SAS随机分组方法及实现
- 格式:docx
- 大小:54.98 KB
- 文档页数:20

机化原则进行随机分组。
2. 方法:(1) 抽签法或投币法。
(2) 随机数字表法(random number table)---随机数字表法只有在样本数量足够大时,才能做到二组例数相等或相近,常用于大样本的临床试验流行病学调查研究。
(3) 随机化区组方法(randomized blocks)---小样本随机化区组是临床随机对照试验中常用的随机化方法,其优点是试验组与对照组可以病例数分配相等,并在多中心试验时,每个中心可有各自的随机化区组。
<1>一般的随机区组设计:---适用于病人条件相似、要求两组病例数相等时。
通过随机数字表中的数字或区组随机表随机分配。
<2> 配对随机区组设计:---配对随机化区组设计不但可以把需要观察比较的内容有计划地进行配对,还可以把一些比较复杂的情况分层配对。
因此,配对随机区组设计己被公认为目前临床试验中较好的方法并广泛应用。
随机数字卡的应用:---临床试验中通过随机化方法将受试者按试验要求进行分组,具体实施则要借助随机数字卡。
1. 随机数字卡在随机对照试验中的应用(1) 在SAS软件系统中进行随机分组:---包括序号和随机码,序号从1开始,比如试验单位承担60例病例,试验组与对照组各30例,那么序号即从1到60。
随机码通常由A、B、C…等英文字母代表,实施中要设置随机码代表的组别,如A为试验组,B为对照组。
(2) 随机数字卡由信封加封,信封上的编号与随机数字卡上的序号相同。
(3) 临床试验开始后,按照受试者进入观察的顺序拆开号码相同的信封,按照随机数字卡上的随机码确定受试者是服用试验药还是对照药。
2.随机数字卡在随机对照盲法试验中的应用随机数字卡在随机对照盲法试验中的应用基本同随机对照试验,由于盲法试验中涉及到试验药与对照药的特殊制备问题,试验药与对照药除编号不同外,外观完全一致,因此,随机数字卡在盲法试验中的应用与随机对照试验中又有所不同。
(1) 盲法试验中要根据随机数字表将试验药与对照药编号。

随机分组方法包括« 简单随机化(SimPIe randomizatiOn)« 区组随机化(block randomization)・分段(或分层)随机化(Stratified randomization)・分层区组随机化(Stratified block randomization)« 动态随机化(dynamic randomization)一、简单随机化,又称完全随机化1、定义:在事先或者实施过程中不作任何限制和干预或调整,对研究对象直接进行随机分组。
通常,通过掷硬币、随机数字表、计算机产生随机数来进行随机化。
2、适用条件:在研究例数较少、总体中个体差异较小时,采用此法。
3、缺点:在研究对象例数较少时,由于随机误差难以保证组间病例数的均衡,各组例数可能会出现不平衡现象。
4、解决办法:随机数表法、随机数余数分组法。
随机数余数分组法的具体操作: 编号:研究对象(动物按体重大小、患者按预计样本量编号)从1 到N 编号;获取随机数字:从随机数字表中任意一个数开始,沿同一方向顺序每个研究对象对应取一个随机数字;求余数:随机数除以组数求余数。
若整除,则取组数作为余数;分组:按余数数值分组;调整:假如某组待调整,该组共有n 例。
从中抽取1 例,就取下一个随机数,随机数除以n 。
除以n 的余数(若整除则余数为n )作为在该组中所抽研究对象的序号,调整到其他组。
例1-1 :两组对心脑病区观察20例(编号1〜20)心血管病患者分为2组,一组以灯盏花注射液为治疗组,另一组给予瓜蒌薤白汤。
从随机数字表任一行开始(以第11行第1个数(57)计),按序查找,凡小于或等于20 的数标记,查够10个数;将与这10 个数对应编号患者列为一组,余下患者为另一组第一组:9, 10 , 4, 6, 15, 20,11 ,12 , 3, 7;第二组:1 , 2 ,5, 8, 13 , 14 , 16 , 17, 18, 19。

SPSS随机分组操作步骤SPSS(19.0)随机分组操作步骤1.输入原始数据纵向输入原始数据,包括原编号、分组依据的变量,变量列降序排列(Sort Descending)。
2.生成随机种子转换(Transform)→随机数字生成器(Random Number Generators)勾选“活动生成器初始化(Active Generator Initialization)”中的“设置起点(Set Starting Value)”,选中“固定值(Fixed Value)”,默认2,000,000,单击“确定(OK)”。
3.生成随机数字转换(Transform)→计算变量(Compute Variable)目标变量(Target Variable):random函数组(Function Group):随机数字(Random Number)函数和随机变量(Functions and Special Variables):Rv.Uniform,双击选中数字表达式(Numberic Expression):RV.UNIFORM(1,100)→单击“确定(OK)”。
