Cognos开发之Cube
- 格式:doc
- 大小:781.00 KB
- 文档页数:20



1.1. NT环境Cube数据自动更新1.1.1.NT环境Cube数据自动更新脚本处理方法由于COGNOS的CUBE 发布后,可能出现后台在更新Cube数据时,客户端正在访问要被更新的Cube,如果不取消Cube的访问权限,更新将无法正常进行.基于此理由,在NT环境下,提出如下解决办法,即更新Cube数据前,将CUBE设为不可访问,全部更新后,恢复访问.具体操作如下:1 停止Cube的访问.执行命令示例如下:@ppadmtool connect lsj user "administrator" password "" disable cube 解释: lsj 是PPES 的Sever 名;user "administrator" password "" 代表登录PPES的用户名和口令disable cube 代表被停止的Cube名或Folder名.2 全部Cube数据更新完毕后,恢复对Cube的访问.执行命令示例如下:@ppadmtool connect lsj user "administrator" password "" enable cube调用脚本(Load.bat)示例如下:@rem #初始化@set tmppath=%path%@set path=D:\多维设计\cognos\bat;D:\Program Files\Cognos\cer1\bin@rem #开始执行加载Cube脚本@ppadmtool connect lsj user "administrator" password "" disable cube@rem # 1 收入类月分析指标(欠费用户类)@call Fm_ArrUser_IncomeM@echo 收入类月分析指标(欠费用户类)Fm_ArrUser_IncomeM.bat: >> D:\多维设计\cognos\log\cube加载日志.log@type D:\多维设计\cognos\log\收入类月分析指标(欠费用户类).log >> D:\多维设计\cognos\log\cube加载日志.log@ppadmtool connect lsj user "administrator" password "" enable cube@rem #恢复path路径@set path=%tmppath%@echo 全部Cube生成完毕!!!@ExitFm_ArrUser_IncomeM.bat文件内容示例:@echo 加载Cube:收入类月分析指标(欠费用户类)Fm_ArrUser_IncomeM@echo 开始执行日期及时间: & @date /t & @time /ttrnsfrmr -n2 -s -kReport_Up=sa/123456 "收入类月分析指标(欠费用户类).mdl"@echo [收入类月分析指标(欠费用户类)Fm_ArrUser_IncomeM] cube加载完毕!!!。

Cognos8.3错误解决方法总结1、jre 路径导致报错这个时候我遇到一个问题,Cognos Configuration 无法正常启动,提示信息忘记截图了,不过这个问题比较简单。
错误提示中已经详细的描述了解决办法,其实是因为我的开发机上有Tomcat,设置了JA V A_HOME。
并且用的是JDK142的包,所以必须先修改其路径为Cognos的jre。
否则启动Cognos Configuration的时候会报错。
2、Cognos8 运行数据库无法连接遇到这个问题,是因为jdbc的缘故,如果是Oracle作为运行数据库,就会遇到。
将oracle\jdbc\lib\classes12.jar拷贝到Cognos8/webapps/p2pd/WEB-INF/lib下即可.3、错误码:CFG-ERR-0103 Unable to start Cognos 8 service.这个错误出现的原因是你的内容库是oracle,而且oracle数据库没有试用UTF-8编码。
将内容库的oracle更改成UTF-8编码就可以解决问题。
4、CFG-ERR-0106 问题这个问题就比较诡异了,反正就是启动超时,但是又没有具体原因,百度也没有任何解决办法。
外事不决问Google,还是Google强大,E文网站上倒是有不少同学遇到此类问题。
其实,是因为开发机上跑的程序太多,资源占用厉害导致的。
最后确定的解决办法是修改配置文件,增加Cognos的启动时间。
修改c8_location /configuration/ cogconfig.prefs增加以下两个配置ServiceWaitInterval=*默认是500,代表0.5秒ServiceMaxTries=*默认360,代表倍数默认应该是3分钟超时。
我增加到1000*500,8分多钟。
5、CFG-ERR-0103这个问题是在我们的Cognos测试服务器上遇到的,首先想到的就是BAIDU,发现也有不少朋友碰到这个问题。

Cognos 8.3 BI自动刷新Cube简要配置设计简述:Cognos Transformer是Cognos V8.3多维分析模型设计工具,经过前几个本版的演变,部分功能已经整合Web Server服务中,而Cognos 8.4又重新PowerPlay Studio组件;在7.3的版本中有PPES服务,全方位支持Cube展现、性能优化、页面美化、发布等功能操作。
虽然Transformer在原有基础上做了简化,但相应的功能集成到了BI Web Server服务中,以致用户操作与调整配置相对繁琐。
前些时间与Cognos技术工程师交流,也提到最版本存在缺陷是在所难免,往后版本中会更加人性化和界面化。
国内BI圈很难找到Cognos系统教学资料,更没有相关书籍。
这与Cognos产品有关,一年一个版本,产品不断发展,版本不断更新,新产品替代旧产品,而大多数企业BI系统,使用Cognos BI产品会延续好几年,买Cognos技术服务是需要资金,对企业来讲,把精力放在自己维护人员身上。
据了解,国内众多BI分析系统或者MIS系统,在前端开发都是满足客户OLAP分析、报表、即席查询三大模块。
本文档,是自己项目中摸索与记录下的资料,并不代表统一标准解决方案。
基于Windows环境开发设计模型,手工调度Cube运行比较简单,但需要维护人员触发。
而对于一个庞大的数据仓库系统,按照业务部门需求来定义数据集市,根据需求设计不同类型的分析主题,同时设计的OLAP分析模型也增多。
