sas聚类分析(SAS)分解
- 格式:ppt
- 大小:691.50 KB
- 文档页数:15

35. 聚类分析(一)概述聚类分析,相当于“物以类聚” ,用于对事物的类别面貌尚不清楚,甚至在事前连总共有几类都不能确定的情况下对数据进行分类。
而判别分析,必须事先知道各种判别的类型和数目,并且要有一批来自各判别类型的样本,才能建立判别函数来对未知属性的样本进行判别和归类。
聚类分析是把分类对象按一定规则分成组或类,这些组或类不是事先给定的而是根据数据特征而定的。
在同类的对象在某种意义上倾向于彼此相似,而在不同类里的这些对象倾向于不相似。
根据这种相似性的不同定义,聚类分析也有不同的方法。
聚类分析分为:对样品的聚类,对变量的聚类。
样品聚类:其统计指标是类与类之间距离,把每一个样品看成空间中的一个点,用某种原则规定类与类之间的距离,将距离近的点聚合成一类,距离远的点聚合成另一类。
变量聚类:其统计指标是相似系数,将比较相似的变量归为一类,而把不怎么相似的变量归为另一类,用它可以把变量的亲疏关系直观地表示出来。
(二)原理一、距离和相似系数1. 距离设有n组样品,每组样品有p 个变量的数据如下:例如,X i 到X j 的闵科夫斯基距离定义为:1p q qd ij |x ik x jk | , 1 i,j nk1q=2 时为欧几里得距离;还有马氏距离:T -1d ij = (X i -X j ) T S-1 (X i -X j)其中,X i =( x i1 , ⋯, x ip ) ,S-1为n 个样品的p×p 的协方差矩阵的逆矩阵。
注:马氏距离考虑了观测变量之间的相关性和变异性 (不再受各指标量纲的影响)距离选择的基本原则:1)要考虑所选择的距离公式在实际应用中有明确的意义。
如欧氏距离就有非常明确的空间距离概念。
马氏距离有消除量纲影响的作用。
(2)要综合考虑对样本观测数据的预处理和将要采用的聚类分析方法。
如在进行聚类分析之前已经对变量作了标准化处理,则通常就可采用欧氏距离。
(3)应根据研究对象的特点不同做出具体分折。

SAS 聚类分析(描述算法)系统聚类法系统聚类法(Hierarchical clustering method )是目前使用最多的一种方法。
其基本思想是首先将n 个样品看成n 类(即一类包括一个样品),然后规定样品之间的距离和类与类之间的距离。
将距离最近的两类合并为一个新类,在计算新类和其他类之间的距离,再从中找出最近的两类合并,继续下去,最后所有的样品全在一类。
将上述并类过程画成聚类图,便可以决定分多少类,每类各有什么样品。
系统聚类法的步骤为:①首先各样品自成一类,这样对n 组样品就相当于有n 类;②计算各类间的距离,将其中最近的两类进行合并;③计算新类与其余各类的距离,再将距离最近的两类合并;④重复上述的步骤,直到所有的样品都聚为一类时为止。
下面我们以最短距离法为例来说明系统聚类法的过程。
最短距离法的聚类步骤如下:① 规定样品之间的距离,计算样品的两两距离,距离矩阵记为()0S ,开始视每个样品分别为一类,这时显然应有pq d q p D =),(;② 选择距离矩阵()0S 中的最小元素,不失一般性,记其为),(q p D ,则将p G 与q G 合并为一新类,记为m G ,有q p m G G G ⋃=;③ 计算新类m G 与其他各类的距离,得到新的距离矩阵记为()1S ;④ 对()1S 重复开始进行第②步,…,直到所有样本成为一类为止。
值得注意的是在整个聚类的过程中,如果在某一步的距离矩阵中最小元素不止一个时,则可以将其同时合并。
● 系统聚类法是最常用的一种聚类方法,常用的系统聚类方法有最短距离法、最长距离法、中间距离法、类平均法、重心法、Ward 最小方差法、密度估计法、两阶段密度估计法、最大似然估计法、相似分析法和可变类平均法。
● 大多数的研究表明:最好综合特性的聚类方法为类平均法或Ward 最小方差法,而最差的则为最短距离法。
Ward 最小方差法倾向于寻找观察数相同的类。
