大工20春《数据挖掘》课程大作业满分答案
- 格式:doc
- 大小:737.50 KB
- 文档页数:10

一、解答题(满分30分,每小题5分)1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。
知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。
流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。
2. 时间序列数据挖掘的方法有哪些,请详细阐述之时间序列数据挖掘的方法有:1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。
例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。
2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。
若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。
3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。
由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。
假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
3. 数据挖掘的分类方法有哪些,请详细阐述之分类方法归结为四种类型:1)、基于距离的分类方法:距离的计算方法有多种,最常用的是通过计算每个类的中心来完成,在实际的计算中往往用距离来表征,距离越近,相似性越大,距离越远,相似性越小。

大学课程《数据挖掘》试题参考答案范围:∙ 1.什么是数据挖掘?它与传统数据分析有什么区别?定义:数据挖掘(Data Mining,DM)又称数据库中的知识发现(Knowledge Discover in Database,KDD),是目前人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。
数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术等,高度自动化地分析企业的数据,做出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,做出正确的决策。
区别:(1)数据挖掘的数据源与以前相比有了显著的改变;数据是海量的;数据有噪声;数据可能是非结构化的;(2)传统的数据分析方法一般都是先给出一个假设然后通过数据验证,在一定意义上是假设驱动的;与之相反,数据挖掘在一定意义上是发现驱动的,模式都是通过大量的搜索工作从数据中自动提取出来。
即数据挖掘是要发现那些不能靠直觉发现的信息或知识,甚至是违背直觉的信息或知识,挖掘出的信息越是出乎意料,就可能越有价值。
在缺乏强有力的数据分析工具而不能分析这些资源的情况下,历史数据库也就变成了“数据坟墓”-里面的数据几乎不再被访问。
也就是说,极有价值的信息被“淹没”在海量数据堆中,领导者决策时还只能凭自己的经验和直觉。
因此改进原有的数据分析方法,使之能够智能地处理海量数据,即演化为数据挖掘。
∙ 2.请根据CRISP-DM(Cross Industry Standard Process for Data Mining)模型,描述数据挖掘包含哪些步骤?CRISP-DM 模型为一个KDD工程提供了一个完整的过程描述.该模型将一个KDD工程分为6个不同的,但顺序并非完全不变的阶段.1: business understanding: 即商业理解. 在第一个阶段我们必须从商业的角度上面了解项目的要求和最终目的是什么. 并将这些目的与数据挖掘的定义以及结果结合起来.2.data understanding: 数据的理解以及收集,对可用的数据进行评估.3: data preparation: 数据的准备,对可用的原始数据进行一系列的组织以及清洗,使之达到建模需求.4:modeling: 即应用数据挖掘工具建立模型.5:evaluation: 对建立的模型进行评估,重点具体考虑得出的结果是否符合第一步的商业目的.6: deployment: 部署,即将其发现的结果以及过程组织成为可读文本形式.(数据挖掘报告)∙ 3.请描述未来多媒体挖掘的趋势随着多媒体技术的发展,人们接触的数据形式不断地丰富,多媒体数据库的日益增多,原有的数据库技术已满足不了应用的需要,人们希望从这些媒体数据中得到一些高层的概念和模式,找出蕴涵于其中的有价值的知识。

大工20春《数据挖掘》在线作业1(参考)
【奥鹏】-[大连理工大学]大工20春《数据挖掘》在线作业1 试卷总分:100 得分:100
第1题,下面标识符中不是Python语言的关键字的是:()
A、float
B、except
