应用多元统计分析习题解答-第五章Word版
- 格式:doc
- 大小:1.19 MB
- 文档页数:24

第二章2.1 试述多元联合分布和边缘分布之间的关系。
设X =(X 1,X 2,⋯X p )′是p 维随机向量,称由它的q (<p )个分量组成的子向量X(i)=(X i1,X i2,⋯X iq )′的分布为X 的边缘分布,相对地把X 的分布称为联合分布。
当X 的分布函数为F (x 1,x 2,⋯x p )时,X (1)的分布函数即边缘分布函数为F (x 1,x 2,⋯x p )=P(X 1≤x 1,⋯X q ≤x q ,X q+1≤∞,⋯X p ≤∞) = F (x 1,x 2,⋯x q ,∞,⋯∞)当X 有分布密度f (x 1,x 2,⋯x p )则X (1)也有分布密度,即边缘密度函数为:f (x 1,x 2,⋯x q )=∫⋯+∞−∞∫f (x 1,x 2,⋯x p )dx q+1⋯d +∞−∞x p 2.2 设随机向量X =(X 1,X 2)′服从二元正态分布,写出其联合分布密度函数和X 1,X 2各自的边缘密度函数。
联合分布密度函数12πσ1σ2(1−ρ2)1/2exp{−12(1−ρ2)[(x 1−μ1)2σ12−2ρ(x 1−μ1)(x 2−μ2)σ1σ2+f (x 1,x 2)=(x 2−μ2)2σ22]} , x 1>0,x 2>00 , 其他(x 1−μ1)2σ12−2ρ(x 1−μ1)(x 2−μ2)σ1σ2+(x 2−μ2)2σ22=(x 1−μ1)2σ12−2ρ(x 1−μ1)(x 2−μ2)σ1σ2+(x 2−μ2)2σ22+ρ2(x 1−μ1)2σ12−ρ2(x 1−μ1)2σ12=[ρ(x 1−μ1)σ1−(x 2−μ2)σ2]2+(1−ρ2)(x 1−μ1)2σ12所以指数部分变为−12{[11√1−ρ2σ1−22√1−ρ2σ2]2+(x 1−μ1)2σ12}令t=22√1−ρ2σ2−11√1−ρ2σ1 ∴dt =√1−ρ2σ22∴f (x 1)=∫f (x 1,x 2)+∞−∞dx 2=12πσ1σ2(1−ρ2)1/2exp{−(x 1−μ1)22σ12∫exp(+∞−∞−12t 2√1−ρ22dt =√2πσexp[−(x 1−μ1)22σ12] √2πσexp[−(x 1−μ1)22σ12] , x 1>0f (x 1)=0 ,其他 同理, √2πσ2exp[−(x 2−μ2)22σ22] , x 2>0f (x 2)=0 ,其他2.3 已知随机向量X =(X 1,X 2)′的联合分布密度函数为f (x 1,x 2)=2[(d−c )(x 1−a )+(b−a )(x 2−c )−2(x 1−a)(x 2−c)(b−a)2(d−c)2,其中,a ≤x 1≤b,c ≤x 2≤d 。
![应用多元统计分析答案详解汇总_高惠璇[1]](https://uimg.taocdn.com/5f0eb38784868762caaed582.webp)

2.1.试叙述多元联合分布和边际分布之间的关系。
解:多元联合分布讨论多个随机变量联合到一起的概率分布状况,12(,,)p X X X X '=L 的联合分布密度函数是一个p 维的函数,而边际分布讨论是12(,,)p X X X X '=L 的子向量的概率分布,其概率密度函数的维数小于p 。
2.2设二维随机向量12()X X '服从二元正态分布,写出其联合分布。
解:设12()X X '的均值向量为()12μμ'=μ,协方差矩阵为21122212σσσσ⎛⎫ ⎪⎝⎭,则其联合分布密度函数为1/21222112112222122121()exp ()()2f σσσσσσσσ--⎧⎫⎛⎫⎛⎫⎪⎪'=---⎨⎬ ⎪⎪⎝⎭⎝⎭⎪⎪⎩⎭x x μx μ。
2.3已知随机向量12()X X '的联合密度函数为121212222[()()()()2()()](,)()()d c x a b a x c x a x c f x x b a d c --+-----=--其中1ax b ≤≤,2c x d ≤≤。
求(1)随机变量1X 和2X 的边缘密度函数、均值和方差; (2)随机变量1X 和2X 的协方差和相关系数;(3)判断1X 和2X 是否相互独立。
