2二维线性鉴别分析(2DLDA)
- 格式:doc
- 大小:45.50 KB
- 文档页数:3

基于双向2 DLDA与 LDA相结合的 SAR目标识别算法杨佐龙;王德功;胡朝军;尹辉;岳剑飞【期刊名称】《计算机应用与软件》【年(卷),期】2014(000)011【摘要】线性判决分析( LDA)用于图像特征提取时,存在着损失二维空间结构信息、计算复杂度大的缺点。
二维线性判决分析(2DLDA)弥补了LDA的缺点,但2DLDA仅消除了图像各列间的相关性,所提取的图像特征维数仍然较大。
为解决上述问题,采用双向2DLDA与LDA相结合的特征提取算法对图像的行和列同时进行压缩,减少特征矩阵维数,降低计算量。
实验结果表明,所提出的SAR ( Synthetic Aperture Radar)图像目标识别方法有效地降低了图像数据维数,提高了识别率,并克服了方位角变化对识别结果的影响。
%Linear discriminant analysis ( LDA) has the disadvantages of information losses in regard to two-dimensional spatial structure and high computational complexity when applying to image feature extraction.Two-dimensional linear discriminant analysis (2DLDA) makes up the flaws of LDA.However, it only eliminates the pertinence between the columns of image, while the number of features extracted is still large.In order to solve the problems, we adopt a new feature extraction algorithm to compress the columns and rows of image simultaneously, which combines the bidirectional 2DLDA with LDA, thus reduces the number of feature matrix dimensions and decreases the calculation amount.Experimental results show that the SAR images recognition method presented in this paper effectively reducesimage dimensions numberand raises recognition rate, it also overcomes the impact on recognition result brought by the variation of target azimuth.【总页数】5页(P279-282,317)【作者】杨佐龙;王德功;胡朝军;尹辉;岳剑飞【作者单位】空军航空大学吉林长春 130022;空军航空大学吉林长春 130022;解放军94916部队江苏南京 210022;空军航空大学吉林长春 130022;解放军66347部队河北保定 071000【正文语种】中文【中图分类】TN957.52;TP391【相关文献】1.一种基于重采样双向2DLDA融合的人脸识别算法 [J], 李文辉;姜园媛;王莹;傅博2.一种用于SAR目标特征提取的I2DLDA方法 [J], 刘振;姜晖3.2DPCA+2DLDA和改进的LPP相结合的人脸识别算法 [J], 李球球;杨恢先;奉俊鹏;蔡勇勇;翟云龙4.两向2DLDA与SVM相结合的SAR图像识别 [J], 杨佐龙;王德功;胡朝军;王新超5.基于局部二元模式和重采样双向2DLDA的人脸识别算法 [J], 苏立明;王莹;姜园媛;李文辉因版权原因,仅展示原文概要,查看原文内容请购买。


线性判别分析
线性判别分析(linear discriminant analysis,LDA)是对费舍尔的线性鉴别方法的归纳,这种方法使用统计学,模式识别和机器学习方法,试图找到两类物体或事件的特征的一个线性组合,以能够特征化或区分它们。
所得的组合可用来作为一个线性分类器,或者,更常见的是,为后续的分类做降维处理。
之前我们讨论的PCA、ICA也好,对样本数据来言,可以是没有类别标签y的。
回想我们做回归时,如果特征太多,那么会产生不相关特征引入、过度拟合等问题。
我们可以使用PCA来降维,但PCA没有将类别标签考虑进去,属于无监督的。
比如回到上次提出的文档中含有“learn”和“study”的问题,使用PCA后,也许可以将这两个特征合并为一个,降了维度。
但假设我们的类别标签y是判断这篇文章的topic是不是有关学习方面的。
那么这两个特征对y几乎没什么影响,完全可以去除。