C、continue
D、global
正确答案:
第2题,以下不属于Python的关键字的是()
A、mark
B、del
C、return
D、global
正确答案:A
第3题,Python中定义函数的关键字是()
A、def
B、define
C、function
D、defunc
正确答案:A
第4题,以下选项对Python文件操作描述错误的是()
A、当文件以文本方式打开时,读写会按照字节流方式进行
B、Python能以文本和二进制两种方式处理文件
C、文件使用结束后要用close()方法关闭,释放文件的使用授权
D、Python能通过内置的open()函数打开一个文件进行操作正确答案:A
第5题,下列不是Python对文件进行读操作的方法是()
A、readtext
B、readlines
C、read
D、readline
正确答案:A
第6题,Python中操作集合时,可以使用哪个函数来对集合进行增加元素的操作()A、append。

1.关于import引用,下列选项中描述错误的是()A.使用import turtle可引入turtle库B.使用from turtle import setup 可引入turtle库C.使用import turtle as t可引入turtle库,取别名为tD.import关键字用于导入模块或者模块中的对象【参考答案】: B2.以下选项中是Python中文分词的第三方库的是()A.turtleB.jiebaC.timeD.itchat【参考答案】: B3.以下选项中使Python脚本程序转变为可执行程序的第三方库的是()A.randomB.requestsC.pyinstallerD.pygame【参考答案】: C4.以下选项中,不是Python对文件的打开模式的是:()A.c'B.'r'C.'w'D.'r'【参考答案】: A5.关于Python语言的注释,以下描述错误的是?()A.Python语言的多行注释以'''(三个单引号)开头和结尾B.Python语言的单行注释以#开头C.Python语言有两种注释方式:单行注释和多行注释 D.Python语言的单行注释以单引号'开头【参考答案】: D6.以下程序语句中,哪个是正确利用切片语句取出字符串s="pi=3.1415926"中的所有数字部分()A.s[3:-1]B.s[3:11]C.s[4:-1]D.s[3:12]【参考答案】: D7.以下关于Python组合数据类型描述错误的是?A.序列类型可以通过序号访问元素,元素之间不存在先后关系B.组合数据类型可以分为3类:序列类型、集合类型和映射类型C.Python组合数据类型能够将多个同类型或者不同类型的数据组织起来,通过单一的表示使数据操作更有序、更容易D.Python中字符串、元组和列表都是序列类型【参考答案】: A8.下面Python关键字中,不用于表示分支结构的是:()A.elseB.ifC.elseifD.elif【参考答案】: C9.关于函数,以下描述错误的是()A.函数能完成特定的功能,对函数的使用不需要了解函数内部实现原理,只要了解函数的输入输出方式即可B.使用函数的主要目的是降低编程难度和代码重用C.函数是一段具有特定功能的、可重用的语句组D.Python中使用del关键字定义一个函数【参考答案】: D10.下列选项不属于函数的作用的是:()A.复用代码B.降低编程复杂度C.提高代码的执行速度D.增强代码的可读性【参考答案】: C11.函数体现的是代码复用和模块化设计思想。


大工20春《数据挖掘》课程大作业满分答案网络教育学院《数据挖掘》课程大作业题目:KNN算法原理及Python实现姓名:研究中心:第一大题:数据挖掘》是一门实用性非常强的课程,数据挖掘是大数据这门前沿技术的基础,拥有广阔的前景,在信息化时代具有非常重要的意义。
数据挖掘的研究领域非常广泛,主要包括数据库系统、基于知识的系统、人工智能、机器研究、知识获取、统计学、空间数据库和数据可视化等领域。
在研究过程中,我也遇到了不少困难,例如基础差,对于Python基础不牢,尤其是在进行这次课程作业时,显得力不从心;个别算法也研究的不够透彻。
在接下来的研究中,我仍然要加强理论知识的研究,并且在研究的同时联系实际,在日常工作中注意运用《数据挖掘》所学到的知识,不断加深巩固,不断发现问题,解决问题。
另外,对于自己掌握不牢的知识要勤复,多练,使自己早日成为一名合格的计算机毕业生。
第二大题:KNN算法介绍KNN算法,又叫K最邻近分类算法,是数据挖掘分类技术中最简单的方法之一。
所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
KNN算法的基本思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN算法流程1.计算测试数据与各个训练数据之间的距离;2.按照距离的递增关系进行排序;3.选取距离最小的K个点;4.确定前K个点所在类别的出现频率;5.返回前K个点中出现频率最高的类别作为测试数据的预测分类。
