Spark性能优化(shuffle调优)
- 格式:doc
- 大小:1.62 MB
- 文档页数:12

面向大数据处理的Spark集群架构与性能优化在大数据时代,面向大数据处理的Spark集群架构和性能优化是一个重要的课题。
Spark作为一种快速、通用、可扩展的大数据处理框架,已经成为了许多公司和组织数据处理和分析的首选。
本文将深入探讨Spark集群架构的设计原则,以及如何通过性能优化来提高Spark的处理能力。
首先,我们来了解一下Spark集群架构的设计原则。
Spark集群通常包括一个主节点(Master)和多个工作节点(Worker)。
主节点负责整个集群的管理和调度工作,而工作节点则是实际执行任务的计算节点。
在正式使用Spark之前,我们需要在每个工作节点上安装和配置Spark,并确保它们可以与主节点进行通信。
Spark集群架构的设计原则是可伸缩性和容错性。
伸缩性使得Spark可以轻松地处理大规模数据集,而容错性则确保在节点故障的情况下能够提供可靠的数据处理。
为了实现这些原则,我们可以采取以下策略:1. 增加工作节点的数量:通过增加工作节点的数量,可以提高Spark集群的处理能力。
当负载增加时,可以动态地添加新的工作节点来分担负载,从而实现伸缩性。
同时,多个工作节点之间的数据可以并行处理,进一步提高处理效率。
2. 合理分配资源:在设计Spark集群架构时,需要根据任务的需求来合理分配资源。
可以通过调整每个工作节点的内存和CPU核数来优化性能。
对于内存密集型的任务,可以增加每个工作节点的内存大小;对于计算密集型的任务,可以增加每个工作节点的CPU核数。
此外,还可以通过动态分配资源的方式,根据当前任务的需求来动态调整分配的资源。
3. 数据本地性调度:在Spark中,数据本地性调度是一种重要的优化技术。
它可以将计算任务调度到存储有所需数据的工作节点上,从而避免数据传输的开销。
Spark提供了多种数据本地性调度策略,包括PROCESS_LOCAL、NODE_LOCAL、RACK_LOCAL等。
通过合理选择数据本地性调度策略,可以减少数据传输的开销,提高计算效率。

Spark Shuffle原理、Shuffle操作问题解决和参数调优Spark Shuffle原理、Shuffle操作问题解决和参数调优摘要:1 shuffle原理1.1 mapreduce的shuffle原理1.1.1 map task端操作1.1.2 reduce task端操作1.2 spark现在的SortShuffleManager2 Shuffle操作问题解决2.1 数据倾斜原理2.2 数据倾斜问题发现与解决2.3 数据倾斜解决方案3 spark RDD中的shuffle算子3.1 去重3.2 聚合3.3 排序3.4 重分区3.5 集合操作和表操作4 spark shuffle参数调优内容:1 shuffle原理概述:Shuffle描述着数据从map task输出到reduce task输入的这段过程。
在分布式情况下,reducetask需要跨节点去拉取其它节点上的maptask结果。
这一过程将会产生网络资源消耗和内存,磁盘IO的消耗。
1.1 mapreduce的shuffle原理1.1.1 map task端操作每个,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
Spill过程:这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。
整个缓冲区有个溢写的比例spill.percent(默认是memory写,同时溢写线程锁定已用memory,先对key(序列化的字节)做排序,如果client程序设置了Combiner,那么在溢写的过程中就会进行局部聚合。
Merge过程:每次溢写都会生成一个临时文件,在maptask真正完成时会将这些文件归并成一个文件,这个过程叫做Merge。
1.1.2 reducetask端操作当某台TaskTracker上的所有map task执行完成,对应节点的reduce task开始启动,简单地说,此阶段就是不断地拉取(Fetcher)每个maptask所在节点的最终结果,然后不断地做merge形成reducetask的输入文件。
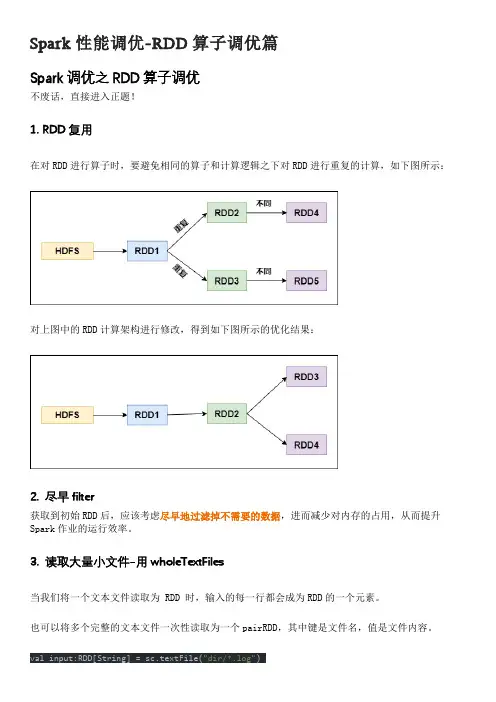
Spark性能调优-RDD算子调优篇Spark调优之RDD算子调优不废话,直接进入正题!1. RDD复用在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示:对上图中的RDD计算架构进行修改,得到如下图所示的优化结果:2. 尽早filter获取到初始RDD后,应该考虑尽早地过滤掉不需要的数据,进而减少对内存的占用,从而提升Spark作业的运行效率。
3. 读取大量小文件-用wholeTextFiles当我们将一个文本文件读取为 RDD 时,输入的每一行都会成为RDD的一个元素。
也可以将多个完整的文本文件一次性读取为一个pairRDD,其中键是文件名,值是文件内容。
val input:RDD[String] = sc.textFile("dir/*.log")如果传递目录,则将目录下的所有文件读取作为RDD。
文件路径支持通配符。
但是这样对于大量的小文件读取效率并不高,应该使用wholeTextFiles返回值为RDD[(String, String)],其中Key是文件的名称,Value是文件的内容。
def wholeTextFiles(path: String, minPartitions: Int = defaultMinPartitions): RDD[(String, String)])wholeTextFiles读取小文件:val filesRDD: RDD[(String, String)] =sc.wholeTextFiles("D:\\data\\files", minPartitions = 3)val linesRDD: RDD[String] = filesRDD.flatMap(_._2.split("\\r\\n"))val wordsRDD: RDD[String] = linesRDD.flatMap(_.split(" "))wordsRDD.map((_, 1)).reduceByKey(_ + _).collect().foreach(println)4. mapPartition和foreachPartition•mapPartitionsmap(_….) 表示每一个元素mapPartitions(_….) 表示每个分区的数据组成的迭代器普通的map算子对RDD中的每一个元素进行操作,而mapPartitions算子对RDD中每一个分区进行操作。

Spark性能优化本文章来自于阿里云云栖社区摘要: Spark的性能分析和调优很有意思,今天再写一篇。
