第五节 数字视频压缩基础知识
- 格式:ppt
- 大小:308.50 KB
- 文档页数:71

数字电视视频压缩技术原理摘要:视频压缩通过减少和去除冗余视频数据的方式,达到有效发送和存储数字视频文件的目的。
在压缩过程中,需要应用压缩算法对源视频进行压缩以创建压缩文件,以便进行传输和存储。
要想播放压缩文件,则需要应用相反的解压缩算法对视频进行还原,还原后的视频内容与原始的源视频内容几乎完全相同。
压缩、发送、解压缩和显示文件所需的时间称为延时。
在相同处理能力下,压缩算法越高级,延时就越长。
传统的压缩编码是建立在香农(Shannon)信息论基础上的,它以经典的集合论为基础,用统计概率模型来描述信源,但它未考虑信息接受者的主观特性及事件本身的具体含义、重要程度和引起的后果。
因此,压缩编码的发展历程实际上是以香农信息论为出发点,一个不断完善的过程。
从不同角度考虑,数据压缩编码具有不同的分类方式。
按信源的统计特性可分为预测编码、变换编码、矢量量化编码、子带-小波编码、神经网络编码方法等。
数眼的视觉特性可能基于方向滤波的图像编码、基于图像轮廓-纹理的编码方法等。
按图像传递的景物特性可分为分形编码、基于内容的编码方法等。
视频压缩技术是计算机处理视频的前提。
视频信号数字化后数据带宽很高,通常在20MB/秒以上,因此计算机很难对之进行保存和处理。
采用压缩技术以后通常数据带宽右以降到1-10MB/秒,这样就可以将视频信号保存在计算机中并作相应的处理。
常用的算法是由ISO制订的,即JPEG和MPEG算法。
JPEG是静态图像压缩标准,适用于连续色调彩色或灰度图像,它包括两部分:一是基于DPCM(空间线性预测)技术的无失真编码,一是基于DCT(离散余弦变换)和哈夫曼编码的有失真算法,前者压缩比很小,主要应用的是后一种算法。
在非线性编辑中最常用的是MJPEG算法,即Motion JPEG。
它是将视频信号50帧/秒(PAL制式)变为25帧/秒,然后按照25帧/秒的速度使用JPEG算法对每一帧压缩。
通常压缩倍数在3.5-5倍时可以达到Betacam的图像质量。

数字视频基础知识数字视频是现代社会中广泛应用的一种媒体形式。
它以数字信号为基础,通过图像编码、传输和解码等技术,实现对视频图像的采集、处理和展示。
数字视频的应用领域涉及电视、电影、广告、网络视频等众多领域。
本文将介绍数字视频的基础知识,包括视频编码、视频格式、视频分辨率和帧率等方面。
一、视频编码数字视频的编码技术是将连续的视频图像序列转化为数字信号的过程。
常见的视频编码标准有MPEG-2、H.264、H.265等。
这些编码标准通过对图像进行压缩,实现了视频数据的高效传输和存储。
视频编码的核心原理是空间和时间的冗余性去除,即通过图像的相似性和相邻帧之间的相关性,减少视频数据的冗余程度。
二、视频格式视频格式是指数码视频文件的存储和传输格式。
常见的视频格式包括AVI、MOV、MP4、MKV等。
这些格式不仅包含视频数据,还可以携带音频数据、字幕等相关信息。
不同的视频格式适用于不同的应用场景,选择合适的视频格式可以提高视频的传输和播放效果。
三、视频分辨率视频分辨率是指视频图像的大小和清晰度程度,通常以像素为单位来表示。
常见的视频分辨率有1080p、720p、480p等。
数字视频的分辨率决定了图像的细节和清晰度,高分辨率的视频图像能够更真实地还原真实场景,但也需要更大的存储和传输带宽。
四、帧率帧率是指视频中每秒显示的图像帧数。
常见的帧率有24fps、30fps、60fps等。
帧率的选择直接影响到视频图像的流畅度和感官效果。
较低的帧率可能导致视频卡顿和画面不连贯,而较高的帧率则能够呈现出更加细腻和流畅的动态效果。
五、视频编解码器视频编解码器是视频编码和解码的工具软件或硬件。
常见的视频编解码器有X264、X265、FFmpeg等。
视频编解码器的作用是将视频数据进行压缩编码和解码还原,实现视频文件的传输和播放。
