用最小二乘法求线性回归方程
- 格式:doc
- 大小:460.00 KB
- 文档页数:12

⼀元线性回归的最⼩⼆乘法详解及代码。
个⼈记录,⼤部分摘⾃概率论与数理统计⼀元线性回归模型设y与x间有相关关系,称x为⾃变量,y为因变量,我们只考虑在x是可控变量,只有y是随机变量,那么他们之间的相关关系可以表⽰为y=f(x)+ε其中ε是随机误差,⼀般假设ε~N(0,σ2)。
由于ε是随机变量,导致y也是随机变量。
进⾏回归分析⾸先是回归函数形式的选择。
通常采⽤画散点图来进⾏选择。
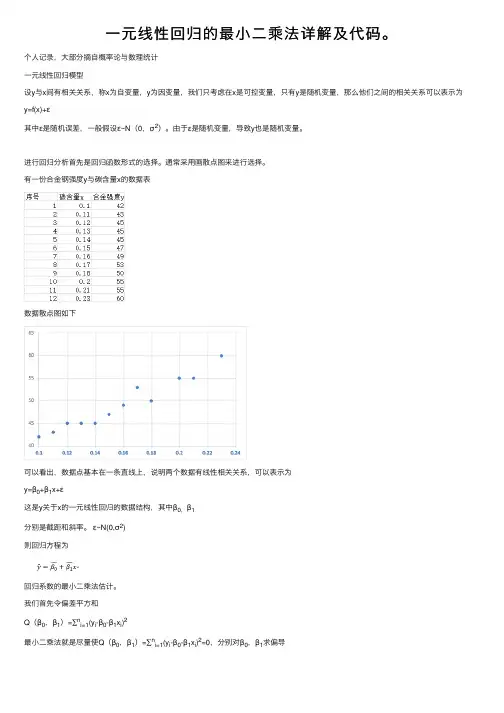
有⼀份合⾦钢强度y与碳含量x的数据表数据散点图如下可以看出,数据点基本在⼀条直线上,说明两个数据有线性相关关系,可以表⽰为y=β0+β1x+ε这是y关于x的⼀元线性回归的数据结构,其中β0,β1分别是截距和斜率。
ε~N(0,σ2)则回归⽅程为回归系数的最⼩⼆乘法估计。
我们⾸先令偏差平⽅和Q(β0,β1)=∑n i=1(y i-β0-β1x i)2最⼩⼆乘法就是尽量使Q(β0,β1)=∑n i=1(y i-β0-β1x i)2=0,分别对β0,β1求偏导整理后可知⽅程组 1如⽆特殊声明Σ均表⽰Σn i=1,则有解⽅程组1 可知python代码1import numpy as np2#导⼊回归数据3 x=np.array([0.1,0.11,0.12,0.13,0.14,0.15,0.16,0.17,0.18,0.2,0.21,0.23])4 y=np.array([42,43,45,45,45,47.5,49,53,50,55,55,60])5#x求和6 sx=sum(x)7# y求和8 sy=sum(y)9#参数个数10 n=len(x)11#x的平均值12 mx=np.mean(x)13#y的平均值14 my=np.mean(y)15#∑(xi)^2,所有xi的平⽅和16 sx2=sum(x*x)17#∑(yi)^2所有yi的平⽅和18 sy2=sum(y*y)19#∑xiyi 所有xiyi的和20 sxy=sum(x*y)21#lxx22 lxx=sx2-1/n*pow(sx,2)23#lxy24 lxy=sxy-1/n*sx*sy25#lyy26 lyy=sy2-1/n*pow(sy,2)27#β128β1=lxy/lxx29#β030β0=my-mx*β13132#结果 y=28.08+132.90到此结束。
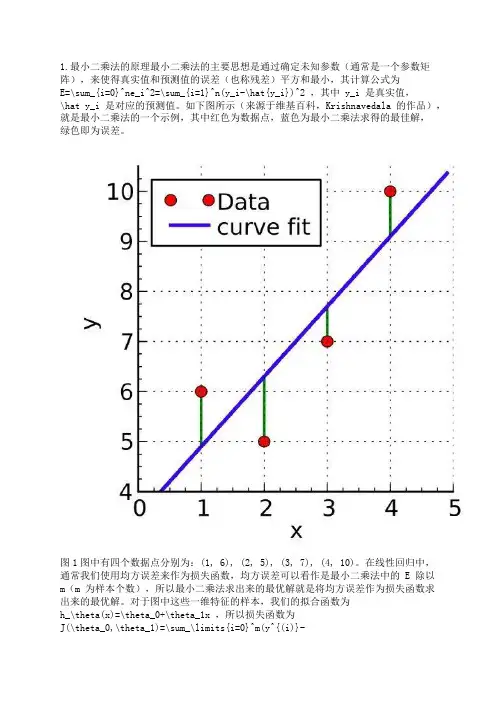
1.最小二乘法的原理最小二乘法的主要思想是通过确定未知参数(通常是一个参数矩阵),来使得真实值和预测值的误差(也称残差)平方和最小,其计算公式为E=\sum_{i=0}^ne_i^2=\sum_{i=1}^n(y_i-\hat{y_i})^2 ,其中 y_i 是真实值,\hat y_i 是对应的预测值。
如下图所示(来源于维基百科,Krishnavedala 的作品),就是最小二乘法的一个示例,其中红色为数据点,蓝色为最小二乘法求得的最佳解,绿色即为误差。
图1图中有四个数据点分别为:(1, 6), (2, 5), (3, 7), (4, 10)。
在线性回归中,通常我们使用均方误差来作为损失函数,均方误差可以看作是最小二乘法中的 E 除以m(m 为样本个数),所以最小二乘法求出来的最优解就是将均方误差作为损失函数求出来的最优解。
对于图中这些一维特征的样本,我们的拟合函数为h_\theta(x)=\theta_0+\theta_1x ,所以损失函数为J(\theta_0,\theta_1)=\sum_\limits{i=0}^m(y^{(i)}-h_\theta(x^{(i)}))^2=\sum_\limits{i=0}^m(y^{(i)}-\theta_0-\theta_1x^{(i)})^2 (这里损失函数使用最小二乘法,并非均方误差),其中上标(i)表示第 i 个样本。
2.最小二乘法求解要使损失函数最小,可以将损失函数当作多元函数来处理,采用多元函数求偏导的方法来计算函数的极小值。
