统计学教程(含spss)二 统计量描述
- 格式:ppt
- 大小:366.00 KB
- 文档页数:24


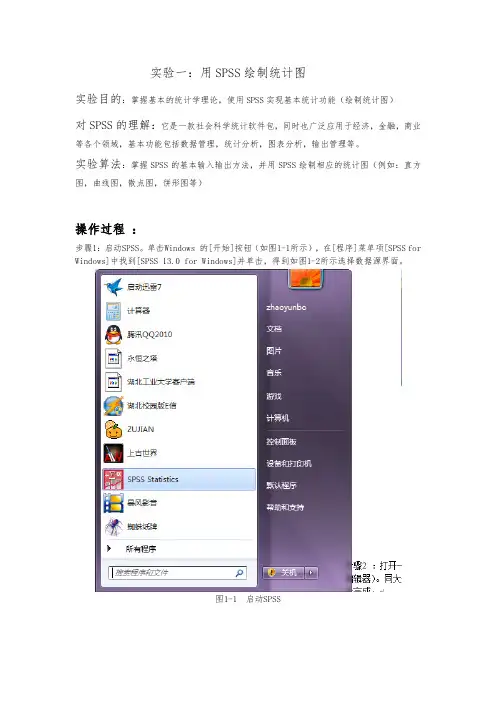
实验一:用SPSS绘制统计图实验目的:掌握基本的统计学理论,使用SPSS实现基本统计功能(绘制统计图)对SPSS的理解:它是一款社会科学统计软件包,同时也广泛应用于经济,金融,商业等各个领域,基本功能包括数据管理,统计分析,图表分析,输出管理等。
实验算法:掌握SPSS的基本输入输出方法,并用SPSS绘制相应的统计图(例如:直方图,曲线图,散点图,饼形图等)操作过程:步骤1:启动SPSS。
单击Windows 的[开始]按钮(如图1-1所示),在[程序]菜单项[SPSS for Windows]中找到[SPSS 13.0 for Windows]并单击,得到如图1-2所示选择数据源界面。
图1-1 启动SPSS图1-2 选择数据源界面步骤2 :打开一个空白的SPSS数据文件,如图1-3。
启动SPSS 后,出现SPSS 主界面(数据编辑器)。
同大多数Windows 程序一样,SPSS 是以菜单驱动的。
多数功能通过从菜单中选择完成。
图1-3 空白的SPSS数据文件步骤3:数据的输入。
打开SPSS以后,直接进入变量视图窗口。
SPSS的变量视图窗口分为data view和variable view两个。
先在variable view中定义变量,然后在data view里面直接输入自定义数据。
命名为mydata并保存在桌面。
如图1-4所示。
图1-4 数据的输入步骤4:调用Graphs菜单的Bar过程,绘制直条图。
直条图用直条的长短来表示非连续性资料(该资料可以是绝对数,也可以是相对数)的数量大小。
选择的数据源见表1。
步骤5:数据准备。
激活数据管理窗口,定义变量名:年龄标化发生率为RATE,冠心病临床型为DISEASE,血压状态为BP。
RATE按原数据输入,DISEASE按冠状动脉机能不全=1、猝死=2、心绞痛=3、心肌梗塞=4输入,BP按正常=1、临界=2、异常=3输入。
步骤6:选Graphs菜单的Bar...过程,弹出Bar Chart定义选项框(图1-5)。

统计描述符合正态分布或近似正态分布资料的统计描述统计量:(一)描述平均水平的常用统计量——算术均数(二)描述变异水平(离散程度)的常用统计量——离均差平方和(SS)、平均方差(方差:MS)、标准差(SD)(三)描述抽样误差大小的统计量——标准误(SE)。
SPSS操作:对某1变量(如time)进行统计描述:正态性检验:Analyze→nonparametric tests→1-sample K-S→调入某变量和激活Nomal→OK。
正态的统计描述:analyze→descriptive statistics→descriptives→调入某变量,点击option…→点击mean、SE、SD→OK。
分析结果:表descriptive statistics(可看N、min、max、mean、SD);Z=0.649;P=0.794>0.05.说明time服从近似正态分布。
对某一变量分组进行统计描述(如按男、女分别做time的统计描述):文件分割:data→split file;注意:计算机有记忆功能,文件分割后需要把它还原,才不会影响后续操作。
统计描述(操作同上):analyze→descriptive statistics→descriptives→调入某变量,点击option…→点击mean、SE、SD→OK。
非正态资料的统计描述统计量:(一)描述集中位置——中位数(二)描述变异水平(离散程度)——四分位数间距=P75-P25。
SPSS操作:对某1变量(红血球体积hct)进行统计描述:正态性检验(同上):Analyze→nonparametric tests→1-sample K-S→调入某变量和激活Nomal→OK。
非正态的统计描述:analyze→descriptive statistics→frequencies→调入某变量,点击statistics…→点击median和quartiles。
