统计概率知识点梳理总结
- 格式:doc
- 大小:711.00 KB
- 文档页数:35

概率与统计知识点总结一、概率的基本概念概率,简单来说,就是衡量某个事件发生可能性大小的一个数值。
比如抛硬币,正面朝上的概率是 05,意思是在大量重复抛硬币的实验中,正面朝上的次数大约占总次数的一半。
随机事件,就是在一定条件下,可能出现也可能不出现,而在大量重复试验中具有某种规律性的事件。
比如掷骰子得到的点数就是随机事件。
必然事件,就是在一定条件下必然会发生的事件。
比如太阳从东方升起,这就是必然事件。
不可能事件,就是在一定条件下不可能发生的事件。
比如在地球上,水往高处流就是不可能事件。
概率的取值范围在 0 到 1 之间。
0 表示事件不可能发生,1 表示事件必然发生。
二、古典概型古典概型是一种最简单、最基本的概率模型。
它具有两个特点:试验中所有可能出现的基本事件只有有限个;每个基本事件出现的可能性相等。
计算古典概型中事件 A 的概率公式为:P(A) = A 包含的基本事件个数/基本事件的总数。
例如,一个袋子里有 5 个红球和 3 个白球,从中随机摸出一个球是红球的概率,基本事件总数是 8(5 个红球+ 3 个白球),红球的个数是 5,所以摸到红球的概率就是 5/8。
三、几何概型与古典概型不同,几何概型中的基本事件个数是无限的。
比如在一个时间段内等可能地到达某一地点,或者在一个区域内等可能地取点。
几何概型的概率计算公式是:P(A) =构成事件 A 的区域长度(面积或体积)/试验的全部结果所构成的区域长度(面积或体积)。
举个例子,在区间0, 10中随机取一个数,这个数小于 5 的概率就是 5/10 = 05。
四、条件概率条件概率是在已知某个事件发生的条件下,另一个事件发生的概率。
记事件 A 在事件 B 发生的条件下发生的概率为 P(A|B)。
计算公式为:P(A|B) = P(AB) / P(B) ,其中 P(AB) 表示事件 A 和事件 B 同时发生的概率。
比如说,已知今天下雨,明天也下雨的概率就是一个条件概率。

(完整版)(最全)高中数学概率统计知识点总结-CAL-FENGHAI.-(YICAI)-Company One1概率与统计一、普通的众数、平均数、中位数及方差1、 众数:一组数据中,出现次数最多的数。
2、平均数:①、常规平均数:12nx x x x n++⋅⋅⋅+=②、加权平均数:112212n n n x x x x ωωωωωω++⋅⋅⋅+=++⋅⋅⋅+3、中位数:从大到小或者从小到大排列,最中间或最中间两个数的平均数。
4、方差:2222121[()()()]n s x x x x x x n=-+-+⋅⋅⋅+-二、频率直方分布图下的频率1、频率 =小长方形面积:f S y d ==⨯距;频率=频数/总数2、频率之和:121n f f f ++⋅⋅⋅+=;同时 121n S S S ++⋅⋅⋅+=; 三、频率直方分布图下的众数、平均数、中位数及方差 1、众数:最高小矩形底边的中点。
2、平均数: 112233n nx x f x f x f x f =+++⋅⋅⋅+ 112233n n x x S x S x S x S =+++⋅⋅⋅+3、中位数:从左到右或者从右到左累加,面积等于0.5时x 的值。
4、方差:22221122()()()n n s x x f x x f x x f =-+-+⋅⋅⋅+-四、线性回归直线方程:ˆˆˆybx a =+ 其中:1122211()()ˆ()nni i i i i i nni i i i x x y y x y nxybx x x nx ====---∑∑==--∑∑ , ˆˆay bx =- 1、线性回归直线方程必过样本中心(,)x y ;2、ˆ0:b>正相关;ˆ0:b <负相关。
3、线性回归直线方程:ˆˆˆy bx a =+的斜率ˆb 中,两个公式中分子、分母对应也相等;中间可以推导得到。
五、回归分析1、残差:ˆˆi i i ey y =-(残差=真实值—预报值)。

统计概率知识点梳理总结统计概率是统计学中非常重要的一个分支,它研究随机现象的概率规律,为我们处理不确定性的问题提供了一种方法。
在统计概率的学习中,有一些基本概念和方法是必须掌握的。
本文将对统计概率的相关知识进行梳理总结,包括概率基本概念、概率分布、概率密度函数、概率函数、随机变量、概率质量函数、期望、方差等内容。
1.概率基本概念概率是一个介于0-1之间的数,用来度量一个事件发生的可能性。
概率的基本概念包括样本空间、随机事件、事件的概率、事件的互斥和事件的独立性等。
样本空间是指试验中所有可能结果的集合,随机事件是指样本空间中的一个子集,事件的概率是指该事件发生的可能性大小,用P(A)表示。
事件的互斥指两个事件不可能同时发生,事件的独立性指两个事件之间的发生没有关系。
2.概率分布概率分布是描述随机变量所有可能取值及其对应概率的分布情况。
常见的概率分布包括离散型概率分布和连续型概率分布。
离散型概率分布是指随机变量只能取其中的一个值的概率分布,如伯努利分布和泊松分布;连续型概率分布是指随机变量可以取任意实数值的概率分布,如正态分布和指数分布。
3.概率密度函数概率密度函数是描述连续型随机变量的概率分布的函数,用f(x)表示。
概率密度函数具有非负性、非减性和归一性等性质。
通过概率密度函数可以计算随机变量在其中一区间内取值的概率。
4.概率函数概率函数是描述离散型随机变量的概率分布的函数,它给出了随机变量取各个值的概率。
概率函数具有非负性和归一性等性质。
通过概率函数可以计算随机变量取一些特定值的概率。
5.随机变量随机变量是一个实数值函数,它的取值是试验结果的函数。
随机变量可以是离散型的,也可以是连续型的。
离散型随机变量通常用字母大写表示,如X;连续型随机变量通常用字母小写表示,如x。
随机变量可以有多种数学表达方式,如分布函数、概率密度函数和概率函数等。
6.概率质量函数概率质量函数是描述离散型随机变量的概率分布的函数,用p(x)表示。
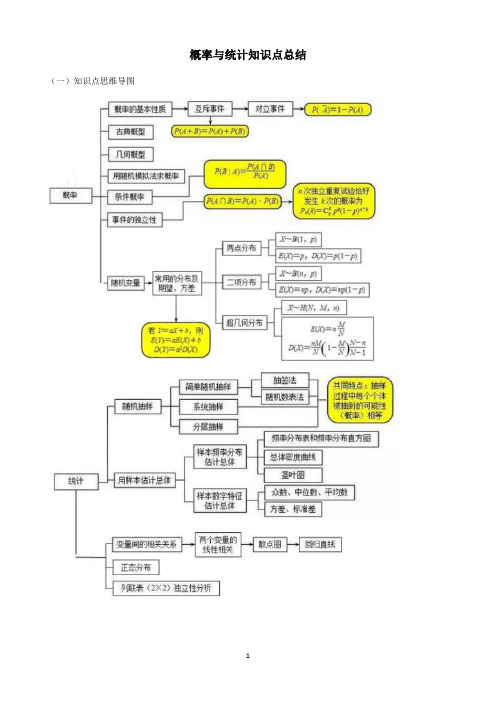
概率与统计知识点总结(一)知识点思维导图(二)常用定理、公式及其变形1.用样本的数字特征估计总体的数字特征(1)样本本均值:nx x x x n +++= 21 (2)样本标准差:nx x x x x x s s n 222212)()()(-++-+-== (3)频率分布直方图估算样本众数、中位数、平均数①众数:最高小矩形中点值;②中位数:先确定中位数所在小组,设中位数为m ,由直线x=m 两侧小矩形面积之和等于0.5列方程求m . ③平均数:各小矩形中点值与其面积的积的和.2.随机事件的概率及概率的意义(1)随机事件:在条件S 下可能发生也可能不发生的事件,叫相对于条件S 的随机事件;(2)概率定义:在相同的条件S 下重复n 次试验,观察某一事件A 是否出现,称n 次试验中事件A 出现的次数n A 为事件A 出现的频数;称事件A 出现的比例f n (A)=n n A为事件A 出现的频率:对于给定的随机事件A ,如果随着试验次数的增加,事件A 发生的频率f n (A)稳定在某个常数上,把这个常数记作P (A ),称为事件A 的概率.3.概率的基本性质(1)事件的包含、并事件、交事件、相等事件(2)若A∩B 为不可能事件,即A∩B=ф,那么称事件A 与事件B 互斥;(3)若A∩B 为不可能事件,A∪B 为必然事件,那么称事件A 与事件B 互为对立事件;(4)当事件A 与B 互斥时,满足加法公式:P(A∪B)= P(A)+ P(B);若事件A 与B 为对立事件,则A∪B 为必然事件,所以P(A∪B)= P(A)+ P(B)=1,于是有P(A)=1—P(B)4.