数据挖掘作业
- 格式:doc
- 大小:41.00 KB
- 文档页数:2

《数据挖掘》作业第一章引言一、填空题(1)数据库中的知识挖掘(KDD)包括以下七个步骤:数据清理、数据集成、数据选择、数据变换、数据挖掘、模式评估和知识表示(2)数据挖掘的性能问题主要包括:算法的效率、可扩展性和并行处理(3)当前的数据挖掘研究中,最主要的三个研究方向是:统计学、数据库技术和机器学习(4)在万维网(WWW)上应用的数据挖掘技术常被称为:WEB挖掘(5)孤立点是指:一些与数据的一般行为或模型不一致的孤立数据二、单选题(1)数据挖掘应用和一些常见的数据统计分析系统的最主要区别在于:(B )A、所涉及的算法的复杂性;B、所涉及的数据量;C、计算结果的表现形式;D、是否使用了人工智能技术(2)孤立点挖掘适用于下列哪种场合?(D )A、目标市场分析B、购物篮分析C、模式识别D、信用卡欺诈检测(3)下列几种数据挖掘功能中,( D )被广泛的应用于股票价格走势分析A. 关联分析B.分类和预测C.聚类分析D. 演变分析(4)下面的数据挖掘的任务中,( B )将决定所使用的数据挖掘功能A、选择任务相关的数据B、选择要挖掘的知识类型C、模式的兴趣度度量D、模式的可视化表示(5)下列几种数据挖掘功能中,(A )被广泛的用于购物篮分析A、关联分析B、分类和预测C、聚类分析D、演变分析(6)根据顾客的收入和职业情况,预测他们在计算机设备上的花费,所使用的相应数据挖掘功能是( B )A.关联分析B.分类和预测C. 演变分析D. 概念描述(7)帮助市场分析人员从客户的基本信息库中发现不同的客户群,通常所使用的数据挖掘功能是( C )A.关联分析B.分类和预测C.聚类分析D. 孤立点分析E. 演变分析(8)假设现在的数据挖掘任务是解析数据库中关于客户的一般特征的描述,通常所使用的数据挖掘功能是( E )A.关联分析B.分类和预测C. 孤立点分析D. 演变分析E. 概念描述三、简答题(1)什么是数据挖掘?答:数据挖掘是指从大量数据中提取或“挖掘”知识。

数据挖掘的其他基本功能介绍一、关联规则挖掘关联规则挖掘是挖掘数据库中和指标(项)之间有趣的关联规则或相关关系。
关联规则挖掘具有很多应用领域,如一些研究者发现,超市交易记录中的关联规则挖掘对超市的经营决策是十分重要的。
1、 基本概念设},,,{21m i i i I =是项组合的记录,D 为项组合的一个集合。
如超市的每一张购物小票为一个项的组合(一个维数很大的记录),而超市一段时间内的购物记录就形成集合D 。
我们现在关心这样一个问题,组合中项的出现之间是否存在一定的规则,如A 游泳衣,B 太阳镜,B A ⇒,但是A B ⇒得不到足够支持。
在规则挖掘中涉及到两个重要的指标:① 支持度 支持度n B A n B A )()(⇒=⇒,显然,只有支持度较大的规则才是较有价值的规则。
② 置信度 置信度)()()(A n B A n B A ⇒=⇒,显然只有置信度比较高的规则才是比较可靠的规则。
因此,只有支持度与置信度均较大的规则才是比较有价值的规则。
③ 一般地,关联规则可以提供给我们许多有价值的信息,在关联规则挖掘时,往往需要事先指定最小支持度与最小置信度。
关联规则挖掘实际上真正体现了数据中的知识发现。
如果一个规则满足最小支持度,则称这个规则是一个频繁规则;如果一个规则同时满足最小支持度与最小置信度,则通常称这个规则是一个强规则。
关联规则挖掘的通常方法是:首先挖掘出所有的频繁规则,再从得到的频繁规则中挖掘强规则。
在少量数据中进行规则挖掘我们可以采用采用简单的编程方法,而在大量数据中挖掘关联规则需要使用专门的数据挖掘软件。
关联规则挖掘可以使我们得到一些原来我们所不知道的知识。
应用的例子:* 日本超市对交易数据库进行关联规则挖掘,发现规则:尿片→啤酒,重新安排啤酒柜台位置,销量上升75%。
* 英国超市的例子:大额消费者与某种乳酪。
那么,证券市场上、期货市场上、或者上市公司中存在存在哪些关联规则,这些关联规则究竟说明了什么?关联规则挖掘通常比较适用与记录中的指标取离散值的情况,如果原始数据库中的指标值是取连续的数据,则在关联规则挖掘之前应该进行适当的数据离散化(实际上就是将某个区间的值对应于某个值),数据的离散化是数据挖掘前的重要环节,离散化的过程是否合理将直接影响关联规则的挖掘结果。

大连理工大学22春“计算机科学与技术”《数据挖掘》作业考核题库高频考点版(参考答案)一.综合考核(共50题)1.在Python3.5中,集合类型的各个元素之间存在先后顺序。
()A.正确B.错误参考答案:B2.以下哪一种数据类型元素之间是无序的,相同元素在集合中唯一存在?()A.元组B.字符串C.列表D.集合参考答案:D3.python中内置了round函数来进行小数的四舍五入操作,请选择round(3.1415923, 4)对应的结果()。
A.3.142B.3.14C.3.1416D.3.0参考答案:C4.遍历循环for语句中,不可以遍历的结构是()。
A.字符串B.元组C.数字类型D.字典5.以下选项中不是Python关键字的是()。
A.whileB.exceptC.inD.do参考答案:D6.以下选项中是Python中文分词的第三方库的是()。
A.turtleB.jiebaC.timeD.itchat参考答案:B7.以下选项中,不是Python对文件的打开模式的是()。
A.‘c’B.‘r+’C.‘w’D.‘r’参考答案:A8.Python中的注释是为了让计算机更能理解程序表达的意思。
()A.正确B.错误参考答案:B9.B.错误参考答案:B10.以下选项对Python文件操作描述错误的是()。
A.当文件以文本方式打开时,读写会按照字节流方式进行B.Python能以文本和二进制两种方式处理文件C.文件使用结束后要用close方法关闭,释放文件的使用授权D.Python能通过内置的open函数打开一个文件进行操作参考答案:A11.局部变量若与全局变量重名,则不能在函数内部创建和使用。