例如对于一维特征的最小二乘法, J(\theta_0,\theta_1) 分别对 \theta_0 , \theta_1 求偏导,令偏导等于 0 ,得:\frac{\partial J(\theta_0,\theta_1)}{\partial\theta_0}=-2\sum_\limits{i=1}^{m}(y^{(i)}-\theta_0-\theta_1x^{(i)}) =0\tag{2.1}\frac{\partial J(\theta_0,\theta_1)}{\partial\theta_1}=-2\sum_\limits{i=1}^{m}(y^{(i)}-\theta_0-\theta_1x^{(i)})x^{(i)} = 0\tag{2.2}联立两式,求解可得:\theta_0=\frac{\sum_\limits{i=1}^m(x^{(i)})^2\sum_\limits{i=1}^my^{(i)}-\sum_\limits{i=1}^mx^{(i)}\sum_\limits{i=1}^mx^{(i)}y^{(i)}}{m\sum_\limits{i=1}^m(x^{(i)})^2-(\sum_\limits{i=1}^mx^{(i)})^2} \tag{2.3}\theta_1=\frac{m\sum_\limits{i=1}^mx^{(i)}y^{(i)}-\sum_\limits{i=1}^mx^{(i)}\sum_\limits{i=1}^my^{(i)}}{m\sum_\limits{i=1}^m(x^{(i)})^2-(\sum_\limits{i=1}^mx^{(i)})^2} \tag{2.4}对于图 1 中的例子,代入公式进行计算,得: \theta_0 = 3.5, \theta_1=1.4,J(\theta) = 4.2 。

“最小二乘法求线性回归方程”教学设计一.内容和内容解析本节课的主要内容为用最小二乘法求线性回归方程。
本节课内容作为上节课线性回归方程探究的知识发展,在知识上有很强的联系,所以,核心概念还是回归直线。
在“经历用不同估算方法描述两个变量线性相关关系”的过程后,解决好用数学方法刻画“从整体上看,各点与此直线的距离最小”,让学生在此基础上了解更为科学的数据处理方式——最小二乘法,有助于更好的理解核心概念,并最终体现回归方法的应用价值。
就统计学科而言,对不同的数据处理方法进行“优劣评价”是“假设检验”的萌芽,而后者是统计学学科研究的另一重要领域。
了解“最小二乘法思想”,比较各种“估算方法”,体会它的相对科学性,既是统计学教学发展的需要,又在体会此思想的过程中促进了学生对核心概念的进一步理解。
“最小二乘法思想”作为本节课的核心思想,由此得以体现。
而回归思想和贯穿统计学科中的随机思想,也在本节课中需有所渗透。
所以,在内容重点的侧重上,本节课与上节课有较大的区别:上节课侧重于估算方法设计,在不同的数据处理过程中,体会回归直线作为变量相关关系代表这一概念特征;本节课侧重于估算方法评价与实际应用,在评价中使学生体会核心思想,理解核心概念。
考虑到本节课的教学侧重点与新课程标准的要求,对线性回归方程系数的计算公式,可直接给出。
由于公式的复杂性,一方面,既要通过教学设计合理体现知识发生过程,不搞“割裂”;另一方面,要充分利用计算机或计算器,简化繁琐的求解系数过程,简化过于形式化的证明说理过程。
基于上述内容分析,确定本节课的教学重点为知道最小二乘法思想,并能根据给出的线性回归方程的系数公式建立线性回归方程。
二.目标和目标解析本节课要求学生了解最小二乘法思想,掌握根据给出的线性回归方程系数公式建立线性回归方程,理解线性回归方程概念和回归思想,在以上过程中体会随机思想:1.能用数学符号刻画出“从整体上看,各点与此直线的点的偏差”的表达方式;2.通过减少样本点个数,经历对表达式的展开,把“偏差最小”简化为“二次多项式”最小值问题,通过合情推理,使学生接受最小二乘法的科学性,在此过程中了解最小二乘法思想;3.能结合具体案例,经历数据处理步骤,根据回归方程系数公式建立回归方程;4.通过改变同一问题下样本点的选择进而对照回归方程的差异,体会随机思想;5.利用回归方程预测,体现用“确定关系研究相关关系”的回归思想;三.教学目标分析在经历用不同估算方法描述两个变量线性相关的过程后,在学生现有知识能力范围内,如何选择一个最优方法,成为知识发展的逻辑必然。



