模式识别研究进展
- 格式:docx
- 大小:18.42 KB
- 文档页数:7

模式识别受体及其相关分子佐剂研究进展戴志红;蒋卉;李翠;魏津;郭彩云;关孚时;王在时【摘要】综述了模式识别受体(Pattern recognition receptors,PRRs)及其相关分子佐剂的研究进展。
PRRs是一类表达于固有免疫细胞并可识别病原体相关分子模式的识别分子。
PRRs主要包括Toll样受体、NOD样受体、RIG—I样受体、清道夫受体、甘露糖受体和髓系细胞触发受体等。
与PRRs直接相关的分子佐剂主要包括TLR激动剂、NLR激动剂、RIG—I和MDA5激动剂及CD40和肿瘤坏死因子受体超家族(TNFRSF)激动剂等。
%In this paper, the developments of PRRs and its relevant molecular adjuvants were reviewed. PRRs were a kind of recognition molecules expressed on innate immune cells that can recognize pathogen - associated molecular patterns (PAMPs). PRRs mainly included Toll- like receptors (TLRs), NOD -like receptors (NLRs), RIG- I like receptors (RLRs), scavenger receptors (SRs), mannose receptors (MRs) and triggering receptors expressed on myeloid cells (TREMs), etc. Molecular adjuvants directly related to PRRs mainly including TLR agonists, NLR agonists, RIG - I & MDA5 agonists and CD40 & tumor necrosis factor receptor of superfamily (TNFRSF) agonists, etc.【期刊名称】《中国兽药杂志》【年(卷),期】2012(046)012【总页数】6页(P61-66)【关键词】模式识别受体;分子佐剂;激动剂【作者】戴志红;蒋卉;李翠;魏津;郭彩云;关孚时;王在时【作者单位】中国兽医药品监察所,北京100081;中国兽医药品监察所,北京100081;中国兽医药品监察所,北京100081;中国兽医药品监察所,北京100081;中国兽医药品监察所,北京100081;中国兽医药品监察所,北京100081;中国兽医药品监察所,北京100081【正文语种】中文【中图分类】Q7疫苗免疫一般认为是防治动物传染病最有效和最经济的手段之一。

机器视觉与模式识别技术的研究与应用一、引言机器视觉与模式识别技术是计算机科学领域中的重要分支,它的研究和应用对于提高人工智能技术水平、推动社会进步具有重要意义。
机器视觉技术通过模拟人类视觉系统,让机器能够感知和理解图像、视频等视觉信息,模式识别技术则是在机器视觉的基础上,通过对数据进行分析和判断,实现对模式和规律的识别。
这两个技术的结合,不仅可以实现机器对视觉信息的自动理解和处理,还可以应用于许多领域,如智能监控、机器人导航和医学图像分析等。
二、机器视觉技术的研究进展1. 图像处理和分析图像是机器视觉技术的基础,图像处理和分析是机器对图像进行预处理和特征提取的重要步骤。
传统的图像处理方法包括图像滤波、边缘检测和特征提取等,而近年来,基于深度学习的图像处理方法得到了快速发展,如卷积神经网络(CNN)等。
这些方法在图像分类、目标检测和图像生成等方面都取得了显著的成果。
2. 目标检测和跟踪目标检测和跟踪是机器视觉技术中的重要研究方向。
目标检测主要是指在图像或视频中检测和定位出感兴趣的目标物体。
传统的目标检测算法主要是基于特征提取和分类器的组合,如Haar特征和支持向量机(SVM)等。
而现在,基于深度学习的目标检测算法,如YOLO和Faster R-CNN等,已经取得了更好的性能。
3. 三维重建与虚拟现实通过对多个角度或帧的图像进行处理和分析,机器可以实现三维重建和虚拟现实等技术。
三维重建主要是从二维图像中推断出物体的三维结构和形状,这对于工业设计和文化遗产保护等领域具有重要的应用价值。
虚拟现实则是通过对图像和视频进行处理和增强,模拟出逼真的虚拟场景,如游戏和培训等。
三、模式识别技术的应用领域1. 人脸识别人脸识别技术是模式识别技术中的一个重要应用领域。
通过对图像或视频中的人脸进行特征提取和比对,可以实现人脸的自动识别和身份验证,这对于安防和公共交通等领域具有重要的意义。
近年来,基于深度学习的人脸识别算法取得了巨大的突破,其性能已经超过了人类的水平。

核酸识别模式识别受体在糖尿病中的作用研究进展刘英奇,谢璐,刘雨霞,周娟,刘志平摘要:糖尿病在全球的发病率日益增长,由它引起的各种并发症(糖尿病性肾病综合症,糖尿病性心肌病等)所导致的死亡率也日益增多。
模式识别受体(PRRs)能启动先天性免疫应答,清除相关病原体从而维持机体稳态,与糖尿病的发生发展有着密切的联系。
PRRs 家族成员主要有TOLL 样受体(TLRs)、NOD 样受体(NLRPs)、AIM2 样受体(ALRs)、STING 和RIG-I 样受体(RLRs)等,其中部分TLRs、ALRs、STING 和RLRs 主要识别核酸(DNA 或RNA)。
一系列研究表明识别核酸的PRRs 能通过不同的方式调控糖尿病及其并发症的发生发展,本文对此进行综述,研究结果提示调节识别核酸的PRRs及其信号通路能为糖尿病的预防、治疗、预后提供思路和理论基础。
关键词:模式识别受体;糖尿病;糖尿病性并发症据国际糖尿病联盟(International Diabetes Federa-tion,IDF)的数据显示,全球糖尿病患病人数约为4.25亿人[1]。
糖尿病是心血管疾病高发病率和死亡率的主要原因之一[2]。
但糖尿病的发病机制十分复杂,包括环境因素,饮食因素,遗传因素等多方面原因。
模式识别受体(Pattern recognition receptors,PRRs)是主要分布在先天性免疫细胞的受体,它们能识别体外微生物的保守结构称之为病原相关分子模式(Pathogen-associated molecular patterns,PAMPs)来感应微生物的存在,也能识别体内受损细胞释放的某种因子,称之为损伤相关分子模式(Damage-as-sociated molecular pattern,DAMPs)[3]。
