基于聚类分析法的土地利用分区研究_冯仁德
- 格式:pdf
- 大小:320.30 KB
- 文档页数:2


基于聚类分析法的土地利用功能分区研究摘要:土地利用功能分区是土地利用总体规划中的重要内容,为区域建设规划、生态保护和土地管制提供了科学依据。
本文以广西壮族自治区罗城县为研究对象,在充分考虑区域自然、社会、经济和土地利用现状的基础上,筛选和确定土地功能分区指标因子,建立区域土地功能分区指标体系,采用聚类分析方法,计算确定样本之间的相似性或差异性,以地域相似性和差异性,划分区域土地利用功能区。
结果表明:将研究区域划分为优先建设、重点建设、引导建设和限制建设区,与该区域土地利用和经济发展水平是吻合的。
关键词:土地利用功能分区聚类分析法罗城县引言我国人口的迅速增加、经济的快速增长和城镇化进程的高速发展,加剧了人类对土地的迫切需求,使人地关系矛盾日益突出。
在土地供需不平衡的市场条件下,土地利用功能分区作为土地利用规划的重要内容,对规范土地开发秩序、调控土地开发规模、优化土地利用结构、促进区域协调发展具有重要的意义[1、2]。
在“十一五”规划中提出了“根据资源环境承载力,现有开发密度和发展潜力,统筹考虑未来我国人口分布、经济布局、国土利用和城镇化格局,将国土空间划分为优化开发、重点开发、限制开发和禁止开发四类主体功能区[3]”。
“十二五”规划再次明确“实施主体功能区战略,优化国土空间开发格局。
实施分类管理的区域政策。
实施各有侧重的绩效评价和建立健全衔接协调机制[4]”。
同时,上世纪80年代开始,我国众多学者对土地利用分区理论和方法已展开了研究,随着土地利用分区理论的不断完善和计算机以及软件技术的深入应用,土地利用分区研究也取得了一定的进展[5]。
在技术方法上,专题图叠置法、定性分析法、系统聚类分析法、主成分分析法、综合评价法等是土地功能分区常用方法,其中,系统聚类分析法运用较为广泛[6]。
本文选取罗城县为研究对象,结合系统聚类分析方法和定性分析法划定该区域土地利用功能区,为该区域实施土地有效利用和土地差别化管理提供科学合理的依据。


聚类分析在江苏省经济区域划分中的应用摘要:本文探讨了如何运用SPSS中的聚类分析对江苏省十三个市按国民经济的相关指标进行经济区域的划分,以便对十三个市的经济发展分类指导,做到有的放矢,从而更好地带动江苏经济的发展。
首先阐述了聚类分析的相关原理及指标体系,然后根据相关原始数据,对其标准化后进行聚类分析,最后得出江苏省应划分苏南、苏中、苏北三个经济区。
关键字:聚类分析,经济区域,江苏省1 引言研究一个省的经济发展状况,通常需要对该省所有地级市根据不同国民经济发展状况进行经济区域的划分,以便进行分类指导。
江苏省共拥有十三个地级市,不同地级市的国民经济发展状况各不相同。
如何对这十三个地级市进行合理区分,从而从每个地区的经济情况做到有的放矢,这对整个江苏经济的发展有着十分重要的作用。
通常,描述一个地区的经济发展状况会有很多的指标,那么如何根据这些指标合理地进行区域的划分呢?利用世界著名的统计软件SPSS的聚类分析功能效果会比较理想。
本文对江苏省十三个地级市(南京、无锡、徐州、常州、苏州、南通、连云港、淮安、盐城、扬州、镇江、泰州、宿迁)经济区域的划分就利用了聚类分析的功能。
2 聚类分析的基本原理及其指标体系2.1 基本原理聚类分析的基本原理是:首先将一定数量的样本各自看成一类,然后根据样本之间的亲疏程度,将亲密程度最高的两类进行合并;然后考虑合并后的类与其他类之间的亲疏程度,再进行合并;重复这一过程,直至将所有的样本合并为一类。
聚类分析的实质是建立一种分类方法,它能够将一批样本数据按照他们在性质上的亲密程度在没有先验知识的情况下自动进行分类。
