面积的符号为负,其余均应为正。
下表给出了1983——2000中国粮食生产的相关数据,拟建立中国粮食生产函数。
(1)建立Y对所有解释变量的回归模型,结果如下:Y = -12815.75 + 6.213*X1 + 0.421*X2 - 0.166*X3 - 0.098*X4 - 0.028*X5Variable Coefficient Std. Error t-Statistic Prob.C -12815.75 14078.90 -0.910280 0.3806X1 6.212562 0.740881 8.385373 0.0000X2 0.421380 0.126925 3.319919 0.0061X3 -0.166260 0.059229 -2.807065 0.0158X4 -0.097770 0.067647 -1.445299 0.1740X5 -0.028425 0.202357 -0.140471 0.8906R-squared 0.982798 Mean dependent var 44127.11Adjusted R-squared 0.975630 S.D. dependent var 4409.100S.E. of regression 688.2984 Akaike info criterion 16.16752Sum squared resid 5685056. Schwarz criterion 16.46431Log likelihood -139.5077 F-statistic 137.1164Durbin-Watson stat 1.810512 Prob(F-statistic) 0.000000从计算结果看,R2较大并接近于1,而且F=137.11>F0.05=3.11,故认为粮食生产量与上述所有解释变量间总体线性相关显著。
计量经济学实验报告多元线性回归自相关 Document number【980KGB-6898YT-769T8CB-246UT-18GG08】实验报告课程名称计量经济学实验项目名称多元线性回归自相关异方差多重共线性班级与班级代码 08国际商务1班实验室名称(或课室)实验楼910 专业国际商务任课教师刘照德学号: 043姓名:张柳文实验日期: 2011 年 06 月 23日广东商学院教务处制姓名张柳文实验报告成绩评语:指导教师(签名)年月日说明:指导教师评分后,实验报告交院(系)办公室保存。
计量经济学实验报告实验项目:多元线性回归、自相关、异方差、多重共线性实验目的:掌握多元线性回归模型、自相关模型、异方差模型、多重共线性模型的估计和检验方法和处理方法实验要求:选择方程进行多元线性回归;熟悉图形法检验和掌握D-W 检验,理解广义差分法变换和掌握迭代法;掌握Park或Glejser检验,理解同方差性变换;实验原理:普通最小二乘法图形检验法 D-W检验广义差分变换加权最小二乘法 Park检验等实验步骤:首先:选择数据为了研究影响中国税收收入增长的主要原因,选择国内生产总值(GDP)、财政支出(ED)、商品零售价格指数(RPI)做为解释变量,对税收收入(Y)做多元线性回归。
从《中国统计年鉴》2011中收集1978—2009年各项影响因素的数据。
如下表所示:199219931994199519961997199819992000200120022003200420052006200720082009实验一:多元线性回归1、将数据导入后,分别对三个解释变量与被解释变量做散点图,选择两个变量作为group打开,在数据表“group”中点击view/graph/scatter/simple scatter,出现数据的散点图,分别如下图所示:从散点图看,变量间不一定呈现线性关系,可以试着作线性回归。
2、进行因果关系检验在“workfile”中按住“ctrl”键,点击所要选择的变量,作为组打开后,在“View”下拉列表中选择“Grange Causality”,滞后期为2,得出如下结果:Pairwise Granger Causality TestsDate: 06/23/11 Time: 16:14Sample: 1978 2009Lags: 2Null Hypothesis:Obs F-Statistic ProbabilityED does not Granger Cause Y30Y does not Granger Cause EDPairwise Granger Causality TestsDate: 06/23/11 Time: 16:15Sample: 1978 2009Lags: 2Null Hypothesis:Obs F-Statistic ProbabilityGDP does not Granger Cause Y30Y does not Granger Cause GDPPairwise Granger Causality TestsDate: 06/23/11 Time: 16:19Sample: 1978 2009Lags: 2Null Hypothesis:Obs F-Statistic ProbabilityRPI does not Granger Cause Y30Y does not Granger Cause RPI从因果关系检验看,ED明显影响财政收入Y,其他两个因素影响不显着。
