string底层原理
- 格式:docx
- 大小:36.42 KB
- 文档页数:1

str转浮点-概述说明以及解释1.引言1.1 概述概述部分:在编程语言中,常常会遇到将字符串类型转换为浮点数类型的需求。
当我们需要对一些数字进行计算时,通常需要将其从字符串转换为浮点数。
字符串转浮点数的过程涉及到一些类型转换和错误处理的问题。
本文将介绍如何将字符串类型转换为浮点数类型,并探讨在转换过程中可能遇到的异常情况及其处理方法。
首先,我们将讨论如何在常见的编程语言中进行字符串到浮点数的转换操作。
不同的编程语言可能采用不同的转换函数或方法来实现字符串到浮点数的转换。
我们将关注在Python、Java和C++这三种常用的编程语言中的转换方法。
其次,我们将探讨在进行字符串到浮点数转换时可能会遇到的一些异常情况,如输入字符串不符合浮点数的格式、字符串为空等。
针对这些异常情况,我们将介绍一些常见的异常处理机制和技巧,以确保程序能够正确地处理这些异常情况,并给出相应的错误提示。
最后,我们将总结本文的主要内容,并展望未来对字符串转浮点数的研究和应用方向。
字符串转浮点数是编程中常见的操作,而如何处理转换过程中可能出现的异常情况是一个有待进一步研究的问题。
我们期望未来能够有更加高效、准确的方法来处理字符串转浮点数的相关问题,以提高程序的稳定性和可靠性。
通过本文的学习,读者将能够了解到字符串转浮点数的基本概念和常见方法,并掌握如何处理在转换过程中可能出现的异常情况。
这将帮助读者在实际编程中更好地应用字符串转浮点数的技巧,提高程序的质量和效率。
1.2文章结构文章结构部分的内容:本文主要围绕着将字符串(str)转换为浮点数(float)展开讨论。
通过对这一过程的详细介绍,读者将能够了解到在编程中如何正确地将字符串类型的数据转换为浮点数类型的数据,并掌握相应的操作方法。
本篇文章主要分为引言、正文和结论三个部分。
引言部分首先对本文的论题进行了概述,即字符串转浮点。
通过引出这一话题,读者可以了解到在实际的编程过程中,很多时候需要进行不同类型数据之间的相互转换操作,而其中字符串转浮点则是一种常见且重要的类型转换需求。

mapstruct底层原理英文版The Underlying Principles of MapStructIntroductionMapStruct is a code generation library that simplifies the object mapping process between different layers of an application, such as between domain models and data transfer objects (DTOs). It utilizes annotations to generate the boilerplate code, removing the need for manual mapping and thus improving development efficiency. Let's delve into the underlying principles of MapStruct and understand how it works.1. Annotation ProcessingMapStruct's core functionality is built around annotation processing. Developers annotate their mapper interfaces with MapStruct's annotations, such as @Mapper or @MapperConfig. These annotations serve as markers for the MapStruct code generator.2. Code GenerationDuring the build process, MapStruct's code generator intercepts the annotated mapper interfaces and generates their implementations. These implementations handle the actual mapping logic, converting objects from one type to another. The generated code is highly optimized and focused on performance.3. Model MappingMapStruct's mapping logic is based on field-to-field mapping. It compares the source and target object's fields and performs the necessary conversions. This mapping can be straightforward, such as assigning a field's value directly, or it can involve complex