Python实现算法及预测在Python中,我们可以使用sklearn库来实现KNN算法。
具体实现代码如下:pythonfrom sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier(n_neighbors=k)knn.fit(X_train。

(完整word版)数据挖掘题⽬及答案⼀、何为数据仓库?其主要特点是什么?数据仓库与KDD的联系是什么?数据仓库是⼀个⾯向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,⽤于⽀持管理决策。
特点:1、⾯向主题操作型数据库的数据组织⾯向事务处理任务,各个业务系统之间各⾃分离,⽽数据仓库中的数据是按照⼀定的主题域进⾏组织的。
2、集成的数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加⼯、汇总和整理得到的,必须消除源数据中的不⼀致性,以保证数据仓库内的信息是关于整个企业的⼀致的全局信息。
3、相对稳定的数据仓库的数据主要供企业决策分析之⽤,⼀旦某个数据进⼊数据仓库以后,⼀般情况下将被长期保留,也就是数据仓库中⼀般有⼤量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
4、反映历史变化数据仓库中的数据通常包含历史信息,系统记录了企业从过去某⼀时点(如开始应⽤数据仓库的时点)到⽬前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
所谓基于数据库的知识发现(KDD)是指从⼤量数据中提取有效的、新颖的、潜在有⽤的、最终可被理解的模式的⾮平凡过程。
数据仓库为KDD提供了数据环境,KDD从数据仓库中提取有效的,可⽤的信息⼆、数据库有4笔交易。
设minsup=60%,minconf=80%。
TID DATE ITEMS_BOUGHTT100 3/5/2009 {A, C, S, L}T200 3/5/2009 {D, A, C, E, B}T300 4/5/2010 {A, B, C}T400 4/5/2010 {C, A, B, E}使⽤Apriori算法找出频繁项集,列出所有关联规则。
解:已知最⼩⽀持度为60%,最⼩置信度为80%1)第⼀步,对事务数据库进⾏⼀次扫描,计算出D中所包含的每个项⽬出现的次数,⽣成候选1-项集的集合C1。


一、解答题(满分30分,每小题5分)1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。
知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。
流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。
2. 时间序列数据挖掘的方法有哪些,请详细阐述之时间序列数据挖掘的方法有:1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。
例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。
2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。
若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。
3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。
由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。
假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
3. 数据挖掘的分类方法有哪些,请详细阐述之分类方法归结为四种类型:1)、基于距离的分类方法:距离的计算方法有多种,最常用的是通过计算每个类的中心来完成,在实际的计算中往往用距离来表征,距离越近,相似性越大,距离越远,相似性越小。
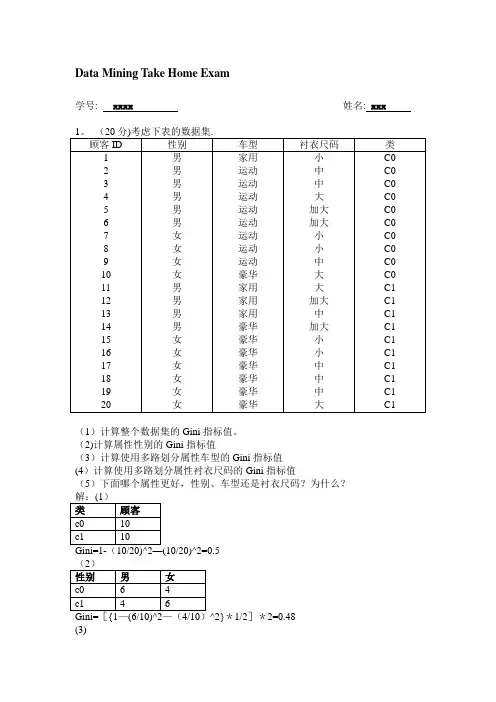
Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?^2}*1/2]*2=0.48(3)—(8/8)^2-(0/8)^2}*8/20+{1—(1/8)^2—(7/8)^2}*8/20=26/160=0。
16254/7)^2}*7/20+[{1—(2/4)^2—(2/4)^2}*4/20]*2=8/25+6/35=0。
4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0。
1625最小,即使用车型属性更好。
2。
