最小二乘法一元线性回归
- 格式:ppt
- 大小:977.00 KB
- 文档页数:58




8.2.1一元线性回归模型1.生活经验告诉我们,儿子的身高与父亲的身高相关.一般来说,父亲的身高较高时,儿子的身高通常也较高.为了进一步研究两者之间的关系,有人调查了14名男大学生的身高及其父亲的身高,得到的数据如表1所示.编号1234567891011121314父亲身高/cm 174 170 173 169 182 172 180 172 168 166 182 173 164 180 儿子身高/cm 176 176 170 170 185 176 178 174 170 168 178 172 165 182从图上看,散点大致分布在一条直线附近根据我们学过的整理数据的方法:相关系数r =0.886.父亲身高/cm180 175 170 165 160160 165 170 175180 185 190 ·· ·· · · · 儿子身高/cm· · · · ·185 1).问题1:可以得到什么结论?由散点图的分布趋势表明儿子的身高与父亲的身高线性相关,通过相关系数可知儿子的身高与父亲的身高正线性相关,且相关程度较高.2).问题2:是否可以用函数模型来刻画?不能,因为不符合函数的定义.这其中还受其它因素的影响.3).问题3:那么影响儿子身高的其他因素是什么?影响儿子身高的因素除父亲的身外,还有母亲的身高、生活的环境、饮食习惯、营养水平、体育锻炼等随机的因素,儿子身高是父亲身高的函数的原因是存在这些随机的因素.4).问题4: 你能否考虑到这些随机因素的作用,用类似于函数的表达式,表示儿子身高与父亲身高的关系吗?用x表示父亲身高,Y表示儿子的身高,用e表示各种其它随机因素影响之和,称e为随机误差, 由于儿子身高与父亲身高线性相关,所以Y=bx+a.考虑随机误差后,儿子的身高可以表示为:Y=bx+a+e由于随机误差表示大量已知和未知的各种影响之和,它们会相互抵消,为使问题简洁,可假设随机误差e的均值为0,方差为与父亲身高无关的定值 . 2σ2即E e D eσ:()0,().==我们称①式为Y 关于x 的一元线性回归模型,其中,Y 称为因变量或响应变量,x 称为自变量或解释变量 . a 称为截距参数,b 称为斜率参数;e 是Y 与bx+a 之间的随机误差.2,()0,().Y bx a e E e D e σ=++⎧⎨==⎩① 2、一元线性回归模型如果用x 表示父亲身高,Y 表示儿子的身高,e 表示随机误差.假定随机误差e 的均值为0,方差为与父亲身高无关的定值 ,则它们之间的关系可以表示为2σ4.问题5:你能结合具体实例解释产生模型①中随机误差项的原因吗?产生随机误差e的原因有:(1)除父亲身高外,其他可能影响儿子身高的因素,比如母亲身高、生活环境、饮食习惯和锻炼时间等.(2)在测量儿子身高时,由于测量工具、测量精度所产生的测量误差.(3)实际问题中,我们不知道儿子身高和父亲身高的相关关系是什么,可以利用一元线性回归模型来近似这种关系,这种近似关系也是产生随机误差e的原因.8.2.2一元线性回归模型参数的最小二乘法估计二、自主探究问题1.为了研究两个变量之间的相关关系, 我们建立了一元线性回归模型表达式 刻画的是变量Y 与变量x 之间的线性相关关系,其中参数a 和b 未知,我们如何通过样本数据估计参数a 和b?2,()0,().Y bx a e E e D e σ=++⎧⎨==⎩问题2.我们怎样寻找一条“最好”的直线,使得表示成对样本数据的这些散点在整体上与这条直线最“接近”?从成对样本数据出发,用数学的方法刻画“从整体上看,各散点与蓝色直线最接近”利用点到直线y=bx+a 的“距离”来刻画散点与该直线的接近程度,然后用所有“距离”之和刻画所有样本观测数据与该直线的接近程度.