多元线性回归实例分析报告
- 格式:doc
- 大小:1004.00 KB
- 文档页数:18

多元线性回归分析范例多元线性回归是一种用于预测因变量和多个自变量之间关系的统计分析方法。
它假设因变量与自变量之间存在线性关系,并通过拟合一个多元线性模型来估计因变量的值。
在本文中,我们将使用一个实际的数据集来进行多元线性回归分析的范例。
数据集介绍:我们选取的数据集是一份汽车销售数据,包括了汽车的价格(因变量)和多个与汽车相关的特征(自变量),如车龄、行驶里程、汽车品牌等。
我们的目标是通过这些特征来预测汽车的价格。
数据集包括了100个样本。
数据集的构成如下:车龄(年),行驶里程(万公里),品牌,价格(万元)----------------------------------------5,10,A,153,5,B,207,12,C,10...,...,...,...建立多元线性回归模型:我们首先需要将数据集划分为自变量矩阵X和因变量向量y。
其中,自变量矩阵X包括了车龄、行驶里程和品牌等特征,因变量向量y包括了价格。
在Python中,我们可以使用NumPy和Pandas库来处理和分析数据。
我们可以使用Pandas的DataFrame来存储数据集,并使用NumPy的polyfit函数来拟合多元线性模型。
首先,我们导入所需的库并读取数据集:```pythonimport pandas as pdimport numpy as np#读取数据集data = pd.read_csv('car_sales.csv')```然后,我们将数据集划分为自变量矩阵X和因变量向量y:```python#划分自变量矩阵X和因变量向量yX = data[['车龄', '行驶里程', '品牌']]y = data['价格']```接下来,我们使用polyfit函数来拟合多元线性模型。
我们将自变量矩阵X和因变量向量y作为输入,并指定多项式的次数(线性模型的次数为1):```python#拟合多元线性模型coefficients = np.polyfit(X, y, deg=1)```最后,我们可以使用拟合得到的模型参数来预测新的样本。

《多元线性回归分析的实例研究》篇一一、引言多元线性回归分析是一种统计学方法,用于探究一个因变量与多个自变量之间的关系。
这种方法在各个领域的研究中广泛应用,如经济学、社会学、心理学等。
本文将通过一个具体的实例,展示多元线性回归分析的应用过程及其实证结果。
二、研究背景与目的本研究以某地区房价为研究对象,探讨房价与地理位置、房屋面积、房屋装修等因素之间的关系。
目的是通过多元线性回归分析,找出影响房价的主要因素,为房地产投资者和购房者提供参考依据。
三、数据收集与处理本研究采用某地区房地产交易数据,包括房价、地理位置、房屋面积、房屋装修等变量。
在数据收集过程中,我们确保数据的准确性和完整性,并对数据进行清洗和处理,以消除异常值和缺失值的影响。
四、多元线性回归分析(一)模型构建根据研究目的和收集的数据,构建多元线性回归模型。
假设房价为因变量Y,地理位置、房屋面积、房屋装修等因素为自变量X1、X2、X3。
则模型可以表示为:Y = β0 + β1X1 + β2X2 +β3X3 + ε。
其中,β0为常数项,β1、β2、β3为回归系数,ε为随机误差项。
(二)参数估计与假设检验利用统计软件对模型进行参数估计,得到各回归系数的估计值及其显著性水平。
通过假设检验,检验自变量与因变量之间的线性关系是否显著。
若显著性水平低于预设的阈值(如0.05),则认为自变量与因变量之间存在显著的线性关系。
(三)模型检验与优化对模型进行检验和优化,包括检查模型的拟合优度、自相关性和异方差性等。
若存在显著问题,则采取相应的方法进行修正和优化。
五、实证结果与分析(一)回归系数解释根据参数估计结果,得出各回归系数的估计值。
解释各系数在模型中的意义和作用,如地理位置对房价的影响程度、房屋面积对房价的影响程度等。
(二)实证结果分析根据实证结果,分析自变量与因变量之间的关系及影响程度。
通过对比各回归系数的估计值和显著性水平,找出影响房价的主要因素。
同时,结合实际情况,对实证结果进行深入分析和解释。

《多元线性回归分析的实例研究》篇一一、引言多元线性回归分析是一种统计方法,用于研究多个变量之间的关系。
在社会科学、经济分析、医学等多个领域,这种分析方法的应用都十分重要。
本实例研究以一个具体的商业案例为例,展示了如何应用多元线性回归分析方法进行研究,以便深入理解和探索各个变量之间的潜在关系。
二、背景介绍以某电子商务公司的销售额预测为例。
电子商务公司销售量的影响因素很多,包括市场宣传、商品价格、消费者喜好等。
因此,本文通过收集多个因素的数据,使用多元线性回归分析,以期达到更准确的销售预测和因素分析。
三、数据收集与处理为了进行多元线性回归分析,我们首先需要收集相关数据。
在本例中,我们收集了以下几个关键变量的数据:销售额(因变量)、广告投入、商品价格、消费者年龄分布、消费者性别比例等。
这些数据来自电子商务公司的历史销售记录和调查问卷。
在收集到数据后,我们需要对数据进行清洗和处理。
这包括去除无效数据、处理缺失值、标准化处理等步骤。
经过处理后,我们可以得到一个干净且结构化的数据集,为后续的多元线性回归分析提供基础。
四、多元线性回归分析1. 模型建立根据所收集的数据和实际情况,我们建立了如下的多元线性回归模型:销售额= β0 + β1广告投入+ β2商品价格+ β3消费者年龄分布+ β4消费者性别比例+ ε其中,β0为常数项,β1、β2、β3和β4为回归系数,ε为误差项。
2. 模型参数估计通过使用统计软件进行多元线性回归分析,我们可以得到每个变量的回归系数和显著性水平等参数。
这些参数反映了各个变量对销售额的影响程度和方向。
3. 模型检验与优化为了检验模型的可靠性和准确性,我们需要对模型进行假设检验、R方检验和残差分析等步骤。