PRRs家族成员主要有TOLL 样受体(Toll-like receptors,TLRs)、NOD样受体(Nod-like receptors,NLRPs)、AIM2样受体(Aim2-like receptors,ALRs)、STING (Stimulator of interferon genes)和RIG-Ⅰ样受体(RIG-Ⅰ-like re-ceptors,RLRs)等。

基于模式识别的智能识别技术研究随着科技的不断发展,越来越多的技术走进了我们的日常生活中。
智能识别技术便是其中之一。
而基于模式识别的智能识别技术,则是人工智能研究的重要领域之一。
本文将围绕基于模式识别的智能识别技术展开探讨。
一、模式识别技术简介模式识别,是一种人工智能领域的技术,它的主要任务是从大量的数据中识别出一种或多种规律,并使用这些规律来破解、分类或预测未知的数据。
模式识别技术常被用在图像识别、语音识别、生物信息学、计算机辅助诊断、人脸识别、指纹识别、语义分析等领域。
二、基于模式识别的智能识别技术的应用领域模式识别技术能够识别出一系列的模式,如图像、声音、文字、信号、行为等,并将这些模式进行分类、聚类、回归、推断等操作以达到人工智能的目的。
而基于模式识别的智能识别技术则是将这种技术应用到更广泛的领域中。
以下是一些基于模式识别的智能识别技术的应用领域:1. 人脸识别人脸识别技术是基于模式识别算法的一种,通过分析面部特征,使用计算机程序识别和鉴别人脸,并将其与数据库中的人脸进行比对。
在人脸识别领域,模式识别技术被广泛应用于安全系统、门禁管理、视频监控等领域。
2. 视频监控视频监控技术是利用摄像机进行的视觉监测,可以帮助人们了解房间内的活动、交通堵塞状况、危险状态等。
而模式识别技术则可以针对视频数据进行处理和识别,如识别异常行为、自动拍摄等。
3. 声音识别声音识别是将声音信息转换并匹配到文字、图像或特定的动作上的技术。
在语音识别和自然语言处理中,模式识别技术被广泛应用。
主要作用是将语音转写成可编辑的文本,或将语音转化为命令并发出动作控制。
三、基于模式识别的智能识别技术的研究进展模式识别技术作为一种高新技术,十分重要和复杂。
在过去的几十年间,模式识别技术在不断地取得进展。
1. 深度学习深度学习是目前机器学习领域最为流行的技术,它通过建立多层神经网络,对数据进行分析、学习和预测。
深度学习技术已经成功应用在语音识别、图像识别等领域,并在这些领域内取得了大量优秀的成果。

人群运动轨迹分析与模式识别研究人类社会中人群运动是一种普遍存在的现象,而对人群运动轨迹进行分析与模式识别研究,可以对城市规划、公共安全、流行病传播等领域提供重要的指导和决策支持。
本文将对人群运动轨迹分析与模式识别的研究进行探讨,旨在加深对该领域的理解和认识。
一、人群运动轨迹分析的意义与方法1.1 意义:人群运动轨迹分析可以通过收集大规模的人员位置数据,揭示出个体之间的关联和相互作用,有助于理解人类运动的行为模式、地理分布和时间特征,从而帮助我们更好地理解人类社会。
此外,对人群运动轨迹的分析还能为城市规划、公共安全、流行病传播等领域提供重要的决策支持。
1.2 方法:人群运动轨迹分析的方法有很多种,其中最常见的包括:(1)轨迹数据采集与预处理:通过位置感知技术(如GPS、基站定位等),采集大规模的人员位置数据,并进行数据清洗和预处理,以确保数据的准确性和完整性。
(2)轨迹可视化与描述统计分析:通过可视化手段将轨迹数据以图表形式呈现,可视化工具如地图、散点图、时空图等,用于直观地描述和分析人群运动轨迹的特征与规律。
(3)轨迹聚类与分类分析:通过聚类算法和分类模型对轨迹数据进行分组和分类,以挖掘不同群体的运动模式和特征。
(4)轨迹模式识别与行为预测:通过机器学习和数据挖掘等方法,建立轨迹模式识别和行为预测模型,用于预测人群的运动行为和未来的轨迹。
二、人群运动轨迹模式识别的研究进展2.1 轨迹模式识别的研究内容:人群运动轨迹模式识别是指对轨迹数据进行处理和分析,挖掘其中的模式和规律。
目前,轨迹模式识别的研究主要集中在以下几个方面:(1)轨迹数据压缩与表示:由于轨迹数据量庞大,传统的数据挖掘与机器学习方法在处理时面临巨大的计算和存储压力,因此研究者们提出了一系列轨迹数据压缩和表示方法,以减小数据规模和提高数据处理效率。
(2)轨迹数据聚类与分类:通过聚类算法和分类模型对轨迹数据进行聚类和分类,以将相似的轨迹归为一类,并发现其中的运动模式和特征。

深度学习在模式识别和预测分析中的应用进展随着科技的飞速发展,人工智能领域取得了显著的进步,其中深度学习技术更是成为了研究的热点。
深度学习,这个被誉为“人工智能的瑞士军刀”,在模式识别和预测分析中展现出了惊人的能力。
它如同一位敏锐的侦探,能够从海量数据中发现隐藏的线索,揭示出事物的本质。
首先,让我们来探讨一下深度学习在模式识别方面的应用。
模式识别是指通过计算机对输入数据进行分析和处理,从而实现对特定目标或现象的识别。
在这个过程中,深度学习就像是一位精通各种乐器的音乐家,能够精准地捕捉到数据中的微妙变化,并将其转化为有价值的信息。
例如,在图像识别领域,深度学习可以通过训练大量的样本数据,自动学习到图像的特征表示,从而实现对图像中物体的准确识别。
这种能力使得深度学习在人脸识别、自动驾驶等众多领域得到了广泛应用。
接下来,我们再来看看深度学习在预测分析方面的表现。
预测分析是指根据历史数据和现有趋势,对未来可能发生的事件进行预测。
在这方面,深度学习就如同一位经验丰富的航海家,能够在茫茫大海中找到正确的航线。
通过建立复杂的神经网络模型,深度学习能够挖掘出数据中的潜在规律,并据此进行准确的预测。
例如,在金融市场中,深度学习可以分析历史交易数据,预测股票价格的走势;在气象预报领域,深度学习可以根据气象数据预测未来的天气情况。
这些应用不仅提高了预测的准确性,还为相关行业带来了巨大的经济效益。
然而,尽管深度学习在模式识别和预测分析中取得了显著的成果,但我们也必须认识到其存在的局限性。
深度学习需要大量的训练数据和计算资源,这使得在一些资源有限的应用场景中难以发挥出其最大的潜力。
此外,深度学习模型的解释性较差,往往被视为一个“黑箱”,这在一定程度上限制了其在关键领域的应用。
因此,如何克服这些挑战,进一步推动深度学习技术的发展,仍然是一个值得关注的问题。
总的来说,深度学习在模式识别和预测分析中的应用已经取得了令人瞩目的进展。

