表空间及分区表的概念
- 格式:docx
- 大小:23.16 KB
- 文档页数:10

oracle下的数据库实例、表空间、⽤户及其表的区分完整的Oracle数据库通常由两部分组成:Oracle数据库和数据库实例。
1) 数据库是⼀系列物理⽂件的集合(数据⽂件,控制⽂件,联机⽇志,参数⽂件等);2) Oracle数据库实例则是⼀组Oracle后台进程/线程以及在服务器分配的共享内存区。
在启动Oracle数据库服务器时,实际上是在服务器的内存中创建⼀个Oracle实例(即在服务器内存中分配共享内存并创建相关的后台内存),然后由这个Oracle数据库实例来访问和控制磁盘中的数据⽂件。
Oracle有⼀个很⼤的内存快,成为全局区(SGA)。
⼀、数据库、表空间、数据⽂件1、数据库数据库是数据集合。
Oracle是⼀种数据库管理系统,是⼀种关系型的数据库管理系统。
通常情况了我们称的“数据库”,并不仅指物理的数据集合,他包含物理数据、数据库管理系统。
也即物理数据、内存、操作系统进程的组合体。
我们在安装Oracle数据库时,会让我们选择安装启动数据库(即默认的全局数据库)如下图:全局数据库名:就是⼀个数据库的标识,在安装时就要想好,以后⼀般不修改,修改起来也⿇烦,因为数据库⼀旦安装,数据库名就写进了控制⽂件,数据库表,很多地⽅都会⽤到这个数据库名。
启动数据库:也叫全局数据库,是数据库系统的⼊⼝,它会内置⼀些⾼级权限的⽤户如SYS,SYSTEM等。
我们⽤这些⾼级权限账号登陆就可以在数据库实例中创建表空间,⽤户,表了。
查询当前数据库名:select name from v$database;2、数据库实例⽤Oracle官⽅描述:实例是访问Oracle数据库所需的⼀部分计算机内存和辅助处理后台进程,是由进程和这些进程所使⽤的内存(SGA)所构成⼀个集合。
其实就是⽤来访问和使⽤数据库的⼀块进程,它只存在于内存中。
就像Java中new出来的实例对象⼀样。
我们访问Oracle都是访问⼀个实例,但这个实例如果关联了数据库⽂件,就是可以访问的,如果没有,就会得到实例不可⽤的错误。

oracle 建分区时间范围(最新版)目录1.Oracle 分区的概念和作用2.Oracle 分区表的类型3.Oracle 建分区的方法4.时间范围分区的创建方法5.Oracle 分区表的优缺点正文Oracle 分区是一种数据库对象,可以将一个大表分成多个小表存储,以提高查询效率。
分区表可以基于不同的属性进行分区,如时间、地理位置等。
在 Oracle 中,分区表是一种特殊的表类型,它可以根据指定的列值将数据分散存储在多个物理存储设备上,从而提高查询效率和系统性能。
Oracle 分区表主要有两种类型:范围分区和哈希分区。
范围分区是基于数据范围的分区方式,可以将数据表根据某个列的值范围进行划分。
哈希分区则是基于数据哈希值的分区方式,可以将数据表根据某个列的哈希值进行划分。
要创建一个基于时间范围的分区表,可以使用以下步骤:1.首先,创建一个表空间,用于存储分区表的数据。
2.然后,创建一个分区表,并指定分区方式为范围分区。
3.接下来,指定分区列和分区范围。
分区列通常是日期类型,分区范围则是根据业务需求设定的时间区间。
4.最后,为分区表添加数据。
例如,假设有一个订单表,需要根据订单日期进行分区。
可以按照以下步骤创建一个时间范围分区表:1.创建表空间:```sqlCREATE TABLESPACE order_tsDATAFILE "order_ts.dbf" SIZE 100MAUTOEXTEND ON NEXT 10M;```2.创建分区表:```sqlCREATE TABLE order(order_id NUMBER, customer_id NUMBER, order_date DATE, amount NUMBER)PARTITION BY RANGE (order_date)INTERVAL (NUMTOYMINTERVAL(1, "MONTH"))(PARTITION order_p1 VALUES LESS THAN(TO_DATE("01-APR-2021", "DD-MON-YYYY")) TABLESPACE order_ts );```3.添加数据:```sqlINSERT INTO order VALUES (1, 100, TO_DATE("01-APR-2021", "DD-MON-YYYY"), 100);INSERT INTO order VALUES (2, 101, TO_DATE("01-MAY-2021", "DD-MON-YYYY"), 200);```Oracle 分区表的优点包括:1.提高查询效率:分区表可以将数据分散存储在多个物理存储设备上,从而减少查询时的 I/O 操作。

什么是分区表分区表可以描述磁盘上的分区。
如果磁盘分区表丢失,用户将无法读取磁盘数据并在其上写入新数据。
• MBR分区表传统的分区方案(MBR分区)将分区信息保存在磁盘的第一个扇区(MBR扇区)上。
每个分区条目为16个字节,总数为64个字节。
因此,分区表最多限制为4个条目。
换句话说,基于MBR的硬盘最多可支持4个分区。
但是,许多人想要创建超过4个分区。
因此,为此需求引入了扩展分区。
而且,MBR磁盘中单个分区的大小只能达到2TB e因此,基于MBR的分区方案不能满足日益增长的需求。
