Hadoop 学习笔记
- 格式:docx
- 大小:280.90 KB
- 文档页数:10

云计算学习笔记Hadoop+HDFS和MapReduce+架构浅析 34IT168文云计算学习笔记hadoop+hdfs和mapreduce+架构浅析-34-it168文hadoophdfs和mapreduce架构浅析前言hadoop是一个基于java的分布式密集数据处理和数据分析的软件框架。
hadoop在很大程度上是受google在2021年白皮书中阐述的mapreduce技术的启发。
mapreduce工作原理是将任务分解为成百上千个小任务,然后发送到计算机集群中。
每台计算机再传送自己那部分信息,mapreduce则迅速整合这些反馈并形成答案。
简单来说,就是任务的分解和结果的合成。
hadoop的扩展性非常杰出,hadoop可以处置原产在数以千计的低成本x86服务器排序节点中的大型数据。
这种高容量低成本的女团引人注目,但hadoop最迎合人的就是其处置混合数据类型的能力。
hadoop可以管理结构化数据,以及诸如服务器日志文件和web页面上涌的数据。
同时还可以管理以非结构化文本为中心的数据,如facebook和twitter。
1hadoop基本架构hadoop并不仅仅是一个用于存储的分布式文件系统,而是在由通用计算设备组成的大型集群上执行分布式应用的框架。
apachehadoop项目中包含了下列产品(见图1)。
图1hadoop基本共同组成pig和hive是hadoop的两个解决方案,使得在hadoop上的编程更加容易,编程人员不再需要直接使用javaapis。
pig可加载数据、转换数据格式以及存储最终结果等一系列过程,从而优化mapreduce运算。
hive在hadoop中饰演数据仓库的角色。
hive需向hdfs嵌入数据,并容许采用相似sql的语言展开数据查阅。
chukwa就是基于hadoop集群的监控系统,直观来说就是一个watchdog。
hbase就是一个面向列于的分布式存储系统,用作在hadoop中积极支持大型稠密表的列存储数据环境。

Hadoop学习总结HDFS相关HDFS写数据的流程⾸先由客户端向NameNode服务发起写数据请求NameNode收到请求后会进⾏基本验证验证类容包括对请求上传的路径进⾏合法验证对请求的⽤户进⾏权限验证验证没有问题后,NameNode会响应客户端允许上传接下来客户端会对⽂件按照blocksize⼤⼩进⾏切块,切完后依次以块为单位上传此时客户端会请求上传第⼀个块信息服务端接到上传请求后会依据HDFS默认机架感知原理,返回3台存放数据块副本的DataNode机器客户端收到机器列表后会依据⽹络拓扑原理找到其中⼀台机器进⾏传输通道的建⽴然后依次和三台机器进⾏串⾏连接这样的连接主要是为了减轻客户端本地IO的压⼒当通道建⽴成功后,客户端会通过HDFS的FSOutputStream流对象进⾏数据传输数据传输的最⼩单位为packet传输过程中每台DataNode服务器串⾏连接,依次将数据传递最后⼀个数据块被传输完成后相当于⼀次写⼊结束,如果还有数据块要传输,那就接着传输第⼆个数据块HDFS读数据的流程和写数据⼀样,由客户端向NameNode发出请求NameNode收到请求后会进⾏⽂件下载路径的合法性以及权限验证如果验证没问题,就会给客户端返回⽬标⽂件的元数据信息信息中包含⽬标⽂件数据块对应的DataNode的位置信息然后客户端根据具体的DataNode位置信息结合就近原则⽹络拓扑原理找到离⾃⼰最近的⼀台服务器对数据进⾏访问和下载最后通过HDFS提供的FSInputStream对象将数据读取到本地如果有多个块信息就会请求多次DataNode直到⽬标⽂件的全部数据被下载HDFS的架构及每个服务的作⽤HDFS是Hadoop架构中负责完成数据分布式存储管理的⽂件系统⾮⾼可⽤集群⼯作时会启动三个服务,分别是NameNode、DataNode以及SecondaryNameNode其中NameNode是HDFS的中⼼服务,主要维护管理⽂件系统中的⽂件的元数据信息DataNode主要负责存储⽂件的真实数据块信息DataNode的数据块信息中也包含⼀些关于当前数据块的元数据信息,如检验值,数据长度,时间戳等在⾮⾼可⽤HDFS集群中,NameNode和DataNode可以理解为是⼀对多的关系⼆者在集群中也要保存通信,通常默认3秒钟会检测⼀下⼼跳最后SecondaryNameNode的⼯作很单⼀,就是为了给NameNode的元数据映像⽂件和编辑⽇志进⾏合并,并⾃⼰也保留⼀份元数据信息,以防NameNode元数据丢失后有恢复的保障HDFS中如何实现元数据的维护NameNode的元数据信息是通过fsimage⽂件 + edits编辑⽇志来维护的当NameNode启动的时候fsimage⽂件和edits编辑⽇志的内容会被加载到内存中进⾏合并形成最新的元数据信息当我们对元数据进⾏操作的时候,考虑到直接修改⽂件的低效性,⽽不会直接修改fsimage⽂件⽽是会往edits编辑⽇志⽂件中追加操作记录当满⾜⼀定条件时,会让Secondary NameNode来完成fsimage⽂件和edits编辑⽇志⽂件的合并Secondary NameNode⾸先会让NameNode停⽌对正在使⽤的edits编辑⽇志⽂件的使⽤,并重新⽣成⼀个新的edits编辑⽇志⽂件接着把NameNode的fsimage⽂件和已停⽌的edits⽂件拷贝到本地在内存中将edits编辑⽇志⽂件的操作记录合并到fsimage⽂件中形成⼀个最新的fsimage⽂件最后会将这个最新的fsimage⽂件推送给NameNode并⾃⼰也备份⼀份NN和DN的关系,以及DN的⼯作流程从数据结构上看,就是⼀对多的关系⼀个HDFS集群中只能有⼀个NameNode⽤于维护元数据信息,同时会有多个DataNode⽤于存储真实的数据块当HDFS集群启动的时候,会⾸先进⼊到安全模式下在安全模式下我们只能对数据进⾏读取不能进⾏任何写操作此时集群的每⼀台DataNode会向NameNode注册⾃⼰注册成功后DataNode会上报⾃⼰的数据块详细信息当数据块汇报满⾜最⼩副本条件后,会⾃动退出安全模式此后DataNode和NameNode每三秒会通信⼀次,如果NameNode检测到DataNode没有响应,会继续检测⼀直到10分30秒后还没有检测到,就确定当前的DataNode不可⽤MapReduce相关⼿写MR的⼤概流程和规范MR程序的结构可以分为3部分,⼀是程序的执⾏⼊⼝,通常简称为驱动类驱动类主要编写MR作业的提交流程以及⾃定义的⼀些配置项⼆是Map阶段核⼼类,需要⾃定义并继承Mappper类,重写Mapper中的map⽅法在map⽅法中编写⾃⼰的业务逻辑代码将数据处理后利⽤context上下⽂对象的写出落盘三是Reduce阶段的核⼼类,同时也需要继承Hadoop提供的Reducer类并重写reduce⽅法在reduce⽅法中编写⾃⼰的业务逻辑代码,处理完数据后通过context上下⽂对象将数据写出,这也就是最终的结果⽂件如何实现Hadoop的序列化,Hadoop的序列化和Java的序列化有什么区别⾸先,序列化是把内存中的Java对象转化成⼆进制字节码,反序列化是将⼆进制字节码转化成Java对象通常我们在对Java对象进⾏磁盘持久化写⼊或将Java对象作为数据进⾏⽹络传输的时候需要进⾏序列化相反如果要将数据从磁盘读出并转化成Java对象需要进⾏反序列化实现Hadoop中的序列化需要让JavaBean对象实现Writable接⼝,并重写wirte()⽅法和readFields()⽅法其中wirte()是序列化⽅法,readFields()⽅法是反序列化⽅法Hadoop序列化和Java序列化的区别在于,java序列化更重量级Java序列化后的结果不仅仅⽣成⼆进制字节码⽂件,同时还会针对当前Java对象⽣成对应的检验信息以及集