Hadoop现场演示与编程过程
- 格式:ppt
- 大小:1.55 MB
- 文档页数:36

hadoop工作流程Hadoop工作流程Hadoop是一个开源的分布式计算框架,它能够处理大规模数据集并行计算。
Hadoop的工作流程可以分为数据存储、数据处理和数据输出三个部分。
一、数据存储Hadoop的数据存储是通过Hadoop分布式文件系统(HDFS)实现的。
HDFS将数据分成多个块,并将这些块存储在不同的节点上。
每个块都有多个副本,以保证数据的可靠性和高可用性。
当一个节点出现故障时,HDFS会自动将该节点上的块复制到其他节点上,以保证数据不会丢失。
二、数据处理Hadoop的数据处理是通过MapReduce实现的。
MapReduce是一种分布式计算模型,它将数据分成多个小块,并将这些小块分配给不同的节点进行处理。
每个节点都会执行Map和Reduce两个操作,Map操作将输入数据转换成键值对,Reduce操作将相同键的值进行合并。
最终的结果会被写入到HDFS中。
三、数据输出Hadoop的数据输出是通过Hadoop的输出格式实现的。
Hadoop支持多种输出格式,包括文本、序列化、Avro、Parquet等。
用户可以根据自己的需求选择不同的输出格式。
输出的数据可以被存储到HDFS中,也可以被导出到其他系统中。
总结Hadoop的工作流程可以分为数据存储、数据处理和数据输出三个部分。
数据存储是通过HDFS实现的,数据处理是通过MapReduce实现的,数据输出是通过Hadoop的输出格式实现的。
Hadoop的分布式计算能力使得它能够处理大规模数据集,并且具有高可靠性和高可用性。
Hadoop已经成为了大数据处理的重要工具之一,它的应用范围越来越广泛。


Python Hadoop的使用方法和技巧随着数据存储量的不断增加,处理大规模数据已经成为了重要的课题。
为了解决这一问题,Hadoop逐渐成为了大数据处理领域的重要工具之一。
Python是一种流行的编程语言,也被广泛用于大数据处理。
如何在Python中使用Hadoop,并获得最佳效果呢?本文将就此问题进行探讨。
Hadoop概述Hadoop是一种大数据处理架构,包含两个核心组件:HDFS和MapReduce。
HDFS是一个具有高容错性的分布式文件系统,可以在不同节点之间分配文件存储。
而MapReduce是一种并行处理框架,能够对大规模数据进行分析和处理。
Hadoop的分布式特性和强大的处理能力,使其成为了大规模数据处理的首选工具之一。
Python概述Python是一种高级编程语言,易于学习,丰富的库和模块使其适合于各种任务,包括数据处理。
其语法简单、直观、易于理解,非常灵活,可用于各种数据处理任务。
Python还可以与其他大型工具和框架集成,如Hadoop。
Python Hadoop远程操作技巧Python与Hadoop集成主要通过Hadoop Streaming实现,它允许使用标准输入和输出流作为MapReduce任务的输入和输出端点。
Hadoop Streaming默认情况下使用基于Java的MapReduce实现。
Python代码可以通过标准输入或标准输出传递数据,Hadoop Streaming将负责确保其在分布式环境中正确地执行。
以下是Python与Hadoop的操作技巧和步骤:1.准备MapReduce任务首先,需要准备一个MapReduce任务。
在Python中,可以使用其他Python库来创建MapReduce程序。
例如,可以使用mrjob库来定义和运行MapReduce任务。
2.Streaming命令streaming命令是一种将MapReduce作业提交到Hadoop集群的方法。
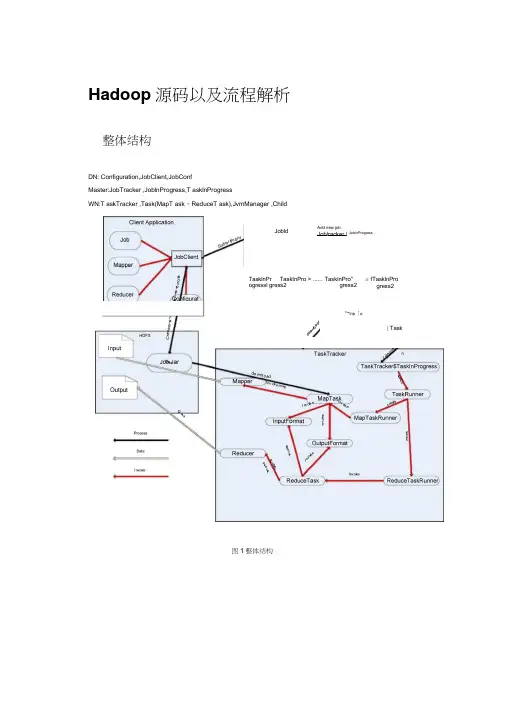
