编译原理_实验报告实验二__语法分析(算符优先) 2
- 格式:doc
- 大小:552.50 KB
- 文档页数:10

编译原理语法分析实验报告第一篇:编译原理语法分析实验报告实验2:语法分析1.实验题目和要求题目:语法分析程序的设计与实现。
实验内容:编写语法分析程序,实现对算术表达式的语法分析。
要求所分析算术表达式由如下的文法产生。
E→E+T|E-T|TT→T*F|T/F|F F→id|(E)|num实验要求:在对输入表达式进行分析的过程中,输出所采用的产生式。
方法1:编写递归调用程序实现自顶向下的分析。
方法2:编写LL(1)语法分析程序,要求如下。
(1)编程实现算法4.2,为给定文法自动构造预测分析表。
(2)编程实现算法4.1,构造LL(1)预测分析程序。
方法3:编写语法分析程序实现自底向上的分析,要求如下。
(1)构造识别所有活前缀的DFA。
(2)构造LR分析表。
(3)编程实现算法4.3,构造LR分析程序。
方法4:利用YACC自动生成语法分析程序,调用LEX自动生成的词法分析程序。
实现(采用方法1)1.1.步骤:1)对文法消除左递归E→TE'E'→+TE'|-TE'|εT→FT'T'→*FT'|/FT'|εF→id|(E)|num2)画出状态转换图化简得:3)源程序在程序中I表示id N表示num1.2.例子:a)例子1 输入:I+(N*N)输出:b)例子2 输入:I-NN 输出:第二篇:编译原理实验报告编译原理实验报告报告完成日期 2018.5.30一.组内分工与贡献介绍二.系统功能概述;我们使用了自动生成系统来完成我们的实验内容。
我们设计的系统在完成了实验基本要求的前提下,进行了一部分的扩展。
增加了声明变量类型、类型赋值判定和声明的变量被引用时作用域的判断。
从而使得我们的实验结果呈现的更加清晰和易懂。
三.分系统报告;一、词法分析子系统词法的正规式:标识符(|)* 十进制整数0 |(1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)* 八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)* 十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)* 运算符和分隔符 +| * | / | > | < | = |(|)| <=|>=|==;对于标识符和关键字: A5—〉 B5C5 B5—〉a | b |⋯⋯| y | z C5—〉(a | b |⋯⋯| y | z |0|1|2|3|4|5|6|7|8|9)C5|ε综上正规文法为: S—〉I1|I2|I3|A4|A5 I1—〉0|A1 A1—〉B1C1|ε C1—〉E1D1|ε D1—〉E1C1|εE1—〉0|1|2|3|4|5|6|7|8|9 B1—〉1|2|3|4|5|6|7|8|9 I2—〉0A2 A2—〉0|B2 B2—〉C2D2 D2—〉F2E2|ε E2—〉F2D2|εC2—〉1|2|3|4|5|6|7 F2—〉0|1|2|3|4|5|6|7 I3—〉0xA3 A3—〉B3C3 B3—〉0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f C3—〉(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)|C3|εA4—〉+ |-| * | / | > | < | = |(|)| <=|>=|==; A5—〉 B5C5 B5—〉a | b |⋯⋯| y | z C5—〉(a | b |⋯⋯| y | z |0|1|2|3|4|5|6|7|8|9)C5|ε状态图流程图:词法分析程序的主要数据结构与算法考虑到报告的整洁性和整体观感,此处我们仅展示主要的程序代码和算法,具体的全部代码将在整体的压缩包中一并呈现另外我们考虑到后续实验中,如果在bison语法树生成的时候推不出目标的产生式时,我们设计了报错提示,在这个词的位置出现错误提示,将记录切割出来的词在code.txt中保存,并记录他们的位置。

编译原理课程实验报告实验2:语法分析
(2)输出针对此测试程序对应的语法错误报告;
四、实验中遇到的问题总结
(一)实验过程中遇到的问题如何解决的?
问题1:关于action表中需要存储空‘#’以代表在某个状态读入空后所应该进行的动作,如何在action表中安排空这一列?
答:以0代表空,所以action表的列数为终结符数量加1,其中第0列表示某状态读入空时应该执行的动作。
问题2:关于数据结构,显然,文法中的终结符和非终结符都应该有一个唯一的标号来标识这是哪个文法符号,如何进行存储(文件和内存中)?用什么约束使得处理得到简化?答:我是通过一个short型的整型数标识文法符号的;文法输入文件的约束是,以终极符的数量加一为第一个非终结符的标识值,之后依次加一,必须连续且不重复。
对于终结符,从1开始为第1个终结符的标识值(0代表空),以后依次加一,必须连续且不重复;如此设计可以方便后续的action表和goto表的构建和查询操作。
问题3:构建项目集规范族或计算first集和follow集的过程中常常需要用到集合操作,如何编写相关代码?
答:可以直接使用现有的库或者自己实现一个set数据结构。

编译原理实验报告一、实验目的编译原理是计算机科学中的重要学科,它涉及到将高级编程语言转换为计算机能够理解和执行的机器语言。
本次实验的目的是通过实际操作和编程实践,深入理解编译原理中的词法分析、语法分析、语义分析以及中间代码生成等关键环节,提高我们对编译过程的认识和编程能力。
二、实验环境本次实验使用的编程语言为C++,开发环境为Visual Studio 2019。
此外,还使用了一些相关的编译工具和调试工具,如 GDB 等。
三、实验内容(一)词法分析器的实现词法分析是编译过程的第一步,其任务是将输入的源程序分解为一个个单词符号。
在本次实验中,我们使用有限自动机的理论来设计和实现词法分析器。
首先,定义了各种单词符号的类别,如标识符、关键字、常量、运算符等。
然后,根据这些类别设计了相应的状态转换图,并将其转换为代码实现。
在实现过程中,使用了正则表达式来匹配输入字符串中的单词符号。
对于标识符和常量等需要进一步处理的单词符号,使用了相应的规则进行解析和转换。
(二)语法分析器的实现语法分析是编译过程的核心环节之一,其任务是根据给定的语法规则,分析输入的单词符号序列是否符合语法结构。
在本次实验中,我们使用了递归下降的语法分析方法。
首先,根据实验要求定义了语法规则,并将其转换为相应的递归函数。
在递归函数中,通过对输入单词符号的判断和处理,逐步分析语法结构。
为了处理语法错误,在分析过程中添加了错误检测和处理机制。
当遇到不符合语法规则的输入时,能够输出相应的错误信息,并尝试进行恢复。
(三)语义分析及中间代码生成语义分析的目的是对语法分析得到的语法树进行语义检查和语义处理,生成中间代码。
在本次实验中,我们使用了三地址码作为中间代码的表示形式。
在语义分析过程中,对变量的定义和使用、表达式的计算、控制流语句等进行了语义检查和处理。
对于符合语义规则的语法结构,生成相应的三地址码指令。
四、实验步骤(一)词法分析器的实现步骤1、定义单词符号的类别和对应的正则表达式。


编译原理实验报告——算符优先文法分析指导教师:***学号:**********姓名:***【实验名称】算符优先文法分析【实验目的】掌握算符优先分析法的原理,利用算符优先分析法将赋值语句进行语法分析,翻译成等价的四元式表示。
【实验内容】1.算术表达式的文法可以是:(1)S->#E# (2)E->E+T (3)E->T (4)T->T*F (5)T->F (6)F->P^F (7)F->P (8)P->(E) (9)P->i2.根据算符优先分析法,将表达式进行语法分析,判断一个表达式是否正确。
【设计思想】(1)定义部分:定义常量、变量、数据结构。
(2)初始化:设立算符优先关系表、初始化变量空间(包括堆栈、结构体、数组、临时变量等);(3)控制部分:从键盘输入一个表达式符号串;(4)利用算符优先文法分析算法进行表达式处理:根据优先关系表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。
【流程图】【源码】#include <iostream>#include <cstdio>#include <cstdlib>#include <cstring>#include <stack>using namespace std;struct Node1{char vn;char vt;char s[10];}MAP[20];//存储分析预测表每个位置对应的终结符,非终结符,产生式int k;//用R代表E',W代表T',e代表空char G[10][10]={"E->TR","R->+TR","R->e","T->FW","W->*FW","W->e","F->(E)","F->i"};//存储文法中的产生式char VN[6]={'E','R','T','W','F'};//存储非终结符char VT[6]={'i','+','*','(',')','#'};//存储终结符char SELECT[10][10]={"(,i","+","),#","(,i","*","+,),#","(","i"};//存储文法中每个产生式对应的SELECT集char Right[10][8]={"->TR","->+TR","->e","->FW","->*FW","->e","->(E)","->i"};stack <char> stak,stak1,stak2;bool compare(char *a,char *b){int i,la=strlen(a),j,lb=strlen(b);for(i=0;i<la;i++)for(j=0;j<lb;j++){if(a[i]==b[j])return 1;}return 0;}char *Find(char vn,char vt){int i;for(i=0;i<k;i++){if(MAP[i].vn==vn && MAP[i].vt==vt)return MAP[i].s;}return "error";}char * Analyse(char * word){char p,action[10],output[10];int i=1,j,l=strlen(word),k=0,l_act,m;while(!stak.empty())stak.pop();stak.push('#');stak.push('E');printf("_________________________________________________________________________ _______\n");printf("\n 对符号串%s的分析过程\n",word);printf(" 步骤栈顶元素剩余输入串推到所用产生式或匹配\n");p=stak.top();while(p!