余志文集成学习算法及应用
- 格式:pptx
- 大小:4.50 MB
- 文档页数:13



数论在密码学、编码理论、算法设计等领域的应用研究摘要数论作为数学的一个重要分支,研究整数的性质和关系,其理论基础和研究方法在密码学、编码理论、算法设计等众多领域有着广泛的应用。
本文将探讨数论在这些领域中的应用,并分析其对相关领域发展的贡献和影响。
关键词:数论,密码学,编码理论,算法设计,应用研究1. 绪论数论的研究对象是整数及其性质,包括整除性、素数、同余、不定方程等。
其理论体系丰富而严谨,具有高度的抽象性和逻辑性,这使其在计算机科学、信息安全等领域拥有重要的应用价值。
2. 数论在密码学中的应用数论在密码学中的应用尤为突出,其基础理论构成了现代密码学的重要基石。
2.1 公钥密码学公钥密码学是现代密码学的重要组成部分,其核心思想是将密钥分为公钥和私钥,公钥用于加密,私钥用于解密。
公钥密码学中的许多算法都依赖于数论中的重要概念,例如:*RSA算法: RSA算法利用了大数分解的困难性,将两个大素数相乘得到模数,公钥为模数和加密指数,私钥为模数和解密指数。
由于大数分解的复杂性,破解RSA算法需要花费大量的时间和计算资源。
*ElGamal算法: ElGamal算法基于离散对数问题的困难性,通过对离散对数的计算来进行加密和解密。
离散对数问题与数论中的群论和有限域理论有着密切联系。
*ECC算法: ECC算法基于椭圆曲线上的点运算,其安全性依赖于椭圆曲线上的离散对数问题。
椭圆曲线密码学近年来受到广泛关注,其优势在于更高的安全性、更小的密钥尺寸和更高的计算效率。
2.2 对称密码学对称密码学使用相同的密钥进行加密和解密。
数论也为对称密码学的算法设计提供了理论基础,例如:*AES算法: AES算法是目前使用最广泛的对称加密算法,其核心算法基于S盒和列混淆操作。
S盒的生成过程利用了有限域上的多项式运算,列混淆操作则利用了矩阵乘法,这些都体现了数论在对称密码学中的应用。
2.3 其他密码学应用除了公钥密码学和对称密码学之外,数论还在哈希函数、数字签名、密钥管理等密码学领域有着广泛的应用。

集成学习算法总结1、集成学习概述1.1 集成学习概述集成学习在机器学习算法中具有较⾼的准去率,不⾜之处就是模型的训练过程可能⽐较复杂,效率不是很⾼。
⽬前接触较多的集成学习主要有2种:基于Boosting的和基于Bagging,前者的代表算法有Adaboost、GBDT、XGBOOST、后者的代表算法主要是随机森林。
1.2 集成学习的主要思想集成学习的主要思想是利⽤⼀定的⼿段学习出多个分类器,⽽且这多个分类器要求是弱分类器,然后将多个分类器进⾏组合公共预测。
核⼼思想就是如何训练处多个弱分类器以及如何将这些弱分类器进⾏组合。
1.3、集成学习中弱分类器选择⼀般采⽤弱分类器的原因在于将误差进⾏均衡,因为⼀旦某个分类器太强了就会造成后⾯的结果受其影响太⼤,严重的会导致后⾯的分类器⽆法进⾏分类。
常⽤的弱分类器可以采⽤误差率⼩于0.5的,⽐如说逻辑回归、SVM、神经⽹络。
1.4、多个分类器的⽣成可以采⽤随机选取数据进⾏分类器的训练,也可以采⽤不断的调整错误分类的训练数据的权重⽣成新的分类器。
1.5、多个弱分类区如何组合基本分类器之间的整合⽅式,⼀般有简单多数投票、权重投票,贝叶斯投票,基于D-S证据理论的整合,基于不同的特征⼦集的整合。
2、Boosting算法2.1 基本概念Boosting⽅法是⼀种⽤来提⾼弱分类算法准确度的⽅法,这种⽅法通过构造⼀个预测函数系列,然后以⼀定的⽅式将他们组合成⼀个预测函数。
他是⼀种框架算法,主要是通过对样本集的操作获得样本⼦集,然后⽤弱分类算法在样本⼦集上训练⽣成⼀系列的基分类器。
他可以⽤来提⾼其他弱分类算法的识别率,也就是将其他的弱分类算法作为基分类算法放于Boosting 框架中,通过Boosting框架对训练样本集的操作,得到不同的训练样本⼦集,⽤该样本⼦集去训练⽣成基分类器;每得到⼀个样本集就⽤该基分类算法在该样本集上产⽣⼀个基分类器,这样在给定训练轮数 n 后,就可产⽣ n 个基分类器,然后Boosting框架算法将这 n个基分类器进⾏加权融合,产⽣⼀个最后的结果分类器,在这 n个基分类器中,每个单个的分类器的识别率不⼀定很⾼,但他们联合后的结果有很⾼的识别率,这样便提⾼了该弱分类算法的识别率。