4.输入分组后新编号假设分为a个组,每组n个样本,输入a个1,a个2,……a个n。
5.分组转换(Transform)→个案排秩(Rank Cases)变量(Variable(s)):random排序标准(By):新编号列将秩1指定给(Assign Rank 1 to )“最大值”(Largest value)→单击“确定(OK)”。
“Rrandom”列升序排列(Sort Ascending)。
“Rrandom”列即分组后的组别,“新编号”列即分组后的编号。

SAS数据分析常用操作指南在当今数据驱动的时代,数据分析成为了企业决策、科学研究等领域的重要手段。
SAS 作为一款功能强大的数据分析软件,被广泛应用于各个行业。
本文将为您介绍 SAS 数据分析中的一些常用操作,帮助您更好地处理和分析数据。
一、数据导入与导出数据是分析的基础,首先要将数据导入到 SAS 中。
SAS 支持多种数据格式的导入,如 CSV、Excel、TXT 等。
以下是常见的导入方法:1、通过`PROC IMPORT` 过程导入 CSV 文件```sasPROC IMPORT DATAFILE='your_filecsv'OUT=your_datasetDBMS=CSV REPLACE;RUN;```在上述代码中,将`'your_filecsv'`替换为实际的 CSV 文件路径,`your_dataset` 替换为要创建的数据集名称。
2、从 Excel 文件导入```sasPROC IMPORT DATAFILE='your_filexlsx'OUT=your_datasetDBMS=XLSX REPLACE;RUN;```导出数据同样重要,以便将分析结果分享给他人。
可以使用`PROC EXPORT` 过程将数据集导出为不同格式,例如:```sasPROC EXPORT DATA=your_datasetOUTFILE='your_filecsv'DBMS=CSV REPLACE;RUN;```二、数据清洗与预处理导入的数据往往存在缺失值、异常值等问题,需要进行清洗和预处理。
1、处理缺失值可以使用`PROC MEANS` 过程查看数据集中变量的缺失情况,然后根据具体情况选择合适的处理方法,如删除包含缺失值的观测、用均值或中位数填充等。
2、异常值检测通过绘制箱线图或计算统计量(如均值、标准差)来检测异常值。
对于异常值,可以选择删除或进行修正。
3、数据标准化/归一化为了消除不同变量量纲的影响,常常需要对数据进行标准化或归一化处理。

SAS随机分组方法及实现随机分组方法包括:•简单随机化(simple randomization)•区组随机化(block randomization)•分段(或分层)随机化(stratified randomization)•分层区组随机化(stratified block randomization)•动态随机化(dynamic randomization)一、简单随机化,又称完全随机化1、定义:在事先或者实施过程中不作任何限制和干预或调整,对研究对象直接进行随机分组。
通常,通过掷硬币、随机数字表、计算机产生随机数来进行随机化。
2、适用条件:在研究例数较少、总体中个体差异较小时,采用此法。
3、缺点:在研究对象例数较少时,由于随机误差难以保证组间病例数的均衡,各组例数可能会出现不平衡现象。
4、解决办法:随机数表法、随机数余数分组法。
随机数余数分组法的具体操作:编号:研究对象(动物按体重大小、患者按预计样本量编号)从1 到N 编号;获取随机数字:从随机数字表中任意一个数开始,沿同一方向顺序每个研究对象对应取一个随机数字;求余数:随机数除以组数求余数。
若整除,则取组数作为余数;分组:按余数数值分组;调整:假如某组待调整,该组共有n 例。
从中抽取1 例,就取下一个随机数,随机数除以n。
除以n 的余数(若整除则余数为n )作为在该组中所抽研究对象的序号,调整到其他组。
例1-1:两组对心脑病区观察20例(编号1~20)心血管病患者分为2组,一组以灯盏花注射液为治疗组,另一组给予瓜蒌薤白汤。
从随机数字表任一行开始(以第11行第1个数(57)计),按序查找,凡小于或等于20的数标记,查够10个数;将与这10个数对应编号患者列为一组,余下患者为另一组。
57 35 27 33 72 24 53 63 94 09.4110 . 76 47 91 4404.95 49 66 39 6004 . 59 81 48 50 86 54 48 2206.3472 52 82 21 15.6520.33 29 94 7111 . 15.91 2912.03.61 96 48 9503.07第一组:9,10,4,6,15,20,11,12,3,7;第二组:1,2,5,8,13,14,16,17,18,19。

随机分组的具体方法
随机分组是一种常见的研究方法,用于将参与者随机分配到不同的实验组,以便比较不同实验组之间的差异。
具体实现随机分组的方法有以下几种:
1. 简单随机分组:将参与者按照编号或其他随机指标分配到不同实验组中,确保每个组的参与者数量相同或尽可能接近。
2. 分层随机分组:根据参与者的特定属性(如性别、年龄、教育程度等)进行分层,然后在每一层内进行简单随机分组,以确保各组之间的差异不是由于这些属性的不同造成的。