成体系结构这样的话,⽆形中我们需要维护更多的数据但是Hadoop序列化不会产⽣除了Java对象内部属性外的任何信息,整体内容更加简洁紧凑,读写速度相应也会提升很多,这也符合⼤数据的处理背景MR程序的执⾏流程MR程序执⾏先从InputFormat类说起,由InputFormat负责数据读⼊,并在内部实现切⽚每个切⽚的数据对应⽣成⼀个MapTask任务MapTask中按照⽂件的⾏逐⾏数据进⾏处理,每⼀⾏数据会调⽤⼀次我们⾃定义的Mapper类的map⽅法map⽅法内部实现具体的业务逻辑,处理完数据会通过context对象将数据写出到磁盘,接下来ReduceTask会开始执⾏⾸先ReduceTask会将MapTask处理完的数据结果拷贝过来每组相同key的values会调⽤⼀次我们⾃定义Reducer类的reduce⽅法当数据处理完成后,会通过context对象将数据结果写出到磁盘上InputFormat负责数据写份时候要进⾏切⽚,为什么切⽚⼤⼩默认是128M⾸先切⽚⼤⼩是可以通过修改配置参数来改变的,但默认情况下是和切块blocksize⼤⼩⼀致这样做的⽬的就是为了在读取数据的时候正好能⼀次性读取⼀个块的数据,避免了在集群环境下发⽣跨机器读取的情况如果跨机器读取会造成额外的⽹络IO,不利于MR程序执⾏效率的提升描述⼀下切⽚的逻辑MR中的切⽚是发⽣在数据读⼊的阶段中,所以我们要关注InputFormat的实现通过追溯源码,在InputFormat这个抽象类中有⼀个getSplits(),这个⽅法就是实现切⽚的具体逻辑⾸先关注两个变量,分别是minSize和maxSize,默认情况minSize = 1,maxSize = Long.MAX_VALUE源码中声明了⼀个集合List splits = new ArrayList(),⽤于装载将来的切⽚对象并返回接下来根据提交的job信息获取到当前要进⾏切⽚的⽂件详情⾸先判断当前⽂件是否可以进⾏切分,这⼀步主要考虑到⼀些不⽀持切分的压缩⽂件不能进⾏切⽚操作,否则就破坏了数据的完整性如果当前⽂件可以切⽚的话,就要计算切⽚的⼤⼩切⽚的⼤⼩⼀共需要三个因⼦,分别是minSize、maxSize、blocksize最后通过Math.max(minSize,Math.min(maxSize,blocksize)),计算逻辑获取到切⽚的⼤⼩默认情况下切⽚⼤⼩和数据块⼤⼩⼀致如果想要改变切⽚的⼤⼩可以通过修改mapreduce.input.fileinputformat.split.minsize(把切⽚调⼤)、mapreduce.input.fileinputformat.split.maxsize(把切⽚调⼩)两个参数实现获取到切⽚⼤⼩后继续往下执⾏,在最终完成切⽚之前还有⼀个关键判断就是判断剩余⽂件是否要进⾏切⽚CombineTextInputFormat机制是怎么实现的CombineTextInoutFormat是InputFormat的⼀个实现类,主要⽤于解决⼩⽂件场景⼤概思路是先在Job提交中指定使⽤InputFormat的实现类为CombineTextInputFormat接下来的切⽚过程中会先把当前⽂件的⼤⼩和设置的切⽚的最⼤值进⾏⽐较如果⼩于最⼤值,就单独划分成⼀块如果⼤于切⽚的最⼤值并⼩于两倍的切⽚的最⼤值,就把当前⽂件⼀分为⼆划分成两块以此类推逐个对⽂件进⾏处理,这个过程称之为虚拟过程最后⽣成真正的切⽚的时候,根据虚拟好的⽂件进⾏合并只要合并后⽂件⼤⼩不超过最开始设置好的切⽚的最⼤值那就继续追加合并直到达到设置好的切⽚的最⼤值此时就会产⽣⼀个切⽚,对应⽣成⼀个MapTaskShuffle机制流程当MapTask执⾏完map()⽅法后通过context对象写数据的时候开始执⾏shuffle过程⾸先数据先从map端写⼊到环形缓冲区内写出的数据会根据分区规则进⼊到指定的分区,并且同时在内存中进⾏区内排序环形缓冲区默认⼤⼩为100M当数据写⼊的容量达到缓冲区⼤⼩的80%,数据开始向磁盘溢写如果数据很多的情况下,可能发⽣N次溢写这样在磁盘上就会产⽣多个溢写⽂件,并保证每个溢写⽂件中区内是有序的到此shuffle过程在Map端就完成了接着Map端输出的数据会作为Reduce端的数数据再次进⾏汇总操作此时ReduceTask任务会把每⼀个MapTask中计算完的相同的分区的数据拷贝到ReduceTask的内存中,如果内存放不下,开始写⼊磁盘再接着就是对数据进⾏归并排序,排序完还要根据相同的key进⾏分组将来⼀组相同的key对应的values调⽤⼀次reduce⽅法,如果有多个分区就会产⽣多个ReduceTask来处理,处理的逻辑都⼀样MR程序中由谁来决定分区的数量,哪个阶段环节会开始往分区中写数据在Job提交的时候可以设置ReduceTask的数量ReduceTask的数量决定分区的编号默认有多少ReduceTask任务就会产⽣多少个分区在Map阶段的map⽅法中通过context.wirte()往外写数据的时候其实就是在往指定的分区中写数据了阐述MR中实现分区的思路默认情况下不指定分区数量就会有⼀个分区如果要指定分区,可以通过在Job提交的时候指定ReduceTask的数量来指定分区的数量从Map端处理完数据后,数据就会被溢写到指定的分区中决定kv数据究竟写到哪个分区中是通过Hadoop提供的Partitioner对象控制的Partitioner对象默认实现HashPartitioner类它的规则就是⽤当前写出数据的key和ReduceTask的数量做取余操作,得到的结果就是当前数据要写⼊的分区的编号除此之外,我们也可以⾃定义分区器对象需要继承Hadoop提供的Partitioner对象,然后重写getPartitioner()⽅法在该⽅法中根据⾃⼰的业务实现分区编号的返回最后再将我们⾃定义的分区器对象设置到Job提交的代码中覆盖默认的分区规则Hadoop中实现排序的两种⽅案分别是什么第⼀种⽅式是直接让参与⽐较的对象实现WritableComparable接⼝并指定泛型接下来实现CompareTo()⽅法,在该⽅法中实现⽐较规则即可第⼆种⽅式是⾃定义⽐较器对象,需要继承WritableComparator类,重写它的compare⽅法在构造器中调⽤⽗类对当前的要参与⽐较的对象进⾏实例化当前要参与⽐较的对象必须要实现WritableComparable接⼝最后在Job提交代码中将⾃定义的⽐较器对象设置到Job中就可以了编写MR的时候什么情况下使⽤Combiner,实现的具体流程是什么Combiner在MR中是⼀个可选流程,通常也是⼀种优化⼿段当我们执⾏完Map阶段的计算后数据量⽐较⼤,kv组合过多这样在Reduce阶段执⾏的时候会造成拷贝⼤量的数据以及汇总更多的数据为了减轻Reduce的压⼒,此时可以选择在Map阶段进⾏Combiner操作,将⼀些汇总⼯作提前进⾏OutputFormat⾃定义实现流程OutputFormat是MR中最后⼀个流程,它主要负责数据最终结果的写出如果对最终输出结果⽂件的名称或者输出路径有个性化需求,就可以通过⾃定义OutputFormat来实现⾸先⾃定义⼀个OutputFormat类,然后继承OutputFormat重写OutputFormat的getRecordWriter()⽅法,在该⽅法中返回RecordWriter对象由于RecordWriter是Hadoop内部对象,如果我们想实现⾃⼰的逻辑,还得⾃定义⼀个RecordWriter类,然后继承RecordWriter类重写该类中的write()⽅法和close()⽅法MR实现MapJoin的思路,MapJoin的局限性是什么Mapjoin解决了数据倾斜给Reduce阶段带来的问题⾸先MapJoin的前提就是我们需要join的两个⽂件⼀个是⼤⽂件,⼀个是⼩⽂件在此前提下,我们可以将⼩的⽂件提前缓存到内存中,然后让Map端直接处理⼤⽂件每处理⼀⾏数据就根据当前的关联字段到内存中获取想要的数据,然后将结果写出。