父亲身高/cm180 175 170 165 160160 165 170 175180 185 190 ·· ·· · · · 儿子身高/cm· · · · ·185 父亲身高/cm180 175 170 165 160160 165 170 175 180 185 190·· ·· · · · 儿子身高/cm· · · · ·185设满足一元线性回归模型的两个变量的n 对样本数据为(x 1,y 1),(x 2,y 2),…,(x n ,y n )父亲身高/cm180 175170165 160160165 170 175 180 185 190·· · · · · · 儿子身高/cm· ·· · · 185()()(1,2,3,,-).i i i i i i i i i i i y bx a e i n y bx a e e x y x bx a =++=⋅⋅⋅+=+由),得(显然越小,表示点,与点,的距离越小,()0,.i i i x y =即样本数据点离直线y=bx+a 的竖直距离越小,如上图特别地,当e 时,表示点在这条直线上1-)ni i i y bx a =+∑因此可用(来刻画各样本观测数据与直线y=bx+a 的整体接近程度.()iix y ,y=bx+a()i i x bx a +,·[]21(,)()ni i i Q a b y bx a ==-+∑残差平方和: 即求a ,b 的值,使Q ( a ,b )最小残差:实际值与估计值之间的差值,即 使Q 取得最小值,当且仅当b 的取值为121()()()nii i nii xx y y b xx ==--=-∑∑b.,ˆ,ˆ的最小二乘估计叫做求得a b a b(,).x y 经验回顾直线必经过的符号相同与相关系数r b ˆ最小二乘法我们将 称为Y 关于x 的经验回归方程,也称经验回归函数或经验回归公式,其图形称为经验回归直线,这种求经验回归方程的方法叫最小二乘法.ˆˆˆy bxa =+12111=i ni n22i ni n x x y y ˆb ,x x ˆˆa x y x y x xy b .i i i i i i ΣΣx )n ΣΣ(()()n ====⎧--⎪=⎪⎨-⎪⎪--=⎩-问题2:依据用最小二乘估计一元线性回归模型参数的公式,求出儿子身高Y 关于父亲身高x 的经验回归方程.儿子的身高不一定会是177cm ,这是因为还有其他影响儿子身高的因素,回归模型中的随机误差清楚地表达了这种影响,父亲的身高不能完全决定儿子的身高,不过,我们可以作出推测,当父亲的身高为176cm 时,儿子身高一般在177cm 左右.当x=176时, ,如果一位父亲身高为176cm,他儿子长大后身高一定能长到177cm 吗?为什么?177y ≈083928957ˆy .x .=+的意义?∧b残差的定义,e a bx Y ++=一元线性回归模型,,Y y 对于通过观测得响应到的数据称量为变观测值ˆ,y通过经验回归方程得到称为预报值的ˆ.ˆey y =-残观测值减去预报值称为即差判断模型拟合的效果:残差分析问题3:儿子身高与父亲身高的关系,运用残差分析所得的一元线性回归模型的有效性吗?残差图:作图时纵坐标为残差,横坐标可以选为样本编号,或身高数据或体重估计值等,这样作出的图形称为残差图.从上面的残差图可以看出,残差有正有负,残差点比较均匀地分布在横轴的两边,可以判断样本数据基本满足一元线性回归模型对于随机误差的假设.所以,通过观察残差图可以直观判断样本数据是否满足一元线性回归模型的假设,从而判断回归模型拟合的有效性.所以,只有图(4)满足一元线性回归模型对随机误差的假设图(1)显示残差与观测时间有线性关系,应将时间变量纳入模型; 图(2)显示残差与观测时间有非线性关系,应在模型中加入时间的非线性函数部分; 图(3)说明残差的方差不是一个常数,随观测时间变大而变大图(4)的残差比较均匀地集中在以横轴为对称轴的水平带状区域内.根据一元线性回归模型中对随机误差的假定,残差应是均值为0,方差为 的随机变量的观测值.2σ观察以下四幅残差图,你认为哪一个残差满足一元线性回归模型中对随机误差的假定?1.残差等于观测值减预测值2.残差的平方和越小越好;3.原始数据中的可疑数据往往是残差绝对值过大的数据;4. 对数据刻画效果比较好的残差图特征:残差点比较均匀的集中在水平带状区域内.归纳小结(残差图中带状越窄,精度越高)1.关于残差图的描述错误的是( )A.残差图的横坐标可以是样本编号B.残差图的横坐标也可以是解释变量或预报变量C.残差点分布的带状区域的宽度越窄相关指数越小D.残差点分布的带状区域的宽度越窄残差平方和越小C 三、巩固提升2.