(1)解:随机变量1X 和2X 的边缘密度函数、均值和方差;112121222[()()()()2()()]()()()dx cd c x a b a x c x a x c f x dx b a d c --+-----=--⎰12212222222()()2[()()2()()]()()()()dd c c d c x a x b a x c x a x c dx b a d c b a d c -------=+----⎰ 121222202()()2[()2()]()()()()dd c c d c x a x b a t x a t dt b a d c b a d c ------=+----⎰ 2212122222()()[()2()]1()()()()d cdc d c x a x b a t x a t b a d c b a d c b a------=+=----- 所以 由于1X 服从均匀分布,则均值为2b a+,方差为()212b a -。

5.4经计算可得:<4.64、‘2.8794 10.0100 -1.8091、x = 45.4,S =10.0100 199.7884 -5.64009.965;c 1.8091 -5.6400 3.6277 丿‘0.5862 -0.02210.2580、S'1 = -0.0221 0.0061 -0.0016、0.2580 -0.0016 0.4018 丿S 的特征值和特征向量分别为人=1.3014,q =(—0.8175 0.0249 —0.5754)'& = 4.5316,色=(0.5737 -0.053—0.8173)'入=200.4625心=(0.0508 0.9983 -0.029if由所有(u l9u 2,u 3)组成U 的90%置信椭圆为由于 ^17 (0.1) = 2.44,故有其三个主轴的长度分别为:2列紀 j 如 2xVF^J 鍔X2.44 - 24.8071 2 佝鳩3x19 -—x 2.44 =307.884920x17(b)排汗量XI 的Q ・Q 图:'0.5862 -0.0221 20(4.64一绚,45.4-u 2,9.965一禺)-0.0221 0.0061 ,0.2580 -0.0016 0.2580-0.00160.4018‘4.64 - )45.4 — u 2 W 、9.965 _如丿3x19 1717(0.1)"0.5862 -0.0221 20(4.64 -绚,45.4 一 u 2,9.965 -冷)-0.0221 0.0061、0.2580 -0.0016 0.2580-0.00160.4018孑4.64-普、 45.4 — (9.965-均丿< 8.18123x19 - ------- x 2.44 =46.2911 20x17钠含量X2的Q ・Q 图:QQ Plot of Sample Data X2 versus Standard Normal钾含量的Q-Q 图:70 o o o o6 5 4 3 <D-dlues -ndu- joQQ Plot of Sample Data X1 versus Standard Normal-1.5-0.5 0 0.5 1 Standard Normal Quantiles1.5 29 8 7 6 5 4 3①-dLUBS Indu- jo s ①三UBno-1.5-1-0.5 0 0.5 1 Standard Normal Quantiles1.5 2QQ Plot of Sample Data X3 versus Standard Normal•1.5-105 0 0.5 1 Standard Normal Quantiles1.5 254321098761— 1— XI 和X2的散点图:80 r 70 60 50 40 30 20 XI 和X3的散点图:5 x114—鼻■13*♦12一♦11■ ** *m10■ *♦ ♦98♦ * *« **71 1 1 1 11 ♦2 3 45 678 9X1X2和X3的散点图:14r♦131211co10由排汗量XI 、钠含量X2、钾含量X3数据的Q.Q 都接近于直线,而且各对观察值的散点图 都近似的接近于椭圆,因此可以认为多元正态假定是合理的。



第二章2.1.试叙述多元联合分布和边际分布之间的关系。
解:多元联合分布讨论多个随机变量联合到一起的概率分布状况,12(,,)p X X X X '=的联合分布密度函数是一个p 维的函数,而边际分布讨论是12(,,)p X X X X '=的子向量的概率分布,其概率密度函数的维数小于p 。
2.2设二维随机向量12()X X '服从二元正态分布,写出其联合分布。