hadoop知识点一、Hadoop简介Hadoop是一个开源的分布式计算系统,由Apache基金会开发和维护。
它能够处理大规模数据集并存储在集群中的多个节点上,提供高可靠性、高可扩展性和高效性能。
Hadoop主要包括两个核心组件:Hadoop Distributed File System(HDFS)和MapReduce。
二、HDFS1. HDFS架构HDFS是一个分布式文件系统,它将大文件分割成多个块并存储在不同的节点上。
它采用主从架构,其中NameNode是主节点,负责管理整个文件系统的命名空间和访问控制;DataNode是从节点,负责存储实际数据块。
2. HDFS特点HDFS具有以下特点:(1)适合存储大型文件;(2)数据冗余:每个数据块都会复制到多个节点上,提高了数据可靠性;(3)流式读写:支持一次写入、多次读取;(4)不适合频繁修改文件。
三、MapReduce1. MapReduce架构MapReduce是一种编程模型,用于处理大规模数据集。
它将任务分为两个阶段:Map阶段和Reduce阶段。
Map阶段将输入数据划分为若干组,并对每组进行处理得到中间结果;Reduce阶段将中间结果进行合并、排序和归约,得到最终结果。
2. MapReduce特点MapReduce具有以下特点:(1)适合处理大规模数据集;(2)简化了分布式计算的编程模型;(3)可扩展性好,可以在数百甚至数千台服务器上运行。
四、Hadoop生态系统1. Hadoop Common:包含Hadoop的基本库和工具。
2. HBase:一个分布式的、面向列的NoSQL数据库。
3. Hive:一个数据仓库工具,可以将结构化数据映射成HiveQL查询语言。
4. Pig:一个高级数据流语言和执行框架,用于大规模数据集的并行计算。
5. ZooKeeper:一个分布式协调服务,用于管理和维护集群中各个节点之间的状态信息。
五、Hadoop应用场景1. 日志分析:通过Hadoop收集、存储和分析日志数据,帮助企业实现对用户行为的监控和分析。

hadoop学习笔记(⼗):hdfs在命令⾏的基本操作命令(包括⽂件的上传和下载和
hdfs。
hdfs命令⾏
(1)查看帮助
hdfs dfs -help
(2)查看当前⽬录信息
hdfs dfs -ls /
(3)上传⽂件
hdfs dfs -put /本地路径 /hdfs路径
(4)剪切⽂件
hdfs dfs -moveFromLocal a.txt /aa.txt
(5)下载⽂件到本地
hdfs dfs -get /hdfs路径 /本地路径
(6)合并下载
hdfs dfs -getmerge /hdfs路径⽂件夹 /合并后的⽂件
(7)创建⽂件夹
hdfs dfs -mkdir /hello
(8)创建多级⽂件夹
hdfs dfs -mkdir -p /hello/world
(9)移动hdfs⽂件
hdfs dfs -mv /hdfs路径 /hdfs路径
(10)复制hdfs⽂件
hdfs dfs -cp /hdfs路径 /hdfs路径
(11)删除hdfs⽂件
hdfs dfs -rm /aa.txt
(12)删除hdfs⽂件夹
hdfs dfs -rm -r /hello
(13)查看hdfs中的⽂件
hdfs dfs -cat /⽂件
hdfs dfs -tail -f /⽂件
(14)查看⽂件夹中有多少个⽂件
hdfs dfs -count /⽂件夹
(15)查看hdfs的总空间
hdfs dfs -df /
hdfs dfs -df -h /
(16)修改副本数
hdfs dfs -setrep 1 /a.txt。

黑马程序员hadoop笔记Hadoop是当前最流行的大数据处理框架之一,具备高可靠性、高扩展性和高效性等特点。
本文将全面介绍Hadoop的相关内容,包括其基本概念、架构设计、应用场景以及使用方法等。
1. Hadoop的基本概念Hadoop是一个开源的分布式计算平台,其核心由Hadoop分布式文件系统(HDFS)和MapReduce计算框架组成。
HDFS采用主从架构,支持海量数据的分布式存储和处理;MapReduce则是一种分布式计算模型,提供了高效的数据处理能力。
2. Hadoop的架构设计Hadoop采用了分布式存储和计算的架构设计,主要包括主节点(NameNode)和多个工作节点(DataNode)组成。
主节点负责管理整个系统的元数据信息,存储在内存中,而工作节点则负责存储和计算任务的执行。
3. Hadoop的应用场景Hadoop广泛应用于大规模数据处理和分析领域。
它可以处理各种类型的数据,包括结构化数据、半结构化数据和非结构化数据等。
常见的应用场景包括日志分析、推荐系统、搜索引擎和数据仓库等。
4. Hadoop的使用方法使用Hadoop进行数据处理通常需要编写MapReduce程序,它由Mapper和Reducer两个组件组成。
Mapper负责将输入数据切分成若干键值对,然后执行相应的逻辑处理;Reducer负责对Mapper的输出结果进行归纳和聚合。
在编写MapReduce程序时,我们需要定义数据的输入和输出路径,并指定Mapper和Reducer的逻辑处理方式。
通过Hadoop提供的命令行工具和API,可以方便地操作Hadoop集群,提交任务并监控任务的执行状态。
本文对Hadoop的概念、架构设计、常见应用场景和使用方法进行了简要介绍。
Hadoop作为一种强大的大数据处理框架,具备高可靠性和高扩展性,适用于处理大规模数据和复杂计算任务。
通过深入学习和掌握Hadoop的知识,我们可以更好地应对现实中的数据挑战,并开展相关的数据分析和应用开发工作。

Hadoop+Ubuntu 学习笔记——IT 进行时(zhengxianquan AT )环备一、境准Hadoop-0.20.1Ubuntu 9.10二、安装JDK6开终执打端,行以下命令:sudo apt-get install sun-java6-jdk按照提示做就是了。
配置JAVA 环变境量:sudo gedit /etc/environment在其中添加如下两行:CLASSPATH=.:/usr/lib/jvm/java-6-sun/libJAVA_HOME=/usr/lib/jvm/java-6-sun执行命令:sudo gedit /etc/jvm,在最前面加入:/usr/lib/jvm/java-6-sun三、配置SSH见方便起,新增hadoop 组户的及其同名用:zhengxq@zhengxq-desktop:~$ sudo addgroup hadoopzhengxq@zhengxq-desktop:~$ sudo adduser --ingroup hadoop hadoop 别则请接下来需要做些特的工作(否参考FAQ“xx is not in the sudoers file”): hadoop@zhengxq-desktop:~$ suroot@zhengxq-desktop:/home/hadoop# ls -l /etc/sudoers-r--r----- 1 root root 557 2009-11-10 22:01 /etc/sudoersroot@zhengxq-desktop:/home/hadoop# chmod u+w /etc/sudoersroot@zhengxq-desktop:/home/hadoop# ls -l /etc/sudoers-rw-r----- 1 root root 557 2009-11-10 22:01 /etc/sudoersroot@zhengxq-desktop:/home/hadoop# gedit /etc/sudoers在root ALL=(ALL) ALL后面添加:hadoop ALL=(ALL) ALLroot@zhengxq-desktop:/home/hadoop# chmod u-w /etc/sudoersroot@zhengxq-desktop:/home/hadoop# exit安装openssh-server:$ sudo apt-get install openssh-server建立SSH KEY:zhengxq@zhengxq-desktop:~$ su hadoophadoop@zhengxq-desktop:/home/zhengxq$ ssh-keygen -t rsa -P ""Generating public/private rsa key pair.Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):Created directory '/home/hadoop/.ssh'.Your identification has been saved in /home/hadoop/.ssh/id_rsa.Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.The key fingerprint is:f4:5f:6a:f4:e5:bf:1d:c8:08:28:1c:88:b4:31:4a:a0 hadoop@zhengxq-desktop ……启用SSH KEY:hadoop@zhengxq-desktop:~$ cat $HOME/.ssh/id_rsa.pub >>$HOME/.ssh/authorized_keyshadoop@zhengxq-desktop:~$ sudo /etc/init.d/ssh reload* Reloading OpenBSD Secure Shell server's configuration sshd [ OK ]验证SSH的配置:hadoop@zhengxq-desktop:~$ ssh localhostThe authenticity of host 'localhost (::1)' can't be established.RSA key fingerprint is 52:9b:e2:62:93:01:88:e6:46:a8:16:68:52:91:8a:ea.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'localhost' (RSA) to the list of known hosts.Linux zhengxq-desktop 2.6.31-14-generic #48-Ubuntu SMP Fri Oct 1614:04:26 UTC 2009 i686……四、安装配置hadoop下及安装4.1载下一个0.20.1版本;到/dyn/closer.cgi/hadoop/core/载下,并改所有者hadoop:tar压缩或者直接解到/usr/local/hadoop/变为zhengxq@zhengxq-desktop:/usr/local$ sudo chown -R hadoop:hadoop hadoop4.2配置4.2.1配置$HADOOP_HOME/conf/hadoop-env.shzhengxq@zhengxq-desktop:/usr/local/hadoop$ cd had*zhengxq@zhengxq-desktop:/usr/local/hadoop/hadoop-0.20.1$ gedit conf/hadoop-env.shzhengxq@zhengxq-desktop:/usr/local/hadoop/hadoop-0.20.1$ sudo geditconf/hadoop-env.sh修改点:为export JAVA_HOME=/usr/lib/jvm/java-6-sun4.2.2配置$HADOOP_HOME/conf/core-site.xmlzhengxq@zhengxq-desktop:/usr/local/hadoop/hadoop-0.20.1$ sudo geditconf/core-site.xml空的,内容加上:<property><name></name><value>hdfs://localhost:9000</value></property><property><name>dfs.replication</name><value>1</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/tmp</value></property></property>注:如没有配置hadoop.tmp.dir时统认临时录为参数,此系默的目:/tmp/hadoop-才行,否会出。

Hadoop实训个人总结与收获引言Hadoop作为大数据处理的核心技术之一,在当前的数据驱动时代扮演了至关重要的角色。
通过参加Hadoop实训,我全面、深入地学习了Hadoop的核心概念、架构和使用方法,并通过实际操作加深了对Hadoop的理解和实践能力。
本文将对我在Hadoop实训中的重要观点、关键发现和进一步思考进行总结。
重要观点Hadoop的核心概念在实训中,我深入学习了Hadoop的核心概念,包括Hadoop分布式文件系统(HDFS)、MapReduce编程模型和YARN资源管理器。
这些核心概念是构建大规模数据处理系统的基础。
HDFS作为一个高容错性的分布式文件系统,可以将大规模数据存储在多个节点上,实现数据的可靠性和高可用性。
MapReduce编程模型则为并行处理大规模数据提供了一个简单而有效的框架,通过将任务分解为多个Map和Reduce阶段,实现了高效的数据处理和计算。
YARN资源管理器则实现了对集群资源的高效调度和分配,提供了更好的资源利用率。
Hadoop生态系统Hadoop不仅仅是一个单独的分布式计算框架,还构建了一个完整的生态系统,涵盖了各种数据处理和存储技术。
在实训中,我接触了一些Hadoop生态系统的重要组件,如HBase、Hive、Sqoop和Flume等。
这些组件分别承担了数据存储、数据仓库、数据导入和数据流等不同的角色。
通过熟悉这些组件的使用方法,我进一步掌握了构建大数据处理系统的能力。
大数据处理的挑战与解决方案实训中,我也认识到了大数据处理所面临的挑战,如数据规模庞大、数据类型多样、数据质量参差不齐等。
面对这些挑战,我们需要采取相应的解决方案。
在Hadoop 中,可以通过横向扩展集群来应对数据规模扩大的需求,通过数据预处理和清洗来提高数据质量,通过多样化的基于Hadoop的工具来处理不同类型的数据。
关键发现分布式计算的优势通过实训,我深刻认识到分布式计算的优势。
分布式计算充分利用了集群中多台计算机的计算能力,将任务分解成多个子任务并行处理,从而显著提高了计算速度和效率。

hadoop学习心得Hadoop是一个开源的分布式计算框架,用于处理大规模数据集的存储和分析。
在学习Hadoop的过程中,我深刻体味到了它的强大功能和灵便性。
以下是我对Hadoop学习的心得体味。
首先,Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)和MapReduce计算模型。
HDFS是一个可靠性高、可扩展性好的分布式文件系统,它将大规模数据集分散存储在多个计算节点上,实现了数据的冗余备份和高效的并行读写。
MapReduce是一种编程模型,用于将大规模数据集分解为小的数据块,并在分布式计算集群上进行并行处理。
通过将计算任务分发到不同的计算节点上,MapReduce能够高效地处理大规模数据集。
其次,Hadoop生态系统提供了许多与Hadoop集成的工具和框架,如Hive、Pig、HBase和Spark等。