同时,我们还可以通过引入交互项、调整自变量等方式优化模型,提高预测精度。
五、结果分析与讨论1. 结果解读根据多元线性回归分析的结果,我们可以得到以下结论:广告投入、商品价格、消费者年龄分布和消费者性别比例均对销售额有显著影响。

多元线性回归模型的案例分析年份 Y/千克 X/元 P 1/(元/千克)P 2/(元/千克)P 3/(元/千克)年份 Y/千克 X/元 P 1/(元/千克)P 2/(元/千克)P 3/(元/千克)1980 397 1992 911 1981 413 1993 931 1982 439 1994 1021 1983 459 1995 1165 1984 492 1996 1349 1985 528 1997 1449 1986 560 1998 1575 1987 624 1999 1759 1988 666 2000 1994 1989 717 2001 2258 1990 768 2002 24781991843(1)求出该地区关于家庭鸡肉消费需求的如下模型:01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2)请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。
先做回归分析,过程如下:输出结果如下:所以,回归方程为:123ln 0.73150.3463ln 0.5021ln 0.1469ln 0.0872ln Y X P P P =-+-++由上述回归结果可以知道,鸡肉消费需求受家庭收入水平和鸡肉价格的影响,而牛肉价格和猪肉价格对鸡肉消费需求的影响并不显著。
验证猪肉价格和鸡肉价格是否有影响,可以通过赤池准则(AIC )和施瓦茨准则(SC )。
若AIC 值或SC 值增加了,就应该去掉该解释变量。
去掉猪肉价格P 2与牛肉价格P 3重新进行回归分析,结果如下:VariableCoefficient Std. Error t-Statistic Prob. C LOG(X) LOG(P1)R-squaredMean dependentvarAdjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic )通过比较可以看出,AIC 值和SC 值都变小了,所以应该去掉猪肉价格P 2与牛肉价格P 3这两个解释变量。

《多元线性回归分析的实例研究》篇一一、引言多元线性回归分析是一种统计方法,用于研究多个变量之间的线性关系。
在实际生活和科研工作中,这种分析方法广泛应用于经济、医学、生态学等领域。
本文以一个具体实例为例,深入探讨多元线性回归分析的步骤和应用。
该实例关注于房屋价格的影响因素分析。
二、研究背景及目的随着房地产市场的发展,房屋价格受到多种因素的影响。
为了探究这些因素如何共同影响房屋价格,本文选取了一组具有代表性的房屋数据,并运用多元线性回归分析方法进行实证研究。
研究目的在于揭示影响房屋价格的主要因素,为购房者和房地产投资者提供参考依据。
三、数据与方法(一)数据来源本研究的数据来源于某城市房屋交易数据库,涵盖了多个区域的房屋信息,包括房屋价格、房屋面积、房屋年龄、周边环境、学区等因素。
(二)研究方法本研究采用多元线性回归分析方法,通过建立模型来研究各因素与房屋价格之间的线性关系。
具体步骤包括:数据清洗、变量选择、模型建立、模型检验和结果解释等。
四、多元线性回归分析步骤及结果(一)变量选择与数据清洗根据研究目的和前人研究成果,本研究选择了以下变量:房屋价格(因变量)、房屋面积、房屋年龄、周边环境(包括交通、商业、绿化等)、学区等(自变量)。
在数据清洗阶段,剔除了异常值和缺失值,确保数据的准确性和可靠性。
(二)模型建立根据选定的变量,建立多元线性回归模型。
模型形式如下:P = β0 + β1 × Area + β2 × Age + β3 × Environment + β4 × Schoo l + ε其中,P表示房屋价格,Area表示房屋面积,Age表示房屋年龄,Environment表示周边环境因素,School表示学区因素,βi 为各变量的回归系数,ε为随机误差项。
(三)模型检验通过SPSS软件进行模型检验。
首先进行多重共线性检验,发现各变量之间不存在明显的共线性问题。

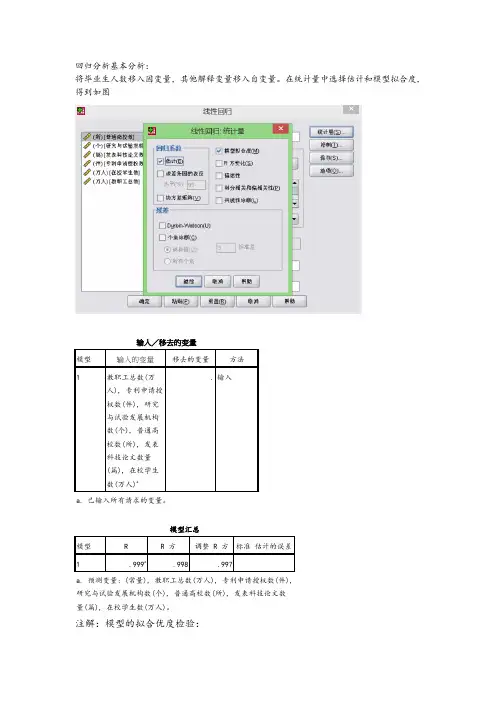
SP SS--回归-多元线性回归模型案例解析!( 一)多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为:Y = 00 十 十 E毫无疑问,多元线性回归方程应该为:上图中的x1, x2, xp 分别代表“自变量” Xp 截止,代表有P 个自变量,如果有“ N 组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示:记n 俎样本分别是(兀那么,多元线性回归方程矩阵形式为:'"" + £1的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样)2:无偏性假设,即指:期望值为 3:同共方差性假设,即指,所有的4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。
今天跟大家一起讨论一下, SPSS---多元线性回归的具体操作过程, 下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。
通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。
数据如下图所示:V = B Q +02] +角工2 + -…+y =>'2*a A1X"1儿丿,0 二卩\■■■ ■丿 /鞋丿其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释1服成正太分布,即指:随机误差必须是服成正太分别的随机变量。