()A.正确B.错误参考答案:B12.下列不是Python对文件进行读操作的方法是()。
A.readtextB.readlinesC.readD.readline参考答案:A13.for循环和while循环中都存在一个else扩展用法,continue关键字对else没有影响。

数据挖掘Part I:手写作业:Part II: 上机作业:Recommendation Systems Hand-in: The list of association rules generated by the model.设置min-support=5%,min-confidence=50%,如图所示:结果如下图所示:关联规则如下:⇒biscuits m ilk yoghurt milk⇒⇒tom ato souse pastatomato souse milk⇒∧⇒pasta water milk⇒juices milk∧⇒biscuits pasta milk⇒rice pasta∧⇒tomato souse pasta milk∧⇒coffee pasta milk∧⇒tomato souse milk pasta∧⇒biscuits w ater m ilkbrioches pasta milk∧⇒∧⇒yoghurt pasta milkSort the rules by lift, support, and confidence, respectively to see the rules identified. Hand-in: For each case, choose top 5 rules (note: make sure no redundant rules in the 5 rules) and give 2-3 lines comments. Many of the rules will be logically redundant and therefore will have to be eliminated after you think carefully about them.按support排序:support最高的5个规则是:1.biscuits m ilk⇒2.yoghurt milk⇒3.tom ato souse pasta⇒4.tomato souse milk⇒5.pasta water milk∧⇒按support排序的前5个规则没有冗余规则。


数据挖掘大作业例子1. 超市购物数据挖掘呀!想想看,如果把超市里每个顾客的购买记录都分析一遍,那岂不是能发现很多有趣的事情?比如说,为啥周五晚上大家都爱买啤酒和薯片呢,是不是都打算周末在家看剧呀!2. 社交媒体情感分析这个大作业超有意思哦!就像你能从大家发的文字里看出他们今天是开心还是难过,那简直就像有了读心术一样神奇!比如看到一堆人突然都在发伤感的话,难道是发生了什么大事情?3. 电商用户行为挖掘也很棒呀!通过分析用户在网上的浏览、购买行为,就能知道他们喜欢什么、不喜欢什么,这难道不是很厉害吗?就像你知道了朋友的喜好,能给他推荐最适合的礼物一样!4. 交通流量数据分析呢!想象一下,了解每个路口的车流量变化,是不是就能更好地规划交通啦?难道这不像是给城市的交通装上了一双明亮的眼睛?5. 医疗数据挖掘更是不得了!能从大量的病例中找到疾病的规律,这简直是在拯救生命啊!难道这不是一件超级伟大的事情吗?比如说能发现某种疾病在特定人群中更容易出现。
6. 金融交易数据挖掘也超重要的呀!可以知道哪些交易有风险,哪些投资更靠谱,那不就像有个聪明的理财顾问在身边吗!就好比能及时发现异常的资金流动。
7. 天气数据与出行的结合挖掘也很有趣呀!根据天气情况来预测大家的出行选择,真是太神奇了吧!难道不是像有了天气预报和出行指南合二为一?8. 音乐喜好数据挖掘呢!搞清楚大家都喜欢听什么类型的音乐,从而能更好地推荐歌曲,这不是能让人更开心地享受音乐吗!好比为每个人定制了专属的音乐播放列表。
9. 电影票房数据挖掘呀!通过分析票房数据就能知道观众最爱看的电影类型,这不是超厉害的嘛!就像知道了大家心里最期待的电影是什么样的。
我觉得数据挖掘真的太有魅力了,可以从各种看似普通的数据中发现那么多有价值的东西,真是让人惊叹不已啊!。
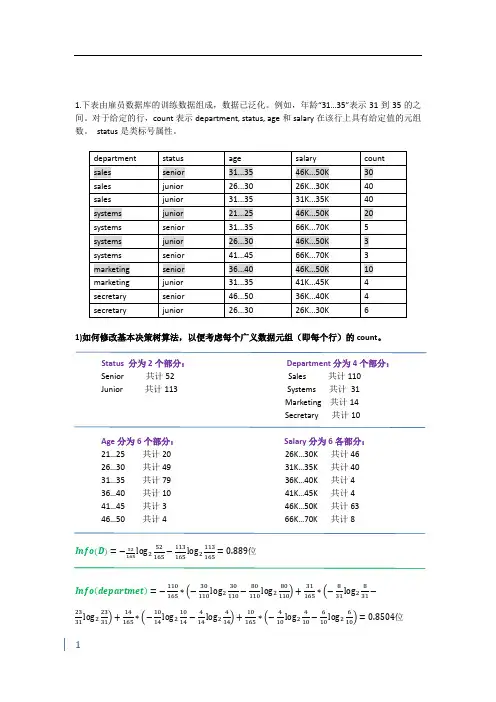
1.下表由雇员数据库的训练数据组成,数据已泛化。
例如,年龄“31…35”表示31到35的之间。
对于给定的行,count表示department, status, age和salary在该行上具有给定值的元组数。
status是类标号属性。
1)如何修改基本决策树算法,以便考虑每个广义数据元组(即每个行)的count。
Status 分为2个部分:Department分为4个部分:Senior 共计52 Sales 共计110Junior 共计113 Systems 共计31Marketing 共计14Secretary 共计10Age分为6个部分:Salary分为6各部分:21…25 共计20 26K…30K 共计4626…30 共计49 31K…35K 共计4031…35 共计79 36K…40K 共计436…40 共计10 41K…45K 共计441…45 共计3 46K…50K 共计6346…50 共计4 66K…70K 共计8Info(D)=−52165log252165−113165log2113165=0.889位Info(departmet)=−110165∗(−30110log230110−80110log280110)+31165∗(−831log2831−23 31log22331)+14165∗(−1014log21014−414log2414)+10165∗(−410log2410−610log2610)=0.8504位Gain(department)=Info(D)−Info(department)=0.0386位Info(age)=−20165∗(−020log2020−2020log22020)+49165∗(−049log2049−4949log24949)+79165∗(−3579log23575−3479log23479)+10165∗(−1010log21010−010log2010)+3165∗(−33log233−03log203)+4 