主要话题是shuffle,当然也牵涉一些其他代码上的小把戏。
以前写过一篇文章,比较了几种不同场景的性能优化,包括portal的性能优化,web service的性能优化,还有Spark j ob的性能优化。
Spark的性能优化有一些特殊的地方,比如Spark的性能分析和调优很有意思,今天再写一篇。
主要话题是shuffle,当然也牵涉一些其他代码上的小把戏。
以前写过一篇文章,比较了几种不同场景的性能优化(原文链接:/3658?spm=5176.100239.blogcont53509.5.zDcg U3),包括portal的性能优化,web service的性能优化,还有Spark job的性能优化。
Spark的性能优化有一些特殊的地方,比如实时性一般不在考虑范围之内,通常我们用Spark来处理的数据,都是要求异步得到结果的数据;再比如数据量一般都很大,要不然也没有必要在集群上操纵这么一个大家伙,等等。
事实上,我们都知道没有银弹,但是每一种性能优化场景都有一些特定的“大boss”,通常抓住和解决大boss以后,能解决其中一大部分问题。
比如对于portal来说,是页面静态化,对于web service来说,是高并发(当然,这两种可以说并不确切,这只是针对我参与的项目总结的经验而已),而对于Spark来说,这个大boss就是shuffle。
首先要明确什么是shuffle。
Shuffle指的是从map阶段到reduce阶段转换的时候,即map的output向着reduce的input映射的时候,并非节点一一对应的,即干map 工作的slave A,它的输出可能要分散跑到reduce节点A、B、C、D …… X、Y、Z 去,就好像shuffle的字面意思“洗牌”一样,这些map的输出数据要打散然后根据新的路由算法(比如对key进行某种hash算法),发送到不同的reduce节点上去。

Spark性能优化:开发调优篇1、前言在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。
Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,应用范围与前景非常广泛。
在美团?大众点评,已经有很多同学在各种项目中尝试使用Spark。
大多数同学(包括笔者在内),最初开始尝试使用Spark的原因很简单,主要就是为了让大数据计算作业的执行速度更快、性能更高。
然而,通过Spark开发出高性能的大数据计算作业,并不是那么简单的。
如果没有对Spark作业进行合理的调优,Spark作业的执行速度可能会很慢,这样就完全体现不出Spark 作为一种快速大数据计算引擎的优势来。
因此,想要用好Spark,就必须对其进行合理的性能优化。
Spark的性能调优实际上是由很多部分组成的,不是调节几个参数就可以立竿见影提升作业性能的。
我们需要根据不同的业务场景以及数据情况,对Spark作业进行综合性的分析,然后进行多个方面的调节和优化,才能获得最佳性能。
笔者根据之前的Spark作业开发经验以及实践积累,总结出了一套Spark作业的性能优化方案。
整套方案主要分为开发调优、资源调优、数据倾斜调优、shuffle调优几个部分。
开发调优和资源调优是所有Spark作业都需要注意和遵循的一些基本原则,是高性能Spark 作业的基础;数据倾斜调优,主要讲解了一套完整的用来解决Spark作业数据倾斜的解决方案;shuffle调优,面向的是对Spark的原理有较深层次掌握和研究的同学,主要讲解了如何对Spark作业的shuffle运行过程以及细节进行调优。
本文作为Spark性能优化指南的基础篇,主要讲解开发调优以及资源调优。
2、开发调优Spark性能优化的第一步,就是要在开发Spark作业的过程中注意和应用一些性能优化的基本原则。
开发调优,就是要让大家了解以下一些Spark基本开发原则,包括:RDD lineage设计、算子的合理使用、特殊操作的优化等。

【Spark调优】:尽量避免使⽤shuffle类算⼦ 如果有可能的话,尽量避免使⽤shuffle类算⼦。
因为Spark作业运⾏过程中,最消耗性能的地⽅就是shuffle过程。
shuffle过程,就是将分布在集群中多个节点上的同⼀个key,拉取到同⼀个节点上,进⾏聚合或join等操作。
⽐如reduceByKey、join等算⼦,都会触发shuffle操作。
shuffle过程中,各个节点上的相同key都会先写⼊本地磁盘⽂件中,然后其他节点需要通过⽹络传输拉取各个节点上的磁盘⽂件中的相同key。
⽽且相同key都拉取到同⼀个节点进⾏聚合操作时,还有可能会因为⼀个节点上处理的key过多,导致内存不够存放,进⽽溢写到磁盘⽂件中。
因此在shuffle过程中,可能会发⽣⼤量的磁盘⽂件读写的IO操作,以及数据的⽹络传输操作。
会引起⼤量磁盘IO和⽹络数据传输也是shuffle性能较差的主要原因。
因此在⽣产环境开发过程中,能避免则尽可能避免使⽤reduceByKey、join、distinct、repartition等会进⾏shuffle的算⼦,尽量使⽤map类的⾮shuffle算⼦。
这样的话,没有shuffle操作或者仅有较少shuffle操作的Spark作业,可以⼤⼤减少性能开销。
spark中会导致shuffle操作的有以下⼏种算⼦:重分区类操作: ⽐如repartition、repartitionAndSortWithinPartitions、coalesce(shuffle=true)等。
重分区⼀般会shuffle,因为需要在整个集群中,对之前所有的分区的数据进⾏随机,均匀的打乱,然后把数据放⼊下游新的指定数量的分区内。
聚合,byKey类操作: ⽐如reduceByKey、groupByKey、sortByKey等。
byKey类的操作要对⼀个key,进⾏聚合操作,那么肯定要保证集群中,所有节点上的相同的key,移动到同⼀个节点上进⾏处理。