根据如下样本数据:得到的经验回归方程为 ,则( ) A. >0, >0B. >0, <0C. <0, >0D. <0, <0 x 2 3 4 5 6 Y42.5-0.5-2-3a $a $a $a$$b $b$b$b $$ybx a =+$ B3.某种产品的广告支出费用x(单位:万元)与销售额Y(单位:万元)的数据如表:已知Y 关于x 的经验回归方程为 =6.5x+17.5,则当广告支 出费用为5万元时,残差为________. x 2 4 5 6 8Y 30 40 60 50 70$y当x=5时, =6.5×5+17.5=50,表格中对应y=60,于是残差为60-50=10.$y10一元线性回归模型的应用例1.经验表明,对于同一树种,一般树的胸径(树的主干在地面以上1.3m处的直径)越大,树就越高.由于测量树高比测量胸径困难,因此研究人员希望由胸径预测树高.在研究树高与胸径之间的关系时,某林场收集了某种树的一些数据如下表所示,试根据这些数据建立树高关于胸径的经验回归方程.编号 1 2 3 4 5 6胸径/cm 18.1 20.1 22.2 24.4 26.0 28.3树高/m 18.8 19.2 21.0 21.0 22.1 22.1编号7 8 9 10 11 12胸径/cm 29.6 32.4 33.7 35.7 38.3 40.2树高/m 22.4 22.6 23.0 24.3 23.9 24.7dh· · ·· · · · · · · · · 解: 以胸径为横坐标,树高为纵坐标作散点图如下:散点大致分布在一条从左下角到右上角的直线附近,表明两个变量线性相关,并且是正相关,因此可以用一元线性回归模型刻画树高与胸径之间的关系.0.249314.84h d =+··· ·· · · · · · · · 用d 表示胸径,h 表示树高,根据据最小二乘法,计算可得经验回归方程为0.249314.84h d =+根据经验回归方程,由胸径的数据可以计算出树高的预测值(精确到0.1)以及相应的残差,如下表所示.编号胸径/cm 树高观测值/m 树高预测值/m 残差/m1 18.1 18.8 19.4 -0.62 20.1 19.2 19.9 -0.73 22.2 21.0 20.4 0.64 24.4 21.0 20.9 0.15 26.0 22.1 21.3 0.86 28.3 22.1 21.9 0.27 29.6 22.4 22.2 0.28 32.4 22.6 22.9 -0.39 33.7 23.0 23.2 -0.210 35.7 24.3 23.7 0.611 38.3 23.9 24.4 -0.512 40.2 24.7 24.9 -0.2以胸径为横坐标,残差为纵坐标,作残差图,得到下图.30252015-1.0-0.5 0.0 0.5 1.0· · · · · · · 残差/m· · · ·· 354045胸径/cm观察残差表和残差图,可以看到残差的绝对值最大是0.8,所有残差分布在以横轴为对称轴、宽度小于2的带状区域内 .可见经验回归方程较好地刻画了树高与胸径的关系,我们可以根据经验回归方程由胸径预测树高.编号1 2 3 4 5 6 7 8 年份 1896 1912 1921 1930 1936 1956 1960 1968 记录/s 11.8010.6010.4010.3010.2010.1010.009.95例2.人们常将男子短跑100m 的高水平运动员称为“百米飞人”.下表给出了1968年之前男子短跑100m 世界纪录产生的年份和世界纪录的数据.试依据这些成对数据,建立男子短跑100m 世界纪录关于纪录产生年份的经验回归方程以成对数据中的世界纪录产生年份为横坐标,世界纪录为纵坐标作散点图,得到下图在左图中,散点看上去大致分布在一条直线附近,似乎可用一元线性回归模型建立经验回归方程.将经验回归直线叠加到散点图,得到下图:76913031.4902033743.0ˆ1+-=t y用Y 表示男子短跑100m 的世界纪录,t 表示纪录产生的年份 ,利用一元线性回归模型来刻画世界纪录和世界纪录产生年份之间的关系 . 根据最小二乘法,由表中的数据得到经验回归方程为:从图中可以看到,经验回归方程较好地刻画了散点的变化趋势,请再仔细观察图形,你能看出其中存在的问题吗?你能对模型进行修改,以使其更好地反映散点的分布特征吗?仔细观察右图,可以发现散点更趋向于落在中间下凸且递减的某条曲线附近.