多重共线性实验报告武颖经济统计学一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。
二、实验要求:应用教材第119页案例做多元线性回归模型,并识别和修正多重共线性。
三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。
四、预备知识:最小二乘法估计的原理、t 检验、F 检验、2R 值。
五、实验步骤1.假定模型:设定并估计多元线性回归模型tt t t t t t u X X X X X Y ++++++=66554433221ββββββ2.录入数据:国内旅游收入为Y ,国内旅游人数为X2,城镇居民人均旅游支出为X3,农村居民人均旅游费用为X4,公路里程为X5,铁路里程为X6.3.回归结果:在Eview行输入LS Y C XX3 X4 X5 X6,得到回归结果2模型估计结果为:Yt=-274.3773+0.013088X2+5.438193X3+3.271773X4-563.1077X5+12.98624X6(1316.690) (0.012692) (1.380395) (0.944215) (4.177929) (321.2830)t=(-0.208384)(1.031172)(3.939591)(3.465073)(3.108296)(-1.752685)R2=0.995406 F=173.35254.模型检验:该模型R2=0.995406,R2=0.989664,可决系数很高,F检验值为173.3525,明显显著。
假设显著性水平α=0.05,X2>0.05,X6>0.05,接受原假设,可能存在严重的多重共线性六.多重共线性的识别(1)得到解释变量的相关系数矩阵将解释变量x2、x3、x4、x5、x6选中,双击选择Open Group(或点击右键,选择Open/as Group),然后再点击View/covariance analysis/Correlation/Common Sample,即可得出相关系数再点击表顶部的Freeze,可得一个Table类型独立的object.由相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,特别是x2和x3之间高度相关,证实解释变量之间存在多重共线性。
实验题目:多元线性回归、异方差、多重共线性实验目的:掌握多元线性回归的最小二乘法,熟练运用Eviews软件的多元线性回归、异方差、多重共线性的操作,并能够对结果进行相应的分析。
实验内容:习题3.2,分析1994-2011年中国的出口货物总额(Y)、工业增加值(X2)、人民币汇率(X3),之间的相关性和差异性,并修正。
实验步骤:1.建立出口货物总额计量经济模型:(3.1)1.1建立工作文件并录入数据,得到图1图1在“workfile"中按住”ctrl"键,点击“Y、X2、X3”,在双击菜单中点“open group”,出现数据表。
点”view/graph/line/ok”,形成线性图2。
图21.2对(3.1)采用OLS估计参数在主界面命令框栏中输入ls y c x2 x3,然后回车,即可得到参数的估计结果,如图3所示。
图 3根据图3中的数据,得到模型(3.1)的估计结果为(8638.216)(0.012799)(9.776181)t=(-2.110573) (10.58454) (1.928512)F=522.0976从上回归结果可以看出,拟合优度很高,整体效果的F检验通过。
但当=0.05时,= 2.131.有重要变量X3的t检验不显著,可能存在严重的多重共线性。
2.多重共线性模型的识别2.1计算解释变量x2、x3的简单相关系数矩阵。
点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x2、x3,点击OK,即可得出相关系数矩阵(同图4)。
相关系数矩阵图4由图4相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实解释变量之间存在多重共线性。
2.2多重共线性模型的修正将各变量进行对数变换,在对以下模型进行估计。
利用eviews软件,对、X2、X3分别取对数,分别生成lnY、lnX2、lnX3的数据,采用OLS方法估计模型参数,得到回归结果,如图:图5图6模型估计结果为:ln=-20.52+1.5642lnX2+1.7607lnX3(5.4325) (0.0890) (0.6821)t =-3.778 17.578 2.581F=539.736该模型可决系数很高,F检验值,明显显著。
计量经济学实验报告回归分析计量经济学实验报告:回归分析一、实验目的本实验旨在通过运用计量经济学方法,对收集到的数据进行分析,研究自变量与因变量之间的关系,并估计回归模型中的参数。
通过回归分析,我们可以深入了解变量之间的关系,为预测和决策提供依据。
二、实验原理回归分析是一种常用的统计方法,用于研究自变量与因变量之间的线性或非线性关系。
在回归分析中,我们通过最小二乘法等估计方法,得到回归模型中未知参数的估计值。
根据估计的参数,我们可以对因变量进行预测,并分析自变量对因变量的影响程度。
三、实验步骤1.数据收集:收集包含自变量与因变量的数据集。