spark性能优化(⼀)本⽂内容说明初始化配置给rdd和dataframe带来的影响repartition的相关说明cache&persist的相关说明性能优化的说明建议以及实例配置说明spark:2.4.0服务器:5台(8核32G)初始化配置项%%init_sparklauncher.master = "yarn" = "BDP-xw"launcher.conf.spark.driver.cores = 1launcher.conf.spark.driver.memory = '1g'launcher.conf.spark.executor.instances = 3launcher.conf.spark.executor.memory = '1g'launcher.conf.spark.executor.cores = 2launcher.conf.spark.default.parallelism = 5launcher.conf.spark.dynamicAllocation.enabled = Falseimport org.apache.spark.sql.SparkSessionvar NumExecutors = spark.conf.getOption("spark.num_executors").reprvar ExecutorMemory = spark.conf.getOption("spark.executor.memory").reprvar AppName = spark.conf.getOption("").reprvar max_buffer = spark.conf.getOption("spark.kryoserializer.buffer.max").reprimport org.apache.spark.rdd.RDDimport org.apache.spark.sql.{DataFrame, Row}import org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.functions.monotonically_increasing_idimport org.apache.log4j.{Level, Logger}import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType}import org.apache.spark.sql.functions.{udf, _}import org.apache.spark.{SparkConf, SparkContext}object LoadingData_from_files{def main(args: Tuple2[String, Array[String]]=Tuple2(hdfs_file, etl_date:Array[String])): Unit = {for( a <- etl_date){val hdfs_file_ = s"$hdfs_file" + aval rdd_20210113 = spark.sparkContext.textFile(hdfs_file_).cache()val num1 = rdd_20210113.countprintln(s"加载数据啦:$a RDD的数据量是$num1")}val rdd_20210113_test = spark.sparkContext.textFile(hdfs_file + "20210328").cache()var num1 = rdd_20210113_test.count()println(s"加载数据啦:20210113 RDD的数据量是$num1")rdd_20210113_test.unpersist() // 解除持久化val df_20210420 = spark.sparkContext.textFile(hdfs_file + "20210113").toDF.cache()num1 = df_20210420.count() // 指定memory之后,cache的数量太多之前cache的结果会被⼲掉println(s"加载数据啦:20210420 DataFrame的数据量是$num1")}}// 配置参数multiple_duplicatedval hdfs_file = "hdfs://path/etl_date="val etl_date = Array("20210113","20210112","20210112","20210112","20210112","20210112", "20210113")LoadingData_from_files.main(hdfs_file, etl_date)得到结果如下:结果分析可以看到默认情况下,RDD的缓存⽅式都是到Memory的,⽽DataFrame的缓存⽅式都是Memory and Disk的指定memory之后,cache的数量太多之前cache的结果会被⼲掉⽆特定配置项import org.apache.spark.sql.SparkSessionvar NumExecutors = spark.conf.getOption("spark.num_executors").reprvar ExecutorMemory = spark.conf.getOption("spark.executor.memory").reprvar AppName = spark.conf.getOption("").reprobject LoadingData_from_files{def main(args: Tuple2[String, Array[String]]=Tuple2(hdfs_file, etl_date:Array[String])): Unit = {for( a <- etl_date){val hdfs_file_ = s"$hdfs_file" + aval rdd_20210113 = spark.sparkContext.textFile(hdfs_file_).cache()val num1 = rdd_20210113.countprintln(s"加载数据啦:$a RDD的数据量是$num1")}val rdd_20210113_test = spark.sparkContext.textFile(hdfs_file + "20210328").cache()var num1 = rdd_20210113_test.count()println(s"加载数据啦:20210328 RDD的数据量是$num1")rdd_20210113_test.unpersist() // 解除持久化val df_20210420 = spark.sparkContext.textFile(hdfs_file + "20210113").toDF.cache()num1 = df_20210420.count() // 指定memory之后,cache的数量太多之前cache的结果会被⼲掉println(s"加载数据啦:20210420 DataFrame的数据量是$num1 \n当前环境下cache的个数及id为:")spark.sparkContext.getPersistentRDDs.foreach(i=>println("cache的id:" + i._1))}}// ⽆配置参数multiple_duplicatedval hdfs_file = "hdfs://path/etl_date="val etl_date = Array("20210113","20210112","20210112","20210112","20210112","20210112", "20210113" )LoadingData_from_files.main(hdfs_file, etl_date)得到结果如下:结果分析spark的配置⽂件中,设置的也是动态分配内存;cache的结果也是到达memory限制的时候,已经cache的结果会⾃动消失;上述例⼦中,我们增加了8个⽂件,但最终只保留了5个cache的结果;通过for重复从⼀个⽂件取数,并val声明给相同变量并cache,结果是会被多次保存在memory或者Disk中的;查看当前服务下的所有缓存并删除spark.sparkContext.getPersistentRDDs.foreach(i=>println(i._1))spark.sparkContext.getPersistentRDDs.foreach(i=>{i._2.unpersist()})repartitionrepartition只是coalesce接⼝中shuffle为true的实现repartition 可以增加和减少分区,⽽使⽤ coalesce 则只能减少分区每个block的⼤⼩为默认的128M//RDDrdd.getNumPartitionsrdd.partitions.lengthrdd.partitions.size// For DataFrame, convert to RDD firstdf.rdd.getNumPartitionsdf.rdd.partitions.lengthdf.rdd.partitions.sizeRDD默认cache的级别是Memoryval hdfs_file = "hdfs://path1/etl_date="val rdd_20210113_test = spark.sparkContext.textFile(hdfs_file + "20210113").cache()// ⽂件⼤⼩为1.5Grdd_20210113_test.getNumPartitions// res2: Int = 13val rdd_20210113_test_par1 = rdd_20210113_test.repartition(5)rdd_20210113_test_par1.partitions.size// res9: Int = 5val rdd_20210113_test_par2 = rdd_20210113_test_par1.coalesce(13)rdd_20210113_test_par2.partitions.length// res14: Int = 5 增加分区没⽣效val rdd_20210113_test_par3 = rdd_20210113_test_par1.coalesce(3)rdd_20210113_test_par3.partitions.length// res16: Int = 3 增加分区⽣效DataFrame默认cache的级别是Memory and Diskval hdfs_file = "hdfs://path1/etl_date="val df_20210420 = spark.sparkContext.textFile(hdfs_file + "20210113").toDF().cache()df_20210420.rdd.getNumPartitions// res18: Int = 13val df_20210420_par1 = df_20210420.repartition(20)df_20210420_par1.rdd.getNumPartitions// res19: Int = 20 增加分区⽣效val df_20210420_par2 = df_20210420_par1.coalesce(5)df_20210420_par2.rdd.getNumPartitions// res20: Int = 5cache&persist对⽐cache调⽤的是⽆参数版本的persist()persist的说明import org.apache.spark.storage.StorageLevel._// MEMORY_AND_DISKval hdfs_file = "hdfs://path1/etl_date="var etl_date = "20210113"var hdfs_file_ = s"$hdfs_file" + etl_dateval rdd_20210113_DISK_MEMORY = spark.sparkContext.textFile(hdfs_file_).persist(MEMORY_AND_DISK)println("DISK_ONLY数据量为" + rdd_20210113_DISK_MEMORY.count())// MEMORY_ONLYetl_date = "20210112"hdfs_file_ = s"$hdfs_file" + etl_dateval rdd_20210113_MEMORY_ONLY = spark.sparkContext.textFile(hdfs_file_).persist(MEMORY_ONLY)println("MEMORY_ONLY数据量为" + rdd_20210113_MEMORY_ONLY.count())// DISK_ONLYetl_date = "20210328"hdfs_file_ = s"$hdfs_file" + etl_dateval rdd_20210113_DISK_ONLY = spark.sparkContext.textFile(hdfs_file_).persist(DISK_ONLY)println("DISK_ONLY数据量为" + rdd_20210113_DISK_ONLY.count())// DISK_ONLY数据量为4298617// MEMORY_ONLY数据量为86340// DISK_ONLY数据量为20000性能优化参数说明参数配置建议优化⽅⾯说明tipsyarn集群中⼀般有资源申请上限,如,executor-memory*num-executors < 400G 等,所以调试参数时要注意这⼀点如果GC时间较长,可以适当增加--executor-memory的值或者减少--executor-cores的值yarn下每个executor需要的memory = spark-executor-memory + spark.yarn.executor.memoryOverhead.⼀般需要为,后台进程留下⾜够的cores(⼀般每个节点留⼀个core)。

Spark性能优化指南——⾼级篇前⾔继讲解了每个Spark开发⼈员都必须熟知的开发调优与资源调优之后,本⽂作为《Spark性能优化指南》的⾼级篇,将深⼊分析数据倾斜调优与shuffle调优,以解决更加棘⼿的性能问题。