='#'){printf("%7d ",i++);p=stak.top();stak.pop();printf("%6c ",p);for(j=k,m=0;j<l;j++)output[m++]=word[j];output[m]='\0';printf("%10s",output);if(p==word[k]){if(p=='#'){printf(" 接受\n");return "SUCCESS";}printf(" “%c”匹配\n",p);k++;}else{strcpy(action,Find(p,word[k]));if(strcmp(action,"error")==0){printf(" 没有可用的产生式\n");return "ERROR";}printf(" %c%s\n",p,action);int l_act=strlen(action);if(action[l_act-1]=='e')continue;for(j=l_act-1;j>1;j--)stak.push(action[j]);}}if(strcmp(output,"#")!=0)return "ERROR";}int main (){freopen("in.txt","r",stdin);//freopen("out.txt","w",stdout);char source[100];int i,j,flag,l,m;printf("\n为了方便编写程序,用R代表E',W代表T',e代表空\n\n");printf("该文法的产生式如下:\n");for(i=0;i<8;i++)printf(" %s\n",G[i]);printf("\n该文法的SELECT集如下:\n");for(i=0;i<8;i++){printf(" SELECT(%s) = { %s }\n",G[i],SELECT[i]);}//判断是否是LL(1)文法flag=1;for(i=0;i<8;i++){for(j=i+1;j<8;j++){if(G[i][0]==G[j][0]){if(compare(SELECT[i],SELECT[j])){flag=0;break;}}}if(j!=8)break;}if(flag)printf("\n有相同左部产生式的SELECT集合的交集为空,所以文法是LL(1)文法。

华北水利水电学院编译原理实验报告一、实验题目:语法分析(算符优先分析程序)(1)选择最有代表性的语法分析方法算符优先法;(2)选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。
二、实验内容(1)根据给定文法,先求出FirstVt和LastVt集合,构造算符优先关系表(要求算符优先关系表输出到屏幕或者输出到文件);(2)根据算法和优先关系表分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程)(3)给定表达式文法为:G(E’): E’→#E#E→E+T | TT→T*F |FF→(E)|i(4) 分析的句子为:(i+i)*i和i+i)*i三、程序源代#include<stdlib.h>#include<stdio.h>#include<string.h>#include<iostream.h>#define SIZE 128char priority[6][6]; //算符优先关系表数组char input[SIZE]; //存放输入的要进行分析的句子char remain[SIZE]; //存放剩余串char AnalyseStack[SIZE]; //分析栈void analyse();int testchar(char x); //判断字符X在算符优先关系表中的位置void remainString(); //移进时处理剩余字符串,即去掉剩余字符串第一个字符int k;void init()//构造算符优先关系表,并将其存入数组中{priority[0][2]='<';priority[0][3]='<';priority[0][4]='>';priority[0][5]='>';priority[1][0]='>';priority[1][1]='>';priority[1][2]='<';priority[1][3]='<';priority[1][4]='>';priority[1][5]='>';priority[2][0]='>';priority[2][1]='>';priority[2][2]='$';//无优先关系的用$表示priority[2][3]='$';priority[2][4]='>';priority[2][5]='>';priority[3][0]='<';priority[3][1]='<';priority[3][2]='<';priority[3][3]='<';priority[3][4]='=';priority[3][5]='$';priority[4][0]='>';priority[4][1]='>';priority[4][2]='$';priority[4][3]='$';priority[4][4]='>';priority[4][5]='>';priority[5][0]='<';priority[5][3]='<';priority[5][4]='$';priority[5][5]='=';}void analyse()//对所输入的句子进行算符优先分析过程的函数{FILE *fp;fp=fopen("li","a");int i,j,f,z,z1,n,n1,z2,n2;int count=0;//操作的步骤数char a; //用于存放正在分析的字符char p,Q,p1,p2;f=strlen(input); //测出数组的长度for(i=0;i<=f;i++){a=input[i];if(i==0)remainString();if(AnalyseStack[k]=='+'||AnalyseStack[k]=='*'||AnalyseStack[k]=='i'||Analy seStack[k]=='('||AnalyseStack[k]==')'||AnalyseStack[k]=='#')j=k;elsej=k-1;z=testchar(AnalyseStack[j]);//从优先关系表中查出s[j]和a的优先关系if(a=='+'||a=='*'||a=='i'||a=='('||a==')'||a=='#')n=testchar(a);else //如果句子含有不是终结符集合里的其它字符,不合法{printf("错误!该句子不是该文法的合法句子!\n");break;}if(p=='$'){printf("错误!该句子不是该文法的合法句子!\n");return;}if(p=='>'){ for( ; ; ){Q=AnalyseStack[j];if(AnalyseStack[j-1]=='+'||AnalyseStack[j-1]=='*'||AnalyseStack[j-1]=='i'||AnalyseStack[j-1]=='('||AnalyseStack[j-1]==')'||AnalyseStack[j-1]=='#')j=j-1;elsej=j-2;z1=testchar(AnalyseStack[j]);n1=testchar(Q);p1=priority[z1][n1];if(p1=='<') //把AnalyseStack[j+1]~AnalyseStack[k]归约为N{count++;printf("(%d) %s\t%10c\t%5c%17s\t 归约\n",count,AnalyseStack,p,a,remain);fprintf(fp,"(%d) %s\t%17s\t %s\n",count,AnalyseStack,remain,"归约");k=j+1;i--;AnalyseStack[k]='N';int r,r1;r=strlen(AnalyseStack);for(r1=k+1;r1<r;r1++)AnalyseStack[r1]='\0';break;}else}}else{if(p=='<') //表示移进{count++;printf("(%d) %s\t%10c\t%5c%17s\t 移进\n",count,AnalyseStack,p,a,remain);fprintf(fp,"(%d) %s\t%17s\t %s\n",count,AnalyseStack,remain,"移进");k=k+1;AnalyseStack[k]=a;remainString();}else{if(p=='='){z2=testchar(AnalyseStack[j]);n2=testchar('#');p2=priority[z2][n2];if(p2=='='){count++;printf("(%d) %s\t%10c\t%5c%17s\t 接受\n",count,AnalyseStack,p,a,remain);fprintf(fp,"(%d) %s\t%17s\t %s\n",count,AnalyseStack,remain,"接受");printf("该句子是该文法的合法句子。

编译原理语法分析实验报告编译原理实验报告一、实验目的本实验的主要目的是熟悉编译原理中的语法分析算法及相关知识,并通过实际编码实现一个简单的语法分析器。
二、实验内容1.完成一个简单的编程语言的语法定义,并用BNF范式表示;2.基于给定的语法定义,实现自顶向下的递归下降语法分析器;3.实验所用语法应包含终结符、非终结符、产生式及预测分析表等基本要素;4.实现语法分析器的过程中,需要考虑文法的二义性和优先级等问题。