古典概型及随机数的产生(1)古典概型的使用条件:试验结果的有限性和所有结果的等可能性.(2)公式P (A )=总的基本事件个数包含的基本事件数A 5.几何概型及均匀随机数的产生(1)几何概率模型:如果每个事件发生的概率只与构成该事件区域的长度(面积或体积)成比例,则称这样的概率模型为几何概率模型;(2)公式:P (A )=积)的区域长度(面积或体试验的全部结果所构成积)的区域长度(面积或体构成事件A . 6.随机变量:如果随机试验可能出现的结果可以用一个变量X 来表示,并且X 是随着试验的结果的不同而变化,那么这样的变量叫做随机变量. 随机变量常用大写字母X 、Y 等或希腊字母 ξ、η等表示.7.离散型随机变量的分布列:一般的,设离散型随机变量X 可能取的值为x 1,x 2,..... ,x i ,......,x n .X 取每一个值 x i (i=1,2,......)的概率P(ξ=x i )=P i ,则称表为离散型随机变量X 的概率分布,简称分布列分布列性质:∪ p i ≥0, i =1,2, … ;∪ p 1 + p 2 +…+p n = 1.9.条件概率:对任意事件A 和事件B ,在已知事件A 发生的条件下事件B 发生的概率,叫做条件概率.记作P(B|A),读作A 发生的条件下B 的概率公式:.0)(,)()()|(>=A P A P AB P A B P 10.相互独立事件:事件A(或B)是否发生对事件B(或A)发生的概率没有影响,这样的两个事件叫做相互独立事件,)()()(B P A P B A P ⋅=⋅12.数学期望:一般地,若离散型随机变量ξ的概率分布为 则称 Eξ=x 1p 1+x 2p 2+…+x n p n 为ξ的数学期望或平均数、均值,数学期望又简称为期望.是离散型随机变量.13.方差:D(ξ)=(x 1-Eξ)2·P 1+(x 2-Eξ)2·P 2 +......+(x n -Eξ)2·P n 叫随机变量ξ的均方差,简称方差.14.正态分布:(1)定义:若概率密度曲线就是或近似地是函数 的图象,其中解析式中的实数0)μσσ>、(是参数,分别表示总体的平均数与标准差.则其分布叫正态分布(,)N μσ记作:,f( x )的图象称为正态曲线;(2)基本性质:∪曲线在x 轴的上方,与x 轴不相交;∪曲线关于直线x=对称,且在x=时位于最高点;∪当一定时,曲线的形状由确定.越大,曲线越“矮胖”;表示总体的分布越分散;越小,曲线越“瘦高”,表示总体的分布越集中;∪正态曲线下的总面积等于1.15.3原则:从上表看到,正态总体在 以外取值的概率只有4.6%,在 以外取值的概率只有0.3% 由于这些概率很小,通常称这些情况发生为小概率事件.也就是说,通常认为这些情况在一次试验中几乎是不可能发生的.),(,21)(222)(+∞-∞∈=--x e x f x σμσπμμμσσσσ)2,2(σμσμ+-)3,3(σμσμ+-17.回归分析。

必修第二册第九章 统计知识点总结知识点一:简单随机抽样1. 全面调查和抽样调查2.简单随机抽样的概念放回简单随机抽样不放回简单随机抽样一般地,设一个总体含有N(N 为正整数)个个体,从中逐个抽取n (1≤n<N)个个体作为样本如果抽取是放回的,且每次抽取时总体内的各个个体被抽到的概率都相等,我们把这样的抽样方法叫做放回简单随机抽样如果抽取是不放回的,且每次抽取时总体内未进入样本的各个个体被抽到的概率都相等,我们把这样的抽样方法叫做不放回简单随机抽样放回简单随机抽样和不放回简单随机抽样统称为简单随机抽样.通过简单随机抽样获得的样本称为简单随机样本3.抽签法先把总体中的个体编号,然后把所有编号写在外观、质地等无差别的小纸片(也可以是卡片、小球等)上作为号签,并将这些小纸片放在一个不透明的盒里,充分搅拌.最后从盒中不放回地逐个抽取号签,使与号签上的编号对应的个体进入样本,直到抽足样本所需要的个体数.调查方式全面调查(普查)抽样调查定义对每一个调查对象都进行调查的方法,称为全面调查,又称普查根据一定目的,从总体中抽取一部分个体进行调查,并以此为依据对总体的情况作出估计和推断的调查方法,称为 抽样调查相关概念总体:在一个调查中,我们把调查对象的全体称为总体.个体:组成总体的每一个调查对象称为个体样本:把从总体中抽取的那部分个体 称为样本.样本量:样本中包含的个体数称为 样本量4.随机数法(1)定义:先把总体中的个体编号,用随机数工具产生已编号范围内的整数随机数,把产生的随机数作为抽中的编号,使与编号对应的个体进入样本,重复上述过程,直到抽足样本所需要的个体数.(2)产生随机数的方法:(i)用随机试验生成随机数;(ii)用信息技术生成随机数.5.总体均值和样本均值(1)总体均值:一般地,总体中有N个个体,它们的变量值分别为Y1,Y2,…,Y N,则称Y=Y1+Y2+⋯+Y NN =1N∑i=1NY i为总体均值,又称总体平均数.(2)总体均值加权平均数的形式:如果总体的N个变量值中,不同的值共有k(k≤N)个,不妨记为Y1,Y2,…,Y k,其中Y i出现的频数f i(i=1,2,…,k),则总体均值还可以写成加权平均数的形式Y=1N ∑i=1kf i Y i.(3)如果从总体中抽取一个容量为n的样本,它们的变量值分别为y1,y2,…,y n,则称y=y1+y2+⋯+y nn =1n∑i=1ny i为样本均值,又称样本平均数.6.分层随机抽样的相关概念(1)分层随机抽样的定义:一般地,按一个或多个变量把总体划分成若干个子总体,每个个体属于且仅属于一个子总体,在每个子总体中独立地进行简单随机抽样,再把所有子总体中抽取的样本合在一起作为总样本,这样的抽样方法称为分层随机抽样,每一个子总体称为层.(2)比例分配:在分层随机抽样中,如果每层样本量都与层的大小成比例,那么称这种样本量的分配方式为比例分配.(3)进行分层随机抽样的相关计算时,常用到的关系①样本容量n总体容量N =该层抽取的个体数该层的个体数;②总体中某两层的个体数之比等于样本中这两层抽取的个体数之比;③样本的平均数和各层的样本平均数的关系:w=mm+n x+nm+ny=MM+Nx+NM+Ny.1.画频率分布直方图的步骤(1)求极差:极差为一组数据中最大值与最小值的差;(2)决定组距与组数:当样本容量不超过100时,常分成5-12组,为方便起见,一般取等长组距,并且组距应力求“取整”;(3)将数据分组;(4)列频率分布表:一般分四列:分组、频数累计、频数、频率.其中频数合计应是样本容量,频率合计是⑥1;.(5)画频率分布直方图:横轴表示分组,纵轴表示频率组距=频率,各小长方形的面积的总和等于1.小长方形的面积=组距×频率组距2.其他统计图表统计图表主要应用扇形图直观描述各部分数据在全部数据中所占的比例条形图和直方图直观描述不同类别或分组数据的频数和频率反映统计对象在不同时间(或其他合适情形)的发展折线图变化情况1.第p百分位数:一般地,一组数据的第p百分位数是这样一个值,它使得这组数据中至少有p%的数据小于或等于这个值,且至少有(100-p)%的数据大于或等于这个值.2.计算一组n个数据的第p百分位数的步骤第1步,按从小到大排列原始数据.第2步,计算i=n×p%.第3步,若i不是整数,而大于i的比邻整数为j,则第p百分位数为第j项数据;若i是整数,则第p百分位数为第i项与第(i+1)项数据的平均数.3.四分位数:第25百分位数,第50百分位数,第75百分位数,这三个分位数把一组由小到大排列后的数据分成四等份,因此称为四分位数.知识点四:总体集中趋势的估计1.众数、中位数和平均数的定义(1)众数:一组数据中出现次数最多的数.(2)中位数:一组数据按大小顺序排列后,处于中间位置的数.如果这组数据是偶数个,则取中间两个数据的平均数.(3)平均数:一组数据的和除以数据个数所得到的数.2.