第4章数据的统计描述
- 格式:pptx
- 大小:840.13 KB
- 文档页数:78






青岛版数学七年级上册第4章《数据的收集、整理与描述》教学设计一. 教材分析《青岛版数学七年级上册》第4章《数据的收集、整理与描述》的内容包括数据的收集、整理、描述和分析。
这部分内容是学生初步接触数据分析的基础知识,通过这部分的学习,使学生了解数据收集和整理的方法,学会用图表和统计量描述数据,并能对数据进行分析,从而培养学生对数据的敏感性和数据分析能力。
二. 学情分析七年级的学生已经具备了一定的逻辑思维能力和数学基础,但对于数据的收集、整理和描述可能还比较陌生。
因此,在教学过程中,需要引导学生从实际问题中提出数学问题,培养学生的数据意识,同时,要注重学生动手操作和小组合作的能力。
三. 教学目标1.了解数据的收集、整理和描述的方法;2.学会使用图表和统计量描述数据;3.能对数据进行分析,培养数据分析能力;4.培养学生的数据意识和团队协作能力。
四. 教学重难点1.数据的收集和整理方法;2.图表和统计量的表示方法;3.数据分析的方法和技巧。
五. 教学方法采用问题驱动法、案例教学法和小组合作法。
通过实际问题引导学生提出数学问题,培养学生的问题解决能力;通过案例教学,使学生了解数据的收集、整理和描述的方法;通过小组合作,培养学生的团队协作能力。
六. 教学准备1.教学PPT;2.教学案例和数据;3.小组合作学习资料。
七. 教学过程1.导入(5分钟)通过一个实际问题,引导学生提出数学问题,激发学生的学习兴趣。
例如:某班有50名学生,男生和女生各有多少人?2.呈现(15分钟)呈现教学案例和数据,让学生观察和分析数据,引导学生思考如何收集和整理数据。
例如:某班学生的身高数据如下:165, 170, 168, 162, 167, 172, 164, 166, 163, 169, 165, 171, 168, 160, 166, 170, 167, 164, 165, 162, 169, 166, 172, 163, 168, 164, 167, 165, 171, 166, 170, 162, 164, 167, 163, 169, 165, 172, 168, 166, 171, 167, 164, 165, 163, 168, 164, 167, 165, 171, 166, 170, 162, 164, 167, 163, 169, 165, 172, 168, 166, 171, 167, 164, 165, 163, 168, 164, 167, 165, 171, 166, 170, 162, 164, 167, 163, 169, 165, 172, 168, 166, 171, 167, 164, 165, 163, 168, 164, 167, 165, 171, 166, 170, 162, 164, 167, 163, 169, 165, 172, 168, 166, 171, 167, 164, 165, 163, 168, 164, 167, 165, 171, 166, 170, 162, 164, 167,在完成《青岛版数学七年级上册》第4章《数据的收集、整理与描述》的教学设计后,进行课堂反思是十分重要的。
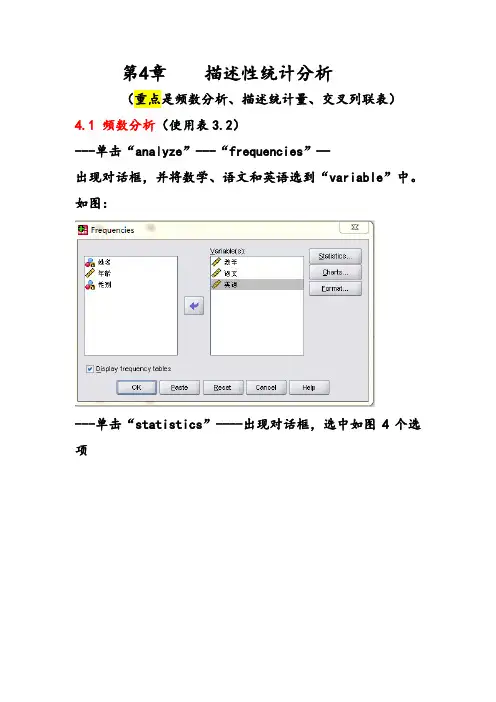
第4章描述性统计分析(重点是频数分析、描述统计量、交叉列联表)4.1 频数分析(使用表3.2)---单击“analyze”---“frequencies”—出现对话框,并将数学、语文和英语选到“variable”中。
如图:---单击“statistics”----出现对话框,选中如图4个选项-----单击“continue”回到前一对话框----单击“OK”结果如表4.1-----如图,重新选择语文---单击“charts”---得到一个对话框,如图选中2个选项----单击“continue”----回到前一对话框---单击“OK”。
结果如表4.24.2 基本描述统计量(使用表3.2)---单击“analyze”---“descriptive statistics”—“Descriptives”---得到对话框,并将数据进行如图选入:-----单击“options”—得到对话框,并选中如图6个选项:----单击“continue”----回到前一对话框---单击“OK”。