解:设12()X X '的均值向量为()12μμ'=μ,协方差矩阵为21122212σσσσ⎛⎫ ⎪⎝⎭,则其联合分布密度函数为1/21222112112222122121()exp ()()2f σσσσσσσσ--⎧⎫⎛⎫⎛⎫⎪⎪'=---⎨⎬ ⎪⎪⎝⎭⎝⎭⎪⎪⎩⎭x x μx μ。
2.3已知随机向量12()X X '的联合密度函数为121212222[()()()()2()()](,)()()d c x a b a x c x a x c f x x b a d c --+-----=--其中1a x b ≤≤,2c x d ≤≤。
求(1)随机变量1X 和2X 的边缘密度函数、均值和方差; (2)随机变量1X 和2X 的协方差和相关系数; (3)判断1X 和2X 是否相互独立。
(1)解:随机变量1X 和2X 的边缘密度函数、均值和方差;112121222[()()()()2()()]()()()dx cd c x a b a x c x a x c f x dx b a d c --+-----=--⎰12212222222()()2[()()2()()]()()()()dd cc d c x a x b a x c x a x c dx b a d c b a d c -------=+----⎰ 12122222()()2[()2()]()()()()dd cc d c x a x b a t x a t dt b a d c b a d c ------=+----⎰2212122222()()[()2()]1()()()()d cdcd c x a x b a t x a t b a d c b a d c b a------=+=----- 所以由于1X 服从均匀分布,则均值为2b a +,方差为()212b a -。
第二章2.1.试叙述多元联合分布和边际分布之间的关系。
解:多元联合分布讨论多个随机变量联合到一起的概率分布状况,12(,,)p X X X X '=的联合分布密度函数是一个p 维的函数,而边际分布讨论是12(,,)p X X X X '=的子向量的概率分布,其概率密度函数的维数小于p 。
2.2设二维随机向量12()X X '服从二元正态分布,写出其联合分布。
解:设12()X X '的均值向量为()12μμ'=μ,协方差矩阵为21122212σσσσ⎛⎫ ⎪⎝⎭,则其联合分布密度函数为1/21222112112222122121()exp ()()2f σσσσσσσσ--⎧⎫⎛⎫⎛⎫⎪⎪'=---⎨⎬ ⎪⎪⎝⎭⎝⎭⎪⎪⎩⎭x x μx μ。
2.3已知随机向量12()X X '的联合密度函数为121212222[()()()()2()()](,)()()d c x a b a x c x a x c f x x b a d c --+-----=--其中1a x b ≤≤,2c x d ≤≤。
求(1)随机变量1X 和2X 的边缘密度函数、均值和方差; (2)随机变量1X 和2X 的协方差和相关系数; (3)判断1X 和2X 是否相互独立。
(1)解:随机变量1X 和2X 的边缘密度函数、均值和方差;112121222[()()()()2()()]()()()dx cd c x a b a x c x a x c f x dx b a d c --+-----=--⎰12212222222()()2[()()2()()]()()()()dd cc d c x a x b a x c x a x c dx b a d c b a d c -------=+----⎰ 12122222()()2[()2()]()()()()dd cc d c x a x b a t x a t dt b a d c b a d c ------=+----⎰2212122222()()[()2()]1()()()()d cdcd c x a x b a t x a t b a d c b a d c b a------=+=----- 所以由于1X 服从均匀分布,则均值为2b a +,方差为()212b a -。

一、填空题:1、多元统计剖析是运用数理统计方法来研究解决多指标问题的理论和方法 .2、回归参数明显性查验是查验解说变量对被解说变量的影响能否著.3、聚类剖析就是剖析怎样对样品(或变量)进行量化分类的问题。
往常聚类分析分为Q型聚类和R型聚类。
4、相应剖析的主要目的是追求列联表行要素A和列要素B的基本剖析特点和它们的最优联立表示。
