程序代码相似度度量算法研究_邓爱萍
- 格式:pdf
- 大小:209.10 KB
- 文档页数:4



程序代码相似度度量研究的开题报告一、研究背景和意义程序代码相似度度量是软件工程领域的一项重要问题,它可以用于代码重构、复杂度分析、代码复用等方面。
在软件开发过程中,代码相似度度量可以帮助程序员找到相似点和差异点,有助于更好地理解程序的结构和设计,还可以帮助学生和开发人员提高代码质量,从而提高软件开发效率和质量。
目前,市面上已经有很多代码相似度度量工具可供选择,但是这些工具大多基于字符、标记或者语法树的比较方法,往往不能很好地解决代码的语义相似度问题,而且时间复杂度高,处理大规模代码数据困难。
因此,研究如何快速、准确地衡量程序代码的语义相似度,具有很高的研究和应用价值。
二、研究目标和内容本课题的研究目标是:结合自然语言处理、机器学习等技术,设计一种能够准确、高效地度量程序代码相似度的方法,以提高程序开发效率和质量。
研究内容包括:1. 收集和预处理程序代码。
这一步包括获取开源代码、规范化和清理代码,以及将代码转换为可处理的格式。
2. 提取代码特征。
针对代码特有的语法结构和语义规则,设计合适的代码特征提取方法,将程序代码转换为特征向量。
3. 利用机器学习算法训练分类器。
根据分类问题的特点,选择合适的分类器进行训练和优化。
4. 应用训练好的分类器度量程序代码相似度。
对于给定的一对程序代码,用训练好的分类器计算它们之间的相似度得分。
5. 实验分析。
对比其他常见的代码相似度度量方法,分析新方法的优缺点,并针对不同应用场景进行实验测试,评估度量方法的准确性、效率和可拓展性。
三、研究方案和方法本课题借鉴了相关领域的研究方法和实践经验,主要采用以下方法和技术:1. 自然语言处理技术。
程序代码和自然语言都有类似的结构和规则,因此可以应用自然语言处理技术提取程序代码的语义特征。
例如通过词干提取、词向量化等方法将代码转换为向量表示,或通过句法分析、语义分析等方法提取更丰富的语义信息。
2. 机器学习算法。
基于特征向量的分类算法是程序代码相似度度量的常用方法,本课题将探究构建合适的特征向量和选择最优的分类器,例如支持向量机、随机森林、神经网络等。


网络通讯及安全本栏目责任编辑:代影程序代码相似度检测技术的研究与实现卫军超,耿楠*(西北农林科技大学信息工程学院,陕西杨凌712100)摘要:针对传统相似度算法应用在程序设计课程作业检测中精度较低这一问题,通过研究最长公共子序列等算法,发现其优缺点,在分析的基础上,结合结构度量技术和属性技术两种技术,提出一种性能较好的程序相似度计算方法。
方法首先对源程序进行初步处理,将程序中的注释语句和空格删除,再次确定常用元素及常用结构,然后利用Lex 统计、抽取程序元素;利用开源代码ucc 生成语法树,之后抽取相应的语法结构;最后生成特征向量,并计算代码相似度。
实验结果表明该方法比最长公共子序列算法精度提高了10.6%。
关键词:属性计数法;结构度量技术;相似度度量中图分类号:TP311文献标志码:A 文章编号:1009-3044(2017)05-0039-02Research on and Application of Techniques of Test for Similarity of Program Codes WEI Jun-chao,GENG Nan *(College of Information Engineering Northwest A&F University,Yangling 712100,China)Abstract:To solve the problem of the low precision of testing for similarity of program codes in traditional ways,this thesis pro-poses an improved technique to make such a test on the combination of technology of attribute counting and that of structure cal-culation through studying and comparing several different methods of calculating the Longest Common Subsequence.Firstly,source program is processed primarily,annotation statements and spaces are deleted,and common elements and structures get confirmation;next,statistics are made by means of Lex,program elements are extracted,and abstract syntax trees get to be gen-erated using