随机误差变量方差都相等“分析”一一回归一一线性一一进入如下图所示的界面:1 salesnesaletyp&priceengiriE 」horse pow , wheelbaswidth ] length1S.919' 16 360 0 21.500!1.8140 101.2 67.3 172.4 39 364 19S75 0 2B4003 2225 108 1 70 3 192 3 14.114 18225 0 - 3.2 225 106.9 70.5 192.0 8 588 29 725 0 42 000 3-S' 210 114 6 71 4 1966 20 397 2225S 0 33.990 1.8 150 1O2?6 63 2 178.0 1378023i'S5'5 033 9&0 28 200 108 7 76 1 192 O' 138039 00062 000 第 310 113 0 74 Q 1982 19 747 -0 26.9902.5 170 107.3 63.4 1176.01 9_231 2Se75 0 33 400 I2.8133 107 3 63 5 17'6 O' 17.537 3& 13S 0| 3S.900 ; 2-8 1931114 70.9 188.0 91 561 12-475 0 21 9751 ! 31 175 1i0'9 0 72 7194.6 39.3£0 13.740 0 25.300 , 3.3 240 109 0 72 7 196^2 27 861 20 190' 0 31.965j : 3.3 205 1138 747 206.8 S326Z 13 360'0 27 635 1 30 205 1122 73 5 200 0 63.72&22525 0 39.E95 ; 壮 275 115.3 74.5 2072 15 94327 100' O '44-475 1 46 275 112 2 75 0 201 0 e.53G 25725 0 39.G&5 , 4.6 275 108.0 75 S 200.G 11 IBS IS 2250 31 CIO i30 2C0 107 4 70 3 194呂 14.785 - 1 46.225;! 5 7 355 117.5 77.0 201.2 US. 519' 9.250' 0 13 2S0 2.2, 115 104.1 67 9 ieo'9 135 12611 22516 6351 ; 3 1 170 107 0 69 4 1904 24.62& 10.3110'0| 1S.S90 1 3.1 175 110I7.& 72 S200.9 42 593 11 525O '19 390134180110 572 7197 9curt点击蛆厂逛[manuracl]Mod si [mo'del I 炉新车售价(单位=... 茨拜肯二手车售价… £| Vehicle 射pg [typ 鬪 捞'Price in thousand... 炉 Engine size [engi... 袴 Horsep'OW'erlhor... 夕'jVlieelba3€ |whe…, 拧车宽[WFdlhl 務军衽[lergtA] 少车净垂[curb.wgt] 少 Fuel capacity 拐耗油量辺硏Inpgj @ Cooks Dfstance [... 少 95铀 LCI forinsa... 撐95«i4UCliforInsa...LCI kr Insa...将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等个自变量 拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可 以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示 的结果:(所有的自变量,都会强行进入)輸入/窿去的吏量h移去的娈量左法 1油量迎册, 车稳 Price in tnoLJsands,Vehicle type, 车毘Engine size, Fuel capacity, Wheelbase, 军淨重, Horsepower输入a. 已输入斯肓诸號的吏量•b. 因变呈:Log-transformecJ sales如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“ 计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,J [,牯贴£川重置迟)]〔取消j [ M Ja 篷择变>(E >:! J一个对签Q* I 护 Pneo 需thousands [price]VVLS 权重®:10块1的1 ijj Veliicleb'peltyipeJPrice inthodsandslprice] $ Engine siz&Iergine^s]贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于,当概率值大于等于时将会被剔除)“选择变量(E)"框内,我并没有输入数据,如果你需要对某个“自变量”进行条件筛选, 可以将那个自变量,移入“选择变量框”内,有一个前提就是:该变量从未在另一个目标列表中出现!,再点击“规则”设定相应的“筛选条件”即可,如下图所示:定义琏弃规则sales 値W:....... k.i. J .產壬一二不等于小于小于等于丸于大于等于thousands h点击“统计量”弹出如下所示的框,如下所示:□ Ddrbin*Watson(U) n 个就诊断©在“回归系数”下面勾选“估计,在右侧勾选” 模型拟合度“和”共线性诊断“两个选项, 再勾选“个案诊断”再点击“离群值”一般默认值为“3”,(设定异常值的依据,只有当残差超过3倍标准差的观测才会被当做异常值) 点击继续。