3. 区组随机分组:将参与者按照不同的地理区域或其他特定属性进行分组,然后在每个区组内进行简单随机分组,以确保各个区组之间的差异不会影响实验结果。
4. 交叉随机分组:将参与者随机分配到各种实验组合中,以便比较不同实验因素之间的交互作用。
以上方法都可以通过计算机程序或抽签等方式进行实现,但需要注意的是,在随机分组过程中要确保随机性和公正性,以避免实验结果的偏差。
- 1 -。

SPSS详细教程:轻松实现随机分组我们常常把随机分组挂在嘴边,好像只要⼀提到随机化,整个研究就能提升⼀个level。
但是在实际的研究过程中,很多研究者并不知道怎么才能正确的实现随机分组。
所以,⼩咖决定⼿把⼿来教⼤家如何通过SPSS,轻松实现随机分组。
随机分组随机分组,就是将参加研究的受试对象,按照随机化的原则,分配到不同处理组的过程。
随机分组可以保证每⼀个受试者均有相同的机会被分配到试验组或对照组,使得⼀些可能影响试验结果的临床特征和⼲扰因素在组间分配均衡,具有较好的可⽐性。
结果不受⾮处理因素的⼲扰和影响,从⽽有效避免了各种⼈为的客观因素和/或主观因素对研究结果产⽣的偏倚,使结果更加真实可靠。
随机分组的基本思路尽管随机分组看上去⾮常简单,但是在临床试验的具体操作过程中,往往会被误解和误⽤。
例如有研究⼈员按照研究对象的⼊组顺序,把受试者交替纳⼊试验组和对照组,这种分组⽅法很容易被误认为是随机分组,但实际上当前⼀个研究对象的分组被确定时,也就决定了下⼀个研究对象的分组,因此⽆法保证研究对象有相同的机会进⼊不同的处理组。
那么⼀般⽤什么⽅法实现随机分组呢?随机分组可以采⽤抽签、掷硬币或掷骰⼦等⽅法,但更科学、更可靠的是使⽤随机数字来进⾏分组,其基本思路为:1. 对临床试验中纳⼊的每⼀研究对象产⽣⼀个对应的随机数字;2. 按照随机数字由⼩到⼤(或由⼤到⼩)的顺序进⾏排序;3. 根据事先设定的各个处理组样本量⼤⼩,按随机数字顺序选择相应的样本数量,分配到不同的处理组。
在临床试验中,研究对象往往是陆续⼊组的,研究者不可能要等到研究对象都收集⾜够的时候,再分组进⾏试验,所以⼀般在研究开始前,要事先按照研究对象的⼊组顺序,根据对应的随机数字将研究对象随机地分配⾄不同的处理组,并做好分组隐匿。
⼀旦研究对象符合⼊选条件纳⼊研究时,就可以根据事先确定好的分组⽅案,直接进⼊对应的分组开始试验。
随机分组SPSS操作⼀、研究实例假设某研究拟纳⼊330名研究对象,按照研究对象⼊组顺序进⾏编号,研究对象⼊组后被随机分配到A、B、C三组给予不同的治疗措施,其中A为安慰剂组,B为常规⽤药组,C为联合⽤药组,每组各110⼈。

SAS分组与排序SAS 分组与排序SAS对数据集进⾏操作时,经常需要在SET、MERGE、MODIFY或 UPDATE语句中使⽤分组数据。
使⽤分组数据最基本的⽅法是使⽤BY 语句,其基本形式如下:BY 变量列表;BY语句除了可⽤于DATA步中对数据集进⾏操作外,也可以⽤于 SAS PROC步。
在这些地⽅使⽤分组数据时,要求所有的观测必须按BY 语句中的变量以数字或字符顺序升序或降序排列,或者以某种⽅式分组,例如以⽇历的⽉份或格式化后的值为条件进⾏分组。
如果数据不满⾜这个条件,可使⽤SORT过程对其进⾏排序分组。
1.使⽤SORT过程对观测进⾏排序使⽤SORT过程的基本形式如下:PROC SORT DATA=输⼊数据集 <OUT=输出数据集> <其他选项>;BY 变量列表;RUN;·输⼊数据集指定需要排序的数据集。
·变量列表指定排序变量,可以是⼀个变量或多个变量。
当指定多个变量时,SAS⾸先会按照第⼀个变量分组,然后在同⼀个分组内依照变量列表中的其他变量逐个进⾏排序。
·选项OUT=指定存储排序后数据的新数据集。
当该选项不存在时,排序⽣成的数据写⼊由选项DATA=指定的数据集。
输出数据集可以和输⼊数据集相同,不过此时会覆盖输⼊数据集。
当输出数据集与输⼊数据集不同时,会创建新数据集。
·还可以指定其他选项。
默认情况下,SAS根据BY变量的值升序排列分组。
对公司员⼯先按照部门(Dept)名称进⾏排序,在同⼀部门⾥按照⼊职⽇期(Entry_Date)进⾏排序。
公司员⼯所在数据集saslib.employee的部分数据如图3.13所⽰。
该数据集包含员⼯编号、姓名、所在部门、职位和⼊职年份。
使⽤SORT过程对该数据集进⾏排序时,在BY语句中先后指定排序的变量Dept和Entry_Date。
proc sort data=saslib.employee out=saslib.employee_sorted;by Dept Entry_Date;run;2.使⽤选项DESCENDING对观测按变量降序排序在BY语句中,还可以在每个变量之前指定选项DESCENDING对变量进⾏降序排序,或者根据需要对部分变量进⾏升序排序、部分变量降序排序。

精品文档随机分组方法包括:简单随机化(simple randomization) ?区组随机化(block randomization)?分段(或分层)随机化(stratified randomization) ?分层区组随机化(stratified block randomization) ?动态随机化(dynamic randomization)?一、简单随机化,又称完全随机化1、定义:在事先或者实施过程中不作任何限制和干预或调整,对研究对象直接进行随机分组。