结果如表4.34.3 探索性分析(使用表3.2)---单击“analyze”---“descriptive statistics”—“Explore”---得到对话框,并将数据进行如图选入:----单击“Plots”—得到对话框,并选中如图4个选项:----单击“continue”----回到前一对话框---单击“OK”。
结果如表4.6(与书有不同)4.4交叉列联表分析(使用表化环0708)(1)T ransform(修改)----Recode into Different variable----选定身高------点击“向右箭头”------在“name”下写个名字:eg:T1-------change-------(此处T1和T2是已经做好的分组)点击-----old and new values对其分组---例:Range LOWEST through values :160 new values :1Rang :160 through :170 2Range HIGHEST through values :170 3 点击continue-----回到前一个对话框点击------OK同样的方法做好T2---------点击“analyze(分析)”-----“Descriptive Statistics(描述性统计)”------“Crosstabs(交叉列联表)”选中行列------点击“Exat….“则弹出“exct tests(精确检测)对话框”点“Statistics…”则弹出“Crosstabs:statistics(交叉表统计)对话框”-------点击“Chi—square(卡方检验)”----“continue”点“Cells…”则弹出“Crosstabs:Cells display(交叉表统计)对话框”-------选择“Counts”中的“Observed”和“Expected”为期望频数,-------选择“Percentages”中的“Row”“Column”“Total”选项,分别计算“频数”“列频数”“总频数”-------选择“Residuals”中的“Standardized”分别计算单元格的非标准化残差、标准化残差、调整后的残差----“continue”回到前一页点----“OK”4.5比率分析(课本71页)不需要掌握英语未写完作业:1-10,11-25,26-30。




第四章 静态指标分析法(一)一、填空题1、数据分布集中趋势的测度值(指标)主要有、和。
其中和用于测度品质数据集中趋势的分布特征,用于测度数值型数据集中趋势的分布特征。
2、标准差是反映的最主要指标(测度值)。
3、几何平均数是计算和的比较适用的一种方法。
4、当两组数据的平均数不等时,要比较其数据的差异程度大小,需要计算。
5、在测定数据分布特征时,如果M M e X 0==,则认为数据呈分布。
6、当一组工人的月平均工资悬殊较大时,用他们工资的比其算术平均数更能代表全部工人工资的总体水平。
二.选择题单选题:1.反映的时间状况不同,总量指标可分为( )A 总量指标和时点总量指标B 时点总量指标和时期总量指标C 时期总量指标和时间指标D 实物量指标和价值量指标2、某厂1999年完成产值200万元,2000年计划增长10%,实际完成了231万元,超额完成( )A 5.5%B 5%C 115.5%D 15.5%3、在同一变量数列中,当标志值(变量值)比较大的次数较多时,计算出来的平均数( )A 接近标志值小的一方B 接近标志值大的一方C 接近次数少的一方D 接近哪一方无法判断4、在计算平均数时,权数的意义和作用是不变的,而权数的具体表现( )A 可变的B 总是各组单位数C 总是各组标志总量D 总是各组标志值 5、1998年某厂甲车间工人的月平均工资为520元,乙车间工人的月平均工资为540元,1999年各车间的工资水平不变,但甲车间的工人占全部工人的比重由原来的40%提高到了60%,则1999年两车间工人的总平均工资比1998年( )A 