数据倾斜调优调优概述有的时候,我们可能会遇到⼤数据计算中⼀个最棘⼿的问题——数据倾斜,此时Spark作业的性能会⽐期望差很多。
数据倾斜调优,就是使⽤各种技术⽅案解决不同类型的数据倾斜问题,以保证Spark作业的性能。
数据倾斜发⽣时的现象绝⼤多数task执⾏得都⾮常快,但个别task执⾏极慢。
⽐如,总共有1000个task,997个task都在1分钟之内执⾏完了,但是剩余两三个task却要⼀两个⼩时。
这种情况很常见。
原本能够正常执⾏的Spark作业,某天突然报出OOM(内存溢出)异常,观察异常栈,是我们写的业务代码造成的。
这种情况⽐较少见。
数据倾斜发⽣的原理数据倾斜的原理很简单:在进⾏shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的⼀个task来进⾏处理,⽐如按照key进⾏聚合或join等操作。
此时如果某个key对应的数据量特别⼤的话,就会发⽣数据倾斜。
⽐如⼤部分key对应10条数据,但是个别key却对应了100万条数据,那么⼤部分task可能就只会分配到10条数据,然后1秒钟就运⾏完了;但是个别task可能分配到了100万数据,要运⾏⼀两个⼩时。
因此,整个Spark作业的运⾏进度是由运⾏时间最长的那个task决定的。
因此出现数据倾斜的时候,Spark作业看起来会运⾏得⾮常缓慢,甚⾄可能因为某个task处理的数据量过⼤导致内存溢出。
下图就是⼀个很清晰的例⼦:hello这个key,在三个节点上对应了总共7条数据,这些数据都会被拉取到同⼀个task中进⾏处理;⽽world和you这两个key分别才对应1条数据,所以另外两个task只要分别处理1条数据即可。
此时第⼀个task的运⾏时间可能是另外两个task的7倍,⽽整个stage的运⾏速度也由运⾏最慢的那个task所决定。


SparkSubmit参数及参数性能调优⾸先摆出常⽤的参数设定bin/spark-submit \--class com.xyz.bigdata.calendar.PeriodCalculator \--master yarn \--deploy-mode cluster \--queue default_queue \--num-executors 50 \--executor-cores 2 \--executor-memory 4G \--driver-memory 2G \--conf "spark.default.parallelism=250" \--conf "spark.shuffle.memoryFraction=0.3" \--conf "spark.storage.memoryFraction=0.5" \--conf "spark.driver.extraJavaOptions=-XX:+UseG1GC" \--conf "spark.executor.extraJavaOptions=-XX:+UseG1GC" \--verbose \${PROJECT_DIR}/bigdata-xyz-0.1.jar关于spark-submit的执⾏过程,读Spark Core的源码能够获得⼀个⼤致的印象。
今天事情⽐较多,所以之后会另写⽂章专门叙述关于Spark on YARN的事情(⼜挖了⼀个坑,上⼀个坑是关于Java String和JVM的,需要尽快填上了)。
num-executors含义:设定Spark作业要⽤多少个Executor进程来执⾏。
设定⽅法:根据我们的实践,设定在30~100个之间为最佳。
如果不设定,默认只会启动⾮常少的Executor。
如果设得太⼩,⽆法充分利⽤计算资源。

Spark性能调优之合理设置并⾏度Spark性能调优之合理设置并⾏度1.Spark的并⾏度指的是什么?spark作业中,各个stage的task的数量,也就代表了spark作业在各个阶段stage的并⾏度!当分配完所能分配的最⼤资源了,然后对应资源去调节程序的并⾏度,如果并⾏度没有与资源相匹配,那么导致你分配下去的资源都浪费掉了。
同时并⾏运⾏,还可以让每个task要处理的数量变少(很简单的原理。
合理设置并⾏度,可以充分利⽤集群资源,减少每个task处理数据量,⽽增加性能加快运⾏速度。
)举例:假如,现在已经在spark-submit 脚本⾥⾯,给我们的spark作业分配了⾜够多的资源,⽐如50个executor ,每个executor 有10G内存,每个executor有3个cpu core 。
基本已经达到了集群或者yarn队列的资源上限。
task没有设置,或者设置的很少,⽐如就设置了,100个task 。
50个executor ,每个executor 有3个core ,也就是说Application 任何⼀个stage运⾏的时候,都有总数150个cpu core ,可以并⾏运⾏。
但是,你现在只有100个task ,平均分配⼀下,每个executor 分配到2个task,ok,那么同时在运⾏的task,只有100个task,每个executor 只会并⾏运⾏ 2个task。
每个executor 剩下的⼀个cpu core 就浪费掉了!你的资源,虽然分配充⾜了,但是问题是,并⾏度没有与资源相匹配,导致你分配下去的资源都浪费掉了。
合理的并⾏度的设置,应该要设置的⾜够⼤,⼤到可以完全合理的利⽤你的集群资源;⽐如上⾯的例⼦,总共集群有150个cpu core ,可以并⾏运⾏150个task。
那么你就应该将你的Application 的并⾏度,⾄少设置成150个,才能完全有效的利⽤你的集群资源,让150个task ,并⾏执⾏,⽽且task增加到150个以后,即可以同时并⾏运⾏,还可以让每个task要处理的数量变少;⽐如总共 150G 的数据要处理,如果是100个task ,每个task 要计算1.5G的数据。
Spark详解(09)-Spark调优Spark详解(09) - Spark调优Spark 性能调优常规性能调优常规性能调优⼀:最优资源配置Spark性能调优的第⼀步,就是为任务分配更多的资源,在⼀定范围内,增加资源的分配与性能的提升是成正⽐的,实现了最优的资源配置后,在此基础上再考虑进⾏后⾯论述的性能调优策略。
资源的分配在使⽤脚本提交Spark任务时进⾏指定,标准的Spark任务提交脚本如下所⽰:1. bin/spark-submit \2. --class com.zhangjk.spark.Analysis \3. --master yarn4. --deploy-mode cluster5. --num-executors 80 \6. --driver-memory 6g \7. --executor-memory 6g \8. --executor-cores 3 \9. /usr/opt/modules/spark/jar/spark.jar \可以进⾏分配的资源如表所⽰:名称说明--num-executors配置Executor的数量--driver-memory配置Driver内存(影响不⼤)--executor-memory配置每个Executor的内存⼤⼩--executor-cores配置每个Executor的CPU core数量调节原则:尽量将任务分配的资源调节到可以使⽤的资源的最⼤限度。
