pthread之线程堆栈分配不足coredump分析
- 格式:doc
- 大小:37.50 KB
- 文档页数:5

先来讲说线程内存相关的东西,主要有下面几条:1.进程中的所有的线程共享相同的地址空间。
2.任何声明为static/extern的变量或者堆变量可以被进程内所有的线程读写。
3.一个线程真正拥有的唯一私有储存是处理器寄存器。
4.线程栈可以通过暴露栈地址的方式与其它线程进行共享。
有大数据量处理的应用中,有时我们有必要在栈空间分配一个大的内存块或者要分配很多小的内存块,但是线程的栈空间的最大值在线程创建的时候就已经定下来了,如果栈的大小超过个了个值,系统将访问未授权的内存块,毫无疑问,再来的肯定是一个段错误。
可是没办法,你还是不得不分配这些内存,于是你开会为分配一个整数值而动用malloc这种超级耗时的操作。
当然,在你的需求可以评估的情况下,你的需求还是可以通过修改线程的栈空间的大小来改变的。
下面的我们用pthread_attr_getstacksize和pthread_attr_setstacksize的方法来查看和设置线程的栈空间。
注意:下面的测试代码在我自己的机子上(ubuntu6.06,ubuntu6.10,redhat 9, gentoo)通过了测试,但是很奇怪的是在我同事的机子上,无论是改变环境,还是想其它方法都不能正常的运行。
在网上查了一下,很多人也存在同样的问题,至今不知道为何。
linux线程的实现方式决定了对进程的限制同样加在了线程身上:)所以,有问题,请参见<pthread之线程栈空间(2)(进行栈)直接看代码吧,只有一个C文件(thread_attr.c)#include <limits.h>#include <pthread.h>#include "errors.h"//线程体,在栈中分配一个大小为15M的空间,并进行读写void *thread_routine (void *arg){printf ("The thread is here\n");//栈大小为16M,如果直接分配16M的栈空间,会出现段错误,因为栈中还有其它的//变量要放署char p[1024*1024*15];int i=1024*1024*15;//确定内存分配的确成功了while(i--){p[i] = 3;}printf( "Get 15M Memory\n" );//分配更多的内存(如果分配1024*1020*512的话就会出现段错误) char p2[ 1024 * 1020 + 256 ];memset( p2, 0, sizeof( char ) * ( 1024 * 1020 + 256 ) );printf( "Get More Memory\n" );return NULL;}int main (int argc, char *argv[]){pthread_t thread_id;pthread_attr_t thread_attr;size_t stack_size;int status;status = pthread_attr_init (&thread_attr);if (status != 0)err_abort (status, "Create attr");status = pthread_attr_setdetachstate (&thread_attr, PTHREAD_CREATE_DETACHED);if (status != 0)err_abort (status, "Set detach");//通常出现的问题之一,下面的宏没有定义#ifdef _POSIX_THREAD_ATTR_STACKSIZE//得到当前的线程栈大小status = pthread_attr_getstacksize (&thread_attr, &stack_size); if (status != 0)err_abort (status, "Get stack size");printf ("Default stack size is %u; minimum is %u\n",stack_size, PTHREAD_STACK_MIN);//设置当前的线程的大小status = pthread_attr_setstacksize (&thread_attr, PTHREAD_STACK_MIN*1024);if (status != 0)err_abort (status, "Set stack size");//得到当前的线程栈的大小status = pthread_attr_getstacksize (&thread_attr, &stack_size);if (status != 0)err_abort (status, "Get stack size");printf ("Default stack size is %u; minimum is %u\n",stack_size, PTHREAD_STACK_MIN);#endifint i = 5;//分配5个具有上面的属性的线程体while(i--){status = pthread_create (&thread_id, &thread_attr, thread_routine, NULL); if (status != 0)err_abort (status, "Create thread");}getchar();printf ("Main exiting\n");pthread_exit (NULL);return 0;}看看执行过程:dongq@DongQ_Lap ~/workspace/test/pthread_attr $ makecc -pthread -g -DDEBUG -lrt -o thread_attr thread_attr.cdongq@DongQ_Lap ~/workspace/test/pthread_attr $ ./thread_attrDefault stack size is 8388608; minimum is 16384 //默认的栈大小为8MDefault stack size is 16777216; minimum is 16384 //设置后的结果为16MThe thread is hereThe thread is hereThe thread is hereThe thread is hereThe thread is hereGet 15M MemoryGet More MemoryGet 15M MemoryGet More MemoryGet 15M MemoryGet 15M MemoryGet More MemoryGet More MemoryGet 15M MemoryGet More MemoryMain exitings用下面的命令来看linux下面的对系统的一些限制:dongq@DongQ_Lap ~/workspace/test/pthread_attr $ ulimit -acore file size (blocks, -c) 0data seg size (kbytes, -d) unlimitedscheduling priority (-e) 0file size (blocks, -f) unlimitedpending signals (-i) 16365max locked memory (kbytes, -l) 32max memory size (kbytes, -m) unlimitedopen files (-n) 1024pipe size (512 bytes, -p) 8POSIX message queues (bytes, -q) 819200real-time priority (-r) 0stack size (kbytes, -s) 8196cpu time (seconds, -t) unlimitedmax user processes (-u) 16365virtual memory (kbytes, -v) unlimitedfile locks (-x) unlimited通过上面的命令,我们可以清楚的看到一个进程在正常的情况下,最大的栈空间为8M。