数据可以来自数据库、调查、实验等。
2.数据预处理:对收集到的数据进行清洗、整理和格式化,以确保数据的质量和适用性。
3.模型选择:根据问题的特点和数据的特性,选择合适的回归模型。
常见的回归模型包括线性回归模型、多元回归模型、岭回归模型等。
4.模型估计:运用最小二乘法等估计方法,对选择的回归模型进行估计,得到模型中未知参数的估计值。
5.模型检验:对估计后的模型进行检验,以确保模型的适用性和可靠性。
常见的检验方法包括残差分析、拟合优度检验等。
6.预测与分析:根据估计的模型参数,对因变量进行预测,并分析自变量对因变量的影响程度。
四、实验结果与分析1.数据收集与预处理本次实验选取了某网站的销售数据作为样本,数据包含了商品价格、销量、评价等指标。
在数据预处理阶段,我们剔除了缺失值和异常值,以确保数据的完整性和准确性。
2.模型选择与估计考虑到商品价格和销量之间的关系可能存在非线性关系,我们选择了多元回归模型进行建模。
采用最小二乘法进行模型估计,得到的估计结果如下:销量 = 100000 + 10000 * 价格 + 5000 * 评价 + 随机扰动项3.模型检验对估计后的模型进行残差分析,发现残差分布较为均匀,且均在合理范围内。
同时,拟合优度检验也表明模型对数据的拟合程度较高。
多元线性回归模型实验报告计量经济学多元线性回归模型是一种比较常见的经济学建模方法,其可用于对多个自变量和一个因变量之间的关系进行分析和预测。
在本次实验中,我们将使用一个包含多个自变量的数据集,对其进行多元线性回归分析,并对分析结果进行解释。
数据集介绍本次实验使用的数据集来自于UCI Machine Learning Repository,数据集包含有关汽车试验的多个自变量和一个连续因变量。
数据集中包含了204条记录,其中每条记录包含了一辆汽车的14个属性,分别是:MPG(燃油效率),气缸数(Cylinders)、排量(Displacement)、马力(Horsepower)、重量(Weight)、加速度(Acceleration)、模型年(Model Year)、产地(Origin)等。
模型建立在进行多元线性回归分析之前,我们首先需要对数据进行预处理。
为了确保数据的可用性,我们需要先检查数据是否存在缺失值和异常值。
如果有,需要进行相应的处理,以确保因变量和自变量之间的关系受到了正确地分析。
在对数据进行预处理之后,我们可以使用Python中的statsmodels包来对数据进行多元线性回归分析。
具体建模过程如下:```import statsmodels.api as sm# 准备自变量和因变量数据X = data[['Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']]y = data['MPG']# 添加常数项X = sm.add_constant(X)# 拟合线性回归模型model = sm.OLS(y, X).fit()# 输出模型摘要print(model.summary())```在上述代码中,我们首先通过data[['Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']]选择了所有自变量列,用于进行多元线性回归分析;然后,我们又通过`sm.add_constant(X)`,向自变量数据中添加了一列全为1的常数项,用于对截距进行建模;最后,我们使用`sm.OLS(y, X).fit()`来拟合线性回归模型,并使用`model.summary()`输出模型摘要。
计量经济学实验报告多元线性回归、多重共线性、异方差实验报告一、研究目的和要求:随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。
旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。
尤其是假日旅游,有力刺激了居民消费而拉动内需。
2012年,我国全年国内旅游人数达到30.0亿人次,同比增长13.6%,国内旅游收入2.3万亿元,同比增长19.1%。
旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。
为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。
影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。
旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。
因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。
二、模型设定根据以上的分析,建立以下模型Y=β0+β1X1+β2X2+β3X3+β4X4+Ut参数说明:Y ——旅游景区营业收入/万元X1——旅游业从业人员/人X2——旅游景区固定资产/万元X3——旅游外汇收入/万美元X4——城镇居民可支配收入/元收集到的数据如下(见表2.1):表2.1 2011年全国旅游景区营业收入及相关数据(按地区分)数据来源:1.中国统计年鉴2012,2.中国旅游年鉴2012。
