【思维导图】summary_of_knowledge_atlas-云计算平台知识图谱
- 格式:xmin
- 大小:1.19 MB
- 文档页数:52

AI使能的信道知识地图高效构建与应用目录1. 内容概括 (2)1.1 AI与信道知识地图简介 (2)1.2 高效构建与应用的必要性 (3)1.3 本文档结构概览 (4)2. 信道知识地图基础 (6)2.1 信道知识地图定义与构建原则 (7)2.2 数据的收集与整理方法 (9)2.3 分类与组织知识图谱的最佳实践 (10)3. AI技术在信道知识图谱中的角色 (11)3.1 机器学习算法的选择与训练 (12)3.2 自然语言处理在知识提取中的应用 (15)3.3 数据挖掘与深度学习算法 (16)4. 信道知识地图的构建流程 (18)4.1 需求分析 (19)4.2 数据准备 (20)4.3 模型选择与训练 (21)4.4 图谱结构设计 (23)4.5 图谱评估与质量控制 (24)4.6 部署与应用 (25)5. 信道知识地图的应用场景 (27)5.1 企业网络管理 (28)5.2 信息安全与威胁分析 (29)5.3 移动通信网络的优化 (31)5.4 智能交通系统 (33)5.5 其他潜在应用领域 (34)6. 案例研究 (35)6.1 信道知识地图在企业中的应用 (37)6.2 数据特性对信道知识图谱构建的影响 (39)6.3 信道知识图谱在学术研究中的用途 (40)6.4 信道知识图谱未来发展的展望 (41)7. 结论与建议 (42)7.1 总结已有研究成果与挑战 (43)7.2 对构建与应用信道知识图谱的最终建议 (44)7.3 未来的研究方向与发展趋势 (45)1. 内容概括本文档旨在介绍AI使能的信道知识地图高效构建与应用的相关知识和实践。
信道知识地图是一种将信道信息与网络设备、应用和服务相结合的可视化表示,有助于提高网络性能和安全性。
AI技术在信道知识地图的构建和应用过程中发挥着关键作用,包括数据挖掘、模式识别、智能优化等。
本文将详细介绍AI技术在信道知识地图构建中的应用场景、方法和技术,以及如何利用AI技术实现信道知识地图的高效管理和优化。




人工智能技术中的知识图谱构建近年来,随着人工智能技术的不断发展和应用,知识图谱的构建成为了人工智能技术领域的热门话题。
那么,知识图谱是什么?为什么要构建知识图谱?又该如何构建知识图谱呢?本文将从这些问题出发,来探讨人工智能技术中的知识图谱构建。
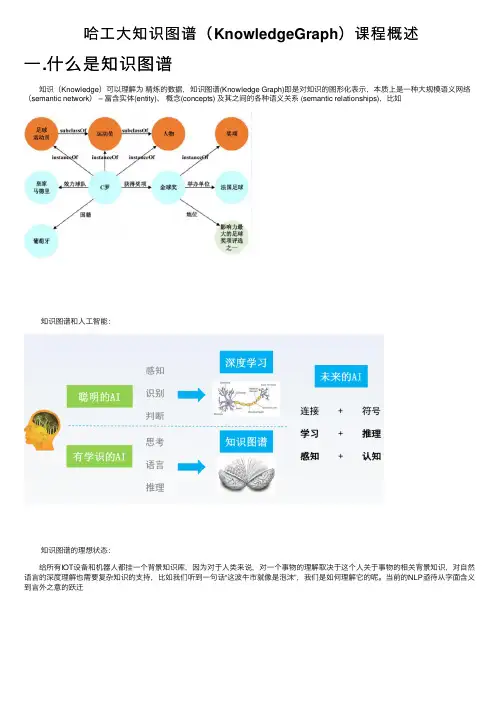
一、什么是知识图谱?知识图谱,英文名为Knowledge Graph,指的是一种语义模型,可以用来表示知识和实体之间的关系。
换言之,它是一种大规模、半结构化和语义化的数据集合,通常包含实体、属性、关系和上下位关系等多种关键信息。
而知识图谱的构建,旨在将人类知识和经验以可计算的方式进行表达,从而实现机器知识的自动化处理和应用。
二、为什么要构建知识图谱?构建知识图谱的目的在于,让机器具有人类的语义理解和推理能力,从而更好地服务于人类社会。
具体来说,有以下几个方面的优势:1.实现语义化查询知识图谱能够将数据与语义信息相结合,从而实现更精准、更快速的语义化查询。
2.提升自然语言处理能力知识图谱的存在,使得机器能够更好地理解人类使用的自然语言,从而提升自然语言处理能力。
3.推理性思维支持知识图谱能够提供上下位关系、属性关系等多种关键信息,从而支持机器进行推理性思维。
4.服务于人工智能应用知识图谱的构建,不仅能够提升人工智能技术的自动化处理能力,还能够服务于包括智能问答、搜索智能化等多种人工智能领域的应用。
三、如何构建知识图谱?知识图谱的构建,通常需要进行以下几个环节的工作:1.实体识别与属性提取首先,需要从大规模的数据中进行实体识别和属性提取,从而将实体与属性进行关联。
2.实体链接和关系抽取将实体与属性进行关联之后,需要进行实体链接和关系抽取,从而将实体之间的关系和属性之间的关系进行抽象出来。
