运用stata进行时间序列分析
- 格式:doc
- 大小:58.00 KB
- 文档页数:8




stata时间序列回归步骤命令1.引言1.1 概述概述部分的内容:时间序列回归是一种经济学和统计学领域中常用的分析方法,用于研究随时间变化的因果关系。
它涉及使用时间上的观测数据来分析自变量和因变量之间的关系,并预测未来的值。
Stata是一种功能强大的统计软件,广泛用于数据分析和经济研究。
在Stata中,有一系列的命令可供使用,用于进行时间序列回归分析。
本文将介绍使用Stata进行时间序列回归分析的步骤和相应的命令。
通过学习这些命令,读者将能够熟练地使用Stata进行时间序列回归分析,并获得准确和可靠的结果。
本文主要包括以下章节内容:1. 引言部分介绍了时间序列回归的概述、文章结构和目的,旨在帮助读者全面了解本文内容。
2. 正文部分将详细介绍时间序列回归的概念和原理,并介绍Stata中的时间序列回归命令。
这些命令包括数据准备、建立模型、模型估计和统计推断等步骤。
3. 结论部分对本文进行总结,并展望时间序列回归在未来的应用前景。
同时,还会指出时间序列回归分析中可能存在的局限性,以及可能的改进方向。
通过本文的学习,读者将了解时间序列回归分析的基本概念和步骤,掌握对时间序列数据进行回归分析的方法和技巧,并能够运用Stata软件进行实际的分析工作。
1.2文章结构文章结构(Article Structure)本文将按照以下结构进行叙述。
第一部分为引言部分,目的是对时间序列回归步骤命令进行一个概述,并说明本文的目的。
接下来,第二部分将详细介绍时间序列回归的概念和一般步骤,并使用stata命令进行说明。
同时,本文还将重点介绍两个关键要点,这些要点对于正确进行时间序列回归分析非常重要。
最后,第三部分为结论,将总结本文的主要内容,并展望一下未来可能的研究方向。
在正文部分,我们将首先概述时间序列回归的基本概念,并提供了一个对该方法的整体认识。
然后,我们将详细介绍stata时间序列回归步骤命令的使用方法,包括数据导入、变量设定、模型拟合和结果解释等。


stata时间序列分解法预测
Stata是一种广泛使用的统计和数据分析软件,它提供了多种时间序列分析工具,包括时间序列分解法。
时间序列分解法是一种将时间序列数据分解为趋势、季节性和随机波动成分的方法,通过这种方法可以更好地理解数据的长期趋势和短期波动,并提高预测的准确性。
在Stata中进行时间序列分解的步骤如下:
1.导入数据:首先需要将时间序列数据导入到Stata中。
可以使用use
命令或import命令来导入数据。
2.平稳化处理:在进行时间序列分解之前,需要对数据进行平稳化处
理,以消除趋势和季节性成分。
可以使用tsset命令来设置时间变
量,并使用diff命令或coseal命令来进行差分或对数转换等处
理。
3.分解模型:使用tsls命令或tsomp命令来估计分解模型。
这些命
令将使用最小二乘法或加权最小二乘法来估计趋势、季节性和随机波动成分。
4.预测:在估计出分解模型后,可以使用predict命令来生成预测
值。
可以选择不同的预测期限,并指定要预测的成分(如趋势、季节性或随机波动)。
通过以上步骤,可以使用Stata的时间序列分解法对时间序列数据进行预测,并提高预测的准确性。

运用stata进行时间序列分析1 时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着Box and Jenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令1.1时间序列数据的处理1)声明时间序列:tsset 命令use gnp96.dta, clear list in 1/20 gen Lgnp = L.gnp tsset date list in 1/20 gen Lgnp = L.gnp 2)检查是否有断点:tsreport, report use gnp96.dta, clear tsset date tsreport, report drop in 10/10 list in 1/12 tsreport, report tsreport, report list /*列出存在断点的样本信息*/ 3)填充缺漏值:tsfill tsfill tsreport, report list list in 1/12 4)追加样本:tsappend use gnp96.dta, clear tsset date list in -10/-1 sum tsappend , add(5)/*追加5个观察值*/ list in -10/-1 sum 2 5)应用:样本外预测:predict reg gnp96 L.gnp96 predict gnp_hat list in -10/-1 6)清除时间标识:tsset, clear tsset, clear 1.2变量的生成与处理1)滞后项、超前项和差分项help tsvarlist use gnp96.dta, clear tsset date gen Lgnp = L.gnp96 /*一阶滞后*/ gen L2gnp = L2.gnp96 gen Fgnp = F.gnp96 /*一阶超前*/ gen F2gnp= F2.gnp96 gen Dgnp = D.gnp96 /*一阶差分*/ gen D2gnp = D2.gnp96 list in 1/10 list in -10/-1 2)产生增长率变量:对数差分gen lngnp = ln(gnp96)gen growth = D.lngnp gen growth2 = (gnp96-L.gnp96)/L.gnp96 gen diff = growth - growth2 /*表明对数差分和变量的增长率差别很小*/ list date gnp96 lngnp growth* diff in 1/10 1.3日期的处理日期的格式help tsfmt 基本时点:整数数值,如-3, -2, -1, 0, 1, 2, 3 .... 