众数、中位数、平均数与频率分布直方图的关系(1)平均数:在频率分布直方图中,样本平均数可以用每个小矩形底边中点的横坐标与小矩形的面积的乘积之和近似代替.(2)中位数:在频率分布直方图中,中位数左边和右边的直方图的面积应该相等.(3)众数:众数是最高小矩形底边的中点所对应的数据.2.众数、中位数、平均数与频率分布直方图的关系众数众数是最高小长方形底边的中点所对应的数据,表示样本数据的中心值中位数①在频率分布直方图中,中位数左边和右边的直方图面积相等,由此可以估计中位数的值,但是有偏差;②表示样本数据所占频率的等分线平均数①平均数等于每个小长方形的面积乘小长方形底边中点的横坐标之和;②平均数是频率分布直方图的重心,是频率分布直方图的平衡点1.一组数据x1,x2,…,x n的方差和标准差数据x1,x2,…,x n的方差为1n ∑i=1n(x i-x)2=1n∑i=1nx i2-x2,标准差为√1n∑i=1n(x i-x)2.2.总体方差和总体标准差(1)总体方差和标准差:如果总体中所有个体的变量值分别为Y1,Y2,…,Y N,总体的平均数为Y,则称S2= 1N ∑i=1N(Y i-Y)2为总体方差,S=√S2为总体标准差.(2)总体方差的加权形式:如果总体的N个变量值中,不同的值共有k(k≤N)个,不妨记为Y1,Y2,…,Y k,其中Y i出现的频数为f i(i=1,2,…,k),则总体方差为S2= 1N ∑i=1kf i(Y i-Y)2.3.样本方差和样本标准差如果一个样本中个体的变量值分别为y1,y2,…,y n,样本平均数为y,则称s2= 1n ∑i=1n(y i-y)2为样本方差,s=√s2为样本标准差.4.标准差的意义标准差刻画了数据的离散程度或波动幅度,标准差越大,数据的离散程度越大;标准差越小,数据的离散程度越小.5.分层随机抽样的方差设样本容量为n,平均数为x,其中两层的个体数量分别为n1,n2,两层的平均数分别为x1,x2,方差分别为s12,s22,则这个样本的方差为s2=n1n [s12+(x1-x)2]+n2n[s22+(x2-x)2].必修第二册第十章概率知识点总结知识点一:有限样本空间与随机事件1.随机试验的概念和特点(1)随机试验:我们把对随机现象的实现和对它的观察称为随机试验,简称试验,常用字母E表示.(2)随机试验的特点:(i)试验可以在相同条件下重复进行;(ii)试验的所有可能结果是明确可知的,并且不止一个;(iii)每次试验总是恰好出现这些可能结果中的一个,但事先不能确定出现哪一个结果.2.样本点和样本空间定义字母表示样本点我们把随机试验E的每个可能的基本结果称为样本点用ω表示样本点样本空间全体样本点的集合称为试验E的样本空间用Ω表示样本空间有限样本空间如果一个随机试验有n个可能结果ω1,ω2,…,ωn,则称样本空间Ω={ω1,ω2,…,ωn}为有限样本空间Ω={ω1,ω2,…,ωn}3.事件的类型我们将样本空间Ω的子集称为随机事件,简称事件,并把只包含一个样本点的事件称为基本事件.随机事件一般用大写字母A,B,C,…表示.在每次试验中,当且仅当A中某个样本点出现时,称为事件A发生.Ω作为自身的子集,包含了所有的样本点,在每次试验中总有一个样本点发生,所以Ω总会发生,我们称Ω为必然事件.而空集⌀不包含任何样本点,在每次试验中都不会发生,我们称⌀为不可能事件.必然事件与不可能事件不具有随机性.为了方便统一处理,将必然事件和不可能事件作为随机事件的两个极端情形.这样,每个事件都是样本空间Ω的一个子集.知识点二:事件的关系和运算1.包含关系定义一般地,若事件A 发生,则事件B 一定发生,我们就称事件B 包含事件A(或事件A 包含于事件B)含义 A 发生导致B 发生 符号表示B ⊇A(或A ⊆B)图形表示特殊情形如果事件B 包含事件A,事件A 也包含事件B,即B ⊇A 且A ⊇B,则称事件A 与事件B 相等,记作A=B2.并事件(和事件)定义一般地,事件A 与事件B 至少有一个发生,这样的一个事件中的样本点或者在事件A 中,或者在事件B 中,我们称这个事件为事件A 与事件B 的并事件(或 和事件)含义 A 与B 至少有一个发生符号表示A ∪B(或A+B)图形表示3.交事件(积事件)定义一般地,事件A 与事件B 同时发生,这样的一个事件中的样本点既在事件A中,也在事件B 中,我们称这样的一个事件为事件A 与事件B 的交事件(或积 事件)含义 A 与B 同时发生 符号表示A ∩B(或AB)图形表示4.互斥(互不相容)一般地,如果事件A与事件B不能同时发生,也就是说A∩B是一个不可能定义事件,即A∩B=⌀,则称事件A与事件B互斥(或互不相容)含义A与B不能同时发生符号表示A∩B=⌀图形表示5.互为对立一般地,如果事件A与事件B在任何一次试验中有且仅有一个发生,即A∪B=定义Ω,且A∩B=⌀,那么称事件A与事件B互为对立.事件A的对立事件记为A 含义A与B有且仅有一个发生符号表示A∩B=⌀,且A∪B=Ω图形表示6.清楚随机事件的运算与集合运算的对应关系有助于解决此类问题.符号事件的运算集合的运算A 随机事件集合A A的对立事件A的补集AB 事件A与B的交事件集合A与B的交集A∪B 事件A与B的并事件集合A与B的并集知识点三:古典概型1.古典概型的定义试验具有如下共同特征:(1)有限性:样本空间的样本点只有有限个;(2)等可能性:每个样本点发生的可能性相等.我们将具有以上两个特征的试验称为古典概型试验,其数学模型称为古典概率模型,简称古典概型.2.古典概型的概率计算公式一般地,设试验E是古典概型,样本空间Ω包含n个样本点,事件A包含其中的k个样本点,则定义事件A的概率P(A)= kn =n(A)n(Ω),其中n(A)和n(Ω)分别表示事件A和样本空间Ω包含的样本点个数.知识点四:概率的基本性质1.概率的基本性质性质1 对任意的事件A,都有P(A)≥0.性质2 必然事件的概率为1,不可能事件的概率为0,即P(Ω)=1,P(⌀)=0.性质3 如果事件A与事件B互斥,那么P(A∪B)=P(A)+P(B).性质4 如果事件A与事件B互为对立事件,那么P(B)=1-P(A),P(A)=1-P(B).性质5 如果A⊆B,那么P(A)≤P(B).性质6 设A,B是一个随机试验中的两个事件,我们有P(A∪B)=P(A)+P(B)-P(A∩B).知识点五:事件的相互独立性1.相互独立事件的定义:对任意两个事件A与B,如果P(AB)=P(A)P(B)成立,则称事件A 与事件B相互独立,简称为独立.2.相互独立事件的性质:当事件A,B相互独立时,则事件A与事件B相互独立,事件A与事件B相互独立,事件A与事件B相互独立.【提示】公式P(AB)=P(A)P(B)可以推广到一般情形:如果事件A1,A2,…,A n相互独立,那么这n个事件同时发生的概率等于每个事件发生的概率的积,即P(A1A2·…·A n)=P(A1)P(A2)·…·P(A n).3. 两个事件是否相互独立的判断方法(1)直接法:由事件本身的性质直接判定两个事件发生是否相互影响.(2)公式法:若P(AB)=P(A)P(B),则事件A,B为相互独立事件.4.求相互独立事件同时发生的概率的步骤:①首先确定各事件之间是相互独立的.②求出每个事件的概率,再求积.5.事件间的独立性关系已知两个事件A,B相互独立,它们的概率分别为P(A),P(B),则有事件表示概率A,B同时发生AB P(A)P(B)A,B都不发生A B P(A)P(B)A,B恰有一个发生(A B)∪(A B) P(A)P(B)+P(A)P(B)A,B中至少有一个发生(A B)∪(A B)∪(AB) P(A)P(B)+P(A)P(B)+P(A)P(B)A,B中至多有一个发生(A B)∪(A B)∪(A B) P(A)P(B)+P(A)P(B)+P(A)P(B)。