Fisher提出LDA距今已近七十年,仍然是降维和模式分类领域应用中最为广泛采用而且极为有效的方法之一,其典型应用包括人脸检测、人脸识别、基于视觉飞行的地平线检测、目标跟踪和检测、信用卡欺诈检测和图像检索、语音识别等。

线性判别分析(LinearDiscriminantAnalysis,LDA)⼀、LDA的基本思想线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discriminant ,FLD),是模式识别的经典算法,它是在1996年由Belhumeur引⼊模式识别和⼈⼯智能领域的。
线性鉴别分析的基本思想是将⾼维的模式样本投影到最佳鉴别⽮量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的⼦空间有最⼤的类间距离和最⼩的类内距离,即模式在该空间中有最佳的可分离性。
如下图所⽰,根据肤⾊和⿐⼦⾼低将⼈分为⽩⼈和⿊⼈,样本中⽩⼈的⿐⼦⾼低和⽪肤颜⾊主要集中A组区域,⿊⼈的⿐⼦⾼低和⽪肤颜⾊主要集中在B组区域,很显然A组合B组在空间上明显分离的,将A组和B组上的点都投影到直线L上,分别落在直线L的不同区域,这样就线性的将⿊⼈和⽩⼈分开了。
⼀旦有未知样本需要区分,只需将⽪肤颜⾊和⿐⼦⾼低代⼊直线L的⽅程,即可判断出未知样本的所属的分类。
因此,LDA的关键步骤是选择合适的投影⽅向,即建⽴合适的线性判别函数(⾮线性不是本⽂的重点)。
⼆、LDA的计算过程1、代数表⽰的计算过程设已知两个总体A和B,在A、B两总体分别提出m个特征,然后从A、B两总体中分别抽取出、个样本,得到A、B两总体的样本数据如下:和假设存在这样的线性函数(投影平⾯),可以将A、B两类样本投影到该平⾯上,使得A、B两样本在该直线上的投影满⾜以下两点:(1)两类样本的中⼼距离最远;(2)同⼀样本内的所有投影距离最近。
我们将该线性函数表达如下:将A总体的第个样本点投影到平⾯上得到投影点,即A总体的样本在平⾯投影的重⼼为其中同理可以得到B在平⾯上的投影点以及B总体样本在平⾯投影的重⼼为其中按照Fisher的思想,不同总体A、B的投影点应尽量分开,⽤数学表达式表⽰为,⽽同⼀总体的投影点的距离应尽可能的⼩,⽤数学表达式表⽰为,,合并得到求从⽽使得得到最⼤值,分别对进⾏求导即可,详细步骤不表。

2二维线性鉴别分析(2DLDA)2 二维线性鉴别分析(2DLDA )2.1 实验原理由上面的公式计算w G 和b G ,类似于经典的Fisher 准则,二维图像直接投影的广义Fisher 准则定义如下:()T b T w X G X J X X G X= 一般情况下w G 可逆,也就是根据1w b G G -计算本征值、本征向量,取最大的d 个本征值对应的本征向量作为二维投影的向量组。
需要特别指出的是,尽管b G 和w G 都是对称矩阵,但1w b G G -不一定是对称矩阵。
所以各投影轴之间关于w G 及t G 共轭正交,而不是正交。
本实验为简单起见,使用的为欧式距离。
2.2 实验过程读取训练样本——〉求样本均值——〉求类内散布矩阵——〉特征值分解——〉对实验样本分类——〉计算分类正确率2.3 实验结果分析本实验中的类别数为40,每类的样本数为10,训练数为5,检测数为5。
实验的结果正确率为72%,结果正确率偏低。
2.4 matlab 代码clear all;t0=clock;class_num = 40;class_sample = 10;train_num = 5;test_num = 5;scale = 1;allsamples=[];%所有训练图像gnd=[];k=1;path = ['C:\Documents and Settings\dongyan\桌面\模式识别\ORL\ORL\ORL'];for i=1:class_numfor j =1:train_numname =[path num2str(10*i+j-10,'%.3d') '.BMP' ];[a,map]=imread(name,'bmp');a = imresize(a,scale);a=double(a);ImageSize=size(a);height=ImageSize(1);width=ImageSize(2);A=reshape(a,1,ImageSize(1)*ImageSize(2));allsamples=[allsamples;A];gnd(k)=i;k=k+1;end;end;trainData=allsamples;sampleMean=mean(allsamples);%求所有图片的均值[nSmp,nFea] = size(trainData);classLabel = unique(gnd);nClass = length(classLabel);classmean=zeros(nClass,height*width);%求每类的均值for i=1:nClassindex = find(gnd==classLabel(i));classmean(i,:)=mean(trainData(index, :));endGb=0;Amean=reshape(sampleMean,height,width);%求类间散布矩阵Gbfor