Core dump 基本知识本节主要探讨 core dump 产生的背景知识。
对这部分不感兴趣的读者可以直接阅读第二章,了解基本的 core dump 定位手段。
起源软件是人思维的产物。
智者千虑,必有一失,人的思维总有缺陷,反映到软件层面上就是程序 bug。
程序 bug 的终极体现就是 core dump,core dump 是软件错误无法恢复的产物。
生成过程进程 core dump 与系统 dump 的产生,从程序原理上来说是基本一致的。
dump 的生成一般是在系统进行中断处理时进行的,下面简单介绍一下中断机制。
操作系统的中断机制操作系统是由中断驱动的。
广义的中断一般分为两类,中断 (Interrupts) 和异常(Exceptions)。
中断可在任何时候发生,与 CPU 正在执行什么指令无关,中断主要由 I/O 设备、处理器时钟(分时系统依赖时钟中断划分时间片)或定时器等硬件引发,可以被允许或取消。
而异常是由于 CPU 执行了某些指令引起的,可以包括存储器存取违规、除 0 或者特定调试指令等,内核也将系统服务视为异常。
系统对这两类中断的处理基本上是相同的。
每个中断都会唯一对应到一个中断处理程序,在该中断触发时,相应的处理程序就会被执行。
例如应用进程进行系统调用时,就会触发一个软件异常,进入中断处理函数,完成从用户态到系统态的迁移并进入相应系统调用的入口点。
应用进程 coredump 也是一个类似的过程。
应用进程 core dump 生成过程在进程运行出现异常行为时,例如无效地址访问、浮点异常、指令异常等,将导致系统转入内核态进行异常处理(即中断处理),向相应的进程发出特定信号例如 SIGSEGV、SIGFPE、SIGILL 等。
如果应用进程注册了相应信号的处理函数(例如可通过 sigaction 注册信号处理函数),则调用相应处理函数进行处理(应用程序可以选择记录信息后生成 core dump 并退出);否则将采取默认动作,例如 SIGSEGV 的默认动作是生成 core dump 并退出程序。
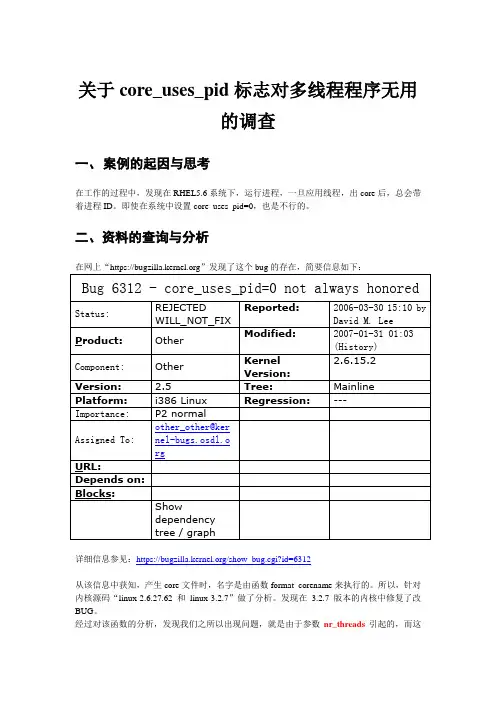
关于core_uses_pid标志对多线程程序无用的调查一、案例的起因与思考在工作的过程中,发现在RHEL5.6系统下,运行进程,一旦应用线程,出core后,总会带着进程ID。
即使在系统中设置core_uses_pid=0,也是不行的。
二、资料的查询与分析在网上“https://”发现了这个bug的存在,简要信息如下:Bug 6312 - core_uses_pid=0 not always honoredStatus: REJECTEDWILL_NOT_FIXReported: 2006-03-30 15:10 byDavid M. LeeProduct: Other Modified: 2007-01-31 01:03(History)Component: Other KernelVersion:2.6.15.2Version: 2.5 Tree: Mainline Platform: i386 Linux Regression: --- Importance: P2 normalAssigned To: other_other@ker nel-bugs.osdl.o rgURL:Depends on:Blocks:Showdependencytree / graph详细信息参见:https:///show_bug.cgi?id=6312从该信息中获知,产生core文件时,名字是由函数format_corename来执行的。
所以,针对内核源码“linux-2.6.27.62 和linux-3.2.7”做了分析。
发现在3.2.7版本的内核中修复了改BUG。
经过对该函数的分析,发现我们之所以出现问题,就是由于参数nr_threads引起的,而这个参数的含义就是使用该资源的线程个数,该值是被内敛函数“zap_threads”来设置的。
而这段代码基本上是不可避免的都要走到的。
我们如何跳过这段代码呢?如何让nr_threads 不起作用呢?/* Backward compatibility with core_uses_pid:** If core_pattern does not include a %p (as is the default)* and core_uses_pid is set, then .%pid will be appended to* the filename. Do not do this for piped commands. */if (!ispipe && !pid_in_pattern&& (core_uses_pid || nr_threads)) {rc = snprintf(out_ptr, out_end - out_ptr,".%d", task_tgid_vnr(current));if (rc > out_end - out_ptr)goto out;out_ptr += rc;}Fork为何会遵循core_uses_pid的设置呢?参见zap_threads中的解释。


段错误 (core dumped)当我们的程序崩溃时,内核有可能把该程序当前内存映射到core文件里,方便程序员找到程序出现问题的地方。
最常出现的,几乎所有C程序员都出现过的错误就是“段错误”了。
也是最难查出问题原因的一个错误。
下面我们就针对“段错误”来分析core文件的产生、以及我们如何利用core文件找到出现崩溃的地方。
何谓core文件当一个程序崩溃时,在进程当前工作目录的core文件中复制了该进程的存储图像。
core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。
使用core文件调试程序看下面的例子:#includechar *str = "test";void core_test(){str[1] ='T';}int main(){core_test();return0;}编译:gcc –g core_dump_test.c -o core_dump_test如果需要调试程序的话,使用gcc编译时加上-g选项,这样调试core文件的时候比较容易找到错误的地方。