在设计阶段,感觉不到分析模型给系统的压力,必须考虑利用调度工具来自动运行,这样可以大大减少维护工作压力,可利用系统资源空闲时运行。
Cognos系统配置检查打开Cognos Configuration配置,检查“Authentication”下的认证配置,如:dbAuth是第三方认证登录域名。
在下图中:A区和B区的“dbAuth”名字必须相同时,调用批处理命令行加载登录信息才能通过认证。

Cognos Transformer增量刷新cube生成cognos PowerCube的主要目的是在进行多维分析时,性能会比使用DMR (dimensioned-model-relational)的模型有更好的性能,因为DMR是基于DB查询,每次要动态的生成MDX语句来访问关系型DB。
另外还有一个使用cube的原因是,受限于DB存储的价格和空间,可能只保存了最近一段时间的数据,而生成cube之后,只占用disk空间,不受DB空间限制,可以降低DB的使用费用。
不过如果只是输出为固定报表或其它即席查询的报表,其实不需要制作cube,因为生成cube需要额外的工作,而且在日常运营中会有额外的维护工作,如cube生成调度,失败后的重新刷新等。
之所以要使用增量刷新,最主要的原因就是全量数据太大,如果每次都做全量刷新,会非常消耗时间和资源,因此每次(一般是每天或每月)只把最近一个周期的数据增加到cube 中,一可以减少生成cube的时间,另外,如果做了cube分区,也可以只刷出现问题的cube,而不用每次都重刷。
增量刷新cube需要通过以下2个步骤实现:●在创建cube时指定cube是增量更新;●在cube的数据源获取中,要指定事实数据的SQL或其它方式提供的源只有增量数据,确保每次增加的只是变化的数据,否则cube中中会有重复的数据。
示例以下以一个实际示例为讲解:星型模型如下从上面可以看出,有3个维度:品牌、指标、地区。
其中地区又分为2层,要注意的是为了提高分析性能,在事实表中也增加了city_id字段,这样看似数据有点冗余,其实这样做的目的是,当获取某个city的数据时,不用关联d_county再去过滤,直接在事实表上过滤即可。
物理表结构如下事实表:st_kpi_month品牌维表地市维表:区县维表:KPI指标维表:Trasnformer配置本示例使用IQD文件来提供数据,首先需要在如下文件中c:\Program Files (x86)\ibm\cognos\c10\CS7Gateways\bin\cs7g.ini 增加以下部分内容:其中testcon是连接名称,用于在IQD文件中定义时使用;后面的内容是在cognos administration中添加数据源,测试DB连接时系统自动生成的内容。

cognos常见问题汇总Cognos常见问题汇总(1).Cube如何自动刷新?在cognos8中,如何自动更新cube呢?将类似于以下代码保存为.bat文件\Files\\cognos\\cer5\\bin\\trnsfrmr.exe\生产\\工作票合格率.pyi\其中n2表示显示执行过程窗口,n1表示最小化执行窗口,n表示不显示执行窗口.注意:powerplay transformer模型文件.pyi路径与数据立方体文件.mdc的生成路径要为同一目录.如果碰到生成之后数据不变,就要在powerplay transformer中的files-首选项菜单中设cube的临时目录,运行方式,可以直接双击.bat文件立刻生成新的cube,也可以用 cognos自带的Scheduler设置定时更新,当然也可以用windows自带的Scheduler(应该可以,没有试.)(2)oracle数据出错:ORA-12154:TNS:无法处理服务名是由于oracle没有配制好。
(3)我用transformer manager发布包mypackage后并生成iqd文件,在生成立方体的时候出现错误:Database Signon mypackage wasn't fount on the local machine.这是怎么回事?需本在配制文件congif.ini中添加数据源。
(4)我用framework manager发布包后,用query studio打开后为什么是这样的呀(点不开的,我是直接从数据库取数据发布包的,不是从cube). 不知其原因!晕倒,重装cognos解决.(5)怎么调用DTS包,让它执行,ASP、Java(JSP)、都行,怎么调用DTS包?可以用存储过程调,比较通用,调用DTS的方法 --存储过程方法:CREATE PROCEDURE my_proc1 ASEXEC master.dbo.xp_cmdshell 'dtsrun /S /E /N\包名称\/A\/A\文件.xls\数据库名\GOE:.net调用方式://说明需要添加 Microsoft.SqlServer.DTSPkg80.Package2Class ////// 运行DTS(Data Transformation Services )////// public string runDTS() { try {string returnValue;Microsoft.SqlServer.DTSPkg80.Package2Class package = newMicrosoft.SqlServer.DTSPkg80.Package2Class(); string fileName = \string password = null; string packageID = null; string versionID = null; string name = \object pVerpersistStfOfHost = null;package.LoadFromStorageFile(fileName,password,packageID,versionID,name,refpVerpersistStfOfHost); package.Execute(); package.UnInitialize();package=null;returnValue = \return returnValue; }catch(Exception ex) {throw ex; } }(6)如何使用模板技术?参照Report Studio的快速入门教程。
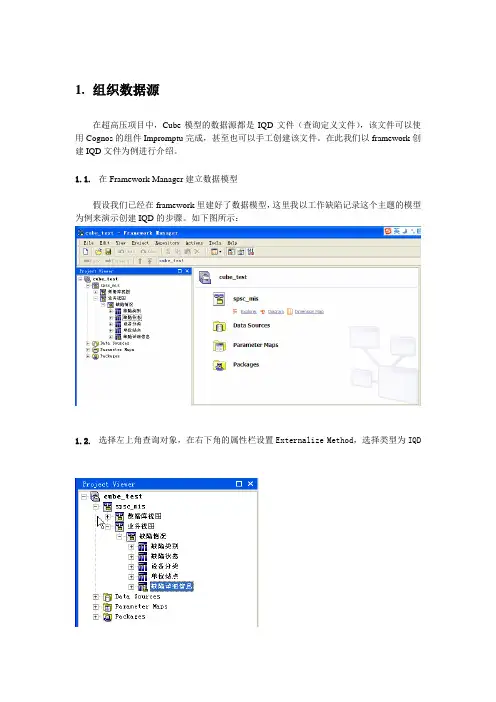
1.组织数据源在超高压项目中,Cube模型的数据源都是IQD文件(查询定义文件),该文件可以使用Cognos的组件Impromptu完成,甚至也可以手工创建该文件。