三、实验步骤1.设计一个简单的编程语言的语法,用BNF范式进行表达。
例如,可以定义表达式文法为:<exp> ::= <term> { + <term> , - <term> }<term> ::= <factor> { * <factor> , / <factor> }<factor> ::= <digit> , (<exp>) , <variable><digit> ::= 0,1,2,3,4,5,6,7,8,9<variable> ::= a,b,c,...,z2. 根据所设计的语法,构建语法分析器。
首先定义需要用到的终结符、非终结符和产生式。
例如,终结符可以是+、-、*、/、(、)等,非终结符可以是<exp>、<term>、<factor>等,产生式可以是<exp> ::= <term> + <term> , <term> - <term>等。
3.实现递归下降语法分析器。
根据语法的产生式,编写相应的递归函数进行递归下降分析。
递归函数的输入参数通常是一个输入字符串和当前输入位置,输出结果通常是一个语法树或语法分析错误信息。
4.在语法分析的过程中,需要处理语法的二义性和优先级问题。

西安邮电大学编译原理实验报告学院名称:计算机学院****:***实验名称:语法分析器的设计与实现班级:计科1405班学号:04141152时间:2017年5月12日一.实验目的1.熟悉语法分析的过程2.理解相关文法分析的步骤3.熟悉First集和Follow集的生成二.实验要求对于给定的文法,试编写调试一个语法分析程序:要求和提示:1)可选择一种你感兴趣的语法分析方法(LL(1)、算符优先、递归下降、SLR(1)等)作为编制语法分析程序的依据。
2)对于所选定的分析方法,如有需要,应选择一种合适的数据结构,以构造所给文法的机内表示。
3)能进行分析过程模拟。
如输入一个句子,能输出与句子对应的语法树,能对语法树生成过程进行模拟;能够输出分析过程每一步符号栈的变化情况。
设计一个由给定文法生成First集和Follow集并进行简化的算法动态模拟三.实验内容1.文法:E->TE’E’->+TE’|εT->FT’T’->*FT’|εF->(E)|i:2.程序描述(LL(1)文法)本程序是基于已构建好的某一个语法的预测分析表来对用户的输入字符串进行分析,判断输入的字符串是否属于该文法的句子。
基本实现思想:接收用户输入的字符串(字符串以“#”表示结束)后,对用做分析栈的一维数组和存放分析表的二维数组进行初始化。
然后取出分析栈的栈顶字符,判断是否为终结符,若为终结符则判断是否为“#”且与当前输入符号一样,若是则语法分析结束,输入的字符串为文法的一个句子,否则出错若不为“#”且与当前输入符号一样则将栈顶符号出栈,当前输入符号从输入字符串中除去,进入下一个字符的分析。
若不为“#”且不与当前输入符号一样,则出错。
3.判断是否LL(1)文法要判断是否为LL(1)文法,需要输入的文法G有如下要求:具有相同左部的规则的SELECT集两两不相交,即:SELECT(A→?)∩SELECT(A→?)= ?如果输入的文法都符合以上的要求,则该文法可以用LL(1)方法分析。

实验2 语法分析(算符优先分析)一、实验任务:算术表达式的文法:E→ E+T | E-T | TT→ T*F | T/F | FF→(E)| i根据算符优先分析法,将表达式进行语法分析,判断一个表达式是否正确。
二、实验时间:上机2次。
三、实验过程和指导:(一)准备:1.确定算术表达式的文法,设计出算符优先关系表;2.考虑好设计方案,设计出模块结构、测试数据;3.初步编制好程序。
(二)上机实验:上机调试,发现错误,分析错误,逐渐修改完善。
(三)程序要求:程序输入/输出示例:如参考C语言的运算符。
输入如下表达式(以分号为结束)和输出结果:(1)10输出:正确(2)1+2*(15-6)输出:正确(3)(1+2)/3+4- (11+6/7)输出:正确(4)((1-2)/3+4输出:错误,出错位置是(5)1+2-3+(*4/5)输出:错误,出错位置是注意:1.为降低难度,表达式中不含变量(只含无符号整数);2.可以直接调用此法分析程序,取得单词;3.如果遇到错误的表达式,应输出错误提示信息(该信息越详细越好,最好有详细的出错位置和出错性质说明);4.测试用的表达式事先放在文本文件中,一行存放一个表达式,同时以分号分割。
同时将预期的输出结果写在另一个文本文件中,以便和输出进行对照;5.对学有余力的同学,可增加功能:当判断一个表达式正确时,输出计算结果,计算过程用浮点表示,但要注意不要被0除。
(四)练习该实验的目的和思路:程序比较复杂,需要利用到大量的编译原理,也用到了大量编程技巧和数据结构,通过这个练习可极大提高编程能力。
程序规模大概为300行。
通过练习,掌握对表达式进行处理的一种方法。
(五)为了能设计好程序,注意以下事情:1.模块设计:将程序分成合理的多个模块(函数),每个模块做具体的同一事情。
2.写出(画出)设计方案:模块关系简图、流程图、全局变量、函数接口等。
3.编程时注意编程风格:空行的使用、注释的使用、缩进的使用、变量合理命名等。
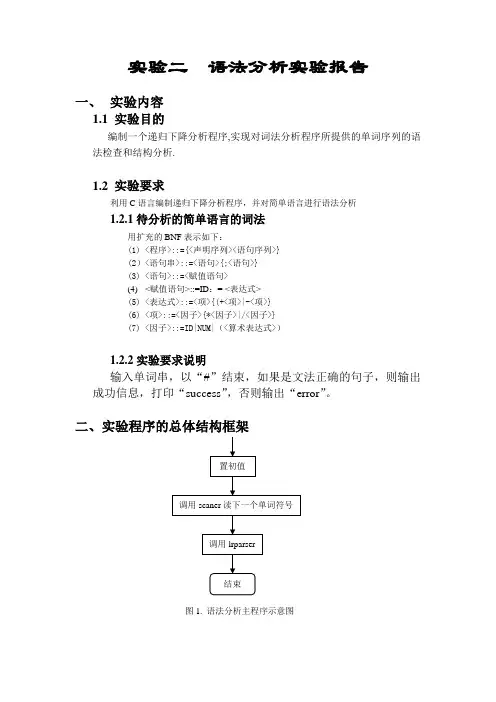
实验二语法分析实验报告一、实验内容1.1 实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析.1.2 实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析1.2.1待分析的简单语言的词法用扩充的BNF表示如下:(1) <程序>::={<声明序列><语句序列>}(2)<语句串>::=<语句>{;<语句>}(3) <语句>::=<赋值语句>(4) <赋值语句>::=ID:= <表达式>(5) <表达式>::=<项>{(+<项>|-<项>}(6) <项>::=<因子>{*<因子>|/<因子>}(7) <因子>::=ID|NUM|(<算术表达式>)1.2.2实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
二、实验程序的总体结构框架图1. 语法分析主程序示意图图2.递归下降分析程序示意图图5. expression表达式分析函数示意图图6.term分析函数示意图三、关键技术的实现方法Scanner函数定义已在实验一给出,本实验不再重复给出void Irparser(){kk=0;if(syn==1){scaner();yucu();if(syn==6){scaner();if(syn==0 && (kk==0)) cout<<"success!"<<endl;}else{if(kk!=1)cout<<"缺end!"<<endl;kk=1;}}else {cout<<"缺begin!"<<endl;kk=1;}return;}void yucu(){statement();while(syn==26){scaner();statement();}return;}void statement() {if(syn==10){scaner();if(syn==18){scaner();expression();}else{cout<<"赋值号错误"<<endl;kk=1;}}else{cout<<"语句错误"<<endl;kk=1;}return;}void expression(){term();while((syn==13)||(syn==14)){scaner();term();}return;}void term(){factor();while((syn==15)||(syn==16)){scaner();factor();}return;}void factor(){if((syn==10)||(syn==11))scaner();else if(syn==27){scaner();expression();if(syn==28)scaner();else{cout<<")错误"<<endl;kk=1;}}else{cout<<"表达式错误"<<endl;kk=1;}return;}void main(){p=0;cout<<"Please input string"<<endl;do{cin.get(ch);if(ch!=”\n”)prog[p++]=ch;}while(ch!='#');p=0;scaner();Irparser();}四、实验心得语法分析是编译过程的核心部分,它的主要功能是按照程序语言的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行语法检查,为语义分析和代码生成做准备。

华北水利水电学院编译原理实验报告2010~2011学年第二学期 xxxx 级计算机专业班级: xxxxx 学号: xxxxx 姓名: xxx一、实验目的通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。
二、实验要求⑴选择最有代表性的语法分析方法,如LL(1)分析法、算符优先法或LR分析法⑵选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。
⑶实习时间为6小时。