通常,通过掷硬币、随机数字表、计算机产生随机数来进行随机化。
2、适用条件:在研究例数较少、总体中个体差异较小时,采用此法。
3、缺点:在研究对象例数较少时,由于随机误差难以保证组间病例数的均衡,各组例数可能会出现不平衡现象。
4、解决办法:随机数表法、随机数余数分组法。
随机数余数分组法的具体操作:精品文档.精品文档编号:研究对象(动物按体重大小、患者按预计样本量编号)从1 到N编号;获取随机数字:从随机数字表中任意一个数开始,沿同一方向顺序每个研究对象对应取一个随机数字;求余数:随机数除以组数求余数。
若整除,则取组数作为余数;分组:按余数数值分组;调整:假如某组待调整,该组共有n 例。
从中抽取1 例,就取下一个随机数,随机数除以n。
除以n 的余数(若整除则余数为n )作为在该组中所抽研究对象的序号,调整到其他组。
例1-1:两组对心脑病区观察20例(编号1~20)心血管病患者分为2组,一组以灯盏花注射液为治疗组,另一组给予瓜蒌薤白汤。
从随机数字表任一行开始(以第11行第1个数(57)计),按序查找,凡小于或等于20的数标记,查够10个数;将与这10个数对应编号患者列为一组,余下患者为另一组。
精品文档.精品文档094157 35 27 33 72 24 53 63 94.04106076 47 91 4495 49 66 39..06043459 81 48 50 86 54 48 22..20157172 52 82 2133 29 9465..0312********91 2961 96 48 95.....,5,7;第二组:1,2126,,15,20,11,,3,10第一组:9,,4。

简单随机抽样的SAS实现1 SURVEYSELECT 过程该过程提供了很多方法,用于基于概率的随机样本的选择。
基本命令语句如下:Proc surveyselect data=<SAS-data-set>method=srs n=<samplesize>out=<SAS-data-set>seed=number;run;n是指抽样样本量。
SEED指定一个W2**31-1的正整数,用该值作为随机数发生器的初始数值,以便在下次运行该程序时得到的结果不变。
举例:在1000个数据中随机抽取100个。
Data a;Do i= 1 to 1000;output;end;run;/*产生1-1000共1000个数字*/proc surveyselect data=a method= srs n=100 out=bseed=25070419;run;proc print data=b;run;备注:(1),如果没有指定随机数种子(seed),则SAS程序会使用计算机的时间作为种子。
可以使用seed选项设定随机数初始种子。
Seed的值必须是一个正整数,否则SAS会使用计算机的时间作为种子(零或负整数的情况),或者出错(小数的情况)。
(2).如果我们只需要保留其中的某几个字段,则可以使用id语句。
(3)在实际应用场景中,有时候需要独立重复抽取多组样本,这时可以使用rep选项。
SAS程序会以rep设定的值独立重复抽取若干次样本,每组样本的容量是sampsize或n选项指定的值。
(4)样本容量的另一种表述是其占总体的比例。
比如,抽取10%的样本。
这时我们使用samprate或rate替代sampsize。
Samprate的值可以是正小数,也可以是正整数。
当samprate的值是正小数时,其值在(0, 1]之间,不可为零;为1时表示100%。
当samprate是正整数时,表示相应的百分比,如10表示10%,需要注意的是,整数1表示100%,而不是1%。
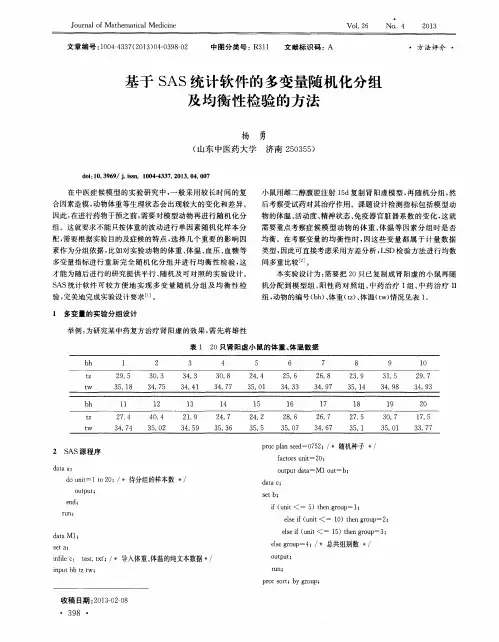
最小化随机分组方法介绍及其SAS实现赵丽君;李宏田;段蜚藩;廖紫珺;周玉博;刘建蒙【摘要】目的介绍最小化随机分组方法的基本原理及运算过程,编制专用的SAS 宏程序. 方法通过文献查阅,综述最小化法的基本原理及其运算过程.依照运算过程,结合模拟实例,编制专用的SAS宏程序,并给出模拟实例的分组结果. 结果最小化法作为一种动态随机分组方法,依据已入组病例重要预后因素组间分布情况,动态确定新入组病例的分配概率,最大限度保障重要预后因素组间分布均衡.它根据因素不平衡函数、总体不平衡函数和最优分配概率三个参数确定病例的分组,实施过程相对繁复是限制其应用的一个重要方面.通过编制SAS宏程序,可提高最小化法的分组效率. 结论最小化法适用于小样本、基线特征复杂的临床试验,SAS宏程序能简化实施过程,有利于最小化法的应用.