这些工具和框架扩展了Hadoop的功能,使得我们能够更方便地进行数据分析和处理。
例如,Hive是一个基于Hadoop的数据仓库基础设施,它提供了类似于SQL的查询语言,使得我们能够以简单的方式进行数据查询和分析。
Pig是一个用于数据分析的高级编程语言,它提供了一套简化的操作符,使得我们能够更轻松地进行数据转换和处理。
HBase是一个分布式的、可扩展的NoSQL数据库,它提供了高速的随机读写能力,适合于存储海量的结构化数据。
Spark是一个快速而通用的集群计算系统,它提供了丰富的API,支持多种编程语言,并能够在内存中高效地进行数据处理。
再次,通过实践和项目应用,我发现Hadoop在大数据处理方面具有许多优势。
首先,Hadoop能够处理海量的数据,能够轻松地处理TB级别甚至PB级别的数据集。
其次,Hadoop具有高可靠性和容错性。
由于数据存储在多个计算节点上,并且备份了多个副本,即使某个节点发生故障,数据仍然可靠地保留在其他节点上。
此外,Hadoop还具有高扩展性和高性能。
我们可以根据需求增加计算节点的数量,从而实现更高的计算能力和处理速度。

hadoop复习资料大全Hadoop复习资料大全在当今信息爆炸的时代,数据已经成为了一种宝贵的资源。
然而,要处理和分析海量的数据并从中获取有用的信息是一项复杂而困难的任务。
这就是为什么Hadoop这样的大数据处理框架变得如此重要和流行的原因之一。
作为一个开源的分布式系统,Hadoop提供了一种可靠和高效地处理大规模数据的方法。
对于那些希望深入了解和掌握Hadoop的人来说,复习资料是必不可少的。
一、Hadoop的基础知识要理解Hadoop的工作原理和基本概念,首先需要掌握一些基础知识。
这包括Hadoop的核心组件,如Hadoop分布式文件系统(HDFS)和MapReduce。
此外,还需要了解Hadoop的架构,包括主节点(NameNode)和从节点(DataNode)之间的交互方式。
二、Hadoop生态系统除了核心组件外,Hadoop还有一个庞大而丰富的生态系统。
这个生态系统包括各种工具和技术,用于处理和分析大规模数据。
其中一些工具包括Hive、Pig、HBase和Sqoop等。
每个工具都有其独特的功能和用途,掌握它们可以帮助我们更好地利用Hadoop的能力。
三、Hadoop的安装和配置要使用Hadoop,首先需要将其安装和配置在自己的机器上。
这可能是一个有些复杂的过程,因为Hadoop有很多配置选项和参数需要设置。
因此,掌握正确的安装和配置过程是非常重要的。
有很多在线教程和指南可以帮助你完成这个过程,你可以找到一些详细的步骤和说明。
四、Hadoop的性能调优一旦你安装和配置好了Hadoop,接下来就是优化它的性能。
Hadoop的性能调优是一个复杂的过程,需要细致的分析和调整。
这包括调整Hadoop的配置参数,优化数据存储和访问方式,以及使用适当的算法和技术来处理数据。
了解这些技巧和技术可以帮助你更好地利用Hadoop的潜力。
五、Hadoop的安全性和故障恢复在处理大规模数据时,安全性和故障恢复是非常重要的考虑因素。
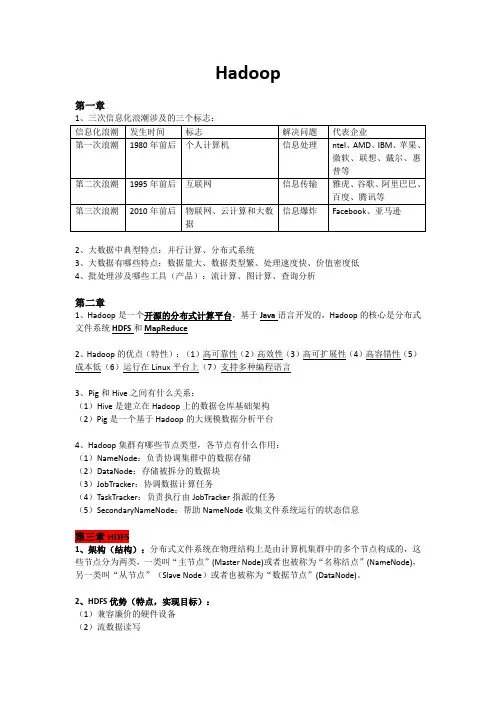
Hadoop第一章2、大数据中典型特点:并行计算、分布式系统3、大数据有哪些特点:数据量大、数据类型繁、处理速度快、价值密度低4、批处理涉及哪些工具(产品):流计算、图计算、查询分析第二章1、Hadoop是一个开源的分布式计算平台,基于Java语言开发的,Hadoop的核心是分布式文件系统HDFS和MapReduce2、Hadoop的优点(特性):(1)高可靠性(2)高效性(3)高可扩展性(4)高容错性(5)成本低(6)运行在Linux平台上(7)支持多种编程语言3、Pig和Hive之间有什么关系:(1)Hive是建立在Hadoop上的数据仓库基础架构(2)Pig是一个基于Hadoop的大规模数据分析平台4、Hadoop集群有哪些节点类型,各节点有什么作用:(1)NameNode:负责协调集群中的数据存储(2)DataNode:存储被拆分的数据块(3)JobTracker:协调数据计算任务(4)TaskTracker:负责执行由JobTracker指派的任务(5)SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息第三章HDFS1、架构(结构):分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)。
2、HDFS优势(特点,实现目标):(1)兼容廉价的硬件设备(2)流数据读写(3)大数据集(4)简单的文件模型(5)强大的跨平台兼容性3、HDFS局限性:(1)不适合低延迟数据访问(2)无法高效存储大量小文件(3)不支持多用户写入及任意修改文件4、“块”默认大小为64MB5、HDFS采用“块”有什么好处:(1)支持大规模文件存储:文件以块为单位进行存储,一个大规模文件可以被分拆成若干个文件块,不同的文件块可以被分发到不同的节点上,因此,一个文件的大小不会受到单个节点的存储容量的限制,可以远远大于网络中任意节点的存储容量(2)简化系统设计:首先,大大简化了存储管理,因为文件块大小是固定的,这样就可以很容易计算出一个节点可以存储多少文件块;其次,方便了元数据的管理,元数据不需要和文件块一起存储,可以由其他系统负责管理元数据(3)适合数据备份:每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性6、namenode和datanode存储了什么功能(1)Namenode:负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog。
大数据专业学习笔记分享在当今的信息化时代,数据成为了重要的经济资源。
大数据也因此成为了一个热门的行业,越来越多的人选择学习和从事大数据相关的工作。
本篇文章将分享我在学习大数据专业时的笔记和经验。
一、基础知识1.1 数据结构数据结构是大数据中最基础的知识点。
掌握数据结构对于学习大数据有非常重要的作用,因为大数据是基于庞大量的数据运算和存储的。
1.2 编程语言编程语言是学习大数据必备的技能之一,常见的编程语言有Python、Java、Scala等。
在学习时需要掌握语言的基本语法和操作方式,熟练掌握编程语言后还需要学习各种开源工具和框架的使用。
二、大数据工具和框架2.1 HadoopHadoop是大数据处理中的重要工具,它可以处理结构化和非结构数据,并且可以实现分布式处理。
学会使用Hadoop可以带来更高效的大数据处理和管理。
2.2 SparkSpark是处理大规模数据处理的一种模型,具有处理速度快,容易扩展等优点,而且还可以处理实时流数据。
学会使用Spark能够更加灵活的处理海量数据。
2.3 HiveHive是一种针对Hadoop的工具,它可以将基于SQL的语法转换成存储在Hadoop上的MapReduce程序。
学习使用Hive需要对于SQL语句有一定的了解。
三、数据挖掘3.1 数据清洗大数据中可能存在噪声、重复、空缺等问题,所以数据清洗是处理大数据的第一步。
在处理大数据前,我们需要对数据进行清晰、格式化,确保数据能够被正确识别和使用。
3.2 数据预处理数据预处理是一项重要的工作,它包括数据标准化、统计、聚类等处理。
数据预处理是为后续的分析工作打下重要的基础。
3.3 数据挖掘算法数据挖掘算法涵盖了大量的数学理论。
学会使用算法能够有效地处理数据,比如聚类算法、分类算法、关联规则挖掘等。
四、机器学习4.1 监督学习监督学习的基础是训练数据集和测试数据集。
学习监督学习需要了解SVM、决策树、朴素贝叶斯等算法。
Hadoop大数据开发基础笔记一、概述随着互联网和信息技术的迅猛发展,大数据技术已成为当前热门的领域之一。
