浅论植物学考试成绩统计分析及评价
- 格式:doc
- 大小:30.50 KB
- 文档页数:3


生物期末成绩总结分析引言生物是研究生命现象和生物系统的科学,是现代科学中一个极其重要的学科。
在生物学的学习过程中,我们通过学习生命的起源、进化、结构和功能,理解了生物在地球上的种类和多样性。
生物学作为一门学科,有着广泛的应用领域,包括医学、农业、环境科学等等。
因此,生物学的学习是我们提高科学素养、增长科学知识的重要途径。
本篇文章将对我在生物学期末考试中的成绩进行总结和分析,以及对学习生物学的感想和认识。
一、成绩总结在这次生物学的期末考试中,我取得了较为满意的成绩。
总的来说,我在各个知识点上都取得了一定的进步。
具体来说,我在细胞生物学、遗传学、生态学等方面的知识掌握较为扎实,能够较好地进行问题解答和知识运用。
然而,在某些分支知识上,比如植物生理学和动物行为学等方面的知识储备较为有限,答题也相对较困难。
因此,在今后的学习中,我将继续加强对这些分支知识的学习和理解。
二、问题分析在这次考试中,我发现了一些自己在生物学学习过程中的一些弱点和问题,需要进一步加以改进和解决。
1. 知识记忆不牢固在考试中,我发现自己对一些知识点的记忆不够牢固。
在答题过程中,经常会出现反复思考和回忆的情况,影响了答题的效率和准确性。
这主要是因为平时的知识复习不够充分,只注重了知识点的理解和应用,而忽略了对知识点的记忆。
2. 对题目理解不准确有时在考试中,我对于一些题目的理解不够准确。
这导致了我在答题过程中偏离了正确的思路。
在今后的学习中,我需要更加仔细地阅读题目,确保对题目的理解正确。
3. 对实验设计和数据分析的不熟悉在一些实验设计和数据分析的题目上,我发现自己的理解和运用能力有所欠缺。
这可能是因为我在平时的学习中较少涉及到这方面的内容,而是更多地关注了理论知识的学习。
在之后的学习中,我将重视实验设计和数据分析的学习,提升自己在这方面的能力。
三、改进措施为了更好地提高生物学学习成绩,我计划采取以下措施加以改进:1. 加强基础知识的记忆通过背诵和总结,不断巩固生物学的基础知识,对于重要的知识点进行重复记忆,以增强记忆力和记忆效果。

生物期中成绩质量分析及反思成绩分析
本文旨在对生物期中成绩的质量进行分析和反思。
以下是对本学期生物期中考试成绩的分析:
- 平均成绩:根据我们收集到的数据,生物期中考试的平均成绩为75分。
- 成绩分布:成绩分布呈正态分布,大部分学生的成绩集中在中等水平,少数学生表现出色,也有少数学生表现较差。
- 高分原因:我们发现,那些取得高分的学生通常具备对生物知识的深入理解和扎实的基础。
他们在准备考试时,充分利用了课堂教学和课后资料,并进行了系统性的复和练。
反思与建议
针对这次生物期中考试,我提出以下反思和建议,希望能够帮助学生们在下次考试中取得更好的成绩:
- 加强基础知识掌握:生物学是一门基础性很强的学科,在研
究过程中要注重对基础知识的理解和掌握。
建议学生们要及时复课
堂内容,查漏补缺,确保基础知识牢固。
- 注重题训练:领会了基础知识后,学生们应该进行大量的题
训练,加强对知识的运用和理解。
可以选择一些题集或者刷题软件
进行练,提高解题能力。
- 科学复规划:制定科学的复计划,合理安排每天的研究时间,确保每个知识点都得以复和巩固。
同时,要注意合理分配时间,避
免过度研究导致疲劳。
- 合理应对考试压力:考试时常伴随着一定的压力,但学生们
需要学会合理应对压力,保持良好的心态。
可以通过运动、听音乐、与朋友交流等方式缓解考试压力。
通过对生物期中成绩的质量分析和反思,我们可以发现自己的
不足,并针对性地改进学习方法和策略。
希望在下次考试中,大家
都能取得更好的成绩!。

生物期中考试学生成绩分析
考试简介
本文通过分析生物期中考试的学生成绩,探讨考试结果的分布情况、学生表现突出的知识点和普遍存在的薄弱环节,以及提出可能的改进方案。
成绩分布情况
首先,对生物期中考试成绩进行整体分布的统计,结果显示大部分学生的成绩集中在60-80分之间,中位数约为70分。
少部分学生获得90分以上的高分,同时也存在一定比例的低分学生,主要集中在50分以下。
知识点分析
在知识点方面,学生表现最好的主题包括生物的基本概念、典型生物的特征和生态系统的基本原理。
相比之下,对于遗传学和细胞生物学等较为复杂的知识点,学生表现较为普遍地欠缺,这往往体现在答题的深度和准确度上。
学习态度与分数关系
进一步分析发现,与学生成绩较为相关的因素之一是学习态度。
那些在学习过程中态度认真、主动探求知识的学生,一般能取得更好的成绩。
另外,参加课外辅导或进行主动复习的学生,也往往表现出相对较好的成绩。
改进方案
针对生物期中考试学生成绩的分析结果,我们可以提出以下改进方案:
1.强化学生的基础知识,建议师生共同努力,注重知识的系统性和连贯
性,在授课的同时加强互动和实践。
2.提醒学生注意学习态度和时间管理,教育学生学会自主学习,养成良
好学习习惯。
3.加强对薄弱环节的补充和巩固,针对性地设立练习和辅导。
总结
通过对生物期中考试学生成绩的深入分析,我们可以更清晰地了解学生在生物学科上的优势和不足,为接下来的教学工作和学习指导提供有益参考。