%Objective To introduce the basic principle and operation process of minimization,and compile a customized SAS macro program.Methods Through literature review,the basic principle and operation process of minimization were summarized.By using a simulation example,we introduced a customized SAS macro program of minimization,and the results of allocation for the simulation example were provided.Results As a dynamic randomization method,minimization assigned the next patient into treatment groups with dynamic probability which depended on the balance of some prognostic factors,in order to achieve well-balanced groups.The assignment depended on three functions:the factor level imbalance function,the total imbalance function,and the optimal allocation probabilities.Although the method of minimization has advantages compared with other methods ofrandomization,its application has been limited probably because of the relatively complicated implementation procedure.As demonstrated by the simulated example,the utilization of minimization could be simplified by using the customized SAS macro.Conclusion Minimization was a method suitable for clinical trials with small sample and complex baseline characteristics.The SAS macro program could simplify the implementation process and facilitate the application of minimization.【期刊名称】《中国生育健康杂志》【年(卷),期】2018(029)002【总页数】5页(P101-105)【关键词】最小化法;随机分组方法;临床试验;SAS宏【作者】赵丽君;李宏田;段蜚藩;廖紫珺;周玉博;刘建蒙【作者单位】100191 北京,北京大学生育健康研究所/卫生部生育健康重点实验室;北京大学公共卫生学院流行病与卫生统计学系;100191 北京,北京大学生育健康研究所/卫生部生育健康重点实验室;北京大学公共卫生学院流行病与卫生统计学系;100191 北京,北京大学生育健康研究所/卫生部生育健康重点实验室;北京大学公共卫生学院流行病与卫生统计学系;100191 北京,北京大学生育健康研究所/卫生部生育健康重点实验室;北京大学公共卫生学院流行病与卫生统计学系;100191 北京,北京大学生育健康研究所/卫生部生育健康重点实验室;北京大学公共卫生学院流行病与卫生统计学系;100191 北京,北京大学生育健康研究所/卫生部生育健康重点实验室;北京大学公共卫生学院流行病与卫生统计学系【正文语种】中文随机分组主要目的是保证临床试验组间基线特征分布均衡,以最大限度控制干扰因素影响,更科学地估计干预效应。
随机化临床试验及随机化的SAS实现-中国临床试验与研究网从科学的观点来看,临床试验中有足够样本含量的随机化、对照、盲法临床试验是最理想的研究设计。
不采用随机化和盲法设计,当临床医生对某种疗法偏爱或厌恶时,会有意无意地影响试验效应的判定,甚至剔除某些对象或改变对象处理安排,给试验带来偏倚,难以保证结果的可靠性。
目前临床试验中最多采用的是多中心、随机、对照、平行、双盲试验。
随机化保证了研究对象有相同的机会进入处理组或对照组,但并不是所有的随机化方案都是等效的。
有些研究人员自称的随机方案其实并不是真正的随机,不能有效地控制偏倚。
一些时有报道使用的交替分配、表格号码(奇或偶)或出生日期等分配方法,貌似随机,可能并未真正随机。
这些方法会潜在影响分配决定,因为负责分配病人的调研人员可能会事先知道下一个处理是什么,从而决定病人是否进入研究或根据自己对处理的偏好来分配病人;另外,这样的分配有时还会和病人自身的某些规律暗合,因而这些都不是真正的随机方案。
洗牌、抛硬币等方法尽管是随机的,但不能检查或重复。
使用随机数字表、随机排列表是很好的方法,因为表中的数字是经过随机产生后定下来的,因此可以重复,但较为麻烦,对于样本量较大的临床试验,也很费时。