多元线性回归模型案例分析——中国人口自然增长分析一·研究目的要求中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。
此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。
影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。
(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。
二·模型设定为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。
暂不考虑文化程度及人口分布的影响。
从《中国统计年鉴》收集到以下数据(见表1):表1 中国人口增长率及相关数据设定的线性回归模型为:1222334t t t t t Y X X X u ββββ=++++三、估计参数 利用EViews 估计模型的参数,方法是:1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对话框“Workfile Range ”。
在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。
其中已有变量:“c ”—截距项 “resid ”—剩余项。

多元线性回归模型案例分析报告多元线性回归模型是一种用于预测和建立因变量和多个自变量之间关系的统计方法。
它通过拟合一个线性方程,找到使得回归方程和实际观测值之间误差最小的系数。
本报告将以一个实际案例为例,对多元线性回归模型进行案例分析。
案例背景:公司是一家在线教育平台,希望通过多元线性回归模型来预测学生的学习时长,并找出对学习时长影响最大的因素。
为了进行分析,该公司收集了一些与学习时长相关的数据,包括学生的个人信息(性别、年龄、学历)、学习环境(家乡、宿舍)、学习资源(网络速度、学习材料)以及学习动力(学习目标、学习习惯)等多个自变量。
数据分析方法:通过建立多元线性回归模型,我们可以找到与学习时长最相关的因素,并预测学生的学习时长。
首先,我们将根据实际情况对数据进行预处理,包括数据清洗、过滤异常值等。
然后,我们使用逐步回归方法,通过逐步添加和删除自变量来筛选最佳模型。
最后,我们使用已选定的自变量建立多元线性回归模型,并进行系数估计和显著性检验。
案例分析结果:经过数据分析和模型建立,我们得到了如下的多元线性回归模型:学习时长=0.5*年龄+0.2*学历+0.3*学习资源+0.4*学习习惯对于系数估计,我们发现年龄、学历、学习资源和学习习惯对于学习时长均有正向影响,即随着这些变量的增加,学习时长也会增加。
其中,年龄和学习资源的影响较大,学历和学习习惯的影响较小。
在显著性检验中,我们发现该模型的拟合度较好,因为相关自变量的p值均小于0.05,表明它们对学习时长的影响具有统计学意义。
案例启示:本案例的分析结果为在线教育平台提供了重要的参考。
公司可以针对年龄较大、学历高、学习资源丰富和有良好学习习惯的学生,提供个性化的学习服务和辅导。
同时,公司也可以通过提供更好的学习资源和培养良好的学习习惯,来提升学生的学习时长和学习效果。
总结:多元线性回归模型在实际应用中具有广泛的应用价值。
通过对因变量和多个自变量之间的关系进行建模和分析,我们可以找到相关影响因素,并预测因变量的取值。
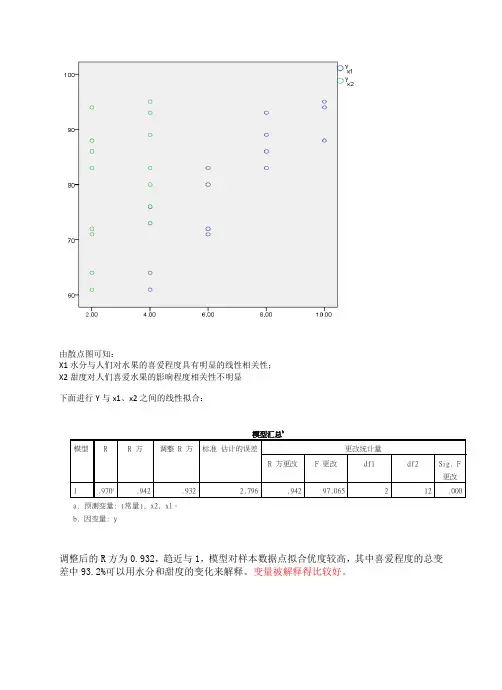
由散点图可知:
X1水分与人们对水果的喜爱程度具有明显的线性相关性;
X2甜度对人们喜爱水果的影响程度相关性不明显
下面进行Y与x1、x2之间的线性拟合:
调整后的R方为0.932,趋近与1,模型对样本数据点拟合优度较高,其中喜爱程度的总变差中93.2%可以用水分和甜度的变化来解释。
变量被解释得比较好。
H0:β
=0 (水果甜度和人们对水果的喜爱程度无显著线性关系)
2
H1:β
≠0(水果甜度和人们对水果的喜爱程度有显著线性关系)
2
P值0.000,小于0.05,拒绝原假设,接受对立假设,即水果甜度和人们对水果的喜爱程度有显著线性关系
线性回归方程:
Y=4.395x1+4.326x2+37.955
方程的解释:
在水果甜度不变的前提下,水果水分每增加1个单位,人们对水果的喜爱程度增加4.395个单位
在水果水分不变的前提下,水果甜度每增加1个单位,人们对水果的喜爱程度增加4.326个单位
残差的正态性检验:
H0:该模型的误差项符合正态性检验
H1:该模型的误差项不符合正态性检验
K-S检验的P值为0.763,大于0.05,接受原假设,该模型符合正态性检验,说明误差项的正态性假设是合理的。
残差的方差齐性检验:
上述散点图水果水分与误差近似分布在一条水平的带状线中,那么就可以认为残差的齐性假设是合理的。
散点图水果甜度与误差近似分布在一条垂直的带状线中,可以认为残差的齐性假设是不合理的。
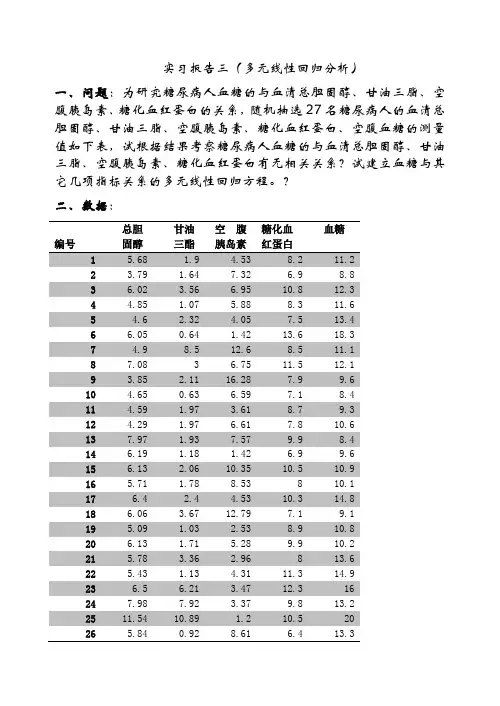
实习报告三(多元线性回归分析)一、问题:为研究糖尿病人血糖的与血清总胆固醇、甘油三脂、空腹胰岛素、糖化血红蛋白的关系,随机抽选27名糖尿病人的血清总胆固醇、甘油三脂、空腹胰岛素、糖化血红蛋白、空腹血糖的测量值如下表,试根据结果考察糖尿病人血糖的与血清总胆固醇、甘油三脂、空腹胰岛素、糖化血红蛋白有无相关关系?试建立血糖与其它几项指标关系的多元线性回归方程。