希望学生在后续的学习中能够有所改进,取得更好的成绩。
以上内容为生物期中考试学生成绩分析报告,希望对您有所帮助。
生物期末考试成绩分析报告一、考试概况本次生物期末考试共有75名学生参加,考试内容涵盖了生物学的各个章节,考试形式为闭卷笔试。
考试时间为90分钟,满分100分。
二、成绩分布情况1. 总体成绩分布•平均分:65分•及格线:60分•及格人数:58人•优秀人数(90分以上):5人•良好人数(80-89分):12人•中等人数(70-79分):22人•不及格人数:17人2. 成绩波动情况学生成绩波动较大,最高分为98分,最低分为33分。
分数主要集中在60-80分之间,个别学生表现明显优异或较弱。
三、各章节表现1. 分子与细胞•平均分:68分•表现较好的章节,学生掌握情况较为扎实。
•考题涵盖了细胞结构、分子生物学等内容,普遍表现较好。
2. 遗传与进化•平均分:60分•表现一般,部分学生对于遗传与进化理论掌握不够扎实。
•考题主要涵盖了基因遗传、人类进化等内容。
3. 生物体的结构与功能•平均分:72分•表现较好的章节,学生对生物体结构和功能的理解比较深入。
•考题主要涵盖了器官系统、生理机能等内容。
四、学习建议1. 巩固基础知识建议学生重点巩固生物学的基础知识,加强对生物学原理的理解和应用能力。
2. 多做习题通过多做生物学习题,加强对知识点的掌握和运用,提高解题能力。
3. 多参加讨论建议学生积极参加生物学知识讨论和学习小组,与同学互相交流、讨论,共同提高学习水平。
五、结语本次生物期末考试成绩分析报告显示,绝大多数学生在生物学学习上取得了较好的成绩,但也有部分学生表现不佳。
希望通过此次分析,为学生提供有针对性的学习建议,帮助他们更好地提高生物学学习的效果,取得更好的成绩。
植物病理学报ACTAPHYTOPATHOLOGICASINICA㊀45(1):1 ̄6(2015)收稿日期:2014 ̄02 ̄06ꎻ修回日期:2014 ̄10 ̄14基金项目:国家自然科学基金资助项目(31471731)ꎻ高等学校学科创新引智计划(B07049)ꎻ 后稷学者 人才专项(Z111021008)资助通讯作者:胡小平ꎬ教授ꎬ主要从事植物病害流行学研究ꎻE ̄mail:xphu@nwsuaf.edu.cn第一作者:徐向明ꎬ研究员ꎬ主要从事植物抗病遗传及病害流行学研究ꎻE ̄mail:xiangming.xu@emr.ac.ukꎮdoi:10.13926/j.cnki.apps.2015.01.001专题评述植物病理学中常见数据的统计分析方法徐向明1ꎬ2ꎬ胡小平1∗(1西北农林科技大学植物保护学院/旱区作物逆境生物学国家重点实验室ꎬ中国杨凌712100ꎻ2东茂林研究所ꎬ英国肯特州郡ME196BJ)摘要:数据统计分析不充分或不正确ꎬ是导致中国科研工作者在国际期刊投稿中遭拒的主要原因之一ꎮ过去20年ꎬ统计方法学及计算机软件在统计应用方面已有重大进展ꎮ但是ꎬ大多数中国植物病理学家仍然使用传统的方差分析或普通的分析方法去分析一些数据ꎬ而这些数据其实可用更合适的方法分析ꎮ本文简要介绍一些适于植物病理学常见数据的统计分析方法ꎬ希望对广大科研工作者有所帮助ꎬ也希望加强与应用统计学家的科研合作ꎮ关键词:一般线性模型ꎻ广义线性模型ꎻ方差分析ꎻ植物病理学Statisticalanalysisofdatacommonlyoccurredinplantpathology㊀XUXiang ̄ming1ꎬ2ꎬHUXiao ̄ping1㊀(1StateKeyLaboratoryofCropStressBiologyinAridAreasandCollegeofPlantProtectionꎬNorthwestA&FUniversityꎬYangling712100ꎬChinaꎻ2EastMallingResearchꎬKentꎬME196BJꎬUK)Abstract:OneofmainreasonsforrejectionofmanuscriptwrittenbyChinesescientistsbyinternationaljournalsistheinadequateorincorrectstatisticaldataanalysis.Overthelasttwodecadesꎬtherehavebeensignificantde ̄velopmentsinstatisticalmethodologyandimplementationofstatisticsascomputersoftware.HoweverꎬmostplantpathologistsinChinaarestillusingconventionalANOVAorordinaryanalysisfortypesofdatathatshouldbeanalyzedbymoreappropriatemethods.Inthisshortpaperꎬwebrieflyintroducesomestatisticalmethodsthataremostlikelytobeappropriateforcommondatatypesencounteredinplantpathology.Wehopethiswoulden ̄ableresearcherstoreadmoreinaparticulartopicandtocollaboratewithappliedstatisticians.Keywords:generallinearmodelꎻgeneralizedlinearmodelꎻANOVAꎻplantpathology中图分类号:S431.2ꎻS431.3㊀㊀㊀㊀㊀文献标识码:A㊀㊀㊀㊀㊀文章编号:0412 ̄0914(2015)01 ̄0001 ̄06㊀㊀对于科研工作者而言ꎬ在同行审阅的国际期刊上发布研究结果是有压力的ꎮ由于投稿数量不断增加ꎬ而期刊的卷(期)并未同步增长ꎬ导致拒稿率不断提高ꎮ作者曾与一些国际期刊资深编辑进行讨论ꎬ大家认为研究者特别是中国科研工作者稿件被拒的主要原因之一是使用不恰当的统计方法分析数据ꎬ并从中得出结论ꎮ还有ꎬ即使使用了正确的统计方法ꎬ但没有在文章中清楚地呈现ꎮ本文旨在介绍植物病理学中常见数据相关的统计方法新进展ꎬ以期对科研工作者的数据分析有所帮助ꎮ1㊀植物病理学中常见的数据类型㊀㊀使用恰当的统计方法分析试验数据才能得出客观的结论ꎮ人们感兴趣的变量有它固有的变异性ꎬ无论怎样很好地实施试验ꎬ变量在重复单元之间或重复试验之间总会有差异ꎮ人们几乎不可能观察到感兴趣的总(群)体ꎬ而只能开展试验去研究感兴趣总体的样本ꎬ从样本推断总体会有很多不确定性ꎬ需要统计和量化这些不确定性ꎮ必须强调的是除了正确的数据统计分析外ꎬ恰当的试验设计㊀植物病理学报45卷也很关键ꎮ这里暂不讨论试验设计中的区组㊁随机化和重复问题ꎮ㊀㊀常规方差分析是科研工作者最熟悉的方法ꎮ该方法有4个假设ꎬ即:(1)每个数据相互独立ꎻ(2)残差呈正态分布ꎻ(3)残差方差相等(或 同质化 )ꎻ(4)残差和平均数(处理效应)是加性的ꎮ任何违反一个或多个假设都会导致常规方差分析结论在不同程度上的不准确性ꎮ统计分析和后续的显著性检验主要取决于数据的分布特征ꎮ这里先介绍植物病理学中一般数据类型的特征ꎮ1.1㊀发病率㊀㊀通常以统计一个小区发病植株(或植株单元ꎬ如叶片)的数目ꎬ或者估计发病植株所占的比率为基础ꎬ推测病叶率㊁病果率或病株率等ꎮ另一种数据类型是百分率ꎬ如萌发率ꎬ数字(频数)和比率都可以使用ꎮ例如ꎬ20片叶中有10片发病ꎬ就等于50%的病叶率ꎮ但必须注意的是ꎬ当使用比率数据时ꎬ必须给出评估单元的总数量ꎬ因为它会影响比率的准确性(或不确定性)ꎮ例如ꎬ将2个中有1个发病的比率与20个中有10个发病的比率相比ꎬ人们更相信后者ꎮ㊀㊀从评估单元的角度来看ꎬ一个单元只能是发生病害或者未发生病害两种类型ꎬ因此发病率是一个二进制变量ꎮ从整体来看ꎬ发病率是一个含有自然分母(总数)的可计数变量ꎮ例如ꎬ在总的评估单元数目中发病单元所占的数目(Y/NꎬY ̄发病的数目ꎬN ̄观察的总数目ꎬ如5/10)ꎮ可以看出ꎬ发病率应遵循平均数为p和方差为p(1-p)/N的二项分布ꎬ当样本容量(N)很大时ꎬ发病率可以近似为一个连续变量ꎬ近似于正态分布ꎮ以前ꎬ在普通的回归分析中ꎬ推荐用反正弦函数对发病率数据进行转换ꎬ从而使发病率数据更近于正态分布ꎮ随着统计理论和计算能力方面的进步ꎬ这种分析方法通常不再被使用ꎬ而是在假定发病率数据符合二项分布的条件下ꎬ采用广义线性回归法分析ꎮ1.2㊀病害严重度㊀㊀病害严重度是衡量植物组织相对的或绝对的发病面积ꎮ对于很多病害而言ꎬ严重度是植物表面的病斑面积ꎬ通常用占整个植物(观察单元)面积的比例或百分数表示ꎮ观察单元可以是叶片㊁根㊁茎㊁果实等ꎮ当观察值是面积(相对的或绝对的)时ꎬ严重度就是一个连续变量ꎬ可以用很多连续变量分布中的一个来描述ꎬ包括正态分布ꎮ因此ꎬ这些数据经一定转换后ꎬ可以使用普通回归模型进行分析ꎮ1.3㊀病害分级㊀㊀与发病率相比ꎬ病害严重度是一个更准确的指标ꎬ开发病害分级标准有助于对病害的评估ꎬ但很耗时ꎮ分级通常是发病程度的顺序排列ꎬ属有序分类变量ꎮ在对这类数据进行分析时必须注意几个问题:除非病害级数在病害严重度上是线性的ꎬ否则计算平均级数值是无意义的ꎮ举一个例子来说明这个问题ꎮ假定一种病害有4个级别:0级ꎬ无病ꎻ1级ꎬ0<发病面积⩽5%ꎻ2级ꎬ5%<发病面积<25%ꎻ3级ꎬ发病面积⩾25%ꎮ在调查的20张叶片中0级病叶10张ꎬ2级病叶10张时ꎬ其平均病级数是1.0ꎬ这完全不同于20片叶均为1级的情况ꎬ前者的发病面积大约在6.6%ꎬ后者大约在2.5%ꎮ㊀㊀由于病害级数在病害严重度上是非线性的ꎬ计算平均数和采用传统的方差分析法分析病害级数数据是不正确的ꎮ对于这种类型的数据有2种分析方法可以使用:第一种ꎬ在分析数据之前ꎬ先将病害级数转换回到病害严重度(每一个级数等于该级数病害严重度的平均值ꎻ在上面的例子中ꎬ1级为相当于2.5%病害严重度)ꎮ第二种ꎬ可以采用基于多项分布的广义线性模型ꎬ这种方法叫做比例优势模型(ProportionalOddsModel ̄POM)ꎮ1.4㊀病害密度㊀㊀对于很多病害来说ꎬ统计每个植株或单位面积上的病斑数(或其他侵染单元)ꎬ常被当作一种严重度ꎮ例如ꎬ估计每张叶片上的白粉病斑数或锈菌孢子堆数ꎮ虽然它是一个计数变量ꎬ但与发病率数据不同的是它没有固有的自然分母ꎮ例如ꎬ人们并不知道叶片上孢子堆或病斑可能的最大数量ꎮ同样的ꎬ来自于孢子捕捉器的孢子数也可以作为病害密度的测量指标ꎮ对于这种计数数据可以用泊松分布㊁负二项分布等来描述ꎮ以前是先将病害密度数据进行对数转换ꎬ然后进行普通回归分析ꎬ现在应该假定数据符合泊松分布的条件下使用广义线性模型进行分析ꎮ通常一张叶片上的病斑分布不是随机分布ꎬ而是受局部传播或微气候条件的影响呈聚集分布ꎮ在这种情况下ꎬ可以假定数据符合负2㊀㊀1期徐向明ꎬ等:植物病理学中常见数据的统计分析方法二项分布ꎬ采用广义线性模型进行分析ꎮ1.5㊀相关联的观测值㊀㊀在植物病理学研究中ꎬ人们不仅仅对某一时间点上病害的发展感兴趣ꎬ对特定样本或处理病害的时间动态更感兴趣ꎬ而且了解病害的时间发展动态对病害管理是至关重要的ꎮ这类数据叫作重复测量数据ꎬ但同一个处理的时序观测值间有相关性ꎮ例如ꎬ第一次观测的发病率是10%ꎬ那么第二次观测的结果不应小于10%ꎮ同样的ꎬ有时候开展试验的田间小区可能与相邻田块是关联的ꎬ这样就会导致观测值中的非处理相关性ꎮ例如ꎬ病害发展通常从一个位点开始ꎬ从这一点产生的孢子就会局部传播ꎬ导致相邻小区菌源量水平与之相似ꎬ与远处小区不同ꎮ㊀㊀在撰写试验报告时ꎬ要注意术语混淆问题ꎮ准确度是指观察值与真实值之间的接近程度ꎮ精确度是指同一个处理不同观察值之间的彼此接近程度ꎮ通常并不知道试验的真实值ꎬ因此无法得到准确度ꎬ只能得到较高的精确度(更高的重复性)ꎮ2㊀统计分析的基本原理㊀㊀试验的目的是为了评估处理效应的大小和与其它变量间的关系ꎬ以及估计这些关系的不确定程度ꎮ统计分析作为一种工具是为了达到估计参数及其不确定性ꎮ假设目的变量(如病害严重度)遵循某一分布ꎬ通常利用算数平均数和方差去概括该分布特征ꎮ平均值表示的是分布的中心位点ꎬ而方差表示的是从中心位点的分散程度ꎮ人们感兴趣的通常是平均数(处理效应)ꎬ但有时感兴趣的也可能是某一变量的变异性ꎮ例如ꎬ真菌毒素污染小麦的可能范围ꎮ依据处理效应(或变量间的关系)相对于该处理效应(或关系)不确定程度的大小ꎬ可以推断是否有真实处理作用(或关系)ꎮ㊀㊀统计分析的复杂程度是由问题决定的ꎬ没有固定的对所有可能情形都是最好的统计分析方法ꎮ每个特定问题都有其适合的分析方法ꎮ即使对于相同的数据ꎬ回答不同的问题可能需要使用不同的分析方法ꎮ每种方法都有它自己的假定ꎮ因此ꎬ有必要了解这些基本假定ꎬ否则可能会导致得出错误的结论ꎮ㊀㊀我们选用常规方差分析来总结统计分析的基本原理和过程ꎮ每组(处理)内重复观察值是有变化的(用方差表示)ꎬ不同处理平均数间也是有差异的ꎬ这可能源于自然变化(相同与组内误差)和处理效应ꎮ如果没有处理效应(无效假设)ꎬ那么组间和组内的变异(方差)应该是相等的ꎮ因此ꎬ可以使用这2个方差的比值来确定是否有处理效应-方差比率ꎮ使用F分布确定得到的比率大于(或等于)从观察数据所得到方差比率值的概率ꎬ如果该概率小于所定显著性的概率(通常为5%或1%)ꎬ就表明有处理效应ꎮ该分析方法的前提是假定观察值符合上述4个假设ꎮF概率是在假定从一个正态分布总体(也就是说在无效假设成立的前提下ꎬ所有观察值都来自于同一分布总体)中随机抽样ꎬ利用F分布数学公式计算出的概率ꎮ如果数据不符合这些假设ꎬ显著性检验就不可靠了ꎮ㊀㊀基本的统计方法ꎬ如t测验㊁配对测验㊁常规方差分析等可以用回归分析来描述ꎬ唯一的区别在于回归分析的数据类型ꎮ方差分析中回归分析的自变量是分类变量(处理因素ꎬ如品种㊁杀菌剂等)ꎮ在 传统 的回归分析中ꎬ自变量是连续变量ꎬ如温度㊁株高和杀菌剂的剂量等ꎮ在协方差分析中ꎬ回归分析的自变量包含分类变量和连续变量ꎮ因此ꎬ这里以回归模型的形式来阐述数据分析ꎮ2.1㊀一般线性模型(普通回归)㊀㊀一个自变量的简单线性模型为:Yij=μi+εij=α+Xijβi+εij㊀㊀Yij是第i个处理的第j个观察值ꎬμi是第i个处理的期望值ꎬ可由线性回归模型(α+Xβ)预测ꎬα为总平均值ꎬεij是残差ꎮ在方差分析中ꎬX是代表处理水平的设计矩阵(1或0)ꎬβ是处理效应ꎻ在回归分析中ꎬX是连续变量ꎬα为截距ꎬβ是斜率(一个自变量的效应)ꎮ上面的公式可以很容易地通过矩阵的方式扩展为多个自变量(α也包含在斜率矩阵中)ꎮμi可使用回归分析来估算ꎮ㊀㊀如前所述ꎬ方差分析必须同时符合4个基本假设ꎬ如果分布不同或非可加性都会使处理效应与误差混淆ꎻ非正态分布或处理间的方差不等会影响显著性检测的可靠性ꎮ在回归分析中ꎬ还存在自变量共线性问题及影响点问题(一个或者几个异常数据点对参数的影响)等ꎮ㊀㊀除了评估处理效应(β)外ꎬ还需要评估误差方差(σ2)来评价处理效应的不确定性(每个处理的分布均值(μi)和共同误差方差(σ2))ꎮ对于正态分布而言ꎬ均值与方差分布是不相关的ꎬ可以使用最小二乘法估计参数ꎮ3㊀植物病理学报45卷㊀㊀在拟合回归方程后ꎬ需要检查残差(非原始数据)是否符合这几个假设ꎮ常见的统计分析软件包都能提供针对这几个假设的数据或图形ꎮ如果与一个或多个假设相违背时ꎬ应当寻求替代分析方法ꎬ最简单的办法是进行数据转换ꎮ例如ꎬ误差和处理均值是非可加性的ꎬ而是倍数关系时ꎬ可以使用对数转换使之符合可加性ꎮ对数转换经常被用来减少处理间的方差异质性ꎻ反正弦转换经常用于百分比