提高B 不变C 降低D 不能做结论 6、在变异指标(离散程度测度值)中,其数值越小,则( )A 说明变量值越分散,平均数代表性越低B 说明变量值越集中,平均数代表性越高C 说明变量值越分散,平均数代表性越高D 说明变量值越集中,平均数代表性越低7、有甲、乙两数列,已知甲数列:07.7,70==甲甲σX ;乙数列:41.3,7==乙乙σX 根据以上资料可直接判断( )A 甲数列的平均数代表性大B 乙数列的平均数代表性大C 两数列的平均数代表性相同D 不能直接判别8、杭州地区每百人手机拥有量为90部,这个指标是 ( )A 、比例相对指标B 、比较相对指标C 、结构相对指标D 、强度相对指标 9、某组数据呈正态分布,计算出算术平均数为5,中位数为7,则该数据分布为 ( ) A 、左偏分布 B 、右偏分布 C 、对称分布 D 、无法判断10、加权算术平均数的大小 ( )A 主要受各组标志值大小的影响,与各组次数多少无关;B 主要受各组次数多少的影响,与各组标志值大小无关;C 既与各组标志值大小无关,也与各组次数多少无关;D 既与各组标志值大小有关,也受各组次数多少的影响11、已知一分配数列,最小组限为30元,最大组限为200元,不可能是平均数的为 ( ) A 、50元 B 、80元 C 、120元 D 、210元12、比较两个单位的资料,甲的标准差小于乙的标准差,则 ( ) A 两个单位的平均数代表性相同 B 甲单位平均数代表性大于乙单位C 乙单位平均数代表性大于甲单位D 不能确定哪个单位的平均数代表性大 13、若单项数列的所有标志值都增加常数9,而次数都减少三分之一,则其算术平均数 ( ) A 、增加9 B 、增加6C 、减少三分之一 D 、增加三分之二 14、如果数据分布很不均匀,则应编制( )A 开口组B 闭口组C 等距数列D 异距数列 15、计算总量指标的基本原则是:( ) A 总体性B 全面性C 同质性D 可比性16、某企业的职工工资分为四组:800元以下;800-1000元;1000—1500元;1500以上,则1500元以上这组组中值应近似为()A1500元 B 1600元 C 1750元D 2000元 17、统计分组的首要问题是( )A 选择分组变量和确定组限B 按品质标志分组C 运用多个标志进行分组,形成一个分组体系D 善于运用复合分组18、某连续变量数列,其末组为开口组,下限为200,又知其邻组的组中值为170,则末组组中值为( )A 230B 260C 185D 215 19、分配数列中,靠近中间的变量值分布的次数少,靠近两端的变量值分布的次数多,这种分布的类型是( )A 钟型分布B U 型分布C J 型分布D 倒J 型分布 20、要了解上海市居民家庭的开支情况,最合适的调查方式是:() A 普查B 抽样调查C 典型调查D 重点调查21、已知两个同类企业的职工平均工资的标准差分别为5元和6元,而平均工资分别为3000元,3500元则两企业的工资离散程度为 ( )A 甲大于乙B 乙大于甲C 一样的D 无法判断 22、加权算术平均数的大小取决于( )A 变量值B 频数C 变量值和频数D 频率23、如果所有标志值的频数都减少为原来的1/5,而标志值仍然不变.那么算术平均数( ) A 不变 B 扩大到5倍 C 减少为原来的1/5 D 不能预测其变化 24、 计算平均比率最好用 ( )A 算术平均数B 调和平均数C 几何平均数D 中位数25、若两数列的标准差相等而平均数不同,在比较两数列的离散程度大小时,应采用() A 全距 B 平均差 C 标准差 D 标准差系数26、若n=20,∑∑==2080,2002x x ,标准差为( )A 2B 4C 1.5D 327、已知某总体3215,3256==eMM,则数据的分布形态为( )A左偏分布B正态分布 C 右偏分布DU型分布28、一次小型出口商品洽谈会,所有厂商的平均成交额的方差为156.25万元,标准差系数为14.2%,则平均成交额为( )万元A11 B 177.5 C 22.19 D 8826、欲粗略了解我国钢铁生产的基本情况,调查了上钢、鞍钢等十几个大型的钢铁企业,这是()A普查B重点调查C典型调查D抽样调查多选题:1.某企业计划2000年成本降低率为8%,实际降低了10%。