• GPT分区表GUID分区表(GPT)是使用全局唯一标识在物理硬盘上布局分区表的标准。
它在MBR分区表上有许多优点。
具体而言,它允许用户在硬盘上创建多达128个分区。
它支持18EB卷,而MBR最多支持2TB卷。
更重要的是,所有重要数据都存储在分区而不是隐藏的扇区中。
另外,GPT磁盘提供backup-partition-table来提高数据结构的完整性。
FATFAT (文件分配表)用于记录文件的位置。
如果FAT丢失,则无法读取磁盘数据,因为操作系统无法找到准确的位置。
不同的操作系统使用不同的文件系统DOS 6和Windows 3.x想使用FAT16QS/2操作系统使用HPFS。
,Windows NT使用NTFS O实际上z FAT32和NTFS是最常见的两种文件系统。
分区表使用柱面,磁头和扇区的单元细分存储介质。
FAT32文件系统将逻辑驱动器划分为Boot区域,FAT区域和DATA区域。
系统区域包括Boot和FAT区域。
引导区占用三个扇区,它包含扇区字节,引导记录和其他重要信息。
在那之后,这个区域有一些保留的部门。
但是,FAT16文件系统的Boot区域只占用一个扇区。
FAT可以管理可用空间和存储空间(集群链)。
文件系统将通过集群管理数据区的存储空间。
Cluster是Windows操作系统中最小的存储单元,会影响磁盘空间的利用率和性能。
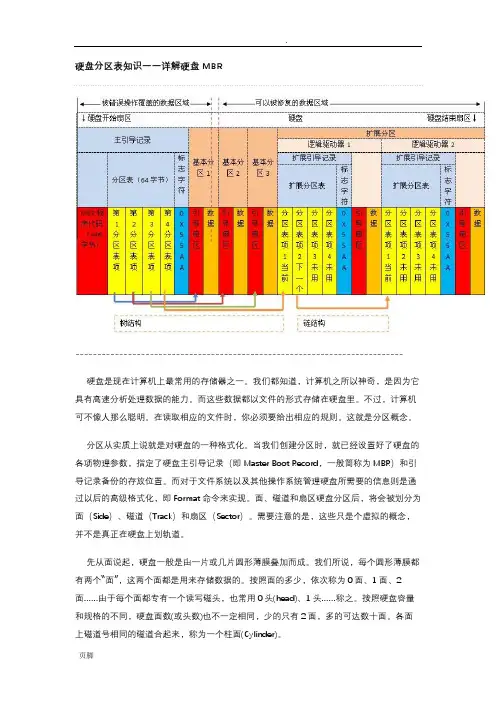
硬盘分区表知识——详解硬盘MBR--------------------------------------------------------------------------- 硬盘是现在计算机上最常用的存储器之一。
我们都知道,计算机之所以神奇,是因为它具有高速分析处理数据的能力。
而这些数据都以文件的形式存储在硬盘里。
不过,计算机可不像人那么聪明。
在读取相应的文件时,你必须要给出相应的规则。
这就是分区概念。
分区从实质上说就是对硬盘的一种格式化。
当我们创建分区时,就已经设置好了硬盘的各项物理参数,指定了硬盘主引导记录(即Master Boot Record,一般简称为MBR)和引导记录备份的存放位置。
而对于文件系统以及其他操作系统管理硬盘所需要的信息则是通过以后的高级格式化,即Format命令来实现。
面、磁道和扇区硬盘分区后,将会被划分为面(Side)、磁道(Track)和扇区(Sector)。
需要注意的是,这些只是个虚拟的概念,并不是真正在硬盘上划轨道。
先从面说起,硬盘一般是由一片或几片圆形薄膜叠加而成。
我们所说,每个圆形薄膜都有两个“面”,这两个面都是用来存储数据的。
按照面的多少,依次称为0面、1面、2面……由于每个面都专有一个读写磁头,也常用0头(head)、1头……称之。
按照硬盘容量和规格的不同,硬盘面数(或头数)也不一定相同,少的只有2面,多的可达数十面。
各面上磁道号相同的磁道合起来,称为一个柱面(Cylinder)。
上面我们提到了磁道的概念。
那么究竟何为磁道呢?由于磁盘是旋转的,则连续写入的数据是排列在一个圆周上的。
我们称这样的圆周为一个磁道。
如果读写磁头沿着圆形薄膜的半径方向移动一段距离,以后写入的数据又排列在另外一个磁道上。
根据硬盘规格的不同,磁道数可以从几百到数千不等;一个磁道上可以容纳数KB的数据,而主机读写时往往并不需要一次读写那么多,于是,磁道又被划分成若干段,每段称为一个扇区。

数据库中的分区表设计在数据库设计和管理过程中,分区表已经成为了数据组织和管理的一个重要的工具。
分区表将数据划分为不同的分区,以提高查询性能、维护策略和管理数据量的能力。
本文将探讨数据库中的分区表设计,包括分区表的概念、设计原则和实现方法。
一、分区表的概念分区表是指根据一定的规则,将一张大表(或索引)按照一定的方式,拆分为多个子表(或子索引)的一种表结构。
这些子表(或子索引)之间互相独立,可以单独维护。
使用分区表可以有效地提高数据库查询性能,避免数据量过大导致的查询效率低下的问题。
分区表的设计原则在设计分区表时,需要遵循以下原则:1.分区表的分区规则应该与应用程序的查询需求相匹配。
2.创建分区表时,应该考虑分区表中的数据量和分区密度。
3.在设计分区表时,需要考虑表空间的使用情况。
4.在设计分区表时,应该考虑表的维护性能和可用性。
实现方法实现分区表的方式有很多种,本文着重介绍以下两种实现方法:1、水平分区水平分区是指将一张大表按行分为多个子表的方式。
每个子表包含相同数目的行数。
水平分区适用于对数据的操作大致相同的情况。
例如,对于交易系统的数据库,每个子表可以包含一段时间内的所有交易记录。
2、垂直分区垂直分区是指将一张大表按列分为多个子表的方式。
每个子表包含相同的列。
垂直分区适用于数据读取密集型应用程序。
例如,对于使用者经常只需要查询数据库的一部分数据的应用程序,每个子表可以包含一个相对较小的数据集,例如先前二十四小时的数据。
总结数据库中的分区表已经成为了数据库管理的标准工具。
正确的分区表设计可以帮助我们提高数据管理效率、降低维护成本,更好地应对数据增长和可用性需求。
分区表设计应该根据具体业务需求进行调整,以达到最佳性能和可用性的平衡。
需要考虑分区规则、数据量、表空间的使用情况和维护性能等因素,才能确保分区表的有效性和可用性。