三、参数估计利用Eviews6.0做多元线性回归分析步骤如下:1、创建工作文件双击Eviews6.0图标,进入其主页。
在主菜单中依次点击“File\New\Workfile”,出现对话框“Workfile Range”。
本例中是截面数据,在workfile structure type中选择“Unstructured/Undated”,在Date range中填入observations 31,点击ok键,完成工作文件的创建。
2、输入数据在命令框中输入 data Y X1 X2 X3 X4,回车出现“Group”窗口数据编辑框,在对应的Y X1 X2 X3 X4下输入相应数据,关闭对话框将其命名为group01,点击ok,保存。
对数据进行存盘,点击“File/Save As”,出现“Save As”对话框,选择存入路径,并将文件命名,再点“ok”。
3、参数估计在Eviews6.0命令框中键入“LS Y C X1 X2 X3 X4”,按回车键,即出现回归结果。
利用Eviews6.0估计模型参数,最小二乘法的回归结果如下:表3.1 回归结果Dependent Variable: YMethod: Least SquaresDate: 11/14/13 Time: 21:14Sample: 1 31Included observations: 31Coefficient Std. Error t-Statistic Prob.C 32390.83 39569.49 0.818581 0.4205X1 0.603624 0.366112 1.648741 0.1112X2 0.234265 0.041218 5.683583 0.0000X3 0.044632 0.060755 0.734620 0.4691X4 -1.914034 2.098257 -0.912202 0.3700R-squared 0.879720 Mean dependent var 114619.2 Adjusted R-squared 0.861215 S.D. dependent var 112728.1S.E. of regression 41995.55 Akaike info criterion 24.27520Sum squared resid 4.59E+10 Schwarz criterion 24.50649Log likelihood -371.2657 Hannan-Quinn criter. 24.35060F-statistic 47.54049 Durbin-Watson stat 2.007191Prob(F-statistic) 0.000000根据表中的样本数据,模型估计结果为^Y=32390.83+0.603624X1+0.234265X2+0.044632X3-1.914034X4(39569.49)(0.366112)(0.041218)(0.060755)(2.098257)t = (0.818581) (1.648741) (5.683583) (0.734620) (-0.912202)R2=0.879720--R2=0.861215 F=47.54049 DW=2.007191可以看出,可决系数R2=0.879720,修正的可决系数--R2=0.861215。
说明模型的拟合程度还可以。
但是当α=0.05时,X1、X2、X4系数均不能通过检验,且X4的系数为负,与经济意义不符,表明模型很可能存在严重的多重共线性。
四、模型修正1.多重共线性的检验与修正(1)检验选中X1 X2 X3 X4数据,点击右键,选择“Open/as Group”,在出现的对话框中选择“View/Covariance Analysis/correlation”,点击ok,得到相关系数矩阵。
计算各个解释变量的相关系数,得到相关系数矩阵。
表4.1 相关系数矩阵变量X1 X2 X3 X4X1 1.0000000.8097770.8720930.659239X2 0.809777 1.0000000.7583220.641086X3 0.8720930.758322 1.0000000.716374由相关系数矩阵可以看出,解释变量X2、X3之间存在较高的相关系数,证实确实存在严重的多重共线性。
(2)多重共线性修正采用逐步回归的办法,检验和回归多重共线性问题。
分别作Y对X1、X2、X3、X4的一元回归,在命令窗口分别输入LS Y C X1,LS Y C X2,LS Y C X3,LS Y C X4,并保存,整理结果如表4.2所示。
表4.2 一元回归结果 变量 X1 X2 X3 X4 参数估计值 1.978224 0.315120 0.316946 12.54525 t 统计量 8.635111 12.47495 6.922479 4.005547 R 20.719983 0.842924 0.622988 0.356191 -2R0.7103270.8375080.6099880.333991其中,X2的方程-2R 最大,以X2为基础,顺次加入其它变量逐步回归。
在命令窗口中依次输入:LS Y C X2 X1,LS Y C X2 X3, LS Y C X2 X4,并保存结果,整理结果如表4.3所示。