执行:./core_dump_test段错误运行core_dump_test程序出现了“段错误”,但没有产生core文件。
这是因为系统默认core文件的大小为0,所以没有创建。
可以用ulimit命令查看和修改core文件的大小。
ulimit -c 0ulimit -c 1000ulimit -c 1000-c指定修改core文件的大小,1000指定了core文件大小。
也可以对core文件的大小不做限制,如:ulimit -c unlimitedulimit -c unlimited如果想让修改永久生效,则需要修改配置文件,如.bash_profile、/etc/profile或/etc/security/limits.conf。
再次执行:./core_dump_test段错误 (core dumped)ls core.*core.6133可以看到已经创建了一个core.6133的文件.6133是core_dump_test程序运行的进程ID。
Linux内核调试方法总结之coredump什么是core dump?分析core dump是Linux应用程序调试的一种有效方式,像内核调试抓取ram dump一样,core dump主要是获取应用程序崩溃时的现场信息,如程序运行时的内存、寄存器状态、堆栈指针、内存管理信息、函数调用堆栈信息等。
Core dump又称为“核心转储”,是Linux基于信号实现的。
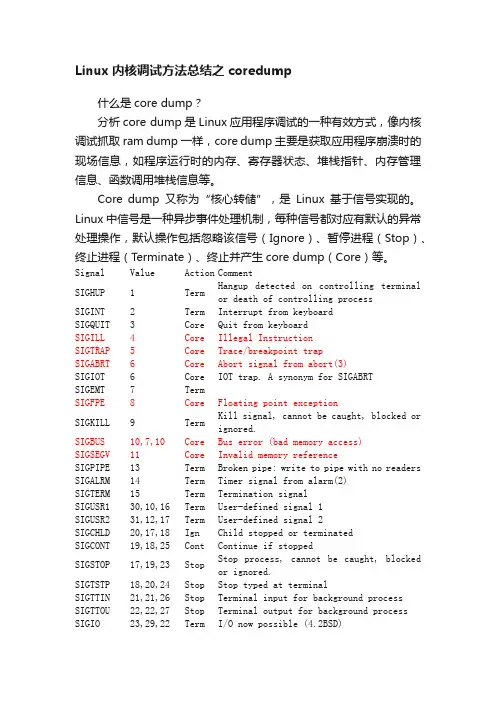
Linux中信号是一种异步事件处理机制,每种信号都对应有默认的异常处理操作,默认操作包括忽略该信号(Ignore)、暂停进程(Stop)、终止进程(T erminate)、终止并产生core dump(Core)等。
Signal Value Action CommentSIGHUP 1 Term Hangup detected on controlling terminal or death of controlling processSIGINT 2 Term Interrupt from keyboard SIGQUIT 3 Core Quit from keyboardSIGILL4Core Illegal InstructionSIGTRAP5Core Trace/breakpoint trapSIGABRT6Core Abort signal from abort(3) SIGIOT 6 Core IOT trap. A synonym for SIGABRT SIGEMT 7 TermSIGFPE8Core Floating point exceptionSIGKILL 9 Term Kill signal, cannot be caught, blocked or ignored.SIGBUS10,7,10Core Bus error (bad memory access)SIGSEGV11Core Invalid memory referenceSIGPIPE 13 Term Broken pipe: write to pipe with no readers SIGALRM 14 Term Timer signal from alarm(2)SIGTERM 15 Term Termination signalSIGUSR1 30,10,16 Term User-defined signal 1SIGUSR2 31,12,17 Term User-defined signal 2SIGCHLD 20,17,18 Ign Child stopped or terminatedSIGCONT 19,18,25 Cont Continue if stoppedSIGSTOP 17,19,23 Stop Stop process, cannot be caught, blocked or ignored.SIGTSTP 18,20,24 Stop Stop typed at terminalSIGTTIN 21,21,26 Stop Terminal input for background process SIGTTOU 22,22,27 Stop Terminal output for background process SIGIO 23,29,22 Term I/O now possible (4.2BSD)SIGPOLL Term Pollable event (Sys V). Synonym for SIGIO SIGPROF 27,27,29 Term Profiling timer expiredSIGSYS12,31,12Core Bad argument to routine (SVr4)SIGURG 16,23,21 Ign Urgent condition on socket (4.2BSD) SIGVTALRM 26,26,28 Term Virtual alarm clock (4.2BSD)SIGXCPU24,24,30Core CPU time limit exceeded (4.2BSD) SIGXFSZ25,25,31Core File size limit exceeded (4.2BSD) SIGSTKFLT 16 Term Stack fault on coprocessor (unused) SIGCLD 18 Ign A synonym for SIGCHLDSIGPWR 29,30,19 Term Power failure (System V)SIGINFO 29 A synonym for SIGPWR, on an alpha SIGLOST 29 Term File lock lost (unused), on a sparc SIGWINCH 28,28,20 Ign Window resize signal (4.3BSD, Sun) SIGUNUSED 31 Core Synonymous with SIGSYS什么情况下会产生core dump呢?以下情况会出现应用程序崩溃导致产生core dump:1.内存访问越界(数组越界、字符串无\n结束符、字符串读写越界)2.多线程程序中使用了线程不安全的函数,如不可重入函数3.多线程读写的数据未加锁保护(临界区资源需要互斥访问)4.非法指针(如空指针异常或者非法地址访问)5.堆栈溢出怎么获取core dump呢?Linux提供了一组命令来配置core dump行为:1. ulimit –c 查看core dump机制是否使能,若为0则默认不产生core dump,可以使用ulimit –c unlimited使能core dump2. cat /proc/sys/kernel/core_pattern 查看core文件默认保存路径,默认情况下是保存在应用程序当前目录下,但是如果应用程序中调用chdir()函数切换了当前工作目录,则会保存在对应的工作目录3. echo “/data/xxx/<core_file>” > /proc/sys/kernel/core_pattern 指定core文件保存路径和文件名,其中core_file可以使用以下通配符:%% 单个%字符%p 所dump进程的进程ID%u 所dump进程的实际用户ID%g 所dump进程的实际组ID%s 导致本次core dump的信号%t core dump的时间 (由1970年1月1日计起的秒数)%h 主机名%e 程序文件名4. ulimit –c [size] 指定core文件大小,默认是不限制大小的,如果自定义的话,size值必须大于4,单位是block(1block = 512bytes)怎么分析core dump?我们首先编写一个程序,人为地产生core dump并获取core dump文件。


