实验六-用SPSS进行非线性回归分析
- 格式:docx
- 大小:123.07 KB
- 文档页数:4

SPSS—非线性回归(模型表达式)案例解析SPSS—非线性回归(模型表达式)案例解析2011-11-16 10:56由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二!非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢?答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究:第一步:非线性模型那么多,我们应该选择“哪一个模型呢?”1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型点击“图形”—图表构建程序—进入如下所示界面:点击确定按钮,得到如下结果:放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高!点击“分析—回归—曲线估计——进入如下界面在“模型”选项中,勾选”二次项“和”S"两个模型,点击确定,得到如下结果:通过“二次”和“S“ 两个模型的对比,可以看出S 模型的拟合度明显高于“二次”模型的拟合度(0.912 >0.900)不过,几乎接近接着,我们采用S 模型,得到如下所示的结果:结果分析:1:从ANOVA表中可以看出:总体误差= 回归平方和+ 残差平方和(共计:0.782)F统计量为(240.216)显著性SIG为(0.000)由于0.000<0.01 (所以具备显著性,方差齐性相等)2:从“系数”表中可以看出:在未标准化的情况下,系数为(-0.986)常数项为2.672所以S 型曲线的表达式为:Y(销售量)=e^(b0+b1/t) = e^(2.672-0.986/广告费用)当数据通过标准化处理后,常数项被剔除了,所以标准化的S型表达式为:Y(销售量) = e^(-0.957/广告费用)下面,我们直接采用“非线性”模型来进行操作第一步:确定“非线性模型”从绘图中可以看出:广告费用在1千万——4千多万的时候,销售量增加的跨度较大,当广告费用超过“4千多万"的时候,增加幅度较小,在达到6千多万”达到顶峰,之后呈现下降趋势。

![非线性回归的参数设置_SPSS 统计分析从入门到精通_[共3页]](https://uimg.taocdn.com/b94e9cb227d3240c8547ef16.webp)
155回归分析 第 8 章2.参数初始值的选择
SPSS 的“非线性”过程需要设置待估参数的初始值,
初始值的大小直接影响着模型的收敛性。
参考图8-27
所示的散点图,对初始值进行如下的计算和设置。
(1)b 1代表了销售量上升趋势的终点,观察散点
图,发现销售量的最大值接近于13,因此建议设定b 1
的初始值为13。
(2)b 2为当x = 0时的y 值与y 的最大值(上限)
之差,因此,可以用y 的最小值减去b 1作为b 2的初始
值,即b 2=7−b 1=7−13=−6。
(3)b 3的初始值可以用图中两个分离点的斜率来表示。
取两个点(x =2,y =8)和(x =5,y =12)
,它们之间的斜率为(12−8)/(5−2)=1.33,所以b 3的初始值可以设为−1.33。
8.3.3 非线性回归的参数设置
依次单击菜单“分析→回归→非线性…”执行非线性回归分析的功能,其主设置界面如图8-28所示,在此设置分析变量和模型的函数形式。
图8-28 非线性回归分析的主设置界面
1.变量选择及模型设置
在变量列表中单击选中“销售量”变量,单击从上至下第一个
按钮,将其指定为因变量;在
模型表达式编辑框中输入b1+b2*EXP(b3*advert)。
① 因变量:从变量列表中选入一个数值型变量作为因变量。
② 模型表达式编辑框:用于设置模型的函数表达式,可以直接输入和编辑函数表达式;还可以从变量列表中选入自变量的名称(单击旁边的即可);从符号区域选入数字或运算符(单变量列表
参数列表
函数说明区 函数列表
图8-27 销售量对广告费用的散点图。


非线性回归分析(转载)(2009-10-23 08:40:20)转载分类:Web分析标签:杂谈在回归分析中,当自变量和因变量间的关系不能简单地表示为线性方程,或者不能表示为可化为线性方程的时侯,可采用非线性估计来建立回归模型。