在此我们以framework创建IQD文件为例进行介绍。
1.1.在Framework Manager建立数据模型假设我们已经在framework里建好了数据模型,这里我以工作缺陷记录这个主题的模型为例来演示创建IQD的步骤。
如下图所示:1.2.选择左上角查询对象,在右下角的属性栏设置Externalize Method,选择类型为IQD1.3.创建一个Package,选择要生成IQD的查询对象,下一步,完成1.4.发布Package,选中Generate the files for externalized query subjects,选择IQD的保存路径,点击发布,到此完成IQD文件的创建。
2.制作cube模型Cognos的Cube模型文件的存储有两种,包括Pyi和Mdl格式,其中Mdl格式又分动态的和结构化的。
Pyi文件属于二进制格式,Mdl文件属于文本格式,可以查看编辑。
默认情况下,Cognos的Mdl文件格式是结构化的,要生成动态的,需要修改参数配置文件trnsfrmr.ini(在Bin目录下)中的选项,增加一行参数:VerbOutput=1,然后重新启动Transformer即可包括Pyi和Mdl格式。
超高压现场用的是cognos8.2,在完成cube开发后进行自动刷新cube的时候发现,如果用Mdl格式就会出现刷新cube不成功的现象,而用Pyi格式就没有问题。
所以下面我们演示Pyi格式模型的创建。
2.1.Insert 数据源在这一步骤里,把一个Cube模型要用到的所有事实表和维度表Iqd文件加入到Transformer的Data Source窗口。
如下示意图:数据源类型选择Iqd(Impromptu Query Definition)录入访问数据的用户和口令一个Cube加入完成,示意图如下:在Data Sources区域点击右键,把其他数据源加入进来。

IBM Cognos Dynamic Cubes V11.0.0用户指南IBM©产品信息本文档适用于 IBM Cognos Analytics V11.0.0,并且还可能适用于后续发行版。
版权Licensed Materials-Property of IBM©Copyright IBM Corp.2012,2018.US Government Users Restricted Rights–Use,duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp.IBM、IBM徽标和 是 International Business Machines Corp.在全球许多管辖区域注册的商标或注册商标。
其他产品和服务名称可能是 IBM或其他公司的商标。
IBM商标的当前列表可以在 Web上的"Copyright and trademark informa-tion"中获取,网址为:/legal/copytrade.shtml。
以下术语是其他公司的商标或注册商标:v Adobe、Adobe徽标、PostScript和 PostScript徽标是 Adobe Systems Incorporated在美国和/或其他国家或地区的注册商标或商标。
v Microsoft、Windows、Windows NT和 Windows徽标是 Microsoft Corporation在美国和/或其他国家或地区的商标。
v Intel、Intel徽标、Intel Inside、Intel Inside徽标、Intel Centrino、Intel Centrino徽标、Celeron、Intel Xeon、Intel SpeedStep、Itanium和 Pentium是 Intel Corporation或其子公司在美国和其他国家或地区的商标或注册商标。

目录前言 (2)Cognos 8 产品结构图: (3)FrameWork (3)样例1-发布一个Package (3)样例2-发布数据库模型 (4)TransFormer (15)Cognos Transformer简介 (15)引入数据 (15)维度(Dimension)设计 (20)指标(Measure)设计 (23)生成立方体 (28)发布Cube (30)Analysis Studio (34)Analysis Studio简介 (34)Analysis Studio操作界面构成 (34)菜单部分说明 (35)前言这个文本介绍了Cognos 8 功能组件,并主要功能及开发指引。
Cognos 8 的功能组件Cognos 8 的功能组件分为服务器端和客户端两部分,服务器端是基于SOA构架的Cognos 8服务,以Web Service的方式接受和处理用户请求;客户端程序是开发人员使用,用于构建CUBE和Cognos 8元数据的工具,它们分别是:TransFormer 和FrameWork。
用户制作、浏览报表和业务分析都是基于浏览器的,不需要安装插件或客户端,在浏览器端,用户可以访问以下组件:Report Studio 、Query Studio 、Analysis Studio。
同时用户也可以基于Cognos提供的SDK开发应用直接访问Cognos 8 服务。
Cognos 8 产品结构图:FrameWorkFramework是元数据模型工具。
元数据模型是对数据源的业务描述。
你的数据源可以是数据库或者Cognos Cube等任何Cognos支持的数据源。
样例1-发布一个Package步骤1.打开Cognos FrameWork,新建一个Project2.选择Data Source下一步3.选择一个已经建好的数据源,也可以新建一个数据源。
我们新建一个数据源,按New4.下一步,数据源名称,下一步5.类型选择ODBC,下一步(以Sybase IQ为例)6.ODBC 数据源、ODBC 连接字符串中输入已配置的ODBC名称:下一步。

Cognos产品操作手册贵州电网项目组2007年1月COGNOS系统操作手册利用Cognos进行数据展现的过程包括建立信息目录,建立imr报表,生成iqd文件,建立展现模型,生成PowerCube,发布PowerCube,制作展现报表,发布到Web Server和展现这一系列的过程。
Cognos系统的操作包括三个主要产品以及一些管理员工具的维护工作。
下面将对Cognos产品的操作进行一个简单的介绍。