1960年1月1日,取值为0;3 显示格式:定义含义默认格式%td 日%tdDlCY %tw 周%twCY!ww %tm 月%tmCY!mn %tq 季度%tqCY!qq %th 半年%thCY!hh %ty 年%tyCY 1)使用tsset 命令指定显示格式use B6_tsset.dta, clear tsset t, daily list use B6_tsset.dta, clear tsset t, weekly list 2)指定起始时点cap drop month generate month = m(1990-1)+ _n - 1 format month %tm list t month in 1/20 cap drop year gen year = y(1952)+ _n - 1 format year %ty list t year in 1/20 3)自己设定不同的显示格式日期的显示格式%d (%td)定义如下:%[-][t]d<描述特定的显示格式> 具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符c y m l n d j h q w _ . , :- / ' !c C Y M L N D J W 定义如下:c and C 世纪值(个位数不附加/附加0)y and Y 不含世纪值的年份(个位数不附加/附加0)m 三个英文字母的月份简写(第一个字母大写)4 M 英文字母拼写的月份(第一个字母大写)n and N 数字月份(个位数不附加/附加0)d and D 一个月中的第几日(个位数不附加/附加0)j and J 一年中的第几日(个位数不附加/附加0)h 一年中的第几半年(1 or 2)q 一年中的第几季度(1, 2, 3, or 4)w and W 一年中的第几周(个位数不附加/附加0)_ display a blank (空格). display a period(句号), display a comma(逗号):display a colon(冒号)- display a dash (短线)/ display a slash(斜线)' display a close single quote(右引号)!c display character c (code !!to display an exclamation point)样式1:Format Sample date in format ----------------------------------- %td07jul1948 %tdM_d,_CY July 7, 1948 %tdY/M/D 48/07/11 %tdM-D-CY 07-11-1948 %tqCY.q 1999.2 %tqCY:q 1992:2 %twCY,_w 2010, 48 ----------------------------------- 样式2:Format Sample date in format ---------------------------------- %d 11jul1948 %dDlCY 11jul1948 %dDlY 11jul48 %dM_d,_CY July 11, 1948 %dd_M_CY 11 July 1948 %dN/D/Y 07/11/48 %dD/N/Y 11/07/48 %dY/N/D 48/07/11 %dN-D-CY 07-11-1948 ---------------------------------- clear set obs 100 5 gen t = _n + d(13feb1978)list t in 1/5 format t %dCY-N-D /*1978-02-14*/ list t in 1/5 format t %dcy_n_d /*1978 2 14*/ list t in 1/5 use B6_tsset, clear list tsset t, format(%twCY-m)list 4)一个实例:生成连续的时间变量use e1920.dta, clear list year month in 1/30 sort year month gen time = _n tsset time list year month time in 1/30 generate newmonth = m(1920-1)+ time - 1 tsset newmonth, monthly list year month time newmonth in 1/30 1.4图解时间序列1)例1:clear set seed 13579113 sim_arma ar2, ar(0.7 0.2)nobs(200)sim_arma ma2, ma(0.7 0.2)tsset _t tsline ar2 ma2 * 亦可采用twoway line 命令绘制,但较为繁琐twoway line ar2 ma2 _t 2)例2:增加文字标注sysuse tsline2, clear tsset daytsline calories, ttick(28nov2002 25dec2002, tpos(in))/// ttext(3470 28nov2002 "thanks" /// 3470 25dec2002 "x-mas", orient(vert))6 3)例3:增加两条纵向的标示线sysuse tsline2, clear tsset day tsline calories, tline(28nov2002 25dec2002)* 或采用twoway line 命令local d1 = d(28nov2002)local d2 = d(25dec2002)line calories day, xline(`d1' `d2')4)例4:改变标签tsline calories, tlabel(, format(%tdmd))ttitle("Date (2002)")tsline calories, tlabel(, format(%td))二、ARIMA 模型和SARMIA模型ARIMA模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。