165∗(−44log244−04log204)=0.4998位Gain(age)=Info(D)−Info(age)=0.3892位Info(salary)=−46165∗(−046log2046−4646log24646)+40165∗(−040log2040−4040log24040)+4165∗(−44log244−04log204)+63165∗(−3063log23063−3363log23363)+8165∗(−88log288−08log208)=0.3812位Gain(salary)=Info(D)−Info(salary)=0.5078位由以上的计算知按信息增益从大到小对属性排列依次为:salary、age、department,所以定由这个表可知department和age的信息增益将都为0。

南开19春学期(1709、1803、1809、1903)《数据挖掘》在线作业-2一、单选题共20题,40分1、( )用替代的、较小的数据表示形式替换原数据。
A维归约B数量归约C离散D聚集【南开】答案是:B2、只有非零值才重要的二元属性被称作( )。
A计数属性B离散属性C非对称的二元属性D对称属性【南开】答案是:C3、职位可以按顺序枚举,对于教师有:助教、讲师、副教授、教授。
职位属性是( )。
A标称属性B序数属性C数值属性D二元属性【南开】答案是:B4、( )去掉数据中的噪声,这类技术包括分箱、回归和聚类。
A光滑B聚集C规范化D属性构造【南开】答案是:A5、在基于规则分类器的中,依据规则质量的某种度量对规则排序,保证每一个测试记录都是由覆盖它的“最好的”规格来分类,这种方案称为( )。
A基于类的排序方案B基于规则的排序方案C基于度量的排序方案D基于规格的排序方案【南开】答案是:B6、分位数是取自数据分布的每隔一定间隔上的点,把数据划分成基本上大小相等的连贯集合。
如:4-分位数是( )个数据点,它们把数据分布划分成4个相等的部分,使得每部分表示数据分布的四分之一。
A1B2C3D4【南开】答案是:C7、决策树学习:决策树算法对数据处理过程中,将数据按( )结构分成若干分枝形成决策树,从根到树叶的每条路径创建一个规则。
A树状B网状C星形D雪花形【南开】答案是:A8、以下属于可伸缩聚类算法的是( )。
ACUREBDENCLUECCLIQUEDOPOSSUM【南开】答案是:A9、( )将两个簇的邻近度定义为不同簇的所有点对的平均逐对邻近度,它是一种凝聚层次聚类技术。
AMIN(单链)BMAX(全链)C组平均DWard方法【南开】答案是:C10、如果规则集R中不存在两条规则被同一条记录触发,则称规则集R中的规则为( )。
A无序规则B穷举规则C互斥规则D有序规则【南开】答案是:C11、( )是KDD。
A数据挖掘与知识发现B领域知识发现C文档知识发现D动态知识发现【南开】答案是:A12、在有关数据仓库测试,下列说法不正确的是( )。

Weka数据挖掘期末大作业是一个非常重要的任务。
它涉及到许多数据挖掘技术,可以帮助学生们了解数据挖掘的核心概念,以及如何应用这些技术来解决实际问题。
首先,学生需要了解Weka数据挖掘工具,包括其特点和功能。
Weka是一个开源的数据挖掘工具,它提供了各种有用的算法,可以帮助学生们进行数据分析,比如分类、聚类和关联分析。
Weka还有一个灵活的用户界面,可以让学生们轻松地查看和编辑数据。
其次,学生还需要了解如何通过Weka来完成期末大作业。
学生可以使用Weka的GUI工具,轻松地训练和评估机器学习模型。
另外,学生还可以使用Weka的API,在Java或其他编程语言中编写自己的算法。
第三,学生还需要考虑如何将实际问题转换为可以在Weka中解决的问题。
这要求学生们了解数据挖掘的基本概念,如数据预处理、特征选择、模型训练和评估。
最后,期末大作业还需要学生提交一份报告,说明他们在数据挖掘中学到的内容。
报告中需要包括算法的细节,以及实验结果分析,以便说明学生们是如何使用Weka解决实际问题的。
总之,Weka数据挖掘期末大作业是一个很重要的任务,可以帮助学生们更好地理解数据挖掘技术,以及如何将其应用于实际问题。

大工21春《数据挖掘》在线作业3试卷总分:100 得分:100一、单选题 (共 10 道试题,共 50 分)1.下面变量名称命名合法的是:()<-A.->_tempStr<-B.->is<-C.->2018python<-D.->123Python【-参考.选择-】:A2.下面不能用来作为变量名称的是:()<-A.->list<-B.->_1ab<-C.->not<-D.->a1b2【-参考.选择-】:C3.下列标识符中哪个是不合法的?()<-A.->40temp<-B.->tempStr<-C.->list<-D.->_124【-参考.选择-】:A4.遍历循环for语句中,不可以遍历的结构是()<-A.->字符串<-B.->元组<-C.->数字类型<-D.->字典【-参考.选择-】:C5.python中内置了round函数来进行小数的四舍五入操作,请选择round(3.1415923, 4)对应的结果:()<-A.->3.142<-B.->3.14<-C.->3.1416<-D.->3.0【-参考.选择-】:C6.以下选项中描述错误的是:()<-A.->Python是解释性语言<-B.->Python是跨平台语言<-C.->Python是脚本语言。

网络教育学院《数据挖掘》课程大作业题目: SVM算法原理以及python实现姓名:学习中心:要将庞大的数据转换成为有用的信息,必须先有效率地收集信息。
随着科技的进步,功能完善的数据库系统就成了最好的收集数据的工具。