六、数字视频的应用数字视频在现代社会中有着广泛的应用。
电视、电影、广告等传统媒体领域,数字视频成为了主流媒体形式。
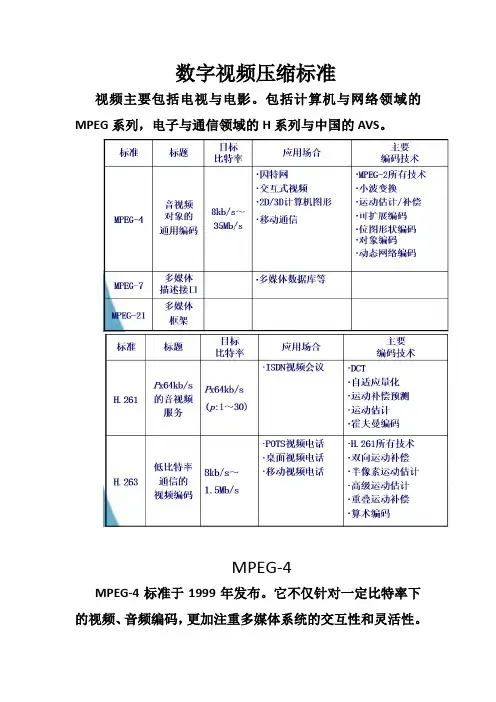
数字视频压缩标准视频主要包括电视与电影。
包括计算机与网络领域的MPEG系列,电子与通信领域的H系列与中国的AVS。
MPEG-4MPEG-4标准于1999年发布。
它不仅针对一定比特率下的视频、音频编码,更加注重多媒体系统的交互性和灵活性。
这标准主要应用于视像电话、视像电子邮等,对传输速率要求较低,在4800-6400bit/s之间,分辨率为176×144。
MPEG-4利用很窄的带宽,通过帧重建技术、数据压缩,以求用最少的数据获得最佳的图像质量。
利用MPEG-4的高压缩率和高的图像还原质量可以把DVD里面的MPEG-2视频文件转换为体积更小的视频文件。
经过这样处理,图像的视频质量下降不大,但数据可缩小几倍,可以很方便地用CD-ROM来保存DVD上的数据。
MPEG-4以对象为基本编码单位,对一系列VOP的纹理、形状和运动信息进行编码。
首先编码器的对象分割单元分析输入视频,按照方法把视频分割成多个VO,然后编码器对每个视频对象VOP进行纹理、形状和运动信息编码,最终利用码流复用器组织码流。
整个图像可以分解为多个目标,目标分割是最困难的地方,但并不需要标准。
目标由形状,运动和纹理描述,形状和纹理随着时间改变而改变。
MPEG假定编码器有一个分割图,知道如何编码形状,运动和纹理,视频对象平面是MPEG-4视频压缩处理的基本单元。
一个视频对象平面由一个矩形窗(如图所示的VOP窗)框定,矩形窗包含了组成视频对象平面的最少数量的宏块。
图1中的参考窗是原始帧的大小,VOP窗是MPEG-4编码前的处理得到的最小矩形窗,图中还标定了宏块的三种类型:外部宏块,边缘宏块和内部宏块。
VOP填充模块为了支持基于对象的编码,MPEG-4标准引入了视频对象平面(VOP)的概念与以前的视频压缩MPEG-1、MPEG-2标准一样,MPEG-4也采用了运动预测补偿技术来消除视频序列中的时间冗余。
这个过程包括一个搜索算法用于搜索被编码宏块(块)在参考帧中最好的匹配。



知识讲堂:视频压缩基本原理
视频编解码器
在压缩过程中,需要应用压缩算法对源视频进行压缩以创建压缩文件,
以便进行传输和存储。
要想播放压缩文件,则需要应用相反的解压缩算法对视频进行还原,还原后的视频内容与原始的源视频内容几乎完全相同。
文件压缩、传送、解压和显示所需的时间称为时延。
压缩算法越高级,时延就越长。
视频编解码器(编码器/解码器)是指两个协同运行的压缩-解压算法。
使用
不同标准的视频编解码器通常彼此之间互不兼容;也就是说,使用一种标准进行压缩的视频内容无法使用另外一种标准进行解压缩。
例如,MPEG-4 Part 2 解码
器就不能与H.264 编码器协同运行。
这是因为一种算法无法正确地对另外一个算法的输出信号进行解码,然
而我们可以在同一软件或硬件中使用多种不同的算法,实现多种格式共存。
图像压缩与视频压缩
由于不同的视频压缩标准会使用不同的方法来减少数据量,因此压缩结
果在比特率、质量和时延方面也各不相同。
图像压缩采用帧内编码技术。
这种技术通过删除肉眼看不到的无关信息,仅压缩一帧图像内的数据。
M-JPEG 是这种压缩标准的一个例子。
M-JPEG 序列
中的图像按单个JPEG 图像进行编码或压缩。
[nextpage]
视频压缩算法,如MPEG-4 和H.264 等,采用帧内预测模式压缩一系列
帧之间的数据。
这种算法涉及多种技术,如差分编码,一帧与参考帧进行比较,。

视频压缩技术视频压缩技术是一项重要的数字媒体处理技术,它可以将大尺寸、高解析度的视频文件压缩为更小的文件大小,从而方便存储、传输和播放。
随着数字媒体应用的广泛普及,视频压缩技术在各个领域得到了广泛的应用,如在线视频、视频会议、数字电视等。
本文将介绍视频压缩技术的原理、常见的视频压缩算法以及其在不同领域的应用。