CoreDump详解1. 什么是Core:Sam之前一直以为Core Dump中Core是Linux Kernel的意思. 今天才发现在这里,Core是另一种意思:在使用半导体作为内存的材料前,人类是利用线圈当作内存的材料(发明者为王安),线圈就叫作core ,用线圈做的内存就叫作core memory。
如今,半导体工业澎勃发展,已经没有人用core memory 了,不过,在许多情况下,人们还是把记忆体叫作core 。
2. 什么是Core Dump:我们在开发(或使用)一个程序时,最怕的就是程序莫明其妙地当掉。
虽然系统没事,但我们下次仍可能遇到相同的问题。
于是这时操作系统就会把程序当掉时的内存内容dump 出来(现在通常是写在一个叫core 的file 里面),让我们或是debugger 做为参考。
这个动作就叫作core dump。
3. Core Dump时会生成何种文件:Core Dump时,会生成诸如core.进程号的文件。
4. 为何有时程序Down了,却没生成Core文件。
Linux下,有一些设置,标明了resources available to the shell and to processes。
可以使用#ulimit -a来看这些设置。
(ulimit是bash built-in Command)-a All current limits are reported-c The maximum size of core files created-d The maximum size of a process鈥檚data segment-e The maximum scheduling priority ("nice")-f The maximum size of files written by the shell and its children-i The maximum number of pending signals-l The maximum size that may be locked into memory-m The maximum resident set size (has no effect on Linux)-n The maximum number of open file descriptors (most systems do not allow this value to be set)-p The pipe size in 512-byte blocks (this may not be set)-q The maximum number of bytes in POSIX message queues -r The maximum real-time scheduling priority-s The maximum stack size-t The maximum amount of cpu time in seconds-u The maximum number of processes available to a single user-v The maximum amount of virtual memory available to the shell-x The maximum number of file locks从这里可以看出,如果-c是显示:core file size (blocks, -c)如果这个值为0,则无法生成core文件。

Segmentationfault(coredumped)错误的⼀种解决场景错误类型Segmentation fault (core dumped)产⽣原因Segmentation fault 段错误。
Core Dump 核⼼转储(是操作系统在进程收到某些信号⽽终⽌运⾏时,将此时进程地址空间的内容以及有关进程状态的其他信息写出的⼀个磁盘⽂件。
这种信息往往⽤于调试),其实“吐核”这个词形容的很恰当,就是核⼼内存吐出来。
出现这种错误可能的原因(其实就是访问了内存中不应该访问的东西):1,内存访问越界:(1)数组访问越界,因为下标出超出了范围。
(2)搜索字符串的时候,通过字符串的结尾符号来判断结束,但是实际上没有这个结束符。
(3)使⽤strcpy, strcat, sprintf, strcmp,strcasecmp等字符串操作函数,超出了字符中定义的可以存储的最⼤范围。
使⽤strncpy, strlcpy, strncat, strlcat, snprintf, strncmp, strncasecmp等函数防⽌读写越界。
2,多线程程序使⽤了线程不安全的函数。
3,多线程读写的数据未加锁保护。
对于会被多个线程同时访问的全局数据,应该注意加锁保护,否则很容易造成核⼼转储4,⾮法指针(1)使⽤NULL指针(2)随意使⽤指针类型强制转换,因为在这种强制转换其实是很不安全的,因为在你不确认这个类型就应该是你转化的类型的时候,这样很容易出错,因为就会按照你强制转换的类型进⾏访问,这样就有可能访问到不应该访问的内存。
5,堆栈溢出不要使⽤⼤的局部变量(因为局部变量都分配在栈上),这样容易造成堆栈溢出,破坏系统的栈和堆结构,导致出现莫名其妙的错误。
解决场景在linux的虚拟机上跑了⼀个数据结构,在虚拟机上出现上述错误,在Windows的宿主机弹出错误。
于是试运⾏⼀个相似的较简单的哈希函数,虚拟机上出现相同错误,,注意到以下代码:// generates a hash value for a sting// same as djb2 hash functionunsigned int CountMinSketch::hashstr(const char *str) {unsigned long hash = 5381;int c;while (c = *str++) {hash = ((hash << 5) + hash) + c; /* hash * 33 + c */}return hash;}这是⼀个针对字符串的哈希函数,其中⼀⾏hash = ((hash << 5) + hash) + c; /* hash * 33 + c */是问题所在,针对较长的字符串,这个hash变量会不断变⼤,甚⾄溢出。

什么是coredump?以及如何使⽤gdb对coredumped进⾏调试什么是core dump?(down = 当) core的意思是:内存,dump的意思是:扔出来、堆出来。