第1篇1. 请简述Oracle数据库的体系结构,并说明各层的作用。
2. 请解释什么是Oracle实例?实例与数据库之间的关系是什么?3. 请简述Oracle数据库的存储结构,包括数据文件、控制文件、日志文件等。
4. 请说明Oracle数据库的内存结构,包括SGA、PGA等。
5. 请解释Oracle数据库的备份策略,包括全备份、增量备份、差异备份等。
6. 请说明Oracle数据库的恢复策略,包括不完全恢复、完全恢复等。
7. 请解释Oracle数据库的事务管理,包括事务的ACID特性。
8. 请说明Oracle数据库的锁机制,包括共享锁、排他锁等。
9. 请解释Oracle数据库的并发控制,包括多版本并发控制(MVCC)。
10. 请说明Oracle数据库的安全机制,包括角色、权限、用户等。
二、SQL语言1. 请简述SQL语言的组成,包括数据定义语言(DDL)、数据操纵语言(DML)、数据控制语言(DCL)等。
2. 请说明如何创建一个简单的表,包括表结构、字段类型、约束等。
3. 请编写一个查询语句,查询某个表中所有年龄大于30岁的记录。
4. 请编写一个更新语句,将某个表中年龄大于40岁的记录的年龄加1。
5. 请编写一个删除语句,删除某个表中年龄小于20岁的记录。
6. 请编写一个插入语句,插入一条记录到某个表中。
7. 请说明如何使用SQL语句实现分页查询。
8. 请说明如何使用SQL语句实现多表查询。
9. 请说明如何使用SQL语句实现子查询。
10. 请说明如何使用SQL语句实现联合查询。
三、Oracle高级特性1. 请解释什么是视图?如何创建视图?2. 请解释什么是索引?有哪些常见的索引类型?3. 请解释什么是触发器?如何创建触发器?4. 请解释什么是存储过程?如何创建存储过程?5. 请解释什么是函数?如何创建函数?6. 请解释什么是包?如何创建包?7. 请解释什么是序列?如何创建序列?8. 请解释什么是同义词?如何创建同义词?9. 请解释什么是物化视图?如何创建物化视图?10. 请解释什么是分区表?如何创建分区表?四、Oracle性能优化1. 请说明如何查看Oracle数据库的性能统计信息。

一、概述在数据库管理系统中,表空间是一种逻辑存储结构,用于组织和管理数据库中的数据。
在SQL中,表空间的概念是非常重要的,它可以影响到数据库的性能和存储结构。
本文将介绍SQL表空间的结构以及页、区、段的定义,帮助读者更好地理解和管理数据库。
二、SQL表空间的结构1. 表空间的概念在SQL中,表空间是用来存放数据库对象的一种逻辑结构。
每个数据库都包括一个或多个表空间,表空间包含了数据库中的表、索引、视图等对象。
通过表空间,可以有效地管理数据库的存储空间,并对数据进行组织和存储。
2. 表空间的组成表空间由多个数据文件组成,每个数据文件对应一个操作系统文件。
这些数据文件可以存放在不同的磁盘上,从而实现数据在多个磁盘上的分布存储。
表空间还包括了表和索引的存储结构定义,以及一系列的控制信息,用于管理和维护表空间中的数据。
3. 表空间的作用表空间的设计对数据库的性能和管理非常重要。
合理的表空间设计可以提高数据库的性能,减少空间的浪费,并且便于数据库的管理和维护。
通过表空间,可以对数据进行分区存储,将不同的数据存放在不同的表空间中,从而提高查询和管理效率。
三、页、区、段的定义1. 页的概念在数据库中,页是数据存储的最小单位。
每个数据文件被分成多个页,每个页的大小通常为4KB或8KB。
数据库将数据存储在页中,每个页可以存储一定大小的数据记录,数据按页的方式进行读写和管理。
2. 区的概念区是页的集合,用于组织和管理数据文件中的页。
数据库将一个数据文件划分为多个区,在每个区中存放了一定数量的页。
区的划分可以提高数据的存取效率,便于数据库对数据进行管理和优化。
3. 段的概念段是数据库中的逻辑存储单位,每个表和索引都包含一个或多个段。
段可以理解为表或索引在磁盘上的存储结构,它包括了数据文件和控制信息,用于管理和维护数据的存储。
数据库根据段来管理表和索引的存储、访问和维护。
四、结论通过本文的介绍,读者可以更好地理解SQL表空间的结构和页、区、段的定义。

分区表的作用分区表的作用在数据库中是非常重要的,可以应用到各种场景中。
它可以在很大程度上提高效率,节省存储空间,更方便的进行数据备份和恢复操作。
本文将主要介绍分区表的作用,并结合实际案例加以详细阐述。
一、分区表简介分区表是数据库管理中一个非常重要的概念,它可以将一个大表按照一定的规则,划分成多个小表。
这些小表之间是互相独立的,但是它们共享一个表名,也就是说,在管理上是作为一个整体对待的。
分区表中的数据并不是随机分配到各个区域的,而是根据相应的条件来进行分配的。
这些条件可以是范围、列表或者是Hash值等。
二、分区表的作用1.提高查询效率将大表分区后,查询单个分区表的数据量将大大减少,从而提高查询效率。
例如,一个包含10亿条记录的表,如果没有分区,当我们进行一些条件查询的时候,可能需要扫描全表。
如果采用分区表,我们可以先定位到某个分区表,然后再对这个分区表进行查询,这样可以节省很多时间。
2.减少备份/恢复所需时间对于一些大型的数据库,备份和恢复数据的时间是非常长的。
如果使用分区表,我们只需要备份/恢复其中某个分区表即可,这样大大减少了备份/恢复所需时间。