数据ꎬ特别是当观察值小于0.3或者大于0.7的情况下ꎮ转换并不能消除所有与假设违背的情况ꎬ可能会在回转时引致偏差ꎮ建立在转换后数值为基础的统计推断往往不容易在原始测量尺度上解释ꎮ㊀㊀必须强调的是ꎬ如果感兴趣的变量不呈正态分布(例如ꎬ发病率数据呈二项式分布)ꎬ这时就不应该试图转换数据ꎬ而应该试图寻找一个新方法来解决问题ꎮ近年来ꎬ在统计方法和计算机计算能力方面都取得了重大进展ꎮ现在ꎬ可以利用回归模型拟合不符合正态分布的数据(见广义线性模型部分)ꎮ因此ꎬ对常见非正态分布(如二项式分布㊁泊松分布㊁负二项分布)的数据进行数据转换后再进行普通回归(例如方差分析)一般是不会被接受的ꎬ例如ꎬ发病率数据经反正弦转换后ꎬ进行简单的方差分析ꎮ这类型数据经过转换进行简单方差分析得出的结论ꎬ远没有经过广义线性模型直接分析得出的可靠ꎮ一般情况下ꎬ最好选择不需数据转换的数据分析方法ꎮ㊀㊀除了转换数据外ꎬ在特定条件下其它测试显著性的方法也可以使用ꎮ例如ꎬ可以用排列和随机化法进行显著性分析ꎬ而不是F测验ꎮ如果数据不服从一般的分布ꎬ可使用不依赖分布类型的数据分析方法(非参数法ꎬ如秩序法)ꎮ如果误差不是独立的(空间㊁时间或时空上相关)ꎬ就应该使用混合模型ꎬ特别是对于有大的邻近效应的重复测量数据和田间数据的分析ꎮ2.2 广义线性模型㊀㊀广义线性模型是将普通回归模型拓展到适合非正态分布数据的分析方法ꎮ广义线性模型公式为:Yij=h(μi)+εij㊀㊀这里h(μi)=Xiβ和一般线性模型是一样的ꎮ在广义线性模型中ꎬ假定(1)处理效应和εij(误差)是可加性的ꎻ(2)εij相互独立和具有相同的分布ꎻ(3)εij遵循指数分布ꎮ具体的指数分布是比较难理解的ꎬ但在植物病理学中所常见的分布如正态㊁二项㊁泊松㊁负二项和γ分布等都属于指数分布ꎮ因此ꎬ一般线性模型是依变量遵循正态分布的广义线性模型的一个特例ꎮ㊀㊀在广义线性模型中y的期望值仍然是μiꎬ但是它的一个函数(称为关联函数)与自变量成线性关系ꎮ广义线性模型有3个组成部分:首先ꎬ需要指定一个分布类型ꎮ其次ꎬ一个自变量的线性模型(Xβ)ꎮ第三ꎬ使用关联函数g()=h-1(Xβ)将线性模型和分布函数的平均值(及处理效应)联系起来ꎮ处理效应通过g()转换为自变量的线性函数ꎮ该转换确保了预测的正确性ꎮ例如ꎬ发病率(p)的取值范围是从0到1ꎬ如果不做数据转换ꎬ将它直接与自变量回归ꎬ在很多情况下ꎬ预测的p值将在(0ꎬ1)之外ꎮ对于二项分布而言ꎬ常用的关联函数是logit[ln(p/(1-p))]ꎬ因此ln(p/(1-p))=Xβ确保了p(=exp(Xβ)/(1+exp(Xβ)))在正确(0-1)范围内ꎮ要强调的是ꎬ通过这个函数的数据转换和通常进行线性回归之前的数据转换是不同的ꎬ关联数据转换应用到期望平均值(μi)ꎬ而传统的数据转换是应用到个体的观察值ꎮ㊀㊀一旦确定了分布类型和关联函数ꎬ那么拟合一个广义线性模型的方法与一般线性模型的方法是相似的ꎮ因此ꎬ只需要知道数据的分布类型和模型的适用范围(关联函数)ꎮ数据分析软件包通常对于一个特定分布有它系统默认的关联函数ꎬ比如logit适于二项分布ꎬ对数适于泊松分布等ꎮ而正态分布的关联函数就是其本身(成为普通回归模型)ꎮ选择关联函数和确定随机变量的分布是分开进行的ꎬ需要参考统计程序包的说明或统计学书籍ꎮ㊀㊀除正态分布外ꎬ其他所有分布的方差随着平均值而变化ꎬ如泊松分布的方差和它的平均值相等ꎮ因此参数估计一般是通过最大似然迭代法来估计的ꎮ重要的是不需要知道算法是如何工作的ꎬ而是要知道为何使用广义线性模型进行分析ꎮ㊀㊀模型的评估是基于相当于普通回归中方差的DevianceꎮDeviance是log似然值的最大值和一个饱和模型(完美拟合:有一个观察值就有一个参数)的log的最大似然值之间的差值ꎮDeviance越大ꎬ拟合越差ꎮ模型的检验方法和普通回归模型相似ꎮ㊀㊀把病害分级数据(3个或更多的有序分类级别)当作连续数据分析是不正确的ꎬ有几种可能的数据分析方法:一是比例优势模型(POM)ꎮPOM4㊀㊀1期徐向明ꎬ等:植物病理学中常见数据的统计分析方法预测在类别j中或超出每个处理的ln(odds)(Odd是一个事件的概率比值ꎬ如发病的概率与未发病概率的比值)ꎬ评估ln(odds)是如何被自变量影响的ꎬ其本质是对二项分布数据进行广义线性模型分析的拓展ꎬ在二项分布数据(发病或未发病)中只有两种结果ꎬ但是在病害级数数据中要多于两个结果ꎮ其二减少多类级别到两个类别ꎬ例如发病与未发病ꎬ然后进行二项分布广义线性模型的分析ꎮ2.3㊀线性或广义线性混合模型㊀㊀普通线性和广义线性模型适合于只有一个随机或误差来源的数据ꎮ在很多情况下ꎬ误差有很多来源ꎬ一个混合模型可包含一个以上的误差来源ꎮ例如ꎬ在测试杀菌剂的效果时ꎬ可以在多地对随机选择的品种植株进行病害发展过程观测(看看杀菌剂的持久性)ꎬ在这里ꎬ个体植株㊁受试品种㊁受试地点和每个观察的剩余变异等都会有随机变异ꎮ众所周知ꎬ在农业试验中的裂区设计有2个误差来源(大区与小区)ꎮ㊀㊀标准的方差分析法可以用来分析有一个以上误差来源的平衡数据ꎬ但不能分析植物病理学中常见的不平衡数据ꎮ这些数据可以使用REML(Re ̄stricted[或Residual]MaximumLikelihood)方法进行分析ꎮ使用REML方法ꎬ也可以运用meta分析ꎬ对感兴趣处理的不同数据集同时分析来获得综合评估ꎬ这也是当今的热点问题之一ꎮ由于研究者来自不同的组织机构ꎬ所做的试验相似但不同ꎬ常规统计方法无法从这些试验中得到综合性结果ꎮ㊀㊀如之前所述ꎬ在田间病害试验中由于接种点及局部传播问题ꎬ邻近小区的病害在空间上是相关的ꎬ而且受盛行风向的进一步影响ꎬ这将违背方差分析的一个假设ꎬ即观测值的独立性ꎮ采用每个小区处理的随机分配法只能消除特定处理与单个小区的系统误差ꎬ但不能消除空间上的相关性ꎮ这种空间上相关的数据可以用REML方法来分析ꎬ可以明确如何在二维空间中模拟空间相关性ꎬ从而得到有关处理效应的更可靠的结论ꎮ在REML分析方法中ꎬ不同类型的模型可以用来模拟空间相关性ꎬ比如自回归模型㊁幂模型等ꎮ㊀㊀在植物病理学研究中的次级抽样技术也很容易导致相关联的观测值ꎮ例如ꎬ在有3个区组ꎬ每一个区组有4个小区(4个处理)的随机区组设计中ꎬ从每个小区中随机选取10株植物观察病害发展情况ꎬ可以用随机区组设计的方差分析来分析每个小区10株植物的平均值ꎮ但如果每个植株的观测值被直接用来进行传统的方差分析就不正确了ꎬ因为在相同小区中的10个植株处于同一环境下具有一定的相关性ꎬ需要用混合模型进行分析ꎬ要理解试验单元(小区)和观测单元(个体植株)之间的差异ꎮ㊀㊀植物病理学中一个常用数据类型是对同一植株或处理病害发展的重复评价ꎮ如果研究重点是每个处理中病害发展的时间动态ꎬ则可以拟合病害发展曲线(通常是非线性模型ꎬ在这篇文章中没有涉及)ꎬ比较处理间的参数ꎮ另一方面ꎬ因为同一个处理的观察值在时间上是关联的ꎬ使用传统的方差分析来分析该类数据是不对的ꎬ而应使用重复测量的方差分析法ꎮ观测值间的时间相关性可能是不相等的ꎬ相近的观察值较相远的观察值的相关性更大ꎬ而重复测量方差分析的假定是同等相关性ꎬ在这种情况下ꎬ应该使用REML分析方法ꎮ对于重复测量数据还有几种先进的分析方法ꎬ如随机相关系数模型等ꎮ㊀㊀在混合模型中ꎬ有时需要确定哪一个因子是混合的ꎬ哪一个是随机的ꎬ但没有一个清晰的定义ꎮ如果仅仅对特定的处理(一个特定的水平)感兴趣ꎬ那么这个因子应该被视为固定的ꎮ另一方面ꎬ如果试验处理是一个群体的一个随机样本ꎬ那么这个因子可被认为是随机的ꎮ例如ꎬ在测验2个品种在5个县的抗病性试验中ꎬ如果对2个品种在这5个县的表现特别感兴趣ꎬ那么这些县就可以被当做固定因子(这2个品种只是种植在这5个县)ꎮ如果这5个县是一个很大区域中的一个随机样点ꎬ这2个品种将会在这一大片区域种植ꎬ那么这些县应该被视为随机因子ꎮ有时ꎬ所有的试验因子都是随机因子ꎮ例如ꎬ想评估地域和品种对小麦赤霉菌毒素变异性的影响ꎬ那么地域和品种就被视为随机因子ꎬ应该从所有可能的地域和品种中随机选取ꎮ㊀㊀在普通线性回归分析中(假设数据服从正态分布)ꎬ通常使用方差分析或REML混合模型分析几种变异来源ꎮ广义混合线性模型是比较新的方法ꎬ它拓展了广义线性模型框架ꎬ允许在线性模型中包括可加性随机效应ꎬ仍然是当前的研究热点ꎮ2.4㊀2种模型的比较㊀㊀在方差分析中ꎬ当整体有显著处理效应时ꎬ可以使用两两比较法比较2个处理水平间的差异ꎮ5㊀植物病理学报45卷在一个给定的回归模型里ꎬ常用t测验确定一自变量的斜率参数是否大于0ꎮ同样的ꎬ在比较2个模型的相同自变量的斜率ꎬ可以使用t测验去估计这2个斜率是否相等ꎮ但在进行多重比较时(尤其是在方差分析中有很多配对比较)ꎬ可能得出假的显著效应ꎮ例如ꎬ假定显著水平设定为5%ꎬ即使20对间没有显著差异ꎬ也可能会在20对中有1对的结果被确定为有显著差异ꎮ㊀㊀以上的两两比较分析相当于2个模型的比较ꎮ但2个模型的比较常常不仅是只比较一个参数ꎬ而是要同时评估多个参数的差异性ꎮ当比较2个模型时ꎬ人们不会问 一个模型是对还是错 ꎬ而是问哪一个模型对这些数据的拟合程度更好 ?一个模型的优势是相对于其他模型来说的ꎮ比较2个模型时ꎬ要知道它们是否是嵌套关系ꎮ㊀㊀ 嵌套模型 是一个很重要的概念ꎬ非线性模型㊁广义线性模型和混合模型的比较和假设检验都基于这个概念ꎮ当一个模型的所有项出现在另外一个模型中时ꎬ那么这2个模型是嵌套的ꎬ前者嵌套在后者中ꎬ也就是说简单模型源于较大的模型ꎮ例如ꎬ假定模型A是y=a+bxꎬ模型B是y=aꎬ那么模型B就是模型A的嵌套模型ꎬ因为在模型A中加一个限制条件b=0ꎬ就可以得到模型Bꎮ模型比较基于一个原则ꎬ即用2个模型残差的差异来衡量这些限制因子是否合理ꎮ如果2个残差之间没有显着差异ꎬ那么就并不需要额外的参数(b)ꎮ也就是说ꎬ模型A中参数b等于零ꎮ㊀㊀对于具有正态分布误差的嵌套回归模型(包括非线性回归)的比较ꎬ可以使用F ̄测验ꎮ假定大模型的残差平方和SSf的自由度为mꎬ嵌套模型有q个限制参数ꎬ残差平方和为SSrꎬ可以通过自由度为q和m的F ̄测验ꎬ确定是否可以接受q个限制条件:㊀㊀方差比值=SSr-SSfq/SSfm这是比较多项参数模型的一个很强大的技术ꎮ例如ꎬ使用逻辑斯蒂曲线拟合4个品种上的某病害发展数据ꎬ也许有人会问是否有一个对于所有品种共同的速率参数?