数据仓库,简单地说,就是搜集来自其它系统的有用数据,存放在一整合的储存区内。
所以其实就是一个经过处理整合,且容量特别大的关系型数据库,用以储存决策支持系统所需的数据,供决策支持或数据分析使用。
数据挖掘的研究领域非常广泛,主要包括数据库系统、基于知识的系统、人工智能、机器学习、知识获取、统计学、空间数据库和数据可视化等领域。
主要是可以做以下几件事:分类、估计、预测、关联分析、聚类分析、描述和可视化、复杂数据类型挖掘。
运行环境Pyhton3numpy(科学计算包)matplotlib(画图所需,不画图可不必)计算过程st=>start: 开始e=>end: 结束op1=>operation: 读入数据op2=>operation: 格式化数据cond=>condition: 是否达到迭代次数op3=>operation: 寻找超平面分割最小间隔ccond=>conditon: 数据是否改变op4=>operation: 输出结果st->op1->op2->condcond(yes)->op4->econd(no)->op3啊,这markdown flow好难用,我决定就画到这吧=。
=输入样例/* testSet.txt*/3.542485 1.977398 -13.018896 2.556416-17.551510 -1.580030 12.114999 -0.004466-18.127113 1.274372 17.108772 -0.98690618.610639 2.046708 12.326297 0.265213-13.634009 1.730537 -10.341367 -0.894998-13.125951 0.293251 -12.123252 -0.783563-10.887835 -2.797792 -17.139979 -2.329896 11.696414 -1.212496 -18.117032 0.623493 18.497162 -0.266649 14.658191 3.507396 -18.197181 1.545132 11.208047 0.213100 -11.928486 -0.321870 -12.175808 -0.014527 -17.886608 0.461755 13.223038 -0.552392 -13.628502 2.190585 -17.407860 -0.121961 17.286357 0.251077 12.301095 -0.533988 -1-0.232542 -0.547690 -13.457096 -0.082216 -13.023938 -0.057392 -18.015003 0.885325 18.991748 0.923154 17.916831 -1.781735 17.616862 -0.217958 12.450939 0.744967 -17.270337 -2.507834 11.749721 -0.961902 -11.803111 -0.176349 -18.804461 3.044301 11.231257 -0.568573 -12.074915 1.410550 -1-0.743036 -1.736103 -13.536555 3.964960 -18.410143 0.025606 17.382988 -0.478764 16.960661 -0.245353 18.234460 0.701868 18.168618 -0.903835 11.534187 -0.622492 -19.229518 2.066088 17.886242 0.191813 12.893743 -1.643468 -11.870457 -1.040420 -15.286862 -2.358286 16.080573 0.418886 12.544314 1.714165 -16.016004 -3.753712 10.926310 -0.564359 -10.870296 -0.109952 -12.369345 1.375695 -11.363782 -0.254082 -17.279460 -0.189572 11.896005 0.515080 -18.102154 -0.603875 12.529893 0.662657 -11.963874 -0.365233 -18.132048 0.785914 18.245938 0.372366 16.543888 0.4331641-0.236713 -5.766721 -18.112593 0.29583919.803425 1.495167 11.497407 -0.552916-11.336267 -1.632889 -19.205805 -0.58648011.966279 -1.840439 -18.398012 1.58491817.239953 -1.764292 17.556201 0.24118519.015509 0.345019 18.266085 -0.23097718.545620 2.788799 19.295969 1.34633212.404234 0.570278 -12.037772 0.021919-11.727631 -0.453143 -11.979395 -0.050773-18.092288 -1.372433 11.667645 0.239204-19.854303 1.365116 17.921057 -1.32758718.500757 1.492372 11.339746 -0.291183-13.107511 0.758367 -12.609525 0.902979-13.263585 1.367898 -12.912122 -0.202359-11.731786 0.589096 -12.387003 1.573131-1代码实现# -*- coding: utf-8 -*-__author__ = 'Wsine'from numpy import *import