?二、数据:编号总胆固醇甘油三酯空腹胰岛素糖化血红蛋白血糖2 3.79 1.64 7.32 6.9 8.83 6.02 3.56 6.95 10.8 12.34 4.85 1.07 5.88 8.3 11.65 4.6 2.32 4.05 7.5 13.46 6.05 0.64 1.42 13.6 18.37 4.9 8.5 12.6 8.5 11.18 7.08 3 6.75 11.5 12.19 3.85 2.11 16.28 7.9 9.610 4.65 0.63 6.59 7.1 8.411 4.59 1.97 3.61 8.7 9.312 4.29 1.97 6.61 7.8 10.613 7.97 1.93 7.57 9.9 8.414 6.19 1.18 1.42 6.9 9.615 6.13 2.06 10.35 10.5 10.916 5.71 1.78 8.53 8 10.117 6.4 2.4 4.53 10.3 14.818 6.06 3.67 12.79 7.1 9.119 5.09 1.03 2.53 8.9 10.820 6.13 1.71 5.28 9.9 10.221 5.78 3.36 2.96 8 13.622 5.43 1.13 4.31 11.3 14.923 6.5 6.21 3.47 12.3 1624 7.98 7.92 3.37 9.8 13.225 11.54 10.89 1.2 10.5 2026 5.84 0.92 8.61 6.4 13.3三、统计处理:该实际问题涉及五个连续型随机变量:血清总胆固醇()、甘油三脂()、空腹胰岛素()、糖化血红蛋白()、血糖(Y)。
多元线性回归模型实验报告实验报告:多元线性回归模型1.实验目的多元线性回归模型是统计学中一种常用的分析方法,通过建立多个自变量和一个因变量之间的模型,来预测和解释因变量的变化。
本实验的目的是利用多元线性回归模型,分析多个自变量对于因变量的影响,并评估模型的准确性和可靠性。
2.实验原理多元线性回归模型的基本假设是自变量与因变量之间存在线性关系,误差项为服从正态分布的随机变量。
多元线性回归模型的表达形式为:Y=b0+b1X1+b2X2+...+bnXn+ε,其中Y表示因变量,X1、X2、..、Xn表示自变量,b0、b1、b2、..、bn表示回归系数,ε表示误差项。
3.实验步骤(1)数据收集:选择一组与研究对象相关的自变量和一个因变量,并收集相应的数据。
(2)数据预处理:对数据进行清洗和转换,排除异常值、缺失值和重复值等。
(3)模型建立:根据收集到的数据,建立多元线性回归模型,选择适当的自变量和回归系数。
(4)模型评估:通过计算回归方程的拟合优度、残差分析和回归系数的显著性等指标,评估模型的准确性和可靠性。
4.实验结果通过实验,我们建立了一个包含多个自变量的多元线性回归模型,并对该模型进行了评估。
通过计算回归方程的拟合优度,我们得到了一个较高的R方值,说明模型能够很好地拟合观测数据。
同时,通过残差分析,我们检查了模型的合理性,验证了模型中误差项的正态分布假设。
此外,我们还对回归系数进行了显著性检验,确保它们是对因变量有显著影响的。
5.实验结论多元线性回归模型可以通过引入多个自变量,来更全面地解释因变量的变化。
在实验中,我们建立了一个多元线性回归模型,并评估了模型的准确性和可靠性。
通过实验结果,我们得出结论:多元线性回归模型能够很好地解释因变量的变化,并且模型的拟合优度较高,可以用于预测和解释因变量的变异情况。
同时,我们还需注意到,多元线性回归模型的准确性和可靠性受到多个因素的影响,如样本大小、自变量的选择等,需要在实际应用中进行进一步的验证和调整。
中国税收增长的分析一、研究的目的要求改革开放以来,随着经济体制的改革深化和经济的快速增长,中国的财政收支状况发生了很大的变化,中央和地方的税收收入1978年为519.28亿元到2002年已增长到17636.45亿元25年间增长了33倍。
为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。
影响中国税收收入增长的因素很多,但据分析主要的因素可能有:〔1〕从宏观经济看,经济整体增长是税收增长的基根源泉。
〔2〕公共财政的需求,税收收入是财政的主体,社会经济的开展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收入可能有一定的影响。
〔3〕物价水平。
我国的税制结构以流转税为主,以现行价格计算的DGP等指标和和经营者收入水平都与物价水平有关。
〔4〕税收政策因素。
我国自1978年以来经历了两次大的税制改革,一次是1984—%。
但是第二次税制改革对税收的增长速度的影响不是非常大。
因此可以从以上几个方面,分析各种因素对中国税收增长的具体影响。
二、模型设定为了反映中国税收增长的全貌,选择包括中央和地方税收的‘国家财政收入’中的“各项税收〞〔简称“税收收入〞〕作为被解释变量,以反映国家税收的增长;选择“国内生产总值〔GDP〕〞作为经济整体增长水平的代表;选择中央和地方“财政支出〞作为公共财政需求的代表;选择“商品零售物价指数〞作为物价水平的代表。
由于税制改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑。