3.节省存储空间分区表可以根据不同的条件存储不同的数据,从而避免了存储重复数据的情况,减少了存储空间的占用。
例如,在一个包含大量历史记录的表中,我们可以按年份建立不同的分区表,这样可以避免重复存储相同的年份记录。
4.改善并发性能在大型数据库系统中,由于并发访问的高峰期,可能会导致出现一些性能瓶颈。
在这些情况下,通过使用分区表,可以将并发访问的压力分散到多个分区表中,从而提高整个系统的并发性能。
三、分区表实例说明以一个大型金融数据库为例,假设我们需要存储每天市场上的股票信息,每天需要存储几亿条数据。
如果不使用分区表,那么对于这个表,我们需要建立很大的空间来存储这些数据。
如果使用分区表,我们可以将数据按照时间进行分区,一天的数据存储在一个分区表中,这样就可以避免存储重复数据,并且方便备份和恢复数据,提高查询效率和并发访问性能。

数据库分区表一、什么是数据库分区表?数据库分区表,顾名思义,就是根据某种规则将表的数据拆分成若干部分,分别存储在不同的物理位置,也就是分区中。
分区表是一种针对海量容量的数据仓库开发分区存储机制,通过这种方式,可以提升大数据量的管理和维护效率。
二、分区表的分类方式2.1.基于水平切分的分区表水平切分意味着将数据按照某个字段的值来拆分成若干部分,相同值的数据被固定为一个分区。
常用的字段有时间、状态、区域等。
以时间字段作为例子:通常一个系统中,某个表由于数据量过大,需要将其水平切分,切分方式就是按照时间的不同划分,例如“按月切分”,那么这个数据表就被分为12个分区,每个分区表示一个月的数据;如果采用按天分区,则表被分为365个分区,每个分区表示一个具体日期的数据;如果采用按周分区,则表被分为52个分区,每个分区表示一周的数据。
这样的分区方式可以满足查询及管理所需,降低系统的资源耗用,提高效率。
2.2.基于垂直切分的分区表垂直切分意味着将表按照列的不同进行拆分,将不同的字段存储在不同的分区中。
常用的拆分字段有:数据访问频率、数据类型等。
以数据类型作为例子:对于一些表来说,有些字段的数据类型不同,某些属性需要经常查询,而有些属性不经常查询。
将经常查询的字段存储在一个分区中,将不经常查询的字段存储在另一个分区中,这样做可以提高查询效率,优化系统性能。
三、分区表的优势3.1.提高数据查询及管理效率当数据量达到一定的规模时,查询效率不能保证,此时就需要采用数据分区来提高效率,加快查询速度;同时,管理过程中,通过数据分区可以有效地减少数据备份时间,提高系统的整体稳定性。
3.2.提升系统的可扩展性随着数据量的不断增加,系统也需要不断拓展,基于分区表可以更加有效地扩展数据库,支持更大的数据容量,可以根据实际需求灵活扩展数据库容量。
3.3.增强系统的可靠性数据库分区表有助于提升系统的可靠性和稳定性,一旦出现数据异常或错误,可以快速定位到分区,修复或恢复。

分区表的概念
分区表是一种数据库表的设计方式,它将表数据分成多个部分,每个部分称为一个分区。
通常,分区是根据一些特定的规则进行的,例如按时间、按地理位置、按功能等等。
分区表的设计可以提高表的查询效率,减少查询数据的范围,从而提高查询速度。
分区表的设计可以带来许多好处,例如:
-提高查询效率:分区表可以将数据分为多个区域,每个区域的数据可以单独管理和查询,从而减少查询数据的范围,提高查询效率。
-方便维护:分区表可以将数据分为多个区域,每个区域可以单独备份和恢复,从而提高了数据库的可靠性,也方便了维护工作。
-满足特定需求:分区表可以根据特定的规则进行划分,例如按时间、按地理位置、按功能等等,从而满足不同的业务需求。
在使用分区表时,需要考虑以下几点:
-分区规则:需要根据实际情况选择合适的分区规则,例如按时间、按地理位置等等。
-分区数目:需要根据实际情况选择合适的分区数目,过多或过少的分区数目都会影响查询效率。
-数据迁移:在使用分区表时,可能需要对数据进行迁移,例如将历
史数据迁移到归档表中,需要考虑数据迁移的成本和效率问题。
总之,分区表是一种高效的数据库表设计方式,可以提高查询效率、方便维护和满足特定需求。
在设计和使用分区表时,需要注意合适的分区规则和分区数目,并考虑数据迁移的成本和效率问题。

数据库中的分区表介绍在数据库管理系统中,分区表是一种将表中的数据分割为多个逻辑或物理部分的技术。
通过将数据划分到不同的分区中,可以提高数据库的性能、管理和维护的效率。
本文将介绍数据库中的分区表,并探讨其用途、优点和实现方法。
一、什么是分区表?分区表是指将数据库表按照某种规则分成多个分区,每个分区存储特定范围的数据。
在逻辑上,分区表看起来仍然是一个完整的表,但在物理存储上,数据被分割到不同的存储单元中。
这样,当进行数据查询时,查询只需要访问特定的分区,而不需要扫描整个表,从而提高了查询效率。
二、分区表的用途1. 提高查询性能:分区表可以将数据分散存储在不同的磁盘上,使得数据查询只需要访问特定的分区,减少了数据的扫描量,提高了查询性能。
2. 简化管理和维护:当数据库表的数据量非常大时,对整个表进行备份、恢复或优化都是非常耗时的操作。
分区表将数据分割后,可以针对某个或某些分区进行相关操作,大大简化了管理和维护的工作量。
3. 实现数据存储策略:通过分区表,可以根据业务需求将数据按照不同的规则分散存储,比如按照时间、地域、客户等进行分区,使得不同类型的数据存储在不同的分区中,方便管理和检索。