概率统计知识点总结一、概率统计基本概念1. 随机事件和样本空间在概率统计中,随机事件是指在一次试验中可能发生的结果,例如抛硬币的结果可以是正面或反面。
样本空间是指所有可能的结果的集合,例如抛硬币的样本空间为{正面,反面}。
2. 概率和基本概率公式概率是指某一事件在所有可能事件中发生的频率,通常用P(A)表示。
基本概率公式是P(A)=n(A)/n(S),其中n(A)表示事件A发生的次数,n(S)表示样本空间的大小。
3. 条件概率条件概率是指在事件B已经发生的条件下,事件A发生的概率,通常表示为P(A|B)。
4. 独立事件两个事件A和B称为独立事件,意味着事件A的发生不受事件B的影响,其概率关系为P(A∩B)=P(A)×P(B)。
二、概率统计的数据分析方法1. 描述性统计描述性统计是对数据进行总结和描述的方法,包括平均数、中位数、众数、标准差、极差等指标,用来描述数据的集中趋势、离散程度和分布形状。
2. 探索性数据分析探索性数据分析是一种用图表和统计分析方法探索数据背后的规律和结构的方法,通过绘制图表和计算相关指标,发现数据之间的关系、趋势和异常值。
3. 统计推断统计推断是根据样本数据对总体参数进行推断的方法,包括点估计和区间估计,以及假设检验。
三、概率统计的应用1. 随机过程随机过程是研究随机事件随时间或空间变化的规律性的数学模型,包括马尔可夫过程、布朗运动、泊松过程等,广泛应用于金融、电信、生物等领域。
2. 统计建模统计建模是根据数据建立数学模型,预测未来的趋势和规律,包括线性回归模型、时间序列模型、机器学习模型等。
3. 贝叶斯统计贝叶斯统计是一种基于贝叶斯定理的概率统计方法,它将先验信息和样本数据结合起来,进行参数估计和模型推断,常用于医学、生态学、市场营销等领域。
四、概率统计的挑战和发展1. 大数据与统计随着大数据时代的到来,传统的统计方法和模型已经无法满足大规模、高维度、非结构化数据的分析需求,需要发展新的统计方法和算法。
概率与统计一、概率及随机变量的分布列、期望与方差(一)概率及其计算1.几个互斥事件和事件概率的加法公式①如果事件A 与事件B 互斥,则()P A B =()()P A P B +.推广:如果事件1A ,2A ,…,n A 两两互斥(彼此互斥),那么事件12n A A A +++发生的概率,等于这n 个事件分别发生的概率的和,即()12n P A A A +++=()()()12n P A P A P A ++.②若事件B 与事件A 互为对立事件,则()P A =()1P B -. 2.古典概型的概率公式P (A )=A 包含的基本事件的个数基本事件的总数.(二)随机变量的分布列、期望与方差1. 常用的离散型随机变量的分布列(1)二项分布如果随机变量X 的可能取值为0,1,2,…,n ,且X 取值的概率()P X k ==C k k n kn p q-(其中0,1,2,,,1k n q p ==-),其随机变量分布列为X 0 1 …k…nP0C nnp q111C n np q-…C k k n knp q-…0C n n n p q则称X 服从二项分布,记为(),X B n p ~.(2)超几何分布在含有M 件次品的N 件产品中,任取n 件,其中恰有X 件次品,则事件{}X k =发生的概率为C C C k n kM N Mn N--()0,10,1,2,,2,,k m =,其中{}min ,m M n =,且n N …,M N …,n ,M ,*N ÎN .此时称随机变量X 的分布列为超几何分布列,称随机变量X 服从超几何分布.2.条件概率及相互独立事件同时发生的概率 I.条件概率条件概率一般地,设A ,B 为两个事件,且()0P A >,称()()()P ABP B A P A=为事件A 发生的条件下,事件B 发生的条件概率.在古典概型中,若用()n A 表示事件A 中基本事件的个数,则()()()()()n AB P AB P B A n A P A ==. II .相互独立事件相互独立事件(1)若,A B 相互独立.则()P AB =()()P A P B .(3)若A 与B 相互独立,则A 与B ,A 与B ,A 与B 也都相互独立. III .独立重复试验与二项分布独立重复试验与二项分布在n 次独立重复试验中,事件A 发生k 次的概率为(每次试验中事件A 发生的概率为p)()C 1n kkknp p --,事件A 发生的次数是一个随机变量X ,其分布列为()01)2()C 1(n kk knP X k k n p p -===-¼,,,,,此时称随机变量X 服从二项分布. 学科*网3.离散型随机变量的数学期望(均值)与方差 (1)若离散型随机变量X 的概率分布列为的概率分布列为X x 1 x 2 … x i … x n P p 1 p 2 … p i … p n则称EX =1122i i n n x p x p x p x p ++++¼+¼为随机变量X 的均值或数学期望. (2)若Y aX b =+,则EY =aEX b +,)(D aX b +=2a DX (3)若()X B n p ~,,则EX np =.()(1)D X np p -=. 4.正态分布(1)正态曲线的性质:正态曲线的性质:①曲线位于x 轴上方,与x 轴不相交;②曲线是单峰的,它关于直线x m =对称;③曲线在x m=处达到峰值12πs;④曲线与x 轴之间的面积为1;⑤当s 一定时,曲线的位置由m 确定,曲线随着m 的变化而沿x 轴平移,⑥当m 一定时,曲线的形状由s 确定,s 越小,曲线越“瘦高”,表示总体的分布越集中;s 越大,曲线越“矮胖”,表示总体的分布越分散,如图乙所示.(3)服从正态分布的变量在三个特殊区间内取值的概率服从正态分布的变量在三个特殊区间内取值的概率 ①0().6826P X m s m s -<+=…;②2209().544P X m s m s -<+=…; ③3309().974P X m s m s -<+=…. 二、统计与统计案例 (一)抽样方法 1.简单随机抽样设一个总体含有N 个个体,从中逐个不放回地抽取n 个个体作为样本()n N …,如果每次抽取时总体内的各个个体被抽到的机会都相等,就把这种抽样方法叫做简单随机抽样,最常用的简单随机抽样的方法:抽签法和随机数表法.最常用的简单随机抽样的方法:抽签法和随机数表法. 2.系统抽样的步骤假设要从容量为N 的总体中抽取容量为n 的样本.的样本.(1)先将总体的N 个个体编号.(2)确定分段间隔k ,对编号进行分段,当Nn是整数时,取N k n =.如果遇到Nn不是整数的情况,可以先从总体中随机地剔除几个个体,使得总体中剩余的个体数能被样本容量整除得总体中剩余的个体数能被样本容量整除(3)在第1段用简单随机抽样确定第一个个体编号()l l k ….(4)按照一定的规则抽取样本,通常是将l 加上间隔k 得到第2个个体编号()l k +,再加k 得到第3个个体编号()2l k +,依次进行下去,直到获取整个样本.直到获取整个样本.3.分层抽样在抽样时,将总体分成互不交叉的层,然后按照一定的比例,从各层独立地抽取一定数量的个体,将各层取出的个体合在一起作为样本,这种抽样方法是一种分层抽样.分层抽样的应用范围:当总体是由差异明显的几个部分组成的,往往选用分层抽样.层抽样.注:注:不论哪种抽样方法不论哪种抽样方法,总体中的每一个个体入样的概率是相同的. (二)统计图表的含义 1.作频率分布直方图的步骤(1)求极差(即一组数据中最大值与最小值的差).(2)决定组距和组数.(3)将数据分组.(4)列频率分布表.列频率分布表. (5)画频率分布直方图.画频率分布直方图. (三)样本的数字特征1.众数:在一组数据中,出现次数最多的数据叫做这组数据的众数.