所以解释变量设定为可观测“国内生产总值〔GDP〕〞、“财政支出〞、“商品零售物价指数〞从《中国统计年鉴》收集到以下数据年份财政收入〔亿元〕Y国内生产总值(亿元〕X2财政支出〔亿元〕X3商品零售价格指数〔%)X419781979 102 1980 106 1981198219831984 717119851986 106 1987198819891990199119921993199419951996199719981999 97 200020012002设定线性回归模型为:Y i=β0+β2X2+β3X3+β4X4+μ三、参数估计利用eviews软件可以得到Y关于X2的散点图:可以看出Y和X2成线性相关关系Y关于X3的散点图:可以看出Y和X3成线性相关关系Y关于X4的散点图:Dependent Variable: YMethod: Least SquaresDate: 12/01/09 Time: 13:16Sample: 1978 2002Included observations: 25Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid 1463163. Schwarz criterionLog likelihood F-statisticDurbin-Watson stat Prob(F-statistic)模型估计的结果为:Y i=+0.022067X2+X3+X4(940.6119) (0.0056) (0.0332) (8.7383)t={-2.7458} {3.9567} {21.1247} {2.7449}R2=0.997 R2=0.997 F=2717.254 df=21四、模型检验模型估计结果说明,在假定其他变量不变的情况下,当年GDP每增长1亿元,税收收入就会增长0.02207亿元;在假定其他变量不变的情况下,当年财政支出每增长1亿元,税收收入就会增长0.7021亿元;在假定其他变量不变的情况下,当零售商品物价指数上涨一个百分点,税收收入就会增长23.985亿元。
多元线性回归模型案例分析报告多元线性回归模型案例分析——中国人口自然增长分析一·讨论目的要求中国从1971年开头全面开展了方案生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,临近世代更替水平。
此后,人口自然增长率(即人口的生育率)很大程度上与经济的进展等各方面的因素相联系,与经济生活息息相关,为了讨论此后影响中国人口自然增长的主要缘由,分析全国人口增长逻辑,与猜想中国将来的增长趋势,需要建立计量经济学模型。
影响中国人口自然增长率的因素有无数,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的凹凸可能会间接影响人口增长率。
(3)文化程度,因为教导年限的凹凸,相应会改变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。
二·模型设定为了全面反映中国“人口自然增长率”的全貌,挑选人口增长率作为被解释变量,以反映中国人口的增长;挑选“国名收入”及“人均GDP”作为经济整体增长的代表;挑选“居民消费价格指数增长率”作为居民消费水平的代表。
暂不考虑文化程度及人口分布的影响。
从《中国统计年鉴》收集到以下数据(见表1):表1 中国人口增长率及相关数据设定的线性回归模型为:1222334t t t t t Y X X X u ββββ=++++三、估量参数利用EViews 估量模型的参数,办法是:1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对话框“Workfile Range ”。
在“Workfile frequency ”中挑选“Annual ” (年度),并在“Start date ”中输入开头时光“1988”,在“end date ”中输入最后时光“2022”,点击“ok ”,浮现“Workfile UNTITLED ”工作框。
多元线性回归实例分析报告多元线性回归是一种用于预测目标变量和多个自变量之间关系的统计分析方法。
它可以帮助我们理解多个自变量对目标变量的影响,并通过建立回归模型进行预测。
本文将以一个实例为例,详细介绍多元线性回归的分析步骤和结果。
假设我们研究了一个电子产品公司的销售数据,并想通过多元线性回归来预测销售额。
我们收集了以下数据:目标变量(销售额)和三个自变量(广告费用、产品种类和市场规模)。
首先,我们需要对数据进行探索性分析,了解数据的分布、缺失值等情况。
我们可以使用散点图和相关系数矩阵来查看变量之间的关系。
通过绘制广告费用与销售额的散点图,我们可以观察到一定的正相关关系。
相关系数矩阵可以用来度量变量之间的线性关系的强度和方向。
接下来,我们需要构建多元线性回归模型。
假设目标变量(销售额)与三个自变量(广告费用、产品种类和市场规模)之间存在线性关系,模型可以表示为:销售额=β0+β1*广告费用+β2*产品种类+β3*市场规模+ε其中,β0是截距,β1、β2和β3是回归系数,ε是误差项。
我们可以使用最小二乘法估计回归系数。
最小二乘法可以最小化目标变量的预测值和实际值之间的差异的平方和。
通过计算最小二乘估计得到的回归系数,我们可以建立多元线性回归模型。
在实际应用中,我们通常使用统计软件来进行多元线性回归分析。
通过输入相应的数据和设置模型参数,软件会自动计算回归系数和其他统计指标。
例如,我们可以使用Python的statsmodels库或R语言的lm函数来进行多元线性回归分析。
最后,我们需要评估回归模型的拟合程度和预测能力。
常见的评估指标包括R方值和调整R方值。
R方值可以描述自变量对因变量的解释程度,值越接近1表示拟合程度越好。
调整R方值考虑了模型中自变量的个数,避免了过度拟合的问题。
在我们的实例中,假设我们得到了一个R方值为0.8的多元线性回归模型,说明模型可以解释目标变量80%的方差。
这个模型还可以用来进行销售额的预测。
多元线性回归模型的案例分析在实际生活中,多元线性回归模型可以广泛应用于各个领域。
以下是一个案例分析,以说明多元线性回归模型的应用。
案例:房价预测背景:城市的房地产公司想要推出一款房屋估价服务,帮助人们预测房屋的销售价格。
他们收集了一些相关数据,如房屋的面积、房间的数量、地理位置等因素,并希望通过建立一个多元线性回归模型来实现房价的预测。
步骤:1.数据收集:收集相关数据。
在本案例中,我们收集到了50个样本数据,每个样本包含了房屋的面积、房间的数量和房屋的销售价格。