最小二乘法求解线性回归问题最小二乘法是回归分析中常用的一种模型估计方法。
它通过最小化样本数据与模型预测值之间的误差平方和来拟合出一个线性模型,解决了线性回归中的参数估计问题。
在本文中,我将详细介绍最小二乘法在线性回归问题中的应用。
一、线性回归模型在介绍最小二乘法之前,先了解一下线性回归模型的基本形式。
假设我们有一个包含$n$个观测值的数据集$(x_1,y_1),(x_2,y_2),\dots,(x_n,y_n)$,其中$x_i$表示自变量,$y_i$表示因变量。
线性回归模型的一般形式如下:$$y=\beta_0+\beta_1 x_1+\beta_2 x_2+\dots+\beta_px_p+\epsilon$$其中,$\beta_0$表示截距,$\beta_1,\beta_2,\dots,\beta_p$表示自变量$x_1,x_2,\dots,x_p$的系数,$\epsilon$表示误差项。
我们希望通过数据集中的观测值拟合出一个线性模型,即确定$\beta_0,\beta_1,\dots,\beta_p$这些未知参数的值,使得模型对未知数据的预测误差最小化。
二、最小二乘法的思想最小二乘法是一种模型拟合的优化方法,其基本思想是通过最小化优化问题的目标函数来确定模型参数的值。
在线性回归问题中,我们通常采用最小化残差平方和的方式来拟合出一个符合数据集的线性模型。
残差代表观测值与模型估计值之间的差异。
假设我们有一个数据集$(x_1,y_1),(x_2,y_2),\dots,(x_n,y_n)$,并且已经选定了线性模型$y=\beta_0+\beta_1 x_1+\beta_2 x_2+\dots+\beta_p x_p$。
我们希望选择一组系数$\beta_0,\beta_1,\dots,\beta_p$,使得模型对数据集中的观测值的预测误差最小,即最小化残差平方和(RSS):$$RSS=\sum_{i=1}^n(y_i-\hat{y}_i)^2$$其中,$y_i$表示第$i$个观测值的实际值,$\hat{y}_i$表示该观测值在当前模型下的预测值。


最小二乘法与回归分析最小二乘法是回归分析中最常用的方法之一、通过这种方法,可以找到最佳拟合曲线以描述自变量和因变量之间的关系。
最小二乘法通过最小化误差平方和来确定最佳拟合线。
本文将详细介绍最小二乘法和回归分析的概念、原理和应用。
回归分析是一种统计方法,用于确定两个或多个变量之间的关系。
在回归分析中,通常将一个变量定义为因变量,而其他变量则成为自变量,因为它们被认为是影响因变量的因素。
回归分析的目标是建立一个数学模型来描述因变量和自变量之间的关系。
回归模型通常采用线性方程的形式,可以通过拟合数据点来确定最佳拟合线。
最小二乘法是一种估计参数的方法,用于确定最佳拟合线。
最小二乘法的基本原理是通过最小化残差平方和来确定最佳拟合线。
残差是因变量与回归线之间的垂直距离。
残差平方和表示所有数据点与回归线之间的差异的平方和。
通过最小化残差平方和,可以找到最佳拟合线,使得残差达到最小。
在线性回归分析中,通过最小二乘法可以确定回归线的斜率和截距。
斜率表示因变量在自变量变化一个单位时的变化率,截距表示当自变量为零时的因变量的值。
通过求解最小二乘方程求出斜率和截距的估计值,从而得到回归线的方程。
最小二乘法还可以用于评估回归模型的拟合程度。
通过计算拟合优度和均方根误差,可以判断回归模型的预测能力。
拟合优度是一个介于0和1之间的值,表示因变量的变异程度中可以由自变量解释的比例。
均方根误差衡量了回归模型的预测误差的平均大小。
在实际应用中,最小二乘法和回归分析广泛应用于各个领域。
例如,在经济学中,最小二乘法可以用于分析消费者支出和收入之间的关系;在医学中,最小二乘法可以用于探索药物剂量和治疗效果之间的关系。
最小二乘法还可以用于时间序列分析、预测和趋势分析等领域。