时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着Box and Jenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令1.1时间序列数据的处理1)声明时间序列:tsset 命令use gnp96.dta, clearlist in 1/20gen Lgnp = L.gnptsset datelist in 1/20gen Lgnp = L.gnp2)检查是否有断点:tsreport, reportuse gnp96.dta, cleartsset datetsreport, reportdrop in 10/10list in 1/12tsreport, reporttsreport, report list /*列出存在断点的样本信息*/3)填充缺漏值:tsfilltsfilltsreport, report listlist in 1/124)追加样本:tsappenduse gnp96.dta, cleartsset datelist in -10/-1sumtsappend , add(5) /*追加5个观察值*/list in -10/-1sum5)应用:样本外预测: predictreg gnp96 L.gnp96predict gnp_hatlist in -10/-16)清除时间标识: tsset, cleartsset, clear1.2变量的生成与处理1)滞后项、超前项和差分项 help tsvarlistuse gnp96.dta, cleartsset dategen Lgnp = L.gnp96 /*一阶滞后*/gen L2gnp = L2.gnp96gen Fgnp = F.gnp96 /*一阶超前*/gen F2gnp = F2.gnp96gen Dgnp = D.gnp96 /*一阶差分*/gen D2gnp = D2.gnp96list in 1/10list in -10/-12)产生增长率变量: 对数差分gen lngnp = ln(gnp96)gen growth = D.lngnpgen growth2 = (gnp96-L.gnp96)/L.gnp96gen diff = growth - growth2 /*表明对数差分和变量的增长率差别很小*/ list date gnp96 lngnp growth* diff in 1/101.3日期的处理日期的格式 help tsfmt基本时点:整数数值,如 -3, -2, -1, 0, 1, 2, 3 ....1960年1月1日,取值为 0;1)使用 tsset 命令指定显示格式use B6_tsset.dta, cleartsset t, dailylistuse B6_tsset.dta, cleartsset t, weeklylist2)指定起始时点cap drop monthgenerate month = m(1990-1) + _n - 1format month %tmlist t month in 1/20cap drop yeargen year = y(1952) + _n - 1format year %tylist t year in 1/203)自己设定不同的显示格式日期的显示格式 %d (%td) 定义如下:%[-][t]d<描述特定的显示格式>具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符c y m l nd j h q w _ . , : - / ' !cC Y M L ND J W定义如下:c and C 世纪值(个位数不附加/附加0)y and Y 不含世纪值的年份(个位数不附加/附加0)m 三个英文字母的月份简写(第一个字母大写) M 英文字母拼写的月份(第一个字母大写)n and N 数字月份(个位数不附加/附加0)d and D 一个月中的第几日(个位数不附加/附加0)j and J 一年中的第几日(个位数不附加/附加0)h 一年中的第几半年 (1 or 2)q 一年中的第几季度 (1, 2, 3, or 4)w and W 一年中的第几周(个位数不附加/附加0)_ display a blank (空格). display a period(句号), display a comma(逗号): display a colon(冒号)- display a dash (短线)/ display a slash(斜线)' display a close single quote(右引号)!c display character c (code !! to display an exclamation point)样式1:Format Sample date in format-----------------------------------%td 07jul1948%tdM_d,_CY July 7, 1948%tdY/M/D 48/07/11%tdM-D-CY 