对于具体资源的分配,分别讨论Spark的两种Cluster运⾏模式:第⼀种是Spark Standalone模式,在提交任务前,⼀定知道或者可以从运维部门获取到可以使⽤的资源情况,在编写submit脚本的时候,就根据可⽤的资源情况进⾏资源的分配,⽐如说集群有15台机器,每台机器为8G内存,2个CPU core,那么就指定15个Executor,每个Executor分配8G内存,2个CPU core。
Spark性能优化指南1 Spark开发调优篇原则一:避免创建重复的RDD原则二:尽可能复用同一个RDD原则三:对多次使用的RDD进行持久化原则四:尽量避免使用shuffle类算子因此在我们的开发过程中,能避免则尽可能避免使用reduceByKey、join、distinct、repartition等会进行shuffle的算子,尽量使用map类的非shuffle算子。
这样的话,没有shuffle操作或者仅有较少shuffle操作的Spark作业,可以大大减少性能开销。
原则五:使用map-side预聚合的shuffle操作原则六:使用高性能的算子1. 使用reduceByKey/aggregateByKey替代groupByKey详情见“原则五:使用map-side预聚合的shuffle操作”。
2. 使用mapPartitions替代普通mapmapPartitions类的算子,一次函数调用会处理一个partition所有的数据,而不是一次函数调用处理一条,性能相对来说会高一些。
但是有的时候,使用mapPartitions会出现OOM(内存溢出)的问题。
因为单次函数调用就要处理掉一个partition所有的数据,如果内存不够,垃圾回收时是无法回收掉太多对象的,很可能出现OOM异常。
所以使用这类操作时要慎重!3. 使用foreachPartitions替代foreach原理类似于“使用mapPartitions替代map”,也是一次函数调用处理一个partition的所有数据,而不是一次函数调用处理一条数据。
在实践中发现,foreachPartitions类的算子,对性能的提升还是很有帮助的。
比如在foreach函数中,将RDD中所有数据写MySQL,那么如果是普通的foreach算子,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。
[Spark性能调优]第⼀章:性能调优的本质、Spark资源使⽤原理和调优要点分析本課主題⼤数据性能调优的本质Spark 性能调优要点分析Spark 资源使⽤原理流程Spark 资源调优最佳实战Spark 更⾼性能的算⼦引⾔我们谈⼤数据性能调优,到底在谈什么,它的本质是什么,以及 Spark 在性能调优部份的要点,这两点让在进⼊性能调优之前都是⼀个⾄关重要的问题,它的本质限制了我们调优到底要达到⼀个什么样的⽬标或者说我们是从什么本源上进⾏调优。
希望这篇⽂章能为读者带出以下的启发:了解⼤数据性能调优的本质了解 Spark 性能调优要点分析了解 Spark 在资源优化上的⼀些参数调优了解 Spark 的⼀些⽐较⾼效的 RDD 操作算⼦⼤数据性能调优的本质编程的时候发现⼀个惊⼈的规律,软件是不存在的!所有编程⾼⼿级别的⼈⽆论做什么类型的编程,最终思考的都是硬件⽅⾯的问题!最终思考都是在⼀秒、⼀毫秒、甚⾄⼀纳秒到底是如何运⾏的,并且基于此进⾏算法实现和性能调优,最后都是回到了硬件!在⼤数据性能的调优,它的本质是硬件的调优!即基于CPU(计算)、Memory(存储)、IO-Disk/ Network(数据交互)基础上构建算法和性能调优!我们在计算的时候,数据肯定是存储在内存中的。
磁盘IO怎么去处理和⽹络IO怎么去优化。
Spark 性能调优要点分析在⼤数据性能本质的思路上,我们应该需要在那些⽅⾯进⾏调优呢?⽐如:并⾏度压缩序例化数据倾斜JVM调优 (例如 JVM 数据结构化优化)内存调优Task性能调优 (例如包含 Mapper 和 Reducer 两种类型的 Task)Shuffle ⽹络调优 (例如⼩⽂件合并)RDD 算⼦调优 (例如 RDD 复⽤、⾃定义 RDD)数据本地性容错调优参数调优⼤数据最怕的就是数据本地性(内存中)和数据倾斜或者叫数据分布不均衡、数据转输,这个是所有分布式系统的问题!数据倾斜其实是跟你的业务紧密相关的。
Spark实践--性能优化基础1. 性能调优相关的原理讲解、经验总结;2. 掌握⼀整套Spark企业级性能调优解决⽅案;⽽不只是简单的⼀些性能调优技巧。
3. 针对写好的spark作业,实施⼀整套数据倾斜解决⽅案:实际经验中积累的数据倾斜现象的表现,以及处理后的效果总结。
调优前⾸先要对spark的作业流程清楚:Driver到Executor的结构;Master: Driver|-- Worker: Executor|-- job|-- stage|-- Task Task⼀个Stage内,最终的RDD有多少个partition,就会产⽣多少个task,⼀个task处理⼀个partition的数据;作业划分为task分到Executor上,然后⼀个cpu core执⾏⼀个task;BlockManager负责Executor,task的数据管理,task来它这⾥拿数据;1.1 资源分配性能调优的王道:分配更多资源。
分配哪些资源? executor、cpu per executor、memory per executor、driver memory在哪⾥分配这些资源?在我们在⽣产环境中,提交spark作业时,⽤的spark-submit shell脚本,⾥⾯调整对应的参数/usr/local/spark/bin/spark-submit \--class cn.spark.sparktest.core.WordCountCluster \--driver-memory 1000m \ #driver的内存,影响不⼤,只要不出driver oom--num-executors 3 \ #executor的数量--executor-memory 100m \ #每个executor的内存⼤⼩--executor-cores 3 \ #每个executor的cpu core数量/usr/local/SparkTest-0.0.1-SNAPSHOT-jar-with-dependencies.jar \如何调节资源分配第⼀种,Spark Standalone 模式下资源分配。