((1)将每个事务ID视为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度.(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0). (4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0。
8;{b,d}的支持度为2/10=0。
2;{b,d,e}的支持度为2/10=0。
2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0。
8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)〉anova(ls1)Df Sum Sq Mean Sq F value Pr(〉F)x1 1 10021.2 10021.2 62。

大连理工大学智慧树知到“计算机科学与技术”《数据挖掘》网课测试题答案(图片大小可自由调整)第1卷一.综合考核(共10题)1.下列哪一种不是Python的特性?()A.跨平台特性B.解释型语言C.编译型语言D.面向对象2.列表是一个灵活的数据结构,数字、字符串、列表、字典都可以作为其中的元素。
()A.正确B.错误3.元组可以作为字典的键也可以作为字典的值。
()A.正确B.错误4.任何程序中都必须要有分支结构或循环结构。
()A.正确B.错误5.程序语句len(str(‘3.1415’))的输出结果为()。
A.4B.5C.6D.76.Python中,字典是一个键值对的集合,字典以键为索引,一个键只对应一个值。
()A.正确B.错误7.continue结束整个循环过程,不再判断循环的执行条件。
() A.正确B.错误8.按照程序设计语言的发展历程进行分类,Python可以归类为:()A.高级语言B.自然语言C.汇编语言D.机器语言9.按照程序设计语言的发展历程进行分类,Python可以归类为()。
A.高级语言B.自然语言C.汇编语言D.机器语言10.以下选项对Python文件操作描述错误的是()。
A.当文件以文本方式打开时,读写会按照字节流方式进行B.Python能以文本和二进制两种方式处理文件C.文件使用结束后要用close方法关闭,释放文件的使用授权D.Python能通过内置的open函数打开一个文件进行操作第1卷参考答案一.综合考核1.参考答案:C2.参考答案:A3.参考答案:A4.参考答案:B5.参考答案:C6.参考答案:A7.参考答案:B8.参考答案:A9.参考答案:A10.参考答案:A。
大工20秋《数据挖掘》大作业During this semester。
I have gained a lot from the course of data mining。
In today's society。
the value of data is self-XXX analyzing。
mining。
and modeling data。
we can predict users' XXX design ideas for enterprises。
XXX。
XXX。
the value of data is XXX。
XXX summarize massive and complex data and make data create value is related to the course of data mining。
Data mining is implemented based on the Python language。
Through learning this programming language。
we have gone through a systematic learning from basic concepts to specific syntax and framework。
Finally。
XXX is a course with strong XXX course。
I have gained a brand XXX of the value of data。
I believe that I will use it more in the future.1.XXX and Python XXX1.XXX:KNN (K-XXX。
The input is also a sample feature value vector and the corresponding class label。
大连理工大学智慧树知到“计算机科学与技术”《数据挖掘》网课测试题答案(图片大小可自由调整)第1卷一.综合考核(共10题)1.以下程序语句中,哪个是正确利用切片语句取出字符串s=“pi=3.1415926”中的所有数字部分?()A.s[3:-1]B.s[3:11]C.s[4:-1]D.s[3:12]2.在多分支结构中,Python是通过()来判断语句是否属于一个分支结构中。