三、分区表的优点1. 提高查询效率:通过将数据分割到不同的分区中,可以减少查询时的数据扫描量,从而提高查询效率。
2. 简化数据管理:分区表可以根据业务需求将数据分散存储,简化了备份、恢复和维护等数据管理工作。
3. 提高可用性:当某个分区发生故障时,不会影响到整个表的数据,只需关注该分区的修复或恢复。
4. 提高加载和删除数据的效率:通过对分区表进行操作,可以快速加载和删除特定分区的数据。
四、分区表的实现方法在数据库管理系统中,分区表的实现方法因不同的数据库而异。
下面以Oracle数据库为例进行介绍:1. 范围分区:按照范围对表中的数据进行分区,比如按照时间范围,可以将不同时间段内的数据存储到不同的分区中。
2. 列分区:按照表中某一列的值进行分区,比如按照地域进行分区,可以将不同地域的数据存储到不同的分区中。
ORACLE分区表的概念及操作此文从以下几个方面来整理关于分区表的概念及操作: 1.表空间及分区表的概念 2.表分区的具体作用 3.表分区的优缺点4.表分区的几种类型及操作方法5.对表分区的维护性操作. (1.) 表空间及分区表的概念表空间:是一个或多个数据文件的集合,所有的数据对象都存放在指定此文从以下几个方面来整理关于分区表的概念及操作:1.表空间及分区表的概念2.表分区的具体作用3.表分区的优缺点4.表分区的几种类型及操作方法5.对表分区的维护性操作.(1.) 表空间及分区表的概念表空间:是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表,所以称作表空间。
分区表:当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。
表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。
( 2).表分区的具体作用Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。
通常,分区可以使某些查询以及维护操作的性能大大提高。
此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。
分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。
每个分区有自己的名称,还可以选择自己的存储特性。
从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。
但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用SQL DML 命令访问分区后的表时,无需任何修改。
什么时候使用分区表:1、表的大小超过2GB。
2、表中包含历史数据,新的数据被增加都新的分区中。
(3).表分区的优缺点表分区有以下优点:1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
硬盘分区的相关概念(主分区,扩展分区,逻辑分区,MBR,DBR)简介:指定⽂件系统格式前需要分区,分区概念,对理解操作系统启动很有必要,分区是硬盘被系统使⽤的前置条件。
记录并且归纳了⼀下,可能存在Windows和Linux系统⼀些概念的混淆,欢迎指正1,系统启动过程简介BIOS在知道了哪些硬件基本信息后开始读硬盘,⾸先读取MBR(Master Boot Record,即主引导记录)然后从MBR中了解操作的位置从⽽加载操作系统。
⽽这个MBR的内容是在分区操作的时候确定的。
MBR的在硬盘的位置和格式是固定的(即硬盘上第0磁道的第⼀个扇区)。
补充内容:硬盘⾸扇区:即主引导扇区主引导扇区:每块硬盘(不是每个分区)都只有⼀个主引导扇区,即该硬盘0号柱⾯,0号磁头的第⼀个扇区,⼤⼩为512字节。
主引导扇区包含的MBR(硬盘主引导记MBR占446bytes)、DPT(分区表DP占64bytes)、MN(硬盘有效标志Magic Numbe占2byte。
AA和55被称为幻数(Magic Number),BOIS读取MBR的时候总是检查最后是不是有这两个幻数,如果没有就被认为是⼀个没有被分区的硬盘),这3个区域是操作系统⽆关的,在每块硬盘上都存在;MBR是⼀段可执⾏程序,由各个操作系统写⼊不同的代码。
MBR的存储空间限制为446字节,MBR所做的唯⼀的事情就是装载第⼆引导装载程序。
Windows产⽣的MBR装载运⾏PBR;GRUB产⽣的MBR装载运⾏grldrMBR:它是⼀段程序,长度为446字节,作⽤是加载bootloader的。
主引导扇区2,为什么要分区2.1,对数据隔离,⽅便格式化和数据安全主要⽅⾯:系统需要重装⾸先系统分区需要进⾏格式化,所在分区数据需要提前处理次要⽅⾯:读取越频繁,磁盘越容易受损,把读写频繁的⽬录挂载到⼀个单独的分区关于Linux分区,⽐较赞成单独分区的列出来(按优先级排列):1.根⽬录(/),必须挂载到分区!2.家⽬录(/home):⾮常建议挂载的单独分区!3./SWAP(交换分区/虚拟内存):根据本机内存决定若本机实体内存较⼤,⽽且系统应⽤环境对内存需求不⾼(如本机内存有4G,⽽只是⽤于⽇常练习),可以不需要该分区。