07-11-1948%tqCY.q 1999.2%tqCY:q 1992:2%twCY,_w 2010, 48-----------------------------------样式2:Format Sample date in format----------------------------------%d 11jul1948%dDlCY 11jul1948%dDlY 11jul48%dM_d,_CY July 11, 1948%dd_M_CY 11 July 1948%dN/D/Y 07/11/48%dD/N/Y 11/07/48%dY/N/D 48/07/11%dN-D-CY 07-11-1948----------------------------------clearset obs 100gen t = _n + d(13feb1978)list t in 1/5format t %dCY-N-D /*1978-02-14*/list t in 1/5format t %dcy_n_d /*1978 2 14*/list t in 1/5use B6_tsset, clearlisttsset t, format(%twCY-m)list4)一个实例:生成连续的时间变量use e1920.dta, clearlist year month in 1/30sort year monthgen time = _ntsset timelist year month time in 1/30generate newmonth = m(1920-1) + time - 1tsset newmonth, monthlylist year month time newmonth in 1/301.4图解时间序列1)例1:clearset seed 13579113sim_arma ar2, ar(0.7 0.2) nobs(200)sim_arma ma2, ma(0.7 0.2)tsset _ttsline ar2 ma2* 亦可采用 twoway line 命令绘制,但较为繁琐twoway line ar2 ma2 _t2)例2:增加文字标注sysuse tsline2, cleartsset daytsline calories, ttick(28nov2002 25dec2002, tpos(in)) /// ttext(3470 28nov2002 "thanks" ///3470 25dec2002 "x-mas", orient(vert)) 3)例3:增加两条纵向的标示线sysuse tsline2, cleartsset daytsline calories, tline(28nov2002 25dec2002) * 或采用 twoway line 命令 local d1 = d(28nov2002) local d2 = d(25dec2002)line calories day, xline(`d1' `d2')4)例4:改变标签tsline calories, tlabel(, format(%tdmd)) ttitle("Date (2002)") tsline calories, tlabel(, format(%td))二、ARIMA 模型和SARMIA 模型ARIMA 模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。
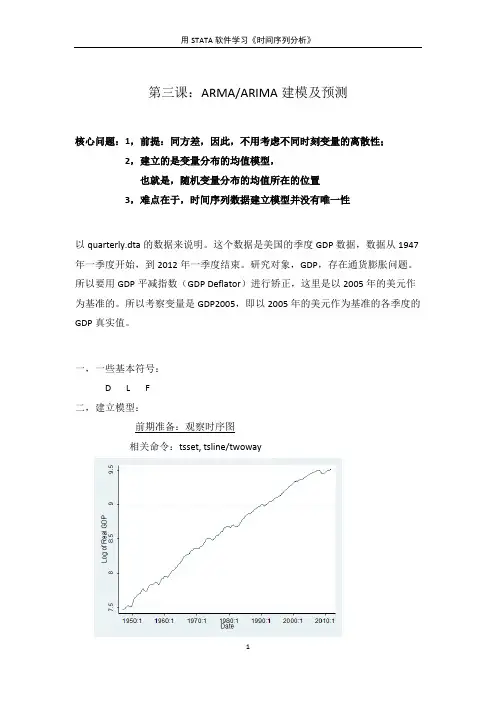
用STATA软件学习《时间序列分析》第三课:ARMA/ARIMA建模及预测核心问题:1,前提:同方差,因此,不用考虑不同时刻变量的离散性;2,建立的是变量分布的均值模型,也就是,随机变量分布的均值所在的位置3,难点在于,时间序列数据建立模型并没有唯一性以quarterly.dta的数据来说明。
这个数据是美国的季度GDP数据,数据从1947年一季度开始,到2012年一季度结束。
研究对象,GDP,存在通货膨胀问题。
所以要用GDP平减指数(GDP Deflator)进行矫正,这里是以2005年的美元作为基准的。
所以考察变量是GDP2005,即以2005年的美元作为基准的各季度的GDP真实值。
一,一些基本符号:D L F二,建立模型: 前期准备:观察时序图相关命令:tsset, tsline/twoway用STATA 软件学习《时间序列分析》从图上可以看出,GDP2005值呈线性的向右上方倾斜,第一种方法:可以用确定性分析理的方法,使用研究变量对时间变量进行回归 即:regress lrgdp date (采用的是最小二乘估计)然后对残差项进行White Noise 检验观察此图:特征大值跟大值,小值跟小值,这说明Residual 中存在着自相关信息。
肯定不是White Noise因此,从这里看出,确定性的方法比较直观,简单,但效果不好,弥补:对残差序列进行回归,建立AR 模型,这就是所谓的 残差自回归模型。
第二种方法BOX-JENKINS 方法,也就是通常所说的ARMA(p,d) /ARIMA(p,d,d)建模(采用的是最大似然估计)。
四大步骤:1、模型识别Identification :决定p 和q 2、模型估计Estimation :估计εσθφμ 个),(,个)(,q p 3、模型检验Diagnostic Checking 4、模型优化Parsimony1,模型识别Identification 相关命令:ac pac这个图的特征是ac值虽然在减小,但其减少类似线性,这时候就要考虑差分了,通常使用的是一阶差分和二阶差分一阶差分generate growth=lrgdp-L.lrgdp这个时候,growth就是经济增长率这张图的ac值快速减少到影音之内,说明在样本中,变量growth显现的是平稳。