i=1:nClassAimean=reshape(classmean(i,:),height,width);Gb=Gb+(Aimean-Amean)'*(Aimean-Amean);endGw=0;%求类内散布矩阵for i=1:nClassfor j=train_num*(i-1)+1:train_num*ig=reshape((trainData(j,:)-classmean(i,:)),height,width);Gw=Gw+g'*g;endendinvGw=inv(Gw);%求(Gw-1)*GbU=invGw*Gb;[eigvu eigvet]=eig(U);%求特征值与特征向量d=diag(eigvu);[d1 index]=sort(d);cols=size(eigvet,2);for i=1:colsvsort(:,i) = eigvet(:, index(cols-i+1) ); % vsort 是一个M*col阶矩阵,保存的是按降序排列的特征向量,每一列构成一个特征向量dsort(i) = d( index(cols-i+1) ); % dsort 保存的是按降序排列的特征值,是一维行向量end %完成降序排列for i=1:8X(:,i)=vsort(:,i);%X表示投影轴endaccu=0;%做测试,记录命中率for i=1:class_numfor j =train_num+1:class_samplename =[path num2str(10*i+j-10,'%.3d') '.BMP' ];Image = double(imread(name));Image = imresize(Image,scale);testdata1=Image*X;for k=1:class_num*train_numjuli(k)=norm(testdata1-reshape(trainData(k,:),height,width)*X);%计算图片与训练样本之间的距离,如果距离最小,认为测试图片与训练图片属于同一类end;[r t]=min(juli);if fix((t-1)/train_num)==(i-1)accu=accu+1;endend;end;accu=accu/(class_num*test_num);accutime1 = etime(clock,t0)。
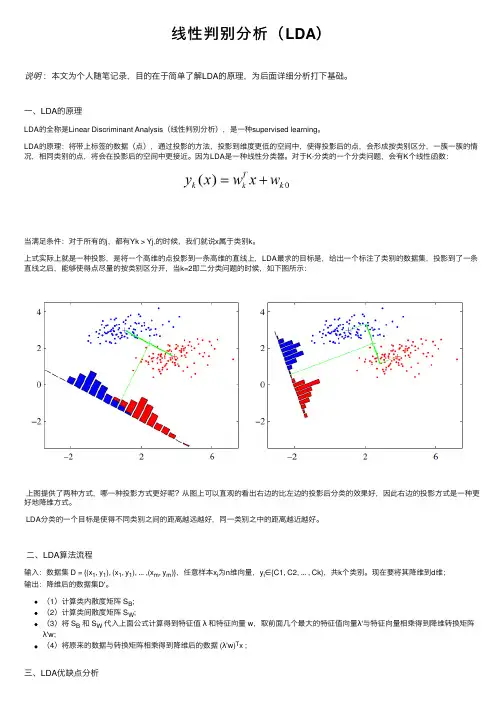
线性判别分析(LDA)说明:本⽂为个⼈随笔记录,⽬的在于简单了解LDA的原理,为后⾯详细分析打下基础。
⼀、LDA的原理LDA的全称是Linear Discriminant Analysis(线性判别分析),是⼀种supervised learning。
LDA的原理:将带上标签的数据(点),通过投影的⽅法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,⼀簇⼀簇的情况,相同类别的点,将会在投影后的空间中更接近。
因为LDA是⼀种线性分类器。
对于K-分类的⼀个分类问题,会有K个线性函数:当满⾜条件:对于所有的j,都有Yk > Yj,的时候,我们就说x属于类别k。
上式实际上就是⼀种投影,是将⼀个⾼维的点投影到⼀条⾼维的直线上,LDA最求的⽬标是,给出⼀个标注了类别的数据集,投影到了⼀条直线之后,能够使得点尽量的按类别区分开,当k=2即⼆分类问题的时候,如下图所⽰:上图提供了两种⽅式,哪⼀种投影⽅式更好呢?从图上可以直观的看出右边的⽐左边的投影后分类的效果好,因此右边的投影⽅式是⼀种更好地降维⽅式。
LDA分类的⼀个⽬标是使得不同类别之间的距离越远越好,同⼀类别之中的距离越近越好。
⼆、LDA算法流程输⼊:数据集 D = {(x1, y1), (x1, y1), ... ,(x m, y m)},任意样本x i为n维向量,y i∈{C1, C2, ... , Ck},共k个类别。
现在要将其降维到d维;输出:降维后的数据集D'。
(1)计算类内散度矩阵 S B;(2)计算类间散度矩阵 S W;(3)将 S B和 S W代⼊上⾯公式计算得到特征值λ和特征向量 w,取前⾯⼏个最⼤的特征值向量λ'与特征向量相乘得到降维转换矩阵λ'w;(4)将原来的数据与转换矩阵相乘得到降维后的数据 (λ'w)T x ;三、LDA优缺点分析LDA算法既可以⽤来降维,⼜可以⽤来分类,但是⽬前来说,主要还是⽤于降维。