Hadoop源码以及流程解析整体结构DN: Configuration,JobClient,JobConfMaster:JobTracker ,JoblnProgress,T asklnProgressWN:T askTracker ,Task(MapT ask、ReduceT ask),JvmManager ,Child图1整体结构Jobld Add new jobJoblracker I JobInProgressTasklnPr TaskInPro > ...... TasklnPro" ogressl gress2 gress2 ■ f TasklnProgress2Ta*lnp「o[ TaskClientConfiguration从Configuration 类的源代码可以看到,定义了如下私有成员变量:private boolean quietmode = true;// 第一个是boolean 型变量quietmode ,用于设置加载配置的模式。
通过阅读源代码就可以清楚,这个quietmode 如果为true ,实际上默认就为true,加载配置的模式为快速模式,其实也就是在解析配置文件的过程中,不输出日志信息,就这么简单。
private ArrayList defaultResources = new ArrayList();// 它是一个列表,该列表中存放的是配置文件的名称private ArrayList<Object> resources = new ArrayList<Object>();// 全部资源的配置包括URL 、String 、Path、InputStreamprivate Set<String> finalParameters = new HashSet<String>();// 程序性的private boolean loadDefaults = true;// 是否载入默认资源private static final WeakHashMap<Configuration, Object> REGISTRY = new WeakHashMap<Configuration, Object>();//private Properties properties;// 个人程序所需要的所有配置会以Properties 的形式存储private Properties overlay;// 它也是一个Properties 变量。

Hadoop编程入门Hadoop 是Google MapReduce的一个Java 实现。
MapReduce是一种简化的分布式编程模式,让程序自动分布到一个由普通机器组成的超大集群上并发执行。
就如同java程序员可以不考虑内存泄露一样,MapReduce的r un-time系统会解决输入数据的分布细节,跨越机器集群的程序执行调度,处理机器的失效,并且管理机器之间的通讯请求。
这样的模式允许程序员可以不需要有什么并发处理或者分布式系统的经验,就可以处理超大的分布式系统得资源。
一、概论作为Hadoop程序员,他要做的事情就是:定义Mapper,处理输入的Key-Value对,输出中间结果。
定义Reducer,可选,对中间结果进行规约,输出最终结果。
定义InputFormat 和OutputFormat,可选,InputFormat将每行输入文件的内容转换为Java类供Mappe r函数使用,不定义时默认为String。
定义main函数,在里面定义一个Job并运行它。
然后的事情就交给系统了。
基本概念:Hadoop的HDFS实现了google的GFS文件系统,NameNode作为文件系统的负责调度运行在master,DataNode运行在每个机器上。
同时Hadoop实现了Google的MapReduce,JobTracker作为MapRe duce的总调度运行在master,TaskTracker则运行在每个机器上执行Task。
main()函数,创建JobConf,定义Mapper,Reducer,Input/OutputFormat 和输入输出文件目录,最后把Job提交給JobTracker,等待Job结束。
JobTracker,创建一个InputFormat的实例,调用它的getSplits()方法,把输入目录的文件拆分成FileSpli st作为Mapper task 的输入,生成Mapper task加入Queue。



Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。
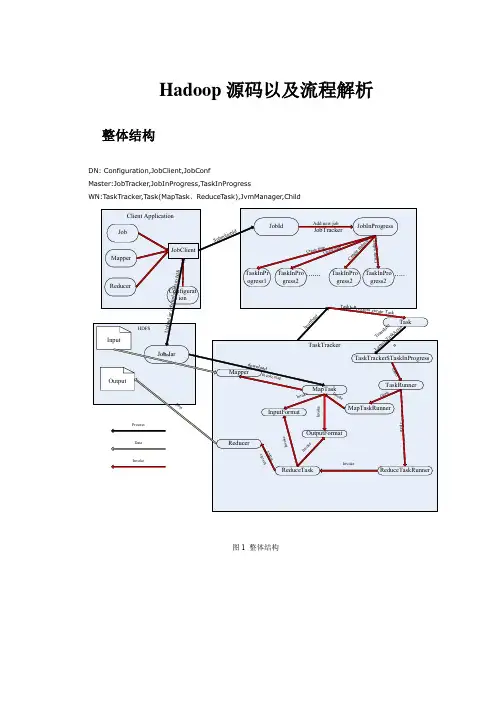
Hadoop源码以及流程解析整体结构DN: Configuration,JobClient,JobConfMaster:JobTracker,JobInProgress,T askInProgressWN:T askTracker,T ask(MapT ask、ReduceT ask),JvmManager,Child图1 整体结构ClientConfiguration从Configuration类的源代码可以看到,定义了如下私有成员变量:private boolean quietmode = true;// 第一个是boolean型变量quietmode,用于设置加载配置的模式。
通过阅读源代码就可以清楚,这个quietmode如果为true,实际上默认就为true,加载配置的模式为快速模式,其实也就是在解析配置文件的过程中,不输出日志信息,就这么简单。
private ArrayList defaultResources = new ArrayList();//它是一个列表,该列表中存放的是配置文件的名称private ArrayList<Object> resources = new ArrayList<Object>();//全部资源的配置包括URL、String、Path、InputStreamprivate Set<String> finalParameters = new HashSet<String>();//程序性的private boolean loadDefaults = true;//是否载入默认资源private static final WeakHashMap<Configuration, Object> REGISTRY = new WeakHashMap<Configuration, Object>();//private Properties properties;//个人程序所需要的所有配置会以Properties的形式存储private Properties overlay;// 它也是一个Properties变量。

Hadoop工作流程引言Hadoop是一个开源的分布式计算框架,用于处理大规模数据集。
它的设计目标是能够在普通的硬件上高效地处理大规模数据。
Hadoop的工作流程是由一系列的步骤组成的,这些步骤共同协作来完成数据处理任务。
本文将介绍Hadoop的工作流程,包括数据划分、并行计算以及结果汇总等过程。
Hadoop的工作流程Hadoop的工作流程可以分为三个主要的步骤:数据划分、并行计算和结果汇总。
下面将详细介绍每个步骤的工作流程。
数据划分Hadoop处理的数据通常存储在分布式文件系统中,比如Hadoop分布式文件系统(HDFS)。
在数据划分阶段,大规模的数据集会根据一定的规则或条件进行划分。
这种划分通常称为分片(或块),有助于提高数据的处理效率。
一般来说,数据划分可以根据输入数据的大小、格式和特定的算法进行。
每个数据分片都会被分配给不同的计算节点进行处理。
并行计算在Hadoop中,每个计算节点上都会运行一个任务调度器(Task Scheduler)。
任务调度器负责将任务分配给计算节点,并监控任务的执行情况。
当一个计算节点完成一个任务时,它会将结果存储在本地磁盘上。
这种分布式的计算模型能够高效地处理大规模数据。
结果汇总当所有的计算节点完成任务后,Hadoop会将这些计算节点上的结果进行汇总。
结果汇总可以通过网络传输,也可以通过物理设备存储在其中一个计算节点上。
汇总结果通常以某种格式存储,比如文本文件、序列化文件、数据库等。
Hadoop工作流程示例为了更好地理解Hadoop的工作流程,下面将结合一个示例来说明。
假设我们有一个包含一百万个URL链接的文本文件,我们想要统计其中每个URL的出现次数。