三、实验内容选题1:使用预测分析法(LL(1)分析法)实现语法分析:(1)根据给定文法,先求出first集合、follow集合和select集合,构造预测分析表(要求预测分析表输出到屏幕或者输出到文件);(2)根据算法和预测分析表分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程)(3)给定表达式文法为:G(E): S→TEE→+TE | εT→FKK→*FK |εF→(S)|i(4)分析的句子为:(i+i)*i和i+i)*i四、程序源代码#include "stdafx.h"#include "SyntaxAnalysis.h"#include "SyntaxAnalysisDlg.h"#ifdef _DEBUG#define new DEBUG_NEW#undef THIS_ char THIS_FILE[] = __FILE__; #endif/////////////////////////////////////////// // CAboutDlg dialog used for App Aboutclass CAboutDlg : public CDialog{public:CAboutDlg();// Dialog Data//{{AFX_DATA(CAboutDlg)enum { IDD = IDD_ABOUTBOX };//}}AFX_DATA// ClassWizard generated virtual function overrides//{{AFX_VIRTUAL(CAboutDlg)protected:virtual void DoDataExchange(CDataExchange* pDX); // DDX/DDV support//}}AFX_VIRTUAL// Implementationprotected://{{AFX_MSG(CAboutDlg)//}}AFX_MSGDECLARE_MESSAGE_MAP()};CAboutDlg::CAboutDlg() : CDialog(CAboutDlg::IDD){//{{AFX_DATA_INIT(CAboutDlg)//}}AFX_DATA_INIT}voidCAboutDlg::DoDataExchange(CDataExchange* pDX){CDialog::DoDataExchange(pDX);//{{AFX_DATA_MAP(CAboutDlg)//}}AFX_DATA_MAP}BEGIN_MESSAGE_MAP(CAboutDlg, CDialog)//{{AFX_MSG_MAP(CAboutDlg)// No message handlers//}}AFX_MSG_MAPEND_MESSAGE_MAP()// CSyntaxAnalysisDlg dialogCSyntaxAnalysisDlg::CSyntaxAnalysisDlg(CWnd * pParent /*=NULL*/): CDialog(CSyntaxAnalysisDlg::IDD, pParent){//{{AFX_DATA_INIT(CSyntaxAnalysisDl g)m_strCode = _T("");m_strResult = _T("");//}}AFX_DATA_INIT// Note that LoadIcon does not require a subsequent DestroyIcon in Win32 m_hIcon = AfxGetApp()->LoadIcon(IDR_MAINFRAME);}voidCSyntaxAnalysisDlg::DoDataExchange(CDataExc hange* pDX){CDialog::DoDataExchange(pDX);//{{AFX_DATA_MAP(CSyntaxAnalysisDlg)DDX_Control(pDX, IDC_LIST1, m_ListCtrl);DDX_Text(pDX, IDC_EDIT_Code, m_strCode);DDX_Text(pDX, IDC_EDIT_Result, m_strResult);//}}AFX_DATA_MAP}BEGIN_MESSAGE_MAP(CSyntaxAnalysisDlg, CDialog)//{{AFX_MSG_MAP(CSyntaxAnalysisDlg)ON_WM_SYSCOMMAND()ON_WM_PAINT()ON_WM_QUERYDRAGICON()ON_BN_CLICKED(IDC_BTN_Analysis, OnBTNAnalysis)//}}AFX_MSG_MAPEND_MESSAGE_MAP()// CSyntaxAnalysisDlg message handlersBOOL CSyntaxAnalysisDlg::OnInitDialog(){CDialog::OnInitDialog();ASSERT((IDM_ABOUTBOX & 0xFFF0) == IDM_ABOUTBOX);ASSERT(IDM_ABOUTBOX < 0xF000);CMenu* pSysMenu = GetSystemMenu(FALSE);if (pSysMenu != NULL){CString strAboutMenu;strAboutMenu.LoadString(IDS_ABOUTBO X);if (!strAboutMenu.IsEmpty()){pSysMenu->AppendMenu(MF_SEPARATOR);pSysMenu->AppendMenu(MF_STRING, IDM_ABOUTBOX, strAboutMenu);}}SetIcon(m_hIcon, TRUE);// Set big iconSetIcon(m_hIcon, FALSE);// Set small icon// TODO: Add extra initialization here//初始化给定文法m_VN[0]="S";m_VN[1]="E";m_VN[2]="T";m_VN[3]="K";m_VN[4]="F";m_VT[0]="i";m_VT[1]="+";m_VT[2]="*";m_VT[3]="(";m_VT[4]=")";m_Gl[0]=0;m_Gr[0]="TE";m_Gl[1]=1;m_Gr[1]="+TE";m_Gl[2]=1;m_Gr[2]="ε";m_Gl[3]=2;m_Gr[3]="FK";m_Gl[4]=3;m_Gr[4]="*FK";m_Gl[5]=3;m_Gr[5]="ε";m_Gl[6]=4;m_Gr[6]="(S)";m_Gl[7]=4;m_Gr[7]="i";Cal_Symbol();Cal_First();Cal_Follow();DrawMList();return TRUE; // return TRUE unless you set the focus to a control}void CSyntaxAnalysisDlg::OnSysCommand(UINT nID, LPARAM lParam){if ((nID & 0xFFF0) == IDM_ABOUTBOX){CAboutDlg dlgAbout;dlgAbout.DoModal();}else{CDialog::OnSysCommand(nID, lParam);}} void CSyntaxAnalysisDlg::OnPaint(){if (IsIconic()){CPaintDC dc(this);SendMessage(WM_ICONERASEBKGND, (WPARAM) dc.GetSafeHdc(), 0);// Center icon in client rectangleint cxIcon = GetSystemMetrics(SM_CXICON);int cyIcon = GetSystemMetrics(SM_CYICON);CRect rect;GetClientRect(&rect);int x = (rect.Width() - cxIcon + 1) / 2;int y = (rect.Height() - cyIcon + 1) / 2;// Draw the icondc.DrawIcon(x, y, m_hIcon);}else{CDialog::OnPaint();}}CSyntaxAnalysisDlg::OnQueryDragIcon(){return (HCURSOR) m_hIcon;}void CSyntaxAnalysisDlg::Cal_Symbol() //求出能推出ε的非终结符{int i,j,k,nEnd;CString Gr[8];for (i=0;i<5;i++)m_nFlags[i]=0; //置初值,0表示否for (i=0;i<8;i++){Gr[i]=m_Gr[i];if (Gr[i]=="ε"){m_nFlags[m_Gl[i]]=1;//1表示是,即能推出ε}}do{nEnd=0;for (i=0;i<5;i++) //检查每一个非终结符{if (m_nFlags[i]==1) //如果该非终结符能推出ε,就将所有表达式右部删去该终结符{for(j=0;j<8;j++) //查找每一个表达式{if (Gr[j].IsEmpty()||Gr[j]=="ε") continue;for (k=0;k<Gr[j].GetLength();k++) //查找表达式右部的每一个字符{if (Gr[j].GetAt(k)==m_VN[i]) //找到该终结符{Gr[j]=Gr[j].Left(k)+Gr[j].Right(Gr[ j].GetLength()-k-1); //删去该终结符nEnd=1;break;}}if (Gr[j].IsEmpty()) m_nFlags[m_Gl[j]]=1; //如果右部为空,就在表中填是}}}} while(nEnd);}void CSyntaxAnalysisDlg::Cal_First() //求各非终结符的First集合{int i,j,k,nEnd,n;CString strFirst;for (i=0;i<5;i++){for (j=0;j<6;j++)m_First[i][j]=0;}for (i=0;i<8;i++){if (m_Gr[i].Left(2)=="ε"){m_First[m_Gl[i]][5]=1;continue;}strFirst=m_Gr[i].GetAt(0);for (j=0;j<5;j++){if(strFirst==m_VT[j]) //如果右部第一个字符是终结符{m_First[m_Gl[i]][j]=1;break;}}}do{nEnd=0;for (i=0;i<8;i++){n=0;strFirst=m_Gr[i].GetAt(0);do{for(j=0;j<5;j++){if (strFirst==m_VN[j]) //如果右部第一个字符是非终结符{for (k=0;k<6;k++){if(m_First[m_Gl[i]][k]!