总之,最小二乘法是回归分析中最常用的方法之一、通过最小化残差平方和,可以确定最佳拟合线并评估回归模型的拟合程度。
最小二乘法在实际应用中具有广泛的应用领域,可以帮助我们了解和解释变量之间的关系。

加权最小二乘法推导加权最小二乘法,是一种常用的线性回归分析方法,也是数理统计学中重要的一种最小二乘法拟合方法。
它的基本思想是对回归模型的误差进行加权处理,以获得更准确的拟合结果。
在传统的最小二乘法中,对于线性回归模型 $Y = \beta_0 +\beta_1X$,我们试图通过最小化残差平方和 $\sum_{i=1}^{n}(Y_i - (\beta_0 + \beta_1X_i))^2$ 来拟合最优的回归系数 $\beta_0$ 和$\beta_1$,其中$n$代表样本数量。
然而,在实际应用中,每个观测样本的重要性往往是不同的,而传统最小二乘法对每个样本的重要性均等看待,这样可能导致某些重要样本的误差被较不重要的样本的误差所掩盖。
为了解决这个问题,引入加权最小二乘法。
其核心思想是为每个样本分配一个权重,以便强调重要样本的贡献,削弱不重要样本的影响。
假设观测值的权重为 $w_i$,则加权最小二乘法的目标是最小化加权残差平方和 $S = \sum_{i=1}^{n} w_i(Y_i - (\beta_0 +\beta_1X_i))^2$。
接下来,我们通过最小化$S$来求解回归系数。
首先,我们对$\beta_0$ 和 $\beta_1$ 分别求导,令导数为零,可以得到以下正规方程组:$$\begin{cases}\sum_{i=1}^{n} w_iY_i = \beta_0\sum_{i=1}^{n} w_i +\beta_1\sum_{i=1}^{n} w_iX_i\\\sum_{i=1}^{n} w_iY_iX_i = \beta_0\sum_{i=1}^{n} w_iX_i + \beta_1\sum_{i=1}^{n} w_iX_i^2\end{cases}$$通过解这个方程组,我们可以得到回归系数的估计值$\hat{\beta_0}$ 和 $\hat{\beta_1}$。
进而,利用这两个估计值,我们可以得到拟合方程为 $\hat{Y} = \hat{\beta_0} +\hat{\beta_1}X$。

线性回归方程a尖公式第一:用所给样本求出两个相关变量的(算术)平均值第二:分别计算分子和分母:(两个公式任选其一)分子第三:计算b:b=分子/分母用最小二乘法估计参数b,设服从正态分布,分别求对a、b的偏导数并令它们等于零。
先求x,y的平均值X,Y再用公式代入求解:b=(x1y1+x2y2+...xnyn-nXY)/(x1+x2+...xn-nX) 后把x,y的平均数X,Y代入a=Y-bX求出a并代入总的公式y=bx+a得到线性回归方程(X为xi的平均数,Y为yi的平均数)线性回归是利用数理统计中的回归分析,来确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法之一,应用十分广泛。
变量的相关关系中最为简单的是线性相关关系,设随机变量与变量之间存在线性相关关系,则由试验数据得到的点,将散布在某一直线周围。
因此,可以认为关于的回归函数的类型为线性函数。
分析按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
介绍线性回归方程的求法:1.根据所给样本计算两个相关变量的平均值(算术)。
2.分子和分母分开计算:(两个公式任意选择一个)分子。
3.计算b:b=分子/分母4.用最小二乘法估计参数b,设服从正态分布,分别求对a、b的偏导数并令它们等于零。
5.首先求x,y的平均X,Y。
6.用以下公式代入求解:b=(x1y1+x2y2+……xnyn-nXY)/(x1+x2+……xn-nX)之后,将x,y的平均数X,Y带入a=Y-bX。
7.求出a并代入总的公式y=bx+a得到线性回归方程(X为xi的平均数,Y为yi的平均数)直线回归方程:b=(x1y1+x2y2+...xnyn-nXY)/(x1+x2+...xn-nX)。