doi:10.3969/j.issn.1000⁃484X.2018.07.028模式识别受体Dectin⁃1的免疫学研究进展①刘绍兰 吴婧楠 李若瑜② 栗玉珍 杨建勋 (哈尔滨医科大学附属第二医院皮肤科,哈尔滨150001) 中图分类号 R392.1 文献标志码 A 文章编号 1000⁃484X (2018)07⁃1102⁃06①本文为国家自然科学基金青年基金经费资助项目(81101228)和黑龙江省青年科学基金项目(QC2011CO48)㊂②北京大学第一医院皮肤科,北京100073㊂作者简介:刘绍兰,女,硕士,就读于哈尔滨医科大学,主要从事皮肤真菌感染方面的研究,E⁃mail:152********@㊂通讯作者及指导教师:杨建勋,女,博士,副主任医师,硕士生导师,主要从事皮肤真菌病方面的研究,E⁃mail:yangjianxun 76@㊂[摘 要] Dectin⁃1是C 型凝集素家族中最重要的受体,它能诱导自身胞内信号传导触发一系列细胞反应,在抗真菌免疫中发挥着重要的作用㊂该文对Dectin⁃1的信号传导途径㊁在抗微生物免疫中的作用㊁与其他受体的相互作用㊁在自身免疫及疾病中的作用㊁在β⁃葡聚糖诱导的免疫调节中的作用㊁潜在的临床应用予以综述㊂[关键词] Dectin⁃1;信号传导;抗微生物免疫;自身免疫;免疫调节Progress in immunology of pattern recognition receptor Dectin⁃1LIU Shao⁃Lan ,WU Jing⁃Nan ,LI Ruo⁃Yu ,LI Yu⁃Zhen ,YANG Jian⁃Xun .Department of Dermatology ,the Second Affiliated Hospital of Harbin Medical University ,Harbin 150001,China[Abstract ] Dectin⁃1,the most important receptor in the C⁃type lectin family,induces a series of cellular responses triggered by its own intracellular signaling and plays an important role in antifungal immunity.The signaling pathway to Dectin⁃1,its role in antimicrobial immunity,its interaction with other receptors,its role in autoimmunity and disease,its role in β⁃glucan⁃induced immune regulation,potential clinical applications are reviewed in this article.[Key words ] Dectin⁃1;Signal transduction;Anti⁃microbial immunity;Autoimmunity;Immunomodulation 高等动物固有免疫系统是机体抗真菌感染的第一道防线,固有免疫细胞(主要包括单核巨噬细胞㊁中性粒细胞)表面有多种模式识别受体(PRR),识别真菌细胞壁表面的病原相关分子模式(PAMP)㊂固有免疫系统对入侵病原微生物的识别是成功清除病原体的首要步骤㊂近期研究发现,C 型凝集素受体家族成员Dectin⁃1成为真菌感染免疫领域研究的热点[1]㊂既往研究表明Dectin⁃1是介导固有免疫细胞识别β⁃葡聚糖的主要受体㊂真菌感染之所以能被宿主细胞的受体识别并免疫杀伤,Dectin⁃1起到了不可或缺的作用㊂对于Dectin⁃1介导的免疫识别的研究为深入探索固有免疫防御机制开辟了新的领域㊂本文对Dectin⁃1的研究进展做一综述㊂1 Dectin⁃1概述Dectin⁃1是膜相关C 型凝集素(C⁃type lectin)家族中最重要的受体㊂含有细胞外碳水化合物识别结构域(CRD)或称C 型凝集素样区域(CTLD)㊁短杆(Stalk)连接的跨膜区和具有免疫受体酪氨酸活化基序(ITAM)的胞浆尾部㊂与其他C 型凝集素样受体不同,Dectin⁃1短杆区缺乏与形成二聚体相关的半胱胺酸残基,它是以单体形式发挥其生物功能的㊂人的Dectin⁃1基因通过转录后可产生8个亚型,2个主要亚型(A㊁B)和6个次要亚型(C㊁D㊁E㊁F㊁G㊁H)㊂其中只有三个亚型(A㊁B㊁E)同时具有完整的CRD 结构域和ITAM 基序㊂Dectin⁃1的A㊁B 两个亚型是主要的功能亚型,近来有研究发现Dectin⁃1E 亚型可以介导白念珠菌刺激引起的胞内信号通路的激活,并首次明确了Dectin⁃1E 亚型为功能亚型,可识别被吞进胞内的白念珠菌[2]㊂Dectin⁃1的细胞内结构域而非配体结合结构域决定着物种特异性配体[3]㊂Dectin⁃1能特异性识别可溶性及颗粒性β⁃1,3和/或β⁃1,6葡聚糖,如酵母多糖㊂酵母多糖刺激树突细胞产生IL⁃10的过程与Dectin⁃1依赖的细胞外信号调节激酶(ERK)及丝裂原活化蛋白激酶(MAPK)活化有关,近来有研究者推断细胞对酵母多糖的识别和结合可能另有其他信号通路来联合完成[4]㊂Dectin⁃1也可识别CD4+和CD8+T 淋巴细胞表面的内源性配体,促进T 淋巴细胞的增生[5]㊂在脾㊁淋巴结和胸腺的T 细胞区,巨噬细胞和树突状细胞Dectin⁃1的表达支持了这一受体在抗原提呈细胞和T 细胞间的联系作用㊂可以推测Dectin⁃1受体的功能可影响机体的免疫能力[6]㊂此外,Dectin⁃1与识别和摄取凋亡细胞以及细胞抗原的交叉提呈相关㊂2 Dectin⁃1的信号传导途径Dectin⁃1受体下游信号的级联反应可分为依赖脾脏酪氨酸激酶(Syk)的NF⁃κB 信号通路和非依赖脾脏酪氨酸激酶(Syk)的NF⁃κB 信号通路,以及Dectin⁃1受体的其他通路(图1[7])㊂2.1 Syk 依赖通道 Dectin⁃1是TLR 家族以外第一个被发现的可产生自身细胞内信号的PRR㊂当Dectin⁃1结合其配体后,ITAM 样基序中的酪氨酸首先被Src 家族激酶磷酸化,从而招募Syk,促进下游信号反应㊂Dectin⁃1只有近膜端含有ITAM 序列的酪氨酸是信号传导所必需的,可能是通过桥联两图1 Dectin⁃1受体的信号通路Fig.1 Dectin⁃1receptor signaling pathwayNote:Signaling network of Dectin⁃1.Multiple pathways downstream ofDectin⁃1rely on Syk.This can lead to PLCγ2/Ca2+signalingleading to PKCδactivation that controls calcineurin /NFAT