回顾已有的函数知识,可以发现函数y=-lnx的图象具有类似的形状特征注意到100m短跑的第一个世界纪录产生于1896年, 因此可以认为散点是集中在曲线y=f(t)=c1+c2ln(t-1895)的周围,其中c1、c2为未知参数,且c2<0.y=f(t)=c1+c2ln(t-1895)这是一个非线性经验回归函数,如何利用成对数据估计参数c1、c2令x=ln(t-1895),则Y=c2x+c1对数据进行变化可得下表:编号 1 2 3 4 5 6 7 8 年份/t 1896 1912 1921 1930 1936 1956 1960 1968 x 0.00 2.83 3.26 3.56 3.71 4.11 4.17 4.29 记录/s 11.80 10.60 10.40 10.30 10.20 10.10 10.00 9.95将x=ln(t-1895)代入:得 8012653.114264398.0ˆ2+-=x y上图表明,经验回归方程对于成对数据具有非常好的拟合精度.将经验回归直线叠加到散点图,得到下图: 8012653.114264398.0ˆ2+-=x y8012653.11)1895ln(4264398.0ˆ2+--=t y经验回归方程为对于通过创纪录时间预报世界纪录的问题,我们建立了两个回归模型,得到了两个回归方程,你能判断哪个回归方程拟合的精度更好吗?8012653.114264398.0ˆ2+-=x y① 2ˆ0.4264398ln(1895)11.8012653y t =--+② 我们发现,散点图中各散点都非常靠近②的图象, 表明非线性经验回归方程②对于原始数据的拟合效果远远好于经验回归方程①.(1).直接观察法.在同一坐标系中画出成对数据散点图、非线性经验回归方程②的图象(蓝色)以及经验回归方程①的图象(红色).28212811ˆ,ˆQ Q (()0.004)0.669i i i i eu ===≈=≈∑∑8012653.114264398.0ˆ2+-=x y① 2ˆ0.4264398ln(1895)11.8012653yt =--+②(2).残差分析:残差平方和越小,模型拟合效果越好.Q 2明显小于Q 1,说明非线性回归方程的拟合效果 要优于线性回归方程.R 2越大,表示残差平方和越小,即模型的拟合效果越好 R 2越小,表示残差平方和越大,即模型的拟合效果越差. 21212ˆ()11()n i i nii i y y y y R ==-=-=--∑∑残差平方和。

《土地利用规划学》一元线性回归分析学院:资源与环境学院班级:2013009姓名:x学号:201300926指导老师:x目录一、根据数据绘制散点图: (1)二、用最小二乘法确定回归直线方程的参数: (1)1)最小二乘法原理 (1)2)求回归直线方程的步骤 (3)三、回归模型的检验: (4)1)拟合优度检验(R2): (4)2)相关系数显著性检验: (5)3)回归方程的显著性检验(F 检验) (6)四、用excel进行回归分析 (7)五、总结 (15)一、根据数据绘制散点图:◎由上述数据,以销售额为y 轴(因变量),广告支出为X 轴(自变量)在EXCEL 可以绘制散点图如下图:◎从散点图的形态来看,广告支出与销售额之间似乎存在正的线性相关关系。
大致分布在某条直线附近。
所以假设回归方程为:x y βα+=二、用最小二乘法确定回归直线方程的参数: 1)最小二乘法原理年份 1.00 2.00 3.00 4.00 5.00 6.00 7.00 8.00 9.00 10.00 广告支出(万元)x 4.00 7.00 9.00 12.00 14.00 17.00 20.00 22.00 25.00 27.00销售额y7.00 12.00 17.00 20.00 23.00 26.00 29.00 32.00 35.00 40.00最小二乘法原理可以从一组测定的数据中寻求变量之间的依赖关系,这种函数关系称为经验公式。
考虑函数y=ax+b ,其中a,b 为待定常数。
如果Pi(xi,yi)(i=1,2,...,n )在一条直线上,则可以认为变量之间的关系为y=ax+b 。
但一般说来, 这些点不可能在同一直线上. 记Ei=yi-(axi+b),它反映了用直线y=ax+b 来描述x=xi ,y=yi 时,计算值y 与实际值yi 的偏差。