1 Cognos产品介绍1.1 介绍Cognos产品的组成现阶段使用的Cognos产品主要包括Impromptu AdministratorAccess Manager AdministrationPowerPlay TransformerPowerPlay Enterprise Server AdministrationUpfront Server AdministrationPowerPlay1.2 工作流程●确定用户需求和数据源●建立中间库,提数●建立查询报表(Impromptu)●生成数据查询文件(Impromptu)●建立查询模型(Transformer)●生成多维数据立方体(Transformer )●发布(PowerPlay Enterprise Server)●数据展现(PowerPlay/IE)2 Impromptu产品Improptu是一个基于Windows桌面的强有力的交互数据报表工具。
生成报表并发布(需要另外购买Cognos IWR)使用Improptu可以完成以下功能:1)从各种数据源查询数据,包括桌面、LAN、Clint/Server环境;2)从数据库中查询数据,而不需要有专业编程知识;3)生成报表并发布。
Impromptu 是企业级、交互式数据库查询和报表生成工具。
该产品有如下特点:. 信息管理员通过定义Catalog(信息目录)将数据库的数据结构按业务用户的需求和数据访问规则来展现,此类似于数据仓库的数据视图,使用户面对的不是后台复杂的数据结构和技术细节,而是自己熟悉的业务术语、数据结构。
1、基本概念1、全量加载:即在一定过滤条件下一次性加载所有数据,该方式加载速度较慢,但最终形成的cube 的访问效率较高。
2、增量加载:即在一定过滤条件下读取新数据,并将新数据堆积在原有立方体上。
该方式加载速度较快,但最终形成的cube 的访问效率会逐渐变低。
3、图形化说明:2、增量加载的重要原则Cognos cube 增量加载是一个反复累积的过程,切记:上一次增量加载之后的mdl 模型文件必须要保存,而且在下一次数据加载之前不要对上次保存之后的mdl 文件做任何改动(包括重新刷新生成各维度的Categories),否则会报TR1901 之类的错误,该类错误目前尚没有解决方法。
3、增量加载的两种基本方式1、Cube Group(虚拟子cube)方式:在模型中添加一个新的Cube 时设置Cube Group 选项,使得最终的Cube 按照日期(也可以是其他维度,选择日期较为常见)进行分区。
该方式将会按Cube Group 设置时所选择的维度生成一批子cube,Cognos将这些子cube用.vcd文件映射到最终的大cube 上面,我们的报表的数据源虽然是这个大cube,但是实际上最终访问的是那些独立存在的以所选维度为名称的子cube。
该方式优点:便于进行cube 增量加载异常的后续处理。
比如说,我们采用该方式增量加载了从年初到5月1日的数据,但5月2日我们发现从4月20 日到25 日之间的数据质量有问题,那么这时就要进行异常处理。
一般方式是:将20100420.mdc~20100425.mdc这6个子cube 删除,然后手工修改iqd文件(添加where 条件将时间限制在4月20 日至25 日),执行增量mdl 模型或者脚本,重新加载这段时间的数据。
该方式下生成的每个子cube 都是独立的,而且都是可以实际访问的,从另一方面来讲,它们都是可以独立生成和处理的。
该方式缺点:占用空间会越来越大,而且会比普通方式大很多倍。
多维报表制作步骤1.配置数据源打开Cognos Impromptu Administrator,出现如下窗口点“Catalog”菜单,选择“Databases”选择数据库类型(这里我们选择Oracle)后点“New Datebase”按钮,会出现现面的窗口在“Logical database name”栏中给我们的数据源取个名字(建议取和实际数据源相同的名字,比如实际数据源是EDW的话,这栏就填EDW)在“SQL *Net connect string”中填上实际数据源的名字,如我们在本地机器上的“tnsnames.ora”文件中有如下内容我们如果要取“EDW”库的内容,那么这一栏就填“EDW”剩下的“Collation Sequence”和“Geteway Type”就不用管了。
完成以上步骤后,我们就可以测试我们的配置是否正确了点“Test”按钮,就会出现要求输入用户名和密码的对话框如果配置成功就会出现下面的窗口否则请检查一下你的数据源的类型、名称、用户名和密码是否正确(以上操作只需要操作一次就可以了,以后就不用再重新配置该数据源了)2.数据源配置成功后,就是开始如何制作多维报表的步骤了在制作多维报表模型之前,先把要用到的集市表和维表列出(这是一种好习惯,希望大家能够坚持这种习惯,呵呵)集市表:SQL> desc TB_B_DM_AM_EXIST_PRD_NUM;Name Type Nullable Default Comments---------------- ---------- -------- ------- ----------------MONTH_ID NUMBER(9) 月份标识LATN_ID NUMBER(9) 本地网标识PRD_ID NUMBER(9) 产品标识URBAN_RURAL_ID NUMBER(9) 城乡标识XCHG_ID INTEGER 管理局标识CUST_MGMT_CHN_ID NUMBER(9) 客户管理渠道标识PRD_NUM NUMBER(12) Y 用户数维表:Tb_b_Dim_Area通过LATN_ID字段和集市表关联Tb_b_Dim_Prd 通过PRD_ID字段和集市表关联Tb_b_Dim_Urban_Rural通过URBAN_RURAL_ID字段和集市表关联Tb_b_Dim_Cust_Mgmt_Chn通过CUST_MGMT_CHN_ID字段和集市表关联下面开始真正介绍如何制作多维报表模型首先为了规范,建议大家先建好相关的文件夹比如说我们这个模型叫“存量用户到达数分析”,那么我们就建一个文件夹,名字就相应的叫“存量用户到达数分析”,并且在这个“存量用户到达数分析”文件夹下另外新建五个文件夹,名字分别取“cat”、“imr”、“iqd”、“mdl”、“mdc”,再在“mdc”文件夹下新建一个文件夹并命名为“bak”(是不是有点麻烦,这也是为了日后的维护方便,嘿嘿),大概情况如下面所显示的那样还是打开“Cognos Impromptu Administrator”,点“Catalog”菜单,选择“New”,出现下面窗口点“Browse”按钮,选择我们刚刚新建的“存量用户到达数分析”文件夹下的“cat”文件夹取个名字同样为“存量用户到达数分析”,保存类型为上图的类型,点保存“Description”栏自己随便想写什么就写什么(懒人的话就什么都不写)“Catalog