HMM隐马尔可夫模型解析
- 格式:ppt
- 大小:856.00 KB
- 文档页数:52

【中⽂分词】隐马尔可夫模型HMMNianwen Xue 在《Chinese Word Segmentation as Character Tagging 》中将中⽂分词视作为序列标注问题(sequence tagging problem ),由此引⼊监督学习算法来解决分词问题。
1. HMM⾸先,我们将简要地介绍HMM (主要参考了李航⽼师的《统计学习⽅法》)。
HMM 包含如下的五元组:状态值集合Q ={q 1,q 2,⋯,q N },其中N 为可能的状态数;观测值集合V ={v 1,v 2,⋯,v M },其中M 为可能的观测数;转移概率矩阵A =a ij ,其中a ij 表⽰从状态i 转移到状态j 的概率;发射概率矩阵(在[2]中称之为观测概率矩阵)B =b j (k ),其中b j (k )表⽰在状态j 的条件下⽣成观测v k 的概率;初始状态分布π.⼀般地,将HMM 表⽰为模型λ=(A ,B ,π),状态序列为I ,对应测观测序列为O 。
对于这三个基本参数,HMM 有三个基本问题:概率计算问题,在模型λ下观测序列O 出现的概率;学习问题,已知观测序列O ,估计模型λ的参数,使得在该模型下观测序列P (O |λ)最⼤;解码(decoding )问题,已知模型λ与观测序列O ,求解条件概率P (I |O )最⼤的状态序列I 。
2. 中⽂分词将状态值集合Q 置为{B ,E ,M ,S },分别表⽰词的开始、结束、中间(begin 、end 、middle )及字符独⽴成词(single );观测序列即为中⽂句⼦。
⽐如,“今天天⽓不错”通过HMM 求解得到状态序列“B E B E B E”,则分词结果为“今天/天⽓/不错”。
通过上⾯例⼦,我们发现中⽂分词的任务对应于解码问题:对于字符串C ={c 1,⋯,c n },求解最⼤条件概率max P (t 1,⋯,t n |c 1,⋯,c n )其中,t i 表⽰字符c i 对应的状态。

隐马尔可夫模型(HMM)中⽂分词1. 马尔可夫模型 如果⼀个系统有n个有限状态S={s1,s2,…s n},随着时间推移,该系统将从某⼀状态转移到另⼀状态,Q={q1,q2,…q n}位⼀个随机变量序列,该序列中的变量取值为状态集S中的某个状态,其中q t表⽰系统在时间t的状态。
那么:系统在时间t处于状态s j的概率取决于其在时间1,2, … t-1的状态,该概率为:P(q t=s j|q t−1=s i,q t−2=s k…)如果在特定条件下,系统在时间t的状态只与其在时间t-1的状态相关,即:P(q t=s j|q t−1=s i,q t−2=s k…)=P(q t=s j|q t−1=s i)则该系统构成⼀个离散的⼀阶马尔可夫链。
进⼀步,如果只考虑上述公式独⽴于时间t的随机过程:P(q t=s j|q t−1=s i)=a ij,1≤i,j≤N该随机过程为马尔可夫模型。
其中,状态转移概率aij 必须满⾜以下条件:a ij≥0,N∑j=1a ij=12.隐马尔可夫模型 相对于马尔可夫模型,在隐马尔可夫模型中,我们不知道模型经过的状态序列,只知道状态的概率函数,即,观察到的事件是状态的随机函数,因此,该模型是⼀个双重的随机过程。
其中,模型的状态转换过程是不可观察的,即隐蔽的,可观察事件的随机过程是隐蔽的观察状态转换过程的随机函数。
隐马尔可夫模型可以⽤五个元素来描述,包括2个状态集合和三个概率矩阵: (1)隐含状态 S 这些状态之间满⾜马尔可夫性质,是马尔可夫模型中实际所隐含的状态。
这些状态通常⽆法通过直接观测⽽得到。
(例如S1,S2,S3等等) (2)可观测状态 O 在模型中与隐含状态相关联,可通过直接观测⽽得到。
(例如O1,O2,O3等等,可观测状态的数⽬不⼀定要和隐含状态的数⽬⼀致。
(3)初始状态概率矩阵π 表⽰隐含状态在初始时刻t=1的概率矩阵,(例如t=1时,P(S1)=p1,P(S2)=P2,P(S3)=p3,则初始状态概率矩阵π=[ p1 p2 p3 ] (4)隐含状态转移概率矩阵A 描述了HMM模型中各个状态之间的转移概率。