在目前计算机应用非常普及的情况下,用统计软件中的随机化功能,事先给出种子数,进行随机化,既简单,又可重复,符合随机化要求,应予提倡。
本文介绍用SAS系统实现临床试验随机化的方法,并兼论随机化试验的盲法及伦理问题。
1 简单随机化可采用SAS系统的PROC PLAN SEED=n过程或UNIFORM(n)函数来实现。
例1:对120例病人随机分成两个等比例组,使每组为120例。
1.1 用PROC PLAN过程进行随机化用PROC PLAN过程实现两组等比例随机化的SAS程序见程序1。
程序1 用PROC PLAN过程实现两组等比例随机化的SAS程序:PROC PLAN SEED=210002;FACTORS n=240; OUTPUT OUT=aaa;DATA bbb; SET aaa; number=_n_;IF n<=120 THEN group='A';ELSE group='B';PROC PRINT NOOBS;VAR number group;RUN;程序1所列程序先在PROC PLAN语句中给定种子数SEED,本例为210002,通过FACTORS产生1~240之间随机排列的数列,并将结果输出至aaa数据集中,然后用条件语句产生以n为条件的分组结果A和B。
随机分组方法包括:∙简单随机化(simple randomization)∙区组随机化(block randomization)∙分段(或分层)随机化(stratified randomization)∙分层区组随机化(stratified block randomization)∙动态随机化(dynamic randomization)一、简单随机化,又称完全随机化1、定义:在事先或者实施过程中不作任何限制和干预或调整,对研究对象直接进行随机分组。
通常,通过掷硬币、随机数字表、计算机产生随机数来进行随机化。
2、适用条件:在研究例数较少、总体中个体差异较小时,采用此法。
3、缺点:在研究对象例数较少时,由于随机误差难以保证组间病例数的均衡,各组例数可能会出现不平衡现象。
4、解决办法:随机数表法、随机数余数分组法。
随机数余数分组法的具体操作:编号:研究对象(动物按体重大小、患者按预计样本量编号)从1 到N 编号;获取随机数字:从随机数字表中任意一个数开始,沿同一方向顺序每个研究对象对应取一个随机数字;求余数:随机数除以组数求余数。
若整除,则取组数作为余数;分组:按余数数值分组;调整:假如某组待调整,该组共有n 例。
从中抽取1 例,就取下一个随机数,随机数除以n。
除以n 的余数(若整除则余数为n )作为在该组中所抽研究对象的序号,调整到其他组。
例1-1:两组对心脑病区观察20例(编号1~20)心血管病患者分为2组,一组以灯盏花注射液为治疗组,另一组给予瓜蒌薤白汤。
从随机数字表任一行开始(以第11行第1个数(57)计),按序查找,凡小于或等于20的数标记,查够10个数;将与这10个数对应编号患者列为一组,余下患者为另一组。
第一组:9,10,4,6,15,20,11,12,3,7;第二组:1,2,5,8,13,14,16,17,18,19。
例1-2:多组(≥3组)将15名血栓性血瘀证患者分为3组。
第一次分组后,甲组6例,乙组5例,丙组4例。
随机分组方法随机分组方法是指在一定的条件下,通过随机的方式将对象或者数据分配到不同的组别中。
这种方法通常用于科学实验、调查研究、抽样调查等领域,以确保分组的公平性和代表性。
在实际应用中,随机分组方法有多种形式,包括简单随机分组、分层随机分组、整群随机分组等。
简单随机分组是最基本的一种随机分组方法,其原理是根据一定的概率分布,将对象或者数据随机地分配到不同的组别中。
这种方法通常适用于样本量较小、分组要求较为简单的情况。
在实际操作中,可以利用随机数发生器或者抽签的方式进行简单随机分组,以确保每个对象或者数据被平等地纳入到各个组别中。
分层随机分组是在简单随机分组的基础上,根据对象或者数据的某些特征进行分层,然后在每个层次内进行简单随机分组。
这种方法可以有效地控制各个组别的代表性,确保样本的多样性和均衡性。
在实际应用中,可以根据不同的特征,如年龄、性别、地区等,将对象或者数据进行分层,然后再进行简单随机分组,以满足实验或者调查的需要。
整群随机分组是将对象或者数据按照一定的特征进行分群,然后再对整个群体进行随机分组。
这种方法常常用于实验或者调查对象较为庞大、分组要求较为复杂的情况。
在实际操作中,可以先将对象或者数据按照某种特征进行分群,然后再对每个群体进行简单随机分组,以确保每个群体内部的均衡性和代表性。
在进行随机分组时,需要注意以下几点,首先,确保随机分组的过程是公平、公正的,避免出现人为干预或者偏向某一组别的情况;其次,要根据实际情况选择合适的随机分组方法,确保分组的合理性和有效性;最后,要对随机分组的结果进行统计分析,评估分组的质量和代表性,以确保实验或者调查的科学性和可靠性。
总之,随机分组方法在科学实验、调查研究等领域具有重要的意义,能够有效地确保分组的公平性和代表性。
在实际应用中,我们可以根据具体情况选择合适的随机分组方法,并严格执行分组的过程,以确保实验或者调查的结果具有科学性和可信度。