类平均法偏向寻找等方差的类。

第三十九课 聚类分析聚类分析是多元统计分析中研究“物以类聚”的一种方法,用于对事物的类别面貌尚不清楚,甚至在事前连总共有几类都不能确定的情况下进行分类的场合。
聚类分析主要目的是研究事物的分类,而不同于判别分析。
在判别分析中必须事先知道各种判别的类型和数目,并且要有一批来自各判别类型的样本,才能建立判别函数来对未知属性的样本进行判别和归类。
若对一批样品划分的类型和分类的数目事先并不知道,这时对数据的分类就需借助聚类分析方法来解决。
聚类分析把分类对象按一定规则分成组或类,这些组或类不是事先给定的而是根据数据特征而定的。
在一个给定的类里的这些对象在某种意义上倾向于彼此相似,而在不同类里的这些对象倾向于不相似。
关于聚类分析的任何通则必定是含糊的、不明确的,因为在众多的各种不同领域里聚类方法已经发展了,类和对象间的相似性具有不同定义。
各种聚类分析方法通过用于聚类分析的各种各样的领域反映出来。
因此尽管聚类方法有很多种,但不管哪一种都不能说得到的分类是准确的。
下面我们介绍聚类分析中常用的一些方法。
一、 距离和相似系数什么是“类”呢?粗略地说,相似物体的集合称作类;聚类分析的目的就是把相似的东西归类。
其次“相似”是什么含意?怎样度量“相似”?我们必须给出度量“相似”的统计指标。
聚类根据实际的需要有两个方向,一是对样品的聚类,一是对变量的聚类。
相应的聚类统计量有两类:一种统计指标是类与类之间距离,它是把每一个样品看成高维空间中的一个点,类与类之间用某种原则规定它们的距离,将距离近的点聚合成一类,距离远的点聚合成另一类。
距离一般用于对样品分类。
另一种是相似系数,根据这个统计指标将比较相似的变量归为一类,而把不怎么相似的变量归为另一类,用它可以把变量的亲疏关系直观地表示出来。
1. 距离设有n 组样品,每组样品有p 个变量,n 组样品数据如表39.1所示:表39.1 p 个变量的n 组样品数据样品号 变量1 2 … n 1X 2Xp X11x 21x … 1n x 12x 22x … 2n xp x 1 p x 2 … np x第i 个与第j 个样品之间距离用ij d 表示,ij d 一般应满足下面的条件: 0 ij d 当第i 个样品与第j 个样品相等;● 0≥ij d 对一切i ,j ; ● ji ij d d =对一切i ,j ;● kj ik ij d d d +≤ 对一切对一切i ,j ,k 。

SAS软件——VARCLUS过程变量聚类如果没有为VARCLUS过程提供初始分类情况,VARCLUS过程开始把所有变量看成一个类,然后它重复以下步骤:(1)首先挑选一个将被分裂的类。
通常这个被选中的类的类分量所解释的方差百分比最小(选项PRECENT=)或者同第二主成分有关的特征值为最大(选项MAXETGH=)。
(2)把选中的类分裂成两个类。
首先计算前两个主成分,再进行斜交旋转,并把每个变量分配到旋转分量对应的类里,分配的原则是使变量与这个主成分的相关系数为最大。
(3)变量重新归类。
通过多次反复重复,变量被重新分配到这些类里,使得由这些类分量所解释的方差为最大。
当每一类满足用户规定的准则时,VARCLUS过程停止。
所谓准则,或是每个类分量所解释的方差的百分比,或是每一类的第二特征值达到预设定的标准为止。
如果没有准则,则当每个类只有一个特征值大于1时,VARCLUS过程停止。
SAS程序输入如下程序:OPTION PS=800;/* 要求输出的结果中每页包括800行内容,可避免不必要的SAS标题反复出现。
*/PROC VARCLUS DA TA=WORK.XLSSAS;VAR X1-X12;RUN;说明:过程语句中没有任何选择项,默认的聚类方法为主成分聚类法。
过程步最终会聚成多少类,将由默认的临界值来决定,即当每个类只有一个特征值大于1时,VARCLUS过程停止。