1. 2. 3. 4. 1. 2. 3. 1. 2. 3. 4. Spark性能调优1 调度与分区优化小分区合并问题:频繁的filter过滤或者过滤掉的数据量过大就会产生问题,造成大量小分区的产生(每个分区数据量小)。
由于Spark是每个数据分区都会分配一个任务执行,如果任务过多,则每个任务处理的数据量很小,会造成线程切换开销大,很多任务等待执行,并行度不高的问题。
解决方式:可以采用RDD中重分区的函数进行数据紧缩,减少分区数,将小分区合并变为大分区。
通过coalesce函数来减少分区。
倾斜问题: 倾斜(skew)有数据倾斜和任务倾斜两种情况,数据倾斜导致的结果即为任务倾斜,在个别分区上,任务执行时间过长。
的原因大致有以下几种:数据倾斜1)key的数据分布不均匀(一般是分区key取得不好或者分区函数设计得不好)。
2)业务数据本身就会产生数据倾斜(像TPC-DS为了模拟真实环境负载特意用有倾斜的数据进行测试)。
3)结构化数据表设计问题。
4)某些SQL语句会产生数据倾斜。
解决方案:1)增大任务数,减少每个分区数据量:增大任务数,也就是扩大分区量,同时减少单个分区的数据量。
2)对特殊key处理:空值映射为特定Key,然后分发到不同节点,对空值不做处理。
3)广播。
①小数据量表直接广播。
②数据量较大的表可以考虑切分为多个小表,多阶段进行Map Side Join。
4)聚集操作可以Map端聚集部分结果,然后Reduce端合并,减少Reduce端压力。
5)拆分RDD:将倾斜数据与原数据分离,分两个Job进行计算。
产生任务倾斜的原因较为隐蔽,一般就是那台机器的正在执行的Executor执行时间过长,因为服务器架构,或JVM,也可任务倾斜:能是来自线程池的问题,等等。
解决方式:可以通过考虑在其他并行处理方式中间加入聚集运算,以减少倾斜数据量。
数据倾斜一般可以通过在业务上将极度不均匀的数据剔除解决。
这里其实还有SkewJoin的一种处理方式,将数据分两个阶段处理,倾斜的key数据作为数据源处理,剩下的key的数据再做同样的处理。
Spark性能调优篇⼀之任务提交参数调整问题⼀:有哪些资源可以分配给spark作业使⽤?答案:executor个数,cpu per exector(每个executor可使⽤的CPU个数),memory per exector(每个executor可使⽤的内存),driver memory问题⼆:在什么地⽅分配资源给spark作业?答案:很简单,就是在我们提交spark作业的时候的脚本中设定,具体如下(这⾥以我的项⽬为例)/usr/local/spark/bin/spark-submit \--class com.xingyun.test.WordCountCluster \--num-executors 3 \*配置executor的数量 *\--driver-memory 100m \*配置driver的内存(影响不⼤)*\--executor-memory 100m \*配置每个executor的内存⼤⼩ *\--executor-cores 3 \*配置每个executor的cpu core数量 *\/usr/local/SparkTest-0.0.1-SNAPSHOT-jar-with-dependencies.jar \我们该如何设定这些参数的⼤⼩呢?下⾯分两种情况讨论。
case1:把spark作业提交到Spark Standalone上⾯。
⼀般⾃⼰知道⾃⼰的spark测试集群的机器情况。
举个例⼦:⽐如我们的测试集群的机器为每台4G内存,2个CPU core,5台机器。
这⾥以可以申请到最⼤的资源为例,那么 --num-executors 参数就设定为 5,那么每个executor平均分配到的资源为:--executor-memory 参数设定为4G,--executor-cores 参数设定为 2 。
case2:把spark作业提交到Yarn集群上去。
那就得去看看要提交的资源队列中⼤概还有多少资源可以背调度。
Spark性能优化:shuffle调优shuffle调优调优概述大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。
因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优。
但是也必须提醒大家的是,影响一个Spark作业性能的因素,主要还是代码开发、资源参数以及数据倾斜,shuffle调优只能在整个Spark的性能调优中占到一小部分而已。
因此大家务必把握住调优的基本原则,千万不要舍本逐末。
下面我们就给大家详细讲解shuffle的原理,以及相关参数的说明,同时给出各个参数的调优建议。
ShuffleManager发展概述在Spark的源码中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。
而随着Spark的版本的发展,ShuffleManager 也在不断迭代,变得越来越先进。
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。
该ShuffleManager而HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件,进而由大量的磁盘IO操作影响了性能。
因此在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。
SortShuffleManager相较于HashShuffleManager来说,有了一定的改进。
主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。
在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
下面我们详细分析一下HashShuffleManager和SortShuffleManager的原理。
HashShuffleManager运行原理未经优化的HashShuffleManager下图说明了未经优化的HashShuffleManager的原理。
这里我们先明确一个假设前提:每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间都只能执行一个task线程。
我们先从shuffle write开始说起。
shuffle write阶段,主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个task处理的数据按key进行“分类”。
所谓“分类”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。
在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