集成学习中完全随机学习策略研究
俞扬;周志华
【期刊名称】《计算机工程》
【年(卷),期】2006(032)017
【摘要】以完全随机树(不包含属性选择过程的决策树)作为基学习器的集成,具有很好的性能.该文探讨了完全随机学习策略推广情况,实现了完全随机决策树桩算法和完全随机规则算法,分析有效的原因.实验表明,性能良好的完全随机算法,易于被许多初学者所掌握.
【总页数】4页(P100-102,152)
【作者】俞扬;周志华
【作者单位】南京大学软件新技术国家重点实验室,南京210093;南京大学软件新技术国家重点实验室,南京210093
【正文语种】中文
【中图分类】TP181
【相关文献】
1.随机森林集成学习模型在高压真空断路器振动信号分析中的应用 [J], 樊浩; 苏海博; 陈立; 史宗谦; 李兴文
2.集成学习之随机森林分类算法的研究与应用 [J], 吴兴惠;周玉萍;邢海花
3.随机森林集成学习模型在高压真空断路器振动信号分析中的应用 [J], 樊浩;苏海博;陈立;史宗谦;李兴文
4.集成学习算法之随机森林与梯度提升决策树的分析比较 [J], 陈雨桐
5.一种随机平均分布的集成学习方法 [J], 艾旭升;盛胜利;李春华
因版权原因,仅展示原文概要,查看原文内容请购买。
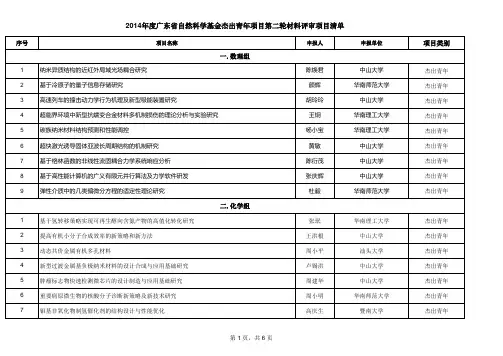



基于改进YOLOv8n的煤矿带式输送异物检测研究目录一、内容概要 (2)1.1 研究背景 (2)1.2 研究意义 (3)1.3 国内外研究现状及发展动态 (4)二、相关工作 (5)2.1 YOLOv8n算法概述 (6)2.2 异物检测方法综述 (7)2.3 改进YOLOv8n的研究进展 (8)三、改进YOLOv8n的异物检测方法 (10)3.1 提升模型性能的方法 (11)3.1.1 数据增强技术 (12)3.1.2 模型结构优化 (13)3.1.3 学习率调整策略 (13)3.2 特征提取与分类器设计 (14)3.2.1 基于卷积神经网络的特征提取 (15)3.2.2 分类器的设计与选择 (16)3.3 多任务学习与迁移学习应用 (18)3.3.1 多任务学习框架 (19)3.3.2 迁移学习在异物检测中的应用 (20)四、实验设计与结果分析 (21)4.1 实验环境与数据集 (22)4.2 实验参数设置 (23)4.3 实验结果与对比分析 (24)4.3.1 模型准确率分析 (25)4.3.2 模型速度分析 (26)4.3.3 与其他方法的比较 (27)五、结论与展望 (29)5.1 研究成果总结 (30)5.2 研究不足与局限 (30)5.3 未来研究方向与展望 (32)一、内容概要引入先进的深度学习模型优化技术,如残差连接和注意力机制,以提高模型的准确性和鲁棒性。
针对煤矿带式输送系统的特点,对目标检测任务的数据集进行定制化处理,以适应不同场景和物体的识别需求。
通过迁移学习的方法,利用预训练的模型权重进行微调,加速模型的训练过程并提高其泛化能力。
优化算法参数和硬件配置,以实现高效的模型推理速度,满足实际应用中对实时性的要求。
开发一个集成到煤矿生产监控系统中的异物检测模块,实现对输送带上的异物进行实时检测和报警,从而提高煤矿生产的安全性和效率。
1.1 研究背景随着国家经济的快速发展,煤炭作为我国最主要的能源之一,其开采和运输环节的安全问题日益凸显。