开发和使⽤linux程序时,有时程序莫名其妙的down掉了,却没有任何的提⽰(有时候会提⽰core dumped)。
这时候可以查看⼀下有没有形如:core的⽂件⽣成,这个⽂件便是操作系统把程序down掉时的内存的内容扔出来⽣成的,它可以做为调试程序的参考。
core dump⼜叫核⼼转储,当程序运⾏过程中发⽣异常,程序异常退出时,由操作系统把程序当前的内存状况存储在⼀个core⽂件中,叫core dump。
为什么没有core⽂件⽣成呢? 有时候程序down掉了,但是core⽂件却没有⽣成。
⾸先,就是要知道错误发⽣的地⽅。
⽽Linux系统可以产⽣core⽂件,配合gdb就可以解决这个问题。
core⽂件的⽣成跟你当前系统的环境设置有关系,可以⽤下⾯的语句设置⼀下,然后再运⾏程序便成⽣成core⽂件了。
第⼀步:让系统在信号中断造成的错误时产⽣core⽂件: ulimit -c unlimited // 设置core⼤⼩为⽆限 ulimit unlimited //设置⽂件⼤⼩为⽆限第⼆步:编译原来的程序: gcc -o xxx xxx.c -g (-g选项的作⽤是在可执⾏⽂件中加⼊源码信息,⽐如可执⾏⽂件中第⼏条机器指令对应源代码的第⼏⾏,但并不是把整个源⽂件嵌⼊到可执⾏⽂件中,⽽是在调试时必须保证gdb能找到源⽂件。
)第三步:运⾏编译后的的程序: ./xxx(或者 xxx) 运⾏后,然后 ls 发现多出来了core⽂件。
core⽂件⽣成的位置⼀般与运⾏程序的路径相同,⽂件名⼀般为core。
第四步:⽤gdb查看core⽂件: 安装完成后使⽤如下命令: gdb xxx core第五步:输⼊bt或者where,就会出现错误的位置,就可以显⽰程序在哪⼀⾏dowm掉的,在哪个函数中down掉的。

linux coredump机制1. 引言1.1 概述Linux Coredump机制是一种操作系统级别的功能,可以在程序崩溃或异常终止时生成一个dump文件,记录了程序崩溃时的内存状态和堆栈信息。
Coredump文件包含了导致崩溃的关键信息,能够帮助开发人员进行故障诊断和问题排查。
本文将介绍Linux Coredump机制的原理、配置和参数设置方法,以及如何分析和利用Coredump文件进行调试与故障处理。
1.2 文章结构本文总共分为五个部分,每个部分都有明确的主题内容。
第一部分是引言部分,首先概述了Linux Coredump机制的基本概念,并介绍了文章的结构和目录。
接下来四个部分依次介绍了Linux Coredump机制的详细内容,包括Coredump生成过程、配置和参数设置、Coredump文件的分析与利用方法等。
最后一部分是总结与展望,对Linux Coredmu机制进行一个总结,并展望其可能的改进方向和发展前景。
1.3 目的本文旨在深入探讨Linux Coredump机制,在读者理解其原理基础上详细介绍其具体实现方法和使用技巧。
通过本文的学习,读者可以了解到如何配置和启用Coredump功能,以及如何利用Coredump文件进行故障诊断和问题排查。
同时,本文也希望能够引发读者对Linux Coredump机制的思考与讨论,鼓励其在实际开发过程中积极应用这一功能,并探索其可能的改进方向和未来发展前景。
2. Linux Coredump机制:2.1 Coredump简介:Coredump是指在软件运行过程中发生了错误或异常情况时,操作系统会将程序当前的内存状态以文件的形式保存下来。
Coredump文件记录了程序在崩溃前的内存数据、寄存器值、堆栈信息等重要调试信息。
它对于故障诊断和问题排查非常有用。
2.2 Coredump生成过程:当一个程序出现了严重错误导致崩溃时,操作系统会为该进程生成一个Coredump文件。
[转]c++多线程编程之pthread线程深⼊理解多线程编程之pthread线程深⼊理解Pthread是 POSIX threads 的简称,是POSIX的线程标准。
前⼏篇博客已经能给你初步的多线程概念。
在进⼀步学习线程同步等多线程核⼼知识之前,须要对多线程深⼊的理解。
⾮常多⼈忽略或者回避这部分内容,直接的问题是学习者⽆法把握多线程编程的内在原理,理解的层次太浅。
1.进程资源:进程资源有存储资源与其它资源。
其它资源包括环境变量。
地址,⽂件等。
存储资源。
进程的内存分配,博客具有⾮常好的參考价值。
多线程进程有所不同:静态区:存储全局变量和静态变量堆区:动态分配区上述静态区。
堆区以及其它资源统称为进程的共享资源。
共享资源被该进程的全部线程所共享。
线程堆:线程⾃⼰维护的堆线程栈:线程⾃⼰维护的栈上述的线程堆,线程栈是每⼀个线程独有的资源。
线程间相互独⽴,不共享。
当建⽴⼀个线程时。
系统会为线程分配堆栈。
你可能已经发现,线程共享进程堆的同⼀时候。
还⾃⼰维护⼀个堆栈。
2.线程私有数据:多线程编程下。
进程的全局变量通过存储于共享数据区,实现为全部线程共⽤。
同⼀时候,线程还能够有⾃⼰的全局变量,称为线程的私有数据。
爱思考的读者可能会问,那线程的⾮全局变量在哪呢。
别忘了⾮全局变量的空间在栈中哦。
3.线程消亡:线程消亡时,线程⾃由的线程堆栈会被释放,归还给系统,同⼀时候线程的私有数据也会被释放。
线程的共享资源。
静态区。
共享的进程堆以及其它资源。
因为这些资源是线程间共享的。
故不会随线程消亡⽽释放。
须要特别注意的是。
线程堆与共享的进程堆之间的差异。
线程理解⾄此。
之后的进⼀步学习。
会有更深⼊的体会。
coredump文件考出解析Core Dump文件是指在计算机程序运行时,出现异常情况导致程序崩溃时所生成的一种文件。
这个文件记录了程序在崩溃时的内存状态信息,包含了程序运行时的堆栈信息、寄存器状态以及其他相关的调试信息等。
通过分析Core Dump文件,可以帮助开发人员定位和解决程序崩溃的问题。
Core Dump文件的解析对于软件开发人员来说是一项非常重要的技能,可以帮助他们快速定位和修复程序中的bug。
下面就让我们来了解一下Core Dump文件的解析过程吧。
要解析Core Dump文件,我们需要借助一些调试工具。
常用的调试工具有GDB(GNU Debugger)、LLDB(LLVM Debugger)等。
这些工具可以加载Core Dump文件,并提供一系列命令和功能来分析和调试程序。
解析Core Dump文件的第一步是加载文件。
使用调试工具加载Core Dump文件后,我们可以查看文件中的各种信息。
比如,我们可以查看程序崩溃时的堆栈信息,了解程序在崩溃前的执行路径。
通过分析堆栈信息,我们可以确定程序崩溃的位置,找出导致程序崩溃的原因。
除了堆栈信息,Core Dump文件还包含了程序崩溃时的内存状态信息。
我们可以通过查看内存状态,了解程序在崩溃前的变量值、函数调用等信息。
这对于定位程序崩溃的原因非常有帮助。
在解析Core Dump文件时,我们还可以使用调试工具提供的其他功能,比如查看变量的值、设置断点、单步执行等。
这些功能可以帮助我们进一步分析和调试程序。
在进行Core Dump文件解析时,我们需要注意以下几点。