编制频数分布表和绘制频数分布直方图一、对数据进行重新编码(recod e)SPSS操作:统计描述:Recode:Transform→recode into different variables…(表示recode后存入新的变量名中,原始数据还在)→调入变量进入“input→output”中,在右侧output框中输入新的变量名,可label→点击change→点击框下的old and new values…→根据手工分组,确定组距后:lowest:1→range→higest:最后一组→OK。






CENTRAL SOUTH UNIVERSITYSPSS实验报告学生姓名王强学号**********指导教师邵留国学院商学院专业工商1101实验一、数据集实验目的:掌握基本的统计学理论,学会使用SPSS录入数据,建立SPSS数据集。
实验内容:1.3:三十名儿童身高、体重样本数据如下表所示。
建立SPSS数据集。
三十名儿童身高、体重样本数据实验步骤:步骤一:启动SPSS。
步骤二:选择文件,新建,数据,如图。
步骤三:切换到变量视图,定义变量。
其中,性别变量需要设置值标签。
如图所示。
步骤四:切换到数据视图,按照次序依次输入数据。
步骤五:保存数据.实验结果:实验二:统计量描述实验目的:(1)结合图表描述掌握各种描述性统计量的构造原理及其应用.(2)熟练掌握运用SPSS进行统计描述的基本技能。
实验内容:大学生在校期间的各门课程考试成绩,尽管在学生与学生之间、院系之间、男女生之间以及不同的课程之间,都存在着各种各样的差异,但整体上的分布状况还是有规律可循的.今有两个学院共1040名男女生的统计学和经济学期末考试成绩数据,储存在SPSS数据文件中,文件名:lytjcj。
sav。
试运用图表描述与统计量描述的方法,对此数据展开尽可能全面和深入的描述与分析。
实验步骤:步骤一:打开SPSS数据,文件名:lytjcj.sav。
如图。
步骤二:点击“分析"中的“描述统计",选择“频率",如图所示。
步骤三:弹出一个“频率"对话框,如图。
步骤四:将“统计成绩”和“经济成绩”拖入“变量"框中,点击确定。
实验结果:实验三:参数估计实验目的:(1)掌握单样本总体均值区间估计。
(2)掌握总体均值差区间估计.(3)熟练掌握相关的SPSS操作。
实验内容:某地区的一位针对老年人市场的电视节目赞助商,希望了解老年人每周看电视的时间,因为这个信息对电视节目设计以及广告策略和广告数量的制定有着重要的参考价值。

在教育技术研究过程中收集到大量的资料数据,但从这些杂乱无章的资料中,很难对其总体水平与分布状况做出评价判断。
因此,必须采用一些适当的方法对这些资料进行处理,使之简约化、分类化、系统化,从中发现它们的分布规律,掌握总体的特征,以便对其水平做出客观的评价。
统计描述方法,是研究简缩数据并描述这些数据的统计方法。
将搜集来的大量数据资料,加以整理、归纳和分组,简缩成易于处理和便于理解的形式,并计算所得数据的各种统计量,如平均数、标准差、以及描述有关事物或现象的分布情况、波动范围和相关程度等,以揭示其特点和规律。
(一)数据资料的整理和表示在教育技术研究中,我们用各种方法搜集来的资料,一般是零散的,它只反映个别现象的个别特征,必须经过整理加工,使之系统化,才能计算统计指标,进行统计分析,为进一步研究提供有用的信息,首先要进行的是统计整理,它包含以下几部分内容:1.数据检查主要检查数据的完整性与正确性。
统计资料完整性的检查,就是要根据调查项目检查是否填写齐全,避免遗漏,删去重复。
正确性检查,就是检查搜集的资料是否真实可靠。
特别是统计数字的真实性是统计工作的生命,统计资料的检查整理必须抓紧这一环。
数据检查可分为逻辑检查和计算检查两种方法。
逻辑检查,是从理论和一般常识上来检查资料内容是否合理,指标之间是否矛盾。
计算检查是检查统计数字在计算方法和计算结果上有否错误。
2.数据分类数据分类就是把搜集来的数据进行分组归类。
数据分类要做到既不重复、不遗漏,又不混淆,一般又可分为品质分类和数量分类。
品质分类:是按事物性质划分为不同的组别、种类。
如以性别为标志可分为男与女;按“理解能力”、“学习态度”等为标志,又可分为好、较好、一般、差等几种水平,每种水平可看成类,每一类可给以相当的数量。
可以通过各类所包含的数据再进行数量化的比较和分析。