type”栏选“Persional”“Name”栏选择我们刚开始配置的数据源名注意:上面的单选一定要选“Select tables”否则后果自负(具体为什么自己慢慢想,嘿嘿)完成上述步骤后点“OK”输入数据源库的用户名和密码点“OK”在“Database tables”栏中显示的是数据源库中所有的表空间,我们选择上面用到的表所在的表空间,如下图的“EDA”双击“EDA”就会显示出“EDA”表空间下所有的表,如图所示再次注意:不要在选择“EDA”,没双击后就点“Add”,否则后果还是自负,而且具体为什么也还是自己琢磨好了,现在就可以选中我们的表,然后点“Add”,把表加到右边的“Catalog tables”栏中其中“Create joins”选择“Manually”,直接点“OK”即可,其他的就先别管了,有兴趣的话自己再慢慢研究再点“OK”(什么也别操作,想问为什么,还是那句话――自己慢慢研究)点“File”菜单,选择“New”,出现下面的窗口选择“Simple List”点“OK”(为什么非要选这个?这个问题有点麻烦,这里就不回答了),出现下面的窗口按顺序操作,先点“Tb_b_Dim_Area”前的“+”号选择我们要用到的字段,点那个向右的箭头点“OK”,该表中的数据就会展现在我们的面前名字建议和表的名字相同,如下图析”下的“iqd”文件夹,如下图注意类型选择上面的类型,点“保存”然后“File”-“Close”—“File”-“New”,又出现下面的窗口选择“Simple List”,点“OK”,按照上面处理“Tb_b_Dim_Area”的步骤那样分别把剩下的几个表处理一遍这里要说下在处理集市表“TB_B_DM_AM_EXIST_PRD_NUM”时,处理到下面的这一步骤时点“Filter”选项框,出现下面窗口点“Catalog Columns”出现选择“TB_B_DM_AM_EXIST_PRD_NUM”表的“Month Id”字段,并双击就会出现这样的窗口再双击左侧的“=”,出现双击左侧的“number”出现这时输入“200701”(输入这表示这个模型这次只装载200701月份的数据)点“OK”,就出现下面的界面然后像开始一样保存为“.imr”格式,然后另存为“.iqd”格式即可,现在可以退出整个“Cognos Impromptu Administrator”(估计手都快操作麻木了)3.下面我们要用到另外一个工具打开“PowerPlay Transformer”,出现下面的窗口点“File”-“New”,出现点“下一步”在“Data source type”里选择“Impromptu Query Definition”,然后点“下一步”,析”文件夹下的“iqd”文件夹,其中“iqd”文件夹中的内容应该如下选中“Tb_b_Dim_Area”后如下点“下一步”输入数据源库的用户名和密码后点“Log On”项”)操作,把“存量用户到达数分析”文件夹下“iqd”文件夹下的剩下的几个“.iqd”文件导入到我们的模型中来,完成后应当显示如下然后鼠标右击“Dimension Map”-“Insert Dimension”如下就会出现下面的窗口在“Dimension name”栏我们填上“日期”,并在“Dimension type”选项中选择“Time”,在选中“Dimension type”后,“Time”选项卡就被激活,如下所示(注意:一个模型一般只需要一个维度在“Dimension type”选项中选择“Time”类型)选择“Do not create levels”,点“OK”,返回下面的界面剩下的就别管了(呵呵,帮你们省事了),直接点“确定”然后点开“TB_B_DM_AM_EXIST_PRD_NUM”表,把该表的“Month Id”拖到“日期”维度下完成后应该是这样的双击“Month Id”出现选中“Unique”(这里要说明一下,以后所有维度的最低一层这个都要选上,表示是通过这个字段把集市表和维表关联起来的),选中时会出现下面的提示选“是”然后选中“Time”选项卡,按照下面图片中显示的填写(以下操作请不要问为什么,等你理解了你自然就会知道,嘿嘿)再然后选择“Order By”选项卡点那个“…”,出现点“More>>>”,选择“Month Id”点“OK”再点“OK”“Sort order”选择升序,“Sort as”选择“Numeric”,点“确定”这样一个时间维度就完成了,下面继续其他的维度右击“Dimension Map”-“Insert Dimension”出现按照下面的填写,不要问为什么(怕麻烦)点“确定”然后点开“Tb_b_Dim_Area”度字段下继续不要问为什么,按照下面进行操作(实在是写累了)单击“Label”栏右边的“…”出现点“More>>>”,选择“Latn Name”,如下点“OK”然后选中“Refresh”栏中的“Label”点“Order By”选项卡,选择按照“Latn Id”进行升序排序,具体过程如下点“确定”“地域”维度完成现在来建立“产品”维度,过程如下点“确定”点开“Tb_b_Dim_Prd”表按照下面图片中显示的那样把相关的字段拖到“产品”维度下先对“Prd Id”进行操作(参照上面“Latn Id”的操作),具体过程如下点“确定”对“Level2 Name”进行操作(注意:这里就不用选中“Unique”了,因为这个表已经确定是通过“Prd Id”字段进行关联的)点“确定”然后对“Level3 Name”进行操作,如下点“确定”这里把对“Level4 Name”的操作留给大家,具体可参照上面的“Level2 Name”、“Level3 Name”完成后,我们的产品维度就建立完成再对“渠道类型”维度的建立进行大致的描述一下(不会再像上面那样详细了,下面要靠你们自己的思考了)。
Cognos实战入门下面是对Cognos使用的一些简单工作总结,希望这些文字对Cognos初学者有帮助!1.Cognos体系结构在Cognos的产品体系中,主要包括以下组件:1 Netscape Directory Server功能:为Upfront Server,Enterprise Server,Transformer,Powerplay, Impromptu提供安全验证来源。
2 Cognos Powerplay Enterprise Server功能:提供Cube或报表的Web访问方式3 Cognos Powerplay Transform Server功能:设计Cube模型和生成Cube。