⼀⽂搞懂HMM(隐马尔可夫模型)什么是熵(Entropy)简单来说,熵是表⽰物质系统状态的⼀种度量,⽤它⽼表征系统的⽆序程度。
熵越⼤,系统越⽆序,意味着系统结构和运动的不确定和⽆规则;反之,,熵越⼩,系统越有序,意味着具有确定和有规则的运动状态。
熵的中⽂意思是热量被温度除的商。
负熵是物质系统有序化,组织化,复杂化状态的⼀种度量。
熵最早来原于物理学. 德国物理学家鲁道夫·克劳修斯⾸次提出熵的概念,⽤来表⽰任何⼀种能量在空间中分布的均匀程度,能量分布得越均匀,熵就越⼤。
1. ⼀滴墨⽔滴在清⽔中,部成了⼀杯淡蓝⾊溶液2. 热⽔晾在空⽓中,热量会传到空⽓中,最后使得温度⼀致更多的⼀些⽣活中的例⼦:1. 熵⼒的⼀个例⼦是⽿机线,我们将⽿机线整理好放进⼝袋,下次再拿出来已经乱了。
让⽿机线乱掉的看不见的“⼒”就是熵⼒,⽿机线喜欢变成更混乱。
2. 熵⼒另⼀个具体的例⼦是弹性⼒。
⼀根弹簧的⼒,就是熵⼒。
胡克定律其实也是⼀种熵⼒的表现。
3. 万有引⼒也是熵⼒的⼀种(热烈讨论的话题)。
4. 浑⽔澄清[1]于是从微观看,熵就表现了这个系统所处状态的不确定性程度。
⾹农,描述⼀个信息系统的时候就借⽤了熵的概念,这⾥熵表⽰的是这个信息系统的平均信息量(平均不确定程度)。
最⼤熵模型我们在投资时常常讲不要把所有的鸡蛋放在⼀个篮⼦⾥,这样可以降低风险。
在信息处理中,这个原理同样适⽤。
在数学上,这个原理称为最⼤熵原理(the maximum entropy principle)。
让我们看⼀个拼⾳转汉字的简单的例⼦。
假如输⼊的拼⾳是"wang-xiao-bo",利⽤语⾔模型,根据有限的上下⽂(⽐如前两个词),我们能给出两个最常见的名字“王⼩波”和“王晓波 ”。
⾄于要唯⼀确定是哪个名字就难了,即使利⽤较长的上下⽂也做不到。
当然,我们知道如果通篇⽂章是介绍⽂学的,作家王⼩波的可能性就较⼤;⽽在讨论两岸关系时,台湾学者王晓波的可能性会较⼤。

HMM隐马尔可夫模型在自然语言处理中的应用隐马尔可夫模型(Hidden Markov Model,HMM)是自然语言处理中常用的一种概率统计模型,它广泛应用于语音识别、文本分类、机器翻译等领域。
本文将从HMM的基本原理、应用场景和实现方法三个方面,探讨HMM在自然语言处理中的应用。
一、HMM的基本原理HMM是一种二元组( $λ=(A,B)$),其中$A$是状态转移矩阵,$B$是观测概率矩阵。
在HMM中,状态具有时序关系,每个时刻处于某一状态,所取得的观测值与状态相关。
具体来说,可以用以下参数描述HMM模型:- 隐藏状态集合$S={s_1,s_2,...,s_N}$:表示模型所有可能的状态。
- 观测符号集合$V={v_1,v_2,...,v_M}$:表示模型所有可能的观测符号。
- 初始状态分布$\pi={\pi (i)}$:表示最初处于各个状态的概率集合。
- 状态转移矩阵$A={a_{ij}}$:表示从$i$状态转移到$j$状态的概率矩阵。
- 观测概率矩阵$B={b_j(k)}$:表示处于$j$状态时,观测到$k$符号的概率。
HMM的主要任务是在给定观测符号序列下,求出最有可能的对应状态序列。
这个任务可以通过HMM的三种基本问题求解。
- 状态序列概率问题:已知模型参数和观测符号序列,求得该观测符号序列下各个状态序列的概率。
- 观测符号序列概率问题:已知模型参数和状态序列,求得该状态序列下观测符号序列的概率。
- 状态序列预测问题:已知模型参数和观测符号序列,求得使得观测符号序列概率最大的对应状态序列。
二、HMM的应用场景1. 语音识别语音识别是指将语音信号转化成文字的过程,它是自然语言处理的关键技术之一。
HMM在语音识别领域具有广泛应用,主要用于建立声学模型和语言模型。
其中,声学模型描述语音信号的产生模型,是从语音输入信号中提取特征的模型,而语言模型描述语言的组织方式,是指给定一个句子的前提下,下一个字或单词出现的可能性。