matplotlib.pyplot as pltimport operatorimport timedef loadDataSet(fileName):dataMat = []labelMat = []with open(fileName) as fr:for line in fr.readlines():lineArr = line.strip().split('\t')dataMat.append([float(lineArr[0]),float(lineArr[1])])labelMat.append(float(lineArr[2])) return dataMat, labelMatdef selectJrand(i, m):j = iwhile (j == i):j = int(random.uniform(0, m))return jdef clipAlpha(aj, H, L):if aj > H:aj = Hif L > aj:aj = Lreturn ajclass optStruct:def __init__(self, dataMatIn, classLabels, C, toler):self.X = dataMatInbelMat = classLabelsself.C = Cself.tol = tolerself.m = shape(dataMatIn)[0]self.alphas = mat(zeros((self.m, 1)))self.b = 0self.eCache = mat(zeros((self.m, 2)))def calcEk(oS, k):fXk = float(multiply(oS.alphas, belMat).T * (oS.X * oS.X[k, :].T)) + oS.bEk = fXk - float(belMat[k])return Ekdef selectJ(i, oS, Ei):maxK = -1maxDeltaE = 0Ej = 0oS.eCache[i] = [1, Ei]validEcacheList = nonzero(oS.eCache[:, 0].A)[0]if (len(validEcacheList)) > 1:for k in validEcacheList:if k == i:continueEk = calcEk(oS, k)deltaE = abs(Ei - Ek)if (deltaE > maxDeltaE):maxK = kmaxDeltaE = deltaEEj = Ekreturn maxK, Ejelse:j = selectJrand(i, oS.m)Ej = calcEk(oS, j)return j, Ejdef updateEk(oS, k):Ek = calcEk(oS, k)oS.eCache[k] = [1, Ek]def innerL(i, oS):Ei = calcEk(oS, i)if ((belMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((belMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):j, Ej = selectJ(i, oS, Ei)alphaIold = oS.alphas[i].copy()alphaJold = oS.alphas[j].copy()if (belMat[i] != belMat[j]):L = max(0, oS.alphas[j] - oS.alphas[i])H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])else:L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)H = min(oS.C, oS.alphas[j] + oS.alphas[i])if (L == H):# print("L == H")return 0eta = 2.0 * oS.X[i, :] * oS.X[j, :].T - oS.X[i, :] * oS.X[i, :].T - oS.X[j, :] * oS.X[j, :].Tif eta >= 0:# print("eta >= 0")return 0oS.alphas[j] -= belMat[j] * (Ei - Ej) / etaoS.alphas[j] = clipAlpha(oS.alphas[j], H, L)updateEk(oS, j)if (abs(oS.alphas[j] - alphaJold) < 0.00001):# print("j not moving enough")return 0oS.alphas[i] += belMat[j] * belMat[i] * (alphaJold - oS.alphas[j])updateEk(oS, i)b1 = oS.b - Ei - belMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[i, :].T - belMat[j] * (oS.alphas[j] - alphaJold) * oS.X[i, :] * oS.X[j, :].Tb2 = oS.b - Ei - belMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[j, :].T - belMat[j] * (oS.alphas[j] - alphaJold) * oS.X[j, :] * oS.X[j, :].Tif (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):oS.b = b1elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):oS.b = b2else:oS.b = (b1 + b2) / 2.0return 1else:return 0def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup=('lin', 0)): """输入:数据集, 类别标签, 常数C, 容错率, 最大循环次数输出:目标b, 参数alphas"""oS = optStruct(mat(dataMatIn), mat(classLabels).transpose(), C, toler)iterr = 0entireSet = TruealphaPairsChanged = 0while (iterr < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):alphaPairsChanged = 0if entireSet:for i in range(oS.m):alphaPairsChanged += innerL(i, oS)# print("fullSet, iter: %d i:%d, pairs changed %d" % (iterr, i, alphaPairsChanged))iterr += 1else:nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]for i in nonBoundIs:alphaPairsChanged += innerL(i, oS)# print("non-bound, iter: %d i:%d, pairs changed %d" % (iterr, i, alphaPairsChanged))iterr += 1if entireSet:entireSet = Falseelif (alphaPairsChanged == 0):entireSet = True# print("iteration number: %d" % iterr)return oS.b, oS.alphasdef calcWs(alphas, dataArr, classLabels):"""输入:alphas, 数据集, 类别标签输出:目标w"""X = mat(dataArr)labelMat = mat(classLabels).transpose()m, n = shape(X)w = zeros((n, 1))for i in range(m):w += multiply(alphas[i] * labelMat[i], X[i, :].T) return wdef plotFeature(dataMat, labelMat, weights, b):dataArr = array(dataMat)n = shape(dataArr)[0]xcord1 = []; ycord1 = []xcord2 = []; ycord2 = []for i in range(n):if int(labelMat[i]) == 1:xcord1.append(dataArr[i, 0])ycord1.append(dataArr[i, 1])else:xcord2.append(dataArr[i, 0])ycord2.append(dataArr[i, 1])fig = plt.figure()ax = fig.add_subplot(111)ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')ax.scatter(xcord2, ycord2, s=30, c='green')x = arange(2, 7.0, 0.1)y = (-b[0, 0] * x) - 10 / linalg.norm(weights)ax.plot(x, y)plt.xlabel('X1'); plt.ylabel('X2')plt.show()def main():trainDataSet, trainLabel = loadDataSet('testSet.txt')b, alphas = smoP(trainDataSet, trainLabel, 0.6, 0.0001, 40)ws = calcWs(alphas, trainDataSet, trainLabel)print("ws = \n", ws)print("b = \n", b)plotFeature(trainDataSet, trainLabel, ws, b)if __name__ == '__main__':start = time.clock()main()end = time.clock()print('finish all in %s' % str(end - start)) 输出样例ws =[[ 0.65307162][-0.17196128]]b =[[-2.89901748]]finish all in 2.5683854014099112。
数据挖掘技术平时作业第一次:1.什么是数据挖掘?当把数据挖掘看作知识发现过程时,描述数据挖掘所涉及的步骤。
【参考答案】数据挖掘是指从大量数据中提取有趣的(有价值的、隐含的、先前未知的、潜在有用的)关系、模式或趋势,并用这些知识与规则建立用于决策支持的模型,提供预测性决策支持的方法。
很多学者把数据挖掘当作另一术语KDD的同义词,而另一些学者把数据挖掘看作KDD的一个步骤。
当把数据挖掘看作知识发现过程时,数据挖掘的过程大致有以下几步:!)数据清理与集成2)任务相关数据分析与选择3)数据挖掘实施4)模式评估5)知识理解与应用第二次:1.在现实世界中,元组在某些属性上缺少值是常有的。
描述处理该问题的各种方法。