多元线性回归与最小二乘估计1.假定条件、最小二乘估计量和高斯—马尔可夫定理 多元线性回归模型:y t = β0 +β1x t 1 +β2x t 2 +…+βk - 1x t k -1 + u t(1.1)其中y t 是被解释变量(因变量),x t j 是解释变量(自变量),u t 是随机误差项,βi , i = 0, 1, … , k - 1是回归参数(通常未知)。
对经济问题的实际意义:y t 与x t j 存在线性关系,x t j , j = 0, 1, … , k - 1, 是y t 的重要解释变量。
u t 代表众多影响y t 变化的微小因素。
使y t 的变化偏离了E( y t ) =多元线性回归与最小二乘估计1.假定条件、最小二乘估计量和高斯—马尔可夫定理 多元线性回归模型:y t = β0 +β1x t 1 +β2x t 2 +…+βk - 1x t k -1 + u t(1.1)其中y t 是被解释变量(因变量),x t j 是解释变量(自变量),u t 是随机误差项,βi , i = 0, 1, … , k - 1是回归参数(通常未知)。
对经济问题的实际意义:y t 与x t j 存在线性关系,x t j , j = 0, 1, … , k - 1, 是y t 的重要解释变量。
u t 代表众多影响y t 变化的微小因素。
使y t 的变化偏离了E( y t ) =β0 +β1x t 1 +β2x t 2 +…+βk - 1x t k -1决定的k 维空间平面。
当给定一个样本(y t , x t 1, x t 2 ,…, x t k -1), t = 1, 2, …, T 时, 上述模型表示为y 1 =β0 +β1x 11 +β2x 12 +…+βk - 1x 1 k -1 + u 1, 经济意义:x t j 是y t 的重要解释变量。
y 2 =β0 +β1x 21 +β2x 22 +…+βk - 1x 2 k -1 + u 2, 代数意义:y t 与x t j 存在线性关系。
最小二乘法计算公式推导最小二乘法是一种常用的参数估计方法,用于拟合数据和求解线性回归模型的参数。
下面我将给出最小二乘法的计算公式推导过程。
假设我们有m个数据点,每个数据点有一个自变量x和一个因变量y,我们的目标是找到一个模型来描述x和y之间的关系。
常用的线性模型形式为:y=β0+β1*x+ε其中,β0和β1是我们需要估计的参数,ε表示模型的误差项。
最小二乘法的目标是通过最小化所有数据点与模型的差距来估计参数。
首先,我们定义残差ri为第i个观测点的观测值yi与模型预测值yi~的差:ri=yiyi~我们希望最小化所有残差的平方和来求解参数。
因此,最小二乘法的目标是使得残差平方和函数S最小:S=Σ(ri^2)其中,Σ表示对所有m个数据点求和。
我们将S对参数β0和β1分别求偏导数,并令偏导数为0,可以得到参数的估计值。
首先,对β0求偏导数:∂S/∂β0=2Σ(ri*(1))令∂S/∂β0=0,得到:Σ(ri*(1))=0这个等式的意义是残差的总和等于0。
接下来,对β1求偏导数:∂S/∂β1=2Σ(ri*(1)*xi)令∂S/∂β1=0,得到:Σ(ri*(1)*xi)=0这个等式的意义是残差与自变量的乘积的总和等于0。
利用这两个等式,我们可以求解出β0和β1的估计值。
首先,利用第一个等式,我们可以得到:Σ(ri*(1))=Σ(yiyi~)=0进一步展开得到:ΣyiΣyi~=0因此,β0的估计值可以表示为:β0=(1/m)*Σyi(1/m)*Σyi~其中,(1/m)*Σyi表示观测值y的平均值,(1/m)*Σyi~表示模型预测值yi~的平均值。
接下来,利用第二个等式可以得到:Σ(ri*(1)*xi)=Σ(yiyi~)*xi=0展开后得到:Σyi*xiΣyi~*xi=0因此,β1的估计值可以表示为:β1=(Σyi*xiΣyi~*xi)/Σxi^2其中,Σyi*xi表示观测值y与自变量x的乘积的总和,Σyi~*xi表示模型预测值yi~与自变量x的乘积的总和,Σxi^2表示自变量x的平方的总和。
最小二乘法公式偏导数最小二乘法是一种常用的线性回归方法,用于估计线性模型中的参数。
在最小二乘法中,我们需要求解使得观测值与模型预测值之间残差平方和最小化的参数。