2.数据预处理:对数据进行预处理,包括缺失值处理、异常值处理等。
在本案例中,我们假设数据已经经过清洗,没有缺失值和异常值。
3.特征选择:选择合适的特征变量。
在本案例中,我们选择房屋的面积和房间的数量作为特征变量,房屋的销售价格作为目标变量。
4.模型建立:建立多元线性回归模型。
根据特征变量和目标变量的关系,建立多元线性回归方程。
在本案例中,假设多元线性回归方程为:房价=β0+β1×面积+β2×房间数量+ε,其中β0、β1和β2分别为回归系数,ε为误差项。
5.模型训练:使用样本数据对模型进行训练。
通过最小二乘法等方法,估计出回归系数的取值。
6.模型评估:评估模型的性能。
通过计算模型的均方误差(MSE)、决定系数(R²)等指标,评估模型的拟合效果和预测能力。
7.模型应用:将模型用于房价的预测。
当有新的房屋数据输入时,通过模型的预测方程,可以得到该房屋的预测销售价格。
通过上述步骤,我们可以建立一个多元线性回归模型,并通过该模型对房价进行预测。
这个模型可以帮助房地产公司提供房价估价服务,也可以帮助购房者了解合理的房价范围。
《多元线性回归分析的实例研究》篇一一、引言多元线性回归分析是一种统计方法,用于研究多个变量之间的关系。
在社会科学、经济学、管理学等多个领域中,它被广泛用于预测和解释一个变量如何受到多个其他变量的影响。
本文将通过一个实际案例,详细介绍多元线性回归分析的应用过程。
二、案例背景假设我们正在研究一个城市的新房销售价格与其相关因素的关系。
我们假设新房的销售价格受到以下因素的影响:房屋面积、地理位置、房屋年龄、装修情况以及开发商的声誉。
我们的目标是建立一个多元线性回归模型,以解释这些因素如何共同影响新房的销售价格。
三、数据收集与处理我们收集了该城市近一年内的新房销售数据,包括每套房子的销售价格、面积、地理位置(用经纬度表示)、房屋年龄、装修情况(分为精装、简装、毛坯等)以及开发商的声誉(以评分形式表示)。
在数据清洗阶段,我们剔除了异常值和缺失值,并对数据进行标准化处理,以便更好地进行后续分析。
四、模型构建与假设基于收集的数据,我们假设多元线性回归模型如下:销售价格= f(房屋面积, 地理位置, 房屋年龄, 装修情况, 开发商声誉)其中,f表示一个线性函数,它反映了各个因素对销售价格的影响。
我们的目标是利用统计软件(如SPSS、SAS等)来估计这个函数的具体形式。
五、多元线性回归分析过程1. 数据描述性统计:首先,我们对数据进行描述性统计分析,了解各变量的分布情况。
这有助于我们判断数据是否满足多元线性回归分析的假设条件。
2. 模型拟合:利用统计软件,我们将数据输入到多元线性回归模型中,进行模型拟合。
这一步将估计出各个变量的系数以及模型的截距。
3. 模型检验:我们对模型进行检验,包括检查模型的显著性、各个自变量的显著性以及模型的多重共线性等问题。
如果模型通过检验,我们可以认为它是一个有效的模型,可以用来解释变量之间的关系。
4. 结果解释:根据模型估计结果,我们可以解释各个因素对销售价格的影响程度。
例如,如果房屋面积的系数为正且显著,那么我们可以认为房屋面积是影响销售价格的重要因素。
SPSS--回归-多元线性回归模型案例解析!(一)
多元线性回归,主要就是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程
为:
毫无疑问,多元线性回归方程应该
为:
上图中的 x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示:
那么,多元线性回归方程矩阵形式为:
其中:代表随机误差, 其中随机误差分为:可解释的误差与不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样)
1:服成正太分布,即指:随机误差必须就是服成正太分别的随机变量。
2:无偏性假设,即指:期望值为0
3:同共方差性假设,即指,所有的随机误差变量方差都相等
4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。
今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。
通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。
数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内, 将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,您也可以选择其它的方式,如果您选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入)
如果您选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该就是跟“因变量”关系最为密切,
贡献最大的,如下图可以瞧出,车的价格与车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0、05,当概率值大于等于0、1时将会被剔除)
“选择变量(E)" 框内,我并没有输入数据,如果您需要对某个“自变量”进行条件筛选,可以将那个自变量,移入“选择变量框”内,有一个前提就就是:该变量从未在另一个目标列表中出现!,再点击“规则”设定相应的“筛选条件”即可,如下图所示:
点击“统计量”弹出如下所示的框,如下所示:
在“回归系数”下面勾选“估计,在右侧勾选”模型拟合度“与”共线性诊断“两个选项,再勾选“个案诊断”再点击“离群值”一般默认值为“3”,(设定异常值的依据,只有当残差超过3倍标准差的观测才会被当做异常值) 点击继续。
提示:
共线性检验,如果有两个或两个以上的自变量之间存在线性相关关系,就会产生多重共线性现象。