什么是表分区,如何表分区什么是表分区?表分区其实就是将⼀张⼤数据量表中的数据按照不同的分区策略分配到不同的系统分区、硬盘或是不同的服务器设备上,实现数据的均衡分配,这样做的好处是均衡⼤数据量数据到不同的存储介⼦中,这样每个分区均摊了⼀部分数据,然后可以定位到指定的分区中,对数据表进⾏需求操作,另外,也⽅便管理⽔表,⽐如要删除某个时间段的数据,就可以按照⽇期分区,然后直接删除该⽇期分区即可,并且效率相对于传统的DELETE数据效率⾼很多,这⾥以Mysql为例进⾏说明。
· 分区分表区别· 表分区的原理· 表分区的策略· 表分区的实施· 表分区的注意⼀、分区分表区别分区和分表针对的都是数据表,⽽分表是真正的⽣成数据表,是将⼀张⼤数据量的表分成多个⼩表实现数据均衡;分区并不是⽣成新的数据表,⽽是将表的数据均衡分摊到不同的硬盘,系统或是不同服务器存储介⼦中,实际上还是⼀张表。
另外,分区和分表都可以做到将表的数据均衡到不同的地⽅,提⾼数据检索的效率,降低数据库的频繁IO压⼒值,分区的优点如下:1、相对于单个⽂件系统或是硬盘,分区可以存储更多的数据;2、数据管理⽐较⽅便,⽐如要清理或废弃某年的数据,就可以直接删除该⽇期的分区数据即可;3、精准定位分区查询数据,不需要全表扫描查询,⼤⼤提⾼数据检索效率;4、可跨多个分区磁盘查询,来提⾼查询的吞吐量;5、在涉及聚合函数查询时,可以很容易进⾏数据的合并;⼆、表分区的原理表的分区的原理理解起来⽐较简单,其实就是把⼀张⼤数据量的表,根据分区策略进⾏分区,分区设置完成之后,由数据库⾃⾝的储存引擎来实现分发数据到指定的分区中去,正如上图所⽰,⼀张数据表被分成了n个分区,并且分区被放⼊到不同的介⼦disk中,每个disk中包含⾃少⼀个分区,这就实现了数据的均衡以及通过跨分区介⼦检索提⾼了整体的数据操作IO吞吐率。
注:想通过表分区来提供查询性能,就是要提⾼磁盘IO性能,必然就需要实现IO的并发,所以表分区就需要放到不同的磁盘上才⾏。
1、简述分区表的概念及其优势
分区表是数据库中常用的一种数据管理技术,它将一张表中的数据按照某种规则划分为不同的部分,每个部分称为一个分区。
每个分区可以独立地存储在物理磁盘上,这样就可以提高查询效率、维护和管理数据的便利性。
分区表的优势如下:
1. 提高查询效率:通过将数据划分为不同的分区,可以只查询与查询条件匹配的分区,减少数据的扫描量,提高查询效率。
例如,如果一个表按照日期进行分区,那么在查询特定日期的数据时,只需要扫描对应日期的分区,而不是整个表。
2. 维护和管理便利:当某个分区的数据量过大时,可以单独对该分区进行维护和管理,如备份、恢复等操作,而不会影响其他分区的正常运行。
这使得数据的维护和管理更加灵活和高效。
3. 降低存储空间:通过将数据划分为不同的分区,可以更好地利用存储空间,避免数据的浪费。
例如,如果一个表按照日期进行分区,那么在删除旧数据时,
只需要删除对应日期的分区,而不是整个表。
4. 提高数据可靠性:当某个分区出现故障时,可以单独对该分区进行恢复,而不会影响其他分区的正常运行。
这使得数据的可靠性更高,因为即使某个分区出现故障,其他分区的数据仍然可以正常访问和使用。
分区表是一种有效的数据管理技术,可以提高查询效率、维护和管理数据的便利性,降低存储空间和提高数据可靠性。
在实际应用中,可以根据具体的需求和场景选择合适的分区策略和算法,以实现更好的数据管理和应用效果。
ORACLE的块、区、段、表空间简述ORACLE在逻辑存储上分4个粒度:块、段、区、表空间。
2.1块: 是粒度最⼩的存储单位,默认的块⼤⼩是8K,(为什么Oracle要⽤数据块作为最⼩单位?因为,⽆论是Windows环境,还是Unix/Linux环境,他们的操作系统存储结构和⽅式、甚⾄字符排列的⽅式都是不同的。
所以,Oracle利⽤数据块将这些差异加以屏蔽,全部数据操作采⽤对Oracle块的操作,相当于是对底层环境的⼀层封装。
)ORACLE每⼀次I/O操作也是按块来操作的,也就是说当ORACLE从数据⽂件读数据时,是读取多少个块,⽽不是多少⾏。
每⼀个Block ⾥可以包含多个row。
【延伸:mysql是页、区、段,pg最⼩单位也是块,本质⼀样。
】2.2区:由⼀系列相邻的块⽽组成,这也是ORACLE 空间分配的基本单位,举个例⼦来说,当我们创建⼀个表A时,⾸先ORACLE会分配⼀区的空间给这个表,随着不断的INSERT数据到A表,原来的这个区容不下插⼊的数据时,ORACLE是以区为单位进⾏扩展的,也就是说再分配多少个区给A表,⽽不是多少个块。
在进⾏存储数据信息的时候,Oracle将分配数据块进⾏存储,但是不能保证所有分配的数据块都是连续的结构。
所以,出现分区extent的概念,表⽰⼀系列连续的数据块集合。
--查看区信息SET LIN 200 PAGES 999COL OWNER FOR A20COL SEGMENT_NAME FOR A20COL SEGMENT_TYPE FOR A10COL TABLESPACE_NAME FOR A10select OWNER,SEGMENT_NAME,SEGMENT_TYPE,TABLESPACE_NAME,EXTENT_ID,FILE_ID,BLOCK_ID,BLOCKS fromdba_extentswhere TABLESPACE_NAME='USERS' AND OWNER='SCOTT' order by 7;从视图中,我们可以清晰看出分区的⼏个特点:⾸先分区是带有段特定性的。