4 Cognos PowerPlay功能:OLAP报表与分析工具(C/S方式分析与展现)5 Cognos Impromptu功能:数据查询和报表制作工具(我们主要用它为Transform提供数据源)6 Impromptu Web Reports功能:Web方式的动态查询报表管理服务2.Cognos安装要点通常情况下,只要严格按照安装文档安装和配置,安装可以顺利完成。
但有时候由于粗心或对文档理解的差异会导致安装配置不当而无法使用。
一般情况下,安装完成后如果出现无法访问的情况,考虑以下因素:1 安装PPES时选择语言时要注意选择双字节语言,一般选择Locales for Simplified Chinese 或者Locales for other Languages.,如果语言选择不恰当,安装完成后配置将会无法完成。
2 安装Netscape Directory 过程中选择端口号时要注意,我成功安装过的是第一个端口号(Directory Server)为389,安装完成后配置的第二个Data Directory Sever的端口号为390。
3 对于7.0以上版本Cognos是通过配置管理器Configuration Manager来进行配置的。
Cognos8开发示例Cube开发示例开发流程:准备业务元数据->生成iqd文件->加载iqd到模型->设计维度/度量->数据处理->生成mdc文件->FM建立数据源(mdc文件)->上传、发布一使用FM制作IQD文件1、打开FM,创建一个新项目,按照向导走;(语言选择:中文(中国))2、新建一个类型为Informix的数据源;点“下一步”,输入数据库相关信息,输入用户ID和密码,测试与数据库的连接是否成功;3、选择刚建好的数据源IQD,点“NEXT“;4、弹出如下框,选择所需要的数据库表/视图;5、去掉“根据主键或外键创建关系”项,点“Import”;『选择生成关系的标准:如果只是把表带过来,只选择关系生成过程中涉及的对象集:(2)』6、把元数据都放到新建的DB TABLE文件夹下便于与新建的query区分开;7、另亦可新建一文件夹,专门存放某一分析主题下的query;8、建立一维度的query;9、选择维度iqd所需的字段;10、选“Filters”标签,添加一条过滤条件;11、可以测试数据是否准确12、选择“理赔类型”后,在属性框内找 Externalize Metho选项,点击按钮,选择iqd类型;此时就可以创建数据包。
13、把刚刚创建的Query Subject选上,接着发布数据包;14、选择本地存放iqd文件的目录;选上Generate the files for externalized query subjects复选框,然后选择,选择要保存的IQD文件的本地路径。
点击。
15、发布成功。
16、到发布的路径查看IQD文件;中间的select语句与用Impormptu Administrator生成的IQD文件不同,有{ }。
所以在语法上与普通的IQD文件select有差异。
二 Transformer做模型1、打开Powerplay Transformer,添加数据源iqd文件;如果出现下图所示的错误:解决方法之一:1)打开impromptu,catalog->database,新建一个名为test的informix数据库连接2)测试连接是否成功,点击“Test”,输入用户名和密码;3)出险如下框表示连接成功。
献给所有cognos新手关于: 基于维度(cube)建立的报表的过滤条件参数解决OR-ERR-021 问题若您已经建立好过滤条件,只要求解决error,请略过第一部分.第一部分:建立维度的过滤条件首先使用Report Studio 打开要加过滤条件的报表.1点击查询资源管理器,要加过滤条件的查询.2 展开要加过滤条件的维度,这里选择的是区划key3将这树状拖入到右边的数据项中,插入层级选择所有层级.4将数据项拖到明细过滤器中,写表达式定义添加参数过滤,验证一下即可.第二部分与前台交互(url方式)若要和前台交互,需以下几个步骤说明:访问的url包括以下url最基本的地址,加上特定的参数.http://<server-name>/cognos8/cgi-bin/cognos.cgi?b_action=xts.run&m=portal/launch.xts若要查看report运行的html需要加以下参数:1ui.tool=CognosViewerui.tool 打开文件的方式,可选CognosViewer/AnalysisStudio2 ui.object= /content/package[@name='pk_ds_yjzs__6']/report[@name='yjzs_rs_2']ui.object 对象的搜索路径(可以在cognos门户->IBM Cognos内容->报表所在文件夹->报表属性->查看搜索路径ID URL 中找到)具体步骤如下:点击cognos内容找到报表所在文件夹点击报表操作中的第一个图标查看属性点击搜索路径id 和URL复制搜索路径3 ui.action=runUi.action 对文件的操作方式run 运行报表,还有其他属性这里不再继续赘述 .4 p_qh=[ds_yjzs__6].[区划key].[区划key].[区划key1]->:[PC].[@MEMBER].[330100]P_qh 指的是传入的参数,与上面表达式中定义的区划相对应,(*千万记得传入的参数需要以p_开头)可以是一个也可以是多个.记得用&分开.因为是基于维度的过滤条件,所以普通的传值,例如P_qh=330100 cognos不会识别,会报错,意外类型的参数值:它只能识别维度内的member,所以,要加的参数应该是这种格式的:[ds_yjzs__6].[区划key].[区划key].[区划key1]->:[PC].[@MEMBER].[330100]它是怎么来的呢? 打开查询,选择加过滤条件的维度数状结构在这里成员中的每一项都是可以加到过滤条件中的,查看的方法,右键点击[区划key],属性,成员唯一名称复制下来也可以选择[区划key]下级的其他成员,例如衢州,5 run.prompt=falseRun.prompt 是否显示提示页面,默认为true显示,这里选为false不显示 .