当然,要求偏差越小越好,但由于Ei 可正可负,所以不能认为当∑Ei=0时,函数y=ax+b 就好好地反应了变量之间的关系,因为可能每个偏差的绝对值都很大。

回归预测法回归预测法回归预测法是指根据预测的相关性原则,找出影响预测目标的各因素,并用数学方法找出这些因素与预测目标之间的函数关系的近似表达,再利用样本数据对其模型估计参数及对模型进行误差检验,一旦模型确定,就可利用模型,根据因素的变化值进行预测。
回归预测法一元线性回归预测法(最小二乘法)公式:Y = a + b XX----自变量Y----因变量或预测量a,b----回归系数根据已有的历史数据Xi Yi i = 1,2,3,...n ( n 为实际数据点数目),求出回归系数 a , b为了简化计算,令 ( X1 + X2 + ... + Xn ) = 0,可以得出a , b 的计算公式如下:a = ( Y1 + Y2 +... + Yn ) / nb = ( X1 Y1 + X2 Y2 + ... + Xn Yn ) / ( X12 + X22 + ... + Xn2 )回归分析预测法的概念回归分析预测法,是在分析市场现象自变量和因变量之间相关关系的基础上,建立变量之间的回归方程,并将回归方程作为预测模型,根据自变量在预测期的数量变化来预测因变量关系大多表现为相关关系,因此,回归分析预测法是一种重要的市场预测方法,当我们在对市场现象未来发展状况和水平进行预测时,如果能将影响市场预测对象的主要因素找到,并且能够取得其数量资料,就可以采用回归分析预测法进行预测。
它是一种具体的、行之有效的、实用价值很高的常用市场预测方法。
回归分析预测法的分类回归分析预测法有多种类型。
依据相关关系中自变量的个数不同分类,可分为一元回归分析预测法和多元回归分析预测法。
在一元回归分析预测法中,自变量只有一个,而在多元回归分析预测法中,自变量有两个以上。
依据自变量和因变量之间的相关关系不同,可分为线性回归预测和非线性回归预测。
回归分析预测法的步骤1.根据预测目标,确定自变量和因变量明确预测的具体目标,也就确定了因变量。
如预测具体目标是下一年度的销售量,那么销售量Y就是因变量。

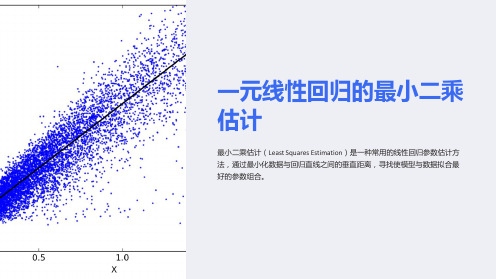

最小二乘法探究0. 前言最小二乘法发源于天体物理学,并广泛应用于其他各个学科。
最小二乘法(Least squares )又称最小平方法,一元线性回归法,是一种数学优化技术,用于建立经验公式,利用它可以把生产或实验中所积累的某些经验提高到理论上加以分析。
它通过最小化误差的平方和寻找数据的最佳函数匹配。
利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。
最小二乘法还可用于曲线拟合,是我们在建模竞赛中常用的一种手段。
一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。
最小二乘法发源于天体物理学,并广泛应用于其他各个学科。
最小二乘法对于统计学具有十分重要的意义。
相关回归分析,方差分析和线性模型理论等数理统计学的几大分支都以最小二乘法为理论基础,正如美国统计学家斯蒂格勒(S.M,Stigler )所说,“最小二乘法之于数理统计学犹如微积分之于数学”。
故对最小二乘法做一番探究进而理解并掌握这一思想是十分有必要的。
1. 原理在古汉语中“平方”称为“二乘”,“最小”指的是参数的估计值要保证各个观测点与估计点的距离的平方和达到最小。
根据教材中的描述(两个变量间的函数关系),其基本原理为: 根据已知的自变量与因变量数据做出散点图,进而观察判定出两者间的函数关系,本次探讨以一次函数关系为例,其他类型的函数关系也可通过两边取对数等方法转化为一次函数形式进行求解。
认定y =f (x )是线性函数:f (x )=ax +b a,b 即为待求的常数。
对于求的函数,我们希望它可以尽可能多的拟合到已知的数据点,或者说尽可能的靠近。
转化为量化形式即为使偏差y i −f (x i ) 都很小,对此经过综合分析我们用M =∑[y i −(ax i +b )]2imax i=0最小来保证每个偏差的绝对值都很小,即根据偏差的平方和为最小的条件来确定常数a,b 。