结果分析:The SA S System 10:04 Wednesday, November 24, 2010 17这是用分解法思想进行斜交主成分聚类的第1步,将全部12个变量聚成1类,能解释的方差为2.134427,占总方差的17.79%;第二特征值为1.5146.,并预告这一类将被分裂。
Oblique Principal Component Cluster AnalysisObservations 1018 PROPORTION 0Variables 12 MAXEIGEN 1Clustering algorithm converged.Cluster summary f or 1 clusterCluster Variation Proportion SecondCluster Members Variation Explained Explained Eigenvalue------------------------------------------------------------------------1 12 12 2.134427 0.1779 1.5146Total variation explained = 2.134427 Proportion = 0.1779Cluster 1 will be split.Clustering algorithm converged.第2步将1类分裂成2类,分别含4个和8个变量Variation Explained 解释方差,即第一特征值;Proportion Explained解释方差占本类总方差的百分比;Second Eigenvalue 类中的第二特征值。

第二十章 聚类分析SAS 程序设计一、聚类基本思想1. 什么是聚类分析聚类分析(cluster analysis):是一种将样本数据按一定科学方法分为若干类的统计方法。
聚类使得在同一类的事物具有高度的同质性(homogeneity),不同类事物具有高度的异质性(heterogeneity)。
聚类分析是为达到“物以类聚”目的分类。
聚类分析是研究事物的分类,事先对事物个体没有分类信息,完全根据数据的内在规律按相近原则划分新的类别。
对一个指标分类相对容易,当有多个指标,要进行分类就不是很容易了,对于事物按多指标同时考虑进行分类需要进行多元分类,即聚类分析。
聚类分析是依赖一批样本,不知道它们的分类,甚至连分成几类也不知道,希望用某种方法把观测样本进行合理的分类,使得同一类的观测比较接近,不同类的观测相差较多。
聚类分析依赖于对观测样本间的接近程度(距离)或相似程度的理解,定义不同的距离量度和相似性量度就可以产生不同的聚类结果。
聚类是相将近或相似的个体归为一类,聚类的实质就是相似性衡量。
类就是相似元素的集合。
聚类分析所要研究的是(1)、如何衡量事物之间的相似性---相似性度量。
(2)、如何将相似事物归为一类---聚类方法。
(3)、分类后如何描述这些类。
如何根据专业知识对所分的真实的类,自然客观的而非主观加工的类,进行经济意义或社会意义的解释。
2、相似度量聚类分析就是要找出具有相近程度的样本聚为一类;相似性度量的种类有多种,主要衡量这个“相近程度”的有距离、相似系数、相关系数、夹角余弦等。
距离的四个条件1.(,)(,)2.(,)0,3.(,)0,4.(,)(,)(,)d P Q d Q P d P Q Q Pd P Q Q Pd P Q d Q R d P R =>≠==≤+若若相似性度量的结果是得到一个相似测度矩阵。
若样本容量为n,n个样本的相似测度矩阵为n*n的对称矩阵。
样本间距离用欧式距离Euclid),马式距离(Mathalanobis),相关系数,夹角余弦等。


聚类分析的sas过程课程设计一、课程目标知识目标:1. 掌握聚类分析的基本概念和原理;2. 学习使用SAS软件进行聚类分析的过程和步骤;3. 了解不同聚类方法的优缺点及适用场景;4. 掌握对聚类结果进行解释和评价的方法。
技能目标:1. 能够运用SAS软件进行数据预处理,为聚类分析做好准备;2. 熟练操作SAS软件,运用合适的聚类方法对数据进行聚类分析;3. 学会对聚类结果进行可视化展示,并从中提取有价值的信息;4. 能够结合实际案例,运用聚类分析方法解决实际问题。