5、因子剖析把每个原始变量分解为两部分要素:一部分为公共因子,另一部分为特别因子。
6、若x( ): N P( ,),=1,2,3 .n且互相独立,则样本均值向量x 听从的散布为 _ x ~N(μ,Σ /n)_。
二、简答1、简述典型变量与典型有关系数的观点,并说明典型有关剖析的基本思想。
在每组变量中找出变量的线性组合,使得两组的线性组合之间拥有最大的有关系数。
选用和最先精选的这对线性组合不有关的线性组合,使其配对,并选用有关系数最大的一对,这样下去直到两组之间的有关性被提取完成为止。
被选出的线性组合配对称为典型变量,它们的有关系数称为典型有关系数。
2、简述相应剖析的基本思想。
相应剖析,是指对两个定性变量的多种水平进行剖析。
设有两组要素A和B,此中要素 A 包括 r 个水平,要素 B 包括 c 个水平。
对这两组要素作随机抽样检查,获得一个 rc 的二维列联表,记为。
要追求列联表列要素 A 和行要素 B 的基本剖析特点和最优列联表示。
相应剖析即是经过列联表的变换,使得要素 A和要素 B 拥有平等性,进而用同样的因子轴同时描绘两个要素各个水平的情况。
把两个要素的各个水平的情况同时反应到拥有同样坐标轴的因子平面上,进而获得要素 A 、 B 的联系。
3、简述费希尔鉴别法的基本思想。
从 k 个整体中抽取拥有 p 个指标的样品观察数据,借助方差剖析的思想结构一个线性鉴别函数系数:确立的原则是使得整体之间差别最大,而使每个整体内部的离差最小。
将新样 品的 p 个指标值代入线性鉴别函数式中求出 值,而后依据鉴别必定的规则,就能够鉴别新的样品属于哪个整体。

第二章2.1 试述多元联合分布和边缘分布之间的关系。
设,是p维随机向量,称由它的q(<p)个分量组成的子向量,的分布为的边缘分布,相对地把的分布称为联合分布。
当的分布函数为F,时,的分布函数即边缘分布函数为F,=P()= F,当X有分布密度f(,)则也有分布密度,即边缘密度函数为:f(,)=(,)2.2 设随机向量服从二元正态分布,写出其联合分布密度函数和各自的边缘密度函数。
联合分布密度函数,0 , 其他==()所以指数部分变为令t== exp[] exp[] ,=0 ,其他 同理,exp[] ,=0 ,其他2.3 已知随机向量 的联合分布密度函数为,其中, 。
求:(1) 随机变量各自的边缘密度函数、均值与方差。
解:==同理,==同理可得()22dc x E +=同理可得()()1222d c x D -=(2)随机变量的协方差和相关系数。
E(==E(==E(==E(=D(E(D(E(Cov E(E(=.===(3)判断是否独立。
不相互独立。
2.4设随机向量,服从正态分布,已知其协差阵为对角阵,证明的分量是相互独立的随机变量。
Σ= ΣΣΣΣ与不相关又 ,服从正态分布与 相互独立。
( , , , , , ) 2.5解: 依据题意,X=E(X)=D(X)=注:利用 11p n n ⨯'=1X X , S 1()n n n n''=-11X I X 其中 1001n ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦I 在SPSS 中求样本均值向量的操作步骤如下:1. 选择菜单项Analyze →Descriptive Statistics →Descriptives ,打开Descriptives 对话框。
将待估计的四个变量移入右边的Variables 列表框中,如图2.1。
图2.1 Descriptives 对话框2. 单击Options 按钮,打开Options 子对话框。
在对话框中选择Mean 复选框,即计算样本均值向量,如图2.2所示。
题目:
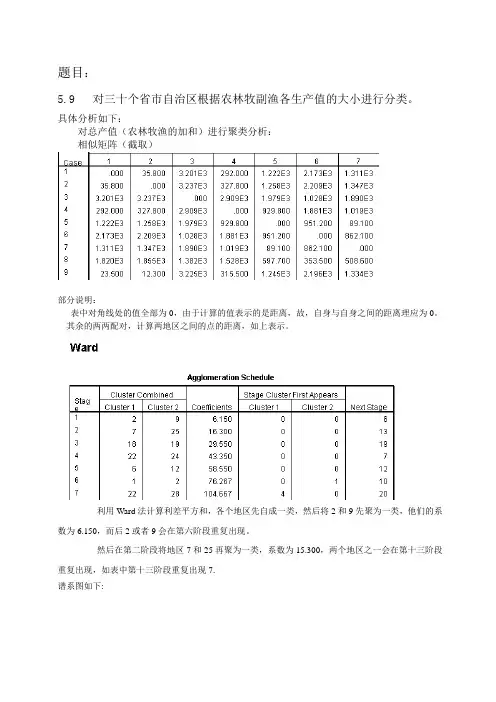
5.9 对三十个省市自治区根据农林牧副渔各生产值的大小进行分类。
具体分析如下:
对总产值(农林牧渔的加和)进行聚类分析:
相似矩阵(截取)
部分说明:
表中对角线处的值全部为0,由于计算的值表示的是距离,故,自身与自身之间的距离理应为0。
其余的两两配对,计算两地区之间的点的距离,如上表示。
利用Ward法计算利差平方和,各个地区先自成一类,然后将2和9先聚为一类,他们的系
数为6.150,而后2或者9会在第六阶段重复出现。
然后在第二阶段将地区7和25再聚为一类,系数为15.300,两个地区之一会在第十三阶段
重复出现,如表中第十三阶段重复出现7.