这个类指的是一个具有相似性个体的集合,不同类之间具有明显的区别。
聚类分析的方法主要有两种,一种是快速聚类,一种是层次聚类。
如果观察值的个数非常多(200个以上),则宜采用快速聚类的方法。
在本例中用到的是层次聚类,并且是层次聚类中的R型聚类,R型聚类是对研究对象的观察变量进行分类,使具有共同特点的变量聚集在一起。


聚类方法在规划分区中的应用——以模糊聚类为例摘要关键词引言1.聚类分析聚类分析可以看做是一种非监督的分类方法,在分类时只依赖对象自身所具有的属性来区分对象之间的相似程度。
将总体中的个体分类以发现数据中的结构,希望一个类中的个体彼此接近或相似,而与其它类中的个体相异,这样就可以对划分出来的每一类进行深入的分析从而概括出每一类的特点。
[1]利用聚类结果,我们能够提取数据集中隐藏的信息,对未来数据进行预测和分类。
目前聚类算法主要分为层次化聚类方法,划分式聚类方法,基于密度的聚类方法,基于网格的聚类方法,基于核的聚类算法,基于谱的聚类方法,基于模型的聚类方法,基于遗传算法的聚类方法,基于SVM 的聚类方法,基于神经网络的聚类方法等等[2]。
通常聚类分析算法一般包含四个部分:(1)特征获取与选择;(2)计算相似度;(3)分组;(4)聚类结果展示;(5)聚类结果评价。
相似度一般用距离函数表示,包括形态、语义、状态、密度、时间等产生的差距,用来度量模式之间的相似程度。
常见的距离函数有欧式距离,马氏距离,夹角余弦距离,Pearson 相关系数,Tanimoto 测度等。
在进行聚类分析时一般根据应用的场合来设计不同的距离函数,目前还没有一个可以通用的距离函数[2]。
2.各种聚类方法1.1层次聚类方法层次聚类算法又称为树聚类算法或系统聚类算法,层次的方法按数据分层建立簇,形成一棵以簇为节点的树。
这种算法的基本思路是首先将所有对象看成独立的个体类,通过计算类间的距离来选择最小距离的两个类合并成一个新类,再重新计算新类和其它类之间的距离,选择最小距离的两个类合并,依次迭代合并直到没有合并为止。
有基于聚集和基于分割的聚类两种,分别是基于数据的最小距离和最大距离原理。
层次聚类算法可以在不同粒度水平上对数据进行探测,而且很容易实现相似度量或距离度量,对于圆形和球形分布的数据具有较好的效果。
但是层次聚类算法由于合并或分裂簇的操作不可逆,也给聚类结果带来不准确性[3]1.2划分式聚类方法划分式聚类方法的主要思想为,对于一个给定的n 个数据对象的数据集,需要预先指定聚类数目或聚类中心,通过反复迭代运算,逐步降低目标函数的误差值,当目标函数值收敛时,得到最终聚类结果。


浅析聚类分析在土地工程能力评价中的应用随着中国经济的快速发展,城市化进程的大步迈进,土地工程的发展和应用对城市化建设和经济的推动有着不可名状的作用和贡献,所以我们要充分认识和认知土地工程这个项目。
只有对这个项目做好提前的了解和把握,才能在使用过程中应用自如。
反观土地工程的使用是一项复杂而且多元化的工作,就要求我们在使用前要掌握牢固的理论知识和基础,对整个城市的规模做到了如指掌,这样方能在土地工程使用工程中得心应手,挥洒自如。
标签土地工程能力;聚类方法;聚类分析;南徐新城土地工程能力的评价需要多元化的因素和方案以及扎实的知识理论,对土地的认知还必须从多方面着手把握和了解,这样在分析过程中才能对土地工程能力作出最直接,最正确,最明了的答案。
城市化工程的建设规模日益扩大,城市地质环境所受到的迫害和影响也同样是有增无减。
因此为了城市工程的百年大计,需要我们对土地工程能力做详细的分析和规划,这样方能使得土地在使用的工程中更好恰如其分,发挥其最大功效,避免土地在使用工程中,大肆浪费,尸位素餐。