随机分组方法包括:∙简单随机化(simple randomization)∙区组随机化(block randomization)∙分段(或分层)随机化(stratified randomization)∙分层区组随机化(stratified block randomization)∙动态随机化(dynamic randomization)一、简单随机化,又称完全随机化1、定义:在事先或者实施过程中不作任何限制和干预或调整,对研究对象直接进行随机分组。
通常,通过掷硬币、随机数字表、计算机产生随机数来进行随机化。
2、适用条件:在研究例数较少、总体中个体差异较小时,采用此法。
3、缺点:在研究对象例数较少时,由于随机误差难以保证组间病例数的均衡,各组例数可能会出现不平衡现象。
4、解决办法:随机数表法、随机数余数分组法。
随机数余数分组法的具体操作:编号:研究对象(动物按体重大小、患者按预计样本量编号)从1 到N 编号;获取随机数字:从随机数字表中任意一个数开始,沿同一方向顺序每个研究对象对应取一个随机数字;求余数:随机数除以组数求余数。
若整除,则取组数作为余数;分组:按余数数值分组;调整:假如某组待调整,该组共有n 例。
从中抽取1 例,就取下一个随机数,随机数除以n。
除以n 的余数(若整除则余数为n )作为在该组中所抽研究对象的序号,调整到其他组。
例1-1:两组对心脑病区观察20例(编号1~20)心血管病患者分为2组,一组以灯盏花注射液为治疗组,另一组给予瓜蒌薤白汤。
从随机数字表任一行开始(以第11行第1个数(57)计),按序查找,凡小于或等于20的数标记,查够10个数;将与这10个数对应编号患者列为一组,余下患者为另一组。
第一组:9,10,4,6,15,20,11,12,3,7;第二组:1,2,5,8,13,14,16,17,18,19。
例1-2:多组(≥3组)将15名血栓性血瘀证患者分为3组。
第一次分组后,甲组6例,乙组5例,丙组4例。
由于各组例数不等,须将甲组调整1例到丙组。
因此,继续查随机数字表,下一个随机数字为58。
由于58/6=9……4,甲组中第4个研究对象调整到丙组。
5、SAS实现对20例病人随机分成两个等比例组,使每组为10例。
方法一:PROC PLAN SEED=n 过程。
PROC PLAN SEED=210000;FACTORS n=20;OUTPUT OUT=patient;RUN;DATA result;SET patient;number=_n_;IF n<=10 THEN group='A';ELSE group='B';RUN;PROC PRINT data=result NOOBS;VAR number group;RUN;方法二:UNIFORM(n)函数。
在完全随机化时,UNIFORM函数法结果的平衡性较差。
DATA patient;DO number=1 to 20;r=UNIFORM(210000);OUTPUT;END;RUN;PROC RANK data=patient OUT=rank;RANKS r_rank;VAR r;RUN;DATA result;SET rank;IF r_rank<=10 THEN group='A';ELSE group='B';RUN;PROC PRINT data=result NOOBS;VAR number group;RUN;二、区组随机化,又称均衡随机化、限制性随机化1、定义:将随机加以约束,使各处理组的分配更加平衡,满足研究要求。
在一个区间内包含一个预定的处理分组数目和比例。
区组:由若干特征相似的试验对象组成。
如同一窝的动物、批号相同的试剂、体重相近的受试者等。
区组的长度:区组中对象的数目。
2、优点:区组随机化分组,避免简单随机化分组可能产生的不平衡现象,不仅提高统计学效率,而且保证分配率不存在时间趋势。
3、适用条件:区组的长度不宜太小,太小则形成不随机。
一般区组的长度至少要求为组数的2倍以上。
区组的长度也不宜太大,太大易使分段内不均衡,如果只有两个组别(试验组和对照组),区组的长度一般可取 4~8,如果有4个组别则区组的长度至少为8。
区组长度还与试验的疗程长短有关:对于疗程较短的疾病,患者入组快,结束快,区组长短影响不大,而对于疗程比较长的疾病,区间长度不宜过大。
例2-1 区组随机化分组(两组)以入院时间(月份)作为配伍因素,将入院时间同月相邻的4位患者作为一个区组,试对24名患者分配到A和B两组处理。
确定区组长度和两个组的所有可能排列:设区组长度为4,则A和B两组所有可能的排列为6。
给每种可能排列的区组分配抽样号码:每个区组4名患者的分配方案,如下图所示。
用抽签方法随机排列上述区组分配的号码:查随机数字表任意选择起始数,28、26、08、73、37、32,按照从小到大排序得出上述区组分配的号码为:3、2、1、6、5、4。
将观察单位按事先编好的病例号从1号开始按顺序进入上述抽签后得到的区组号码顺序的各区组。
5、SAS实现对24例病人按区组随机化方法分成两个等比例组,使每组为12例。
方法一:PROC PLAN SEED=n 过程。