and ROS /NLRP3in flammasome,and the phosphorylation of CARD9⁃Bcl10⁃Malt1.The CARD9complex is able to activate all NF⁃κBsubunits including c⁃Rel by removing its inhibitor,IκB,throughactivation of the IKK complex.Syk can also activate IKK complex through the noncanonical NIK pathway,leading to the activation ofNF⁃κB subunits RelB and p52.This pathway can be inhibited theRaf⁃1⁃mediatedpathwayinvolvingp65.Phosphorylatedandacetylated p65can interact with RelB,sequestering it away from anactive NF⁃κB complex.Resultant activation of NFAT and NF⁃κBresults in modification of gene transcription including cytokinesand chemokines.Dashed arrows represent a pathway that has yet to be fully defined.个Dectin⁃1单体促发的[8]㊂单一酪氨酸基序活化信号传导途径的发现是这一领域的一个重大突破㊂现已证实至少有其他两种受体 CLEC9A 和CLEC2也可利用这一信号传导途径[8⁃10]㊂Syk 是介导大多数Dectin⁃1功能的中枢性激酶,Syk 下游信号传导连接一种新的衔接子CARD9,可启动Syk /CARD9⁃BCL10⁃MALT1级联途径,激活NF⁃κB,最终诱导细胞因子产生㊂其中活化的NF⁃κB 亚基主要是C⁃Rel 和P65,C⁃Rel 亚基可激活Th17细胞释放IL⁃23p19和IL⁃1β,与机体抗致病性念珠菌的感染密切相关[11]㊂最近有研究报道,Dectin⁃1/Syk /ROS /NLRP3通路途径的活化能触发炎症复合体,并且对于巨噬细胞限制寄生虫复制是非常重要的,能有效地对抗宿主对寄生虫的感染[12]㊂此外,Dectin⁃1被认为是第1个能够诱导非典型NF⁃κB 途径的模式识别受体[13]㊂活化的Syk 首先激活NF⁃κB 诱导酶(NIK),后者直接调节NF⁃κB 的合成和激活IKKα,诱导基因转录[14]㊂2.2 非Syk 依赖通道 近年来的研究倾向于认为非Syk 依赖通道与丝氨酸⁃苏氨酸激酶Raf⁃1有关[13]㊂Dectin⁃1受体结合β葡聚糖后,DED 基序活化,激活Ras,进一步激活Raf⁃1,诱导NF⁃κB 合成㊂Raf⁃1可使p65磷酸化,与RelB 形成P65⁃RelB 二聚体,促进DNA 的转录;也可促使IL⁃12p70的合成,诱导Th1细胞分化成熟;还可诱导Th17细胞合成IL⁃23㊁IL⁃1β㊁IL⁃6等[15]㊂Gringhuis 等[16]证实了Raf⁃1的活化受Dectin⁃1受体干扰而不受Syk 影响,并阐明了非依赖Syk 通路中Dectin⁃1受体通过Raf⁃1通路激活了NF⁃κB,诱导细胞因子的分泌,不依赖于Syk 的作用㊂2.3 Dectin⁃1受体的其他通路 Dectin⁃1受体诱导的通路中,还涉及其他转录因子的活化,如活化T细胞核因子的激活(NFAT)㊂在依赖Syk 的NF⁃κB 通路中,PLCγ活化可诱导可溶性IP3,作用于内质网上的钙离子通道,促进Ca 2+释放,胞内Ca 2+浓度的升高激活钙调磷酸酶,使NFAT 去磷酸化,调节基因转录,并使树突细胞IL⁃10和IL⁃2的合成增加㊂与Dectin⁃1受体相互作用的PRR 有TLRS,如TLR4㊁TLR2㊁TLR9㊁TLR7和TLR5等㊂TLRs 依赖的Syk 通路与依赖的MyD88通路能相互作用,协同促进细胞因子的释放㊂Dectin⁃1受体与CR3相互作用时,能使感染灶的嗜中性粒细胞聚集和ROS 的合成增多[17],从而激活MAPK 和PI3K,诱导NF⁃κB 合成㊂最新研究显示Dectin⁃1介导的Syk㊁MAPKsPI3K和NF⁃κB信号传导途径的激活有助于镰刀菌刺激的CXCL⁃8从BEAS⁃2B细胞释放,这为开发临床过敏新型治疗策略提供了重要依据[18]㊂3 在抗微生物免疫中的作用β⁃葡聚糖是真菌细胞壁的主要成分,占细胞壁干重的50%~60%㊂Dectin⁃1可介导识别多种真菌病原体,包括酵母菌属㊁念珠菌属㊁曲霉属㊁肺孢子菌属等㊂通过Dectin⁃1识别这些菌体可促进保护性应答反应,包括通过细胞吞噬作用对配体的摄取,呼吸爆发,花生四烯酸以及大量细胞因子和趋化因子的产生,包括TNF㊁IL⁃1α㊁CXCL2㊁IL⁃1β㊁IL⁃6[19]㊂但是,Dectin⁃1识别也可产生非保护性细胞因子,如IL⁃23和IL⁃10㊂树突状细胞产生IL⁃23是依赖于Dectin⁃1且由β⁃葡聚糖介导的过程[20]㊂IL⁃23可促进Th17反应,而该反应可抑制Th1的保护性反应,促进有害的炎症反应㊂相关研究显示Dectin⁃1通过MSK1/2和CREB依赖性途径调节IL⁃10的产生并促进调节性巨噬细胞标记物的诱导[21]㊂通过这个途径产生的IL⁃10能介导炎症的发生[22],在真菌感染时起负性调节作用,促进真菌持续存在以及长期免疫应答㊂Dectin⁃1识别真菌依赖于β⁃葡聚糖,Dectin⁃1是针对真菌致病形态(发芽的孢子㊁菌丝)非常重要的免疫分子,如非粒细胞缺乏肺曲霉病患者中血清Dectin⁃1水平就明显增高[23]㊂β⁃葡聚糖暴露既可于真菌细胞壁表面,又可于某些特殊区域,如芽痕㊂真菌病原体还可通过隐藏β⁃葡聚糖来避免宿主对其免疫识别,如菌丝㊂菌丝的发生是侵袭性曲霉病形成的基础㊂白念珠菌在宿主体内经历酵母相到菌丝相形态改变,有助于其毒力产生㊂酵母形态可诱导宿主Dectin⁃1介导保护性反应而菌丝形态则不能,菌丝可通过隐藏β⁃葡聚糖避免免疫识别,并有助于菌体与宿主共生,这种逃避识别β⁃葡聚糖受体Dectin⁃1的方式在真菌病原体中广泛存在㊂但是,促进β⁃葡聚糖暴露也可有利于抗真菌反应㊂有学者研究表明,虽然曲霉和念珠菌的菌丝不暴露β⁃葡聚糖,但是通过卡泊芬净处理后,菌体表面β⁃葡聚糖增加,继而增加巨噬细胞释放TNF和CXCL2等炎症反应[24]㊂研究表明,Dectin⁃1还识别分枝杆菌[25]㊂但有趣的是,分枝杆菌并不表达β⁃葡聚糖㊂其与Dectin⁃1相互作用的配体尚不清楚㊂Dectin⁃1可通过未知的配体识别分枝杆菌,同样该受体也可促进分枝杆菌的摄取并产生细胞因子及趋化因子㊂其中值得关注的是Dectin⁃1与TLR2合作激活巨噬细胞对分枝杆菌感染的促炎反应有重要作用[26]㊂相关体外研究提示Dectin⁃1可能与TLR2协作,诱导细胞因子的产生,包括IL⁃12,这些反应可能与结核分枝杆菌的吞噬有关[27]㊂但还有待于进一步研究㊂4 