1.数据划分:首先,Hadoop会将文本文件划分为多个数据分片(或块),每个分片包含一定数量的URL链接。
这些数据分片会分配给不同的计算节点进行处理。
2.并行计算:每个计算节点会分别读取属于自己的数据分片,并统计每个URL的出现次数。

Hadoop集群搭建与编程-分布式模式作者: maple 日期: 2011/06/26 发表评论(0)查看评论前文简单介绍了伪分布式模式搭建hadoop集群的过程,这种方式有利于本地开发和调试,但只有分布式模式才能发挥hadoop的优势。
本文接下来介绍hadoop分布式模式环境的搭建。
主参考文章:Hadoop分布式安装。
准备工作Hadoop要求集群中的机器是同构的。
为了避免意外,我们应该保证:∙集群的机器能够互相访问(尤其是处理好iptables);∙集群的机器使用相同的用户名(最好是新建一个hadoop用户)∙集群的机器中hadoop根目录相同∙集群的机器需要安装版本一致的jdk( 5.0 以上),并配置好JAVA_HOME环境变量满足这些条件后,我们假设这些机器是:# NO. IP HOSTNAME(1) 192.168.1.1 hadoop-test1 #作为Namenode, JobTracker, SecondaryNameNode(2) 192.168.1.2 hadoop-test2 #作为Datanode, TaskTracker(3) 192.168.1.3 hadoop-test3 #作为Datanode, TaskTracker各台机器的用户同为maple,hadoop根目录为:/home/maple/hadoop/hadoop/机器环境配置完成后,就可以开工啦~配置首先,需要配置各个机器间的相互访问:1、按照上面的设置修改各台机器的host文件和hostname文件,保证机器可正常通信。
如1号机器上的hosts文件(相关部分)为:127.0.0.1 localhost192.168.1.1 hadoop-test1192.168.1.2 hadoop-test2192.168.1.3 hadoop-test32、配置ssh的自动登陆(在1号机器上):$ ssh-keygen -t dsa -P ” -f ~/.ssh/id_dsa完成后会在~/.ssh/生成两个文件:id_dsa和id_dsa.pub。
Hadoop大数据开发基础教案Hadoop教案MapReduce入门编程教案第一章:Hadoop概述1.1 Hadoop简介了解Hadoop的发展历程理解Hadoop的核心价值观:可靠性、可扩展性、容错性1.2 Hadoop生态系统掌握Hadoop的主要组件:HDFS、MapReduce、YARN理解Hadoop生态系统中的其他重要组件:HBase、Hive、Pig等1.3 Hadoop安装与配置掌握Hadoop单机模式安装与配置掌握Hadoop伪分布式模式安装与配置第二章:HDFS文件系统2.1 HDFS简介理解HDFS的设计理念:大数据存储、高可靠、高吞吐掌握HDFS的基本架构:NameNode、DataNode2.2 HDFS操作命令掌握HDFS的基本操作命令:mkdir、put、get、dfsadmin等2.3 HDFS客户端编程掌握HDFS客户端API:Configuration、FileSystem、Path等第三章:MapReduce编程模型3.1 MapReduce简介理解MapReduce的设计理念:将大数据处理分解为简单的任务进行分布式计算掌握MapReduce的基本概念:Map、Shuffle、Reduce3.2 MapReduce编程步骤掌握MapReduce编程的四大步骤:编写Map函数、编写Reduce函数、设置输入输出格式、设置其他参数3.3 典型MapReduce应用掌握WordCount案例的编写与运行掌握其他典型MapReduce应用:排序、求和、最大值等第四章:YARN资源管理器4.1 YARN简介理解YARN的设计理念:高效、灵活、可扩展的资源管理掌握YARN的基本概念:ResourceManager、NodeManager、ApplicationMaster等4.2 