SPSS提供了非线性回归“Nonlinear”过程,下面就以实例来介绍非线性拟合“Nonlinear”过程的基本步骤和使用方法。
应用实例研究了南美斑潜蝇幼虫在不同温度条件下的发育速率,得到试验数据如下:表5-1 南美斑潜蝇幼虫在不同温度条件下的发育速率温度℃17.5 20 22.5 25 27.5 30 35 发育速率0.0638 0.0826 0.1100 0.1327 0.1667 0.1859 0.1572 根据以上数据拟合逻辑斯蒂模型:本例子数据保存在DATA6-4.SAV。
1)准备分析数据在SPSS数据编辑窗口建立变量“t”和“v”两个变量,把表6-14中的数据分别输入“温度”和“发育速率”对应的变量中。
或者打开已经存在的数据文件(DATA6-4.SAV)。
2)启动线性回归过程单击SPSS主菜单的“Analyze”下的“Regression”中“Nonlinear”项,将打开如图5-1所示的线回归对话窗口。
图5-1 Nonlinear非线性回归对话窗口3) 设置分析变量设置因变量:从左侧的变量列表框中选择一个因变量进入“Dependent(s)”框。
本例子选“发育速率[v]”变量为因变量。
4) 设置参数变量和初始值单击“Parameters”按钮,将打开如图6-14所示的对话框。
该对话框用于设置参数的初始值。
图5-2 设置参数初始值“Name”框用于输入参数名称。
“Starting”框用于输入参数的初始值。
输入完参数名和初始值后,单击“Add”按钮,则定义的变量及其初始值将显示在下方的参数框中。
需要修改已经定义的参数变量,先用将其选中,然后在“Name”和“Starting”栏里进行修改,完成后点击“Change”按钮确认修改。
实验三非线性回归分析(2学时)一、实验重点掌握非线性回归分析的方法。
二、实验难点模型的选择及对SPSS软件的输出结果进行分析和整理。
三、实验举例例1、对GDP(国内生产总值)的拟合。
选取GDP指标为因变量,单位为亿元,拟合GDP关于时间t的趋势曲线。
以1981年为基准年,取值为t=1,1998年t=18,1991-1998年的数据如下:解:分析过程(一)画散点图图3.1:Y 与t 的散点图图3.2:Ln Y 与t 的散点图(二)根据画散点图,及经济背景可选用模型 复合函数:01t y b b = (也称增长模型或半对数模型)同时,做简单线性回归 01y b b t =+ 以作比较。
(三)模型求解直接用SPSS 软件的Curve Estimation 命令计算。
(也可以用线性化的方法求解,结果基本一致。
) 运行结果如下:(四)结果分析线性回归方程:2ˆ133754417.520.856y t R =-+=复合函数回归方程:ˆ3603.06(1.1924)t y= ………(*)2ˆln 8.190.1760.992y t R =+=注意:不能直接比较两模型的拟合优度,需要对复合函数模型处理,利用(*)式,得到复合函数的残差,计算该模型的残差平方和RSS=2.1696×108 ,并计算y 的离差平方和TSS=1.1×1010 ,得到非线性回归的相关指数82102.169610110.981.110RSS R TSS ⨯=-=-≈⨯ 由于该相关指数大于线性回归的拟合优度,所以可以判断复合函数模型比线性回归模型要好。
例2 、一位药物学家是用下面的非线性模型对药物反应拟合回归模型1021()i i c i c y c u c =-++ 其中,自变量x 为药剂量,用级别表示; 因变量y 为药物反应程度,用百分数表示。
三个参数c 0 ,c 1 ,c 2都是非负的, c 0 的上限是100%,三个参数的初始值取为c 0 =100,c 1=5 ,c 2=4.8.测得9个数据如下表:解:分析过程:(一)画散点图从图形上看,y 与x 确实呈非线性关系! (二)模型求解用SPSS 软件的Nonlinear 命令计算,具体操作如下: (1)建立数据集;(2)在数据窗口点击:Analyze → Regression → Nonlinear …,出现窗口在将y 点入Dependent 框中,在Model Expression 框中输入表达式:c0-c0/(1+(x/c2)**c1)(3) 点击Parametere …, 出现下图:在Name 框中输入: c0Starting Value 框中输入:100点击add,即可得到参数c0的初始赋值,类似的方法可以得到c1和c2参数的初始赋值,Continue 。