=m_First[j][k]){m_First[m_Gl[i]][k]=m_First[j][k];nEnd=1;}}if(m_First[j][5]==1&&n<m_Gr[i].GetLength()-1) //前一字符能推出ε,则下一字符的first集也包含于first(x)strFirst=m_Gr[i].GetAt(++n);elsestrFirst="";break;}}if (j==5) break;}while(!strFirst.IsEmpty());}} while(nEnd);}void CSyntaxAnalysisDlg::Cal_Follow() //求各非终结符的Follow集合{}void CSyntaxAnalysisDlg::DrawMList() //构造预测分析表{int i,j;for (i=0;i<5;i++){for (j=0;j<6;j++){m_M[i][j]="";}}m_M[0][0]="TE";m_M[0][3]="TE";m_M[1][1]="+TE";m_M[1][4]="ε";m_M[1][5]="ε";m_M[2][0]="FK";m_M[2][3]="FK";m_M[3][1]="ε";m_M[3][2]="*FK";m_M[3][4]="ε";m_M[3][5]="ε";m_M[4][0]="i";m_M[4][3]="(S)";m_ListCtrl.SetExtendedStyle(LVS_EX_ GRIDLINES);m_ListCtrl.InsertColumn(0,"",LVCFMT _CENTER,50);m_ListCtrl.InsertColumn(1,"i",LVCFM T_CENTER,50);m_ListCtrl.InsertColumn(2,"+",LVCFM T_CENTER,50);m_ListCtrl.InsertColumn(3,"*",LVCFM T_CENTER,50);m_ListCtrl.InsertColumn(4,"(",LVCFM T_CENTER,50);m_ListCtrl.InsertColumn(5,")",LVCFM T_CENTER,50);m_ListCtrl.InsertColumn(6,"#",LVCFM T_CENTER,50);for (i=0;i<5;i++){m_ListCtrl.InsertItem(i,m_VN[i]);for (j=0;j<6;j++){if(!m_M[i][j].IsEmpty())m_ListCtrl.SetItemText(i,j+1,"→"+m_M[i][j]);}}}void CSyntaxAnalysisDlg::OnBTNAnalysis() {UpdateData(true);if (m_strCode.IsEmpty()){MessageBox("请输入要分析的句子!","提醒");return;}if (Analysis())m_strResult+="归约过程如下:\r\n\r\n"+m_sPro.Right(m_sPro.GetLength( )-3);UpdateData(false);}//主要的程序算法BOOL CSyntaxAnalysisDlg::Analysis(){CString stack[100];int pStack;//定义一个顺序栈stack[0]="#";stack[1]="S";pStack=1;//初始化栈int n=0;CString sStack,sCode,str,strCode,strPro;int i,j;strCode=m_strCode+"#"; //输入串m_sPro="<= S";strPro="S";while (1){if (n==m_strCode.GetLength()&&pStack==0) //分析成功{m_strResult="符合给定文法.";return true;}sStack=stack[pStack];//栈顶字符sCode=strCode.GetAt(n);//剩余输入串的首字符if (sStack==sCode) //匹配{pStack--;n++;continue;}for (i=0;i<5;i++){if (sStack==m_VN[i])break;}if (i==5){m_strResult="不符合给定文法!";return false;}for (j=0;j<5;j++){if (sCode==m_VT[j])break;}if (j==5&&sCode!="#") {m_strResult="不可识别的字符: "+sCode; return false;}str=m_M[i][j]; if (str.IsEmpty()) {m_strResult="不符合给定文法!"; return false;}if (str=="ε") { strPro=strPro.Left(n)+strPro.Right(strPro.GetLength()-n-1);m_sPro="<="+strPro+"\r\n"+m_sPro;pStack--; continue;}strPro=strPro.Left(n)+str+strPro.Right(strPro.GetLength()-n-1);m_sPro="<="+strPro+"\r\n"+m_sPro; pStack--;for(j=0;j<str.GetLength();j++) {pStack++;stack[pStack]=str.GetAt(str.GetLength()-j-1); }}五、运行结果分析句子(i+i)*i正确并写出归约此次实验我继续使用VC++6.0平台编译程序,见面力求简洁,以满足实验功能为主。
专题4_算符优先语法分析李若森 13281132 计科1301一、理论传授语法分析的设计方法和实现原理;算符优先文法、最左素短语、算符优先矩阵、优先函数的基本概念;算符优先文法句型最左素短语的确定;算符优先分析算法的实现。
二、目标任务实验项目实现算符优先分析算法,完成以下描述算术表达式的算符优先文法的算符优先分析过程。
G[E]:E→E+T|E-T|TT→T*F|T/F|FF→(E)|i设计说明终结符号i为用户定义的简单变量,即标识符的定义。
加减乘除即运算符。
设计要求(1)构造该算符优先文法的优先关系矩阵或优先函数;(2)输入串应是词法分析的输出二元式序列,即某算术表达式“专题 1”的输出结果,输出为输入串是否为该文法定义的算术表达式的判断结果;(3)算符优先分析程序应能发现输入串出错;(4)设计两个测试用例(尽可能完备,正确和出错),并给出测试结果。
任务分析重点解决算符优先矩阵的构造和算符优先算法的实现。
能力培养深入理解理论对实践的指导作用;基本原理、实现技术和方法的正确运用。
三、实现过程OPG优先关系设G是一OG(简单优先)文法,a,b∈Vt,U,V,W ∈Vn(1)a = b 当且仅当OG有形如U→….ab….或U→….aVb….的规则(2)a < b 当且仅当OG有形如U→….aW….的规则,而且W=+>b….或W=+>Vb…..(3)a > b 当且仅当OG有形如U→….Wb….的规则,而且W=+> …. a或W=+>….aV 若a,b之间至多存在上述三种优先关系之一,OG为OPG(算符优先)文法。
FIRSTVT集和LASTVT集a)FIRSTVT集▪两条原则1.若有规则U→b…或U→Vb…,则b ∈ FIRSTVT(U)2.若有规则U→V…且b ∈ FIRSTVT(V),则b ∈ FIRSTVT(U)▪过程描述数据结构:STACK栈布尔数组F(U,b) U∈Vn,b∈VtF(U,b) 真 b∈FIRSTVT(U)假 b FIRSTVT(U)▪算法分析初始:F(U,b)初值(根据原则①)F(U,b)为真的(U,b)对进STACK栈循环:直至STACK空(根据原则②)弹出栈顶元素,记(V,b)对每一个形如U→V…的规则若F(U,b) 为假,变为真,进STACK栈若F(U,b) 为真,再循环结果:FIRSTVT(U)={b∣F(U,b)=TRUE}FIRSTVT(E)={ +, -, *, /, (, i }FIRSTVT(T)={ *, /, (, i }b)LASTVT集▪两条原则①若有规则U→…a或U→…aV,则a ∈ LASTVT (U)②若有规则U→…V且a ∈ LASTVT (V),则a ∈ LASTVT (U) ▪过程描述数据结构:STACK栈布尔数组F(U,a) U∈Vn,a∈VtF(U,a) 真 a∈LASTVT (U)假 a LASTVT (U)▪算法分析初始:F(U,a)初值(根据原则①)F(U,a)为真的(U,a)对进STACK栈循环:直至STACK空(根据原则②)弹出栈顶元素,记(V,a)对每一个形如U→V…的规则若F(U,a) 为假,变为真,进STACK栈若F(U,a)为真,再循环结果: LASTVT (U)={a∣F(U,a)=TRUE}LASTVT(E)={ +, -, *, /, ), i }LASTVT(T)={ *, /, ), i }最左素短语算符优先文法句型的一般形式:#N1a1N2a2…… N n a n N n+1# a i∈V t N i∈V n(可有可无)最左素短语的确定:一个OPG句型的最左素短语是满足以下条件的最左子串:N j a j…..N i a i N i+1其中:a j-1 < a ja j = a j+1 = … = a i-1 = a ia i > a i+1a j-1 < a j = a j+1= … = a i-1 = a i> a i+1 所以,构造OPG优先矩阵算法根据构造OPG优先矩阵算法,可得如下优先关系:+ FIRSTVT(T) LASTVT(E) +- FIRSTVT(T) LASTVT(E) -* FIRSTVT(F) LASTVT(T) */ FIRSTVT(F) LASTVT(T) /( FIRSTVT(E) LASTVT(E) ) ( )# FIRSTVT(E) LASTVT(E) #所以,构造OPG优先矩阵如表3.3所示:+ - * / ( ) i #acc算法框架主要数据结构pair<int, string>:用pair<int, string>来存储单个二元组。
编译原理课程实验报告实验2:语法分析
三、系统设计得分
要求:分为系统概要设计和系统详细设计。
(1)系统概要设计:给出必要的系统宏观层面设计图,如系统框架图、数据流图、功能模块结构图等以及相应的文字说明。
1)系统的数据流图:
说明