这时候,用最小二乘法估计的模型参数就会不稳定,回归系数的估计值很容易引起误导或者导致错误的结论。
所以,需要勾选“共线性诊断”来做判断
通过容许度可以计算共线性的存在与否?容许度TOL=1-RI平方或方差膨胀因子(VIF): VIF=1/1-RI平方,其中RI平方就是用其她自变量预测第I个变量的复相关系数,显然,VIF为TOL的倒数,TOL的值越小,VIF的值越大,自变量XI与其她自变量之间存在共线性的可能性越大。
提供三种处理方法:
1:从有共线性问题的变量里删除不重要的变量
2:增加样本量或重新抽取样本。
3:采用其她方法拟合模型,如领回归法,逐步回归法,主成分分析法。
再点击“绘制”选项,如下所示:
上图中:
DEPENDENT( 因变量) ZPRED(标准化预测值) ZRESID(标准化残差) DRESID(剔除残差) ADJPRED(修正后预测值) SRSID(学生化残差) SDRESID(学生化剔除残差)
一般我们大部分以“自变量”作为 X 轴,用“残差”作为Y轴, 但就是,也不要忽略特殊情况,这里我们以“ZPRED(标准化预测值)作为"x" 轴,分别用“SDRESID(血生化剔除残差)”与“ZRESID(标准化残差)作为Y轴,分别作为两组绘图变量。
再点击”保存“按钮,进入如下界面:
如上图所示:勾选“距离”下面的“cook距离”选项 (cook 距离,主要就是指:把一个个案从计算回归系数的样本中剔除时所引起的残差大小,cook距离越大,表明该个案对回归系数的影响也越大)
在“预测区间”勾选“均值”与“单值”点击“继续”按钮,再点击“确定按钮,得到如下所示的分析结果:(此分析结果,采用的就是“逐步法”得到的结果)
SPSS—回归—多元线性回归结果分析(二)
,最近一直很忙,公司的潮起潮落,就好比人生的跌岩起伏,眼瞧着一步步走向衰弱,却无能为力,也许要学习“步步惊心”里面“四阿哥”的座右铭:“行到水穷处”,”坐瞧云起时“。
接着上一期的“多元线性回归解析”里面的内容,上一次,没有写结果分析,这次补上,结果分析如下所示:
结果分析1:
由于开始选择的就是“逐步”法,逐步法就是“向前”与“向后”的结合体,从结果可以瞧出,最先进入“线性回归模型”的就是“price in thousands" 建立了模型1,紧随其后的就是“Wheelbase" 建立了模型2,所以,模型中有此方法有个概率值,当小于等于0、05时,进入“线性回归模型”(最先进入模型的,相关性最强,关系最为密切)当大于等0、1时,从“线性模型中”剔除
结果分析:
1:从“模型汇总”中可以瞧出,有两个模型,(模型1与模型2)从R2 拟合优度来瞧,模型2的拟合优度明显比模型1要好一些
(0、422>0、300)
2:从“Anova"表中,可以瞧出“模型2”中的“回归平方与”为115、311,“残差平方与”为153、072,由于总平方与=回归平方与+残差平方与,由于残差平方与(即指随即误差,不可解释的误差)由于“回归平方与”跟“残差平方与”几乎接近,所有,此线性回归模型只解释了总平方与的一半,
3:根据后面的“F统计量”的概率值为0、00,由于0、00<0、01,随着“自变量”的引入,其显著性概率值均远小于0、01,所以可以显著地拒绝总体回归系数为0的原假设,通过ANOVA 方差分析表可以瞧出“销售量”与“价格”与“轴距”之间存在着线性关系,至于线性关系
的强弱,需要进一步进行分析。
结果分析:
1:从“已排除的变量”表中,可以瞧出:“模型2”中各变量的T检的概率值都大于“0、05”所以,不能够引入“线性回归模型”必须剔除。
从“系数a”表中可以瞧出:
1:多元线性回归方程应该为:销售量=-1、822-0、055*价格+0、061*轴距
但就是,由于常数项的sig为(0、116>0、1) 所以常数项不具备显著性,所以,我们再瞧后面的“标准系数”,在标准系数一列中,可以瞧到“常数项”没有数值,已经被剔除
所以:标准化的回归方程为:销售量=-0、59*价格+0、356*轴距
2:再瞧最后一列“共线性统计量”,其中“价格”与“轴距”两个容差与“vif都一样,而且VIF都为1、012,且都小于5,所以两个自变量之间没有出现共线性,容忍度与
膨胀因子就是互为倒数关系,容忍度越小,膨胀因子越大,发生共线性的可能性也越大
从“共线性诊断”表中可以瞧出:
1:共线性诊断采用的就是“特征值”的方式,特征值主要用来刻画自变量的方差,诊断自变量间就是否存在较强多重共线性的另一种方法就是利用主成分分析法,基本思想就是:如果自变量间确实存在较强的相关关系,那么它们之间必然存在信息重叠,于就是就可以从这些自变量中提取出既能反应自变量信息(方差),而且有相互独立的因素(成分)来,该方法主要从自变量间的相关系数矩阵出发,计算相关系数矩阵的特征值,得到相应的若干成分。
从上图可以瞧出:从自变量相关系数矩阵出发,计算得到了三个特征值(模型2中),最大特征值为2、847, 最小特征值为0、003
条件索引=最大特征值/相对特征值再进行开方 (即特征值2的条件索引为 2、847/0、150 再开方=4、351)
标准化后,方差为1,每一个特征值都能够刻画某自变量的一定比例,所有的特征值能将刻画某自变量信息的全部,于就是,我们可以得到以下结论:
1:价格在方差标准化后,第一个特征值解释了其方差的0、02, 第二个特征值解释了0、97,第三个特征值解释了0、00
2:轴距在方差标准化后,第一个特征值解释了其方差的0、00, 第二个特征值解释了0、01,第三个特征值解释了0、99
可以瞧出:没有一个特征值,既能够解释“价格”又能够解释“轴距”所以“价格”与“轴距”之间存在共线性较弱。
前面的结论进一步得到了论证。
(残差统计量的表中数值怎么来的,这个计算过程,我就不写了)
从上图可以得知:大部分自变量的残差都符合正太分布,只有一,两处地方稍有偏离,如图上的(-5到-3区域的)处理偏离状态。