A.花括号B.冒号C.括号D.缩进3.Python中的注释是为了让计算机更能理解程序表达的意思。
()A.正确B.错误4.random库采用梅森旋转算法生成伪随机序列。
()A.正确B.错误5.函数用于从控制台输入数据,print函数用于将数据输出到控制台显示。
()A.正确B.错误6.全局变量一定不能和局部变量同名。
()A.正确B.错误7.for循环和while循环中都存在一个else扩展用法,continue关键字对else没有影响。
() A.正确B.错误8.程序设计语言中保留字也称为关键字,指被语言内部定义并保留使用的标识符。
()A.正确B.错误9.关于Python中异常处理,以下描述错误的是()。
A.异常语句可以与else和finally关键字配合使用B.程序异常发生后经过异常处理,程序可以继续执行C.Python通过try、except等关键字提供异常处理功能D.编程语言中的异常和错误完全是相同的概念10.按照程序设计语言的发展历程进行分类,Python可以归类为:()A.高级语言B.自然语言C.汇编语言D.机器语言第1卷参考答案一.综合考核1.参考答案:D2.参考答案:D3.参考答案:B4.参考答案:A5.参考答案:A6.参考答案:B7.参考答案:A8.参考答案:A9.参考答案:D10.参考答案:A。
学习中心:专业:计算机科学与技术年级: 2020年秋季学号:学生:1.谈谈你对本课程学习过程中的心得体会与建议?本学期数据挖掘的课程学习对我来说也是收获颇丰的,当今社会数据的价值不言而喻,通过数据的分析挖掘和处理建模,小到可以预测用户的购物行为和使用习惯为企业提供产品设计思路,分析用户心理从而创造出更加方便智能的产品,还可以极大的方便普通人的生活,大到可以为政府领导决策提供可靠的数据依据。
随着互联网技术的不断发展数据的价值也慢慢体现了出来,但是面对海量复杂的数据如何有效的进行分析汇总如何让数据能够创造价值,这就关联到了数据挖掘这门课程了,数据挖掘是基于Python 这门语言来具体实现的,通过对这门编程语言的学习,从基本概念到具体的语法再到框架我们都经过了一个系统的学习,最终也通过具体的项目去融会贯通之前所学到的知识,数据挖掘课程是理论性和实践性都很强的一门学习,通过这门课程的学习让我对数据价值有了一个全新的认识。
相信以后肯定会更多的使用到的。
2. Knn算法原理以及python实现1. Knn算法介绍:KNN(K-Nearest Neighbor)算法,KNN算法是一种有监督的分类算法,输入同样为样本特征值向量以及对应的类标签,输出则为具有分类功能的模型,能够根据输入的特征值预测分类结果。
核心原理就是,与待分类点最近的K个邻居中,属于哪个类别的多,待分类点就属于那个类别。
2. Knn算法流程:KNN算法模型主要有三要素构成:距离度量,k值的选择和分类的决策规则。
KNN分类算法的思路很简洁,实现也很简洁,具体分三步:1)找K个最近邻。
KNN分类算法的核心就是找最近的K个点,选定度量距离的方法之后,以待分类样本点为中心,分别测量它到其他点的距离,找出其中的距离最近的“TOP K”,这就是K个最近邻。
2)统计最近邻的类别占比。
确定了最近邻之后,统计出每种类别在最近邻中的占比。
3)选取占比最多的类别作为待分类样本的类别。
智慧树知道网课《数据挖掘》课后章节测试满分答案第一章测试1【单选题】(20分)什么是KDD?A.C.文档知识发现B.A.数据挖掘与知识发现C.D.动态知识发现D.B.领域知识发现2【判断题】(20分)数据挖掘的主要任务是从数据中发现潜在的规则,从而能更好的完成描述数据、预测数据等任务。
A.错B.对3【多选题】(20分)数据挖掘的预测建模任务主要包括哪几大类问题?A.分类B.模式匹配C.模式发现D.回归4【多选题】(20分)以下哪些学科和数据挖掘有密切联系?A.人工智能B.计算机组成原理C.矿产挖掘D.统计5【判断题】(20分)离群点可以是合法的数据对象或者值。
A.错B.对第二章测试1【单选题】(20分)下面哪个属于定量的属性类型:A.区间B.序数C.标称D.相异2【单选题】(20分)只有非零值才重要的二元属性被称作:A.非对称的二元属性B.离散属性C.对称属性D.计数属性3【判断题】(20分)定量属性可以是整数值或者是连续值。
A.对B.4【单选题】(20分)中心趋势度量模(mode)是指A.数据集中出现频率最高的值B.算术平均值C.最大值D.最小值5【多选题】(20分)以下哪些是属于中心趋势的度量A.标准差B.中位数五数概括D.平均值第三章测试1【单选题】(20分)数据清洗的方法不包括A.一致性检查。
网络教育学院
《数据挖掘》课程大作业
题目:
姓名:
学习中心:
第一大题:讲述自己在完成大作业过程中遇到的困难,解决问题的思路,以及相关感想,或者对这个项目的认识,或者对Python与数据挖掘的认识等等,300-500字。
《数据挖掘》这门课程是一门实用性非常强的课程,数据挖掘是大数据这门前沿技术的基础,拥有广阔的前景,在信息化时代具有非常重要的意义。