transformations, like converting a string toa date.4. Customizations & ExtensionsMapStruct allows for customizations and extensions. Developers can provide their own mapping methods or use custom converters to handle specific mapping scenarios. Thisflexibility allows for seamless integration with various libraries and frameworks.5. PerformanceSince MapStruct generates optimized code during the build process, it provides excellent performance. The generated implementations are fast and efficient, making them suitable for use in production environments.ConclusionMapStruct's underlying principles center around annotation processing, code generation, model mapping, customizations, and performance. By leveraging these principles, MapStruct enables efficient and maintainable object mapping solutions for modern applications.中文版MapStruct底层原理介绍MapStruct是一个代码生成库,它简化了应用程序不同层之间的对象映射过程,例如域模型和数据传输对象(DTO)之间的映射。

ArrayList底层实现contains⽅法的原理。
List实现类ArrayList底层实现contains()的原理实验代码List<String> names= new ArrayList<>();names.add("Jimmy");names.add("tommy");System.out.println(names.contains("Jimmy")); //查询是否包含“Jimmy”contains()源码public boolean contains(Object o) {//此处的o即为contains⽅法中的参数对象,此处指“Jimmy”,o中存储上转型对象return indexOf(o) >= 0;//数值>=0,返回true}public int indexOf(Object o) {return indexOfRange(o, 0, size);//size指调⽤contains()的集合的⼤⼩}int indexOfRange(Object o, int start, int end) {Object[] es = elementData; //将集合中元素放到数组中if (o == null) {//o为null的情况for (int i = start; i < end; i++) {//遍历集合中的元素,直到找到集合中为null的元素为⽌if (es[i] == null) {return i;}}} else {//!o == nullfor (int i = start; i < end; i++) {//if (o.equals(es[i])) {//o调⽤相应的equals()⽅法return i;//返回找到⽐较成功元素的下标}}}return -1;}上⾯o(continue⽅法中的参数对象)调⽤的什么样的equals()⽅法取决于o是什么类型:contains()⽅法中的参数类型调⽤的equals()⽅法String类型String对象中的equals⽅法基本数据类型的包装类包装类中的equals()⽅法类类型类类型中的equals()⽅法分析实现代码的运⾏过程1.当执⾏到names.add("Jimmy");时,调⽤contains()⽅法,其中“Jimmy”赋值给o,o即为String类。

⼀份热乎的字节⾯试真题!(附答案)⾯试题⽬如下:说说 Redis 为什么快Redis 有⼏种数据结构,底层分别是怎么存储的Redis 挂了怎么办?Redis 有⼏种持久化⽅式多线程情况下,如何保证线程安全?⽤过 volatile 吗?底层原理是?MySQL 的索引结构,聚簇索引和⾮聚簇索引的区别MySQL 有⼏种⾼可⽤⽅案,你们⽤的是哪⼀种说说你做过最有挑战性的项⽬秒杀采⽤什么⽅案聊聊分库分表,需要停服嘛你怎么防⽌优惠券有⼈重复刷?抖⾳评论系统怎么设计怎么设计⼀个短链地址有⼀个数组,⾥⾯元素⾮重复,先升序再降序,找出⾥⾯最⼤的值| 基于内存存储实现内存读写是⽐在磁盘快很多的,Redis 基于内存存储实现的数据库,相对于数据存在磁盘的 MySQL 数据库,省去磁盘 I/O 的消耗。