首先,要保证使用的调试工具版本与生成Core Dump文件的程序版本一致,以免出现兼容性问题。
其次,要注意文件的大小,如果Core Dump 文件过大,可能需要分析工具支持加载大文件。
此外,要注意保护好Core Dump文件的安全,避免泄露敏感信息。
除了使用调试工具解析Core Dump文件,还有一些第三方工具和库可以帮助我们更方便地分析Core Dump文件。
coredump配置、产⽣、分析以及分析⽰例关键词:coredump、core_pattern、coredump_filter等等。
应⽤程序在运⾏过程中由于各种异常或者bug导致退出,在满⾜⼀定条件下产⽣⼀个core⽂件。
通常core⽂件包含了程序运⾏时内存、寄存器状态、堆栈指针、内存管理信息以及函数调⽤堆栈信息。
core就是程序当前⼯作转改存储⽣成的⼀个⽂件,通过⼯具分析这个⽂件,可以定位到程序异常退出的时候对应的堆栈调⽤等信息,找出问题点并解决。
1. 配置coredump如果需要使⽤需要通过ulimit进⾏设置,可以通过ulimit -c查看当前系统是否⽀持coredump。
如果为0,则表⽰coredump被关闭。
通过ulimit -c unlimited可以打开coredump。
coredump⽂件默认存储位置与可执⾏⽂件在同⼀⽬录下,⽂件名为core。
可以通过/proc/sys/kernel/core_pattern进⾏设置。
%p 出Core进程的PID%u 出Core进程的UID%s 造成Core的signal号%t 出Core的时间,从1970-01-0100:00:00开始的秒数%e 出Core进程对应的可执⾏⽂件名通过echo "core-%e-%p-%s-%t" > /proc/sys/kernel/core_pattern。
在每个进程下都有coredump_filter节点/proc/<pid>/coredump_filter。
通过配置coredump_filter可以选择需在coredump的时候,将哪些内容dump到core⽂件中。
- (bit 0) anonymous private memory- (bit 1) anonymous shared memory- (bit 2) file-backed private memory- (bit 3) file-backed shared memory- (bit 4) ELF header pages in file-backed private memory areas (it is effective only if the bit 2is cleared)- (bit 5) hugetlb private memory- (bit 6) hugetlb shared memory- (bit 7) DAX private memory- (bit 8) DAX shared memorycoredump_filter的默认值是0x33,也即发⽣coredump时会将所有anonymous内存、ELF头页⾯、hugetlb private memory内容保存。
关于Linux的coredumpcore dump简介core dump就是在进程crash时把包括内存在内的现场保留下来,以备故障分析。
但有时候,进程crash了却没有输出core,因为有一些因素会影响输出还是不输出core文件。
常见的一个coredump开关是ulimit -c,它限制允许输出的coredump文件的最大size,如果要输出的core文件大小超过这个值将不输出core文件。
ulimit -c的输出为0,代表关闭core dump输出。
设置ulimit -c unlimited,将不对core文件大小做限制这样设置的ulimit值只在当前会话中有效,重开一个终端起进程是不受影响的。
ulimit -c只是众多影响core输出因素中的一个,其它因素可以参考man。
其实还漏了一个,进程可以捕获那些本来会出core的信号,然后自己来处理,比如MySQL就是这么干的。
abrtdRHEL/CentOS下默认开启abrtd进行故障现场记录(包括生成coredump)和故障报告此时abrtd进程是启动的,core文件的生成位置被重定向到了abrt-hook-ccpp测试coredump生成以下产生coredump的程序,并执行。
testcoredump.c:编译并执行查看系统日志,中途临时产生了core文件,但最后又被删掉了。
abrtd默认只保留软件包里的程序产生的core文件,修改下面的参数可以让其记录所有程序的core文件。
再执行一次测试程序就好生成core文件了abrtd可以识别出是重复问题,并能够去重,这可以防止core文件生成的过多把磁盘用光。
abrtd对crash报告的大小(主要是core文件)有限制(参数MaxCrashReportsSize设置),超过了也不会生成core文件,相应的日志如下。
abrtd如何工作abrtd是监控/var/spool/abrt/目录触发的,做个copy操作也会触发abrtd。
coredump1. 在嵌入式系统中,有时core dump直接从串口打印出来,结合objdump查找ra和epa地址,运用栈回溯,可以找到程序出错的地方。
2. 在一般Linux系统中,默认是不会产生core dump文件的,通过ulimit -c来查看core dump文件的大小,一般开始是0,可以设置core文件大小,ulimit -c 1024(kbytes单位)或者ulimit -c unlimited。
3. core dump文件输出设置,一般默认是当前目录,可以在/proc/sys/kernel中找到core-user-pid,通过echo "1" > /proc/sys/kernel/core-user-pid使core文件名加上pid号,还可以用mkdir -p /root/corefileecho "/root/corefile/core-%e-%p-%t" > /proc/sys/kernel/core-pattern控制core文件保存位置和文件名格式。
以下是参数列表:%p - insert pid into filename 添加pid%u - insert current uid into filename 添加当前uid%g - insert current gid into filename 添加当前gid%s - insert signal that caused the coredump into the filename 添加导致产生core的信号%t - insert UNIX time that the coredump occurred into filename 添加core文件生成时的unix时间%h - insert hostname where the coredump happened into filename 添加主机名%e - insert coredumping executable name into filename 添加命令名4. 用gdb查看core文件:下面我们可以在发生运行时信号引起的错误时发生core dump了.编译时加上-g发生core dump之后, 用gdb进行查看core文件的内容, 以定位文件中引发core dump的行.gdb [exec file] [core file]如:gdb ./test test.core在进入gdb后, 用bt命令查看backtrace以检查发生程序运行到哪里, 来定位core dump的文件行.5. 给个例子test.cvoid a(){char *p = NULL;printf("%d/n", *p);}int main(){a();return 0;}编译 gcc -g -o test test.c运行 ./test报segmentation fault(core dump)gdb ./test test.core如果生成的是test.core.开发过程中,当一个Linux程序异常退出时,我们可以通过core 文件来分析它异常的详细原因。