完整url实例:(*参数名称区分大小写切记)http://192.168.1.103/cognos10/cgi-bin/cognos.cgi?b_action=xts.run&m=portal/launch.xts&ui.tool= CognosViewer&ui.object=/content/package[@name='pk_ds_yjzs__6']/report[@name='yjzs_rs_2']&ui.action=run&p_rylx=[ds_ yjzs__6].[区划key].[区划key].[区划key1]->:[PC].[@MEMBER].[330100]&run.prompt=false这里运行报表有一个常见的问题,就是乱码的问题,如果url中有中文字符串,需要进行转码.(记得只对参数值转码即可,千万别把整个url都进行转码了,转换的编码使用utf-8即可)Java中使用.URLEncode.encode()转码即可,其他的还没有试过,有别的事例希望大家share一下.除了url也可以使用表单实现附:当过滤条件可能为多值的时候只需要在url中多传参数即可&p_qh=[ds_yjzs__6].[区划key].[区划key].[区划key1]->:[PC].[@MEMBER].[330100]&p_qh=[ds_yjzs__6].[区划key].[区划key].[区划key1]->:[PC].[@MEMBER].[330300]上面这个问题困扰了我很长时间,在网上提问,搜索也找不到答案,最后贝克汉姆的一个回答帖子给我了启示.现在将解决办法记录下来,希望这个问题不要再困扰更多像我一样的新手们.。
Cognos 8开发之CubeV1.0知识成果简要信息表第一章 Cognos简介1.概述Cognos展现的报表基于统一的元数据模型。
统一的元数据模型为应用提供了统一、一致的视图。
用户可以在浏览器中自定义报表,格式灵活,元素丰富,而且可以通过Query Studio进行即席的开放式查询。
Cognos还具有独特的穿透钻取(roll up和drill down)、切片(slice)和切块(dice)、以及旋转(pivot)等功能,使分析人员、管理人员或执行人员能够从多角度对信息进行快速、一致、交互地存取,从而获得对数据的更深入了解,有效地将各种相关的信息关联起来,使用户在分析汇总数据的同时能够深入到自己感兴趣的细节数据中,以便更全面地了解情况,做出正确决策。
Cognos强大的报表制作和展示功能能够制作/展示任何形式的报表,其纯粹的Web界面使用方式又使得部署成本和管理成本降到最低。
同时Cognos还可以同数据挖掘工具、统计分析工具配合使用,增强决策分析功能。
进行合作,推动以AIX 技术为中心的创新,同时开发、测试和使用各种用于支持AIX 操作系统的新应用和中间件。
2 . Cognos 8 的功能组件介绍:Cognos 8 的功能组件分为服务器端和客户端两部分,服务器端是基于SOA构架的Cognos 8服务,以Web Service的方式接受和处理用户请求;客户端程序是开发人员使用,用于构建CUBE 和Cognos 8元数据的工具,它们分别是:TransFormer 和FrameWork。
用户制作、浏览报表和业务分析都是基于浏览器的,不需要安装插件或客户端,在浏览器端,用户可以访问以下组件:Report Studio 、Query Studio 、Analysis Studio。
同时用户也可以基于Cognos提供的SDK开发应用直接访问Cognos 8 服务。
Cognos 8产品结构图:第二章基础概念的理解在我们利用Cognos来进行Cube的开发中的维度信息的设计的时候,我们必须了解什么是维度,什么是层,什么是类别等。
1 维度Dimension:所谓维度就是用户今后进行分析时所用来分析数据的角度,维度可以典型的地说明谁,什么时间,什么地点一类的问题。
在模型设计中有效维度决定了应用能回答问题的类型。
2 层Level:维度数据逻辑上的等级关系(相当于数据的定位),层次化的维度是按业务的组织结构表达数据的等级关系。
每个维度层的等级规则确定了今天分析的下钻路径。
3 类别Categories:是位于一个维度中层上独立的数据元素(层中数据的具体取值),最底层类别表示每维度中最详细的数据元素。
了解了上面什么是维度,什么是层,什么是类别后。
我们在说下指标和映射关联的知识点。
指标Measure:是用于衡量业务成效的数据。
是用于确定业务操作成功的量化结果,或关键的性能指标。
例如:收入,成本,增减额等。
其Cognos有两种类型的度量。
标准指标和计算指标。
所说的标准指标是指由查询的列指接定义的度量。
计算指标是指通过Transfromer里面的Functuon来对查询的列值进行计算表达式生成。
(备注:在我们通过Transfromer向DataSource中导入数据源的时候,把包含有数据源的指标叫做事实表。
事实表一般包括所有维度最低层代码和指标数据列。
事实表一般是数据量最大,抽取时间最长的表,我们在设计的时候要注意抽取数据的效率。
)标准指标和计算指标的区别:总体来说,对于Cognos transformer来说适当的使用计算来生成计算指标不但可以提高数据事实表的抽取效率,更可以是关系数据库表中减少列数从而降低数据库空间开销和IO开销。
根据以往的开发经验,得出过多的使用计算指标不会对生成立方体带来太大的压力。
在有了以上的基础知识后,让我们来自己利用Cognos下的Transformer和Framework来开发我们自己的Cube。
第三章 IQD生成首先,先说下什么是IQD。
IQD文件全称为Imromptu Query Definition其实质就是包含数据串,列名等信息的SQL语句。
我们还可以自己对生成的IQD文件进行些修改,比如:对里面的字段进行格式化的转换工作等,使得生成的文件更有利于我们使用。
那么该如何创建该文件呢?这就要使用Framework。
Framework是元数据模型工具。
元数据模型是对数据源的业务描述。
你的数据源可以是数据库也可以是任何支持Congos Cube的数据源。
第1步:在开始菜单中的程序---Cognos 8---Framework Manager 双击打开后。
你可以打开最近访问的工程,也可以自己New Create Project ,输入名称如下:然后点击OK,接着NEXT,到如下图:Select Data Source若是你新安装的Framework或者是里面没有你当前需要的数据源,那么你可以点击NEW到如图:输入数据源的名称,例如:Measureskey。
点击NEXT 到如下图:在Type里面选择Composite(ODBC),(前提是你在连接数据库的时候使用的计算机本机上带的ODBC数据源。