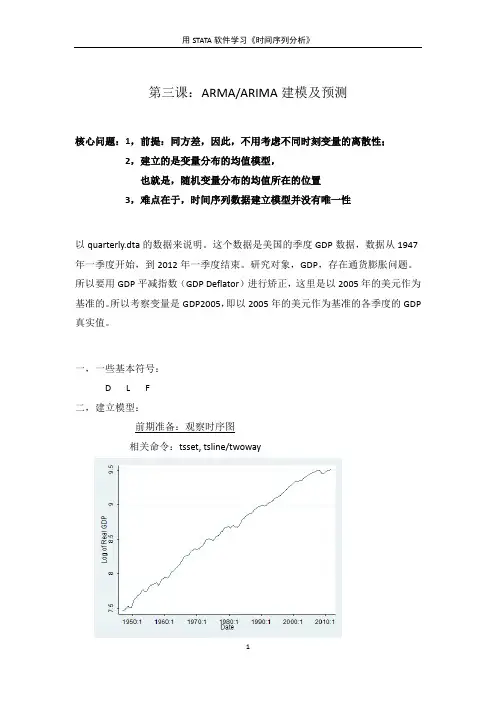
第三课:ARMA/ARIMA建模及预测核心问题:1,前提:同方差,因此,不用考虑不同时刻变量的离散性;2,建立的是变量分布的均值模型,也就是,随机变量分布的均值所在的位置3,难点在于,时间序列数据建立模型并没有唯一性以quarterly.dta的数据来说明。
这个数据是美国的季度GDP数据,数据从1947年一季度开始,到2012年一季度结束。
研究对象,GDP,存在通货膨胀问题。
所以要用GDP平减指数(GDP Deflator)进行矫正,这里是以2005年的美元作为基准的。
所以考察变量是GDP2005,即以2005年的美元作为基准的各季度的GDP 真实值。
一,一些基本符号:D L F二,建立模型:前期准备:观察时序图相关命令:tsset, tsline/twoway从图上可以看出,GDP2005值呈线性的向右上方倾斜,第一种方法:可以用确定性分析理的方法,使用研究变量对时间变量进行回归 即:regress lrgdp date (采用的是最小二乘估计)然后对残差项进行White Noise 检验观察此图:特征大值跟大值,小值跟小值,这说明Residual 中存在着自相关信息。
肯定不是White Noise因此,从这里看出,确定性的方法比较直观,简单,但效果不好,弥补:对残差序列进行回归,建立AR 模型,这就是所谓的 残差自回归模型。
第二种方法BOX-JENKINS 方法,也就是通常所说的ARMA(p,d) /ARIMA(p,d,d)建模(采用的是最大似然估计)。
四大步骤:1、模型识别Identification :决定p 和q2、模型估计Estimation :估计εσθφμ 个),(,个)(,q p 3、模型检验Diagnostic Checking4、模型优化Parsimony1,模型识别Identification 相关命令:ac pac这个图的特征是ac值虽然在减小,但其减少类似线性,这时候就要考虑差分了,通常使用的是一阶差分和二阶差分一阶差分generate growth=lrgdp-L.lrgdp这个时候,growth就是经济增长率这张图的ac值快速减少到影音之内,说明在样本中,变量growth显现的是平稳。

时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着Box and Jenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令1.1时间序列数据的处理1)声明时间序列:tsset 命令use gnp96.dta, clearlist in 1/20gen Lgnp = L.gnptsset datelist in 1/20gen Lgnp = L.gnp2)检查是否有断点:tsreport, reportuse gnp96.dta, cleartsset datetsreport, reportdrop in 10/10list in 1/12tsreport, reporttsreport, report list /*列出存在断点的样本信息*/3)填充缺漏值:tsfilltsfilltsreport, report listlist in 1/124)追加样本:tsappenduse gnp96.dta, cleartsset datelist in -10/-1sumtsappend , add(5) /*追加5个观察值*/list in -10/-1sum5)应用:样本外预测: predictreg gnp96 L.gnp96predict gnp_hatlist in -10/-16)清除时间标识: tsset, cleartsset, clear1.2变量的生成与处理1)滞后项、超前项和差分项 help tsvarlistuse gnp96.dta, cleartsset dategen Lgnp = L.gnp96 /*一阶滞后*/gen L2gnp = L2.gnp96gen Fgnp = F.gnp96 /*一阶超前*/gen F2gnp = F2.gnp96gen Dgnp = D.gnp96 /*一阶差分*/gen D2gnp = D2.gnp96list in 1/10list in -10/-12)产生增长率变量: 对数差分gen lngnp = ln(gnp96)gen growth = D.lngnpgen growth2 = (gnp96-L.gnp96)/L.gnp96gen diff = growth - growth2 /*表明对数差分和变量的增长率差别很小*/ list date gnp96 lngnp growth* diff in 1/101.3日期的处理日期的格式 help tsfmt基本时点:整数数值,如 -3, -2, -1, 0, 1, 2, 3 ....1960年1月1日,取值为 0;1)使用 tsset 命令指定显示格式use B6_tsset.dta, cleartsset t, dailylistuse B6_tsset.dta, cleartsset t, weeklylist2)指定起始时点cap drop monthgenerate month = m(1990-1) + _n - 1format month %tmlist t month in 1/20cap drop yeargen year = y(1952) + _n - 1format year %tylist t year in 1/203)自己设定不同的显示格式日期的显示格式 %d (%td) 定义如下:%[-][t]d<描述特定的显示格式>具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符c