出现次数最多的数据叫做这组数据的众数.2.中位数:将一组数据按大小依次排列,把处在中间位置的一个数据(或中间两个数据的平均数)叫做这组数据的中位数叫做这组数据的中位数3.平均数:样本数据的算术平均数,即x =()121n x x x n+++.4.方差:()()()2222121n s x x x x x x n éù=-+-++-êúëû(n x 是样本数据,n 是样本容量,x 是样本平均数).5.标准差:()()()222121ns x x x x x x n éù=-+-++-êúëû.(四)线性回归直线方程 1.两个变量的线性相关(1)如果散点图中点的分布从整体上看大致在一条直线附近,我们就称这两个变量之间具有线性相关关系,这条直线叫回归直线.(2)从散点图上看,如果点分布在从左下角到右上角的区域内,那么两个变量的这种相关关系称为正相关;如果点分布在从左上角到右下角的区域内,那么两个变量的这种相关关系称为负相关. (3)相关系数相关系数r =ååå===----ni nj jini i i y y x x y y x x 11221)()())((,当0r >时,表示两个变量正相关;当0r <时,表示两个变量负相关.r 的绝对值越接近1,表示两个变量的线性相关性越强;r 的绝对值越接近0,表示两个变量的线性相关性越弱.通常当r 的绝对值大于0.75时,便认为两个变量具有很强的线性相关关系.当1r =时,两个变量在回归直线上两个变量在回归直线上 2.回归直线方程 (1)通过求21()ni i i Qy x a b ==--å的最小值而得出回归直线的方法,即使得样本数据的点到回归直线的距离的平方和最小的方法叫做最小二乘法.该式取最小值时的a ,b 的值即分别为aˆ,b ˆ. (2)两个具有线性相关关系的变量的一组数据:11(,)x y ,22(,)x y ,…,()n n x y ,,其回归方程为a x b y ˆˆˆ+=,则1122211()()ˆ()ˆˆnn i i i i i i n ni ii i x x y y x y nx yb x x x nxa y bx ====ì---×ï==ïí--ïï=-ïîåååå.注:样本点的中心(),x y 一定在回归直线上. (3)相关系数22121ˆ()1()n i ii ni i y yR y y ==-å=--å.2R 越大,说明残差平方和越小,即模型的拟合效果越好;2R 越小,残差平方和越大,即模型的拟合效果越差.在线性回归模型中,2R表示解释变量对于预报变量变化的贡献率,2R 越接近于1,表示回归的效果越好. (六)独立性检验(1)变量的不同“值”表示个体所属的不同类别,像这样的变量称为分类变量.像这样的变量称为分类变量.(2)像下表所示列出两个分类变量的频数表,称为列联表.假设有两个分类变量X和Y ,它们的可能取值分别为12(,)x x 和12(,)y y ,其样本频数列联表(称为22´列联表)为表)为y 1 y 2 总计总计x 1 a b a b + x 2 cdc d +总计a c +b d +a b c d +++构造一个随机变量()()()()()22n ad bc K a b c d a c b d -=++++ ,其中n a b c d =+++为样本容量.确定临界值0k ,如果2K 的观测值0k k …,就认为“两个分类变量之间有关系”;否则就认为“两个分类变量之间没有关系”.。
知识点总结:统计与概率I 统计1.三大抽样 (1)基本定义:①总体:在统计中,所有考查对象的全体叫做全体.②个体:在所有考查对象中的每一个考查对象都叫做个体. ③样本:从总体中抽取的一部分个体叫做总体的样本. ④样本容量:样本中个体的数目叫做样本容量. (2)抽样方法:①简单随机抽样:逐个不放回、等可能性、有限性。
=======★适用于总体较少★抽签法:整体编号(1~N )放入不透明的容器中搅拌均匀逐个抽取n次,即可得样本容量为n 的样本。
随机数表法:整体编号(等位数,如001、111不能是1、111)从0~9中随机取一行一列然后初方向随机(上、下、左、右)重复,超过范围则忽略不计直至取得以n 为样本容量的样本。
②系统抽样:容量大.等距,等可能。
=======★适用于总体多★用随机方法编号,若N 无法被整除,则剔除后再分组,nNk。
再用简单随机抽样法来抽取一个个体,设为l ,则编号为l ,k+l ,2k+l ……(n-1)k ,抽出容量为n 的样本。
(每组编号相同)。
③分层抽样:总体差异明显.按所占比例抽取.等可能.=======★适用于由差异明显的几部分构成的总体★总体有几个差异明显的部分构成,经总体分成几个部分,然后按照所占比例进行抽样.抽样比为:k =nN3.总体分布的估计: (1)一表二图:①频率分布表——数据详实②频率分布直方图——分布直观③频率分布折线图——便于观察总体分布趋势★注:总体分布的密度曲线与横轴围成的面积为1。
(2)茎叶图:①茎叶图适用于数据较少的情况,从中便于看出数据的分布,以及中位数.众位数等。
②个位数为叶,十位数为茎,右侧数据按照从小到大书写,相同的数据重复写。
4.样本分析(1)在频率直方图中计算众数.平均数.中位数众数在样本数据的频率分布直方图中,就是最高矩形的中点的横坐标。
(最多的那个)--忽视其他数据中位数在频率分布直方图中,中位数左边和右边的直方图的面积应该相等。
统计与概率知识点汇总高中统计与概率知识点汇总一、简单随机抽样1.总体和样本在统计学中,把研究对象的全体叫做总体.把每个研究对象叫作个体.把总体中个体的总数叫做总体容量.为了研究总体的有关性质,通常从总体中随机提取一部分:,,,研究,我们表示它为样本.其中个体的个数称作样本容量.2.简单随机抽样,也叫纯随机抽样。
就是从总体中不加任何分组、划类、排队等,完全随机地抽取调查单位。
特点是:每个样本单位被抽中的可能性相同(概率相等),样本的每个单位完全独立,彼此间无一定的关联性和排斥性。
简单随机抽样是其它各种抽样形式的基础。
通常只是在总体单位之间差异程度较小和数目较少时,才采用这种方法。
3.直观随机抽样常用的方法:(1)抽签法;⑵随机数表法;⑶计算机模拟法;⑷使用统计软件直接抽取。
在直观随机抽样的样本容量设计中,主要考量:①总体变异情况;②容许误差范围;③概率确保程度。
(1)给调查对象群体中的每一个对象编号;(2)准备工作分组的工具,实行分组(3)对样本中的每一个个体进行测量或调查基准:恳请调查你所在的学校的学生搞讨厌的体育活动情况。
5.随机数表法:基准:利用随机数Amancey所在的班级中提取10十一位同学出席某项活动。
1.系统抽样(等距抽样或机械抽样):把总体的单位展开排序,再排序出来样本距离,然后按照这一紧固的样本距离提取样本。
第一个样本使用直观随机抽样的办法提取。
k(抽样距离)=n(总体规模)/n(样本规模)前提条件:总体中个体的排序对于研究的变量来说,应当就是随机的,即为不存有某种与研究变量有关的规则原产。
可以在调查容许的条件下,从相同的样本已经开始样本,对照几次样本的特点。
如果存有显著差别,表明样本在总体中的原产成某种循环性规律,且这种循环和样本距离重合。
系统抽样,即等距抽样是实际中最为常用的抽样方法之一。
因为它对抽样框的要求较低,实施也比较简单。
更为重要的是,如果有某种与调查指标相关的辅助变量可供使用,总体单元按辅助变量的大小顺序排队的话,使用系统抽样可以大大提高估计精度。
总结概率与统计的考点梳理概率与统计是一门重要的数学学科,在各个领域都有广泛的应用。
为了帮助大家更好地理解和掌握概率与统计的知识,本文将对其考点进行梳理和总结。
一、概率基础知识概率是研究随机事件发生可能性的数学工具,它是数学中的一种测度。