融合2DDCT、2DPCA和2DLDA的人脸识别方法廖正湘;陈元枝;李强【摘要】二维主分量分析(2DPCA)是人脸识别中的一种非常有效的特征提取方法.二维线性判别(2DLDA)方法具有很好的分类效果.在研究这两种理论的基础上提出一种基于2DDCT(二维离散余弦变换)与2DPCA+ 2DLDA相结合的人脸识别方法,并在0RL人脸库上分别对单一的方法与相融合的方法进行识别比较研究.实验结果表明,提出的方法不仅提高了识别率,而且减少了训练与分类时间.%Two-dimensional principal component analysis (2DPCA) is a very effective feature extraction method in face recognition; two-dimensional linear discriminant (2DLDA) method has very good classification results. In this paper, based on the study of these two theories, we propose a new face recognition method which is on the basis of integrating the two-dimensional discrete cosine transform (2DDCT) with 2DPCA and 2DLDA, and utilising the ORL database we carry out respectively the comparative study on recognitions with each single method and the integrated method. Experimental results show that the integrated method proposed in the paper improves the recognition rate, and it also reduces the training and classification time as well.【期刊名称】《计算机应用与软件》【年(卷),期】2012(029)009【总页数】4页(P237-239,288)【关键词】二维主分量分析;二维线性判别分析;特征提取;离散余弦变换【作者】廖正湘;陈元枝;李强【作者单位】桂林电子科技大学电子工程与自动化学院广西桂林541004;桂林电子科技大学电子工程与自动化学院广西桂林541004;桂林电子科技大学电子工程与自动化学院广西桂林541004【正文语种】中文【中图分类】TP391.410 引言人脸识别技术在身认证、视频监控等安防领域得到了广泛的应用,是生物特征识别系统中研究中的热门话题之一。


判别分析模型研究及应用判别分析模型是一种统计分析方法,用于解决分类问题。
其主要目标是通过对已知分类的样本进行学习,得出一个分类函数,然后通过应用这个分类函数对未知样本进行分类。
判别分析模型在许多领域中都得到广泛的应用,例如医学诊断、金融风险评估、文本分类等。
判别分析模型主要包括线性判别分析(Linear Discriminant Analysis,简称LDA)和二次判别分析(Quadratic Discriminant Analysis,简称QDA)两种。
LDA 假设样本的特征在每个类别中的分布服从正态分布,且各个类别的协方差矩阵相同。
LDA通过计算每个类别的均值向量和协方差矩阵,然后基于贝叶斯决策理论计算后验概率,从而得到分类函数。
QDA则放松了协方差矩阵相同的假设,允许每个类别有不同的协方差矩阵。
判别分析模型的研究主要围绕以下几个方面展开。
首先,模型的建立和求解是研究的重点之一。
在模型建立过程中,需要根据实际问题选择适当的判别准则和优化方法,以提高模型的分类性能。
其次,特征选择和降维也是研究的热点。
由于判别分析模型的性能受样本维度的影响,因此特征选择和降维可以提高模型的准确性和效率。
另外,与其他机器学习方法的集成也是一个重要的研究方向。
判别分析模型与支持向量机、神经网络等机器学习方法相结合,可以提高分类性能,拓展模型的应用范围。
判别分析模型在实际应用中具有广泛的应用价值。
一方面,它可以用于医学诊断,帮助医生识别疾病并制定治疗方案。
例如,通过对病人的病历、症状和检测结果进行分析,可以建立一个判别分析模型,用于区分正常人和疾病人群。
另一方面,判别分析模型也可以用于金融风险评估。
通过对客户的个人信息、信用记录和财务状况进行分析,可以建立一个判别分析模型,用于预测客户是否有违约的风险。
此外,判别分析模型还可以用于文本分类。
通过对文本的词频、词义和句法等进行分析,可以建立一个判别分析模型,用于将文本分类到不同的主题或类别。

基于二维局部保持鉴别分析的特征提取算法
卢官明;左加阔
【期刊名称】《南京邮电大学学报(自然科学版)》
【年(卷),期】2014(034)005
【摘要】提出了一种二维局部保持鉴别分析(Two-dimensional Locality Preserving Discriminant Analysis,2D-LPDA)特征提取算法.该算法直接对图像矩阵进行运算而不需要将矩阵转化为向量后进行运算,较好地保持了图像相邻像素之间的空间结构关系;在LPP算法的基础上,利用训练样本的类别信息计算二维类间散度矩阵和二维类内散度矩阵,并在2D-LPDA的目标函数中引入最大间距准则(Maximum Margin Criterion,MMC),从而求得具有良好鉴别能力的投影向量,同时还避免了小样本情况下矩阵的奇异性问题.通过在ORL人脸图像库上的人脸识别和新生儿面部图像库上的疼痛表情识别实验,验证了所提出的算法的有效性.