视频压缩技术的原理在于利用人眼对视频中的细节变化不敏感的特点,通过删除冗余信息和减少数据量来达到压缩的目的。
视频压缩可以分为有损压缩和无损压缩两种方式。
有损压缩技术通过牺牲视频质量来达到更高的压缩比,而无损压缩技术则可以保持原始视频的质量,但压缩率较低。
常见的视频压缩算法包括基于变换编码的方法和基于预测编码的方法。
在变换编码中,将视频的空间域信号转换为频率域信号,并对频率分量进行量化和编码。
离散余弦变换(DCT)是最常用的变换编码方法之一,它能将视频信号在频域上进行压缩。
在预测编码中,根据视频帧之间的相关性进行预测,并将预测误差编码。
运动补偿是预测编码的关键技术之一,通过对视频帧中的运动进行建模和估计,可以减少预测误差,从而提高压缩效果。
视频压缩技术在各个领域都有着广泛的应用。
在在线视频领域,视频压缩技术可以将大尺寸的视频文件压缩为较小的文件大小,以满足网络传输的带宽限制。
同时,视频压缩技术还可以根据用户的带宽和设备能力,动态选择合适的压缩算法和参数,以提供更好的用户体验。
在视频会议领域,视频压缩技术可以将多个参与者的视频流进行压缩和传输,以实现实时视频通信。
在数字电视领域,视频压缩技术可以将高清视频信号压缩为标清信号,以适应不同类型的接收设备。
总之,视频压缩技术是一项重要的数字媒体处理技术,它可以将大尺寸、高解析度的视频文件压缩为更小的文件大小,以方便存储、传输和播放。
视频压缩技术的原理主要包括变换编码和预测编码两种方法,通过删除冗余信息和减少数据量来实现压缩。
视频压缩技术在各个领域都有着广泛的应用,如在线视频、视频会议和数字电视等。

视频压缩技术视频压缩技术的发展在数字媒体时代具有重要意义。
视频压缩技术通过减少视频数据的冗余性,实现了视频文件的压缩和传输。
本文将介绍视频压缩技术的原理、分类和应用,并探讨其对数字媒体领域的影响。
首先,视频压缩技术的原理是利用人眼对视频细节的感知有限性。
视频是由一系列的连续画面组成的,每秒钟播放的画面数量称为帧率。
为了降低视频数据的存储空间和传输带宽的要求,视频压缩技术可以通过减少帧率、减少每帧的像素数、减少每帧的颜色数等方式来达到压缩效果。
视频压缩技术可以分为有损压缩和无损压缩两种。
有损压缩通过牺牲视频质量来达到更高的压缩比,常见的有损压缩算法有MPEG、H.264等。
无损压缩则保留了原始视频的全部信息,但压缩比较低,适用于对视频质量要求较高的场景。
视频压缩技术在数字媒体领域有广泛的应用。
首先是视频传输领域,通过压缩技术可以实现高清视频的实时传输。
在互联网视频直播和视频会议等场景中,视频压缩技术能够有效降低网络传输带宽的要求,提升用户体验。
其次是视频存储领域,通过压缩技术可以减少视频文件的存储空间,提高存储效率。
这对于视频网站和影视公司等需要大量存储视频文件的机构来说非常重要。
视频压缩技术的发展对数字媒体领域产生了深远的影响。
首先是视频内容的丰富性提升,由于视频压缩技术的发展,用户可以更轻松地上传和分享高质量的视频内容。
这促进了视频社交媒体的兴起,使得用户在日常生活中能够更加方便地记录和分享自己的经历。
其次是视频应用的普及,视频压缩技术的成熟使得视频应用进入了普通用户的生活,例如在线教育、电子商务、远程医疗等领域都广泛应用了视频技术。
总结而言,视频压缩技术的发展为数字媒体领域带来了许多便利和机遇。
通过优化视频文件的压缩和传输,视频压缩技术提升了视频内容的丰富性,推动了视频社交媒体的发展。
另外,视频压缩技术的应用也丰富了数字媒体的应用场景,提升了用户体验。
因此,视频压缩技术对于数字媒体领域的重要性不言而喻。

视频压缩的基本概念视频压缩基本概念视频压缩的目标是在尽可能保证视觉效果的前提下减少视频数据率。
视频压缩比一般指压缩后的数据量与压缩前的数据量之比。
由于视频是连续的静态图像,因此其压缩编码算法与静态图像的压缩编码算法有某些共同之处,但是运动的视频还有其自身的特性,因此在压缩时还应考虑其运动特性才能达到高压缩的目标。