概率的基础知识包括样本空间、随机事件、事件的概率、事件的互斥与独立等。
掌握这些基本概念是理解和运用概率原理的基础。
二、概率统计的基本原理概率统计是通过观察样本数据来推断总体的性质和规律。
它包括参数和统计量、抽样分布和估计等内容。
熟悉概率统计的基本原理对于进行实证研究和数据分析至关重要。
三、概率分布概率分布是概率统计中的重要内容,常见的概率分布有离散概率分布和连续概率分布。
离散概率分布包括二项分布、泊松分布等,而连续概率分布则包括正态分布、指数分布等。
对于每种概率分布,了解其概率密度函数或概率质量函数的性质和特点,并能正确地运用相应的分布进行问题求解是非常重要的。
四、参数估计参数估计是指通过样本数据对总体参数进行估计。
常用的参数估计方法有矩估计和最大似然估计。
在实际问题中,我们需要根据给定的样本数据来估计总体的参数,从而做出合理的推断和决策。
五、假设检验假设检验是概率统计的重要工具,用于判断总体参数是否符合某种假设。
在假设检验中,我们需要先提出原假设和备择假设,然后根据样本数据推断总体参数,最后对原假设进行接受或拒绝的判断。
熟练掌握假设检验的方法和步骤对于进行科学研究和数据分析具有重要意义。
六、回归分析回归分析是利用统计模型研究自变量与因变量之间关系的方法。
简单线性回归、多元线性回归、逻辑回归等是常见的回归分析方法。
通过回归分析可以得出自变量对因变量的影响程度和方向,为实证研究提供有力的依据。
七、抽样与抽样分布抽样是指从总体中取得样本的过程,它是概率统计的基础。
抽样分布是指统计量的概率分布。
通过抽样与抽样分布的理论,我们可以利用样本数据对总体进行推断和研究。
以上是概率与统计的一些重要考点的梳理和总结。
统计概率知识点梳理总结第一章随机事件与概率一、教学要求1.理解随机事件的概念,了解随机试验、样本空间的概念,掌握事件之间的关系与运算.2.了解概率的各种定义,掌握概率的基本性质并能运用这些性质进行概率计算. 3.理解条件概率的概念,掌握概率的乘法公式、全概率公式、贝叶斯公式,并能运用这些公式进行概率计算.4.理解事件的独立性概念,掌握运用事件独立性进行概率计算.5.掌握贝努里概型及其计算,能够将实际问题归结为贝努里概型,然后用二项概率计算有关事件的概率.本章重点:随机事件的概率计算.二、知识要点1.随机试验与样本空间具有下列三个特性的试验称为随机试验:(1) 试验可以在相同的条件下重复地进行;·(2) 每次试验的可能结果不止一个,但事先知道每次试验所有可能的结果;(3) 每次试验前不能确定哪一个结果会出现.试验的所有可能结果所组成的集合为样本空间,用Ω表示,其中的每一个结果用eΩ=.表示,e称为样本空间中的样本点,记作{}e2.随机事件在随机试验中,把一次试验中可能发生也可能不发生、而在大量重复试验中却呈现某 种规律性的事情称为随机事件(简称事件).通常把必然事件(记作Ω)与不可能事件(记作φ)看作特殊的随机事件.3.**事件的关系及运算(1) 包含:若事件A 发生,一定导致事件B 发生,那么,称事件B 包含事件A ,记作A B ⊂(或B A ⊃).(2) 相等:若两事件A 与B 相互包含,即A B ⊃且B A ⊃,那么,称事件A 与B 相等,记作A B =.(3) 和事件:“事件A 与事件B 中至少有一个发生”这一事件称为A 与B 的和事件,记作A B ⋃;“n 个事件1,2,,nA A A 中至少有一事件发生”这一事件称为1,2,,nA A A 的和,记作12n A A A ⋃⋃⋃(简记为1nii A =).(4) 积事件:“事件A 与事件B 同时发生”这一事件称为A 与B 的积事件,记作A B ⋂(简记为AB );“n 个事件1,2,,nA A A 同时发生”这一事件称为1,2,,nA A A 的积事件,记作12n A A A ⋂⋂⋂(简记为12n A A A 或1nii A =).(5) 互不相容:若事件A 和B 不能同时发生,即AB φ=,那么称事件A 与B 互不相容(或互斥),若n 个事件1,2,,nA A A 中任意两个事件不能同时发生,即i j A A φ=(1≤i<j ≤几),那么,称事件1,2,,nA A A 互不相容.(6) 对立事件:若事件A 和B 互不相容、且它们中必有一事件发生,即AB φ=且A B ⋃=Ω,那么,称A 与B 是对立的.事件A 的对立事件(或逆事件)记作A .(7) 差事件:若事件A 发生且事件B 不发生,那么,称这个事件为事件A 与B 的差事件,记作A B -(或AB ) .(8) 交换律:对任意两个事件A和B 有A B B A ⋃=⋃,AB BA =.(9) 结合律:对任意事件A ,B ,C 有()()A B C A B C ⋃⋃=⋃⋃, ()()A B C A B C ⋂⋂=⋂⋂.(10) 分配律:对任意事件A ,B ,C 有()()()A B C A B A C ⋃⋂=⋃⋂⋃, ()()()A B C A B A C ⋂⋃=⋂⋃⋂.(11) 德摩根(De Morgan )法则:对任意事件A 和B 有A B A B ⋃=⋂, A B A B ⋂=⋂.4.频率与概率的定义 (1) 频率的定义设随机事件A 在n 次重复试验中发生了A n 次,则比值A n /n 称为随机事件A 发生的频率,记作()n f A ,即()An n f A n =.(2) 概率的统计定义在进行大量重复试验中,随机事件A 发生的频率具有稳定性,即当试验次数n 很大时,频率()n f A 在一个稳定的值p (0<p <1)附近摆动,规定事件A 发生的频率的稳定值p 为概率,即()P A p =.(3) **古典概率的定义具有下列两个特征的随机试验的数学模型称为古典概型: (i) 试验的样本空间Ω是个有限集,不妨记作12{,,,}n e e e Ω=;(ii) 在每次试验中,每个样本点i e (1,2,,i n =)出现的概率相同,即12({})({})({})n P e P e P e ===.在古典概型中,规定事件A 的概率为()An A P A n ==Ω中所含样本点的个数中所含样本点的个数.(4) 几何概率的定义如果随机试验的样本空间是一个区域(可以是直线上的区间、平面或空间中的区域),且样本空间中每个试验结果的出现具有等可能性,那么规定事件A的概率为()A P A =的长度(或面积、体积)样本空间的的长度(或面积、体积)·(5) 概率的公理化定义设随机试验的样本空间为Ω,随机事件A 是Ω的子集,()P A 是实值函数,若满足下列三条公理:公理1 (非负性) 对于任一随机事件A,有()P A ≥0; 公理2 (规性) 对于必然事件Ω,有()1P Ω=;公理3 (可列可加性) 对于两两互不相容的事件1,2,,,n A A A ,有11()()i i i i P A P A ∞∞===∑,则称()P A 为随机事件A的概率. 5.**概率的性质由概率的三条公理可导出下面概率的一些重要性质 (1) ()0P φ=.(2) (有限可加性) 设n 个事件1,2,,nA A A 两两互不相容,则有121()()nn i i P A A A P A =⋃⋃⋃=∑.(3) 对于任意一个事件A :()1()P A P A =-.(4) 若事件A ,B 满足A B ⊂,则有()()()P B A P B P A -=-,()()P A P B ≤.(5) 对于任意一个事件A ,有()1P A ≤. (6) (加法公式) 对于任意两个事件A ,B ,有()()()()P A B P A P B P AB ⋃=+-.对于任意n 个事件1,2,,nA A A ,有111111()()()()(1)()nnn i i i j i j k n i i j ni j k ni P A P A P A A P A A A P A A -=≤<≤≤<<≤==-+-+-∑∑∑.6.