y m l nd j h q w _ . , : - / ' !cC Y M L ND J W定义如下:c and C 世纪值(个位数不附加/附加0)y and Y 不含世纪值的年份(个位数不附加/附加0)m 三个英文字母的月份简写(第一个字母大写) M 英文字母拼写的月份(第一个字母大写)n and N 数字月份(个位数不附加/附加0)d and D 一个月中的第几日(个位数不附加/附加0)j and J 一年中的第几日(个位数不附加/附加0)h 一年中的第几半年 (1 or 2)q 一年中的第几季度 (1, 2, 3, or 4)w and W 一年中的第几周(个位数不附加/附加0)_ display a blank (空格). display a period(句号), display a comma(逗号): display a colon(冒号)- display a dash (短线)/ display a slash(斜线)' display a close single quote(右引号)!c display character c (code !! to display an exclamation point)样式1:Format Sample date in format-----------------------------------%td 07jul1948%tdM_d,_CY July 7, 1948%tdY/M/D 48/07/11%tdM-D-CY 07-11-1948%tqCY.q 1999.2%tqCY:q 1992:2%twCY,_w 2010, 48-----------------------------------样式2:Format Sample date in format----------------------------------%d 11jul1948%dDlCY 11jul1948%dDlY 11jul48%dM_d,_CY July 11, 1948%dd_M_CY 11 July 1948%dN/D/Y 07/11/48%dD/N/Y 11/07/48%dY/N/D 48/07/11%dN-D-CY 07-11-1948----------------------------------clearset obs 100gen t = _n + d(13feb1978)list t in 1/5format t %dCY-N-D /*1978-02-14*/list t in 1/5format t %dcy_n_d /*1978 2 14*/list t in 1/5use B6_tsset, clearlisttsset t, format(%twCY-m)list4)一个实例:生成连续的时间变量use e1920.dta, clearlist year month in 1/30sort year monthgen time = _ntsset timelist year month time in 1/30generate newmonth = m(1920-1) + time - 1tsset newmonth, monthlylist year month time newmonth in 1/301.4图解时间序列1)例1:clearset seed 13579113sim_arma ar2, ar(0.7 0.2) nobs(200)sim_arma ma2, ma(0.7 0.2)tsset _ttsline ar2 ma2* 亦可采用 twoway line 命令绘制,但较为繁琐twoway line ar2 ma2 _t2)例2:增加文字标注sysuse tsline2, cleartsset daytsline calories, ttick(28nov2002 25dec2002, tpos(in)) /// ttext(3470 28nov2002 "thanks" ///3470 25dec2002 "x-mas", orient(vert)) 3)例3:增加两条纵向的标示线sysuse tsline2, cleartsset daytsline calories, tline(28nov2002 25dec2002) * 或采用 twoway line 命令 local d1 = d(28nov2002) local d2 = d(25dec2002)line calories day, xline(`d1' `d2')4)例4:改变标签tsline calories, tlabel(, format(%tdmd)) ttitle("Date (2002)") tsline calories, tlabel(, format(%td))二、ARIMA 模型和SARMIA 模型ARIMA 模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。
stata时间序列数据的实证过程Stata时间序列数据的实证过程引言时间序列数据是经济学和金融学研究中常见的数据类型,通过对时间序列数据进行实证分析,可以揭示出数据的动态变化规律,为决策提供有价值的参考。
Stata作为一种流行的统计软件,提供了丰富的功能和工具,可以帮助研究人员进行时间序列数据的实证分析。
本文将以Stata为工具,介绍时间序列数据的实证过程。
一、数据准备在进行时间序列数据的实证分析之前,首先需要准备好相关的数据。
一般来说,时间序列数据应包含两个主要的变量:时间变量和观测变量。
时间变量可以是年份、季度、月份等,而观测变量则是我们要研究的经济指标或金融数据。
在Stata中,可以使用import命令或者直接在软件中导入外部数据文件,将数据导入到Stata的工作环境中。