本文笔者就针对如何科学合理的采用浅析聚类分析法来对土地工程能力做精确到位的评价详细落笔,到位分析,希望大家可以参考和借鉴。
1 土地工程能力土地工程能力评价基础是工程地质条件的各种各样的评价信息,同时把土地资源的最佳利用作为最终的目标,这是城市工程地质环境分析的最终目的,而且也同样成为城市规划控制的重要依据之一。
然而跟随城市化发展的快速步伐和工程开发技术的大幅迈进,人们反而忽视了土地的工程能力,通过高强度的土地开发来降低土地的单位成本,这种得不偿失的行为在不经意以及长期使用过程中往往给城市带来无法估量的失衡和不良,降低了土地的最大利用效益,而且其损失也同样是难以计算。
因此,土地开发利用要以土地工程能力为依据,既要避免由于超过土地工程能力而造成的失衡或灾害,又要充分利用其工程能力避免土地资源的浪费。
如何客观综合地评价土地的工程能力,成为工程地质学工作者十分关注的问题。
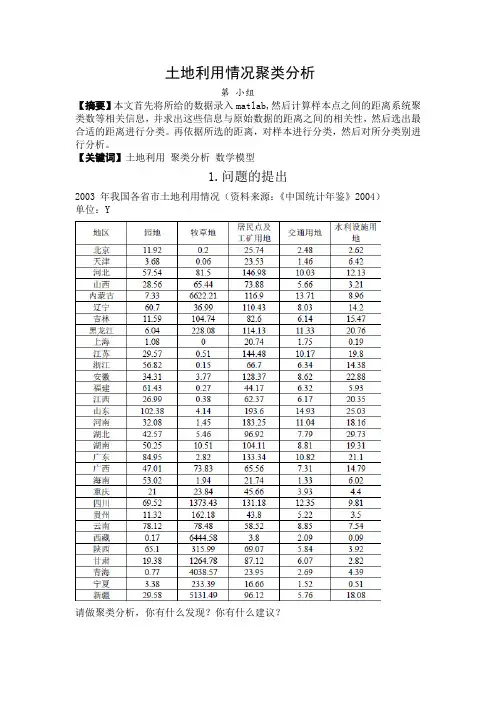
土地利用情况聚类分析第小组【摘要】本文首先将所给的数据录入matlab,然后计算样本点之间的距离系统聚类数等相关信息,并求出这些信息与原始数据的距离之间的相关性,然后选出最合适的距离进行分类。
再依据所选的距离,对样本进行分类,然后对所分类别进行分析。
【关键词】土地利用聚类分析数学模型1.问题的提出2003 年我国各省市土地利用情况(资料来源:《中国统计年鉴》2004)单位:Y请做聚类分析,你有什么发现?你有什么建议?2.假设条件在具体分析问题之前,,我们先做如下假设,以确保研究各组数据的准确性:(1)我们认定图表中所给出的数据都是真实可靠的。
3.问题的解决第一步:将数据导入matlab第二步:计算样本点之间的距离系统聚类数等相关信息,并求出这些信息与原始数据的距离之间的相关性,然后选出最合适的距离进行分类。
编写程序如下:x=[11.92,0.2,25.74,2.48,2.62;3.68,0.06,23.53,1.46,6.42;57.54,81.5,146 .98 ,10.03,12.13;28.56,65.44,73.88,5.66,3.21;7.33,6622.21,116.9,13.71 ,8.96;60.7,36.99,110.43,8.03,14.2;11.59,104.74,82.6,6.14,15.47;6.04,2 28.08,114.13,11.33,20.76;1.08,0,20.74,1.75,0.19;29.57,0.51,144.48,10. 17,19.8;56.82,0.15,66.7,6.34,14.38;34.31,3.77,128.37,8.62,22.88;61.43 ,0.27,44.17,6.32,5.93;26.99,0.38,62.37,6.17,20.35;102.38,4.14,193.6,1 4.93,25.03;32.08,1.45,183.25,11.04,18.16;42.57,5.46,96.92,7.79,29.73;50.25,10.51,104.11,8.81,19.31;84.95,2.82,133.34,10.82,21.1;47.01,73.8 3,65.56,7.31,14.79;53.02,1.94,21.74,1.33,6.02;21,23.84,45.66,3.93,4.4 ;69.52,1373.43,131.18,12.35,9.81;11.32,162.18,43.8,5.22,3.5;78.12,78. 