那么每个执行shuffle write的task,要为下一个stage创建多少个磁盘文件呢?很简单,下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。
比如下一个stage总共有100个task,那么当前stage的每个task都要创建100份磁盘文件。
如果当前stage有50个task,总共有10个Executor,每个Executor执行5个Task,那么每个Executor上总共就要创建500个磁盘文件,所有Executor上会创建5000个磁盘文件。
由此可见,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
接着我们来说说shuffle read。
shuffle read,通常就是一个stage刚开始时要做的事情。
此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。
由于shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。
每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。
聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。
以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
优化后的HashShuffleManager下图说明了优化后的HashShuffleManager的原理。
这里说的优化,是指我们可以设置一个参数,spark.shuffle.consolidateFiles。
该参数默认值为false,将其设置为true即可开启优化机制。
通常来说,如果我们使用HashShuffleManager,那么都建议开启这个选项。
开启consolidate机制之后,在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。
此时会出现shuffleFileGroup的概念,每个shuffleFileGroup 会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。
一个Executor 上有多少个CPU core,就可以并行执行多少个task。
而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。
当Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件。
也就是说,此时task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。
因此,consolidate机制允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
假设第二个stage有100个task,第一个stage有50个task,总共还是有10个Executor,每个Executor执行5个task。
那么原本使用未经优化的HashShuffleManager 时,每个Executor会产生500个磁盘文件,所有Executor会产生5000个磁盘文件的。
但是此时经过优化之后,每个Executor创建的磁盘文件的数量的计算公式为:CPU core 的数量* 下一个stage的task数量。
也就是说,每个Executor此时只会创建100个磁盘文件,所有Executor只会创建1000个磁盘文件。
SortShuffleManager运行原理SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。
当shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass 机制。
普通运行机制下图说明了普通的SortShuffleManager的原理。
在该模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可能选用不同的数据结构。
如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。
接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。
如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。
排序过后,会分批将数据写入磁盘文件。
默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。
写入磁盘文件是通过Java的BufferedOutputStream实现的。
BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO 次数,提升性能。
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。
最后会将之前所有的临时磁盘文件都进行合并,这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。
此外,由于一个task就只对应一个磁盘文件,也就意味着该task为下游stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
SortShuffleManager由于有一个磁盘文件merge的过程,因此大大减少了文件数量。
比如第一个stage有50个task,总共有10个Executor,每个Executor执行5个task,而第二个stage有100个task。
由于每个task最终只有一个磁盘文件,因此此时每个Executor上只有5个磁盘文件,所有Executor只有50个磁盘文件。
bypass运行机制下图说明了bypass SortShuffleManager的原理。
bypass运行机制的触发条件如下:•shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
•不是聚合类的shuffle算子(比如reduceByKey)。
此时task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。
当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。
最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。
因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。