机器学习之隐马尔科夫模型(HMM)机器学习之隐马尔科夫模型(HMM)1、隐马尔科夫模型介绍2、隐马尔科夫数学原理3、Python代码实现隐马尔科夫模型4、总结隐马尔可夫模型介绍马尔科夫模型(hidden Markov model,HMM)是关于时序的概率模型,描述由一个隐藏的马尔科夫随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程,属于一个生成模型。
下面我们来从概率学角度定义马尔科夫模型,从一个典型例子开始:假设有4个盒子,每个盒子里面有不同数量的红、白两种颜色的球,具体如下表:盒子编号1234红球数5368白球数5742现在从这些盒子中取出T个球,取样规则为每次选择一个盒子取出一个球,记录其颜色,放回。
在这个过程中,我们只能观测到球的颜色的序列,观测不到球是从哪个盒子中取出来的,即观测不到盒子的序列,这里有两个随机序列,一个是盒子的序列(状态序列),一个是球的颜色的观测序列(观测序列),前者是隐藏的,只有后者是可观测的。
这里就构成了一个马尔科夫的例子。
定义是所有的可能的状态集合,V是所有的可能的观测的集合:其中,N是可能的状态数,M是可能的观测数,例如上例中N=4,M=2。
是长度为T的状态序列,是对应的观测序列:A是状态转移概率矩阵:其中, 是指在时刻处于状态的条件下在时刻转移到状态的概率。
B是观测概率矩阵:其中, 是指在时刻处于状态的条件下生成观测的概率。
是初始状态概率向量:其中, 是指在时刻=1处于状态的概率。
由此可得到,隐马尔可夫模型的三元符号表示,即称为隐马尔可夫模型的三要素。
由定义可知隐马尔可夫模型做了两个基本假设:(1)齐次马尔科夫性假设,即假设隐藏的马尔科夫链在任意时刻的状态只和-1状态有关;(2)观测独立性假设,观测只和当前时刻状态有关;仍以上面的盒子取球为例,假设我们定义盒子和球模型:状态集合: = {盒子1,盒子2,盒子3,盒子4}, N=4观测集合: = {红球,白球} M=2初始化概率分布:状态转移矩阵:观测矩阵:(1)转移概率的估计:假设样本中时刻t处于状态i,时刻t+1转移到状态j 的频数为那么转台转移概率的估计是:(2)观测概率的估计:设样本中状态为j并观测为k的频数是那么状态j观测为k的概率, (3)初始状态概率的估计为S个样本中初始状态为的频率。

HMM(隐马尔可夫模型)及其应用摘要:隐马尔可夫模型(Hidden Markov Model,HMM)作为一种统计分析模型,创立于20世纪70年代。
80年代得到了传播和发展,成为信号处理的一个重要方向,现已成功地用于语音识别,行为识别,文字识别以及故障诊断等领域。
本文先是简要介绍了HMM的由来和概念,之后重点介绍了3个隐马尔科夫模型的核心问题。
关键词:HMM,三个核心问题HMM的由来1870年,俄国有机化学家Vladimir V. Markovnikov第一次提出马尔可夫模型。
马尔可夫在分析俄国文学家普希金的名著《叶夫盖尼•奥涅金》的文字的过程中,提出了后来被称为马尔可夫框架的思想。
而Baum及其同事则提出了隐马尔可夫模型,这一思想后来在语音识别领域得到了异常成功的应用。
同时,隐马尔可夫模型在“统计语言学习”以及“序列符号识别”(比如DNA序列)等领域也得到了应用。
人们还把隐马尔可夫模型扩展到二维领域,用于光学字符识别。
而其中的解码算法则是由Viterbi和他的同事们发展起来的。
马尔可夫性和马尔可夫链1. 马尔可夫性如果一个过程的“将来”仅依赖“现在”而不依赖“过去”,则此过程具有马尔可夫性,或称此过程为马尔可夫过程。
马尔可夫性可用如下式子形象地表示:X(t+1)=f(X(t))2. 马尔可夫链时间和状态都离散的马尔可夫过程称为马尔可夫链。
记作{Xn=X(n), n=0,1,2,…}这是在时间集T1={0,1,2,…}上对离散状态的过程相继观察的结果。
链的状态空间记作I={a1, a2,…}, ai ∈R.条件概率Pij(m, m+n)=P{ Xm+n = aj | Xm = aj }为马氏链在时刻m处于状态ai条件下,在时刻m+n转移到状态aj的转移概率。
3. 转移概率矩阵如下图所示,这是一个转移概率矩阵的例子。
由于链在时刻m从任何一个状态ai出发,到另一时刻m+n,必然转移到a1,a2…,诸状态中的某一个,所以有当与m无关时,称马尔可夫链为齐次马尔可夫链,通常说的马尔可夫链都是指齐次马尔可夫链。