【总页数】8页(P1-8)
【作者】卢官明;左加阔
【作者单位】南京邮电大学通信与信息工程学院,江苏南京210003;台湾大学电机资讯学院,台湾台北10617;东南大学水声信号处理教育部重点实验室,江苏南京210096
【正文语种】中文
【中图分类】TN911.73;TP391.41
【相关文献】
1.人脸识别中基于熵的局部保持特征提取算法 [J], 刘金莲;王洪春
2.基于二维判别局部排列的特征提取算法 [J], 张向群;张旭
3.基于分块二维局部保持鉴别分析的二级人脸识别方法 [J], 赵春晖;陈才扣
4.基于改进局部保持映射的图像特征提取算法 [J], 刘靖
5.分块二维局部保持鉴别分析在人脸识别中的应用 [J], 赵春晖;陈才扣
因版权原因,仅展示原文概要,查看原文内容请购买。
Statistics and Application 统计学与应用, 2020, 9(1), 47-52Published Online February 2020 in Hans. /journal/sahttps:///10.12677/sa.2020.91006Dimension Reduction Comparison between PCA and LDALihong BaoYunnan University of Finance and Economics, Kunming YunnanReceived: Dec. 27th, 2019; accepted: Jan. 12th, 2020; published: Jan. 19th, 2020AbstractPrincipal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) are commonly used in machine learning. In this paper, we extend PCA and LDA to 2DPCA and 2DLDA, 2DPCA and 2DLDA are directly to reduce the dimension on the original matrix data structure, overcoming the problem of the curse of dimensionality. Empirical research suggests that 2DLDA is a better dimen-sionality reduction classification method than 2DPCA compared with the effect of dimension re-duction and the error rate of classification.KeywordsPCA, LDA, Matrix Data主成分分析与线性判别分析降维比较保丽红云南财经大学,云南昆明收稿日期:2019年12月27日;录用日期:2020年1月12日;发布日期:2020年1月19日摘要主成分分析(PCA)和线性判别分析(LDA)是机器学习领域中常用的降维方法。
判别分析方法汇总判别分析(Discriminant Analysis)是一种常用的统计分析方法,用于解决分类问题。
它是一种监督学习的方法,通过构建一个或多个线性或非线性函数来将待分类样本划分到已知类别的情况下。
判别分析方法广泛应用于模式识别、图像处理、数据挖掘、医学诊断等领域。
判别分析方法可以分为线性判别分析(Linear Discriminant Analysis, LDA)和非线性判别分析(Nonlinear Discriminant Analysis, NDA)两大类。
下面我们将介绍一些常见的判别分析方法。
1. 线性判别分析(LDA):LDA是判别分析方法中最常见的一种。
LDA假设每个类别的样本来自于多元正态分布,通过计算两个类别之间的Fisher判别值,构建一个线性函数,将待分类样本进行分类。
LDA的优点是计算简单、可解释性强,但它的缺点是对于非线性问题无法处理。
2. 二次判别分析(Quadratic Discriminant Analysis, QDA):QDA是LDA的一种扩展,它通过假设每个类别的样本来自于多元正态分布,但允许不同类别之间的协方差矩阵是不一样的。
这样,QDA可以处理协方差矩阵不同的情况,相比于LDA更加灵活,但计算复杂度较高。
3. 朴素贝叶斯分类器(Naive Bayes Classifier):朴素贝叶斯分类器是一种基于贝叶斯定理的分类方法。
它假设每个类别的样本属性之间是相互独立的,通过计算后验概率,选择具有最大概率的类别作为待分类样本的类别。
朴素贝叶斯分类器计算简单、速度快,但它对于属性之间有依赖关系的问题效果较差。