| ⾼效的数据结构MySQL 索引为了提⾼效率,选择了 B+ 树的数据结构。
其实合理的数据结构,就是可以让你的应⽤/程序更快。
先看下 Redis 的数据结构&内部编码图:字符串长度处理:Redis 获取字符串长度,时间复杂度为 O(1),⽽ C 语⾔中,需要从头开始遍历,复杂度为 O(n);空间预分配:字符串修改越频繁的话,内存分配越频繁,就会消耗性能,⽽ SDS 修改和空间扩充,会额外分配未使⽤的空间,减少性能损耗。
惰性空间释放:SDS 缩短时,不是回收多余的内存空间,⽽是 free 记录下多余的空间,后续有变更,直接使⽤ free 中记录的空间,减少分配。
跳跃表是 Redis 特有的数据结构,就是在链表的基础上,增加多级索引提升查找效率。
跳跃表⽀持平均 O(logN),最坏 O(N)复杂度的节点查找,还可以通过顺序性操作批量处理节点。
| 合理的数据编码Redis ⽀持多种数据类型,每种基本类型,可能对多种数据结构。
什么时候,使⽤什么样数据结构,使⽤什么样编码,是 Redis 设计者总结优化的结果。
String:如果存储数字的话,是⽤ int 类型的编码;如果存储⾮数字,⼩于等于 39 字节的字符串,是 embstr;⼤于 39 个字节,则是 raw 编码。

.011# 面试题11.为什么要使用static?使用方式: 通过类名调用创建多个对象时,共享一个静态属性和方法,当有一个对象修改了,其他对象使用时,也会改变一个类只能有一个同名的静态属性和静态方法,这样每个对象创建时,就不会再分配额外空间了,存储在方法区(静态区)节省空间。
2. jvm 内存模型有哪些,分别介绍一下?包括: 堆虚拟机栈本地方法栈程序计数器方法区堆:存储对象数组集合存储new出来的东西方法区: 存储类的信息常量(常量池中)静态变量编译器编译后的数据程序计数器: 相当于当前程序制定的字节码行号,指向下一行代码(因为多线程并发,如何实现轮流切换的,是因为每一个线程都会独立有一个程序计数器,可以保证每个线程切换之后,可以回到原来的位置)虚拟机栈: 存放的是每一个栈帧,每一个栈帧对应的一个被调用的方法栈帧包括: 局部变量表操作数栈常量池引用返回地址 .....局部变量表 : 存储局部变量操作数栈 : 程序中所有的计算过程都是它来完成常量池引用: 在方法运行时,用于引用类中的常量返回地址: 当方法被调用时,方法执行结束,还要回到调用的位置所以要保存一个方法返回地址。
本地方法栈:类似于虚拟机栈,只不过虚拟机栈运行是 java 方法,而它是运行native修饰的方法(本地方法)本地方法是操作系统帮你实现的,java只负责调用即可。
3.创建对象的方式有哪些?1.new2. 克隆3.反射4.反序列化调用构造的: 1. new 2. 反射 newInstance() 调用底层无参构造不用构造: 1. 克隆 : 在堆内存直接将已经存在的对象拷贝一份。
2.反序列化: 表示将本地文件生成一个java对象。
克隆:实现一个接口Cloneable 重写clone()User u = new User();User u2 = u.clone();深克隆:如果对象属性中也有引用类型,这些引用类型也需要实现Cloneable接口,重写clone(), 如果不重写克隆出来的对象基本类型可以克隆,引用类型不会克隆,是指向同一个对象4.什么是自动装箱和拆箱?装箱:就是自动将基本类型转换成封装类型拆箱:就是自动将封装类型转成基本类型。

integer类型的tohexstring方法题目:Integer类型的toHexString方法解析:一窥数据转换的奥秘导言:在计算机科学中,数据转换是一项关键任务。
在编程中,我们常常需要将十进制数字转换为十六进制,或者将十六进制数字转换为十进制。
Java中的Integer类提供了toHexString方法来实现这种转换。
本文将深入探讨该方法的使用原理和应用场景,帮助读者更好地理解数据转换的奥秘。
第一部分:了解toHexString方法的基本概念(200字)Integer类是Java中表示整数的包装类之一。
其中的toHexString方法用于将整数转换为十六进制字符串,并返回结果。
该方法的原型为:public static String toHexString(int i)该方法的输入参数是一个整数,返回值是一个字符串对象。
toHexString方法是一个静态方法,因此可以通过类名直接调用。
第二部分:toHexString方法的使用示例(200字)下面通过几个例子来展示toHexString方法的用法:1. 示例一:将十进制数字转换为十六进制int number = 255;String hexString = Integer.toHexString(number);System.out.println("Number in hexadecimal format: " +hexString);输出结果为:Number in hexadecimal format: ff2. 示例二:将十六进制字符串转换为十进制数字String hexNumber = "1A";int decimalNumber = Integer.parseInt(hexNumber, 16);System.out.println("Number in decimal format: " + decimalNumber);输出结果为:Number in decimal format: 26通过这些示例,我们可以发现toHexString方法在不同的情景下为我们提供了十进制和十六进制之间的转换功能。