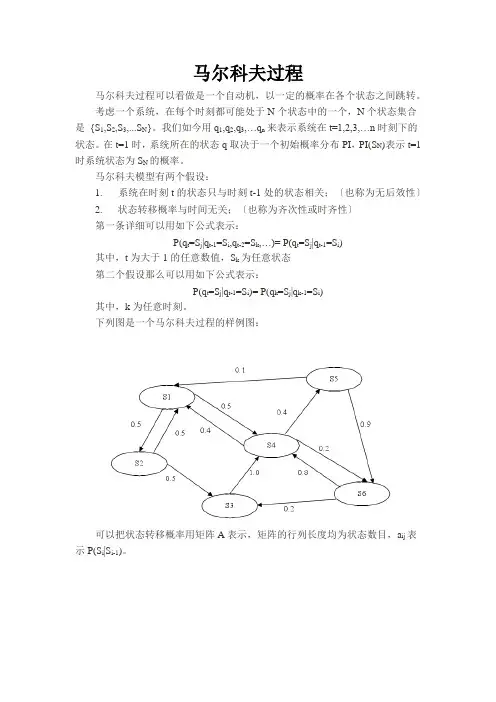
马尔科夫过程马尔科夫过程可以看做是一个自动机,以一定的概率在各个状态之间跳转。
考虑一个系统,在每个时刻都可能处于N个状态中的一个,N个状态集合是{S1,S2,S3,...S N}。
我们如今用q1,q2,q3,…q n来表示系统在t=1,2,3,…n时刻下的状态。
在t=1时,系统所在的状态q取决于一个初始概率分布PI,PI(S N)表示t=1时系统状态为S N的概率。
马尔科夫模型有两个假设:1. 系统在时刻t的状态只与时刻t-1处的状态相关;〔也称为无后效性〕2. 状态转移概率与时间无关;〔也称为齐次性或时齐性〕第一条详细可以用如下公式表示:P(q t=S j|q t-1=S i,q t-2=S k,…)= P(q t=S j|q t-1=S i)其中,t为大于1的任意数值,S k为任意状态第二个假设那么可以用如下公式表示:P(q t=S j|q t-1=S i)= P(q k=S j|q k-1=S i)其中,k为任意时刻。
下列图是一个马尔科夫过程的样例图:可以把状态转移概率用矩阵A表示,矩阵的行列长度均为状态数目,a ij表示P(S i|S i-1)。
隐马尔科夫过程与马尔科夫相比,隐马尔科夫模型那么是双重随机过程,不仅状态转移之间是个随机事件,状态和输出之间也是一个随机过程,如下列图所示:此图是从别处找来的,可能符号与我之前描绘马尔科夫时不同,相信大家也能理解。
该图分为上下两行,上面那行就是一个马尔科夫转移过程,下面这一行那么是输出,即我们可以观察到的值,如今,我们将上面那行的马尔科夫转移过程中的状态称为隐藏状态,下面的观察到的值称为观察状态,观察状态的集合表示为O={O1,O2,O3,…O M}。
相应的,隐马尔科夫也比马尔科夫多了一个假设,即输出仅与当前状态有关,可以用如下公式表示:P(O1,O2,…,O t|S1,S2,…,S t)=P(O1|S1)*P(O2|S2)*...*P(O t|S t) 其中,O1,O2,…,O t为从时刻1到时刻t的观测状态序列,S1,S2,…,S t那么为隐藏状态序列。

隐马尔可夫模型(HMM)简介(一)阿黄是大家敬爱的警官,他性格开朗,身体强壮,是大家心目中健康的典范。
但是,近一个月来阿黄的身体状况出现异常:情绪失控的状况时有发生。
有时候忍不住放声大笑,有时候有时候愁眉不展,有时候老泪纵横,有时候勃然大怒……如此变化无常的情绪失控是由什么引起的呢?据警队同事勇男描述,由于复习考试寝室不熄灯与多媒体作业的困扰,阿黄近日出现了失眠等症状;与此同时,阿黄近日登陆一个叫做“xiaonei网”的网站十分频繁。
经医生进一步诊断,由于其他人也遇到同样的考试压力、作息不规律的情况而并未出现情绪失控;并且,其它登陆XIAONEI网的众多同学表现正常,因此可基本排除它们是情绪失控的原因。
黄SIR的病情一度陷入僵局……最近,阿黄的病情有了新的眉目:据一位对手相学与占卜术十分精通的小巫婆透露,阿黄曾经私下请她对自己的病情进行诊断。
经过观察与分析终于有了重大发现:原来阿黄的病情正在被潜伏在他体内的三种侍神控制!他们是:修罗王、阿修罗、罗刹神。
据悉,这三种侍神是情绪积聚激化而形成的自然神灵,他们相克相生,是游离于个体意识之外的精神产物,可以对人的情绪起到支配作用。
每一天,都会有一位侍神主宰阿黄的情绪。
并且,不同的侍神会导致不同的情绪突然表现。
然而,当前的科技水平无法帮助我们诊断,当前哪位侍神是主宰侍神;更糟的是,不同的侍神(3个)与不同的情绪(4种)并不存在显而易见的一一对应关系。
所以,乍看上去,阿黄的病情再次陷入僵局……我们怎样才能把握阿黄情绪变化的规律?我们怎样才能通过阿黄的情绪变化,推测他体内侍神的变化规律?关键词:两类状态:情绪状态(观察状态):放声大笑,愁眉不展,老泪纵横,勃然大怒侍神状态(隐状态):修罗王,阿修罗,罗刹神(二)阿黄的病情引来了很多好心人的关心。
这与阿黄真诚善良的品格不无关系。
关于侍神的特点,占卜师和很多好心人找来了许多珍贵资料。