UCC;then,grammar structures are extracted;lastly,eigenvector is produced and the similarity can get calculated.The experimental result shows that the new method is 10.6percent more precise than those of calculating the Longest Common Subsequence.Key words:attribute counting;structure measurement;similarity measurement在程序设计课程教学中,尤其是在上机编程训练过程中,需要学生通过独立地编程练习来提高程序设计能力,然而实际的情况是部分学生存在不同程度地抄袭他人的作业。
F福建电脑U J I A N C O M P U T E R福建电脑2018年第6期0 引言C 语言诞生于上世纪70年代,是嵌入式领域的主导语言,和汇编语言一起使用,功能强大,大型游戏软件也多是用C 语言开发,使用广泛。
在课程安排上,C 语言是作为入门的编程语言,辅助操作系统及其它相关课程的学习。
然而随着信息技术的发展,从互联网上获取程序代码资源越来越方便,有些同学直接在互联网上查找相关C 程序代码或者抄袭其他同学的程序代码,所以C 程序代码的相似度检测在编程语言教学中具有重大意义。
因为不同的编程语言的语法规则有许多差异,所以对于不同的编程语言的程序代码的相似度很难用一种统一的标准或方法来检测,本文提出了一种适用于C 程序代码的相似度检测方法。
1程序代码相似度检测的相关技术目前,国内外对于程序代码的相似度检测技术主要有结构度量和属性计数方法[1]。
结构度量技术主要是通过对程序代码的结构信息以及执行流程进行分析来检测两段程序代码的相似度,常选用的检测结构主要有分支结构、循环结构、条件结构和函数个数。
属性计数技术主要是通过处理程序代码的一些属性值,不考虑程序代码的语法结构,实现较为简单,常选用的属性主要有自定义变量个数、数组个数、运算符个数、关键字个数。
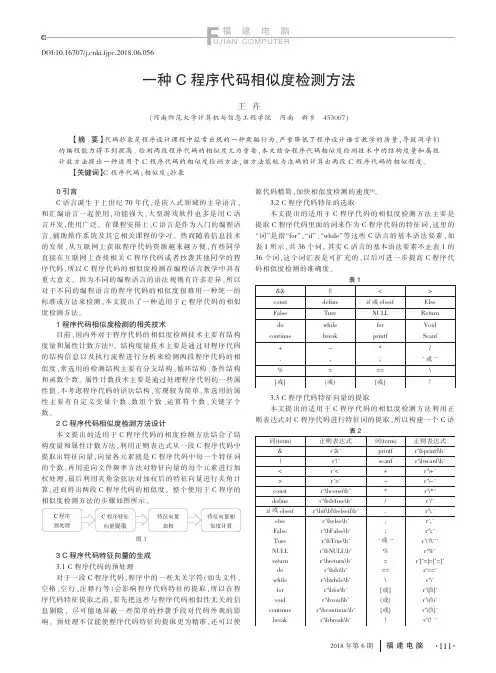
2 C 程序代码相似度检测方法设计本文提出的适用于C 程序代码的相度检测方法结合了结构度量和属性计数方法,利用正则表达式从一段C 程序代码中提取出特征向量,向量各元素就是C 程序代码中每一个特征词的个数,再用逆向文件频率方法对特征向量的每个元素进行加权处理,最后利用夹角余弦法对加权后的特征向量进行夹角计算,进而得出两段C 程序代码的相似度。
整个使用于C 程序的相似度检测方法的步骤如图所示。
3 C 程序代码特征向量的生成3.1C 程序代码的预处理对于一段C 程序代码,程序中的一些无关字符(如头文件、空格、空行、注释行等)会影响程序代码特征的提取,所以在程序代码特征提取之前,要先把这些与程序代码相似性无关的信息剔除,尽可能地屏蔽一些简单的抄袭手段对代码外观的影响。


程序代码相似度检测技术的研究与实现作者:卫军超耿楠来源:《电脑知识与技术》2017年第05期摘要:针对传统相似度算法应用在程序设计课程作业检测中精度较低这一问题,通过研究最长公共子序列等算法,发现其优缺点,在分析的基础上,结合结构度量技术和属性技术两种技术,提出一种性能较好的程序相似度计算方法。
方法首先对源程序进行初步处理,将程序中的注释语句和空格删除,再次确定常用元素及常用结构,然后利用Lex统计、抽取程序元素;利用开源代码ucc生成语法树,之后抽取相应的语法结构;最后生成特征向量,并计算代码相似度。
实验结果表明该方法比最长公共子序列算法精度提高了10.6%。
关键词:属性计数法;结构度量技术;相似度度量中图分类号: TP311 文献标志码: A 文章编号:1009-3044(2017)05-0039-02Abstract: To solve the problem of the low precision of testing for similarity of program codes in traditional ways, this thesis proposes an improved technique to make such a test on the combination of technology of attribute counting and that of structure calculation through studying and comparing several different methods of calculating the Longest Common Subsequence. Firstly,source program is processed primarily, annotation statements and spaces are deleted, and common