集成学习算法原理及应用随着互联网技术的发展,人们在数据处理方面有了更高的要求,如何快速准确地对海量数据进行分类、识别和预测成为了人们关注的焦点。
集成学习算法便是针对这一问题而出现的一种解决方案。
本文将对集成学习算法的原理和应用进行详细介绍。
一、集成学习算法的概述集成学习算法的思想来源于“群体智慧”,即通过将多个“弱学习器”集成在一起,来达到“强学习器”的目的。
弱学习器通常是指分类器,如决策树、逻辑回归、支持向量机等。
集成学习算法可以通过提高模型准确率、降低模型泛化误差、避免过拟合等方面来提升分类器的性能。
集成学习算法主要分为两类:Bagging和Boosting。
Bagging算法中,每个弱学习器之间是相互独立的,每个弱学习器对训练集进行有放回的采样,然后用采样集进行训练,最终将所有弱学习器的结果进行投票。
而Boosting算法中,每个弱学习器之间是有序的,每个弱学习器的输入数据是基于前次学习器的错误结果而产生的“加权样本”,通过多次迭代来提高弱学习器的准确性。
二、集成学习算法的应用2.1 回归问题在回归问题中,集成学习算法可以通过多个弱回归器来提高预测结果的精度。
通过让每个弱回归器都对数据做出不同的预测,然后将预测结果进行加权,获得最终的预测结果。
例如,用随机森林来预测视网膜中的水晶状体密度评分,可以获得比单一回归器更准确的结果。
2.2 分类问题在分类问题中,集成学习算法可以通过多个弱分类器来提高分类准确率和泛化能力。
在集成学习算法中,弱分类器通常是树形结构,如随机森林和AdaBoost等。
通过将多个弱分类器结合在一起,可以生成更优秀的分类器,提高分类的准确度。
例如,在脑电信号分类问题中,可以采用集成学习算法来提高神经元的识别率。
2.3 数据降维在数据降维问题中,集成学习算法可以通过将多个弱分类器结合在一起,来获得更精确的数据特征提取模型。
例如,在人脸识别问题中,采用多个弱特征提取模型,通过加权计算来对人脸进行分类匹配,可以提高人脸识别的准确率。
专利名称:一种基于渐进式学习的集成分类方法专利类型:发明专利
发明人:余志文,陈伟宏,赵卓雄
申请号:CN201810774888.2
申请日:20180716
公开号:CN109165672A
公开日:
20190108
专利内容由知识产权出版社提供
摘要:本发明公开了一种基于渐进式学习的集成分类方法,同时对带噪音标签的高维数据的样本维和属性维进行数据挖掘,并结合渐进式学习原理,解决了学习训练中加入新数据后原数据信息丢失的问题;具体步骤为:(1)输入样本数据集;(2)产生训练样本的bootstrap分支集合;(3)生成分类器;(4)对样本进行分类;(5)选择第一个分类器;(6)选择渐进式分类器;(7)得到预测结果和分类准确率。
本发明对高维数据样本维度和属性维度同时挖掘,构建一个强大的集成分类器;利用带有线性判别分析算法的渐进式集成学习算法提高对带噪音数据的分类能力;并将集成学习与渐进式学习相结合,提高了集成分类方法的准确性、稳定性和鲁棒性。
申请人:华南理工大学
地址:510640 广东省广州市天河区五山路381号
国籍:CN
代理机构:广州市华学知识产权代理有限公司
代理人:裴磊磊
更多信息请下载全文后查看。
基于Markov与PageRank算法的Web日志仿真器
余智学;林文龙
【期刊名称】《计算机技术与发展》
【年(卷),期】2008(18)5
【摘要】获取可靠的Web访问会话数据是Web使用挖掘(WUM)的重要前提,而很多时候这种数据不容易得到.据此,采用数学建模的方法,设计并实现了一个Web 日志仿真器(SSPM,Session Simulator based on PageRank and Markov).SSPM 用Markov链过程模拟用户访问过程,将用户Web访问过程抽象为Markov链,以PageRank算法计算页面重要度,并以此计算Markov初始状态和转移矩阵,获取用户仿真日志.还介绍了SSPM的验证方法.
【总页数】4页(P182-184,187)
【作者】余智学;林文龙
【作者单位】合肥工业大学,电子商务研究所,安徽,合肥,230009;合肥工业大学,电子商务研究所,安徽,合肥,230009
【正文语种】中文
【中图分类】TP393
【相关文献】
1.基于Web日志挖掘的Markov预测模型及算法研究 [J], 张友志;程玉胜;王一宾
2.基于PageRank算法的中间品全球贸易网络格局演变分析 [J], 蒋雪梅;张少雪
3.基于PageRank算法的输电网连锁故障脆弱线路辨识 [J], 魏明奎;周全;宋雨妍;
王渝红;周泓;蔡绍荣;江栗
4.基于PageRank算法的期刊影响因子修正研究 [J], 臧志栋;李秀霞;李兴保
5.基于主题相似度改进的PageRank算法研究 [J], 刘齐;黄树成
因版权原因,仅展示原文概要,查看原文内容请购买。