可以拟合一个针对每个模型的不同参数的完整模型ꎬ然后对所有的品种拟合一个具有相同速率参数的逻辑斯蒂模型ꎬ使用F ̄检验评估4个品种的速率参数是否相等ꎮ㊀㊀比较2个GLM(非正态分布数据)模型或者混合模型ꎬ也是常常通过嵌套模型的概念来评估的ꎬ只不过是用2个嵌套模型之间的deviances差异和卡平方测验来进行评估ꎮ㊀㊀如果2个模型不是嵌套的且有不同数量的参数ꎬ那么以上介绍的方法将不能用来比较ꎮ比较非嵌套模型是基于几个常用信息标准ꎮ最常用的是Akaike信息量准则(AkaikeinformationcriterionꎬAIC)ꎬ它考虑了模型参数的数量ꎬAIC值越小ꎬ表明模型越好ꎮ3 结束语㊀㊀本文没有介绍与植物病理学相关的其它一些数据统计分析方法ꎬ例如非线性模型拟合㊁存活分析㊁时间序列分析等方法ꎮ希望研究者在使用程序软件包分析数据之前能够多思考ꎬ多与应用统计学家讨论ꎮ有兴趣的话ꎬ也可以参考一些教科书[1~7]ꎮ参考文献[1]㊀CoxDRꎬSnellEJ.Analysisofbinarydata[M].London:ChapmanandHall/CRCPressꎬ1989. [2]㊀McCullaghPꎬNelderJA.Generalizedlinearmodels[A].MonographsonStatistics&AppliedProbability[M].London:ChapmanandHall/CRCPressꎬ1989. [3]㊀MillerRGJ.BeyondANOVA:Basicsofappliedstatistics[M].London:ChapmanandHall/CRCPressꎬ1997.[4]㊀PlantRE.Spatialdataanalysisinecologyandagricul ̄tureusingR[M].London:ChapmanandHall/CRCPressꎬ2012.[5]㊀QianSS.EnvironmentalandecologicalstatisticswithR[M].London:Chapman&Hall/CRCPressꎬ2009. [6]㊀SchabenbergerOꎬPierceFJ.Contemporarystatisticalmodelsfortheplantandsoilsciences[M].London:Chapman&Hall/CRCPressꎬ2001.[7]㊀WhitlockMCꎬSchluterD.Theanalysisofbiologicaldata[M].Colorado:RobertsandCompanyPubli ̄shersꎬ2008.责任编辑:于金枝6。
《植物学》分组讲解内容
第一组:植物组织
1、保护组织
2、输导组织
第二组:根
1、根系在土壤中的分布状态,受哪些因子影响?
2、双子叶植物根的初生构造与次生构造的差异有哪些?
第三组:茎
1、分枝的类型及了解植物分枝的指导意义?
2、双子叶植物茎的初生构造与次生构造的差异有哪些?
第四组:叶
1、双子叶植物叶的基本构造?
2、叶的构造与环境的适应性关系如何?
第五组:花
1、花的组成及名称?
2、雌蕊与雄蕊的结构及发育过程?
第六组:果
1、果实的各组成部分是由花的哪部分发育而来的?
2、果实的结构及种类?
第七组:种子
1、种子的组成部分是如何发育来的?
2、种子萌发所必须的条件?为什么?
第八组:植物类群
1、植物各类群的区别主要特征有哪些?
2、植物进化演化的一般规律是怎样的?
注:每组4人,按名单上顺序依次分组,每组设组长一人。
各内容的讲解和讨论在老师讲解此内容之前进行,讲解时可派代表,但代表人数不定,讲解的状态、课件水平代表本组成绩,个人成绩以每个人上交的讲稿为参考,此项内容成绩的评定方法为:个人成绩=小组成绩×40% + 各人讲稿成绩×60%
本课程总评成绩评定方法:
考试(40分)+大作业(12分)+实验报告(14分)+实验预习报告(7分)+小组讲解讨论(5分)+实习报告(6分)+实习考试(6分)+课堂表现(4分)+考勤(6分)=100分
旷课(包括霸王假):-3分/次,迟到、早退:-1分/次。
浅论植物学考试成绩统计分析及评价
摘要:为总结植物学教学经验,检验教学效果,本文对新疆大学生命科学与技术学院生物技术和生物科学专业146名本科生植物学期末考试成绩进行统计分析。
结果表明此次试卷设计较合理,成绩近似正态分布,试题难度属中等。
本文最后结合统计分析结果对改进教学方法和手段提出一些建议。
关键词:植物学;试卷分析;教学评价
中图分类号:G642.0 文献标志码:A 文章编号:1674-9324(2014)30-0146-02
植物学是综合性大学、师范院校及农、林、医等院校生物类相关专业的基础课程。
本课程在大学一年级开设,是学生对所学专业产生兴趣并树立专业志向的入门课程。
植物学课程是一门历史久远、课程体系完整、教学内容庞大的传统学科。
植物学是高等院校涉及面最广的专业基础课程之一,也是新疆大学生命科学与技术学院生物技术、生物工程、生物科学、食品工程等专业新生入学后首开的专业基础课程。
学生通过植物学的学习可为学好后续相关专业课程(如:植物生理学、细胞生物学、生物化学、遗传学、环境生物学、资源植物学等)奠定坚实的基础;同时,也为植物学的一些分支学科(如细胞学、组织学、器官学、孢粉学、胚胎学等)知识的综合应用奠定基础。