说明:本语法分析器是基于上一个实验词法分析器的基础上,通过在界面写或者是导入源程序,词法分析器将源程序识别的词法单元传递给语法分析器,语法分析器验证这个词法单元组成的串是否可以由源语言的文法生成,能够输出语法分析的结果,文法的first集、follow 集和预测分析表,当然也可以以易于理解的方式报告语法错误。
2)系统框架图
本系统框架主要是三部分,一部分是词法分析,负责识别源程序的词法单元识别,并将其存
因为预测分析表实在是过于庞大,因此本处分段截取预测分析表,下面的表是接在上面表的右侧。
(3)针对一测试程序输出其句法分析结果;
测试程序:
语法分析结果:
语法分析树:
(4)输出针对此测试程序对应的语法错误报告;
带错误的测试程序:
语法错误报告:
(5)对实验结果进行分析。
总结:
本语法分析器具有强大的语法分析功能
●允许变量的连续声明,比如int a,b,c;
●允许声明的同时赋值,比如string c = “你好”;
●允许对数组的声明和引用,同时进行赋值,比如char[4] a = {‘a’,’b’,’c’,’d’};a[0] = ‘m’;
●支持多种类型的声明和赋值,比如int,short,long,flaot,double,char,string,boolean
的声明和赋值;
●允许声明和使用一个过程函数,比如:。
《编译原理》课程实验报告题目语法分析专业计算机科学与技术班级学号姓名指导教师签名华东理工大学信息学院计算机系2013年5月8日一. 实验序号:《编译原理》第二次实验二. 实验题目:语法分析三. 实验日期:2013.4-2013.5四. 实验环境(操作系统,开发语言)操作系统:Windows开发语言:C五. 实验内容(实验要求)a)将复合语句语法中的“begin”改为“{”,“end”改为“}”。
b)将赋值语句的语法改为“赋值语句必须以分号;结束”。
c)将条件语句语法中的“条件”前增加“(”,“条件”后增加“)”但删除“then”d)“语句”语法中增加if-else语句:if (<条件>) <语句> else <语句>六. 实验体会(请手写,不能打印)(包括收获、心得体会、存在的问题及解决问题的方法、建议等)七. 实验结果(运行结果截图,关键源程序)复合语句更改后的程序:int CompoundStatement(int i){ PrintParsing(ResultofWordTable[AWordIndex],i,"OB");AWordIndex++;StatementParsing(i+1);while (ResultofWordTable[AWordIndex].W_Type==SEMICOLON){ PrintParsing(ResultofWordTable[AWordIndex],i,"SEMICOLOM");AWordIndex++;StatementParsing(i+1);}if (ResultofWordTable[AWordIndex].W_Type==CB){ PrintParsing(ResultofWordTable[AWordIndex],i,"CB");AWordIndex++;return 1;}elsereturn 0;}赋值语句以分号结尾:int AssignmentStatement(int i){ PrintParsing(ResultofWordT able[AWordIndex],i,"IDENTIFIER");AWordIndex++;if (ResultofWordTable[AWordIndex].W_Type==BECOMES){ PrintParsing(ResultofWordTable[AWordIndex],i,"BECOMES");AWordIndex++;Expression(i+1);if (ResultofWordTable[AWordIndex].W_Type==SEMICOLON){ PrintParsing(ResultofWordTable[AWordIndex],i,"SEMICOLON");AWordIndex++;return 1;}elsereturn 0;}elsereturn 0;}条件语句修改后:int ConditionalStatement(int i){ PrintParsing(ResultofWordTable[AWordIndex],i,"IF");AWordIndex++;if (ResultofWordTable[AWordIndex].W_Type==LPAREN){ PrintParsing(ResultofWordTable[AWordIndex],i,"LPAREN");AWordIndex++;Conditional(i);if (ResultofWordTable[AWordIndex].W_Type==RPAREN){ PrintParsing(ResultofWordTable[AWordIndex],i,"RPAREN");AWordIndex++;StatementParsing(i+1);if (ResultofWordTable[AWordIndex].W_Type==ELSE){ PrintParsing(ResultofWordTable[AWordIndex],i,"ELSE");AWordIndex++;StatementParsing(i+1);return 1; }}elsereturn 0;}elsereturn 0;}其他一些程序代码:主函数:int main(int , char* ){ FILE *fp;if((fp=fopen(FILE_NAME,"r"))==NULL)printf( "Can’t open the file!\n" );if((fp=fopen(FILE_RESULT,"w+"))==NULL)printf( " Can’t open the file!\n" );char ch; //定义读到的每个字符ch = fgetc(fp); //从文件中读入一个字符while(ch != EOF) //按读入字符逐个输出在屏幕中{ putchar(ch);ch = fgetc(fp);}Initialize(); //初始化printf("----------- Parsing Analysis!------------\n");printf("Index Rows Word Analysis\n");ParsingAnalysisFunction(Index);printf("-------------------END------------------\n");getchar();return 0;}分程序分析:int BlockParsing(int i){ PrintParsing(ResultofWordTable[AWordIndex],i-1,"BlockParsing");if(ResultofWordTable[AWordIndex].W_Type==CONST){PrintParsing(ResultofWordTable[AWordIndex],i,"CONST");AWordIndex++;PrintParsing(ResultofWordTable[AWordIndex],i,"oneConstantParsing");oneConstantParsing(i+1); //常量声明分析}if(ResultofWordTable[AWordIndex].W_Type==VAR){PrintParsing(ResultofWordTable[AWordIndex],i,"VAR");AWordIndex++;PrintParsing(ResultofWordTable[AWordIndex],i,"oneVarParsing");oneVariableParsing(i+1); //变量声明分析}while(ResultofWordT able[AWordIndex].W_Type==PROCEDURE){ PrintParsing(ResultofWordTable[AWordIndex],i,"PROCEDURE");AWordIndex++;PrintParsing(ResultofWordTable[AWordIndex],i,"oneProcesureParsing");ProcedureParsing(i+1); //过程声明分析}StatementParsing(i);return 1;}过程调用语句:int ProcedureCall(int i){ PrintParsing(ResultofWordTable[AWordIndex],i,"CALL");AWordIndex++;if (ResultofWordTable[AWordIndex].W_Type==IDENTIFIER){ PrintParsing(ResultofWordTable[AWordIndex],i,"IDENTIFIER");AWordIndex++;return 1;}elsereturn 0;}循环语句分析:int LoopStatement(int i){ PrintParsing(ResultofWordTable[AWordIndex],i,"WHILE");AWordIndex++;Conditional(i);if (ResultofWordTable[AWordIndex].W_Type==DO){ PrintParsing(ResultofWordTable[AWordIndex],i,"DO");AWordIndex++;StatementParsing(i+1);return 1;}elsereturn 0;}实验结果截图:。
实验一词法分析一、实验目的通过设计、编写和调试词法分析程序,了解词法分析程序的作用,组成结构,不同种类单词的识别方法,掌握由单词的词法规则出发,画出识别单词的状态转换图,然后在用程序实现词法分析程序设计方法。
二、词法规则1、注释用{和}括起来。
注释体中不能有{。
注释可以出现在任何记号的后面。
2、记号间的空格可有可无,但关键字前后必须有空格、换行、程序的开头或者结尾的原点。