二、数据处理与描述性统计分析在导入数据之后,我们可以对数据进行处理和描述性统计分析,以了解数据的基本特征。
Stata提供了一系列的命令和函数,可以帮助我们完成这些任务。
例如,我们可以使用summarize命令对观测变量进行基本统计描述,如均值、标准差等。
此外,我们还可以使用generate命令创建新的变量,对数据进行变换和处理。
三、时间序列图形分析时间序列图形是了解数据动态变化的重要工具,可以直观地反映数据的趋势和周期性。
在Stata中,我们可以使用tsline命令绘制时间序列图形。
该命令可以根据时间变量和观测变量,绘制出变量随时间变化的折线图。
通过观察时间序列图形,我们可以初步判断数据是否存在趋势、季节性或周期性。
四、平稳性检验平稳性是时间序列分析的重要前提,它要求数据的均值和方差在时间上保持不变。
在Stata中,可以使用adf命令进行单位根检验,判断时间序列数据是否平稳。
单位根检验的原假设是存在单位根,即数据不平稳;而备择假设是不存在单位根,即数据平稳。
通过adf命令的输出结果,我们可以得到单位根检验的统计量和p值,判断数据是否平稳。
运用stata进行时间序列分析1 时间序列模型结构模型虽然有助于人们理解变量之间的影响关系,但模型的预测精度比较低。
在一些大规模的联立方程中,情况更是如此。
而早期的单变量时间序列模型有较少的参数却可以得到非常精确的预测,因此随着Box and Jenkins(1984)等奠基性的研究,时间序列方法得到迅速发展。
从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。
本章将介绍如下时间序列分析方法,ARIMA模型、ARCH族模型、 VAR模型、VEC模型、单位根检验及协整检验等。
一、基本命令 1.1时间序列数据的处理 1)声明时间序列:tsset 命令 use gnp96.dta, clear list in 1/20 gen Lgnp = L.gnp tsset date list in 1/20 gen Lgnp = L.gnp 2)检查是否有断点:tsreport, report use gnp96.dta, clear tsset date tsreport, report drop in 10/10 list in 1/12 tsreport, report tsreport, report list /*列出存在断点的样本信息*/ 3)填充缺漏值:tsfill tsfill tsreport, report list list in 1/12 4)追加样本:tsappend use gnp96.dta, clear tsset date list in -10/-1 sum tsappend , add(5) /*追加5个观察值*/ list in -10/-1 sum 2 5)应用:样本外预测:predict reg gnp96 L.gnp96 predict gnp_hat list in -10/-1 6)清除时间标识:tsset, clear tsset, clear 1.2变量的生成与处理 1)滞后项、超前项和差分项 help tsvarlist use gnp96.dta, clear tsset date gen Lgnp = L.gnp96 /*一阶滞后*/ gen L2gnp = L2.gnp96 gen Fgnp = F.gnp96 /*一阶超前*/ gen F2gnp = F2.gnp96 gen Dgnp = D.gnp96 /*一阶差分*/ gen D2gnp = D2.gnp96 list in 1/10 list in -10/-1 2)产生增长率变量:对数差分 gen lngnp = ln(gnp96)gen growth = D.lngnp gen growth2 = (gnp96-L.gnp96)/L.gnp96 gen diff = growth - growth2 /*表明对数差分和变量的增长率差别很小*/ list date gnp96 lngnp growth* diff in 1/10 1.3日期的处理日期的格式 help tsfmt 基本时点:整数数值,如 -3, -2, -1, 0, 1, 2, 3 .... 1960年1月1日,取值为 0; 3 显示格式:定义含义默认格式%td 日%tdDlCY %tw 周%twCY!ww %tm 月 %tmCY!mn %tq 季度 %tqCY!qq %th 半年 %thCY!hh %ty 年 %tyCY 1)使用tsset 命令指定显示格式 use B6_tsset.dta, clear tsset t, daily list use B6_tsset.dta, clear tsset t, weekly list 2)指定起始时点 cap drop month generate month = m(1990-1)+ _n - 1 format month %tm list t month in 1/20 cap drop year gen year = y(1952)+ _n - 1 format year %ty list t year in 1/20 3)自己设定不同的显示格式日期的显示格式 %d (%td)定义如下:%[-][t]d<描述特定的显示格式> 具体项目释义:“<描述特定的显示格式>”中可包含如下字母或字符 c y m l n d j h q w _ . , :- / ' !c C Y M L N D J W 定义如下:c and C 世纪值(个位数不附加/附加0)y and Y 不含世纪值的年份(个位数不附加/附加0)m 三个英文字母的月份简写(第一个字母大写)4 M 英文字母拼写的月份(第一个字母大写)n