其中很多人经过一段时间的观察与记录后,在貌似毫无规律的数据背后,发现了侍神与情绪之间的内在规律!!他们在多次观测后,建立在大量数据基础上,表现出宏观的内在联系!由于这些好心人大部分是TONGJI大学的人,所以,这种规律被称作统计规律。

隐马尔可夫模型(Hidden Markov Model, HMM)是一种用来对时序数据进行建模的概率图模型。
它在信号处理、语音识别、自然语言处理等领域被广泛应用,具有重要的理论和实际意义。
隐马尔可夫模型包括三个基本问题及相应的算法,分别是概率计算问题、学习问题和预测问题。
接下来我们将针对这三个问题展开详细探讨。
### 1.概率计算问题概率计算问题是指给定隐马尔可夫模型λ=(A, B, π)和观测序列O={o1, o2, ..., oT},计算在模型λ下观测序列O出现的概率P(O|λ)。
为了解决这个问题,可以使用前向传播算法。
前向传播算法通过递推计算前向概率αt(i)来求解观测序列O出现的概率。
具体来说,前向概率αt(i)表示在时刻t状态为i且观测到o1, o2, ..., ot的概率。
通过动态规划的思想,可以高效地计算出观测序列O出现的概率P(O|λ)。
### 2.学习问题学习问题是指已知观测序列O={o1, o2, ..., oT},估计隐马尔可夫模型λ=(A, B, π)的参数。
为了解决这个问题,可以使用Baum-Welch算法,也称为EM算法。
Baum-Welch算法通过迭代更新模型参数A、B和π,使得观测序列O出现的概率P(O|λ)最大化。
这一过程涉及到E步和M步,通过不断迭代更新模型参数,最终可以得到最优的隐马尔可夫模型。
### 3.预测问题预测问题是指给定隐马尔可夫模型λ=(A, B, π)和观测序列O={o1,o2, ..., oT},求解最有可能产生观测序列O的状态序列I={i1, i2, ..., iT}。
为了解决这个问题,可以使用维特比算法。
维特比算法通过动态规划的方式递推计算最优路径,得到最有可能产生观测序列O的状态序列I。
该算法在实际应用中具有高效性和准确性。
在实际应用中,隐马尔可夫模型的三个基本问题及相应的算法给我们提供了强大的建模和分析工具。
通过概率计算问题,我们可以计算出观测序列出现的概率;通过学习问题,我们可以从观测序列学习到模型的参数;通过预测问题,我们可以预测出最有可能的状态序列。

隐马尔可夫模型(HMM)是一种统计模型,常用于语音识别、自然语言处理等领域。
它主要用来描述隐藏的马尔可夫链,即一种具有未知状态的马尔可夫链。
在语音识别中,HMM被广泛应用于对语音信号进行建模和识别。
下面我将从HMM的基本概念、参数迭代和语音识别应用等方面展开阐述。
1. HMM的基本概念在隐马尔可夫模型中,有三种基本要素:状态、观测值和状态转移概率及观测概率。
状态表示未知的系统状态,它是隐藏的,无法直接观测到。
观测值则是我们可以观测到的数据,比如语音信号中的频谱特征等。
状态转移概率描述了在不同状态之间转移的概率,而观测概率则表示在每个状态下观测到不同观测值的概率分布。
2. HMM参数迭代HMM的参数包括初始状态概率、状态转移概率和观测概率。
在实际应用中,这些参数通常是未知的,需要通过观测数据进行估计。
参数迭代是指通过一定的算法不断更新参数的过程,以使模型更好地拟合观测数据。
常见的参数迭代算法包括Baum-Welch算法和Viterbi算法。
其中,Baum-Welch算法通过最大化似然函数来估计模型的参数,Viterbi算法则用于解码和预测。
3. HMM在语音识别中的应用在语音识别中,HMM被广泛用于建模和识别语音信号。
语音信号被转换成一系列的特征向量,比如MFCC(Mel-Frequency Cepstral Coefficients)特征。
这些特征向量被用来训练HMM模型,学习模型的参数。
在识别阶段,通过Viterbi算法对输入语音进行解码,得到最可能的文本输出。
4. 个人观点和理解从个人角度看,HMM作为一种强大的统计模型,在语音识别领域有着重要的应用。
通过不断迭代参数,HMM能够更好地建模语音信号,提高语音识别的准确性和鲁棒性。