在视频压缩中常需用到以下的一些基本概念:(一)、有损和无损压缩:在视频压缩中有损(Lossy )和无损(Lossless)的概念与静态图像中基本类似。
无损压缩也即压缩前和解压缩后的数据完全一致。
多数的无损压缩都采用RLE行程编码算法。
有损压缩意味着解压缩后的数据与压缩前的数据不一致。
在压缩的过程中要丢失一些人眼和人耳所不敏感的图像或音频信息,而且丢失的信息不可恢复。
几乎所有高压缩的算法都采用有损压缩,这样才能达到低数据率的目标。
丢失的数据率与压缩比有关,压缩比越小,丢失的数据越多,解压缩后的效果一般越差。
此外,某些有损压缩算法采用多次重复压缩的方式,这样还会引起额外的数据丢失。
(二)、帧内和帧间压缩:帧内(Intraframe)压缩也称为空间压缩(Spatial compression)。
当压缩一帧图像时,仅考虑本帧的数据而不考虑相邻帧之间的冗余信息,这实际上与静态图像压缩类似。
帧内一般采用有损压缩算法,由于帧内压缩时各个帧之间没有相互关系,所以压缩后的视频数据仍可以以帧为单位进行编辑。
帧内压缩一般达不到很高的压缩。
采用帧间(Interframe)压缩是基于许多视频或动画的连续前后两帧具有很大的相关性,或者说前后两帧信息变化很小的特点。
也即连续的视频其相邻帧之间具有冗余信息,根据这一特性,压缩相邻帧之间的冗余量就可以进一步提高压缩量,减小压缩比。
帧间压缩也称为时间压缩(T emporal compression),它通过比较时间轴上不同帧之间的数据进行压缩。
帧间压缩一般是无损的。
帧差值(Frame differencing)算法是一种典型的时间压缩法,它通过比较本帧与相邻帧之间的差异,仅记录本帧与其相邻帧的差值,这样可以大大减少数据量。

什么是视频压缩视频压缩是一种通过减少视频数据量和优化编码算法来减小视频文件大小的技术。
在现代数字化社会中,视频成为了人们记录和分享生活的重要方式之一。
然而,由于高分辨率、高帧率和更复杂的编码标准,视频文件的大小也在迅速增长。
为了解决这个问题,视频压缩技术应运而生。
1. 视频压缩的原理视频压缩的基本原理是通过删除或减少视频中的冗余信息和不可察觉的细节来减小文件大小。
这些信息可以是人眼无法察觉的颜色变化或细小的运动。
视频压缩技术利用人眼对动态图像的特性以及观看视频时对画面质量的感知差异,将其应用于编码算法中。
2. 视频压缩的流程视频压缩是一个复杂的过程,一般包括以下几个步骤:(1)采样:采集视频信号并将其分解为连续的图像帧。
(2)预处理:对每一帧图像进行去噪、颜色空间转换和图像增强等处理,以提高图像质量。
(3)编码:将每一帧图像转换为数字数据,并通过编码算法将其压缩成更小的文件。
(4)解码:将压缩后的视频文件解码,还原成可识别的数字数据。
(5)重建:将解码后的数字数据重新构建成连续的图像帧。
(6)显示:将重建的图像帧以恢复的形式显示在观众面前。
3. 常见的视频压缩算法(1)基于帧间预测的压缩算法:针对视频序列中帧之间的相关性,利用前一帧或其他关键帧的信息进行差别编码,以减少冗余数据量。
(2)基于变换编码的压缩算法:通过将视频帧转换为频域中的系数,再根据系数的重要性进行量化和编码,以达到压缩的目的。
(3)基于运动估计的压缩算法:利用视频帧之间的运动信息,通过估计和描述物体在时间上的移动来减少信息冗余。
(4)基于空间域和频域的压缩算法:综合运用空间域和频域中的信息,对视频进行压缩,以提高压缩效率和图像质量。
4. 常见的视频压缩标准(1)MPEG标准:有MPEG-1、MPEG-2、MPEG-4等不同版本,其中MPEG-4具有较高的压缩比和较好的图像质量,广泛应用于互联网视频传输和存储。
(2)H.264/AVC:是一种基于块的视频压缩标准,具有更好的图像质量和更高的压缩比,被广泛应用于数字电视、高清视频和蓝光光盘等领域。