3.知识表示和推理将实体之间的关系和属性之间的关系进行抽象后,需要进行知识的表示和推理。
知识表示通常采用图结构,可以使用RDF (Resource Description Framework)等多种方法对知识进行表达;而知识推理则需要依靠推理引擎和算法进行实现。

人工智能平台中的知识图谱构建与应用随着人工智能的迅速发展,知识图谱作为人工智能的重要组成部分,正在越来越多地应用于各个领域。
知识图谱是一种基于语义关系连接的知识表示方式,可以为机器理解和推理提供有力支持。
在人工智能平台中,构建和应用知识图谱可以帮助机器更好地理解和处理复杂的自然语言任务,提升人工智能系统的智能化水平。
知识图谱的构建是一个复杂而重要的过程。
它首先需要从大量的数据中提取出实体、属性和关系等知识要素,然后通过对这些知识要素的链接和组织,形成一个具有结构化的图谱模型。
在构建过程中,需要借助自然语言处理和机器学习等技术手段,通过分析和挖掘数据中的语义信息,识别实体和关系,构建起一个完整且准确的知识图谱。
知识图谱的应用范围广泛,可以支持人工智能平台在自然语言理解、智能推荐、智能搜索等方面的应用。
首先,通过知识图谱,机器可以更好地理解和处理自然语言任务。
例如,在问答系统中,通过构建知识图谱,机器可以具备对复杂问题的理解和推理能力,从而提供更准确、全面的答案。
其次,知识图谱可以为智能推荐系统提供更精准的推荐结果。
通过分析用户的兴趣和行为,结合知识图谱中的实体和关系信息,智能推荐系统可以为用户提供个性化的推荐服务。
此外,知识图谱还可以应用于智能搜索中,通过对搜索结果的语义理解和推理,提供更准确的搜索结果,满足用户的个性化需求。
然而,知识图谱的构建和应用面临着一些挑战和问题。
首先,构建知识图谱需要大量的数据和语义信息。
尽管现在数据量已经非常庞大,但是如何准确地从数据中提取出高质量的语义信息仍然是个难题。
其次,知识图谱的构建需要耗费大量的人力物力,特别是在标注实体和关系的过程中。
另外,知识图谱的应用需要高度的智能化水平,对算法和模型的要求也很高。
因此,如何解决这些问题,提升知识图谱的构建和应用效果,是人工智能平台所面临的重要挑战。
为了解决这些挑战,研究人员正在积极探索各种新的技术和算法。
例如,利用深度学习和语义表示学习等技术,可以从大规模数据中自动地学习实体和关系的表示,从而减少人工标注的工作量。

图表目录图1知识工程发展历程 (3)图2 Knowledge Graph知识图谱 (9)图3知识图谱细分领域学者选取流程图 (10)图4基于离散符号的知识表示与基于连续向量的知识表示 (11)图5知识表示与建模领域全球知名学者分布图 (13)图6知识表示与建模领域全球知名学者国家分布统计 (13)图7知识表示与建模领域中国知名学者分布图 (14)图8知识表示与建模领域各国知名学者迁徙图 (14)图9知识表示与建模领域全球知名学者h-index分布图 (15)图10知识获取领域全球知名学者分布图 (23)图11知识获取领域全球知名学者分布统计 (23)图12知识获取领域中国知名学者分布图 (23)图13知识获取领域各国知名学者迁徙图 (24)图14知识获取领域全球知名学者h-index分布图 (24)图15 语义集成的常见流程 (29)图16知识融合领域全球知名学者分布图 (31)图17知识融合领域全球知名学者分布统计 (31)图18知识融合领域中国知名学者分布图 (31)图19知识融合领域各国知名学者迁徙图 (32)图20知识融合领域全球知名学者h-index分布图 (32)图21知识查询与推理领域全球知名学者分布图 (39)图22知识查询与推理领域全球知名学者分布统计 (39)图23知识查询与推理领域中国知名学者分布图 (39)图24知识表示与推理领域各国知名学者迁徙图 (40)图25知识查询与推理领域全球知名学者h-index分布图 (40)图26知识应用领域全球知名学者分布图 (46)图27知识应用领域全球知名学者分布统计 (46)图28知识应用领域中国知名学者分布图 (47)图29知识应用领域各国知名学者迁徙图 (47)图30知识应用领域全球知名学者h-index分布图 (48)图31行业知识图谱应用 (68)图32电商图谱Schema (69)图33大英博物院语义搜索 (70)图34异常关联挖掘 (70)图35最终控制人分析 (71)图36企业社交图谱 (71)图37智能问答 (72)图38生物医疗 (72)图39知识图谱领域近期热度 (75)图40知识图谱领域全局热度 (75)表1知识图谱领域顶级学术会议列表 (10)表2 知识图谱引用量前十论文 (56)表3常识知识库型指示图 (67)摘要知识图谱(Knowledge Graph)是人工智能重要分支知识工程在大数据环境中的成功应用,知识图谱与大数据和深度学习一起,成为推动互联网和人工智能发展的核心驱动力之一。

1.通俗易懂解释知识图谱(KnowledgeGraph)1. 前⾔从⼀开始的Google搜索,到现在的聊天机器⼈、⼤数据风控、证券投资、智能医疗、⾃适应教育、推荐系统,⽆⼀不跟知识图谱相关。
它在技术领域的热度也在逐年上升。
本⽂以通俗易懂的⽅式来讲解知识图谱相关的知识、尤其对从零开始搭建知识图谱过程当中需要经历的步骤以及每个阶段需要考虑的问题都给予了⽐较详细的解释。
知识图谱( Knowledge Graph)的概念由⾕歌2012年正式提出,旨在实现更智能的搜索引擎,并且于2013年以后开始在学术界和业界普及。
⽬前,随着智能信息服务应⽤的不断发展,知识图谱已被⼴泛应⽤于智能搜索、智能问答、个性化推荐、情报分析、反欺诈等领域。
另外,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并且形成⼀套Web语义知识库。
知识图谱以其强⼤的语义处理能⼒与开放互联能⼒,可为万维⽹上的知识互联奠定扎实的基础,使Web 3.0提出的“知识之⽹”愿景成为了可能。
2. 知识图谱定义知识图谱:是结构化的语义知识库,⽤于迅速描述物理世界中的概念及其相互关系。
知识图谱通过对错综复杂的⽂档的数据进⾏有效的加⼯、处理、整合,转化为简单、清晰的“实体,关系,实体”的三元组,最后聚合⼤量知识,从⽽实现知识的快速响应和推理。
知识图谱有⾃顶向下和⾃底向上两种构建⽅式。
所谓⾃顶向下构建是借助百科类⽹站等结构化数据源,从⾼质量数据中提取本体和模式信息,加⼊到知识库中;所谓⾃底向上构建,则是借助⼀定的技术⼿段,从公开采集的数据中提取出资源模式,选择其中置信度较⾼的新模式,经⼈⼯审核之后,加⼊到知识库中。
看⼀张简单的知识图谱:如图所⽰,你可以看到,如果两个节点之间存在关系,他们就会被⼀条⽆向边连接在⼀起,那么这个节点,我们就称为实体(Entity),它们之间的这条边,我们就称为关系(Relationship)。

思维导图的起源和介绍说明科学研究已经充分证明:人类的思维特征是呈放射性的,进入大脑的每一条信息、每一种感觉、记忆或思想(包括每一个词汇、数字、代码、食物、香味、线条、色彩、图像、节拍、音符和纹路),都可作为一个思维分支表现出来,它呈现出来的就是放射性立体结构。
英国教育学家、世界记忆之父托尼巴赞(Tony Buzan)在大学时代,在遇到信息吸收、整理及记忆的等困难,前往图书馆寻求协助,却惊讶地发现没有教导如何正确有效使用大脑的相关书籍资料,于是开始思索和寻找新的思想或方法来解决。
托尼巴赞开始研究心理学、神经生理学等科学,渐渐地发现人类头脑的每一个脑细胞及大脑的各种技巧如果能被和谐而巧妙地运用,将比彼此分开工作产生更大的效率。
以放射性思考为基础的收放自如方式,比如:鱼网、河流、树、树叶、人和动物的神经系统、管理的组织结构等,逐渐地,整个架构慢慢形成,Tony Buzan也开始训练一群被称为学习障碍者、阅读能力丧失的族群,这些被称为失败者或曾被放弃的学生,很快的变成好学生,其中更有一部份成为同年纪中的佼佼者。
1971年托尼巴赞开始将他的研究成果集结成书,慢慢形成了发射性思考(Radiant Thinking)和思维导图法(Mind Ma ing)的概念。