然而,HMM也面临着状态空间爆炸、参数收敛速度慢等问题,需要结合其他模型和算法进行改进和优化。
总结回顾通过本文对隐马尔可夫模型(HMM)的介绍,我们从基本概念、参数迭代和语音识别应用等方面对HMM有了更深入的了解。
机器学习中的隐马尔可夫模型解析隐马尔可夫模型(Hidden Markov Model,HMM)是一种常用于描述随机过程的概率模型,在机器学习领域得到广泛应用。
本文将对隐马尔可夫模型的原理、应用以及解析方法进行详细介绍。
一、隐马尔可夫模型的基本原理隐马尔可夫模型由两个基本假设构成:马尔可夫假设和观测独立假设。
根据这两个假设,隐马尔可夫模型可以表示为一个五元组:(N, M, A, B, π),其中:- N表示隐藏状态的数量;- M表示观测状态的数量;- A是一个N×N的矩阵,表示从一个隐藏状态转移到另一个隐藏状态的概率;- B是一个N×M的矩阵,表示从一个隐藏状态生成一个观测状态的概率;- π是一个长度为N的向量,表示初始隐藏状态的概率分布。
在隐马尔可夫模型中,隐藏状态无法被直接观测到,只能通过观测状态的序列来进行推断。
因此,对于给定的观测状态序列,我们的目标是找到最有可能生成该序列的隐藏状态序列。
二、隐马尔可夫模型的应用领域隐马尔可夫模型在自然语言处理、语音识别、图像处理等领域得到广泛应用。
以下是几个常见的应用场景:1. 自然语言处理:隐马尔可夫模型可以用于词性标注、语法分析等任务,通过学习文本中的隐藏状态序列来提取语义信息。
2. 语音识别:隐马尔可夫模型可以用于音频信号的建模,通过观测状态序列推断出音频中的语音内容。
3. 图像处理:隐马尔可夫模型可以用于图像分割、目标跟踪等任务,通过学习隐藏状态序列来提取图像中的特征。
三、隐马尔可夫模型的解析方法解析隐马尔可夫模型有两个基本问题:评估问题和解码问题。
1. 评估问题:给定模型参数和观测状态序列,计算生成该观测序列的概率。
一种常用的解法是前向算法,通过动态规划的方式计算前向概率,即在第t个时刻观测到部分序列的概率。
2. 解码问题:给定模型参数,找到最有可能生成观测状态序列的隐藏状态序列。
一种常用的解法是维特比算法,通过动态规划的方式计算最大后验概率路径,即在第t个时刻生成部分观测序列的概率最大的隐藏状态路径。
如何用简单易懂的例子解释隐马尔可夫模型如何用简单易懂的例子解释隐马尔可夫模型? - 知乎隐马尔可夫(HMM)好讲,简单易懂不好讲。
我想说个更通俗易懂的例子。
我希望我的读者是对这个问题感兴趣的入门者,所以我会多阐述数学思想,少写公式。
霍金曾经说过,你多写一个公式,就会少一半的读者。
还是用最经典的例子,掷骰子。
假设我手里有三个不同的骰子。
第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。
第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。
第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。
然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。
不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。
例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4这串数字叫做可见状态链。
但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。
在这个例子里,这串隐含状态链就是你用的骰子的序列。
比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。
在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。
D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。