设线性回归模型为:$$y=\beta_0+\beta_1x_1+\beta_2x_2+\cdots+\beta_nx_n$$其中,$y$是因变量,$\beta_0,\beta_1,\beta_2,\ldots,\beta_n$是模型的参数,$x_1,x_2,\ldots,x_n$是自变量。
我们定义残差为:$$e=y\hat{y}$$其中,$y$是观测值,$\hat{y}$是模型预测值。
最小二乘法的目标是求解参数$\beta_0,\beta_1,\beta_2,\ldots,\beta_n$,使得残差平方和$SSR$最小。
$SSR$的定义是:$$SSR=\sum_{i=1}^{N}(y_i\hat{y_i})^2$$其中,$N$是样本数量。
为了求解最小二乘法的参数,我们需要对参数进行偏导,然后令导数等于零,求解参数的值。
首先,我们对$\beta_0,\beta_1,\beta_2,\ldots,\beta_n$分别求偏导数,得到以下方程组:$$\frac{\partialSSR}{\partial\beta_0}=2\sum_{i=1}^{N }(y_i\hat{y_i})=0$$$$\frac{\partialSSR}{\partial\beta_1}=2\sum_{i=1}^{N }x_{i1}(y_i\hat{y_i})=0$$$$\frac{\partialSSR}{\partial\beta_2}=2\sum_{i=1}^{N }x_{i2}(y_i\hat{y_i})=0$$$$\cdots$$$$\frac{\partialSSR}{\partial\beta_n}=2\sum_{i=1}^{N }x_{in}(y_i\hat{y_i})=0$$通过求解这个方程组,可以得到最小二乘法的参数估计值。
多元线性回归与最小二乘估计1.假定条件、最小二乘估计量和高斯—马尔可夫定理多元线性回归模型:y t= β0 +β1x t1 +β2x t2 +…+βk- 1x t k -1 + u t(1.1)其中y t是被解释变量(因变量),x t j是解释变量(自变量),u t是随机误差项,βi,i = 0, 1, … , k - 1是回归参数(通常未知)。
对经济问题的实际意义:y t与x t j存在线性关系,x t j,j = 0, 1, … , k - 1, 是y t的重要解释变量。
u t代表众多影响y t变化的微小因素。
使y t的变化偏离了E( y t) =多元线性回归与最小二乘估计1.假定条件、最小二乘估计量和高斯—马尔可夫定理多元线性回归模型:y t= β0 +β1x t1 +β2x t2 +…+βk- 1x t k -1 + u t(1.1)其中y t是被解释变量(因变量),x t j是解释变量(自变量),u t是随机误差项,βi,i = 0, 1, … , k - 1是回归参数(通常未知)。
对经济问题的实际意义:y t与x t j存在线性关系,x t j,j = 0, 1, … , k - 1, 是y t的重要解释变量。
u t代表众多影响y t变化的微小因素。
使y t的变化偏离了E( y t) =β0 +β1x t1 +β2x t2 +…+βk- 1x t k -1决定的k维空间平面。
当给定一个样本(y t,x t1, x t2 ,…, x t k -1), t = 1, 2, …, T时, 上述模型表示为y1 =β0 +β1x11 +β2x12 +…+βk- 1x1 k -1 + u1, 经济意义:x t j是y t的重要解释变量。
y2 =β0 +β1x21 +β2x22 +…+βk- 1x2 k -1 + u2, 代数意义:y t与x t j存在线性关系。
………..几何意义:y t表示一个多维平面。
最小二乘法主要用来求解两个具有线性相关关系的变量的回归方程,该方法适用于求解与线性回归方程相关的问题,如求解回归直线方程,并应用其分析预报变量的取值等.破解此类问题的关键点如下:
①析数据,分析相关数据,求得相关系数r,或利用散点图判断两变量之间是否存在线性相关关系,若呈非线性相关关系,则需要通过变量的变换转化构造线性相关关系.