【参考答案】处理空缺的属性值有以下几种方法:1)忽略元组2)人工填写空缺值3)自动填充(1)使用全局常量,如用Unknown 或-∞(2)使用属性的平均值(3)使用与给定元组属于同一类的所有样本的平均值(4)使用可能的值:这些值可以用回归、判定树、基于推导的贝叶斯形式化方法等确定2.假定用于分析的数据包含属性age,数据元组中age的值如下:13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70a)使用最小-最大规范化,将age值35转换到[0.0,1.0]区间。
【参考答案】根据公式min'(_max_min)_minmax minAA A AA AVV new new new-=-+-进行计算。
根据提供的数据,maxA=70,minA=13,将将age值35转换到[0.0,1.0]区间,有:V’=(35-13)/(70-13)*(1.0-0.0)+0.0=0.386所以,将值35映射到区间[0.0,1.0]后的值为0.386。
b)使用Z-Score规范化转换age值,其中age的标准差为12.94。
姓名:王燕学号:109070018数据挖掘思考和练习题第一章1.1 什么是数据挖掘?什么是知识发现?简述KDD的主要过程。
答:(1)数据挖掘(Data Mining)是指从大量结构化和非结构化的数据中提取有用的信息和知识的过程,它是知识发现的有效手段。
(2)知识发现是从大量数据中提取有效的、新颖的、潜在的有用的,以及最终可理解的模式的非平凡过程。
(3)KDD的过程主要包括:KDD的过程主要由数据整理、数据挖掘、结果的解释评论三部分组成。
可以由模型表示出来:1.确定挖掘目标:了解应用领域及相关的经验知识,从用户的观点出发确定数据挖掘的目标。
这一步是实现数据挖掘的重要因素,相当于系统分析,需要系统分析员和用户的共同参与。
2.建立目标数据集:从现有的数据中,确定哪些数据是与本次数据分析任务相关的。
根据挖掘目标,从原始数据中选择相关数据集,并将不同数据源中的数据集中起来。
在这一阶段需要解决数据挖掘平台、操作系统和数据源数据类型等不同所产生的数据格式差异。
3.数据清洗和预处理:这一阶段即是将数据转变成“干净”的数据。
目标数据集中不可避免地存在着不完整、不一致、不精确和冗余地数据。
数据抽取之后必须利用专业领域地知识对“脏数据”进行清洗。
然后再对它们实施相应的方法,神经网络方法和模糊匹配技术分析多数据源之间联系,然后再对它们实施相应的处理。
4.数据降维和转换:在对数据库和数据子集进行预处理之后,考虑了数据的不变表示或发现了数据的不变的表示情况下,减少变量的实际数目,设法将数据转换到一个更易找到了解的空间上。
5.选择挖掘算法使用合适的数据挖掘算法完成数据分析。
确定实现挖掘目标的数据挖掘功能,这些功能方法包括概念描述、分类、聚类、关联规则。
其次选择合适的模式搜索算法,包括模型和参数的确定。
6.模式评价和解释根据最终用户的决策目的对数据挖掘发现的模式进行评价,将有用的模式或描述有用模式的数据以可视化技术和知识表示技术展示给用户,让用户能够对模型结果作出解释,评价模式的有效性。
大工19秋《数据挖掘》在线作业2试卷总分:100 得分:100一、单选题 (共 10 道试题,共 50 分)1.程序语句len(str('3.1415')) 的输出结果为()A.7B.6C.5D.4答案:B2.关于Python中异常处理,以下描述错误的是()A.编程语言中的异常和错误完全是相同的概念B.程序异常发生后经过异常处理,程序可以继续执行C.异常语句可以与else和finally关键字配合使用D.Python通过try、except等关键字提供异常处理功能答案:A3.以下那个关键字不是异常处理语句的关键字()A.tryB.finallyC.exceptD.elif答案:D4.以下选项中不是Python关键字的是()A.whileB.inC.exceptD.do答案:D5.以下选项中用来捕获特定类型异常的关键字是()A.whileB.passC.exceptD.do答案:C6.以下不属于Python的关键字的是()A.returnB.markC.globalD.del答案:B7.Python中定义函数的关键字是()A.functionB.defuncC.defineD.def答案:D8.以下选项对Python文件操作描述错误的是()A.文件使用结束后要用close()方法关闭,释放文件的使用授权B.当文件以文本方式打开时,读写会按照字节流方式进行C.Python能通过内置的open()函数打开一个文件进行操作D.Python能以文本和二进制两种方式处理文件答案:B9.下列不是Python对文件进行读操作的方法是()A.readtextB.readlinesC.readlineD.read答案:A10.Python中操作集合时,可以使用哪个函数来对集合进行增加元素的操作()A.putB.popC.appendD.add答案:D二、判断题 (共 10 道试题,共 50 分)11.函数的名称可以任意字符组合形成的。
数据挖掘作业答案数据挖掘作业题⽬+答案华理计算机专业选修课第⼆章:假定⽤于分析的数据包含属性age。
数据元组中age值如下(按递增序):13 ,15 ,16 ,16 ,19 ,20 ,20,21 ,22 ,22,25 ,25 ,25 ,25 ,30 ,33 ,33 ,35 ,35 ,35,35,36,40,45,46,52,70.分别⽤按箱平均值和边界值平滑对以上数据进⾏平滑,箱的深度为3.使⽤最⼩-最⼤规范化,将age值35转换到[0.0,1.0]区间使⽤z-Score规范化转换age值35 ,其中age的标准差为12.94年。
使⽤⼩数定标规范化转换age值35。
画⼀个宽度为10的等宽直斱图。
该数据的均值是什么?中位数是什么?该数据的众数是什么?讨论数据的峰(即双峰,三峰等)数据的中列数是什么?(粗略地)找出数据的第⼀个四分位数(Q1 )和第三个四分位数(Q3 )给出数据的五数概括画出数据的盒图第三章假定数据仓库包含三个维:time doctor和patient ;两个度量:count和charge;其中charge是医⽣对病⼈⼀次诊治的收费。