这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。
比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。
隐马尔可夫链模型的递推-概述说明以及解释1.引言1.1 概述隐马尔可夫链模型是一种常用的概率统计模型,它广泛应用于自然语言处理、语音识别、模式识别等领域。
该模型由两个基本假设构成:一是假设系统的演变具有马尔可夫性质,即当前状态的变化只与前一个状态有关;二是假设在每个状态下,观测到的数据是相互独立的。
在隐马尔可夫链模型中,存在两个重要概念:隐含状态和观测数据。
隐含状态是指在系统中存在但无法直接观测到的状态,而观测数据是指我们通过观测手段能够直接获取到的数据。
隐含状态和观测数据之间通过概率函数进行联系,概率函数描述了在每个状态下观测数据出现的概率。
隐马尔可夫链模型的递推算法用于解决两个问题:一是给定模型参数和观测序列,求解最可能的隐含状态序列;二是给定模型参数和观测序列,求解模型参数的最大似然估计。
其中,递推算法主要包括前向算法和后向算法。
前向算法用于计算观测序列出现的概率,后向算法用于计算在某一隐含状态下观测数据的概率。
隐马尔可夫链模型在实际应用中具有广泛的应用价值。
在自然语言处理领域,它可以用于词性标注、语义解析等任务;在语音识别领域,它可以用于语音识别、语音分割等任务;在模式识别领域,它可以用于手写识别、人脸识别等任务。
通过对隐马尔可夫链模型的研究和应用,可以有效提高这些领域的性能和效果。
综上所述,隐马尔可夫链模型是一种重要的概率统计模型,具有广泛的应用前景。
通过递推算法,我们可以有效地解决模型参数和隐含状态序列的求解问题。
随着对该模型的深入研究和应用,相信它将在各个领域中发挥更大的作用,并取得更好的效果。
1.2 文章结构文章结构部分的内容可以包括以下要点:文章将分为引言、正文和结论三个部分。
引言部分包括概述、文章结构和目的三个子部分。
概述部分简要介绍了隐马尔可夫链模型的背景和重要性,指出了该模型在实际问题中的广泛应用。
文章结构部分说明了整篇文章的组织结构,明确了每个部分的内容和目的。
目的部分描述了本文的主要目的,即介绍隐马尔可夫链模型的递推算法和应用,并总结和展望其未来发展方向。
隐马尔可夫模型的基本用法隐马尔可夫模型(HiddenMarkovModel,HMM)是一种用于建模时间序列的统计模型。
它常被应用于语音识别、自然语言处理、生物信息学、金融等领域。
本文将介绍隐马尔可夫模型的基本概念、算法和应用。
一、隐马尔可夫模型的基本概念隐马尔可夫模型由状态序列和观测序列组成。
状态序列是一个由隐含状态组成的序列,观测序列是由状态序列产生的观测值序列。
在语音识别中,状态序列可以表示语音信号的音素序列,观测序列可以表示对应的声学特征序列。
隐马尔可夫模型假设状态序列是马尔可夫链,即当前状态只与前一个状态有关,与其他状态无关。
假设状态序列有N个状态,可以用π=(π1,π2,...,πN)表示初始状态分布,即在时刻t=1时,系统处于状态i的概率为πi。
假设状态i在时刻t转移到状态j的概率为aij,可以用A=(aij)表示状态转移矩阵。
假设在状态i下产生观测值j的概率为b(i,j),可以用B=(b(i,j))表示观测矩阵。
在隐马尔可夫模型中,我们希望根据观测序列来推断状态序列。
这个问题被称为解码(decoding)问题。
同时,我们也希望根据观测序列来估计模型参数,包括初始状态分布、状态转移矩阵和观测矩阵。
这个问题被称为学习(learning)问题。
二、隐马尔可夫模型的算法1.前向算法前向算法是解决解码和学习问题的基础算法。
它用于计算在时刻t观测到的序列为O=(o1,o2,...,ot),且当前状态为i的概率。
这个概率可以用前向概率αt(i)表示,即:αt(i)=P(o1,o2,...,ot,qt=i|λ)其中,qt表示时刻t的状态。
根据全概率公式,αt(i)可以用前一时刻的前向概率和状态转移概率计算得到:αt(i)=∑jαt-1(j)ajbi(ot)其中,∑j表示对所有状态j求和。