Hadoop作为大数据处理领域的重要工具,对于开发者来说是必须掌握的技能之一。
本文将从Hadoop的概念、架构、组件以及基本操作等方面进行系统的介绍和总结,帮助读者快速掌握Hadoop大数据开发的基础知识。
二、Hadoop概述1. Hadoop的概念Hadoop是一个开源的分布式存储和计算评台,最初是由Apache基金会开发的。
它能够处理海量数据,并提供高性能的分布式数据存储和处理能力。
Hadoop的核心是HDFS(Hadoop分布式文件系统)和MapReduce(分布式计算框架),它们共同构成了Hadoop评台的基础架构。
2. Hadoop的特点Hadoop具有高可靠性、高可扩展性和高效能处理大规模数据的能力。
它支持海量数据的存储和处理,并且能够快速地处理数据,从而为用户提供快速的数据分析和挖掘能力。
三、Hadoop架构1. Hadoop的架构组成Hadoop的架构分为HDFS和MapReduce两部分。
其中,HDFS负责数据的存储和管理,而MapReduce负责数据的计算和处理。
另外,Hadoop还包括了YARN(资源调度和管理),这是最新版本中引入的资源管理框架,它为Hadoop提供了更好的资源管理和任务处理能力。
2. Hadoop的工作流程Hadoop的工作流程包括数据的存储、计算和结果的输出等基本步骤。
数据被分割成小的块并存储在HDFS中,然后MapReduce框架将数据分发给不同的计算节点进行处理,最后将处理结果输出到HDFS中。
四、Hadoop组件1. HDFSHDFS是Hadoop分布式文件系统的简称,它是Hadoop的核心组成部分之一。
HDFS采用主从架构,包括一个NameNode节点和多个DataNode节点。
NameNode负责管理文件系统的命名空间和数据块的映射信息,而DataNode负责实际的数据存储。
Hadoop集群环境搭建1、准备资料虚拟机、Redhat6.5、hadoop-1.0.3、jdk1.62、基础环境设置2.1配置机器时间同步#配置时间自动同步crontab -e#手动同步时间/usr/sbin/ntpdate 1、安装JDK安装cd /home/wzq/dev./jdk-*****.bin设置环境变量Vi /etc/profile/java.sh2.2配置机器网络环境#配置主机名(hostname)vi /etc/sysconfig/network#修第一台hostname 为masterhostname master#检测hostname#使用setup 命令配置系统环境setup#检查ip配置cat /etc/sysconfig/network-scripts/ifcfg-eth0#重新启动网络服务/sbin/service network restart#检查网络ip配置/sbin/ifconfig2.3关闭防火墙2.4配置集群hosts列表vi /etc/hosts#添加一下内容到vi 中2.5创建用户账号和Hadoop部署目录和数据目录#创建hadoop 用户/usr/sbin/groupadd hadoop#分配hadoop 到hadoop 组中/usr/sbin/useradd hadoop -g hadoop#修改hadoop用户密码Passwd hadoop#创建hadoop 代码目录结构mkdir -p /opt/modules/hadoop/#修改目录结构权限拥有者为为hadoopchown -R hadoop:hadoop /opt/modules/hadoop/2.6生成登陆密钥#切换到Hadoop 用户下su hadoopcd /home/hadoop/#在master、node1、node2三台机器上都执行下面命令,生成公钥和私钥ssh-keygen -q -t rsa -N "" -f /home/hadoop/.ssh/id_rsacd /home/hadoop/.ssh#把node1、node2上的公钥拷贝到master上scp /home/hadoop/.ssh/ id_rsa.pub hadoop@master:/home/hadoop/.ssh/node1_pubkey scp /home/hadoop/.ssh/ id_rsa.pub hadoop@master:/home/hadoop/.ssh/node2_pubkey#在master上生成三台机器的共钥cp id_rsa.pub authorized_keyscat node1_pubkey >> authorized_keyscat node2_pubkey >> authorized_keysrm node1_pubkey node2_pubkey#吧master上的共钥拷贝到其他两个节点上scp authorized_keys node1: /home/hadoop/.ssh/scp authorized_keys node1: /home/hadoop/.ssh/#验证ssh masterssh node1ssh node2没有要求输入密码登陆,表示免密码登陆成功3、伪分布式环境搭建3.1下载并安装JAVA JDK系统软件#下载jdkwget http://60.28.110.228/source/package/jdk-6u21-linux-i586-rpm.bin#安装jdkchmod +x jdk-6u21-linux-i586-rpm.bin./jdk-6u21-linux-i586-rpm.bin#配置环境变量vi /etc/profile.d/java.sh#手动立即生效source /etc/profile3.2 Hadoop 文件下载和安装#切到hadoop 安装路径下cd /opt/modules/hadoop/#从 下载Hadoop 安装文件wget /apache-mirror/hadoop/common/hadoop-1.0.3/hadoop-1.0.3.tar.gz#如果已经下载,请复制文件到安装hadoop 文件夹cp hadoop-1.0.3.tar.gz /opt/modules/hadoop/#解压hadoop-1.0.3.tar.gzcd /opt/modules/hadoop/tar -xvf hadoop-1.0.3.tar.gz#配置环境变量vi /etc/profile.d/java.sh#手动立即生效source /etc/profile3.3配置hadoop-env.sh 环境变量#配置jdk。
Hadoop学习第一章初识Hadoop分布式计算平台—核心—>HDFS(分布式文件系统)和MapReduce(Google MR开源实现)作用:有效存储和管理大数据优势:* 高可靠按位存储和处理数据能力高* 高扩展使用计算机集簇分配数据并计算,集簇便扩展* 高效能在节点间动态移动数据,并保持个节点动态平衡,故处理速度极快* 高容错能自动保存数据的多副本,自动将失败任务重新分配结构:Pig Chukwa Hive HBase核心MapReduce HDFS ZooKeeper基础API Core Avro* Core 提供常用工具API*Avro 数据序列化系统提供数据结构类型、快可压二进制格式、存储文件集简单调用语言*MapReduce 并行*HDFS 分布式文件系统*Chukwa 数据收集*Hive 整理、存储查询数据集工具支持传统RDBMS的SQL语句查询*HBase 分布式、面向列的开源数据库适合存储非结构化数据基于列模式*Pig 经受住大数据处理的平台体系:*HDFS 分布式底层存储支持主从模式NameNode和DataNode一对多NN 主服务器,管理文件系统及客户对其的操作DN 管理存储数据,受NameNode调度进行相应操作,1文件1组DateNode 关系图如下*MapReduce 