SPSS—非线性回归(模型表达式)案例解析2011-11-16 10:56由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二!非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢?答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究:第一步:非线性模型那么多,我们应该选择“哪一个模型呢?”1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型点击“图形”—图表构建程序—进入如下所示界面:点击确定按钮,得到如下结果:放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高!点击“分析—回归—曲线估计——进入如下界面在“模型”选项中,勾选”二次项“和”S"两个模型,点击确定,得到如下结果:通过“二次”和“S“ 两个模型的对比,可以看出S 模型的拟合度明显高于“二次”模型的拟合度(0.912 >0.900)不过,几乎接近接着,我们采用S 模型,得到如下所示的结果:结果分析:1:从ANOVA表中可以看出:总体误差= 回归平方和 + 残差平方和(共计:0.782)F统计量为(240.216)显著性SIG为(0.000)由于0.000<0.01 (所以具备显著性,方差齐性相等)2:从“系数”表中可以看出:在未标准化的情况下,系数为(-0.986)常数项为2.672所以 S 型曲线的表达式为:Y(销售量)=e^(b0+b1/t) = e^(2.672-0.986/广告费用)当数据通过标准化处理后,常数项被剔除了,所以标准化的S型表达式为:Y(销售量) = e^(-0.957/广告费用)下面,我们直接采用“非线性”模型来进行操作第一步:确定“非线性模型”从绘图中可以看出:广告费用在1千万——4千多万的时候,销售量增加的跨度较大,当广告费用超过“4千多万"的时候,增加幅度较小,在达到6千多万”达到顶峰,之后呈现下降趋势。

《计量地理学》实验指导§2 运用EXCEL、SPSS进行相关分析和线性、非线性回归分析回归分析是处理两个及两个以上变量间线性依存关系的统计方法。
可以通过软件EXCEL 和SPSS实现。
一、利用EXCEL软件实现回归分析以第4章习题2为例,运用EXCEL进行回归分析。
首先在菜单中选择工具==>加载宏,把“分析工具库”和“规划求解”加载上。
然后在“工具”菜单中将出现“数据分析”选项。
点击“数据分析”中的“回归”,将出现对话框如下图1所示。
图1 回归界面【输入】用以选择进行回归分析的自变量和因变量。
在“Y值输入区域”内输入B7:B11,在“X值输入区域”输入A7:A11,如果是多元线性回归,则X值的输入区就是除Y变量以外的全部解释变量“标志”;置信度水平为95%,输出结果选择在一张新的工作表中;“残差分析”,并绘制回归拟合图,点击“确定”即得到残差表。
【输出选项】用于指定输出结果要显示的内容,包括是否需要残差表及图,参差的正态分布图等。
输出结果解释图 2 回归结果显示回归结果分为三部分:(1)回归统计:包括R^2 及调整后的R^2、标准误差和观测值个数(2)方差分析:包括回归平方和、残差平方和总离差平方和以及它们的自由度、均方差和F通机量(3)回归方程的截距、自变量的系数以及它们的t统计值、95%的上下限值图3 残差与子变量之间的散点图图4 预测值与实际值散点图同样,如果在“数据分析”中点击“相关系数”,可以对多个变量进行相关系数的计算。
二、.利用SPSS软件实现回归分析在SPSS软件中,同样可以简单的实现回归分析,因为回归分析包含了线性回归与曲线拟合两部分内容,首先来看线性回归分析过程(LINEAR)(一)线性回归分析过程(LINEAR)例如,课本中数据,把降水量(P)看作因变量,把纬度(Y)看作自变量,在平面直角坐标系中作出散点图,发现它们之间呈线性相关关系,因此,可以用一元线性回归方程近似地描述它们之间的数量关系。

Data42:非线性回归分析 步骤:把数据导入SPSS 程序中,直接进行非线性拟合。
选择analysis->regression->Curve Estimation 。
在弹出来的对话框中选择拟合的变量y(城市化水平)和自变量x (人均GDP),在models 中选择拟合模型。