前向概率可以用递推的方式计算,即:α1(i)=πibi(o1)αt(i)=∑jαt-1(j)ajbi(ot),t=2,3,...,T其中,T表示观测序列的长度。
算法基础(4)隐马尔科夫模型HMM详解展开全文前言隐马尔科夫作为最经典的机器学习方法之一,是动态规划的经典工具,衍生出了Ngram等诸多模型,对其方法原理的理解非常重要。
本文可以说是最详尽的一篇关于隐马尔科夫方法的解读了,就是比较长,可以收藏下来慢慢看。
目录1.基本的概念1.1 知道骰子是什么(知道参数是什么),每种骰子是什么,每次投的是什么骰子,根据骰子的结果求产生这个结果的概率1.2 知道骰子有几种(隐含状态数量),也就是有几种骰子,在上面的例子中就有三种,每种骰子是什么(转换概率),根据扔骰子投出的结果(观测状态链),我想知道每次投的是哪种骰子(隐含状态链)1.3 知道骰子有几种(隐含状态的数量),每种骰子是什么(转换概率),观测到很多次骰子的结果(观测序列),想知道投出这个结果的概率1.4 知道骰子有几种(隐含状态的数量),不知道每种骰子是什么,检测到很多次骰子的结果(观测序列),我现在想知道每种骰子是什么2.公式推导2.1 HMM模型的确定2.2 三个问题2.3 暴力求解2.4 前向算法2.5 后向算法2.6 前向概率和后向概率的关系2.7 学习算法2.8 baum welch算法2.9 预测算法3.代码实现:中文分词案例3.1 有监督学习案例3.2 无监督学习案例1.基本的概念首先举一个比较经典的例子,扔骰子:有三个骰子,第一个是我们最常见的6个面,(1,2,3,4,5,6)每一个面概率1/6;第二个只有4个面,(1,2,3,4)每一个面概率1/4;第三个有8个面,(1,2,3,4,5,6,7,8),每一个面出现的概率1/8。
假如我们先挑一个骰子,挑到每一个骰子的概率就是1/3,然后投掷,可以得到数字中1,2,3,4,5,6,7,8中的一个。
不停重复上述的过程,最后会得到一串数字,例如我们可能得到一串这样的数字,137****7356。
这种数字叫可见状态序列,但在隐马尔科夫模型中,我们不仅仅有这么一串可见序列,还有一串不可见的隐含状态链。
隐马尔可夫模型三个基本问题及算法隐马尔可夫模型(Hien Markov Model, HMM)是一种用于建模具有隐藏状态和可观测状态序列的概率模型。
它在语音识别、自然语言处理、生物信息学等领域广泛应用,并且在机器学习和模式识别领域有着重要的地位。
隐马尔可夫模型有三个基本问题,分别是状态序列概率计算问题、参数学习问题和预测问题。
一、状态序列概率计算问题在隐马尔可夫模型中,给定模型参数和观测序列,计算观测序列出现的概率是一个关键问题。
这个问题通常由前向算法和后向算法来解决。
具体来说,前向算法用于计算给定观测序列下特定状态出现的概率,而后向算法则用于计算给定观测序列下前面状态的概率。
这两个算法相互协作,可以高效地解决状态序列概率计算问题。
二、参数学习问题参数学习问题是指在给定观测序列和状态序列的情况下,估计隐马尔可夫模型的参数。
通常采用的算法是Baum-Welch算法,它是一种迭代算法,通过不断更新模型参数来使观测序列出现的概率最大化。
这个问题的解决对于模型的训练和优化非常重要。
三、预测问题预测问题是指在给定观测序列和模型参数的情况下,求解最可能的状态序列。
这个问题通常由维特比算法来解决,它通过动态规划的方式来找到最可能的状态序列,并且在很多实际应用中都有着重要的作用。
以上就是隐马尔可夫模型的三个基本问题及相应的算法解决方法。
在实际应用中,隐马尔可夫模型可以用于许多领域,比如语音识别中的语音建模、自然语言处理中的词性标注和信息抽取、生物信息学中的基因预测等。
隐马尔可夫模型的强大表达能力和灵活性使得它成为了一个非常有价值的模型工具。
在撰写这篇文章的过程中,我对隐马尔可夫模型的三个基本问题有了更深入的理解。
通过对状态序列概率计算问题、参数学习问题和预测问题的深入探讨,我认识到隐马尔可夫模型在实际应用中的重要性和广泛适用性。
隐马尔可夫模型的算法解决了许多实际问题,并且在相关领域有着重要的意义。
隐马尔可夫模型是一种强大的概率模型,它的三个基本问题和相应的算法为实际应用提供了重要支持。