分布式并行任务处理支持并行编程模式,将任务分发到多台机器的集群上,以高容错方式并行处理大数据集的框架主节点JobTracker集节点TaskTracker数据管理:* HDFS数据管理NameNode-DataNode-Client补充:一个Block会有三份备份;写入文件时,客户端读取一个Block,然后写到第一个DataNode上,接着备份至其他DataNode,知道所有需要此Block的DataNode都成功写入才写下一个Block* HBase数据管理HClient-HMaste-HRgionr 结构图Table & Column FamilyRow Key TimestampColumn FamilyURI Parserr1 t3 url= title=天天特价t2 host=t1r2t5 url= content=每天…t4 host=Ø Row Key: 行键,Table的主键,Table中的记录按照Row Key排序Ø Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version numberØ Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family 中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
第⼀章之初识Hadoop笔记数据存储与分析要实现对多个磁盘数据的并⾏读写需要解决的很多问题1 硬件故障问题。
硬件多了,发⽣故障的概率变⼤。
避免数据丢失的是备份。
RAID(冗余磁盘阵列),HDFS2 ⼤多数分析任务需要以某种⽅式结合⼤部分数据共同完成分析任务,⼀个磁盘读取得数据可能需要和另外的99个磁盘中读取的数据结合使⽤,各种分布式系统允许结合多个来源的数据并实现分析,但保证其正确性是⼀个很⼤的挑战,MapReduce提出⼀个编程模型,该模型将上述磁盘读写问题进⾏抽象,转换为⼀个对数据集(由键/值对组成)的计算。
该计算由map和reduce两部分组成,⽽只有这两部分提供对外的接⼝。
与HDFS类似,MapReduce⾃⾝也有较⾼的可靠性。
与其它系统⽐mapreduce 每个查询⾄少处理整个数据集或者数据集的很⼤部分。
改变了对传统数据的看法,对存放在磁带什么上⾯的数据赋予了创新的机会。
关系型数据库管理系统,为什么使⽤mapreduce(1)磁盘的发展:寻址(将磁头移动到特定磁盘位置进⾏读写操作的过程)是导致磁盘操作延迟的主要原因,⽽传输速率取决于磁盘的带宽。
如果数据访问存在⼤量寻址,那么读取⼤量数据集的时间更长。
(2)如果数据库更新的话,只更新⼀⼩部分,那么传统的B树(关系数据库的结构,受限于寻址的⽐例)更有优势,但是数据库更新⼤量数据的时候,B树效率会⽐MapReduce低很多,因为需要使⽤ “排序/合并”(sort/merge)来重建数据库。
(3)结构化程度不同的数据的处理。
结构化(数据的格式如XML),半结构化(数据松散,可能有格式,但总被忽略,例如电⼦表格),⾮结构化(没有内部结构,⽂本图像什么的).Mapduce 对⾮结构化和半结构化的处理有效,因为在处理数据的时候才对数据进⾏解释,MapReduce输⼊的键和值并不是数据固有的属性,由分析⼈员选择的。
关系型数据库规范,为了保证完整不冗余,mapreduce的核⼼假设之⼀就是它可以进⾏⾼速的流式读写操作。
hadoop实训个人总结与收获一、前言Hadoop是一个开源的分布式计算系统,可以处理大规模数据。
在Hadoop实训中,我学习了如何使用Hadoop进行数据处理和分析,同时也深入了解了Hadoop的原理和架构。
二、Hadoop实训内容1. Hadoop基础知识:学习了Hadoop的基本概念、架构和组成部分,包括HDFS、MapReduce等。
2. HDFS操作:学习了如何在HDFS上进行文件读写、权限控制等操作。
3. MapReduce编程:学习了MapReduce编程的基本原理和实现方法,并通过编写WordCount程序等练习加深理解。
4. Hive使用:学习了如何使用Hive进行SQL查询,以及如何将数据导入到Hive中进行查询和分析。
5. Pig使用:学习了Pig语言的基本语法和使用方法,并通过编写Pig程序完成数据清洗和分析。
三、收获与体会1. 理论与实践相结合更加有效。
通过实际操作,在理解原理的基础上更加深入地掌握了Hadoop的应用场景和技术特点。
2. 团队协作能力得到提升。
在实训过程中,我们需要相互配合完成任务,这锻炼了我们的团队协作能力和沟通能力。
3. 解决问题的能力得到提高。
在实训中,我们遇到了各种各样的问题,需要通过自己的思考和搜索解决。
这锻炼了我们的问题解决能力和自主学习能力。
4. 对大数据技术有了更深入的认识。
通过学习Hadoop,我更加深入地认识到大数据技术对于企业发展的重要性,也对大数据技术的未来发展有了更多思考。
四、总结Hadoop实训是一次非常有价值的学习经历。
通过实际操作,我掌握了Hadoop相关技术,并提高了团队协作能力、问题解决能力和自主学习能力。
同时,我也对大数据技术有了更深入的认识和理解。
希望今后可以继续深入学习和应用大数据技术,为企业发展做出贡献。
Hadoop在Hadoop上运行MapReduce命令实验jar:WordCount.jar运行代码:root/……/hadoop/bin/hadoop jar jar包名称使用的包名称input(输入地址) output(输出地址)生成测试文件:echo -e "aa\tbb \tcc\nbb\tcc\tdd" > ceshi.txt输入地址:/data2/u_lx_data/qiandongjun/eclipse/crjworkspace/input输出地址:/data2/u_lx_data/qiandongjun/eclipse/crjworkspace/output将测试文件转入输入文件夹:Hadoop fs -put ceshi.txt /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/input/ceshi.txt运行如下代码:hadoop jar /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/WordCount.jar WordCount /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/input/ceshi.txt/data2/u_lx_data/qiandongjun/eclipse/crjworkspace/outputHadoop架构1、HDFS架构2、MapReduce架构HDFS架构(采用了Master/Slave 架构)1、Client --- 文件系统接口,给用户调用2、NameNode --- 管理HDFS的目录树和相关的的文件元数据信息以及监控DataNode的状态。
信息以“fsimage”及“editlog”两个文件形势存放3、DataNode --- 负责实际的数据存储,并将数据定期汇报给NameNode。
每个节点上都安装一个DataNode4、Secondary NameNode --- 定期合并fsimage和edits日志,并传输给NameNode(存储基本单位为block)MapReduce架构(采用了Master/Slave 架构)1、Client --- 提交MapReduce 程序并可查看作业运行状态2、JobTracker --- 资源监控和作业调度3、TaskTracker --- 向JobTracker汇报作业运行情况和资源使用情况(周期性),并同时接收命令执行操作4、Task --- (1)Map Task (2)Reduce Task ——均有TaskTracker启动MapReduce处理单位为split,是一个逻辑概念split的多少决定了Map Task的数目,每个split交由一个Map Task处理Hadoop MapReduce作业流程及生命周期一共5个步骤1、作业提交及初始化。