Dectin⁃1与其他受体的相互作用除了β⁃葡聚糖,真菌细胞壁还有其他PAMPS 被多种受体共同识别㊂一些受体的识别出现在真菌摄入及吞噬体成熟的不同阶段㊂研究发现Dectin⁃1在对病原微生物的识别中可与TLRs信号转导发挥协同作用㊂在巨噬细胞, Dectin⁃1与TLR2联合在抗真菌反应中产生TNF,这首次证明了TLR与非TLR的相互作用[28]㊂Dectin⁃1的ITAM样信号转导基序在活化时发生酪氨酸磷酸化,该受体可被募集到包含酵母多糖颗粒的吞噬体㊂在巨噬细胞和树突状细胞,Dectin⁃1可与其他MYD88偶联的TLRs(TLR2㊁TLR4㊁TLR5㊁TLR7㊁TLR9)相互作用,TLRs诱导NF⁃κB的信号转导并产生多种细胞因子,包括:TNF㊁IL⁃10㊁IL⁃6㊁IL⁃23㊂这些反应可被Dectin⁃1增强㊂同样,TLR信号传导还可以增强Dectin⁃1激发的ROS产生㊂因此, Dectin⁃1和TLR直接识别微生物成分所激发的炎症反应呈协同性和非依赖性㊂这些提示通过不同家族天然免疫受体对微生物成分的协同识别是调控炎症反应的关键环节㊂Dectin⁃1受体还可识别真菌其他未知结构,诱导IL⁃12的产生,但目前机制尚不明确[29]㊂同时,这些相互作用也可导致IL⁃12下调㊂对IL⁃12及IL⁃23的负向调节似乎有助于Dectin⁃1介导的Th17反应[30]㊂它们均需要Dectin⁃1介导的Syk和Raf⁃1信号传导途径[13]㊂除此之外,Dectin⁃1可与SIGNR1协同结合真菌,与DC⁃SIGN共刺激引起花生四烯酸代谢,促发炎症反应㊂另外,Dectin⁃1还与四穿膜区蛋白质(traspanin)CD63以及CD37相互作用,使Dectin⁃1稳定于质膜上并介导IL⁃6产生㊂最新研究显示Dectin⁃1的表达还和TLR2/TLR3/TLR4受体有关,可能是建立在TLR2/TLR4对烟曲霉早期识别的基础上,TLR3可能起协同作用[31]㊂5 Dectin⁃1在自身免疫及疾病中的作用Dectin⁃1作为细胞活化的受体可有助于炎症性疾病的发展㊂目前,比较确实的证据来自β⁃葡聚糖可诱导SKG小鼠发生类风湿性关节炎,此外β⁃葡聚糖诱导的关节炎可被Dectin⁃1阻断[32],这表明, Dectin⁃1介导的炎症反应与自身免疫性关节炎的发展相关㊂最新研究显示Dectin⁃1通过激活CD11b+树突状细胞在变应性气道炎症中发挥重要作用[33],这可能与变应性哮喘严重程度相关㊂此外,研究表明Dectin⁃1的表达与白塞病的关节症状相关[34]㊂PTPN22基因内的单核苷酸多态性是一种诱发多种自身免疫性疾病的强烈遗传风险因子㊂目前研究显示PTPN22是一种新的Dectin⁃1信号调节剂,这提供了基因赋予的天然受体信号传导干扰和自身免疫性疾病风险之间的联系[35]㊂6 Dectin⁃1在β⁃葡聚糖诱导的免疫调节中的作用 作为β⁃葡聚糖主要受体,Dectin⁃1在其免疫调节作用中起重要作用,Dectin⁃1诱导的许多细胞反应都与β⁃葡聚糖在体内的作用相关㊂β⁃葡聚糖可诱导树突细胞成熟成为重要的专职抗原提呈细胞(professional APCs),APCs与T细胞相互作用可促进其活化㊂因此,作为β⁃葡聚糖的受体,存在于树突细胞的Dectin⁃1可决定T细胞的活化状态㊂此外,Dectin⁃1及其信号传导通路缺陷可影响颗粒性β⁃葡聚糖诱导的炎症反应[36]㊂相关研究显示,敲除Dectin⁃1基因或Dectin⁃1信号通路被受体激动剂凝胶多糖干扰或阻断,髓系细胞的吞噬和杀伤真菌的功能将受到明显抑制[37]㊂近年来研究利用封闭性单克隆抗体证明Dectin⁃1有助于抗肿瘤活性[38]㊂虽然还没有实验室证据,但推测Dectin⁃1可能通过共刺激TLR反应有助于β⁃葡聚糖的抗感染活性㊂最近研究表明抑制Dectin⁃1介导的信号传导是潜在的免疫疗法,其可与其他免疫疗法协同用于胰腺癌患者的治疗[39]㊂7 潜在的临床应用相关动物实验显示外周血粒细胞表达的Dectin⁃1水平与真菌感染相关,推测Dectin⁃1很可能是真菌感染的一种重要标识[40],此外,最新研究显示TLR2和dectin⁃1水平可能作为治疗或诊断烟曲霉感染的有希望的生物标志物[41]㊂由于β⁃葡聚糖可以出现在真菌感染的患者血液内,因此有学者建议可利用Dectin⁃1制成探针,检测血液中颗粒性及可溶性β⁃葡聚糖㊂现已合成可溶性嵌合型Dectin⁃1,它含有胞外小鼠受体的CRD及短杆区并与人类IgG Fc段融合㊂实验表明它可检测到活的真菌细胞壁β⁃葡聚糖[42]㊂因此,其在真菌感染的诊断中有潜在的应用价值㊂利用Dectin⁃Fc融合蛋白可增强SCID小鼠杀伤卡氏肺孢子菌的能力并减少肺组织的菌载量㊂同样,该融合蛋白可增强小鼠肺组织巨噬细胞杀伤烟曲霉,降低肺菌载量从而降低了侵袭性肺曲霉病小鼠的死亡率[43]㊂最新研究发现FcRγ可以负调节树突状细胞(DC)中的Dectin⁃1反应,根据Dectin⁃1在微生物和肿瘤细胞反应中的作用,推测Dectin⁃1可能在疫苗和癌症治疗发展中有潜在的应用价值[44]㊂最新研究显示食物来源的β⁃葡聚糖可通过Dectin⁃1⁃IL⁃17F⁃钙卫蛋白轴来控制特定的共生微生物群以维持肠内稳态[45]㊂这提示了肠道紊乱疾病治疗的一种新方法㊂临床上大量免疫缺损患者对真菌表现较高的易感性,而大量研究证实,β⁃葡聚糖与Dectin⁃1受体间的作用方式影响着这些糖类的免疫调节活性㊂因此,其在免疫调节活性方面的研究有十分巨大的潜在应用价值㊂8 总结及展望对Dectin⁃1的研究使我们更深入了解固有免疫及适应性免疫的功能㊂它的发现解决了多年来关于这一受体分子存在的争议㊂其在组织㊁细胞的广泛表达为该受体的生物学研究和免疫细胞识别β⁃葡聚糖开辟了新的视角㊂目前已经越来越多地了解了这一受体的信号传导途径以及它与其他受体的相互作用㊂就Dectin⁃1对于β⁃葡聚糖免疫调控能力而言,无疑是一个新的治疗性药物设计靶点㊂进一步对Dectin⁃1在体内作用研究以及深入探讨Dectin⁃1与其他受体相互作用的关系可能是未来抗真菌免疫机制的研究重点,并将有助于推动以β⁃葡聚糖为基础的抗感染和抗肿瘤治疗研究㊂参考文献:[1] 骆雪萍.