数量分类:是按数量的属性分类。
有顺序排列法、等级排列法和次数分布法等。
⒊数据的排序数据排序:将各数据从大到小或从小到大进行排列。
统计学分析与常用SPSS方法统计学分析是利用统计学方法对收集的数据进行分析和解释的过程。
它广泛应用于各个领域,包括社会科学、医学、工程学、经济学等等。
在统计学分析中,借助于计算机软件工具,如SPSS,可以更快速、准确地进行数据整理、统计分析和结果呈现。
本文将介绍统计学分析的一些常用方法和SPSS软件的使用。
统计学分析的基本步骤包括:数据清理和整理、描述性统计分析、推断性统计分析和结果呈现。
首先,数据清理和整理是确保数据的完整性和一致性的重要步骤。
它包括去除缺失值、异常值和离群值,并进行数据转换或缩放,以满足统计分析的要求。
描述性统计分析是对数据的总体特征进行描述的方法。
常见的描述性统计量有均值、中位数、众数、标准差等。
这些统计量可以帮助我们理解数据的分布、集中趋势和离散程度。
此外,描述性统计图也是展示数据特征的重要工具,如直方图、箱线图、散点图等。
推断性统计分析是通过从样本中得出结论来推断总体特征的方法。
常用的推断性统计方法包括假设检验和置信区间估计。
假设检验用于判断样本数据是否与一些假设相符。
其中,显著性水平是一个重要的概念,它表示在零假设成立的情况下,观察到的差异发生的概率。
在假设检验中,常用的方法有t检验、方差分析、相关分析、回归分析等。
置信区间估计是对总体特征的一个区间范围的估计。
它表示我们对总体特征的不确定性。
SPSS(Statistical Package for the Social Sciences)是一个功能强大的统计分析软件。
它提供了丰富的统计分析功能和用户友好的操作界面。
SPSS中常用的方法包括数据的导入和导出、数据整理和变换、描述性统计分析、推断性统计分析、因子分析和聚类分析等。
在SPSS中,数据的导入包括从Excel、文本文件或数据库中导入数据。
数据整理和变换功能包括去除无效数据、添加变量、生成新变量和数据的转换等。
描述性统计分析功能可以计算数据的均值、中位数、标准差、众数、偏度和峰度等统计量,并展示相关的频数分布、累积百分比和分布图。
第二节常用的数据描述统计本节拟讲述如何通过SPSS菜单或命令获得常用的统计量、频数分布表等。
1.数据这部分所用数据为第一章例1中学生成绩的数据,这里我们加入描述学生性别的变量“sex"和班级的变量“class",前几个数据显示如下(图2-2),将数据保存到名为“2-6-1。
sav”的文件中.图2-2:数据输入格式示例1.Frequencies语句(1)操作打开数据文件“2-6—1。
sav”,单击主菜单Analyze /Descriptive Statistics / F requencies…,出现频数分布表对话框如图2—3所示。
图2-3:Frequencies定义窗口把score变量从左边变量表列中选到右边,并请注意选中下方的Display frequency table复选框(要求显示频数分布表).如果您只要求得到一个频数分布表,那么就可以点OK按钮了.如果您想同时获得一些统计量,及统计图表,还需要进一步设置。
①Statistics选项单击Statistics按钮,打开对话框,请按图2—4自行设置。
有关说明如下:(ⅰ)在定义百分位值(percentile value)的矩形框中,选择想要输出的各种分位数,SPSS提供的选项有:●Quartiles四分位数,即显示25%、50%、75%的百分位数。
●Cut points equal 把数据平均分为几份.如本例中要求平均分为3份.●Percentile显示用户指定的百分位数,可重复多次操作。
本例中要求15%、50%、85%的百分位数。
(ⅱ) 在定义输出集中趋势(Central Tendency)的矩形框中,选择想要输出的集中统计量,常用的选项有:●Mean 算术平均数●Median 中数●Mode 众数●Sum 算术和(ⅲ)在定义输出离散统计量(Dispersion)的矩形框中,选择想要输出的离散统计量,常用的选项有:●Std. Deviation 标准差●Variance 方差●Range 全距●Minimum 最小值●Maximum 最大值●S。