因而其学科地位十分重要。
检测学生学习成绩和检查教师教学效果的最直接最简便最有效方法是考试。
通过分析考试成绩发现教学中存在的问题和薄弱环节,筛选高质量试题,而且有助于教师对教学内容进行调整,进一步促进教学方法的革新。
因此,我们对2008、2009、2010级生物科学和生物技术本科生《植物学》期末考试试卷学生成绩进行了统计分析找出存在的问题,以便进一步搞好《植物学》教学,提高教学质量,促进课程建设。
一、研究对象
测试对象为2009、2010级生物技术、生命科学专业班学生,共5个班,146名学生。
采用周云龙主编的普通高等教育“十五”国家级规划教材《植物生物学》。
由我院生物科学系植物教研组老师承担教学任务。
考核采用闭卷考试,考试用时为120分钟考试过程中考场纪律严明,无违反考场纪律现象。
二、试题组成及学生得分情况
各任课教师按教学大纲要求出题,由2名教师负责命题过程及筛选组织试题。
试题覆盖《植物学》教材各部分知识。
整张试题由7部分组成:单项选择题、判断题、填空题、连线题、图中注明各部分名称、名词解释和问答题。
每一大题的编排顺序是由易到难,由简单到复杂。
这样编排可以缓解学生考试过程中的紧张情绪。
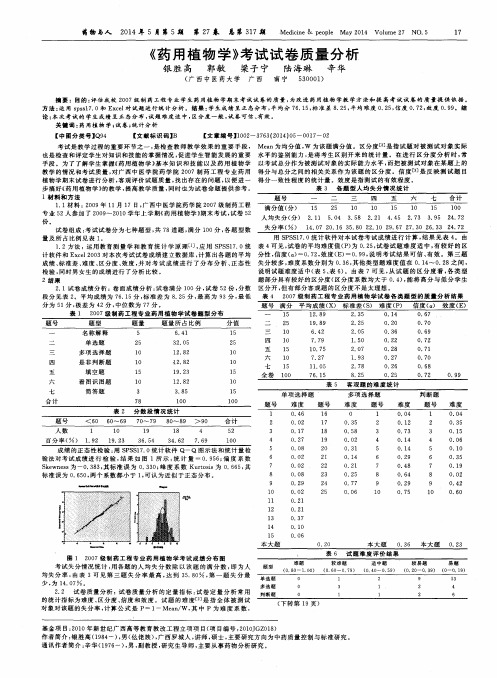
试卷考试题组成及其学生得分情况见表l。
三、考试质量分析
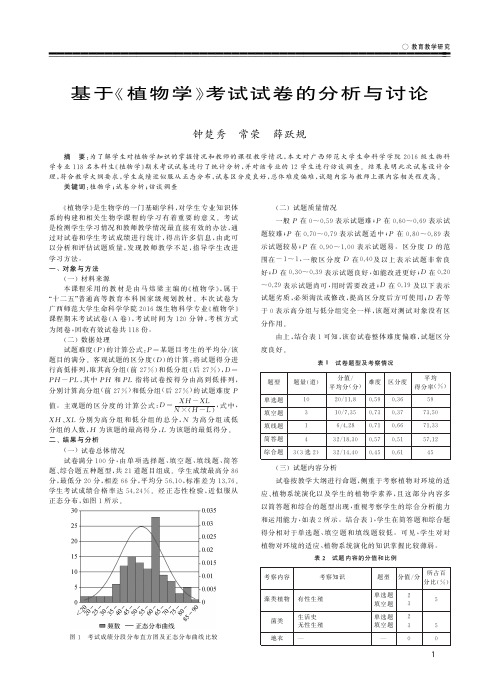
(一)学生成绩频数分布
从统计的学生成绩来看,考试成绩总体比较好,参加考试的146名学生中只
有4名学生不及格,最低分为50分,最高分为93分,相差43分,平均分数为71.34分,标准差为7.03.考试成绩主要集中在65~75分之间,经正态性检验基本符合正态分布。
学生成绩频数分布见表2。
(二)试题难度、区分度
试题难度、区分度和信度是评价试卷质量的主要指标。
其中难度可以衡量考试难易程度,通常用全体考生做出正确回答的百分比表示。
试题难度计算公式为:P=X/W其中P为难度,X为样本平均得分,W为试卷总分。
区分度是指考试题目对考生心理特征的区分能力。
区分度高的试题能将不同水平的考生区分开来,水平高的考生得高分,水平低的考生得低分。
区分度高的考试,优秀、一般、差三个层次的学生都有一定比例,如果某一分数区间学生相对集中,高分太多或不及格太多的考试,区分度则低。
区分度的计算公式为:D=2*(XH-XL)/W,其中D为试卷区分度,XH为27%高分组平均分,XL为27%低分组平均分,W为试卷总分。
本次《植物学》考试试题统计分析中,难度和区分度分别为0.71和
0.51。
四、分析与讨论
本次统计分析的《植物学》考试试题基本涵盖本教材的所有内容,符合教学大纲的要求。
试题注重考查学生掌握的基础知识和基本能力,同时又关注学生植物学知识的形成过程、各知识点之间的联系。
从考试情况看,全部学生按时交卷,没有学生因为时间不够而影响考试成绩,说明试题量与时间安排比较合理。
在试题层次方面,包括记忆、理解和综合分析应用等,能较准确反映学生全面掌握和分析应用植物学知识的能力。
本次《植物学》考试试题统计分析中,试题难度P为0.71。
一般试题难度P≤0.6表示试题难,0.60.4为非常好题,0.3<D≤0.4为良好题,0.2≤D≤0.3为尚可、仍需修改题,D<0.2为差题。
通过对试卷综合分析,发现大多数考生对基础知识比较扎实,对记忆类考题答对率高,而实际综合分析类题答题率低,说明学生学习过程仍以死记硬背为主,没有真正的掌握教材里的内容,知识联系面窄,未养成独立思考分析及逻辑推理的良好习惯。
这种现象提醒我们今后在教学过程中应该改进教学方法和教学手段。
改进教学方法首先要做到有效运用启发式教学;学生能否学好一门课程的前提在于其是否具有学习的积极性、主动性,所以要在启发学生对植物学学科及课程产生兴趣的基础上,进一步启发其学习的积极性,然后才是在每一堂课上对学生进行具体教学内容的启发式教学。
其二,因材施教,注重个性化培养学生的兴趣、能力等许多方面均是多样性的,因此,在教学过程中为学生的个性化发展提供一定的空间。
如对那些在实验和野外实习方面感兴趣的学生,积极考研究生的学生,立志从事教育的学生等分别给予一定的指导。
其三,加强理论课与实践环节有效结合。
如:在理论课上尽量渗透实验原理与过程,而在实验课上适当加强理论上的解释。
同样,对待理论课与野外实习关系的处理上也是如此。
其四,在教学中,应根据课程特色,立足于当地植物资源优势,将植物学基础知识的学习与当地植物资源的开发、利用与保护相结合。
要改进教学手段首先要做到注重课堂教学的同时还适当的延长野外实习,野外考察、实验课的教学时量,让学生进一步更好地掌握课堂上学到的知识。
其二,除了进一步丰富传统的挂图、标本、模型和网络下载的一些植物图片等教学资源外,更加丰富多媒体课件的内容,不仅用网上的植物图片外,还增加一些学生日常生活中能看到的,具有地域特色的
植物的图片,这样帮助学生了解植物动态的生长过程,从而将抽象的专业知识简单化、直观化,而且在有限的时间内大大增加教学信息量,课堂气氛更加活跃,可以提高学生的学习兴趣。