YARN运行流程掌握YARN的运行流程:ApplicationMaster申请资源、ResourceManager 分配资源、NodeManager执行任务4.3 YARN案例实战掌握使用YARN运行WordCount案例掌握YARN调优参数设置第五章:Hadoop生态系统扩展5.1 HBase数据库理解HBase的设计理念:分布式、可扩展、高可靠的大数据存储掌握HBase的基本概念:表结构、Region、Zookeeper等5.2 Hive数据仓库理解Hive的设计理念:将SQL查询转换为MapReduce任务进行分布式计算掌握Hive的基本操作:建表、查询、数据导入导出等5.3 Pig脚本语言理解Pig的设计理念:简化MapReduce编程的复杂度掌握Pig的基本语法:LOAD、FOREACH、STORE等第六章:Hadoop生态系统工具6.1 Hadoop命令行工具掌握Hadoop命令行工具的使用:hdfs dfs, yarn命令等理解命令行工具在Hadoop生态系统中的作用6.2 Hadoop Web界面熟悉Hadoop各个组件的Web界面:NameNode, JobTracker, ResourceManager等理解Web界面在Hadoop生态系统中的作用6.3 Hadoop生态系统其他工具掌握Hadoop生态系统中的其他工具:Azkaban, Sqoop, Flume等理解这些工具在Hadoop生态系统中的作用第七章:MapReduce高级编程7.1 二次排序理解二次排序的概念和应用场景掌握MapReduce实现二次排序的编程方法7.2 数据去重理解数据去重的重要性掌握MapReduce实现数据去重的编程方法7.3 自定义分区理解自定义分区的概念和应用场景掌握MapReduce实现自定义分区的编程方法第八章:Hadoop性能优化8.1 Hadoop性能调优概述理解Hadoop性能调优的重要性掌握Hadoop性能调优的基本方法8.2 HDFS性能优化掌握HDFS性能优化的方法:数据块大小,副本系数等8.3 MapReduce性能优化掌握MapReduce性能优化的方法:JVM设置,Shuffle优化等第九章:Hadoop实战案例9.1 数据分析案例掌握使用Hadoop进行数据分析的实战案例理解案例中涉及的技术和解决问题的方法9.2 数据处理案例掌握使用Hadoop进行数据处理的实战案例理解案例中涉及的技术和解决问题的方法9.3 数据挖掘案例掌握使用Hadoop进行数据挖掘的实战案例理解案例中涉及的技术和解决问题的方法第十章:Hadoop项目实战10.1 Hadoop项目实战概述理解Hadoop项目实战的意义掌握Hadoop项目实战的基本流程10.2 Hadoop项目实战案例掌握一个完整的Hadoop项目实战案例理解案例中涉及的技术和解决问题的方法展望Hadoop在未来的发展和应用前景重点和难点解析重点环节1:Hadoop的设计理念和核心价值观需要重点关注Hadoop的设计理念和核心价值观,因为这是理解Hadoop生态系统的基础。
实验二Hadoop环境下MapReduce并行编程一. 实验目的1.学习MapReduce编程模型,理解MapReduce的编程思想。
会用MapReduce框架编写简单的并行程序。
2.熟悉使用eclipse编写、调试和运行MapReduce并行程序。
二. 实验内容1.登录Openstack云平台,进入搭建好Hadoop的虚拟机,按照实验指导说明,在终端启动hadoop、启动eclipse。
2.用MapReduce编程思想,修改hadoop自带的例子程序WordCount,实现如下功能:统计给定文件data.dat中出现频率最多的三个单词,并输出这三个单词和出现的次数。
(注:这里不区分字母大小写,如he与He当做是同一个单词计数)三. 实验指导1.进入虚拟机,打开终端,切换为root用户,命令使用:su root输入密码2.进入hadoop安装目录,本实验中hadoop安装目录为:/usr/local/hadoop-2.6.0/,使用ls命令查看该目录中的文件:3.所有与hadoop启动/关闭有关的脚本位于sbin目录下,所以继续进入sbin目录。