**条件概率与乘法公式设A 与B 是两个事件.在事件B 发生的条件下事件A 发生的概率称为条件概率,记作(|)P A B .当()0P B >,规定()(|)()P AB P A B P B =.在同一条件下,条件概率具有概率的一切性质.乘法公式:对于任意两个事件A 与B ,当()0P A >,()0P B >时,有()()(|)()(|)P AB P A P B A P B P A B ==.7.*随机事件的相互独立性如果事件A 与B 满足()()()P AB P A P B =,那么,称事件A 与B 相互独立.关于事件A ,月的独立性有下列两条性质:(1) 如果()0P A >,那么,事件A 与B 相互独立的充分必要条件是(|)()P B A P B =;如果()0P B >,那么,事件A 与B 相互独立的充分必要条件是(|)()P A B P A =. 这条性质的直观意义是“事件A 与B 发生与否互不影响”. (2) 下列四个命题是等价的: (i) 事件A 与B 相互独立; (ii) 事件A 与B 相互独立; (iii) 事件A 与B 相互独立; (iv) 事件A 与B 相互独立.对于任意n 个事件1,2,,nA A A 相互独立性定义如下:对任意一个2,,k n =,任意的11k i i n ≤<<≤,若事件1,2,,nA A A 总满足11()()()k k i i i i P A A P A P A =,则称事件1,2,,nA A A 相互独立.这里实际上包含了21nn --个等式.8.*贝努里概型与二项概率设在每次试验中,随机事件A发生的概率()(01)P A p p =<<,则在n 次重复独立试验中.,事件A恰发生k 次的概率为()(1),0,1,,kn k n n P k p p k nk -⎛⎫=-= ⎪⎝⎭,称这组概率为二项概率. 9.**全概率公式与贝叶斯公式全概率公式:如果事件1,2,,nA A A 两两互不相容,且1ni i A ==Ω,()0i P A >,1,2,,i n =,则1()(|)(|),1,2,,()(|)k k k niii P A P B A P A B k nP A P B A ===∑.第二章 离散型随机变量及其分布一、教学要求1.理解离散型随机变量及其概率函数的概念并掌握其性质,掌握0-1分布、二项分布、泊松(Poisson)分布、均匀分布、几何分布及其应用.2.理解二维离散型随机变量联合概率函数的概念及性质;会利用二维概率分布计算有关事件的概率.3.理解二维离散型随机变量的边缘分布,了解二维随机变量的条件分布. 4.掌握离散型随机变量独立的条件.5. 会求离散型随机变量及简单随机变量函数的概率分布. 本章重点:离散型随机变量的分布及其概率计算.二、知识要点 1.一维随机变量若对于随机试验的样本空间Ω中的每个试验结果e ,变量X 都有一个确定的实数值与e 相对应,即()X X e =,则称X 是一个一维随机变量.概率论主要研究随机变量的统计规律,也称这个统计规律为随机变量的分布. 2.**离散型随机变量及其概率函数如果随机变量X 仅可能取有限个或可列无限多个值,则称X 为离散型随机变量. 设离散型随机变量X 的可能取值为(1,2,,,)i a i n =,(),1,2,,,.i i p P X a i n ===若11ii p∞==∑,则称(1,2,,,)i p i n =离散型随机变量X 的概率函数,概率函数也可用下列表格形式表示:3.*概率函数的性质 (1)0i p ≥, 1,2,,,;i n =(2)11ii p∞==∑.由已知的概率函数可以算得概率()i ia SP X S p ∈∈=∑,其中,S 是实数轴上的一个集合. 4.*常用离散型随机变量的分布(1) 0—1分布(1,)B p ,它的概率函数为1()(1)i i P X i p p -==-,其中,0i =或1,01p <<.(2) 二项分布(,)B n p ,它的概率函数为()(1)in in P X i p p i -⎛⎫==- ⎪⎝⎭,其中,0,1,2,,i n =,01p <<.(4) 泊松分布()P λ,它的概率函数为()!iP X i e i λλ-==,其中,0,1,2,,,i n =,0λ>.(5) 均匀分布,它的概率函数为1()i P X a n ==,其中,0,1,2,,i n =.5.二维随机变量若对于试验的样本空间Ω中的每个试验结果e ,有序变量(,)X Y 都有确定的一对实数值与e 相对应,即()X X e =, ()Y Y e =,则称(,)X Y 为二维随机变量或二维随机向量.6.*二维离散型随机变量及联合概率函数如果二维随机变量(,)X Y 仅可能取有限个或可列无限个值,那么,称(,)X Y 为二维离散型随机变量.二维离散型随机变量(,)X Y 的分布可用下列联合概率函数来表示:(,),,1,2,,i j ij P X a Y b p i j ====其中,0,,1,2,,1ij ijijp i j p≥==∑∑.7.二维离散型随机变量的边缘概率函数 设(,)X Y 为二维离散型随机变量,ijp 为其联合概率函数(,1,2,i j =),称概率()(1,2,)i P X a i ==为随机变量X 的边缘概率函数,记为i p 并有.(),1,2,i i ij jp P X a p i ====∑,称概率()(1,2,)j P Y b j ==为随机变量Y 的边缘概率函数,记为.jp ,并有.jp =(),1,2,j ij iP Y b p j ===∑.8.随机变量的相互独立性 .设(,)X Y 为二维离散型随机变量,X 与Y 相互独立的充分必要条件为,,1,2,.ij i j p p p i j ==对一切多维随机变量的相互独立性可类似定义.即多维离散型随机变量的独立性有与二维相应的结论.9.随机变量函数的分布设X 是一个随机变量,()g x 是一个已知函数,()Y g X =是随机变量X 的函数,它也是一个随机变量.对离散型随机变量X ,下面来求这个新的随机变量Y 的分布.设离散型随机变量X 的概率函数为则随机变量函数Y g =的概率函数可由下表求得但要注意,若()i g a 的值中有相等的,则应把那些相等的值分别合并,同时把对应的概率i p 相加.第三章 连续型随机变量及其分布一、教学要求1.理解连续型随机变量及其概率密度的概念,并掌握其性质,掌握均匀分布、指数分布、正态分布及其应用.2.理解二维随机变量的联合分布的概念、性质以及连续型随机变量联合概率密度;会利用二维概率分布计算有关事件的概率.3.理解二维随机变量的边缘分布,了解二维随机变量的条件分布. 4.理解随机变量的独立性概念,掌握连续型随机变量独立的条件.5.掌握二维均匀分布;了解二维正态分布的密度函数,理解其中参数的概率意义.(不考)6.会求两个独立随机变量的简单函数的分布,会求两个独立随机变量的简单函数的分布,会求两个随机变量之和的概率分布. (不考)7.会求简单随机变量函数的概率分布.本章重点:一维及二维随机变量的分布及其概率计算,边缘分布和独立性计算.二、知识要点 1.*分布函数随机变量的分布可以用其分布函数来表示,随机变量X 取值不大于实数x 的概率()P X x ≤称为随机变量X 的分布函数,记作()F x , 即()(),F x P X x x =≤-∞<<∞.2.分布函数()F x 的性质 (1) 0()1;F x ≤≤ (2) ()F x 是非减函数,即当12x x <时,有12()()F x F x ≤;(3) ()0,()1lim lim x x F x F x →-∞→+∞==;(4) ()F x 是右连续函数,即0()()lim x a F x F a →+=.