也可选中其他属性来显示相关数据。
运行后得到模型的拟合效果。
从拟合曲线可以得出,S 模型对世界各国城市化水平与人均GDP 具有较好的拟合效果,同时R2= ,F 检验为 ,信度水平为 ,确定具有非常高的拟合度。
得出的拟合方程为 。
从拟合曲线可以看出,S 模型对表1的人口数据具有较好的拟合效果,同时R2为0.84199,F 检验为149.20201,确定具有非常高的拟合度。
在models 中选择拟合模型:本例选择S 模型。
各种拟合模型的拟合公式如下:Data39 逐步回归分析建立最佳模型步骤:把数据导入SPSS 程序中,直接进行逐步线性回归分析。
选择analysis->regression->linear 。
在弹出来的对话框中选择拟合的变量y(旅游总收入)和自变量x1(国内游客)、x2(海外游客)、x3(第三产业)、x4(人均GDP),然后分别选择Stepwise 、为函数的上限)(其中u b b u y Logistic t b y Power t b b y Inverse e b y l Exponentia e y S tb t b t b b y Cubic t b b y c Lograithmi ey Growth bb y Compound tb t b b y Quadratic t b b y Linear t b t b t b b t b b t 100100)(33221010)(1022101011::/::::)ln(:::::111010+==+===+++=+===++=+=++Remove、Backward、Forward方法对模型进行分析,看看哪种模型是最佳模型。
实验六用SPSS进行非线性回归分析例:通过对比12个同类企业的月产量(万台)与单位成本(元)的资料(如图1),试配合适当的回归模型分析月产量与单位成本之间的关系图1原始数据和散点图分析一、散点图分析和初始模型选择在SPSS数据窗口中输入数据,然后插入散点图(选择Graphs→Scatter命令),由散点图可以看出,该数据配合线性模型、指数模型、对数模型和幂函数模型都比较合适。
进一步进行曲线估计:从Statistic下选Regression菜单中的Curve Estimation命令;选因变量单位成本到Dependent框中,自变量月产量到Independent框中,在Models框中选择Linear、Logarithmic、Power和Exponential四个复选框,确定后输出分析结果,见表1。
分析各模型的R平方,选择指数模型较好,其初始模型为但考虑到在线性变换过程可能会使原模型失去残差平方和最小的意义,因此进一步对原模型表1曲线估计输出结果二、非线性模型的优化SPSS提供了非线性回归分析工具,可以对非线性模型进行优化,使其残差平方和达到最小。
从Statistic下选Regression菜单中的Nonlinear命令;按Paramaters按钮,输入参数A:176.57和B:-.0183;选单位成本到Dependent框中,在模型表达式框中输入“A*EXP(B*月产量)”,确定。
SPSS输出结果见表2。
由输出结果可以看出,经过6次模型迭代过程,残差平方和已有了较大改善,缩小为568.97,误差率小于0.00000001,优化后的模型为:2.1 83887.036 268.159 -.1333.0 83887.036 268.159 -.1333.1 59358.745 340.412 -.1024.0 59358.745 340.412 -.1024.1 26232.008 385.967 -.0655.0 26232.008 385.967 -.0655.1 7977.231 261.978 -.0386.0 7977.231 261.978 -.0386.1 1388.850 153.617 -.0157.0 1388.850 153.617 -.0157.1 581.073 180.889 -.0198.0 581.073 180.889 -.0198.1 568.969 182.341 -.0199.0 568.969 182.341 -.0199.1 568.969 182.334 -.01910.0 568.969 182.334 -.01910.1 568.969 182.334 -.019导数是通过数字计算的。