真菌细胞壁病原相关分子模式TLR/Dectin⁃1通路及相关细胞因子的免疫作用[J].细胞与分子免疫学杂志,2014, 30(8):892⁃895.LUO XP.Effect of TLR/Dectin⁃1pathway and related cytokines on fungal cell⁃wall pathogens[J].J Cell Mol Immunol,2014,30(8): 892⁃895.[2] 董碧麟,李东升,段逸群,等.Dectin⁃1内在化表达介导氧依赖性方式杀伤白色念珠菌[J].中华微生物学和免疫学杂志, 2012,32(7):577⁃584.Dong BL,Li DS,Duan YQ,et al.Internalization of Dectin⁃1 mediates oxygen⁃dependent killing of Candida albicans[J].Chin J Microbiol Immunol,2012,32(7):577⁃584.[3] Takano T,Motozono C,Imai T,et al.Dectin⁃1intracellular domaindetermines species⁃specific ligand spectrum by modulating receptor sensitivity[J].J Biol Chem,2017,292(41):16933. [4] Hardison SE,Brown GD.C⁃type lectin receptors orchestrateantifungal immunity[J].Nature Immunol,2012,13(9):817.[5] Plato A,Willment JA,Brown GD.C⁃type lectin⁃like receptors ofthe dectin⁃1cluster:ligands and signaling pathways[J].Intern Rev Immunol,2013,32(2):134.[6] Upchurch K,Oh S,Joo H.Dectin⁃1in the control of Th2⁃type Tcell responses[J].Receptors Clin Invest,2016,3(1):e1094.[7] Plato A,Willment JA,Brown GD.C⁃type lectin⁃like receptors ofthe dectin⁃1cluster:ligands and signaling pathways[J].Intern Rev Immunol,2013,32(2):134⁃156.[8] Fuller GLJ,Williams JAE,Tomlinson MG,et al.The C⁃type lectinreceptors CLEC⁃2and Dectin⁃1,but not DC⁃SIGN,signal via a novel YXXL⁃dependent signalling cascade[J].J Biol Chem, 2007,282(17):12397.[9] Huysamen C,Willment JA,Dennehy KM,et al.CLEC9A is a novelactivation C⁃type lectin⁃like receptor expressed on BDCA3+ dendritic cells and a subset of monocytes[J].J Biol Chem,2008, 283(24):16693.[10] Huysamen C,Brown GD.The fungal pattern recognition receptor,Dectin⁃1,and the associated cluster of C⁃type lectin⁃like receptors[J].Fems Microbiology Letters,2009,290(2):121. [11] Si G,Ba W,Tm K,et al.Selective C⁃Rel activation via Malt1controls anti⁃fungal TH⁃17immunity by dectin⁃1and dectin⁃2[J].PLoS Pathog,2011,7(1):e1001259.[12] Lima⁃Junior DS,Twp M,Vlg C,et al.Dectin⁃1activation duringleishmania amazonensis phagocytosis prompts syk⁃dependentreactive oxygen species production to trigger inflammasomeassembly and restriction of parasite replication[J].J Immunol,2017,199(6):ji1700258.[13] Gringhuis SI,Den DJ,Litjens M,et al.Dectin⁃1directs T helpercell differentiation by controlling noncanonical NF⁃kappaBactivation through Raf⁃1and Syk[J].Nature Immunol,2009,10(2):203.[14] Yang H,He H,Dong Y.CARD9Syk⁃dependent and Raf⁃1Syk⁃independent signaling pathways in target recognition of Candidaalbicans by Dectin⁃1[J].Eur J Clin Microbiol Infect Dis,2011,30(3):303.[15] Deng Z,Ma S,Zhou H,et al.Tyrosine phosphatase SHP⁃2mediates C⁃type lectin receptor⁃induced activation of the kinaseSyk and anti⁃fungal TH17responses[J].Nature Immunol,2015,16(6):642.[16] Gringhuis SI,Dunnen JD,Litjens M,et al.Dectin⁃1directs Thelper cell differentiation by controlling noncanonical NF⁃[kappa]B activation through Raf⁃1and Syk[J].NatureImmunol,2009,10(2):203.