情感态度价值观目标:1. 培养学生对数据分析的兴趣,提高数据挖掘和统计分析的意识;2. 增强学生的团队协作能力,学会在团队中发挥个人特长,共同完成数据分析任务;3. 培养学生严谨的科学态度,注重实证研究,形成基于数据说话的习惯;4. 引导学生关注社会热点问题,运用所学知识为社会发展和决策提供支持。
课程性质:本课程为数据分析方向的专业课,旨在帮助学生掌握聚类分析方法,提高数据挖掘能力。
学生特点:学生具备一定的统计学基础和SAS软件操作能力,具有较强的学习兴趣和动手实践能力。
教学要求:结合课程性质和学生特点,采用案例教学、课堂讨论与实践操作相结合的教学方式,注重培养学生的实际操作能力和数据分析思维。
通过本课程的学习,使学生能够独立完成聚类分析任务,并为后续相关课程打下坚实基础。
二、教学内容1. 聚类分析基本概念:介绍聚类分析的定义、类型和基本原理,引导学生了解聚类分析在数据分析中的应用和价值。
2. 聚类方法选择:讲解常用的聚类方法(如K-means、系统聚类等),分析各种方法的优缺点及适用场景,帮助学生根据实际需求选择合适的聚类方法。
3. 数据预处理:介绍在聚类分析之前进行数据预处理的必要性,包括数据清洗、标准化、降维等操作,提高学生数据预处理的能力。
4. SAS软件操作:详细讲解SAS软件中进行聚类分析的步骤,包括数据导入、聚类过程调用、参数设置等,使学生熟练掌握SAS软件操作。
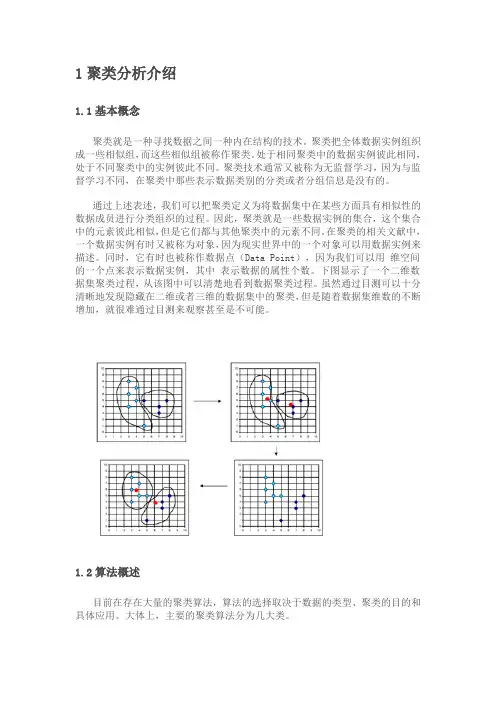
1聚类分析介绍1.1基本概念聚类就是一种寻找数据之间一种内在结构的技术。
聚类把全体数据实例组织成一些相似组,而这些相似组被称作聚类。
处于相同聚类中的数据实例彼此相同,处于不同聚类中的实例彼此不同。
聚类技术通常又被称为无监督学习,因为与监督学习不同,在聚类中那些表示数据类别的分类或者分组信息是没有的。
通过上述表述,我们可以把聚类定义为将数据集中在某些方面具有相似性的数据成员进行分类组织的过程。
因此,聚类就是一些数据实例的集合,这个集合中的元素彼此相似,但是它们都与其他聚类中的元素不同。
在聚类的相关文献中,一个数据实例有时又被称为对象,因为现实世界中的一个对象可以用数据实例来描述。
同时,它有时也被称作数据点(Data Point),因为我们可以用维空间的一个点来表示数据实例,其中表示数据的属性个数。
下图显示了一个二维数据集聚类过程,从该图中可以清楚地看到数据聚类过程。
虽然通过目测可以十分清晰地发现隐藏在二维或者三维的数据集中的聚类,但是随着数据集维数的不断增加,就很难通过目测来观察甚至是不可能。
1.2算法概述目前在存在大量的聚类算法,算法的选择取决于数据的类型、聚类的目的和具体应用。
大体上,主要的聚类算法分为几大类。
聚类算法的目的是将数据对象自动的归入到相应的有意义的聚类中。
追求较高的类内相似度和较低的类间相似度是聚类算法的指导原则。
一个聚类算法的优劣可以从以下几个方面来衡量:(1)可伸缩性:好的聚类算法可以处理包含大到几百万个对象的数据集;(2)处理不同类型属性的能力:许多算法是针对基于区间的数值属性而设计的,但是有些应用需要针对其它数据类型(如符号类型、二值类型等)进行处理;(3)发现任意形状的聚类:一个聚类可能是任意形状的,聚类算法不能局限于规则形状的聚类;(4)输入参数的最小化:要求用户输入重要的参数不仅加重了用户的负担,也使聚类的质量难以控制;(5)对输入顺序的不敏感:不能因为有不同的数据提交顺序而使聚类的结果不同;(6)高维性:一个数据集可能包含若干维或属性,一个好的聚类算法不能仅局限于处理二维或三维数据,而需要在高维空间中发现有意义的聚类;(7)基于约束的聚类:在实际应用中要考虑很多约束条件,设计能够满足特定约束条件且具有较好聚类质量的算法也是一项重要的任务;(8)可解释性:聚类的结果应该是可理解的、可解释的,以及可用的。