48,58.52,8.85,7.54;0.17,6444.58,3.8,2.09,0.09;65.1,315.99,69.07,5.84, 3.92;19.38,1264.78,87.12,6.07,2.82;0.77,4038.57,23.95,2.69,4.39;3.38, 233.39,16.66,1.52,0.51;29.58,5131.49,96.12,5.76,18.08];y1=pdist(x);y2=pdist(x,'seuclid');y3=pdist(x,'mahal');y4=pdist(x,'cityblock');z1=linkage(y1);z2=linkage(y2);z3=linkage(y3);z4=linkage(y4);a1=cophenet(z1,y1);a2=cophenet(z2,y2);a3=cophenet(z3,y3);a4=cophenet(z4,y4);a1=0.9662a2=0.6345a3=0.7171a4=0.9669其中,“a4=0.9669”最大,说明此时应用布洛克距离最好。


聚类分析在城镇土地定级中的应用科学合理地确定城镇土地级别有利于摸清城市土地的资产价值,全面掌握城镇土地的质量和利用状况以及城市地价形成及演变规律,进而为科学管理和合理利用城镇土地服务。
文章运用多因素综合评定法计算研究区的城镇土地作用分值,在此基础上利用聚类分析确定该区域土地级别,其结果与使用数轴法进行定级的结果基本一致,使用聚类分析确定的土地级别能更加客观、合理。
标签:聚类分析;城镇用地;土地定级城镇土地定级就是根据城镇内部土地区位条件和利用效益的差异,确定城镇土地不同级别区域的过程[1],其反映了城市内土地的分布特征和开发利用状况,是科学制定城市规划方案的前提。
从目前的成果来看,研究城镇土地定级方法很多,而针对级别划分探讨很少,主要有:数轴法、总分频率曲线判断法和等间距法、模糊聚类分析[2-3]等。
在以上方法中,需要根据数轴上点分布的稀疏与集中程度或选择频率曲线突变处或根据经验确定间距,主观性性较强,降低了级别划分的准确性,而聚类分析能更加客观、定量的确定定级单元的相似程度。
多因素综合评定法从影响城镇土地使用价值或土地质量的因素出发,系统综合地分析各类因素和因子对土地产生的影响强度,揭示城镇土地价值的空间差异[4],因此文章将使用多因素综合评价法作為定级方法,并运用聚类分析对研究区土地定级数据进行级别划分。
1 各因素作用分值计算城镇土地定级因素是指能体现土地区位差异的经济、社会、自然条件。
文章选择商服繁华影响度、道路通达度、对外交通便利度、公用设施完备度、环境质量优劣度5个影响因素作为评价体系,并采用特尔菲法确定其权重。
各定级分等单元的作用分值计算如下,计算公式见表1。
2 城镇土地级别划分确定城镇土地级别应遵循城市土地质量变化规律。
城镇中各项与土地质量有关的要素,其变化规律一般为连续、渐变的,很少情况下是不连续分布的。
文章在得到各定级单元指数后,运用聚类分析划分城镇土地级别。
聚类分析是根据变量属性或特性的相似性、亲疏程度,用数学的方法把它们逐步地分型划类,最后得到一个能反映个体或站点之间、群体之间亲疏关系的分类系统[5]。
聚类分析在土地利用功能分区中的应用——以西安市雁塔区
为例
马智民;乔亮
【期刊名称】《国土资源科技管理》
【年(卷),期】2007(24)6
【摘要】土地利用功能分区对土地合理、集约利用以及地方经济的快速、持续的发展发挥着重要的作用,是土地利用总体规划的重要组成部分.在介绍系统聚类分析方法的基础上,以西安市雁塔区为例.在实验区内以街道办为单位,选取具有代表性的参考因子来量化分析进行土地利用功能分区.