1. 表空间及分区表的概念表空间:是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表,所以称作表空间。
分区表:当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。
表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个“表空间”(物理文件上),这样查询数据时,不至于每次都扫描整张表而只是从当前的分区查到所要的数据大大提高了数据查询的速度。
2. 表分区的具体作用ORACLE的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。
通常,分区可以使某些查询以及维护操作的性能大大提高。
此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。
分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。
每个分区有自己的名称,还可以选择自己的存储特性。
从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。
但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用SQL DML 命令访问分区后的表时,无需任何修改。
什么时候使用分区表:1. 表的大小超过2GB。
2. 表中包含历史数据,新的数据被增加到新的分区中。
3. 表分区的优缺点表分区有以下优点:1)改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2)增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;3)维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;4)均衡I/O:可以把不同的分区映射到不同磁盘以平衡I/O,改善整个系统性能。
缺点:分区表相关:已经存在的表没有方法可以直接转化为分区表。
不过ORACLE 提供了在线重定义表的功能。
4 表分区的几种类型及操作方法4.1 范围分区范围分区将数据基于范围映射到每一个分区,这个范围是你在创建分区时指定的分区键决定的。
这种分区方式是最为常用的,并且分区键经常采用日期。
举个例子:你可能会将销售数据按照月份进行分区。
当使用范围分区时,请考虑以下几个规则:1)每一个分区都必须有一个VALUES LESS THAN子句,它指定了一个不包括在该分区中的上限值。
分区键的任何值等于或者大于这个上限值的记录都会被加入到下一个高一些的分区中。
2)所有分区,除了第一个,都会有一个隐式的下限值,这个值就是此分区的前一个分区的上限值。
3)在最高的分区中,MAXVALUE被定义。
MAXVALUE代表了一个不确定的值。
这个值高于其它分区中的任何分区键的值,也可以理解为高于任何分区中指定的VALUE LESS THAN的值,同时包括空值。
例一按行数划分假设有一个CUSTOMER表,表中有数据200000行,我们将此表通过CUSTOMER_ID进行分区,每个分区存储100000行,我们将每个分区保存到单独的表空间中,这样数据文件就可以跨越多个物理磁盘。
下面是创建表和分区的代码,如下:CREATE TABLE CUSTOMER(CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY,FIRST_NAME VARCHAR2(30) NOT NULL,LAST_NAME VARCHAR2(30) NOT NULL,PHONE VARCHAR2(15) NOT NULL,EMAIL VARCHAR2(80),STATUS CHAR(1))PARTITION BY RANGE (CUSTOMER_ID)(PARTITION CUS_PART1 VALUES LESS THAN (100000) TABLESPACE CUS_TS01,PARTITION CUS_PART2 VALUES LESS THAN (200000) TABLESPACE CUS_TS02)例二按时间划分CREATE TABLE ORDER_ACTIVITIES(ORDER_ID NUMBER(7) NOT NULL,ORDER_DATE DATE,TOTAL_AMOUNT NUMBER,CUSTOTMER_ID NUMBER(7),PAID CHAR(1))PARTITION BY RANGE (ORDER_DATE)(PARTITION ORD_ACT_PART01 VALUES LESS THAN (TO_DATE('01- MAY -2003','DD-MON-YYYY')) TABLESPACEORD_TS01,PARTITION ORD_ACT_PART02 VALUES LESS THAN(TO_DATE('01-JUN-2003','DD-MON-YYYY')) TABLESPACE ORD_TS02, PARTITION