《统计软件》课程期末论文系(院):理学院专业:数学与应用数学班级:学生姓名:学号:指导教师:耿兴波开课时间:2012-2013 学年一学期目录题目: (2)1.聚类分析 (2)2.判别分析 (2)要求: (2)SAS软件介绍 (2)一、概述 (2)二、SAS系统的特点 (3)聚类分析 (4)基本原理: (4)使用的程序 (5)运行结果 (5)指令介绍 (8)结果分析 (8)判别分析 (9)基本原理: (9)使用的程序 (9)运行结果 (10)指令介绍 (20)结果分析 (22)总结 (22)感谢 (22)参考文献 (23)1题目:1.聚类分析某网站键鼠频道为广大职业玩家及游戏爱好者策划了一次全面的游戏鼠标横向测试,通过专家和消费者打分的形式,收集到了13款游戏鼠标的重要参数,即外观及手感、芯片及微动、功能及驱动、兼容性、游戏性等数据,(数据见Mouse_Cluster.sas7bdat)。
要求以这些指标为依据对所收集的样本进行聚类分析。
2.判别分析在上述聚类分析中,取Ward法聚类结果把13个鼠标分为3类。
假定这13个鼠标的样本来自于已有类别的总体(即已知具体鼠标类别的训练样本)。
现又有两款鼠标的测评数据(Mouce_Discrim.sas7bdat),试利用判别分析的方法把两款鼠标归入对应的类别。
要求:1.介绍SAS软件。
2.介绍聚类分析的基本原理3.介绍使用了哪些命令。
4.介绍题目,结果及最后的分析。
SAS软件介绍一、概述SAS系统全称为Statistics Analysis System,最早由北卡罗来纳大学的两位生物统计学研究生编制,并于1976年成立了SAS软件研究所,正式推出了SAS软件。
SAS是用于决策支持的大型集成信息系统,但该软件系统最早的功能限于统计分析,至今,统计分析功能也仍是它的重要组成部分和核心功能。
SAS现在的版本为9.0版,大小约为1G。
经过多年的发展,SAS已被全世界120多个国家和地区的近三万家机构所采用,直接用户则超过三百万人,遍及金融、医药卫生、生产、运输、通讯、政府和教育科研等领域。

实验报告实验项目名称聚类分析与判别分析所属课程名称统计分析及SAS实现实验类型验证性实验实验日期2016-12-19班级数学与应用数学学号姓名成绩图8.1 聚类谱系图图8.1为proc cluster过程不得出的谱系图,为更方便直观,我们利用proc tree过程步得出图8.2。
②利用proc tree过程步得出聚类谱系图。
过程步:proc tree data=Lmf.tree1 horizontal;id region;run;结果:The TREE ProcedureWard's Minimum Variance Cluster Analysis图8.2 聚类谱系图由表8.2、图8.2得出,分为三类较合适,第一类为北京、天津、上海,第二类为河北、山东、河南、内蒙、江苏、浙江、山西、湖北、四川、福建、江西、湖南、海南、广东、新疆、广西、吉林、黑龙江、辽宁、陕西,第三类为安徽、宁夏、贵州、云南、甘肃、青海、西藏。
【练习8-2】有6个铅弹头,用“中子活化”方法测得7种微量元素含量数据。
表 7种微量元素含量数据Num Ag Al Cu Ca Sb Bi Sn10.05798 5.515347.121.918586174261.6920.08441 3.97347.219.7179472000244030.07217 1.15354.85 3.05238601445949740.1501 1.702307.515.0312290146163805 5.744 2.854229.69.657809912661252060.2130.7058240.313.91898028204135①试用多种系统聚类分析方法对6个铅弹头和7种微量元素进行分类,并进行分类结果。
②试用VARCLUS过程对7中微量元素进行分类。
【解答】①通过比较⑴⑵⑶三种系统聚类的方法类平均法、ward离差平方和法、最长距离法,对6个铅弹头进行分类。