其中,hadoop2.X版本的启动命令主要用到start-dfs.sh和start-yarn.sh。
关闭hadoop主要用到stop-dfs.sh和stop-yarn.sh。
执行start-dfs.sh,然后使用jps命令查看启动项,保证NameNode和DataNode 已启动,否则启动出错:执行start-yarn.sh,jps查看时,保证以下6个启动项已启动:4.打开eclipse,在右上角进入Map/Reduce模式,建立eclispe-hadoop连接5.连接成功后,能够在(1)这个文件夹下再创建文件夹(创建后需refresh)6.建立wordcount项目,如下步骤:7.next,项目名任意(如wordcount),finish。
将WordCount.java文件复制到wordcount项目下src文件中,双击打开。
hadoop工作流程
Hadoop是一个开源的分布式计算框架,主要用于处理大规模数据。
它的工作流程包括以下几个步骤:
1.数据输入:Hadoop将数据分为多个块,并将这些块分配给不同的节点进行处理。
通常情况下,数据会从HDFS(Hadoop分布式文件系统)中输入。
2.数据处理:Hadoop采用MapReduce模型进行数据处理。
首先,Map任务将数据块分为更小的数据块,并将这些数据块分配给不同的节点进行处理。
然后,Reduce任务将Map任务输出的结果进行合并和汇总。
3.数据输出:处理完的数据可以保存到HDFS中或输出到其他存储设备,如数据库或本地文件系统。
4.监控管理:Hadoop集群需要进行监控和管理,以确保其正常运行。
这包括监控节点的健康状态、调度任务和资源分配等。
5.错误处理:如果在处理数据时发生错误,Hadoop会自动处理并重新执行任务。
如果任务多次失败,Hadoop将停止任务并将其标记为失败。
总的来说,Hadoop的工作流程是分布式的,具有高可用性和容错能力,可以有效地处理大规模数据。
- 1 -。
HDFS编程实践(Hadoop3.1.3)⼀、使⽤ Eclipse 开发调试 HDFS Java 程序实验任务:1. 在分布式⽂件系统中创建⽂件并⽤ shell 指令查看;2. 利⽤ Java API 编程实现判断⽂件是否存在以及合并两个⽂件的内容成⼀个⽂件。
1、创建⽂件⾸先启动 hadoop,命令:$ cd /usr/local/hadoop/ ; $ ./sbin/start-dfs.sh,如图:在本地 Ubuntu ⽂件系统的/home/Hadoop/⽬录下创建两个⽂件 file_a.txt、file_b.txt:$ touch /home/Hadoop/file_a.txt$ touch /home/Hadoop/file_b.txt把本地⽂件系统的/home/Hadoop/file_a.txt、/home/Hadoop/file_b.txt上传到 HDFS 中的当前⽤户⽬录下,即上传到 HDFS 的/user/hadoop/⽬录下:./bin/hdfs dfs -put /home/Hadoop/file_a.txt./bin/hdfs dfs -put /home/Hadoop/file_b.txt在⽂件⾥编辑内容:gedit /home/Hadoop/file_a.txtgedit /home/Hdaoop/file_b.txt查看⽂件是否上传成功:./bin/hdfs dfs -ls可以看到,以上两个⽂件已经上传成功。
读取⽂件内容:./bin/hdfs dfs -cat file_a.txt./bin/hdfs dfs -cat file_b.txt上图暂时有个报错,我们可以看到,两个⽂件的读取已经成功。
2、利⽤Java API 编程实现在 Eclipse 中创建项⽬启动 Eclipse,启动后,会弹出如下图所⽰的界⾯,提⽰设置⼯作空间(workspace)直接采⽤默认设置,点击 OK 即可。