非线性回归非线性模型非线性函数非线性表达式SPSSAU非线性回归模型如果数学模型为非线性关系,比如人口学增长模型Logistic(S模型),其模式公式为:y = b1 / (1 + exp(b2 + b3 * x)),其中y为人口数量,x为年份(实际数据为第n年,数字从0年起,依次顺序增加),b1,b2和b3分别为三个估计参数,exp为自然指数的意思。
此数学表达式并非线性表达式,因此不能使用SPSSAU的线性回归进行拟合。
诸如此类非线性关系(即不是直接关系)的非线性模型,可使用非线性回归进行研究。
SPSSAU当前提供约50类非线性函数表达式,涵盖绝大多数非线性函数表达式。
如下图:备注:图中出现的b1,b2,b3等代表待估计参数;exp表示自然指数,ln表示自然对数,cos表示余弦函数;“**”表示指数的意思。
进行非线性回归模型构建时,通常分为三步。
第一步:首先需要结合专业知识选择正确的构建模型,比如人口增长预测时使用logistic模型,经济学研究的抛物线二次曲线模型等。
第二步:设置参数初始值;与线性回归不同,非线性回归模型数学原理上使用迭代思想计算参数估计值,因而对初始值的不同设置,很可能会导致不同的结果,因而初始值设置较为重要,其可使用模型求解更为精确,并且有助于模型快速迭代收敛。
关于初始值的设置在案例中有更详细说明。
第三步:模型预测。
在得到参数拟合值后,并且拟合效果在认可范围内时,那么可使用模型进行预测数据,输入X的数据信息,对应得到Y的预测值。
特别提示:关于初始值。
初始值是由研究人员输入的一个‘大概’值,即参数的大概估计值,大概预期的值,与此同时,也可设置参数的范围,即上下界,但通常情况下不设置上下界值,除非认为有必要,通常不需要设置上下界值。
关于初始值的设置方法。
通常包括两种,一是结合专业知识进行判断,二是利用模型公式时的特殊点(比如X=0时,Y=?)去求解得到。
专业知识判断上,某参数的实际意义为数据的最大值,那么就设定该参数为最大值即可。
线性回归的首要满足条件是因变量与自变量之间呈线性关系,之后的拟合算法也是基于此,但是如果碰到因变量与自变量呈非线性关系的话,就需要使用非线性回归进行分析。
SPSS中的非线性回归有两个过程可以调用,一个是分析—回归—曲线估计,另一个是分析—回归—非线性,两种过程的思路不同,这也是非线性回归的两种分析方法,前者是通过变量转换,将曲线线性化,再使用线性回归进行拟合;后者则是直接按照非线性模型进行拟合。
我们按照两种方法分别拟合同一组数据,将结果进行比较。
分析—回归—曲线估计
变量转换的方法简单易行,在某些情况下是首选,但是只能拟合比较简单的(选项中有的)非线性关系,并且该方法存在一定的缺陷,例如
1.通过变量转换使用最小二乘法拟合的结果,再变换回原值之后不一定是最优解,并且变量转换也可能会改变残差的分布和独立性等性质。
2.曲线关系复杂时,无法通过变量转换进行直线化
3.曲线直线化之后,只能通过最小二乘法进行拟合,其他拟合方法无法实现
基于以上问题,非线性回归模型可以很好的解决,它和线性回归模型一样,也提出一个基本模型框架,所不同的是模型中的期望函数可以为任意形式,甚至没有表达式,在参数估计上,由于是曲线,无法直接使用最小二乘法进行估计,需要使用高斯-牛顿法进行估计,这一方法比较依赖于初始值的设定。
下面我们来直接按照非线性模型进行拟合,看看结果如何
分析—回归—非线性
以上用了两种方差进行拟合,从决定系数来看似乎非线性回归更好一点,但是要注意的是,曲线回归计算出的决定系数是变量转换之后的,并不一定能代表变换之前的变异解释程度,这也说明二者的决定系数不一定可比。
我们可以通过两种方法计算出的预测值与残差图进行比较来判断优劣,首先将相关结果保存为变量,再做图。
SPSS—非线性回归(模型表达式)案例解析非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢?答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究:第一步:非线性模型那么多,我们应该选择“哪一个模型呢?”1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型点击“图形”—图表构建程序—进入如下所示界面:点击确定按钮,得到如下结果:放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高!