4. 支持向量机(Support Vector Machine, SVM):SVM是一种常用的判别分析方法,通过构建一个超平面,将不同类别的样本进行分类。
SVM的优点是能够处理非线性问题,且能够得到全局最优解。
但SVM计算复杂度较高,对于数据量较大的情况会有一定的挑战。
二维线性判别分析摘要线性判别分析(LDA)是一个常用的进行特征提取和降维的方法。
在许多涉及到高维数据,如人脸识别和图像检索的应用中被广泛使用。
经典的LDA方法固有的限制就是所谓的奇异性问题,即当所有的散列矩阵是奇异的时,它就不再适用了。
比较有名的解决奇异性问题的方法是在使用LDA方法之前先用主成分分析(PCA)对数据进行降维。
这个方法就叫做PCA+LDA,在人脸识别领域被广泛应用。
然而,由于涉及到散列矩阵的特征值分解,这个方法在时间和空间上都需要很高的成本。
在本文中,我们提出了一种新的LDA算法,叫做2D-LDA,即二维线性判别分析方法。
2D-LDA方法彻底解决了奇异性问题,并且具有很高的效率。
2D-LDA和经典LDA之间主要的区别在于数据表示模型。
经典LDA采用矢量表示数据,而2D-LDA使用矩阵表示数据。
我们对2D-LDA+LDA,即如何结合2D-LDA和经典LDA,在经典LDA之前使用2D-LDA进一步降维的问题进行了研究。
将本文提出的算法应用于人脸识别,并与PCA+LDA进行了比较。
实验表明:2D-LDA+LDA的方法识别更精确,并且效率更高。
1概述线性判别分析[2][4]是一个著名的特征提取和降维的方法。
已经被广泛应用于人脸识别[1]、图像检索[6]、微列阵数据分类[3]等应用中。
经典的LDA算法就是将数据投影到低维的向量空间,使类间距离和类内距离的比值最大化,从而得到最佳的分类效果。
最佳的投影方向可以通过散列矩阵的特征值分解计算得到。
经典LDA算法的一个限制是其目标函数的散列矩阵必须是奇异的。
对于许多应用了,如人脸识别,所有散列矩阵的问题都可以是奇异的,因为其数据都是高维的,并且通常矩阵的尺寸超过了数据点的额数目。
这就是所谓的“欠采样或奇异性问题[5]”。
近年来,许多用于解决这种高维、欠采样问题的方法被提出,包括伪逆LDA、PCA+LDA和正则LDA。
在文献[5]中可以了解更多细节。
机器学习:线性判别式分析(LDA)1.概述线性判别式分析(Linear Discriminant Analysis),简称为LDA。
也称为Fisher线性判别(Fisher Linear Discriminant,FLD),是模式识别的经典算法,在1996年由Belhumeur引⼊模式识别和⼈⼯智能领域。
基本思想是将⾼维的模式样本投影到最佳鉴别⽮量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的⼦空间有最⼤的类间距离和最⼩的类内距离,即模式在该空间中有最佳的可分离性。
LDA与PCA都是常⽤的降维技术。
PCA主要是从特征的协⽅差⾓度,去找到⽐较好的投影⽅式。
LDA更多的是考虑了标注,即希望投影后不同类别之间数据点的距离更⼤,同⼀类别的数据点更紧凑。
但是LDA有两个假设:1.样本数据服从正态分布,2.各类得协⽅差相等。
虽然这些在实际中不⼀定满⾜,但是LDA被证明是⾮常有效的降维⽅法,其线性模型对于噪⾳的鲁棒性效果⽐较好,不容易过拟合。
2.图解说明(图⽚来⾃⽹络)可以看到两个类别,⼀个绿⾊类别,⼀个红⾊类别。
左图是两个类别的原始数据,现在要求将数据从⼆维降维到⼀维。
直接投影到x1轴或者x2轴,不同类别之间会有重复,导致分类效果下降。
右图映射到的直线就是⽤LDA⽅法计算得到的,可以看到,红⾊类别和绿⾊类别在映射之后之间的距离是最⼤的,⽽且每个类别内部点的离散程度是最⼩的(或者说聚集程度是最⼤的)。
3.图解LAD与PCA的区别(图⽚来⾃⽹络)两个类别,class1的点都是圆圈,class2的点都是⼗字。
图中有两条直线,斜率在1左右的这条直线是PCA选择的映射直线,斜率在 -1左右的这条直线是LDA选择的映射直线。
其余不在这两条直线上的点是原始数据点。
可以看到由于LDA考虑了“类别”这个信息(即标注),映射后,可以很好的将class1和class2的点区分开。
D与PCA的对⽐(1)PCA⽆需样本标签,属于⽆监督学习降维;LDA需要样本标签,属于有监督学习降维。
2 二维线性鉴别分析(2DLDA )
2.1 实验原理
由上面的公式计算w G 和b G ,类似于经典的Fisher 准则,二维图像直接投影的广义Fisher 准则定义如下:
()T b T w X G X J X X G X
= 一般情况下w G 可逆,也就是根据1w b G G -计算本征值、本征向量,取最大的d 个本征值
对应的本征向量作为二维投影的向量组。
需要特别指出的是,尽管b G 和w G 都是对称矩阵,
但1w b G G -不一定是对称矩阵。
所以各投影轴之间关于w G 及t G 共轭正交,而不是正交。