【总页数】4页(P90-93)
【作者】马智民;乔亮
【作者单位】长安大学地球科学和国土资源学院,陕西,西安,710054;长安大学地球科学和国土资源学院,陕西,西安,710054
【正文语种】中文
【中图分类】F301.2(241)
【相关文献】
1.西安市私家车合乘现状调查与分析——以西安市雁塔区为例 [J], 高丽娜;马丽娟;侯茂生
2.基于聚类分析的商业银行个人理财产品市场的细分--以西安市雁塔区为例 [J], 姜姿宇;丁美月;卢丽丽;张兵
3.重大公共事件下地摊经济发展的现状分析及对就业影响的调查研究——以西安市雁塔区为例 [J], 羽南峧;杨泽钥;许俊杰;潘佳韵
4.城市幼儿园空间分布特点及优化策略研究
——以西安市雁塔区为例 [J], 宁忱;陈秀端;雷田旺
5.主成分分析法、聚类分析法在旅游观光农业空间分区中的应用——以西安市为例的研究 [J], 王晓龙;刘笑明;李同升
因版权原因,仅展示原文概要,查看原文内容请购买。
基于聚类分析法的土地利用功能分区研究作者:陈芳张桂花罗清泉来源:《科技经济市场》2013年第01期摘要:土地利用功能分区是土地利用总体规划中的重要内容,为区域建设规划、生态保护和土地管制提供了科学依据。
本文以广西壮族自治区罗城县为研究对象,在充分考虑区域自然、社会、经济和土地利用现状的基础上,筛选和确定土地功能分区指标因子,建立区域土地功能分区指标体系,采用聚类分析方法,计算确定样本之间的相似性或差异性,以地域相似性和差异性,划分区域土地利用功能区。
结果表明:将研究区域划分为优先建设、重点建设、引导建设和限制建设区,与该区域土地利用和经济发展水平是吻合的。
关键词:土地利用功能分区聚类分析法罗城县引言我国人口的迅速增加、经济的快速增长和城镇化进程的高速发展,加剧了人类对土地的迫切需求,使人地关系矛盾日益突出。
在土地供需不平衡的市场条件下,土地利用功能分区作为土地利用规划的重要内容,对规范土地开发秩序、调控土地开发规模、优化土地利用结构、促进区域协调发展具有重要的意义[1、2]。
在“十一五”规划中提出了“根据资源环境承载力,现有开发密度和发展潜力,统筹考虑未来我国人口分布、经济布局、国土利用和城镇化格局,将国土空间划分为优化开发、重点开发、限制开发和禁止开发四类主体功能区[3]”。
“十二五”规划再次明确“实施主体功能区战略,优化国土空间开发格局。
实施分类管理的区域政策。
实施各有侧重的绩效评价和建立健全衔接协调机制[4]”。
同时,上世纪80年代开始,我国众多学者对土地利用分区理论和方法已展开了研究,随着土地利用分区理论的不断完善和计算机以及软件技术的深入应用,土地利用分区研究也取得了一定的进展[5]。
在技术方法上,专题图叠置法、定性分析法、系统聚类分析法、主成分分析法、综合评价法等是土地功能分区常用方法,其中,系统聚类分析法运用较为广泛[6]。
本文选取罗城县为研究对象,结合系统聚类分析方法和定性分析法划定该区域土地利用功能区,为该区域实施土地有效利用和土地差别化管理提供科学合理的依据。
上思县土地利用功能分区研究摘要:土地利用功能分区是土地利用总体规划中的重要内容,为区域建设规划、生态保护和土地管制提供了科学依据。
本文以上思县为研究区域,采用聚类分析方法,同时结合当地的实际情况进行适当调整,确定土地利用功能分区。
在研究各分区特点的基础上,以提高土地利用率,保持土地利用的可持续利用为目标,确定土地利用的合理方向。