点击“分析—回归—曲线估计——进入如下界面在“模型”选项中,勾选”二次项“和”S"两个模型,点击确定,得到如下结果:通过“二次”和“S“ 两个模型的对比,可以看出S 模型的拟合度明显高于“二次”模型的拟合度(0.912 >0.900)不过,几乎接近接着,我们采用S 模型,得到如下所示的结果:结果分析:1:从ANOVA表中可以看出:总体误差= 回归平方和+ 残差平方和(共计:0.782)F统计量为(240.216)显著性SIG为(0.000)由于0.000<0.01 (所以具备显著性,方差齐性相等)2:从“系数”表中可以看出:在未标准化的情况下,系数为(-0.986)常数项为2.672所以S 型曲线的表达式为:Y(销售量)=e^(b0+b1/t) = e^(2.672-0.986/广告费用)当数据通过标准化处理后,常数项被剔除了,所以标准化的S型表达式为:Y(销售量)= e^(-0.957/广告费用)下面,我们直接采用“非线性”模型来进行操作第一步:确定“非线性模型”从绘图中可以看出:广告费用在1千万——4千多万的时候,销售量增加的跨度较大,当广告费用超过“4千多万"的时候,增加幅度较小,在达到6千多万”达到顶峰,之后呈现下降趋势。
多元回归分析f回归f线性,拟合优度检验总离差平方和(tss)::回归平方和(ess) +残差平方和(rss):可决系数的取值范围:[0,1]. R2越接近1,说明实际观测点离样本线越近,拟合优度高_由增加解释变量个数引起的R2的增大与拟合好坏无矢,R2需调整。
调整的可决系数思路是:将残差平方和与总离差平方和分别除以各自的自由度(出),以剔除变量个数对拟合优度的影响:(2)方程总体线性的显著性检验(F检验Ho: Pi=Pz= ... =pk=OHi: Oj不全为0F> F o(/c,n-k-l)或FWFa(k“k • I)来拒绝或接受原假设Ho,以判定原方程总体上的线性矢系是否显著成立。
(3)变量的显著检验(t检验)如果变量X对Y的影响是显著的,那么X前的参数应该显著的不为0检验步骤:1)对总体参数提出假设Ho: Pi=OtHi: Pi#0若|t|>ta/2(n • 2),则拒绝HO,接受HI;(小概率事件发生)若|t|Mta/2(n • 2),贝! I接受H0 ;看指标选模型<拟合程度Adjusted 越接近1拟合程度越好4回归方程的显著性检验F统计量的值,及其Sig4回归系数表回归系数B和显著性检验Sig(4)满足基本要求的样本容量从统计检验的角度:n>30时,Z检验才能应用;”炬8时,t分布较为稳定四、预测一元或多元模型预测的SPSS实现:特征根和方差比特征根是诊断解释变量间是否存在严重的多重共线性的另一种有效方法。
最大特征根的值远远大于其他特征根的值,则说明这些解释变量间具有相当多的重叠信息,原因是仅通过这一个特征根就基本刻画出了所有解釋变量的绝大部分信息。
解释变量标准化后它的方差为“如果某个特征根既能够刻画某解释变量方差的较大部分(0.7以上),同时又可以刻画另一根解释变量方差的较大部分,则说明这两个解释变量间存在较强的线性相矢矢系。
4、条件指数条件指数反映解释变量间多重共线性的指标。
课程名称实用统计软件
实验项目名称非线性回归分析
实验成绩指导老师(签名)日期 2011-9-23
一.实验目的
1.掌握非线性回归的基本原理和算法;
2.能够用SPSS软件应用非线性回归模型解决实际问题。
二. 实验内容与要求
1.根据数据金属强度测试.sav利用曲线参数估计法分析金属强度(y)与温度(x)之间的关系。
2.实现书上 P189 中的研究问题。
第一步要选中所有的模型,然后根据R-square 和拟合曲线标准选择模型!
并且要预测到2010年的数据!
三.实验步骤
1.模型选择(标准:R-square 以及拟合曲线的比较)
2.所选择模型的拟合优度(R-square、拟合曲线)
3.所选择模型的回归方程(回归系数的估计值)
4.所选择模型的检验问题(模型方差分析表:模型显著性F检验、回归系数非零T检验)
5.保存关心的统计数据(预测值、残差值、预测值的置信区间)
具体操作参见课件非线性回归分析.PPT
四. 实验结果(数据与图形)与分析
Cubic,Compound,Growth,Exponential和Logistic较高,其中Cubic最高,所以选择三次函数拟合。
观察得,图形更接近Cubic和Exponential两种曲线。
[0.366,1.072]
[-0.003,0]
2.