谱系图如下:
可以通过做直线,找与图中线的交点确定所分的类,类所包括的内容以及分类的数目。
较详细接直观的展现。
如下图所示的直线以及分类。
对农业进行聚类:
利用的是皮尔逊相关系数,中位数法,说明不同省市的农业收入是不相关的。
相关系数矩阵(截取)
此处用的是相关系数得到的相似矩阵,故对角线处的元素全部为1。
相同的解释类似于对总产值聚类,故不具体说明。
同时也类似的做出下列谱系图:
从图中可以观察到农业产值在数值之间的差异并不是特别大,同样通过做垂线的办法将其分为
读者预想的类别。
略。
第二章2.1.试叙述多元联合分布和边际分布之间的关系。
解:多元联合分布讨论多个随机变量联合到一起的概率分布状况,12(,,)p X X X X '=的联合分布密度函数是一个p 维的函数,而边际分布讨论是12(,,)p X X X X '=的子向量的概率分布,其概率密度函数的维数小于p 。
2.2设二维随机向量12()X X '服从二元正态分布,写出其联合分布。
解:设12()X X '的均值向量为()12μμ'=μ,协方差矩阵为21122212σσσσ⎛⎫ ⎪⎝⎭,则其联合分布密度函数为1/21222112112222122121()exp ()()2f σσσσσσσσ--⎧⎫⎛⎫⎛⎫⎪⎪'=---⎨⎬ ⎪⎪⎝⎭⎝⎭⎪⎪⎩⎭x x μx μ。
2.3已知随机向量12()X X '的联合密度函数为121212222[()()()()2()()](,)()()d c x a b a x c x a x c f x x b a d c --+-----=--其中1a x b ≤≤,2c x d ≤≤。
求(1)随机变量1X 和2X 的边缘密度函数、均值和方差; (2)随机变量1X 和2X 的协方差和相关系数; (3)判断1X 和2X 是否相互独立。
(1)解:随机变量1X 和2X 的边缘密度函数、均值和方差;112121222[()()()()2()()]()()()dx cd c x a b a x c x a x c f x dx b a d c --+-----=--⎰12212222222()()2[()()2()()]()()()()dd cc d c x a x b a x c x a x c dx b a d c b a d c -------=+----⎰ 12122222()()2[()2()]()()()()dd cc d c x a x b a t x a t dt b a d c b a d c ------=+----⎰2212122222()()[()2()]1()()()()d cdcd c x a x b a t x a t b a d c b a d c b a------=+=----- 所以由于1X 服从均匀分布,则均值为2b a +,方差为()212b a -。
第五章 聚类分析5.1 判别分析和聚类分析有何区别?答:即根据一定的判别准则,判定一个样本归属于哪一类。
具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。
聚类分析是分析如何对样品(或变量)进行量化分类的问题。
在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。
通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。
5.2 试述系统聚类的基本思想。
答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。
5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造?答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。
因为我们把n 个样本看作p 维空间的n 个点。
点之间的距离即可代表样品间的相似度。
常用的距离为 (一)闵可夫斯基距离:1/1()()pq qij ik jk k d q X X ==-∑q 取不同值,分为 (1)绝对距离(1q =)1(1)pij ik jkk d X X ==-∑(2)欧氏距离(2q =)21/21(2)()pi j i k j k k d X X==-∑(3)切比雪夫距离(q =∞)1()max ij ik jkk pd X X ≤≤∞=-(二)马氏距离(三)兰氏距离对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。
21()()()ij i j i j d M -'=--X X ΣX X 11()p ik jkij k ik jk X X d L p X X =-=+∑将变量看作p 维空间的向量,一般用(一)夹角余弦(二)相关系数5.4 在进行系统聚类时,不同类间距离计算方法有何区别?选择距离公式应遵循哪些原则?答: 设d ij 表示样品X i 与X j 之间距离,用D ij 表示类G i 与G j 之间的距离。
第五章 聚类分析5.1 判别分析和聚类分析有何区别?答:即根据一定的判别准则,判定一个样本归属于哪一类。