思维导图是大脑放射性思维的外部表现。
依据大脑思维放射性特点,后来成为英国大脑基金会主席、著名教育家的托尼巴赞(Tony Buzan)在思维研究领域取得了令世人瞩目的成就。
思维导图利用色彩、图画、代码和多维度等图文并茂的形式来增强记忆效果,使人们关注的焦点清晰地集中在中央图形上。
思维导图允许学习者产生无限制的联想,这使思维过程更具创造性。
托尼巴赞1942年出生于英国伦敦,毕业于英属哥伦比亚大学,先后获得心理学、英语语言学、数学和普通科学等多种学位。
他所撰写的二十多种大脑方面的图书已被翻译成几十种语言,在全球五十多个国家出版,并成为世界顶级公司进行高级人员培训的必选教材。
自顶向下的知识图谱构建流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor.I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!自顶向下的知识图谱构建流程详解在信息爆炸的时代,知识图谱作为一种有效的数据组织和管理工具,已被广泛应用于搜索引擎、智能推荐系统等领域。
系统分析师考试复习资料南昌大学计算中心武夷河E_Mail:wuyihe5304@说明:本文所有资料均收集于网络,由本人整理而成,在此对原作者表示衷心的感谢!网友们可自由传播此资料,但不得用于商业目的。
1 开发技术:语言与平台 (6)JavaBean 组件模型特点 (6)Enterprise JavaBean (EJB)组件模型特点: (6)JSP 胜过servlet 的关键的优点: (6)J2EE 的重要组成部分: (6)RMI 和RPC 的区别: (7)XML 和HTML 的主要区别: (7)XML 技术和JSP技术集成的方案: (7)XML 与JSP 技术联合的优越性: (7)XML 的特点: (7)SAX (Simple API for XML) 和DOM (Document Object Model) (7)什么DOM? (7)什么SAX? (8)什么类型的SAX 事件被SAX解析器抛出了哪? (9)什么时候使用DOM? (9)什么时候使用SAX? (9)HTML 的缺点: (10)经验结论 (10)用ASP、JSP、PHP 开发的缺陷: (10)XML 的优缺点: (10)XML 主要有三个要素:模式、XSL、XLL。
(10)2 Web Service 相关技术 (10)Web Service (10)创建简单的Web Service 的方法: (11)Web Service 主要目标是跨平台和可互操作性,其特点: (11)Web Service 应该使用的情况: (11)UDDI (统一描述、发现和集成Universal Description,Discovery,andIntegration) (11)SOAP (12)Web Service 技术(SOAP、UDDI、WSDL、EBXML) (12)3 软件工程、软件架构及软件体系结构 (12)3.1 面向对象技术 (12)一组概念 (12)OOA 的主要优点: (12)OOA 过程包括以下主要活动: (12)3.2 UML: (12)UML 包含了3 个方面的内容 (13)UML 提供了3类基本的标准模型建筑块 (13)UML 规定四种事物表示法 (13)UML 提供的建筑块之间的基本联系有四种 (13)UML 图形提供了9 种图形 (13)UML 规定了语言的四种公共机制 (13)UML 的特点: (13)USE CASE: (13)对象类图: (13)交互图: (14)状态图: (14)组件图和配置图: (15)UML 开发工具:ilogix Rhapsody (15)Rational Rose家族成员有: (15)3.3 OMT 方法: (15)OMT 方法有三种模型:对象模型、动态模型、功能模型。
大数据分析师的机器学习库与框架随着大数据时代的到来,机器学习已经成为了解析和应用数据的重要工具。