elements and structures get confirmation; next, statistics are made by means of Lex, program elements are extracted, and abstract syntax trees get to be generated using UCC; then, grammar structures are extracted; lastly, eigenvector is produced and the similarity can get calculated. The experimental result shows that the new method is 10.6 percent more precise than those of calculating the Longest Common Subsequence.Key words: attribute counting; structure measurement; similarity measurement在程序设计课程教学中,尤其是在上机编程训练过程中,需要学生通过独立地编程练习来提高程序设计能力,然而实际的情况是部分学生存在不同程度地抄袭他人的作业。

程序代码相似度检测方法的设计与实现计算机程序代码相似度检测是指利用计算机技术,对两段程序代码进行比较,以从中提取其中的相似性,从而对源程序时间消耗、运行结果做统计把握,用来编写更加高效的程序,有助于加快程序的开发周期,也可以检测两程序是否怀疑“抄袭”或者根据其标准检测出程序代码质量的好坏。
本文讨论的是程序代码相似度检测方法的设计与实现。
程序代码相似度检测的核心思想时对比比较,既然需要比较,那么就要从把程序代码变形为其他形式开始分析。
一般程序语言都具有反汇编的功能,可以将源代码转换为汇编代码。
然后在汇编代码的基础上,再将其转化为由标记组成的字符串。
经过这个变形,我们就可以通过对比比较,寻求两个程序代码之间的相似性,比如比较共同出现的标记,出现次数以及位置等等。
在介绍如何实现程序代码相似度检测之前,先介绍一下两个程序代码之间相似度检测时,必须考虑的要素:(1)选择一种合适的比较方式,有时采用字符串比较,有时采用词语比较,有时采用句子比较。
(2)考虑判断标准,一般有按照比较粒度的大小、相似度的分数(一般使用0-1浮点数来标识),评分越高,说明相似度越大。
(3)考虑比较程序的耗时,一般性的比较会消耗的时间较长。
根据上面的要素,我们可以将程序代码相似度检测实现的思路总结如下:(1)先将源代码转换为机器语句,从而形成一段机器语句包括标记。
(2)在机器语句上,采用一定的比较方式,如字符串比较,词汇比较等,进行比较,并根据不同比较粒度和标准,得出两个比较程序的相似度分数,该分数可以参考拟定出程序的质量,或者用于进行嫌疑程序的抄袭检测。
(3)记录比较过程所耗费的时间,以及相似度检测得分,并将比较结果反馈给用户。
以上是程序代码相似度检测方法设计及实现方面的一些讨论。
通过从获取源程序,到变形比较,再到考虑检测用时,不断根据细致设计,可以有效的检测出两程序之间的相似度,同时也可以作为代码质量的参考依据,从而减少源程序的时间消耗,同时也可以加快程序的开发周期,有助于提升软件的品质。


程序代码相似度度量算法研究
邓爱萍
【期刊名称】《计算机工程与设计》
【年(卷),期】2008(29)17
【摘要】代码剽窃是程序设计课程中经常出现的一种作弊行为,检测剽窃的源代码,验证学生程序作业的原创性在教学中很重要.程序代码的相似度度量是剽窃检测的关键技术.通过对现有程序代码相似度度量技术进行研究后,基于Karp-Rabin和最长公共子串算法思想,提出了一种改进的源代码相似度度量算法,即串的散列值匹配算法.
【总页数】2页(P4636-封3)
【作者】邓爱萍
【作者单位】湖南人文科技学院计算机科学技术系,湖南,娄底,417000
【正文语种】中文
【中图分类】TP311.52
【相关文献】
1.基于本体粗糙集的程序代码相似度度量方法 [J], 张鹏;王国胤;陶春梅;罗海
2.程序代码相似度度量中词法分析器的设计实现 [J], 于海英
3.程序代码相似度度量的研究与实现 [J], 于海英
4.程序代码相似度自动度量技术研究综述 [J], 程金宏;刘东升
5.最长公共子序列算法在程序代码相似度度量中的应用 [J], 于海英;赵俊岚
因版权原因,仅展示原文概要,查看原文内容请购买。
程序代码相似性检测技术在教学中的应用摘要:本文介绍的程序代码相似性检测技术可以帮助教师从学生作业集中快速找出彼此是否存在抄袭嫌疑,并能够对作业对的相似部分做出标记,给教师提供参考,以减轻教师人工判别的工作负担,从而提高工作效率。
关键词:程序代码相似性检测技术;程序设计类课程;代码相似性检测系统;程序作业抄袭程序设计类课程注重学生实际编程能力的培养。
因此,在教学过程中更加强调实践,而不单单是程序设计语言本身。
然而,上机作业中学生间的抄袭行为严重影响了教学效果。