具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。
聚类分析是分析如何对样品(或变量)进行量化分类的问题。
在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。
通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。
5.2 试述系统聚类的基本思想。
答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。
5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造?答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。
因为我们把n 个样本看作p 维空间的n 个点。
点之间的距离即可代表样品间的相似度。
常用的距离为 (一)闵可夫斯基距离:1/1()()pq qij ik jk k d q X X ==-∑q 取不同值,分为 (1)绝对距离(1q =) 1(1)pij ik jk k d X X ==-∑(2)欧氏距离(2q =)21/21(2)()pij ik jk k d X X ==-∑(3)切比雪夫距离(q =∞)1()max ij ik jkk pd X X ≤≤∞=-(二)马氏距离(三)兰氏距离对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。
21()()()ij i j i j d M -'=--X X ΣX X 11()p ik jkij k ik jkX X d L p X X =-=+∑将变量看作p 维空间的向量,一般用(一)夹角余弦(二)相关系数5.4 在进行系统聚类时,不同类间距离计算方法有何区别?选择距离公式应遵循哪些原则?答: 设d ij 表示样品X i 与X j 之间距离,用D ij 表示类G i 与G j 之间的距离。
(1). 最短距离法,mini k j rkr ij X G X G D d ∈∈=min{,}kp kq D D =(2)最长距离法,maxi p j qpq ij X G X G D d ∈∈=,maxi k j rkr ij X G X G D d ∈∈=max{,}kp kq D D =(3)中间距离法其中(4)重心法2()()pq p q p q D X X X X '=-- )(1q q p p rrX n X n n X +=12211cos ()()pik jkk ij p pik jk k k X X X X θ====∑∑∑12211()()()()pik i jk j k ij p pik i jk j k k X X X X r X X X X ===--=--∑∑∑ij G X G X ij d D jj i i ∈∈=,min22222121pq kq kp kr D D D D β++=22222p q p q krkpkqpq rrr n n n n D D D D n n n =+-(5)类平均法221i p j jpq ij X G X G p qD d n n ∈∈=∑∑221i k j rkr ijX G X G k rD d n n ∈∈=∑∑22p q kp kqrrn n D D n n =+(6)可变类平均法其中是可变的且 <1(7)可变法22221()2kr kp kq pq D D D D ββ-=++ 其中是可变的且 <1 (8)离差平方和法1()()tn t it t it t t S X X X X ='=--∑2222k p k q k krkpkq pq r kr kr kn n n n n D D D D n n n n n n ++=+-+++通常选择距离公式应注意遵循以下的基本原则:(1)要考虑所选择的距离公式在实际应用中有明确的意义。
如欧氏距离就有非常明确的空间距离概念。
马氏距离有消除量纲影响的作用。
(2)要综合考虑对样本观测数据的预处理和将要采用的聚类分析方法。
如在进行聚类分析之前已经对变量作了标准化处理,则通常就可采用欧氏距离。
(3)要考虑研究对象的特点和计算量的大小。
样品间距离公式的选择是一个比较复杂且带有一定主观性的问题,我们应根据研究对象的特点不同做出具体分折。
实际中,聚类分析前不妨试探性地多选择几个距离公式分别进行聚类,然后对聚类分析的结果进行对比分析,以确定最合适的距离测度方法。
5.5试述K 均值法与系统聚类法的异同。
答:相同:K —均值法和系统聚类法一样,都是以距离的远近亲疏为标准进行聚类的。
2222(1)()pq kr kpkq pqrrn n D D D D n n ββ=-++不同:系统聚类对不同的类数产生一系列的聚类结果,而K —均值法只能产生指定类数的聚类结果。
具体类数的确定,离不开实践经验的积累;有时也可以借助系统聚类法以一部分样品为对象进行聚类,其结果作为K —均值法确定类数的参考。
5.6 试述K 均值法与系统聚类有何区别?试述有序聚类法的基本思想。
答:K 均值法的基本思想是将每一个样品分配给最近中心(均值)的类中。