②建模型.根据题意确定两个变量,结合数据分析的结果建立回归模型.
③求参数.利用回归直线y=bx+a的斜率和截距的最小二乘估计公式,求出b,a,的值.从而确定线性回归方程.
④求估值.将已知的解释变量的值代入线性回归方程y=bx+a中,即可求得y的预测值.
注意:回归直线方程的求解与应用中要注意两个方面:一是求解回归直线方程时,利用样本点的中心(x,y)必在回归直线上求解相关参数的值;二是回归直线方程的应用,利用回归直线方程求出的数值应是一个估计值,不是真实值.
经典例题:
下图是某地区2000年至2016年环境基础设施投资额(单位:亿元)的折线图.
为了预测该地区2018年的环境基础设施投资额,建立了与时间变量的两个线性回归模型.根据2000年至2016年的数据(时间变量的值依次为1,2.,……,17)建立模型①:y=+;根据2010年至2016年的数据(时间变量的值依次为)建立模型②:y=99+.
(1)分别利用这两个模型,求该地区2018年的环境基础设施投资额的预测值;
(2)你认为用哪个模型得到的预测值更可靠并说明理由.
思路分析:(1)两个回归直线方程中无参数,所以分别求自变量为2018时所对应的函数值,就得结果,(2)根据折线图知2000到2009,与2010到2016是两个有明显区别的直线,且2010到2016的增幅明显高于2000到2009,也高于模型1的增幅,因此所以用模型2更能较好得到2018的预测.
解析:(1)利用模型①,该地区2018年的环境基础设施投资额的预测值为
=–+×19=(亿元).
利用模型②,该地区2018年的环境基础设施投资额的预测值为
=99+×9=(亿元).
(2)利用模型②得到的预测值更可靠.理由如下:
(i)从折线图可以看出,2000年至2016年的数据对应的点没有随机散布在直线y=–+上下,这说明利用2000年至2016年的数据建立的线性模型①不能很好地描述环境基础设施投资额的变化趋势.2010年相对2009年的环境基础设施投资额有明显增加,2010年至2016年的数据对应的点位于一条直线的附近,这说明从2010年开始环境基础设施投资额的变化规律呈线性增长趋势,利
用2010年至2016年的数据建立的线性模型=99+可以较好地描述2010年以后的环境基础设施投资额的变化趋势,因此利用模型②得到的预测值更可靠.(ii)从计算结果看,相对于2016年的环境基础设施投资额220亿元,由模型①得到的预测值亿元的增幅明显偏低,而利用模型②得到的预测值的增幅比较合理,说明利用模型②得到的预测值更可靠.
以上给出了2种理由,考生答出其中任意一种或其他合理理由均可得分.
总结:若已知回归直线方程,则可以直接将数值代入求得特定要求下的预测值;若回归直线方程有待定参数,则根据回归直线方程恒过中心点求参数.
线性回归方程是利用数理统计中的回归分析,来确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法之一,线性回归也是回归分析中第一种经过严格研究并在实际应用中广泛使用的类型。
按自变量个数可分为一元线性回归分析方程和多元线性回归分析方程。
线性方程不难,公式会直接给出,有
时会出现在选择题,这部分难度同样是在于计算,刚开始学这部分知识的时候很多同学没有耐心计算,其实很简单的列个表格算就行了
某公司要推出一种新产品,分6个相等时长的时段进行试销,并对卖出的产品进行跟踪以及收集顾客的评价情况(包括产品评价和服务评价),在试销阶段
共卖出了480件,通过对所卖出产品的评价情况和销量情况进行统计,一方面发现对该产品的好评率为5/6,对服务的好评率为,对产品和服务两项都没有好评有30件,另一方面发现销量和单价有一定的线性相关关系,具体数据如下表:
考点分析:
线性回归方程.