[17] Li X,Utomo A,Cullere X,et al.Theβ⁃glucan receptor dectin⁃1activates the integrin mac⁃1in neutrophils via vav proteinsignaling to promote candida albicans clearance[J].Cell HostMicrobe,2011,10(6):603⁃615.[18] Yeh CC,Horng HC,Hong C,et al.Dectin⁃1⁃mediated pathwaycontributes to fusarium proliferatum⁃induced CXCL⁃8release fromhuman respiratory epithelial cells[J].Intern J Mole Sci,2017,18(3):624.[19] Vautier S,Sousa MD,Brown GD.C⁃type lectins,fungi and Th17responses[J].Cytokine Growth Factor Rev,2010,21(6):405.[20] Dennehy KM,Willment JA,Williams DL,et al.Reciprocalregulation of IL⁃23and IL⁃12following co⁃activation of Dectin⁃1and TLR signaling pathways[J].Eur J Immunol,2010,39(5):1379⁃1386.[21] Elcombe SE,Naqvi S,Bosch MWMVD,et al.Dectin⁃1regulatesIL⁃10production via a MSK1/2and CREB dependent pathwayand promotes the induction of regulatory macrophage markers[J].PLoS One,2013,8(3):e60086.[22] 赵 莹,骆雪萍,张 雪,等.Dectin⁃1在热处理光滑假丝酵母菌刺激大鼠气道上皮细胞中的作用及对IL⁃10和TNF⁃α表达的影响[J].中国感染控制杂志,2017,16(1):10⁃15.Zhao Y,Luo XP,Zhang X,et al.Dectin⁃1′s effect on heat⁃treated smooth muscle cells of rat airway epithelial cells and itseffect on IL⁃10and TNF⁃αexpression[J].Chin J InfectionControl Magazine,2017,16(1):10⁃15.[23] 徐小勇,陈 菲,高卫卫,等.非粒细胞缺乏肺曲霉病患者血清Dectin⁃1的检测[J].中国感染与化疗杂志,2014,14(4):301⁃304.Xu XY,Chen F,Gao WW,et al.Detection of serum Dectin⁃1inpatients with non⁃granulocyte⁃deficient pulmonary aspergillosis[J].Chin J Infection Chemotherapy,2014,14(4):301⁃304.[24] Hohl TM,Feldmesser M,Perlin DS,et al.Caspofungin modulatesinflammatory responses to aspergillus fumigatus through stage⁃specific effects on fungalβ⁃glucan exposure[J].J InfectiousDis,2008,198(2):176⁃185.[25] Tsoni SV,Brown GD.beta⁃Glucans and dectin⁃1[J].Ann N YAcad Sci,2008,1143(1143):45.[26] Yadav M,Schorey JS.The beta⁃glucan receptor dectin⁃1functionstogether with TLR2to mediate macrophage activation bymycobacteria[J].Blood,2006,108(9):3168⁃3175. [27] Shin DM,Yang CS,Yuk JM,et al.Mycobacterium abscessusactivates the macrophage innate immune response via a physicaland functional interaction between TLR2and dectin⁃1[J].Cellular Microbiol,2008,10(8):1608⁃1621.[28] Brown GD.Dectin⁃1:a signalling non⁃TLR pattern⁃recognitionreceptor[J].Nat Rev Immunol,2006,6(1):33. [29] Sancho D,Reis ESC.Signaling by myeloid C⁃type lectin receptorsin immunity and homeostasis[J].Ann Rev Immunol,2012,30(1):491.[30] Rivera A,Hohl TM,Collins N,et al.Dectin⁃1diversifiesAspergillus fumigatus⁃specific T cell responses by inhibiting Thelper type1CD4T cell differentiation[J].J Exp Med,2011,208(2):369.[31] 栗 方,曹 彬,曲久鑫,等.Dectin⁃1和TLR2/TLR3/TLR4受体在免疫缺陷小鼠侵袭性肺曲霉菌病的表达[J].中华临床医师杂志:电子版,2015,9:1626⁃1631.Li F,Cao B,Qu JX,et al.Expression of Dectin⁃1and TLR2/TLR3/TLR4receptors in invasive pulmonary aspergillosis in im⁃munodeficient mice[J].Clin J China Clinicians,2015,9:1626⁃1631[32] Dan JM,Kelly RM,Lee CK,et al.Role of the mannose receptor ina murine model of cryptococcus neoformans infection[J].Infection Immunity,2008,76(6):2362⁃2367.