Logistic,Cublic,Compound,Growth,Exponential拟合度较高。
观察得,Cublic和Logistic曲线更接近观察值。
[-247.725,1414.627] [0.35,0.37]。
实验六用SPSS进行非线性回归分析
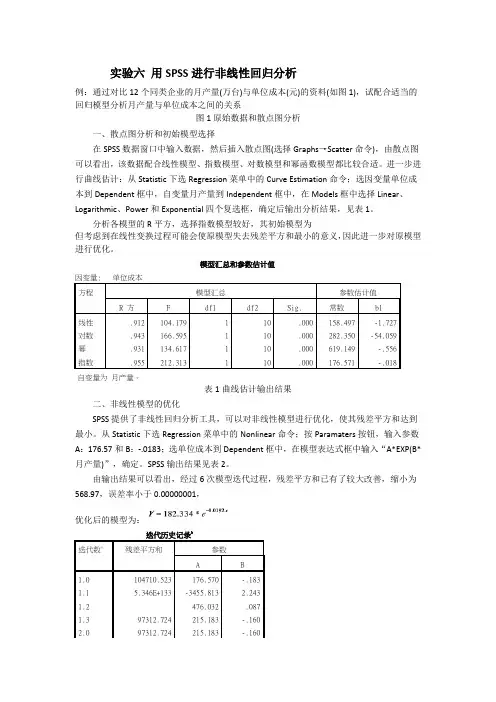
例:通过对比12个同类企业的月产量(万台)与单位成本(元)的资料(如图1),试配合适当的回归模型分析月产量与单位成本之间的关系
图1原始数据和散点图分析
一、散点图分析和初始模型选择
在SPSS数据窗口中输入数据,然后插入散点图(选择Graphs→Scatter命令),由散点图可以看出,该数据配合线性模型、指数模型、对数模型和幂函数模型都比较合适。
进一步进行曲线估计:从Statistic下选Regression菜单中的Curve Estimation命令;选因变量单位成本到Dependent框中,自变量月产量到Independent框中,在Models框中选择Linear、Logarithmic、Power和Exponential四个复选框,确定后输出分析结果,见表1。
分析各模型的R平方,选择指数模型较好,其初始模型为
但考虑到在线性变换过程可能会使原模型失去残差平方和最小的意义,因此进一步对原模型进行优化。
模型汇总和参数估计值
因变量: 单位成本
方程模型汇总参数估计值
R 方 F df1 df2 Sig. 常数b1
线性.912 104.179 1 10 .000 158.497 -1.727
对数.943 166.595 1 10 .000 282.350 -54.059
幂.931 134.617 1 10 .000 619.149 -.556
指数.955 212.313 1 10 .000 176.571 -.018
自变量为月产量。
表1曲线估计输出结果
二、非线性模型的优化
SPSS提供了非线性回归分析工具,可以对非线性模型进行优化,使其残差平方和达到最小。
从Statistic下选Regression菜单中的Nonlinear命令;按Paramaters按钮,输入参数A:176.57和B:-.0183;选单位成本到Dependent框中,在模型表达式框中输入“A*EXP(B*月产量)”,确定。
SPSS输出结果见表2。
由输出结果可以看出,经过6次模型迭代过程,残差平方和已有了较大改善,缩小为568.97,误差率小于0.00000001,
优化后的模型为:
迭代历史记录b
迭代数a残差平方和参数
A B
1.0 104710.523 176.570 -.183
1.1 5.346E+133 -3455.813
2.243
1.2 30684076640.87
3
476.032 .087
1.3 9731
2.724 215.183 -.160
2.0 97312.724 215.183 -.160
2.1 83887.036 268.159 -.133
3.0 83887.036 268.159 -.133
3.1 59358.745 340.412 -.102
4.0 59358.745 340.412 -.102
4.1 26232.008 38
5.967 -.065
5.0 26232.008 385.967 -.065
5.1 7977.231 261.978 -.038
6.0 797
7.231 261.978 -.038
6.1 1388.850 153.617 -.015
7.0 1388.850 153.617 -.015
7.1 581.073 180.889 -.019
8.0 581.073 180.889 -.019
8.1 568.969 182.341 -.019
9.0 568.969 182.341 -.019
9.1 568.969 182.334 -.019
10.0 568.969 182.334 -.019 10.1 568.969 182.334 -.019 导数是通过数字计算的。
a. 主迭代数在小数左侧显示,次迭代数在小数右侧显示。
b. 由于连续残差平方和之间的相对减少量最多为SSCON = 1.000E-008,因此在 22 模型评估和 10 导数评估之后,系统停止运行。
表2非线性回归的输出结果
传统手工运算求解,运算量与迭代次数成正比;而使用SPSS求解,只要输入了初始参数值和模型表达式,无论迭代多少次,都可快速得到最后结果,不仅减轻了计算强度,而且提高了数据准确度,相比Excel又有了极大的进步。