)然后,继续的NEXT到如下图:在ODBC data source中输入你在服务器上配置好的数据源名称,点击下面的Test Connection 进行配置的测试,若成功的话,点击Finish。
就会在你的数据源列表中出现你刚才创建的数据源Measureskey。
也就能使用了。
若出现测试错误,建议你看下你在ODBC 数据源管理器中创建连接服务器的数据源是否位于系统DSN下。
第二步,根据你引入的数据源导入你需要的TABLE和VIEW,完成数据的导入工作。
整体完成后会出现如下图:也就是说你刚才引入的那些数据库的表和试图就会出现在你的工程里面如上面的图所示。
导入的数据库表我们可以认为是数据库的逻辑层,这时候我们要根据需求对导入的表或者试图进行分析,建立业务层需要的Query Subject 如下图:点击OK后,我们的业务层就算建立完成,但是要生成我们需要的IQD文件,我们还需要注意和更改下面的地方:图1完成Externalize Method 下拉框中iqd的选择。
第三步在Packages包下发布你的IQD文件,选择其保存路径就好了。
到此为止,IQD文件创建成功。
第四章生成Cube当需要生成Cube的时候,我们需要借助于Cognos中的Transformer工具来实现。
其主要的功能:设计多维度的模型和按照其模型把数据中或文件中的数据加载生成多维立方体。
1 引入数据(IDQ文件)在开始菜单中的程序---Cognos 8---Tools—PowerPlay Transformer 双击打开后。
新建多维立方体模型从File—New在里面输入你Model的名称,例如:Measureskey选择引入数据的类型,点下一步。
下图中黑框部分为引入数据类型选择,我们可以选择IQD文件(默认)、csv文件等各种类型文件数据源,绝大部分情况下我们使用IQD文件,用其来直接读取数据库中的表。
选择你创建的IQD文件,并通过数据库的验证。
到此你把你生成的IQD文件作为数据源导入到了Transfromer中接着根据不同的需要把Datasource中的列依次的拖动到Dimenision Map和Measures中去,实现划分。
接着在PowerCubes窗口中右键单击选择Insert PowerCube,选择一个磁盘路径作为立方体保存路径。
立方体加载后会是以mdc文件名作为结尾的一个文件。
以后我们所进行的数据分析都直接访问这个数据文件。
生成立方体:选择工具栏上的Create PowerCubes.然后Cognos Transformer会首先依次从Data Sources读取基础数据,再排列、合并、计算、插入生成多维立方体。
生成结束后,我们可以直接在系统双击开始这个多维立方体文件,至此您的第一个多维分析立方体就已经生成好了。
大家慢慢会发现Cognos Transformer本身的使用难度不大,多维分析中真正的设计难点在于底层数据结构设计、多维模型同业务问题的结合以及平衡查询效率同数据访问范围的矛盾。
第五章发布Cub发布一个Cube步骤打开Cognos FrameWork,新建一个Project1选择Data Source下一步2选择一个已经建好的Cube数据源,也可以新建一个Cube数据源。
我们新建一个数据源,按New3下一步,数据源名称,下一步4类型选择Cognos PowerCube,下一步5如果你的服务器是Windows,在Windows路径上输入Windows服务器上的Cube的路径,在FrameWork所在机器上相同路径下也要有这个cube;如果你的服务器是Unix,在Windows 路径上输入FrameWork所在机器上的Cube路径,在Unix服务输入Unix服务器下得路径,完成6输入Package名称,下一步7完成8提示你是否发布这个Package,Yes发布完成后,你就可以通过浏览器用Report Studio、Query Studio 来完成你需要的展现效果。
第六章常见问题及注意事项 1 注意事项:1.在利用Framework创建IQD文件的时候需要更改其对应的属性值为iqd。
2.在利用Transformer引入数据源的时候,所使用的Datasource必须和你在Framework中创建的相同。
3.在你生产Cube的时候,你本地的存放路径必须与你在服务器上Cube保存的路径相同,那样子在发布的时候,才能找到。
不同的操作系统还有区别。
4.区分下生成Cube时保存为不同格式的区别。
*.Mdc格式的文件可以在不同的操作系统上进行移植,而*.Pyi格式的缺不能,因为它是以二进制的形式存放的。
2常见问题集锦:在transformer中说可以用drill-through钻取到其他cube或impromptu报表中,这到底是什么意思,有什么用啊?谁能举个使用的例子?也就是说可以从统计数据链接到所对应的详细数据表中。
例如在对产品销售增长情况的统计分析中,分析者看到某地区在某天的某个产品销售增长很高,他还想看看对应的这个产品的具体单价和功能等情况的话,就要用到drill-through钻取到impromptu 做的详细报表中的数据。
transformer里的计算类别不能自动分组,总是需要手动的分组。
比如:计算列别使用了share函数,share的值总是在实际类别的下面,需要手动的去拖,即使手动的拖好了,可是如果实际类别有增加,share类别又需要去拖放,很郁闷的事情;(有其他方法,琢磨一下)3.怎样控制数据向上汇聚?数据清理后有一个主表和从表,主表数据和从表数据都要向上汇聚,但是主表应该在从表汇聚之后达到一定层次在汇聚,我不知到在transformer中怎样设定?我想了一个办法,就是主从表分别建立一个数据源4.关于虚拟cube虚拟cube实际上有点像数据库中的视图,你可以按照天,月,年等来构建虚拟cube. 比如2003年你是按照月来建立虚拟cube,那么在你存放cube的目录下将有12个cube文件,对应着12个月的cube 数据.如果你要更新3月份的数据,那么利用cognos 的虚拟cube的机制,它只会去更新对应着3月份的cube数据的那个cube文件.这样就比较方便,而且维护起来会比较好.5.净增量的展现的实现?在报表展现时,需要体现本月份与上月份或当天与昨天的某度量的变化量即净增量,请问该如何实现呢?解决了!是在时间类别里加一个计算类,取函数change()或直接‘当月’-‘上月’.总结通过对上面Cube的基础知识和例子的说明,使得自己更加的清创建和使用Cube的过程,也搞清楚了里面些细节上的问题。