3、标识符的记号id 与以字母开头的字母数字串相匹配:Letter->[a-zA-Z]Digit->[0-9]Id->letter (letter | digit)*4、记号num与无符号整数相匹配:Digits->digit digit*Optional_fraction -> . Digits | ɛOptional_exponent->(E(+ | - | ɛ ) digits) | ɛNum ->digits optional_fraction optional_exponent5、关键字要被保留且在文法中以黑体出现6、关系运算符(relop)指:=、<、<>、<=、>=、>7、Addop: + 、 - 、or8、Mulop:*、/ 、div、mod、and9、Assignop: :=三、词法分析程序详细设计及判别状态图1、无符号数(可带小数和指数)的状态转换图:2、标识符/关键字的状态转换图:字母或数程序详细设计:四、开发环境本程序在Microsoft Visual C++ 6.0环境中编写,无特殊编译要求。
五、函数清单void LexcialAnalysis(FILE *fp);//词法分析主函数int JudgeFirstLetter(char ch);//判断单词的第一个字符int IsDigit(char ch);//判断是否为数字int IsLetter(char ch);//判断是否为字母int IsSpecialPunc(char ch);//判断是否为特殊标点void RecogDigit(char StrLine[]);//用状态图识别无符号数字void RecogIdentifier(char strLine[]);//用状态图识别标识符void RecogPunc(char strLine[]);//识别特殊标点int IsKeyWord(string str);//判断标识符是否为关键字void error();//出错处理六、测试程序program example(input, output);{comments goes here!}var x, y: integer;function gcd(a, b: integer): integer;beginif b =1.2e3 then gcd := aelse gcd := gcd(b, a mod b)end;beginread(x, y);write(gcd(x, y));end.七、运行效果八、实验总结通过这次编译器词法分析程序的编写,我更好地了解了词法分析的作用及工作原理,讲课本中的知识融入到程序编写过程中,理论结合了实际。
编译原理算符优先算法语法分析实验报告实验报告:算符优先算法的语法分析一、实验目的本次实验旨在通过算符优先算法对给定的文法进行语法分析,实现对给定输入串的分析过程。
通过本次实验,我们能够了解算符优先算法的原理和实现方式,提升对编译原理的理解和应用能力。
二、实验内容1.完成对给定文法的定义和构造2.构造算符优先表3.实现算符优先分析程序三、实验原理算符优先算法是一种自底向上的语法分析方法,通过构造算符优先表来辅助分析过程。
算符优先表主要由终结符、非终结符和算符优先关系组成,其中算符优先关系用1表示优先关系,用2表示不优先关系,用0表示无关系。
算符优先分析程序的基本思路是:根据算符优先关系,依次将输入串的符号压栈,同时根据优先关系对栈内符号进行规约操作,最终判断输入串是否属于给定文法。
四、实验步骤1.定义和构造文法在本次实验中,我们假设给定文法如下:1)E->E+T,T2)T->T*F,F3)F->(E),i2.构造算符优先表根据给定文法,构造算符优先表如下:+*()i#+212112*222112(111012222122i222222#1112203.实现算符优先分析程序我们可以用C语言编写算符优先分析程序,以下是程序的基本框架:```c#include <stdio.h>//判断是否为终结符int isTerminal(char c)//判断条件//匹配符号int match(char stack, char input)//根据算符优先关系表进行匹配//算符优先分析程序void operatorPrecedence(char inputString[]) //定义栈char stack[MAX_SIZE];//初始化栈//将#和起始符号入栈//读入输入串//初始化索引指针//循环分析输入串while (index <= inputLength)//判断栈顶和输入符号的优先关系if (match(stack[top], inputString[index])) //栈顶符号规约} else//符号入栈}//计算新的栈顶}//判断是否成功分析if (stack[top] == '#' && inputString[index] == '#')printf("输入串符合给定文法!\n");} elseprintf("输入串不符合给定文法!\n");}```五、实验结果经过实验,我们成功实现了算符优先算法的语法分析。
编译原理语法分析实验报告编译原理实验报告二、语法分析(一) 实验题目编写程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析。
(二) 实验内容和要求1. 要求程序至少能分析的语言的内容有:1) 变量说明语句2) 赋值语句3) 条件转移语句4) 表达式(算术表达式和逻辑表达式)5) 循环语句6) 过程调用语句2. 此外要处理:包括依据文法对句子进行分析;出错处理;输出结果的构造。
3. 输入输出的格式:输入:单词文件(词法分析的结果)输出:语法成分列表或语法树(都用文件表示),错误文件(对于不合文法的句子)。
4. 实现方法:可以采用递归下降分析法,LL(1)分析法,算符优先法或LR分析法的任何一种,也可以针对不同的句子采用不同的分析方法。
(三) 实验分析与设计过程1. 待分析的C语言子集的语法:该语法为一个缩减了的C语言文法,估计是整个C语言所有文法的60%(各种关键字的定义都和词法分析中的一样),具体的文法如下:语法:100: program -> declaration_list101: declaration_list -> declaration_list declaration | declaration 102: declaration -> var_declaration|fun_declaration103: var_declaration -> type_specifier ID;|type_specifier ID[NUM]; 104: type_specifier -> int|void|float|char|long|double|105: fun_declaration -> type_specifier ID (params)|compound_stmt 106: params -> params_list|void107: param_list ->param_list,param|param108: param -> type-spectifier ID|type_specifier ID[]109: compound_stmt -> {local_declarations statement_list}110: local_declarations -> local_declarations var_declaration|empty 111: statement_list -> statement_list statement|empty11编译原理实验报告112: statement -> epresion_stmt|compound_stmt|selection_stmt|iteration_stmt|return_stmt113: expression_stmt -> expression;|;114: selection_stmt -> if{expression)statement|if(expression)statement else statement115: iteration_stmt -> while{expression)statement116: return_stmt -> return;|return expression;117: expression -> var = expression|simple-expression118: var -> ID |ID[expression]119: simple_expression ->additive_expression relop additive_expression|additive_expression 120: relop -> <=|<|>|>=|= =|!=121: additive_expression -> additive_expression addop term | term 122: addop -> + | -123: term -> term mulop factor | factor124: mulop -> *|/125: factor -> (expression)|var|call|NUM126: call -> ID(args)127: args -> arg_list|empty128: arg_list -> arg_list,expression|expression该文法满足了实验的要求,而且多了很多的内容,相当于一个小型的文法说明:把文法标号从100到128是为了程序中便于找到原来的文法。
华北水利水电学院编译原理实验报告一、实验题目:语法分析(算符优先分析程序)(1)选择最有代表性的语法分析方法算符优先法;(2)选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。