系统聚类对不同的类数产生一系列的聚类结果,而K —均值法只能产生指定类数的聚类结果。
具体类数的确定,有时也可以借助系统聚类法以一部分样品为对象进行聚类,其结果作为K 均值法确定类数的参考。
有序聚类就是解决样品的次序不能变动时的聚类分析问题。
如果用)()2()1(,,,n X X X 表示n 个有序的样品,则每一类必须是这样的形式,即)()1()(,,,j i i X X X +,其中,1n i ≤≤且n j ≤,简记为},,1,{j i i G i +=。
在同一类中的样品是次序相邻的。
一般的步骤是(1)计算直径{D (i,j )}。
(2)计算最小分类损失函数{L[p(l,k)]}。
(3)确定分类个数k 。
(4)最优分类。
5.7 检测某类产品的重量, 抽了六个样品, 每个样品只测了一个指标,分别为1,2,3,6,9,11.试用最短距离法,重心法进行聚类分析。
(1)用最短距离法进行聚类分析。
采用绝对值距离,计算样品间距离阵0 1 0 2 1 0 5 4 3 0 8 7 6 3 0 10 9 8 5 2 0由上表易知 中最小元素是 于是将,,聚为一类,记为计算距离阵3 06 3 08 5 2 0中最小元素是=2 于是将,聚为一类,记为计算样本距离阵3 06 3 0中最小元素是于是将,聚为一类,记为因此,(2)用重心法进行聚类分析计算样品间平方距离阵1 04 1 025 16 9 064 49 36 9 0100 81 64 25 4 0易知中最小元素是于是将,,聚为一类,记为计算距离阵16 049 9 081 25 4 0注:计算方法,其他以此类推。
中最小元素是=4 于是将,聚为一类,记为计算样本距离阵16 064 16 0中最小元素是于是将,聚为一类,记为因此,5.8 下表是15个上市公司2001年的一些主要财务指标,使用系统聚类法和K-均值法分别对这些公司进行聚类,并对结果进行比较分析。
公司编号净资产收益率每股净利润总资产周转率资产负债率流动负债比率每股净资产净利润增长率总资产增长率1 11.09 0.21 0.05 96.98 70.53 1.86 -44.04 81.9911 30.22 0.16 0.4 87.36 94.88 0.53 729.41 -9.9712 8.19 0.22 0.38 30.31 100 2.73 -12.31 -2.7713 95.79 -5.2 0.5 252.34 99.34 -5.42 -9816.52 -46.8214 16.55 0.35 0.93 72.31 84.05 2.14 115.95 123.4115 -24.18 -1.16 0.79 56.26 97.8 4.81 -533.89 -27.74解:令净资产收益率为X1,每股净利润X2,总资产周转率为X3,资产负债率为X4,流动负债比率为X5,每股净资产为X6,净利润增长率为X7,总资产增长率为X8,用spss对公司聚类分析的步骤如下:a)系统聚类法:1.在SPSS窗口中选择Analyze→Classify→Hierachical Cluster,调出系统聚类分析主界面,并将变量X8X1移入Variables框中。
在Cluster-栏中选择Cases单选按钮,即对样品进行聚类(若选择Variables,则对变量进行聚类)。
在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
图5.1 系统分析法主界面2.点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。
我们选择Agglomeration schedule与Cluster Membership中的Range of solution 2-4,如图5.2所示,点击Continue按钮,返回主界面。
(其中,Agglomeration schedule表示在结果中给出聚类过程表,显示系统聚类的详细步骤;Proximity matrix 表示输出各个体之间的距离矩阵;Cluster Membership 表示在结果中输出一个表,表中显示每个个体被分配到的类别,Range of solution 2-4即将所有个体分为2至4类。
)3.点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。
选中Dendrogram复选框和Icicle栏中的None单选按钮,如图5.3,即只给出聚类树形图,而不给出冰柱图。
单击Continue按钮,返回主界面。
图5.2 Statistics子对话框图5.3 Plots子对话框4.点击Method按钮,设置系统聚类的方法选项。
Cluster Method下拉列表用于指定聚类的方法,这里选择Between-group inkage(组间平均数连接距离);Measure栏用于选择对距离和相似性的测度方法,选择Squared Euclidean distance(欧氏距离);单击Continue按钮,返回主界面。
图5.4 Method子对话框图5.5 Save子对话框5.点击Save按钮,指定保存在数据文件中的用于表明聚类结果的新变量。