and N 数字月份(个位数不附加/附加0)d and D 一个月中的第几日(个位数不附加/附加0)j and J 一年中的第几日(个位数不附加/附加0)h 一年中的第几半年 (1 or 2)q 一年中的第几季度 (1, 2, 3, or 4)w and W 一年中的第几周(个位数不附加/附加0)_ display a blank (空格). display a period(句号), display a comma(逗号):display a colon(冒号)- display a dash (短线)/ display a slash(斜线)' display a close single quote(右引号)!c display character c (code !!to display an exclamation point)样式1:Format Sample date in format ----------------------------------- %td 07jul1948 %tdM_d,_CY July 7, 1948 %tdY/M/D 48/07/11 %tdM-D-CY 07-11-1948 %tqCY.q 1999.2 %tqCY:q 1992:2 %twCY,_w 2010, 48 ----------------------------------- 样式2:Format Sample date in format ---------------------------------- %d 11jul1948 %dDlCY 11jul1948 %dDlY 11jul48 %dM_d,_CY July 11, 1948 %dd_M_CY 11 July 1948 %dN/D/Y 07/11/48 %dD/N/Y 11/07/48 %dY/N/D 48/07/11 %dN-D-CY 07-11-1948 ---------------------------------- clear set obs 100 5 gen t = _n + d(13feb1978)list t in 1/5 format t %dCY-N-D /*1978-02-14*/ list t in 1/5 format t %dcy_n_d /*1978 2 14*/ list t in 1/5 use B6_tsset, clear list tsset t, format(%twCY-m)list 4)一个实例:生成连续的时间变量 use e1920.dta, clear list year month in 1/30 sort year month gen time = _n tsset time list year month time in 1/30 generate newmonth = m(1920-1)+ time - 1 tsset newmonth, monthly list year month time newmonth in 1/30 1.4图解时间序列 1)例1:clear set seed 13579113 sim_arma ar2, ar(0.7 0.2)nobs(200)sim_arma ma2, ma(0.7 0.2)tsset _t tsline ar2 ma2 * 亦可采用 twoway line 命令绘制,但较为繁琐 twoway line ar2 ma2 _t 2)例2:增加文字标注 sysuse tsline2, clear tsset day tsline calories, ttick(28nov2002 25dec2002, tpos(in)) /// ttext(3470 28nov2002 "thanks" /// 3470 25dec2002 "x-mas",orient(vert))6 3)例3:增加两条纵向的标示线 sysuse tsline2, clear tsset day tsline calories, tline(28nov2002 25dec2002)* 或采用 twoway line 命令 local d1 = d(28nov2002)local d2 = d(25dec2002)line calories day, xline(`d1' `d2')4)例4:改变标签 tsline calories, tlabel(, format(%tdmd))ttitle("Date (2002)")tsline calories, tlabel(, format(%td))二、ARIMA 模型和SARMIA模型 ARIMA模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。
这个模型一旦被识别后就可以从时间序列的过去值及现在值来预测未来值。
ARIMA(1,1)模型:t t t t y y εθερα + + + = �6�1 �6�1 1 1 2.1 ARIMA模型预测的基本程序:1)根据时间序列的散点图、自相关函数和偏自相关函数图以ADF单位根检验其方差、趋势及其季节性变化规律,对序列的平稳性进行识别。
一般来讲,经济运行的时间序列都不是平稳序列。
2)对非平稳序列进行平稳化处理。
如果数据序列是非平稳的,并存在一定的增长或下降趋势,则需要对数据进行差分处理,如果数据存在异方差,则需对数据进行技术处理,直到处理后的数据的自相关函数值和偏相关函数值无显著地异于零。
3)根据时间序列模型的识别规则,建立相应的模型。
若平稳序列的偏相关函数是截尾的,而自相关函数是拖尾的,可断定序列适合 AR模型;若平稳序列的偏相关函数是拖尾的,而自相关函数是截尾的,则可断定序列适合 MA模型;若平稳序列的偏相关函数和自相关函数均是拖尾的,则序列适合 ARMA 模型。