二、实验内容(1)根据给定文法,先求出FirstVt和LastVt集合,构造算符优先关系表(要求算符优先关系表输出到屏幕或者输出到文件);(2)根据算法和优先关系表分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程)(3)给定表达式文法为:G(E’): E’→#E#E→E+T | TT→T*F |FF→(E)|i(4) 分析的句子为:(i+i)*i和i+i)*i三、程序源代#include<stdlib.h>#include<stdio.h>#include<string.h>#include<iostream.h>#define SIZE 128char priority[6][6]; //算符优先关系表数组char input[SIZE]; //存放输入的要进行分析的句子char remain[SIZE]; //存放剩余串char AnalyseStack[SIZE]; //分析栈void analyse();int testchar(char x); //判断字符X在算符优先关系表中的位置void remainString(); //移进时处理剩余字符串,即去掉剩余字符串第一个字符int k;void init()//构造算符优先关系表,并将其存入数组中{priority[0][3]='<';priority[0][4]='>';priority[0][5]='>';priority[1][0]='>';priority[1][1]='>';priority[1][2]='<';priority[1][3]='<';priority[1][4]='>';priority[1][5]='>';priority[2][0]='>';priority[2][1]='>';priority[2][2]='$';//无优先关系的用$表示priority[2][3]='$';priority[2][4]='>';priority[2][5]='>';priority[3][0]='<';priority[3][1]='<';priority[3][2]='<';priority[3][3]='<';priority[3][4]='=';priority[3][5]='$';priority[4][0]='>';priority[4][1]='>';priority[4][2]='$';priority[4][3]='$';priority[4][4]='>';priority[4][5]='>';priority[5][0]='<';priority[5][4]='$';priority[5][5]='=';}void analyse()//对所输入的句子进行算符优先分析过程的函数{FILE *fp;fp=fopen("li","a");int i,j,f,z,z1,n,n1,z2,n2;int count=0;//操作的步骤数char a; //用于存放正在分析的字符char p,Q,p1,p2;f=strlen(input); //测出数组的长度for(i=0;i<=f;i++){a=input[i];if(i==0)remainString();if(AnalyseStack[k]=='+'||AnalyseStack[k]=='*'||AnalyseStack[k]=='i'||Analy seStack[k]=='('||AnalyseStack[k]==')'||AnalyseStack[k]=='#')j=k;elsej=k-1;z=testchar(AnalyseStack[j]);//从优先关系表中查出s[j]和a的优先关系if(a=='+'||a=='*'||a=='i'||a=='('||a==')'||a=='#')n=testchar(a);else //如果句子含有不是终结符集合里的其它字符,不合法{printf("错误!该句子不是该文法的合法句子!\n");break;}if(p=='$'){printf("错误!该句子不是该文法的合法句子!\n");return;}if(p=='>'){ for( ; ; ){Q=AnalyseStack[j];if(AnalyseStack[j-1]=='+'||AnalyseStack[j-1]=='*'||AnalyseStack[j-1]=='i'||Ana lyseStack[j-1]=='('||AnalyseStack[j-1]==')'||AnalyseStack[j-1]=='#')j=j-1;elsej=j-2;z1=testchar(AnalyseStack[j]);n1=testchar(Q);p1=priority[z1][n1];if(p1=='<') //把AnalyseStack[j+1]~AnalyseStack[k]归约为N{count++;printf("(%d) %s\t%10c\t%5c%17s\t 归约\n",count,AnalyseStack,p,a,remain);fprintf(fp,"(%d) %s\t%17s\t %s\n",count,AnalyseStack,remain,"归约");k=j+1;i--;AnalyseStack[k]='N';int r,r1;r=strlen(AnalyseStack);for(r1=k+1;r1<r;r1++)AnalyseStack[r1]='\0';break;}else}}else{if(p=='<') //表示移进{count++;printf("(%d) %s\t%10c\t%5c%17s\t 移进\n",count,AnalyseStack,p,a,remain);fprintf(fp,"(%d) %s\t%17s\t %s\n",count,AnalyseStack,remain,"移进");k=k+1;AnalyseStack[k]=a;remainString();}else{if(p=='='){z2=testchar(AnalyseStack[j]);n2=testchar('#');p2=priority[z2][n2];if(p2=='='){count++;printf("(%d) %s\t%10c\t%5c%17s\t 接受\n",count,AnalyseStack,p,a,remain);fprintf(fp,"(%d) %s\t%17s\t %s\n",count,AnalyseStack,remain,"接受");printf("该句子是该文法的合法句子。
\n");fprintf(fp,"%s","该句子是该文法的合法句子。
\n");break;}else{printf("(%d) %s\t%10c\t%5c%17s\t 移进\n",count,AnalyseStack,p,a,remain);fprintf(fp,"(%d) %s\t%17s\t %s\n",count,AnalyseStack,remain,"移进");k=k+1;AnalyseStack[k]=a;remainString();}}else{printf("错误!该句子不是该文法的合法句子!\n");fprintf(fp,"%s","错误!该句子不是该文法的合法句子。
\n");break;}}}}fclose(fp);}int testchar(char x){int m;if(x=='+')m=0;if(x=='*')m=1;if(x=='i')m=2;if(x=='(')m=3;if(x==')')m=4;if(x=='#')return m;}void remainString(){int i,j;i=strlen(remain);for(j=0;j<i;j++)remain[j]=remain[j+1];remain[i-1]='\0';}void main(){int m,n;char s1[6]={ '+','*','i','(',')','#'};init();printf("文法为:\n");printf("(0)E'->#E#\n");printf("(1)E->E+T\n");printf("(2)E->T\n");printf("(3)T->T*F\n");printf("(4)T->F\n");printf("(5)F->(E)\n");printf("(6)F->i\n");FILE *fp;fp=fopen("li","w");fprintf(fp,"%s","要分析的文法为:\n");fprintf(fp,"%s","(0)E'->#E#\n");fprintf(fp,"%s","(1)E->E+T\n");fprintf(fp,"%s","(2)E->T\n");fprintf(fp,"%s","(3)T->T*F\n");fprintf(fp,"%s","(4)T->F\n");fprintf(fp,"%s","(5)F->(E)\n");fprintf(fp,"%s","(6)F->i\n");fprintf(fp,"%s"," + * i ( ) #\n");for(m=0;m<6;m++){fprintf(fp,"%c ",s1[m]);for(n=0;n<6;n++){fprintf(fp,"%c ",priority[m][n]);}fprintf(fp,"%s","\n");}printf("-----------------------------------------\n");printf(" 算符优先关系表\n");printf(" + * i ( ) #\n");printf(" + > < < < > >\n");printf(" * > > < < > >\n");printf(" i > > > >\n");printf(" ( < < < < = \n");printf(" ) > > > >\n");printf(" # < < < < =\n");printf("-----------------------------------------\n");printf("请输入要进行分析的句子(以#号结束输入):\n");gets(input);//将输入的字符串存到数组中fprintf(fp,"%s","需要分析的字符串为:\n");fprintf(fp,"%s",input);fprintf(fp,"%s","\n");fclose(fp);printf("步骤栈优先关系当前符号剩余输入串移进或归约\n");k=0;AnalyseStack[k]='#';AnalyseStack[k+1]='\0';int length,i; //初始化剩余字符串数组为输入串length=strlen(input);//for(i=0;i<length;i++)remain[i]='\0';analyse();//对所输入的句子进行算符优先分析过程的函数}四、测试结果输入串(i+i)*i的算符优先分析过程输入串i+i)*i的算符优先分析过程五、小结(包括收获、心得体会、存在的问题及解决问题的方法、建议等)本次实验是算符优先分析法,这种方法特别有利于表达式分析,宜于手工实现。