表4.3 加入新变量的回归结果(一)经比较,新加入X1的方程-2R =0.866053,改进最大,而且各个参数的t 检验显著,选择保留X1,再加入其它新变量逐步回归,在命令框中依次输入:LS Y C X2 X1 X3,LS Y C X2 X1 X4,保存结果,整理结果如表4.4所示。
表4.4 加入新变量的回归结果(二) 当加入X3或X4时,-2R 均没有所增加,且其参数是t 检验不显著。
从相关系数可以看出X3、X4与X1、X2之间相关系数较高,这说明X3、X4引起了多重共线性,予以剔除。
当取α=0.05时,t α/2(n-k-1)=2.048,X1、X2的系数t 检验均显著,这是最后消除多重共线性的结果。
修正多重共线性影响后的模型为^Y= 0.711446 X1+0.230304 X2(0.265507)(0.039088)t = (2.679575) (5.891959)R2=0.8749832R=0.866053 F=97.98460 DW=1.893654在确定模型以后,进行参数估计表4.5消除多重共线性后的回归结果Dependent Variable: YMethod: Least SquaresDate: 11/14/13 Time: 21:47Sample: 1 31Included observations: 31Coefficient Std. Error t-Statistic Prob.C -4316.824 12795.42 -0.337373 0.7384X1 0.711446 0.265507 2.679575 0.0122X2 0.230304 0.039088 5.891959 0.0000R-squared 0.874983 Mean dependent var 114619.2 Adjusted R-squared 0.866053 S.D. dependent var 112728.1 S.E. of regression 41257.10 Akaike info criterion 24.18480 Sum squared resid 4.77E+10 Schwarz criterion 24.32357 Log likelihood -371.8644 Hannan-Quinn criter. 24.23004 F-statistic 97.98460 Durbin-Watson stat 1.893654 Prob(F-statistic) 0.000000五、异方差检验在实际的经济问题中经常会出现异方差这种现象,因此建立模型时,必须要注意异方差的检验,否则,在实际中会失去意义。
(1)检验异方差由表 4.5的结果,按路径“View/Residual Tests/Heteroskedasticity Tests”,在出现的对话框中选择Specification:White,点击ok.得到White 检验结果如下。
表5.1 White检验结果Heteroskedasticity Test: WhiteF-statistic 3.676733 Prob. F(5,25) 0.0125Obs*R-squared 13.13613 Prob. Chi-Square(5) 0.0221Scaled explained SS 15.97891 Prob. Chi-Square(5) 0.0069Test Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 11/14/13 Time: 21:48Sample: 1 31Included observations: 31Coefficient Std. Error t-Statistic Prob.C -1.10E+09 1.11E+09 -0.992779 0.3303X1 -12789.36 30151.30 -0.424173 0.6751X1^2 0.420716 0.294332 1.429393 0.1653X1*X2 -0.101814 0.083576 -1.218216 0.2345X2 14604.52 5047.701 2.893301 0.0078X2^2 -0.002489 0.008030 -0.309972 0.7592R-squared 0.423746 Mean dependent var 1.54E+09Adjusted R-squared 0.308495 S.D. dependent var 2.70E+09S.E. of regression 2.24E+09 Akaike info criterion 46.07313Sum squared resid 1.26E+20 Schwarz criterion 46.35068Log likelihood -708.1335 Hannan-Quinn criter. 46.16360F-statistic 3.676733 Durbin-Watson stat 1.542170Prob(F-statistic) 0.012464从上表可以看出,nR2=13.13613,由White检验可知,在α=0.05下,查2χ(5)=11.0705,比较计算的2χ统计量与临界值,因为分布表,得临界值χ2.005(5)=11.0705,所以拒绝原假设,表明模型存在异方差。