JobClient将作业相关上传到HDFS上,然后通过RPC通知JobTracker,JobTracker 接收到指令后通过调度模块对作业初始化。
JobInProgressTaskInProgress2、 任务调度与监控。
一出现空白资源,JobTracker 会选择一个合适的任务使用空白资源。
任务调度器(双层结构),首先选择作业再选择作业中的任务(重点考虑数据本地行)。
当TaskTracker 或Task 失败时,转移计算任务 当某Task 计算远落后于其他时,再给一个Task ,取计算较快的结果。
3、 任务运行环境准备。
JVM 的启动和资源隔离,均由TaskTracker 实现。
(每个Task 启动一个独立的JVM )4、 任务执行。
准备好环境后,TaskTracker 便会启动Task 。
JobTracker 5、 作业完成。
MapReduce 编程接口体系接口在应用程序层和MapReduce 执行器之间,可以分为两层。
1、 Java API --- (1)InputFormat (2)Mapper (3)Partitioner (4)Reducer (5)OutputFormat用户只需(2),(4),其余hadoop 自带 2、 工具层,提供了4个编程工具包(1) JobControl (2) ChainMapper/ChainReducer (3) Hadoop Streaming (4) Hadoop Pipes为非java 编程 为c/c++用户MapReduce API — 序列化序列化是指将结构化对象转为字节流以便于通过网络进行传输或写入持久存储的过程,主要作用:永久存储和进程间通信。
管理员自定义配置文件:由管理员设置,定义一些新的配置属性或者覆盖系统默认配置文件中的默认值。
Hadoop 会优先加载Common 的两个配置文件。
配置文件中有3个配置参数:name(属性名)、value(属性值) 和description(属性描述) 此外,Hadoop 为配置文件添加了两个新的特性:final 参数和变量扩展。
final 参数:如果管理员不想让用户程序修改❑ 某些属性的属性值,可将该属性的final 参数置为true 。
变量扩展:当读取配置文件时,如果某个属性存在对其他属性的引用,则 Hadoop 首跟踪作业运行状况 为每个Task ,跟踪每个任务的运行状态先会查找引用的属性是否为下列两种属性之一。
如果是,则进行扩展。
①其他已经定义的属性。
②Java 中System.getProperties() 函数可获取属性。
Java API——MapReduce 作业配置1、环境配置。
环境配置由Hadoop 自动添加。
主要:mapreddefault.xml及mapred-site.xml2、用户自定义配置。
用户自定义配置则由用户自己根据作业特点个性化定制而成。
InputFormatInputFormat 主要用于描述输入数据的格式,它提供以下两个功能。
①数据切分:按照某个策略将输入数据切分成若干个split,以便确定Map Task 个数以及对应的split。
——getSplits 方法②为Mapper 提供输入数据:给定某个split,能将其解析成一个个key/value 对。
getSplits 方法:它会尝试着将输入数据切分成numSplits个InputSplit。
InputSplit:支持序列化操作主要是为了进程间通信。
当数据传送给map时,map会将输入分片传送到InputFormat,InputFormat则调用方法getRecordReader()生成RecordReader,RecordReader再通过creatKey()、creatValue()方法创建可供map处理的<key,value>对。
简而言之,InputFormat()方法是用来生成可供map处理的<key,value>对的。
FileInputFormat该函数实现中最核心的两个算法是文件切分算法和host 选择算法。
(1)文件切分算法如果想让InputSplit尺寸大于block尺寸,则直接增大配置参数mapred.min.split.size即可。
新版API中,InputSplit划分算法不再考虑Map Task个数,而用MaxSize代替(mapred.max.split.size)(2)host 选择算法为此,FileInputFormat 设计了一个简单有效的启发式算法:首先按照rack 包含的数据量对rack 进行排序,然后在rack 内部按照每个node 包含的数据量对node 排序,最后取前N 个node 的host 作为InputSplit 的host 列表,这里的N 为block副本数。
当使用基于FileInputFormat 实现InputFormat 时,为了提高Map Task 的数据本地性,应尽量使InputSplit 大小与block 大小相同。
OutputFormat主要用于描述输出数据的格式,它能够将用户提供的key/value 对写入特定格式的文件中Mapper &Reducer以Mapper为例:新版API:参数封装到Context中(良好扩展性);不再继承JobConfigurable和Closeable,直接添加setup和cleanup进行初始化和清理工作;PartitionerMapReduce 提供了两个Partitioner 实现:HashPartitioner 和TotalOrderPartitioner。
基于TotalOrderPartitioner 全排序的效率跟key 分布规律和采样算法有直接关系;key 值分布越均匀且采样越具有代表性,则Reduce Task 负载越均衡,全排序效率越高。
TotalOrderPartitioner两个典型实例:TeraSort 和HBase 批量数据导入。
JobControl原理JobControl由两个类组成:Job和JobControlJob类:Job 类封装了一个MapReduce 作业及其对应的依赖关系,主要负责监控各个依赖作业的运行状态,以此更新自己的状态。
如果一个作业的依赖作业失败,则该作业也会失败,后续所有作业均会失败。
JobControl类:JobControl 封装了一系列MapReduce 作业及其对应的依赖关系。
同时,它还提供了一些API 用于挂起、恢复和暂停该线程。
ChainMapper/ChainReducer主要为了解决线性链式Mapper 而提出的,在Map或Reduce阶段存在多个Mapper,它产生的结果写到最终的HDFS 输出目录中对于任意一个MapReduce 作业,Map 和Reduce 阶段可以有无限个Mapper,但Reducer 只能有一个。
Hadoop MapReduce 有一个约定,函数OutputCollector.collect(key, value) 执行期间不应改变key 和value 的值。
ChainMapper/ChainReducer实现原理关键技术点:修改Mapper 和Reducer 的输出流,将本来要写入文件的输出结果重定向到另外一个Mapper 中。
当用户调用addMapper 添加Mapper 时,可能会为新添加的每个Mapper 指定一个特有的JobConf,为此,ChainMapper/ChainReducer 将这些JobConf 对象序列化后,统一保存到作业的JobConf 中。
Hadoop工作流引擎在Hadoop 之上出现了很多开源的工作流引擎,主要可概括为两类:隐式工作流引擎和显式工作流引擎。