ORD_ACT_PART02 VALUES LESS THAN(TO_DATE('01-JUL-2003','DD-MON-YYYY')) TABLESPACE ORD_TS03)例三MAXV ALUECREATE TABLE RANGETABLE(IDD INT PRIMARY KEY ,INAME VARCHAR(10),GRADE INT)PARTITION BY RANGE (GRADE)(PARTITION PART1 VALUES LESS THAN (1000) TABLESPACE PART1_TB,PARTITION PART2 VALUES LESS THAN (MAXVALUE) TABLESPACE PART2_TB);4.2 列表分区该分区的特点是某列的值只有几个,基于这样的特点我们可以采用列表分区。
例一CREATE TABLE PROBLEM_TICKETS(PROBLEM_ID NUMBER(7) NOT NULL PRIMARY KEY,DESCRIPTION VARCHAR2(2000),CUSTOMER_ID NUMBER(7) NOT NULL,DATE_ENTERED DATE NOT NULL,STATUS VARCHAR2(20))PARTITION BY LIST (STATUS)(PARTITION PROB_ACTIVE VALUES ('ACTIVE') TABLESPACE PROB_TS01,PARTITION PROB_INACTIVE VALUES ('INACTIVE') TABLESPACE PROB_TS02);例二CREATE TABLE LISTTABLE(ID INT PRIMARY KEY ,NAME VARCHAR (20),AREA VARCHAR (10))PARTITION BY LIST (AREA)(PARTITION PART1 VALUES ('GUANGDONG','BEIJING') TABLESPACE PART1_TB,PARTITION PART2 VALUES ('SHANGHAI','NANJING') TABLESPACE PART2_TB);4.3 散列分区这类分区是在列值上使用散列算法,以确定将行放入哪个分区中。
当列的值没有合适的条件时,建议使用散列分区。
散列分区(也称HASH分区)为通过指定分区编号来均匀分布数据的一种分区类型,因为通过在I/O设备上进行散列分区,使得这些分区大小一致。
例一CREATE TABLE HASH_TABLE(COL NUMBER(8),INF VARCHAR2(100))PARTITION BY HASH (COL)(PARTITION PART01 TABLESPACE HASH_TS01,PARTITION PART02 TABLESPACE HASH_TS02,PARTITION PART03 TABLESPACE HASH_TS03)简写:CREATE TABLE EMP(EMPNO NUMBER (4),ENAME VARCHAR2 (30),SAL NUMBER)PARTITION BY HASH (EMPNO) PARTITIONS 8STORE IN (TBS01,TBS02,TBS03,TBS04,TBS05,TBS06,TBS07,TBS08);HASH分区最主要的机制是根据HASH算法来计算具体某条纪录应该插入到哪个分区中,HASH算法中最重要的是HASH函数,ORACLE中如果你要使用HASH分区,只需指定分区的数量即可。
建议分区的数量采用2的N次方,这样可以使得各个分区间数据分布更加均匀。
4.4 组合范围列表分区这种分区是基于范围分区和列表分区,表首先按某列进行范围分区,然后再按某列进行列表分区,分区之中的分区被称为子分区。
CREATE TABLE SALES(PRODUCT_ID VARCHAR2(5),SALES_DATE DATE,SALES_COST NUMBER(10),STATUS VARCHAR2(20))PARTITION BY RANGE(SALES_DATE) SUBPARTITION BY LIST (STATUS)( PARTITION P1 VALUES LESSTHAN(TO_DATE('2003-01-01','YYYY-MM-DD'))TABLESPACE RPTFACT2009 ( SUBPARTITION P1SUB1 VALUES ('ACTIVE') TABLESPACE RPTFACT2009,SUBPARTITION P1SUB2 VALUES ('INACTIVE') TABLESPACE RPTFACT2009),PARTITION P2 VALUES LESSTHAN (TO_DATE('2003-03-01','YYYY-MM-DD')) TABLESPACE RPTFACT2009( SUBPARTITION P2SUB1 VALUES ('ACTIVE') TABLESPACE RPTFACT2009,SUBPARTITION P2SUB2 VALUES ('INACTIVE') TABLESPACE RPTFACT2009))4.5 复合范围散列分区这种分区是基于范围分区和散列分区,表首先按某列进行范围分区,然后再按某列进行散列分区。