关键词:土地利用;功能分区;聚类分析法1引言土地利用功能分区是一项综合性很强的工作。
涉及到人口、经济、社会、环境等诸多因素,要使区划做到科学、合理、有效、可行,必须制定一些基本的原则。
土地利用功能分区是按照土地基本用途及其生态功能不同所划分的区域,以土地所能提供利用的适宜性为基础,结合国民经济和社会发展的需要,确定土地生态结构和功能基本相似的区域。
其目的是为了协调各类用地之间的矛盾,更好地进行土地用途管制,合理高效地利用有限的土地资源,限制不适当的开发利用行为,实现土地资源的优化配制,使人类的经济活动符合生态学原则、创造既合乎人类理想又符合自然规律的土地利用方式。
土地利用功能分区必须客观地体现土地利用的现势性(利用格局与现状)、适宜性(利用方式与特点)和预见性(利用方向与潜力)。
本文以上思县为例,采用系统聚类分析的方法,以严格保护耕地为前提,以严格控制控制建设用地无序扩张为重点,促进土地资源的集约、节约利用,并针对各区提出不同的发展策略。
2土地利用功能分区2.1土地利用功能分区的原则(1)土地功能分区应结合当地自然和社会经济条件,充分考虑各地的具体情况,制定符合当地土地资源实际的土地用途管制分区方案,增强土地用途管制分区的实际应用效果。
(2)分区方案的确定要以各基本区域单元的自然、社会经济及土地利用的现状为基础,以区域差异性分析为导向,考虑土地利用方式的延续性,兼顾经济、生态、社会效益,兼顾局部、整体利益,兼顾眼前、长远利益。
(3)分区应与上一级分区界线相协调,并尽量保持下一级行政区划的完整性。
基于MATLAB聚类法的耕地质量分等摘要:准确把握区域耕地数量、质量现状以及未来变化,对实现耕地保护由数量平衡与管理向数量-质量综合平衡与管理具有重要意义。
本文通过对2013年海伦市各乡镇关于耕地质量的数据进行研究,分析海伦市各乡镇耕地质量的差异性。
运用MATLAB不同聚类方法对海伦市各乡镇的耕地质量数据进行聚类分析,选取符合海伦市各乡镇耕地质量情况的分析方法。
通过耕地质量研究,查清海伦市耕地位置范围和面积,全面掌握海伦市耕地数量质量及分布状况,为提高海伦市各乡镇耕地质量提出相关建议。
关键词:耕地质量;聚类分析;分等定级;1 耕地与耕地质量1.1耕地的内涵耕地是指经过人类后天培育而适合种植作物或果树的土地,是人类赖以生存的基础和保障。
在人类开发利用土地的过程中,形成的一种有特殊经济价值的土地类型,一般用来常年耕耘和种植农作物。
耕地离开人类的耕作活动不能独立存在,不能独立完成整个生产与再生产过程。
耕地是土地的一种利用类型,是用来种植农作物的土地,特定的利用方式决定自身具有一些特殊性。
1.2耕地质量的概念指耕地的质量内容包括耕地用于一定的农作物栽培时,耕地对农作物的适宜性、生物生产力的大小(耕地地力)、耕地利用后经济效益的多少和耕地环境是否被污染四个方面。
2 海伦市耕地变化2.1 数据来源与数据处理耕地面积数据全部来自《黑龙江年鉴》(2001-2011)。
数据处理工具主要是EXCEL。
2.2耕地面积变化2001年至2010年海伦市耕地总面积基本不变,但随人口的增多与减少,人均耕地占有量整体呈减少趋势。
从表1可以看出随着国民经济的发展,到了2011年,耕地总面积比上年减少了近2万公顷。
如图3所示,随着人口数量的增加,人均耕地面积减少幅度较大。
2003年至2007年人口稳定在80万。
到2008至2011人口有稳定增长的趋势。
由于人口增长,人均耕地面积减少较快。
2009年起,耕地面积与人均耕地面积均急速减少。