线程堆栈⼤⼩pthread_attr_setstacksize的使⽤pthread_create 创建线程时,若不指定分配堆栈⼤⼩,系统会分配默认值,查看默认值⽅法如下:# ulimit -s8192#上述表⽰为8M;单位为KB。
也可以通过# ulimit -a 其中 stack size 项也表⽰堆栈⼤⼩。
ulimit -s value ⽤来重新设置stack ⼤⼩。
⼀般来说默认堆栈⼤⼩为 8388608; 堆栈最⼩为 16384 。
单位为字节。
堆栈最⼩值定义为 PTHREAD_STACK_MIN ,包含#include <limits.h>后可以通过打印其值查看。
对于默认值可以通过pthread_attr_getstacksize (&attr, &stack_size); 打印stack_size来查看。
尤其在嵌⼊式中内存不是很⼤,若采⽤默认值的话,会导致出现问题,若内存不⾜,则 pthread_create 会返回 12,定义如下:#define EAGAIN 11#define ENOMEM 12 /* Out of memory */上⾯了解了堆栈⼤⼩,下⾯就来了解如何使⽤ pthread_attr_setstacksize 重新设置堆栈⼤⼩。
先看下它的原型:#include <pthread.h>int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize);attr 是线程属性变量;stacksize 则是设置的堆栈⼤⼩。
返回值0,-1分别表⽰成功与失败。
这⾥是使⽤⽅法pthread_t thread_id;int ret ,stacksize = 20480; /*thread 堆栈设置为20K,stacksize以字节为单位。
*/pthread_attr_t attr;ret = pthread_attr_init(&attr); /*初始化线程属性*/if (ret != 0)return -1;ret = pthread_attr_setstacksize(&attr, stacksize);if(ret != 0)return -1;ret = pthread_create (&thread_id, &attr, &func, NULL);if(ret != 0)return -1;ret = pthread_attr_destroy(&attr); /*不再使⽤线程属性,将其销毁*/if(ret != 0)return -1;。
先来讲说线程内存相关的东西,主要有下面几条:1.进程中的所有的线程共享相同的地址空间。
2.任何声明为static/extern的变量或者堆变量可以被进程内所有的线程读写。
3.一个线程真正拥有的唯一私有储存是处理器寄存器。
4.线程栈可以通过暴露栈地址的方式与其它线程进行共享。
有大数据量处理的应用中,有时我们有必要在栈空间分配一个大的内存块或者要分配很多小的内存块,但是线程的栈空间的最大值在线程创建的时候就已经定下来了,如果栈的大小超过个了个值,系统将访问未授权的内存块,毫无疑问,再来的肯定是一个段错误。
可是没办法,你还是不得不分配这些内存,于是你开会为分配一个整数值而动用malloc这种超级耗时的操作。
当然,在你的需求可以评估的情况下,你的需求还是可以通过修改线程的栈空间的大小来改变的。
下面的我们用pthread_attr_getstacksize和pthread_attr_setstacksize的方法来查看和设置线程的栈空间。
注意:下面的测试代码在我自己的机子上(ubuntu6.06,ubuntu6.10,redhat 9, gentoo)通过了测试,但是很奇怪的是在我同事的机子上,无论是改变环境,还是想其它方法都不能正常的运行。
在网上查了一下,很多人也存在同样的问题,至今不知道为何。
linux线程的实现方式决定了对进程的限制同样加在了线程身上:)所以,有问题,请参见<pthread之线程栈空间(2)(进行栈)直接看代码吧,只有一个C文件(thread_attr.c)#include <limits.h>#include <pthread.h>#include "errors.h"//线程体,在栈中分配一个大小为15M的空间,并进行读写void *thread_routine (void *arg){printf ("The thread is here\n");//栈大小为16M,如果直接分配16M的栈空间,会出现段错误,因为栈中还有其它的//变量要放署char p[1024*1024*15];int i=1024*1024*15;//确定内存分配的确成功了while(i--){p[i] = 3;}printf( "Get 15M Memory!!!\n" );//分配更多的内存(如果分配1024*1020*512的话就会出现段错误) char p2[ 1024 * 1020 + 256 ];memset( p2, 0, sizeof( char ) * ( 1024 * 1020 + 256 ) );printf( "Get More Memory!!!\n" );return NULL;}int main (int argc, char *argv[]){pthread_t thread_id;pthread_attr_t thread_attr;size_t stack_size;int status;status = pthread_attr_init (&thread_attr);if (status != 0)err_abort (status, "Create attr");status = pthread_attr_setdetachstate (&thread_attr, PTHREAD_CREATE_DETACHED);if (status != 0)err_abort (status, "Set detach");//通常出现的问题之一,下面的宏没有定义#ifdef _POSIX_THREAD_ATTR_STACKSIZE//得到当前的线程栈大小status = pthread_attr_getstacksize (&thread_attr, &stack_size); if (status != 0)err_abort (status, "Get stack size");printf ("Default stack size is %u; minimum is %u\n",stack_size, PTHREAD_STACK_MIN);//设置当前的线程的大小status = pthread_attr_setstacksize (&thread_attr, PTHREAD_STACK_MIN*1024);if (status != 0)err_abort (status, "Set stack size");//得到当前的线程栈的大小status = pthread_attr_getstacksize (&thread_attr, &stack_size);if (status != 0)err_abort (status, "Get stack size");printf ("Default stack size is %u; minimum is %u\n",stack_size, PTHREAD_STACK_MIN);#endifint i = 5;//分配5个具有上面的属性的线程体while(i--){status = pthread_create (&thread_id, &thread_attr, thread_routine, NULL); if (status != 0)err_abort (status, "Create thread");}getchar();printf ("Main exiting\n");pthread_exit (NULL);return 0;}看看执行过程:dongq@DongQ_Lap ~/workspace/test/pthread_attr $ makecc -pthread -g -DDEBUG -lrt -o thread_attr thread_attr.cdongq@DongQ_Lap ~/workspace/test/pthread_attr $ ./thread_attrDefault stack size is 8388608; minimum is 16384 //默认的栈大小为8MDefault stack size is 16777216; minimum is 16384 //设置后的结果为16MThe thread is hereThe thread is hereThe thread is hereThe thread is hereThe thread is hereGet 15M Memory!!!Get More Memory!!!Get 15M Memory!!!Get More Memory!!!Get 15M Memory!!!Get 15M Memory!!!Get More Memory!!!Get More Memory!!!Get 15M Memory!!!Get More Memory!!!Main exitings用下面的命令来看linux下面的对系统的一些限制:dongq@DongQ_Lap ~/workspace/test/pthread_attr $ ulimit -acore file size (blocks, -c) 0data seg size (kbytes, -d) unlimitedscheduling priority (-e) 0file size (blocks, -f) unlimitedpending signals (-i) 16365max locked memory (kbytes, -l) 32max memory size (kbytes, -m) unlimitedopen files (-n) 1024pipe size (512 bytes, -p) 8POSIX message queues (bytes, -q) 819200real-time priority (-r) 0stack size (kbytes, -s) 8196cpu time (seconds, -t) unlimitedmax user processes (-u) 16365virtual memory (kbytes, -v) unlimitedfile locks (-x) unlimited通过上面的命令,我们可以清楚的看到一个进程在正常的情况下,最大的栈空间为8M。
那么8M我们够用吗?当你分配大量的static或者auto变量的时候,一般都是放在栈空间的。
如果分配一个大于8M的数组,会发生什么呢?先来看看测试代码:int main(){int i = 1024 * 1024 * 8;char p[ i ];memset( p, 0, sizeof( char ) * i );while( i-- ){p[ i ] = i;}return 0;}上面的代码直接分配一个大小为8M的数组,编译后运行,出现段错误!!很奇怪吗?不是说可以分配8M吗?怎么不行?当然不行,因为在分配p时,栈中已经放有其它的变量,最明显的就是int i;这样子的话,栈中就没有足够的空间给变量p分配,从而出现段错误。
下面用gdb进行调试:DongQ_Lap pthread_attr # gdb process_stackGNU gdb 6.5(gdb) b mainBreakpoint 1 at 0x8048392: file process_stack.c, line 13.(gdb) r > /home/dongq/tmp/gdb.txtStarting program:/home/dongq/workspace/test/pthread_attr/process_stack >/home/dongq/tmp/gdb.txt[Thread debugging using libthread_db enabled][New Thread -1209533760 (LWP 10947)][Switching to Thread -1209533760 (LWP 10947)]Breakpoint 1, main () at process_stack.c:1313 {(gdb) s15 int i = 1024 * 1024 * 8;(gdb) s16 char p[ i ];(gdb) s17 memset( p, 0, sizeof( char ) * i );(gdb) p p$1 = 0xbf6c3470 <Address 0xbf6c3470 out of bounds>(gdb) sProgram received signal SIGSEGV, Segmentation fault.0x080483d4 in main () at process_stack.c:1717 memset( p, 0, sizeof( char ) * i );(gdb) bt#0 0x080483d4 in main () at process_stack.c:17(gdb) quit看到了吗?char p[i]这句执行后的结果是out of bounds!!也就是内存没有分配成功。