然后运用多远函数的极值求法知识来求解求M =(a,b )的极小值,具体步骤为:{M a (a,b )=0M b (a,b )=0>>>>>>>>>>>>>>{ðM ða =−2∑[y i −(ax i +b )]x i =0imax i=0ðM ðb =−2∑[y i −(ax i +b )]=0imax i=0 >>>>{∑[y i −(ax i +b )]x i =0imax i=0∑[y i −(ax i +b )]=0imax i=0>>>>>>{a ∑x i 2+b ∑x i imax i=0=∑y i x i imax i=0imax i=0a ∑x i + 8b =∑y i imax i=0imax i=0 (1) 然后再列表计算∑x i 2,∑x i imax i=0,∑y i x i imax i=0imaxi=0,及 ∑y i imax i=0,代入方程组(1),即可求出a,b 。

从统计学看线性回归(1)——⼀元线性回归⽬录1. ⼀元线性回归模型的数学形式2. 回归参数β0 , β1的估计3. 最⼩⼆乘估计的性质 线性性 ⽆偏性 最⼩⽅差性⼀、⼀元线性回归模型的数学形式 ⼀元线性回归是描述两个变量之间相关关系的最简单的回归模型。
⾃变量与因变量间的线性关系的数学结构通常⽤式(1)的形式:y = β0 + β1x + ε (1)其中两个变量y与x之间的关系⽤两部分描述。
⼀部分是由于x的变化引起y线性变化的部分,即β0+ β1x,另⼀部分是由其他⼀切随机因素引起的,记为ε。
该式确切的表达了变量x与y之间密切关系,但密切的程度⼜没有到x唯⼀确定y的这种特殊关系。
式(1)称为变量y对x的⼀元线性回归理论模型。
⼀般称y为被解释变量(因变量),x为解释变量(⾃变量),β0和β1是未知参数,成β0为回归常数,β1为回归系数。
ε表⽰其他随机因素的影响。
⼀般假定ε是不可观测的随机误差,它是⼀个随机变量,通常假定ε满⾜:(2)对式(1)两边求期望,得E(y) = β0 + β1x, (3)称式(3)为回归⽅程。
E(ε) = 0 可以理解为ε对 y 的总体影响期望为 0,也就是说在给定 x 下,由x确定的线性部分β0 + β1x 已经确定,现在只有ε对 y 产⽣影响,在 x = x0,ε = 0即除x以外其他⼀切因素对 y 的影响为0时,设 y = y0,经过多次采样,y 的值在 y0 上下波动(因为采样中ε不恒等于0),若 E(ε) = 0 则说明综合多次采样的结果,ε对 y 的综合影响为0,则可以很好的分析 x 对 y 的影响(因为其他⼀切因素的综合影响为0,但要保证样本量不能太少);若 E(ε) = c ≠ 0,即ε对 y 的综合影响是⼀个不为0的常数,则E(y) = β0 + β1x + E(ε),那么 E(ε) 这个常数可以直接被β0 捕获,从⽽变为公式(3);若 E(ε) = 变量,则说明ε在不同的 x 下对 y 的影响不同,那么说明存在其他变量也对 y 有显著作⽤。





一元线性回归方程式为:y=a+b x
b=n∑xy−∑x∑y n∑x2−(∑x)2
a=y̅−bx̅
其中a、b都是待定参数,可以用最小二乘法求得。
(最小平方法)b表示直线的斜率,又称为回归系数。
n表示所有数据的项数。
∑x表示所有x的求和
∑y表示所有y的求和
∑xy表示所有xy的求和
∑x2表示所有x2的求和
(∑x)2表示∑x的平方,即所有x的求和再求平方。
x̅表示所有x的平均数
y̅表示所有y的平均数
答题解法如下:
解:(答:)相关数据如下表:
根据公式b=n∑xy−∑x∑y
n∑x2−(∑x)2
得:
b=6∗1481−21∗426
6∗79−212=8886−8946
474−441
=−60
33
=-1.82
根据公式a=y̅−bx̅得:
a=71−(−1.82)∗3.5=71-(-6.37)=71+6.37=77.37
代入方程式y=a+b x得:
y=77.37+(-1.82)x=77.37-1.82 x
已知7月份产量为7000件,则x=7(千件),代入得:
y=77.37-1.82 x=77.37-1.82*7=77.37-12.74=64.63(元)
根据一元回归方程(最小乘法或最小平方法),当7月份产量为7000件时,其单位成本为64.63元。