由已知随机变量X 的分布函数()F x ,可算得X 落在任意区间(,]a b 的概率()()();P a X b F b F a <≤=-也可以求得()()(0)P X a F a F a ==--.3.联合分布函数二维随机变量(,)X Y 的联合分布函数规定为随机变量X 取值不大于x 实数的概率,同时随机变量Y 取值不大于实数y 的概率,并把联合分布函数记为(,)F x y ,即(,)(,),,F x y P X x Y y x y =≤≤-∞<<+∞-∞<<+∞.4.联合分布函数的性质 (1) 0(,)1F x y ≤≤;(2) (,)F x y 是变量x (固定y )或y (固定x )的非减函数;(3)(,)0,(,)0lim lim x y F x y F x y →-∞→-∞==,(,)0,(,)1lim lim x x y y F x y F x y →-∞→+∞→-∞→+∞==;(4) (,)F x y 是变量x (固定y )或y (固定x )的右连续函数; (5)121222211211(,)(,)(,)(,)(,)P x X x y Y y F x y F x y F x y F x y <≤<≤=--+.5.**连续型随机变量及其概率密度设随机变量X 的分布函数为()F x ,如果存在一个非负函数()f x ,使得对于任一实数x ,有()()xF x f x dx-∞=⎰成立,则称X 为连续型随机变量,函数()f x 称为连续型随机变量X 的概率密度. 6.**概率密度()f x 及连续型随机变量的性质 (1)()0;f x ≥(2)()1f x dx +∞-∞=⎰;(3)连续型随机变量X 的分布函数为()F x 是连续函数,且在()F x 的连续点处有()()F x f x '=;(4)设X 为连续型随机变量,则对任意一个实数c ,()0P X c ==; (5) 设()f x 是连续型随机变量X 的概率密度,则有()()()()P a X b P a X b P a X b P a X b <<=≤<=≤≤=<≤=()baf x dx⎰.7.**常用的连续型随机变量的分布 (1) 均匀分布(,)R a b ,它的概率密度为1,;()0,a xb f x b a⎧<<⎪=-⎨⎪⎩其余. 其中,)a b -∞<<<+∞.(2) 指数分布()E λ,它的概率密度为,0;()0,x e x f x λλ-⎧>=⎨⎩其余. 其中,0λ>.(3) 正态分布2(,)N μσ,它的概率密度为22()2(),x f x x μσ--=-∞<<+∞,其中,,0μσ-∞<<+∞>,当0,1μσ==时,称(0,1)N 为标准正态分布,它的概率密度为22(),x f x x -=-∞<<+∞,标准正态分布的分布函数记作()x Φ,即()x Φ22()t xx dt -Φ=⎰,当出0x ≥时,()x Φ可查表得到;当0x <时,()x Φ可由下面性质得到()1()x x Φ-=-Φ.设2~(,)X N μσ,则有()()x F x μσ-=Φ;()()()b a P a X b μμσσ--<≤=Φ-Φ.8.**二维连续型随机变量及联合概率密度对于二维随机变量(X ,Y)的分布函数(,)F x y ,如果存在一个二元非负函数(,)f x y ,使得对于任意一对实数(,)x y 有(,)(,)xyF x y f s t dtds-∞-∞=⎰⎰成立,则(,)X Y 为二维连续型随机变量,(,)f x y 为二维连续型随机变量的联合概率密度.9.二维连续型随机变量及联合概率密度的性质 (1) (,)0,,f x y x y ≥-∞<<+∞;(2)(,)1f x y dxdy +∞+∞-∞-∞=⎰⎰;(3) 设(,)X Y 为二维连续型随机变量,则对任意一条平面曲线L ,有((,))0P X Y L ∈=; ’(4) 在(,)f x y 的连续点处有2(,)(,)F x y f x y x y ∂=∂∂;(5) 设(,)X Y 为二维连续型随机变量,则对平面上任一区域D 有((,))(,)DP X Y D f x y dxdy∈=⎰⎰.10,**二维连续型随机变量(,)X Y 的边缘概率密度设(,)f x y 为二维连续型随机变量的联合概率密度,则X 的边缘概率密度为()(,)X f x f x y dy+∞-∞=⎰;Y 的边缘概率密度为()(,)Y f y f x y dx+∞-∞=⎰.11.常用的二维连续型随机变量 (1) 均匀分布如果(,)X Y 在二维平面上某个区域G 上服从均匀分布,则它的联合概率密度为1,(,)x y f x y G ⎧∈⎪=⎨⎪⎩,()G;的面积0,其余. (2) 二维正态分布221212(,,,,)N μμσσρ 如果(,)X Y 的联合概率密度2211212221121()()()()1(,)22(1)x x y xf x yμμμμρρσσσσ⎧⎫⎡⎤----⎪⎪=--+⎨⎬⎢⎥-⎪⎪⎣⎦⎩⎭则称(,)X Y服从二维正态分布,并记为221212(,)~(,,,,)X Y Nμμσσρ.如果221212(,)~(,,,,)X Y Nμμσσρ,则211~(,)X Nμσ,222~(,)Y Nμσ,即二维正态分布的边缘分布还是正态分布.12.**随机变量的相互独立性.如果X与Y的联合分布函数等于,X Y的边缘分布函数之积,即(,)()(),,X YF x y F x F y x y=-∞<<+∞对一切,那么,称随机变量X与Y相互独立.设(,)X Y为二维连续型随机变量,则X与Y相互独立的充分必要条件为(,)()(),X Yf x y f x f y=在一切连续点上.如果221212(,)~(,,,,)X Y Nμμσσρ.那么,X与Y相互独立的充分必要条件是0ρ=.多维随机变量的相互独立性可类似定义.即多维随机变量的联合分布函数等于每个随机变量的边缘分布函数之积,多维连续型随机变量的独立性有与二维相应的结论.13.随机变量函数的分布**一维随机变量函数的概率密度设连续型随机变量X的概率密度为()Xf x,则随机变量()Y g X=的分布函数为()()(())()()yY y XIF y P Y y P g X y P X I f x dx=≤=≤=∈=⎰其中,{}y X I ∈与{()}g X y ≤是相等的随机事件,而{||()}y I x g x y =≤是实数轴上的某个集合.随机变量Y 的概率密度()Y f y 可由下式得到: '()()Y Y f y F y =.连续型随机变量函数有下面两条性质: (i) 设连续型随机变量的概率密度为()X f x ,()Y g X =是单调函数,且具有一阶连续导数,()x h y =是()y g x =的反函数,则()Y g X =的概率密度为()(())|'()|Y f y f h y h y =⋅.(ii) 设2~(,)X N μσ,则当0k ≠时,有22~(,)Y kX b N k b k μσ=++,特别当1,k b μσσ==-时,有~(0,1)Y kX b N =+,~(0,1)X N μσ-.特别有下面的结论:设211~(,)X N μσ,222~(,)Y N μσ,且X 与Y 相互独立,则221212~(,)X Y N μμσσ+++.第四章 随机变量的数字特征一、教学要求1.理解随机变量的数学期望、方差的概念,并会运用它们的基本性质计算具体分布的期望、方差,2.掌握二项分布、泊松分布、均匀分布、指数分布、正态分布的数学期望和方差. 3.会根据随机变量X 的概率分布计算其函数()g X 的数学期望[()]E g X ;会根据随机变量(,)X Y 的联合概率分布计算其函数(,)g X Y 的数学期望正[(,)]E g X Y .(不考)4.理解协方差、相关系数的概念,掌握它们的性质,并会利用这些性质进行计算,了解矩的概念。