PROC PLAN SEED=210000;FACTORS block=6 length=4;OUTPUT OUT=patient;RUN;DATA result;SET patient;number=_n_;IF length <=2 THEN group='A';ELSE group='B';RUN;PROC PRINT data=result NOOBS;VAR number group;RUN;方法二:UNIFORM(n)函数。
DATA random;DO block=1 to 6;DO length=1 to 4;r=UNIFORM(210000);OUTPUT;END;END;RUN;DATA patient;SET random;number=_n_;RUN;PROC RANK DATA=patient OUT =rank;RANKS r_rank;VAR r;BY block;RUN;DATA result;SET rank;IF r_rank <=2 THEN group='A';ELSE group='B';RUN;PROC PRINT DATA=result NOOBS;VAR number group;RUN;三、分层随机化分组1、定义:首先根据研究对象进入试验时某些重要的临床特征或危险因素分层,如年龄、性别、病情、疾病分期等;然后在每一层内进行随机分组,最后分别合并为试验组(处理组)和对照组。
2、优点:分层随机化可保证减小Ⅰ型错误,并且可以提高小样本(<400)试验的把握度。
3、适用条件:只适合于有2~3个分层因素,分层因素较多容易出现不均衡的情况。
文献报道,通常受试对象在100~200例之间,2~3个分层因素,每个因素仅有2个水平时,应用分层随机化较恰当;当分层因素较多时各层所含的例数会变少,容易出现各组分层因素分布和组间例数的不均衡,影响分析结果。
分层随机化分组的具体操作:将分组过程分多个层进行,每个层有m个试验对象。
m必须是层数的整倍数,为了保证随机效果,m最好是层数的5倍以上;取m个随机数从小到大排序,得序号R;规定R所对应的处理,如10位患者等分为两组,则R1~5为A组,R6~10为B组;将m个观察对象分配完毕以后,再按以上方法对下一层m个观察对象分组,直到分组结束。
例3-1 分层随机化分组(两组)将男、女各10名受试者按照性别分层后随机等分为两组。
令m= 10,需分2层(男性和女性)完成全部分组。
规定每段随机排列序号R 对应处理,R1~5为A组; R6~10 为B组。
4、SAS实现同上,与区组随机化相同。
四、分层区组随机化分组1、定义:多中心临床试验中,普遍采用的方法是以中心分层,然后在各中心内进行区组随机化,即称为分层的区组随机化。
23、适用条件:在影响因素比较少时,分层区组随机化可以保证组间均衡性;当影响因素多时,各层所含的例数会变少,容易出现各影响因素分布和例数的不均衡。
4、SAS实现对240例病人,按4个中心进行区组随机化分组。
方法一:PROC PLAN SEED=n 过程。
PROC PLAN SEED=210000;FACTORS center=4 block=10 length=6;OUTPUT OUT=patient;RUN;DATA result;SET patient;number=_n_;IF length <=3 THEN group='A';ELSE group='B';RUN;PROC PRINT data=result NOOBS;VAR number group;RUN;方法二:在区组随机化SAS程序基础上,添加一个分层因素(即中心),也可以实现分层区组随机化。
按多个因素分层的区组随机化:临床试验中有时分层的因素可能不止1个。
例如,在某抗生素的临床试验中,按中心进行分层外,还要求按病种分为呼吸系统感染和泌尿系统感染两层。
解决方法:可进行两次按中心分层的区组随机化,两次取不同种子数。
∙各中心例数不等的分层区组随机化实际中医院承担的例数可能不同,可按不同的医院分别区组随机化,且分别给定不同的种子数。
∙随机化确定各中心接收的编码分段先将若干个参加医院编码后,然后采用SAS系统中的随机函数UNIFORM(n)产生相应的随机数,对该随机数由小到大排序,以秩次号作为选取各医院对应的编码分段的依据。
∙随机化确定药物编码用SAS系统中的随机函数UNIFORM(n)分别产生试验组和对照组的随机数,如试验组随机数大于对照组随机数,则试验组以A作为代码,对照组以B作为代码,否则试验组为B,对照组为A。
五、动态随机化分组1、定义:在临床试验的过程中每例患者分到各组的概率不是固定不变的,而是根据一定的条件进行调整的方法。
动态随机化包括:瓮法(urn)、偏币法(biased coin)、最小化法(minimization)等。
在临床试验中,研究者常把患者分为试验组与对照组。
两种做法:先来入试验组,后来入对照组。
在患病严重程度、患病时间等非实验因素方面不均衡,可能造成组间不均衡。
先来入试验组,后来入对照组,然后交叉进行。
同样,可能造成组内不均衡。
按“平衡指数最小原则”进行随机化分组,即动态随机化分组。
2、优点:有效地保证各试验组间例数和某些重要的非处理因素接近一致。