视频压缩视频压缩又称视频编码,所谓视频编码方式就是指通过特定的压缩技术,将某个视频格式的文件转换成另一种视频格式文件的方式。
一般的通用数据压缩方案如下图:压缩就是一个传播的过程,所以在压缩与解压缩之间,没有信号的丢失则称这种压缩就是无损的,相反的就是有损的,都有各自的算法,下面介绍。
无损压缩算法一游长编码(Run-Length Coding, RLC)产生年代:未知。
主要人物:未知。
基本思想:如果我们压缩的信息源中的符号具有这样的连续的性质,即同一个符号常常形成连续的片段出现,那么我们可以对这个符号片段长度进行这样的的编码。
例子:输入:5555557777733322221111111游长编码为:(5,6)(7,5)(3,3)(2,4)(l,7)二变长编码:1 香农-凡诺算法产生年代:未知主要人物:Shannon 和Robert Fano基本思想:对于每个符号出现的频率对符号进行排序,递归的将这些符号分成两部分,每一部分有相近的频率,知道只有一个符号未止。
说明:过程用一颗二叉树完成,它是一种自顶向下的过程,对于此输入5个字符则自然的分成2,3左右两子树,接着就是递归的过程。
因为分法不唯一,所以下列输出是一种情况。
例子:输入:HELLO输出:10 110 0 0 111(左子树标0)2赫夫曼编码产生年代:1952年主演人物:David A.Huffman基本思想:与香农-凡诺算法的区别在于,赫夫曼编码采用的是一种自下而上的描述方式,先从符号的频率中选取最小的两个符号,合成一个新的结点,进行等效的代替,然后也是个递归过程。
说明:赫夫曼编码具有唯一的前缀性质和最优性。
例子:对于输入:HELLO 建立的一刻赫夫曼树 扩展:扩展的赫夫曼编码,这是相对于数据中某个符号的概率较大(接近1.0)时,将几个符号组成组,然后为整个组赋予一个码字。
自适应的赫夫曼编码,这是一个边接收边编码的过程,完全的体现了适应的过程,需要对二叉树进行改变,由接收到的数据去添加进二叉树中,自动生成新的“赫夫曼树”。
数字视频基础知识5 、视频压缩(1 )数据压缩:是将一个文件的数据容量减小,而又基本保持原来文件的内容。
(2 )数据压缩的依据空间冗余:如图像中有许多颜色相同或相近的连续像素组成的区域,像素间具有强相关性. 时间冗余:序列图像中,相邻帧间有强相关性。
视觉冗余:图像的某些信息超出人眼的接受力。
结构冗余:图像存在明显分布状态知识冗余:有些图像的结构可由先验知识或背景知识得到。
(3 )数据压缩的类型无损压缩:解压后的数据可以完全复原。
一般利用数据之间的相关性,将相同或相似的数据特征归类,以减少数据量。
如基于空间冗余或时间冗余。
有损压缩:解压后的数据不能完全复原。
一般利用人的视觉和听觉的特性,针对性地简化不重要的信息,以减少数据。
如基于视觉冗余。
(5 )视频压缩视频压缩:指以尽可能少的比特数代表视频中所包含信息的技术。
数字视频的来源利用计算机生成,如3Dmax 、PR 利用数码摄像机进行拍摄并获取通过视频采集卡把模拟视频转换为数字视频模拟视频的数字化:采样:每秒采多少幅画面,每幅画面采多少个点量化:编码压缩:采用一定格式记录数据、压缩回放时:解压缩-还原多媒体数据的压缩、解压缩过程:多媒体-压缩-存储-传输-解压缩-还原思考:模拟音频数字化的过程?采样:每秒采多少个点采样频率量化:编码压缩:采用一定格式记录数据、压缩回放时:解压缩-还原(6 )常见的视频压缩方式mpg 文件压缩方式: (MPEG :moving picture experts group )MPEG-1 标准(1991) MPEG-2 标准(1993) MPEG-4 多媒体交互新标准:MP4 (1999) MPEG-1 与MPEG-2 标准推出后,工作组试图推出MPEG-3 标准以支持数字电视的应用。
但发现MPEG-2 已能很好地胜任这一工作,于是取消了MPEG-3 。
MP3 就是一种音频压缩技术,由于这种压缩方式的全称叫MPEG Audio Layer3 ,所以人们把它简称为MP3 。