本实验为简单起见,使用的为欧式距离。
2.2 实验过程
读取训练样本——〉求样本均值——〉求类内散布矩阵——〉特征值分解——〉对实验样本分类——〉计算分类正确率
2.3 实验结果分析
本实验中的类别数为40,每类的样本数为10,训练数为5,检测数为5。
实验的结果正确率为72%,结果正确率偏低。
2.4 matlab 代码
clear all;
t0=clock;
class_num = 40;
class_sample = 10;
train_num = 5;
test_num = 5;
scale = 1;
allsamples=[];%所有训练图像
gnd=[];
k=1;
path = ['C:\Documents and Settings\dongyan\桌面\模式识别\ORL\ORL\ORL'];
for i=1:class_num
for j =1:train_num
name =[path num2str(10*i+j-10,'%.3d') '.BMP' ];
[a,map]=imread(name,'bmp');
a = imresize(a,scale);
a=double(a);
ImageSize=size(a);
height=ImageSize(1);
width=ImageSize(2);
A=reshape(a,1,ImageSize(1)*ImageSize(2));
allsamples=[allsamples;A];
gnd(k)=i;
k=k+1;
end;
end;
trainData=allsamples;
sampleMean=mean(allsamples);%求所有图片的均值
[nSmp,nFea] = size(trainData);
classLabel = unique(gnd);
nClass = length(classLabel);
classmean=zeros(nClass,height*width);%求每类的均值
for i=1:nClass
index = find(gnd==classLabel(i));
classmean(i,:)=mean(trainData(index, :));
end
Gb=0;
Amean=reshape(sampleMean,height,width);%求类间散布矩阵Gb
for i=1:nClass
Aimean=reshape(classmean(i,:),height,width);
Gb=Gb+(Aimean-Amean)'*(Aimean-Amean);
end
Gw=0;%求类内散布矩阵
for i=1:nClass
for j=train_num*(i-1)+1:train_num*i
g=reshape((trainData(j,:)-classmean(i,:)),height,width);
Gw=Gw+g'*g;
end
end
invGw=inv(Gw);%求(Gw-1)*Gb
U=invGw*Gb;
[eigvu eigvet]=eig(U);%求特征值与特征向量
d=diag(eigvu);
[d1 index]=sort(d);
cols=size(eigvet,2);
for i=1:cols
vsort(:,i) = eigvet(:, index(cols-i+1) ); % vsort 是一个M*col阶矩阵,保存的是按降序排列的特征向量,每一列构成一个特征向量
dsort(i) = d( index(cols-i+1) ); % dsort 保存的是按降序排列的特征值,是一维行向量end %完成降序排列
for i=1:8
X(:,i)=vsort(:,i);%X表示投影轴
end
accu=0;%做测试,记录命中率
for i=1:class_num
for j =train_num+1:class_sample
name =[path num2str(10*i+j-10,'%.3d') '.BMP' ];
Image = double(imread(name));
Image = imresize(Image,scale);
testdata1=Image*X;
for k=1:class_num*train_num
juli(k)=norm(testdata1-reshape(trainData(k,:),height,width)*X);%计算图片与训练样本之间的距离,如果距离最小,认为测试图片与训练图片属于同一类
end;
[r t]=min(juli);
if fix((t-1)/train_num)==(i-1)
accu=accu+1;
end
end;
end;
accu=accu/(class_num*test_num);
accu
time1 = etime(clock,t0)。