javafloat转string 原理
在Java中,将一个float 类型的值转换为String 类型的值,通常使用Float 类中的toString() 方法或者String 类中的valueOf() 方法。
这些方法的原理是通过将浮点数的位模式转换为十进制表示形式来完成。
下面简要介绍一下这两种方法的原理:
1.Float.toString(float f) 方法:这个方法将一个float 类型的值转换为字符串。
它首先将浮点数的位模式解析为十进制的数字,并根据这些数字创建一个字符串。
这种方法返回的字符串会包含十进制数和可能的小数点。
2.String.valueOf(float f) 方法:这个方法是String 类的静态方法,它接受一个float 类型的参数并返回一个表示该参数的字符串。
它的内部实现与Float.toString(float f) 类似,都是将浮点数的位模式转换为十进制的数字,然后创建一个字符串。
在底层实现中,Java会使用浮点数的IEEE 754标准的位模式来表示浮点数。
转换过程涉及到对位模式的解析和十进制数的生成,以确保最终生成的字符串能够准确地表示原始的浮点数值。
需要注意的是,由于浮点数的特性,转换过程可能会存在一定的精度损失。
因此,在将float 类型的值转换为String 类型时,可能会出现精度问题,特别是当浮点数的小数部分很长或者浮点数本身非常大时。
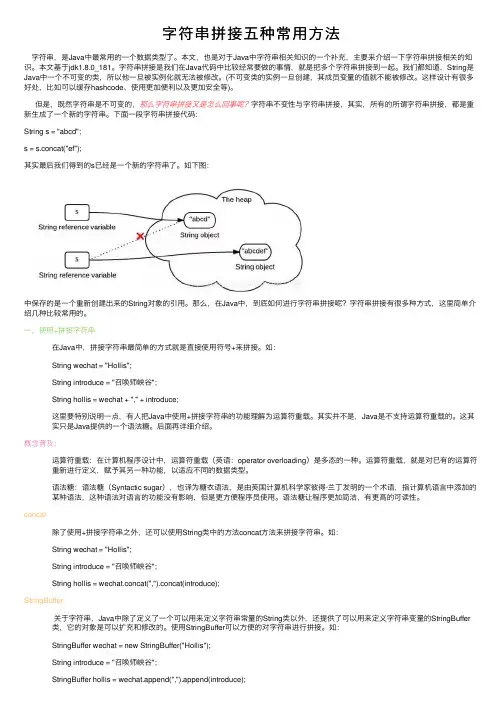
字符串拼接五种常⽤⽅法字符串,是Java中最常⽤的⼀个数据类型了。
本⽂,也是对于Java中字符串相关知识的⼀个补充,主要来介绍⼀下字符串拼接相关的知识。
本⽂基于jdk1.8.0_181。
字符串拼接是我们在Java代码中⽐较经常要做的事情,就是把多个字符串拼接到⼀起。
我们都知道,String是Java中⼀个不可变的类,所以他⼀旦被实例化就⽆法被修改。
(不可变类的实例⼀旦创建,其成员变量的值就不能被修改。
这样设计有很多好处,⽐如可以缓存hashcode、使⽤更加便利以及更加安全等)。
但是,既然字符串是不可变的,那么字符串拼接⼜是怎么回事呢?字符串不变性与字符串拼接,其实,所有的所谓字符串拼接,都是重新⽣成了⼀个新的字符串。
下⾯⼀段字符串拼接代码:String s = "abcd";s = s.concat("ef");其实最后我们得到的s已经是⼀个新的字符串了。
如下图:中保存的是⼀个重新创建出来的String对象的引⽤。
那么,在Java中,到底如何进⾏字符串拼接呢?字符串拼接有很多种⽅式,这⾥简单介绍⼏种⽐较常⽤的。
⼀,使⽤+拼接字符串在Java中,拼接字符串最简单的⽅式就是直接使⽤符号+来拼接。
如:String wechat = "Hollis";String introduce = "召唤师峡⾕";String hollis = wechat + "," + introduce;这⾥要特别说明⼀点,有⼈把Java中使⽤+拼接字符串的功能理解为运算符重载。
其实并不是,Java是不⽀持运算符重载的。
这其实只是Java提供的⼀个语法糖。
后⾯再详细介绍。
概念普及:运算符重载:在计算机程序设计中,运算符重载(英语:operator overloading)是多态的⼀种。
运算符重载,就是对已有的运算符重新进⾏定义,赋予其另⼀种功能,以适应不同的数据类型。

String字符串相加的原理**因为String是⾮常常⽤的类, jvm对其进⾏了优化, jdk7之前jvm维护了很多的字符串常量在⽅法去的常量池中, jdk后常量池迁移到了堆中 **⽅法区是⼀个运⾏时JVM管理的内存区域,是⼀个线程共享的内存区域,它⽤于存储已被虚拟机加载的类信息、常量、静态常量等。
使⽤引号来创建字符串单独(注意是单独)使⽤引号来创建字符串的⽅式,字符串都是常量,在编译期已经确定存储在常量池中了。
⽤引号创建⼀个字符串的时候,⾸先会去常量池中寻找有没有相等的这个常量对象,没有的话就在常量池中创建这个常量对象;有的话就直接返回这个常量对象的引⽤。
所以看这个例⼦:String str1 = "hello";String str2 = "hello";System.out.println(str1 == str2);//truenew的⽅式创建字符串String a = new String("abc");new这个关键字,毫⽆疑问会在堆中分配内存,创建⼀个String类的对象。
因此,a这个在栈中的引⽤指向的是堆中的这个String对象的。
然后,因为"abc"是个常量,所以会去常量池中找,有没有这个常量存在,没的话分配⼀个空间,放这个"abc"常量,并将这个常量对象的空间地址给到堆中String对象⾥⾯;如果常量池中已经有了这个常量,就直接⽤那个常量池中的常量对象的引⽤呗,就只需要创建⼀个堆中的String对象。