作为大数据分析师,熟练掌握机器学习的库和框架是必备的技能之一。
本文将介绍几个常用的机器学习库和框架,以帮助大数据分析师更高效地开展工作。
一、Scikit-learnScikit-learn是Python语言的一个开源机器学习库,它为人工智能应用提供了各种机器学习算法和工具。
Scikit-learn提供了用于回归、分类、聚类等常见任务的API,方便用户快速上手。
此外,该库还提供了数据预处理、特征提取等功能,使得数据处理更加方便灵活。
Scikit-learn是学习机器学习的入门利器,也是大数据分析师不可或缺的工具之一。
二、TensorFlowTensorFlow是由Google开发的一款深度学习框架,它强大的计算能力和灵活的架构使其成为了许多大规模机器学习项目的首选。
TensorFlow支持分布式计算和GPU加速,可以处理大规模的数据集和复杂的神经网络模型。
此外,TensorFlow还提供了丰富的工具和API,使得模型训练和调试更加方便高效。
作为一名大数据分析师,掌握TensorFlow将使你在深度学习领域更具竞争力。
三、PyTorchPyTorch是另一个常用的深度学习框架,它由Facebook开发并广泛应用于学术界和工业界。
与TensorFlow相比,PyTorch在灵活性和易用性方面更具优势。
PyTorch使用动态计算图的方式,可以更方便地进行模型的定义和调试。
此外,PyTorch还提供了丰富的预训练模型和工具库,使得开发者可以更快速地构建和训练自己的模型。
如果你追求灵活性和创新性,那么PyTorch是个不错的选择。
四、Spark MLlibSpark MLlib是Apache Spark的一个机器学习库,它为大规模数据处理和分析提供了一套丰富的机器学习算法和工具。
Spark MLlib基于RDD(弹性分布式数据集)和DataFrame(分布式数据集)提供了多种机器学习功能,包括特征提取、模型评估、模型选择等。
如何利用深度学习进行知识图谱构建知识图谱是一种表示和组织知识的形式化方法,它能够整合和展示领域内的知识,并通过关系连接不同的实体。
深度学习技术的快速发展为知识图谱的构建提供了新的工具和方法。
本文将介绍如何利用深度学习进行知识图谱构建。
首先,进行知识图谱构建前,需要确定知识的来源和范围。
可以从结构化数据、半结构化数据和非结构化数据中获取知识。
结构化数据包括数据库中的表格、关系型数据等;半结构化数据包括HTML、XML等格式;非结构化数据包括文本、图像、音频等。
根据不同的需求,可以选择合适的数据源,以及对应的深度学习模型。
其次,深度学习在知识图谱构建中的具体应用包括实体识别、关系抽取和图谱补全。
实体识别是指从文本中识别出具体的实体,例如人名、地名等。
关系抽取是指从文本中抽取出不同实体之间的关系。
图谱补全是指通过学习已有的知识图谱,预测出缺失的实体、关系或属性。
在实体识别方面,可以使用循环神经网络(RNN)或者卷积神经网络(CNN)来识别实体。
这些网络模型能够学习上下文信息,以及实体之间的语义关联。
此外,还可以采用预训练的词向量,使模型具备更好的语义理解能力。
在关系抽取方面,可以使用递归神经网络(Recursive Neural Network,简称RNN)或者卷积神经网络(CNN)来进行关系的分类。
这些模型能够学习实体之间的语义关系,并进行关系的预测。
此外,可以使用知识图谱中的关系进行监督学习,提高关系抽取的准确率。
在图谱补全方面,可以使用图卷积网络(Graph Convolutional Network,简称GCN)来进行实体和关系的预测。
GCN能够学习图谱中实体和关系之间的连接关系,从而进行实体和关系的补全。
此外,还可以使用知识图谱的图结构进行迭代式的推理,通过多轮迭代来优化图谱的完善程度。
最后,为了提高深度学习在知识图谱构建中的效果,需要准备大量的数据,并进行合理的数据预处理。
数据预处理包括数据清洗、实体标注、关系标注等。