画出该数据仓库的星型模式图。
由基本⽅体[day, doctor, patient]开始,为列出2004年每位医⽣的收费总数,应当执⾏哪些OLAP操作。
如果每维有4层(包括all ),该⽴⽅体包含多少⽅体(包括基本⽅体和顶点⽅体)?第五章数据库有4个事务。
设min_sup=60%,min_conf=80%TID Itmes_boughtT100 {K,A,D,B}T200 {D,A,C,E,B}T300 {C,A,B,E}T400 {B,A,D}分别使⽤Apriori和FP-增长算法找出频繁项集。
列出所有的强关联规则(带⽀持度s和置信度c ),它们不下⾯的元规则匹配,其中,X是代表顼客的变量,itmei是表⽰项的变量(例如:A、B等)下⾯的相依表会中了超级市场的事务数据。
您的本次作业分数为:100分单选题1.下列几种数据挖掘功能中,()被广泛的用于购物篮分析。
∙ A 关联分析∙ B 分类和预测∙ C 聚类分析∙ D 演变分析单选题2.以下哪个指标不是表示对象间的相似度和相异度?∙ A Euclidean距离∙ B Manhattan距离∙ C Eula距离∙ D Minkowski距离单选题3.进行数据规范化的目的是()。
∙ A 去掉数据中的噪声∙ B 对数据进行汇总和聚集∙ C 使用概念分层,用高层次概念替换低层次“原始”数据∙ D 将属性按比例缩放,使之落入一个小的特定区间单选题4.下面哪种数据预处理技术可以用来平滑数据,消除数据噪声?∙ A 数据清理∙ B 数据集成∙ C 数据变换∙ D 数据归约单选题5.下面的数据挖掘的任务中,()将决定所使用的数据挖掘功能。
∙ A 选择任务相关的数据∙ B 选择要挖掘的知识类型∙ C 模式的兴趣度度量∙ D 模式的可视化表示单选题6.下列几种数据挖掘功能中,()被广泛的用于购物篮分析。
∙ A 关联分析∙ B 分类和预测∙ C 聚类分析∙ D 演变分析单选题7.哪种数据变换的方法将数据沿概念分层向上汇总?∙ A 平滑∙ B 聚集∙ C 数据概化∙ D 规范化单选题8.下列哪种可视化方法可用于发现多维数据中属性之间的两两相关性?∙ A 空间填充曲线∙ B 散点图矩阵∙ C 平行坐标∙ D 圆弓分割单选题9.下列几种数据挖掘功能中,()被广泛的应用于股票价格走势分析。
∙ A 关联分析∙ B 分类和预测∙ C 聚类分析∙ D 演变分析单选题10.存放最低层汇总的方体称为()。
∙ A 顶点方体∙ B 方体的格∙ C 基本方体∙ D 维单选题11.规则:age(X,”19-25”) ∧buys(X, “popcorn”) => buys(X, “coke”)是一个()。
∙ A 单维关联规则∙ B 多维关联规则∙ C 混合维关联规则∙ D 不是一个关联规则单选题12.置信度(confidence)是衡量兴趣度度量()的指标。
第5章关联分析
5.1 列举关联规则在不同领域中应用的实例。
5.2 给出如下几种类型的关联规则的例子,并说明它们是否是有价值的。
(a)高支持度和高置信度的规则; (b)高支持度和低置信度的规则; (c)低支持度和低置信度的规则; (d)低支持度和高置信度的规则。
5.3 数据集如表5-14所示:
(a) 把每一个事务作为一个购物篮,计算项集{e}, {b, d}和{b, d, e}的支持度。
(b) 利用(a)中结果计算关联规则{b, d}→{e} 和 {e}→{b, d}的置信度。
置信度是一个对称的度量吗?
(c) 把每一个用户购买的所有商品作为一个购物篮,计算项集{e}, {b, d}和{b, d, e}的支持度。
(d) 利用(b)中结果计算关联规则{b, d}→{e} 和 {e}→{b, d}的置信度。
置信度是一个对称的度量吗?
5.4 关联规则是否满足传递性和对称性的性质?举例说明。
5.5 Apriori 算法使用先验性质剪枝,试讨论如下类似的性质 (a) 证明频繁项集的所有非空子集也是频繁的
(b) 证明项集s 的任何非空子集s ’的支持度不小于s 的支持度
(c) 给定频繁项集l 和它的子集s ,证明规则“s’→(l – s’)”的置信度不高于s →(l – s)的置信度,其中s’是s 的子集
(d) Apriori 算法的一个变形是采用划分方法将数据集D 中的事务分为n 个不相交的子数据集。
证明D 中的任何一个频繁项集至少在D 的某一个子数据集中是频繁的。
5.6 考虑如下的频繁3-项集:{1, 2, 3},{1, 2, 4},{1, 2, 5},
{1, 3, 4},{1, 3, 5},{2, 3, 4},{2, 3, 5},{3, 4, 5}。
(a)根据Apriori 算法的候选项集生成方法,写出利用频繁3-项集生成的所有候选4-项集。
(b)写出经过剪枝后的所有候选4-项集
5.7 一个数据库有5个事务,如表5-15所示。
设min_sup=60%,min_conf = 80%。
(a) 分别用Apriori
(b) 比较穷举法和Apriori算法生成的候选项集的数量。
(c) 利用(1)所找出的频繁项集,生成所有的强关联规则和对应的支持度和置信度。
5.8 购物篮分析只针对所有属性为二元布尔类型的数据集。
如果数据集中的某个属性为连续
型变量时,说明如何利用离散化的方法将连续属性转换为二元布尔属性。
比较不同的离散方法对购物篮分析的影响。
5.9 分别说明利用支持度、置信度和提升度评价关联规则的优缺点。
5.10 表5-16所示的相依表汇总了超级市场的事务数据。
其中hot dogs指包含热狗的事务,
hot dogs指不包含热狗的事务。
hamburgers指包含汉堡的事务,hamburgers指不包含汉堡的事务。
和最小置信度阈值50%,这个关联规则是强规则吗?
计算关联规则“hot dogs ⇒hamburgers”的提升度,能够说明什么问题?购买热狗和购买汉堡是独立的吗?如果不是,两者间存在哪种相关关系?
5.11对于表5-17所示序列数据集,设最小支持度计数为2,请找出所有的频繁模式。
表5-17 习题5.11数据集。