new构造⽅法中传⼊字符串常量, 会在堆中创建⼀个String对象, 但是这个对象不会再去新建字符数组(value) 来存储内容了, 会直接使⽤字符串常量对象中字符数组(value)应⽤,具体⽅法参考/*** Initializes a newly created {@code String} object so that it represents* the same sequence of characters as the argument; in other words, the* newly created string is a copy of the argument string. Unless an* explicit copy of {@code original} is needed, use of this constructor is* unnecessary since Strings are immutable.** @param original* A {@code String}*/public String(String original) {this.value = original.value; //只是把传⼊对象的value和引⽤传给新的对象, 两个对象其实是共⽤同⼀个数组this.hash = original.hash;}value 虽然是private修饰的, 但是构造⽅法中通过original.value;还是可以直接获取另外⼀个对象的值. 因为这两个对象是相同的类的对象所以有下⾯的结果public static void main(String[] args) {String s1 = new String("hello");String s2 = "hello";String s3 = new String("hello");System.out.println(s1 == s2);// falseSystem.out.println(s1.equals(s2));// trueSystem.out.println(s1 == s3);//false}关于“+”运算符常量直接相加:String s1 = "hello" + "word";String s2 = "helloword";System.out,println(s1 == s2);//true这⾥的true 是因为编译期直接就把 s1 优化成了 String s1 = "helloword"; 所以后⾯相等⾮常量直接相加public static void main(String[] args) {String s1 = "a";String s2 = "b";String s3 = new String("b");String s4 = s1 + s3;String s5="ab";String s6 = s1 + s2;String s66= s1 + s2;String s7 = "a" + s2;String s8 = s1 + "b";String s9 = "a" + "b";System.out.println(s2 == s3); //falseSystem.out.println(s4 == s5); //false s4 是使⽤了StringBulider来相加了System.out.println(s4 == s6); //false s4和s6 两个都是使⽤了StringBulider来相加了System.out.println(s6 == s66); //false 两个都是使⽤了StringBulider来相加了System.out.println(s5 == s7); //false s7是使⽤了StringBulider来相加了System.out.println(s5 == s8); //false s8是使⽤了StringBulider来相加了System.out.println(s7 == s8); //false 两个都是使⽤了StringBulider来相加了System.out.println(s9 == s8); //false 两个都是使⽤了StringBulider来相加了}总结下就是: 两个或者两个以上的字符串常量直接相加,在预编译的时候“+”会被优化,相当于把两个或者两个以上字符串常量⾃动合成⼀个字符串常量.编译期就会优化, 编译的字节码直接就把加号去掉了, 直接定义⼀个常量 **其他⽅式的字符串相加都会使⽤到 StringBuilder的. **String的intern()⽅法.这是⼀个native的⽅法,书上是这样描述它的作⽤的:如果字符串常量池中已经包含⼀个等于此String对象的字符串,则返回代表池中这个字符串的String对象;否则,将此String对象包含的字符添加到常量池中,并返回此String对象的引⽤。

java中list集合中contains()的原理Java中List集合中contains()的原理介绍在Java编程中,我们经常使用List集合来存储一组数据。
List 集合提供了contains()方法用于判断集合中是否包含某个元素。
本文将从浅入深,逐步解释contains()方法的原理。
List集合简介List是Java中最基本的集合之一,它是一个有序的集合,可以存储重复的元素。
List实现了Collection接口,并提供了一系列针对元素的操作方法。