数据挖掘的研究领域非常广泛,主要包括数据库系统、基于知识的系统、人工智能、机器学习、知识获取、统计学、空间数据库和数据可视化等领域。
学习过程中,我也遇到了不少困难,例如基础差,对于Python基础不牢,尤其是在进行这次课程作业时,显得力不从心;个别算法也学习的不够透彻。
在接下来的学习中,我仍然要加强理论知识的学习,并且在学习的同时联系实际,在日常工作中注意运用《数据挖掘》所学到的知识,不断加深巩固,不断发现问题,解决问题。
另外,对于自己掌握不牢的知识要勤复习,多练习,使自己早日成为一名合格的计算机毕业生。
第二大题:完成下面一项大作业题目。
2020春《数据挖掘》课程大作业
注意:从以下5个题目中任选其一作答。
题目一:Knn算法原理以及python实现
要求:文档用使用word撰写即可。
主要内容必须包括:
(1)算法介绍。
(2)算法流程。
(3)python实现算法以及预测。
(4)整个word文件名为 [姓名奥鹏卡号学习中心](如
戴卫东101410013979浙江台州奥鹏学习中心[1]VIP )作业提交:
大作业上交时文件名写法为:[姓名奥鹏卡号学习中心](如:戴卫东101410013979浙江台州奥鹏学习中心[1]VIP)
以附件形式上交离线作业(附件的大小限制在10M以内),选择已完成的作业(注意命名),点提交即可。
如下图所示。
注意事项:
独立完成作业,不准抄袭其他人或者请人代做,如有雷同作业,成绩以零分计!
(一)Knn算法介绍
KNN算法,又叫K最邻近分类算法,是数据挖掘分类技术中最简单的方法之一。
所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
KNN算法概括来说,就是已知一个样本空间里的部分样本分成几个类,然后,给定一个待分类的数据,通过计算找出与自己最接近的K个样本,由这K个样本投票决定待分类数据归为哪一类。
kNN算法在类别决策时,只与极少量的相邻样本有关。
由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
(二)Knn算法流程
如果一个样本在特征空间中的 k 个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
通常 K 的取值比较小,不会超过20。
1、计算测试数据与各个训练数据之间的距离
2、按照升序(从小到大)对距离(欧氏距离)进行排序
3、选取距离最小的前k个点
4、确定前k个点所在类别出现的频率
5、返回前k个点中出现频率最高的类别作为测试数据的分类(三)python实现Knn算法以及预测
1、代码实现
# -*- coding: utf-8 -*-"""
使用python程序模拟KNN算法
Created on Sat Jun 22 18:38:22 2019
@author: zhen"""import numpy as npimport collections as cs
data = np.array([
[203,1],[126,1],[89,1],[70,1],[196,2],[211,2],[221,2],[311,3],[27 1,3]
])
feature = data[:,0] # 特征
print(feature)
label = data[:,-1] # 结果分类
print(label)
predictPoint = 200 # 预测数据
print("预测输入特征为:" + str(predictPoint))
distance = list(map(lambda x : abs(predictPoint - x), feature)) # 各点到预测点的距离print(distance)
sortIndex = np.argsort(distance) # 排序,返回排序后各数据的原始下标
print(sortIndex)
sortLabel = label[sortIndex] # 根据下标重新进行排序
print(sortLabel)
# k = 3 # 设置k值大小为3
for k in range(1,label.size+1):
result = cs.Counter(sortLabel[0:k]).most_common(1)[0][0] # 根据k值计算前k个数据中出现次数最多的分类,即为预测的分类
print("当k=" + str(k) + "时预测分类为:" + str(result))
2、结果
[203 126 89 70 196 211 221 311 271]
[1 1 1 1 2 2 2 3 3]
预测输入特征为:200
[3, 74, 111, 130, 4, 11, 21, 111, 71]
[0 4 5 6 8 1 2 7 3]
[1 2 2 2 3 1 1 3 1]
当k=1时预测分类为:1
当k=2时预测分类为:1
当k=3时预测分类为:2。