当一个程序被几个或者十几个同学抄袭,其中用点心的同学还会做一些修改变量名、增加注释等修改,很多学生直接拷贝交给教师。
当学生数较多时,要发现抄袭行为,进而找出谁是原创,谁是抄袭,都比较困难,而且特别耗时费力。
程序代码相似性检测技术能够对学生提交的作业进行检测,找出相似性较大的程序对,帮助教师在大量学生作业中找出存在抄袭嫌疑的作业对象,从而可以减轻教师的工作负担、提高工作效率。
1程序代码相似性检测技术概述Parker和Hamblen于1989年将程序代码的抄袭定义为:一个程序通过将另一个程序的少量常规修改而来。
比较常规的修改主要包括下以几个方面:●逐字逐句的拷贝●更改注释●增加空行或者改变书写格式●标识符重命名●代码段重新排序●改变表达式中的操作数或者操作符的顺序●改变数据类型●增加无关语句或者变量●用等价的结构进行替代检测抄袭就是检测一个程序是否通过对另一个程序的上述修改而来的。
程序代码相似性检测技术能对程序集合中的每两个程序进行比对,找出一个程序对另一个程序经过上述修改而来的相似代码部分,得到描述程序相似程度的量化值(称作相似度similarity),并且能够对两个程序的相似代码部分进行标注,帮助用户找出并判定抄袭的作业对象。
国外对程序代码相似性检测技术的研究比较早,检测方法主要有属性计数(Attribute counting)技术和结构度量(Structure metric)技术。
程序的源代码的相似性判别程序源代码的相似性一、课题内容和要求对于两个C++语言的源程序代码,用哈希表的方法分别统计两个程序中使用C++语言关键字的情况,并最终按定量的计算结果,得出两份程序的相似性。
基本要求:建立C++语言关键字的哈希表,统计在每个源程序中C++关键字出现的频度, 得到两个向量X1和X2,通过计算向量X1和X2的相对距离来判断两个源程序的相似性。
例如:关键字Void Int For Char if else while do break class程序1关键字频度 4 3 0 4 3 0 7 0 0 2程序2关键字频度 4 2 0 5 4 0 5 2 0 1X1=[4,3,0,4,3,0,7,0,0,2]X2=[4,2,0,5,4,0,5,2,0,1]设s是向量X1和X2的相对距离,s=sqrt( ∑(x i1-x i2) 2 ),当X1=X2时,s=0, 反映出可能是同一个程序;s值越大,则两个程序的差别可能也越大。
测试数据: 选择若干组编译和运行都无误的C++程序,程序之间有相近的和差别大的,用上述方法求s, 对比两个程序的相似性。
二、课题需求分析1.需求分析软件的基本功能、输入/输出形式、测试数据要求。
该软件能够比较两个源程序代码的相似度。
需要用户输入两个源代码的文件名,系统会自动计算出两个程序中关键字的个数,并进行对比,而且计算出两个程序的相似度并输出,用户可以根据,系统输出相似度的大小,来估计两个程序相似的概率。
2.概要设计抽象数据类型、主程序流程及模块调用关系。
该程序用到的数据结构主要是哈希表,其次是顺序表:哈希表的功能是统计文件里出现的关键字的个数,通过++模式,该程序主要统计了C++的十个常用关键字break,char,class,do,else,for,if,int,void,while出现的频度,在Hash类里定义了一个哈希表,哈希表的大小为十个整形数据,哈希表里的十个数据是与已知的十个关键字一一对应的,顺序表用于存放处理后的数据。
代码相似性检测技术:研究综述
熊浩;晏海华;郭涛;黄永刚;郝永乐;李舟军
【期刊名称】《计算机科学》
【年(卷),期】2010(037)008
【摘要】程序代码的相似性检测是使用一定的检测手段度量程序代码间的相似程度,其对于提升高等教育中计算机课程教学效果和保护软件知识产权都有着重要的意义.介绍了代码相似性检测技术的研究意义和发展历程,阐述了本领域研究过程中的概念模型,深入分析了已有的几类代码相似性检测技术,总结了这几类技术各自的特点,同时探讨了一些相关研究,最后归纳了目前研究中的问题并展望了本领域研究的发展趋势.
【总页数】7页(P9-14,76)
【作者】熊浩;晏海华;郭涛;黄永刚;郝永乐;李舟军
【作者单位】北京航空航天大学计算机学院,北京100191;中国信息安全评测中心,北京100083;北京航空航天大学计算机学院,北京100191;中国信息安全评测中心,北京100083;中国信息安全评测中心,北京100083;中国信息安全评测中心,北京100083;北京航空航天大学计算机学院,北京100191
【正文语种】中文
【中图分类】TP311
【相关文献】
1.程序代码相似性检测技术在教学中的应用 [J], 王春晖;程金宏;孟繁军;刘东升
2.程序代码相似性检测技术在教学中的应用 [J], 王春晖;程金宏;孟繁军;刘东升
3.基于多特征值的源代码相似性检测技术 [J], 展佳俊;赵逢禹;艾均
4.二进制代码相似性检测技术综述 [J], 方磊;武泽慧;魏强
5.恶意代码检测技术研究综述 [J], 杨坤
因版权原因,仅展示原文概要,查看原文内容请购买。