contains()方法的作用contains()方法用于判断集合中是否包含指定的元素,如果包含则返回true,否则返回false。
contains()方法的使用示例以下是contains()方法的使用示例:List<String> list = new ArrayList<>(); ("apple");("banana");("orange");boolean result = ("apple");(result); // 输出trueresult = ("grape");(result); // 输出falsecontains()方法的底层原理底层原理是指contains()方法的具体实现方式。
List接口有多个实现类,每个实现类对contains()方法的实现可能有所不同。
ArrayList的实现原理ArrayList是List接口的一个常用实现类。
当调用contains()方法时,ArrayList会遍历集合中的元素,逐个与目标元素进行比较。
LinkedList的实现原理LinkedList也是List接口的一个实现类。
它使用双向链表结构存储元素。
当调用contains()方法时,LinkedList会从列表的头部或尾部开始遍历链表,逐个与目标元素进行比较。

oc 字符串数组 containsobject OC中的字符串数组(NSArray<NSString *>)提供了一个便捷的方式来存储和处理字符串。
其中的containsObject方法是一个常用的方法,用于检查数组中是否存在指定的对象。
containsObject方法的定义如下:- (BOOL)containsObject:(ObjectType)anObject;它的作用是判断指定的对象anObject是否存在于数组中,并返回一个BOOL类型的值,即存在返回YES,否则返回NO。
该方法的使用非常简单,只需调用数组对象的containsObject方法,并传入要查询的对象即可。
例如,我们有一个字符串数组arr,我们想要判断其中是否包含某个字符串str,可以这样写:BOOL isContain = [arr containsObject:str];使用containsObject的好处是,它提供了代码的简洁性和可读性。
避免了我们手动遍历数组进行比较的繁琐工作。
此外,containsObject方法内部会根据所给定的对象,调用isEqual方法来进行比较。
因此,它不仅可以用于判断字符串是否存在于数组中,还可以用于判断其他对象的存在性。
下面我将详细介绍containsObject方法的使用场景,使用方法和注意事项,以及它的底层实现原理。
一、使用场景1.判断字符串是否存在于数组中一个常见的使用场景是,我们有一个字符串数组,需要判断其中是否包含某个特定的字符串。
例如,我们有一个存储全体员工姓名的数组,我们想要判断数组中是否包含某个特定的员工名字。
NSArray<NSString *> *employeeNames = @[@"张三", @"李四", @"王五", @"赵六"];NSString *currentEmployee = @"王五";BOOL containsCurrentEmployee = [employeeNames containsObject:currentEmployee];这样,containsCurrentEmployee的值就是YES,因为数组中包含"王五"这个字符串。
JVM插码之三:javaagent介绍及javassist介绍本⽂介绍⼀下,当下⽐较基础但是使⽤场景却很多的⼀种技术,稍微偏底层点,就是字节码插庄技术了...,如果之前⼤家熟悉了asm,cglib以及javassit等技术,那么下⾯说的就很简单了...,因为下⾯要说的功能就是基于javassit实现的,接下来先从javaagent的原理说起,最后会结合⼀个完整的实例演⽰实际中如何使⽤。
1、什么是javassist?Javassist是⼀个开源的分析、编辑和创建Java字节码的类库。
其主要的优点,在于简单,⽽且快速。
直接使⽤java编码的形式,⽽不需要了解虚拟机指令,就能动态改变类的结构,或者动态⽣成2、Javassist 作⽤?a. 运⾏时监控插桩埋点b. AOP动态代理实现(性能上⽐Cglib⽣成的要慢)c. 获取访问类结构信息:如获取参数名称信息3、Javassist使⽤流程4、如何对WEB项⽬对象进⾏字节码插桩1.统⼀获取HttpRequest请求参数插桩⽰例2.获取HttpRequest参数遇到ClassNotFound的问题3.Tomcat ClassLoader 介绍,及javaagent jar包加载机制4.通过class 加载沉机制实现在javaagent 引⽤游jar 包javaagent的主要功能有哪些?1. 可以在加载java⽂件之前做拦截把字节码做修改2. 获取所有已经被加载过的类3. 获取所有已经被初始化过了的类(执⾏过了clinit⽅法,是上⾯的⼀个⼦集)4. 获取某个对象的⼤⼩5. 将某个jar加⼊到bootstrapclasspath⾥作为⾼优先级被bootstrapClassloader加载6. 将某个jar加⼊到classpath⾥供AppClassloard去加载7. 设置某些native⽅法的前缀,主要在查找native⽅法的时候做规则匹配JVMTIJVM Tool Interface,是jvm暴露出来的⼀些供⽤户扩展的接⼝集合,JVMTI是基于事件驱动的,JVM每执⾏到⼀定的逻辑就会调⽤⼀些事件的回调接⼝(如果有的话),这些接⼝可以供开发者去扩展⾃⼰的逻辑。