线性回归方程是高考新增内容,主要考查散点图、变量间的相关关系的判断以及线性回归方程的求法。
题干分析:
(1)由题意得到2×2列联表,由公式求出K2的观测值,对比参考表格得结论;
(2)求出样本的中心点坐标,计算回归方程的系数,写出利润函数w的解析式,求出w(x)的最大值以及对应的x的值.
解题反思:
高考对线性回归方程的考查力度逐步增加,以前只有很少题型出现,但在近几年高考试题中就很常见了,逐渐成为高考数学热点问题之一,由此可以看出这部分知识的重要性了。
3.(2017·山东卷)为了研究某班学生的脚长x (单位:厘米)和身高y (单位:厘米)的关系,从该班随机抽取10名学生,根据测量数据的散点图可以看出y 与x 之间
有线性相关关系,设其回归直线方程为y ^=b ^x +a ^.已知∑10i =1x i =225,∑10i =1y i
=1 600,b ^=4.该班某学生的脚长为24,据此估计其身高为( )
解析 由已知得x =,y =160,
∵回归直线方程过样本点中心(x ,y ),且b
^=4, ∴160=4×+a ^,解得a ^=70.
∴回归直线方程为y ^=4x +70,当x =24时,y ^=166.故选C.
(2)(2016·全国Ⅲ卷)如图是我国2008年至2014年生活垃圾无害化处理量(单位:亿吨)的折线图.
注:年份代码1~7分别对应年份2008~2014.
①由折线图看出,可用线性回归模型拟合y 与t 的关系,请用相关系数加以说明;
②建立y 关于t 的回归方程(系数精确到,预测2016年我国生活垃圾无害化处
理量.
附注:
参考数据:∑7i =1y i =,∑7i =1t i y i =,∑7
i =1 (y i -y )2=,7≈.
回归方程y ^=a ^+b ^t 中斜率和截距的最小二乘估计公式分别为:
(2)解 ①由折线图中的数据和附注中参考数据得
t =4,∑7i =1
(t i -t )2=28,∑7i =1 (y i -y )2=. ∑7i =1 (t i -t )(y i -y )=∑7i =1t i y i -t ∑7i =1
y i =-4×=,所以r ≈错误!≈. 因为y 与t 的相关系数近似为,说明y 与t 的线性相关程度相当高,从而可以用线性回归模型拟合y 与t 的关系. ②由y =错误!=及(1)得错误!=错误!=错误!≈,
a ^=y -b
^t ≈-×4≈. 所以,y 关于t 的回归方程为y ^=+.
将2016年对应的t =9代入回归方程得:y ^=+×9=.
所以预测2016年我国生活垃圾无害化处理量约为亿吨.
探究提高 1.求回归直线方程的关键及实际应用
(1)关键:正确理解计算b ^,a ^的公式和准确地计算.
(2)实际应用:在分析实际中两个变量的相关关系时,可根据样本数据作出散点图来确定两个变量之间是否具有相关关系,若具有线性相关关系,则可通过线性回归方程估计和预测变量的值.
(2)(2017·唐山一模)某市春节期间7家超市的广告费支出x i (万元)和销售额y i (万元)数据如下:
超市 A B C D E F G 广告费支出x i 1 2 4 6 11 13 19 销售额y i
19
32
40
44
52
53
54
①若用线性回归模型拟合y 与x 的关系,求y 关于x 的线性回归方程; ②用对数回归模型拟合y 与x 的关系,可得回归方程y ^=12ln x +22,经计算得出线性回归模型和对数模型的R 2分别约为和,请用R 2说明选择哪个回归模型更合适,并用此模型预测A 超市广告费支出为8万元时的销售额.
参数数据及公式:x =8,y =42,∑7
i =1x i y i =2 794,∑7
i =1
x 2i
=708,
(1)解析 ∵k ≈>,且P (K 2≥k 0==,根据独立性检验思想“这种血清能起到预防感冒的作用”出错的可能性不超过5%. 答案 B
(2)解 ①∵x =8,y =42,∑7
i =1x i y i =2 794,∑7
i =1
x 2i =708.
因此a ^=y -b
^x =42-×8=.
所以,y 关于x 的线性回归方程是y ^=+. ②∵<,
∴对数回归模型更合适.
当x =8时,y ^=12ln 8+22=36ln 2+22=36×+22=万元. ∴广告费支出8万元时,预测A 超市销售额为万元.。