研发工程师面试笔试题目(经典版)编制人:__________________审核人:__________________审批人:__________________编制单位:__________________编制时间:____年____月____日序言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!并且,本店铺为大家提供各种类型的经典范文,如工作计划、工作总结、演讲致辞、合同协议、管理制度、心得体会、法律文书、教学资料、作文大全、其他范文等等,想了解不同范文格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!Moreover, our store provides various types of classic sample essays for everyone, such as work plans, work summaries, speeches, contract agreements, management systems, insights, legal documents, teaching materials, complete essays, and other sample essays. If you want to learn about different sample formats and writing methods, please pay attention!研发工程师面试笔试题目研发工程师面试难吗?求职面试时,面试官一般都会问你一些问题,也可能是通过问卷的形式提问,怎么回答才是最好的呢?这里给大家分享一些研发工程师面试笔试题目,希望对大家有所帮助。
汇编语言writestring1. 引言汇编语言是一种底层程序设计语言,用于直接控制计算机硬件。
在汇编语言中,writestring是一个重要的函数,用于向屏幕输出字符串。
本文将全面、详细、完整地探讨汇编语言中writestring函数的实现原理及应用。
2. writestring函数的功能writestring函数的功能是将一个字符串输出到屏幕上。
在汇编语言中,字符串是由多个字符组成的连续内存区域,以0结尾。
writestring函数接收一个字符串的内存地址作为参数,然后将该字符串逐字符输出到屏幕上,直到遇到0为止。
3. writestring函数的实现原理writestring函数的实现原理如下: 1. 读取字符串的首字母。
2. 将首字母输出到屏幕上。
3. 将字符串的内存地址加1,指向下一个字符。
4. 判断当前字符是否为0,如果是则结束输出,否则跳转到第1步。
4. writestring函数的伪代码下面是使用伪代码表示的writestring函数的实现过程:writestring:参数入栈读取字符串首字母输出字符字符指针加1判断字符是否为0如果是0则结束,否则跳转到读取首字母5. writestring函数的示例下面是一个使用writestring函数输出”Hello World!“的示例代码:section .datahello db 'Hello World!',0section .textglobal _start_start:push hello ; 将字符串地址入栈call writestring ; 调用writestring函数add esp, 4 ; 清除参数栈空间; 程序的其他部分...; ...6. writestring函数的应用场景writestring函数在汇编语言中广泛应用于以下场景: - 显示器输出:将字符串输出到屏幕上,用于显示用户界面、错误信息等。
string字符串拼接底层原理String字符串拼接在编程中是非常常见的操作,但是很多人都不知道这个操作的底层原理。
在本篇文章中,我们将会探讨String字符串拼接的底层原理,其实它的实现原理并不神秘。
一、String字符串是如何存储的在Java中,String字符串是通过char数组来存储的,每个字符占用两个字节,一般情况下我们不需要关心这个,只需要知道字符串中的字符是按照一定的顺序进行存储即可。
二、String字符串拼接的方法在Java中,String字符串拼接有三种常见的方法:1. 使用+进行拼接例如:String str = "hello" + "world";2. 使用StringBuffer或StringBuilder进行拼接例如:StringBuilder sb = new StringBuilder();sb.append("hello").append("world"); String str =sb.toString();3. 使用String的concat方法进行拼接例如:String str1 = "hello"; String str2 = "world"; String str3 = str1.concat(str2);三、String字符串拼接的底层原理在Java中,字符串的拼接操作是非常消耗内存的操作,因为字符串是不可变的对象,一旦进行拼接,就会创建一个新的字符串对象,而原来的字符串对象则会被销毁。
这种行为在频繁进行字符串拼接时,会造成大量的内存开销。
1. 使用+进行拼接的底层原理使用+进行字符串拼接时,Java会对其进行优化,将其转化为StringBuilder的append方法,然后再将StringBuilder对象转化为String对象。
例如:String str = "hello" + "world";实际上被转化为:String str = newStringBuilder().append("hello").append("world").toString();这样做的好处是,避免了大量的临时字符串对象的创建和销毁,但是由于每次都会创建一个StringBuilder对象,这也会带来一定的内存开销。
jediscluster.lpush 底层原理-概述说明以及解释1.引言1.1 概述在分布式系统中,jediscluster.lpush方法是一个常用的操作,用于将一个或多个值插入到列表的头部。
这个方法通常被用于缓存和消息队列等场景中,能够快速地将数据存储到Redis集群中。
本文将深入探讨jediscluster.lpush方法的底层原理,分析其内部实现机制,以及在实际使用中需要注意的一些问题。
通过对该方法的详细解析,读者将能够更深入理解Redis集群在数据处理过程中的工作原理,以及如何优化和提升系统性能。
1.2 文章结构本文将从三个方面对jediscluster.lpush方法进行深入探讨。
首先,将介绍jediscluster.lpush方法的具体功能和用法,包括参数设置和返回结果的解释。
其次,将揭示jediscluster.lpush方法的底层实现原理,包括数据结构和算法等方面的细节。
最后,将列举jediscluster.lpush方法的使用注意事项,帮助读者更好地理解和运用该方法。
通过对这三个方面的分析,读者能够全面了解jediscluster.lpush方法,为后续的应用和优化提供参考依据。
1.3 目的本文的主要目的是探讨jediscluster.lpush 方法在Redis 集群环境下的底层实现原理。
通过深入分析该方法的实现机制,我们可以更加深入地了解Redis 集群在处理数据存储和读写操作时的内部工作方式。
同时,通过研究jediscluster.lpush 的使用注意事项,可以帮助开发人员更好地在实际项目中应用该方法,提高代码质量和性能表现。
通过本文的研究,读者可以对Redis 集群的工作原理有更为全面的了解,并为日后的开发工作提供参考和指导。
2.正文2.1 jediscluster.lpush方法介绍jediscluster.lpush方法是Redis集群中用于向一个列表(List)中添加一个或多个元素的方法。
在 Java 中,BufferedReader是用于读取字符流的缓冲输入流。
BufferedReader.lines()方法是 Java 8 中添加的方法,它返回一个由文件行构成的Stream<String>,用于处理文本文件的每一行。
底层原理涉及到BufferedReader以及 Java 8 引入的 Stream API。
让我们分步解释:1. BufferedReader:
BufferedReader继承自Reader类,它提供了缓冲机制,可以一次读取一行字符,提高了读取的效率。
在读取时,BufferedReader会在内部维护一个缓冲区,减少直接访问底层输入流的次数。
2. Stream API:
Java 8 引入了 Stream API,它提供了一种更为便利的方式来处理集合数据。
BufferedReader.lines()则是基于 Stream API 的一部分。
Stream<String>表示一系列的字符串,而BufferedReader.lines()将文件的每一行表示为 Stream 中的一个元素。
3. 使用示例:
在这个例子中,BufferedReader从文件中读取内容,然后lines()方法将文件的每一行表示为一个字符串元素的 Stream。
forEach(System.out::println)用于遍历输出每一行。
总体而言,BufferedReader.lines()的底层原理是基于 BufferedReader 读取文件内容,然后使用 Stream API 将每一行封装成一个 Stream 对象,使得我们可以使用 Stream API 进行更方便的操作。
string底层原理
string是C++中的一个串类,底层实现是利用字符数组来存储字符串。
也就是说,字符串在内存中就是一段连续的字符数组。
通过指针来操作内存,可以进行字符串的拼接、复制、查找等操作。
当我们声明一个string类型的变量时,实际上是在内存中开辟了一块固定大小的连续地址空间,存储了字符串的内容。
当我们对字符串进行修改或者赋值操作时,会触发内存分配和回收的操作。
在实际使用中,string类封装了大量的字符串操作方法,如substr、replace、find等等,使得字符串操作更加高效、方便。
在底层实现上,这些方法通常是通过调用相应的字符数组函数来实现的。
总的来说,string底层的实现是通过字符数组来存储字符串,通过指针来操作内存,实现了高效、方便的字符串操作方法。