[33] Ito T,Hirose K,Norimoto A,et al.Dectin⁃1plays an importantrole in house dust mite⁃induced allergic airway inflammationthrough the activation of CD11b+dendritic cells[J].J Immunol,2017,198(1):69⁃70.[34] Choi B,Suh CH,Kim HA,et al.The correlation of CD206,CD209,and disease severity in behet′s disease with arthritis[J].Mediators Inflammation,2017,2017(2):7539529. [35] Purvis HA,Clarke F,Jordan CK,et al.Protein TyrosinePhosphatase PTPN22regulates IL⁃1βdependent Th17responsesby modulating dectin⁃1signaling in mice[J].Eur J Immunol,2018,48(2):306⁃315.[36] Leibundgut⁃Landmann S,Gross O,Robinson MJ,et al.Syk⁃andCARD9⁃dependent coupling of innate immunity to the inductionof T helper cells that produce interleukin17[J].Nat Immunol,2007,8(6):630⁃638.[37] Taylor PR,Tsoni SV,Willment JA,et al.Dectin⁃1is required forbeta⁃glucan recognition and control of fungal infection[J].Nature Immunology,2006,8(1):31.[38] Ikeda Y,Adachi Y,Ishii T,et al.Blocking effect of anti⁃Dectin⁃1antibodies on the anti⁃tumor activity of1,3⁃beta⁃glucan and thebinding of Dectin⁃1to1,3⁃beta⁃glucan[J].Biol Pharm Bull,2007,30(8):1384⁃1389.[39] Daley D,Mani VR,Mohan N,et al.Dectin1activation onmacrophages by galectin9promotes pancreatic carcinoma andperitumoral immune tolerance[J].Nature Med,2017,23(5):556⁃567.[40] Ozmentskelton TR,Fluiter EAD,Ha TZ,et al.Leukocyte Dectin⁃1expression is differentially regulated in fungal versuspolymicrobial sepsis[J].Critical Care Medicine,2009,37(3):1038⁃1045.[41] Zhang PP,Xin XF,Xu XY,et al.Toll⁃like receptor2and dectin⁃1function as promising biomarker for Aspergillus fumigatusinfection[J].Exp Ther Med,2017,14(4):3836⁃3840. [42] Graham LM,Tsoni SV,Willment JA,et al.Soluble Dectin⁃1as atool to detect beta⁃glucans[J].J Immunol Methods,2006,314(1⁃2):164⁃169.[43] Mattila PE,Metz AE,Rapaka RR,et al.Dectin⁃1Fc targeting ofaspergillus fumigatus beta⁃glucans augments innate defenseagainst invasive pulmonary aspergillosis[J].Antimicrob AgentsChemother,2008,52(3):1171⁃1172.[44] Pan YG,Yu YL,Lin CC,et al.FcεRIγ⁃Chain NegativelyModulates Dectin⁃1Responses in Dendritic Cells[J].FrontImmunol,2017,8:1424.[45] Kamiya T,Tang C,Kadoki M,et al.beta⁃Glucans in food modifycolonic microflora by inducing antimicrobial protein,calprotectin,in a Dectin⁃1⁃induced⁃IL⁃17F⁃dependent manner[J].MucosalImmunol,2017:doi:10.1038/mi.2017.86.[收稿2017⁃12⁃21 修回2018⁃01⁃22](编辑 倪 鹏)㊃征稿征订㊃‘中国免疫学杂志“征稿㊁征订启事 ‘中国免疫学杂志“是中国免疫学会会刊,是公开发行的全国性学术期刊,为基础医学㊁生物学的核心期刊,是美国‘化学文摘“(CA)的源期刊,为中国科学引文数据库㊁中国学术期刊文摘㊁中国生物医学文摘的来源期刊㊂曾获全国百强科技期刊㊁第二届国家期刊奖百种重点期刊㊁中国首批期刊方阵 双效”期刊㊁第四届中国精品科技期刊㊁首届北方优秀期刊奖㊂本刊主要栏目有专家述评㊁基础免疫学㊁中医中药与免疫㊁生物治疗㊁临床免疫学㊁免疫学技术与方法㊁教学园地㊁专题综述㊁短篇快讯㊁信息速递等㊂本刊为月刊,A4开本,160页,铜版纸印刷,彩图随文㊂定价18.00元/本,216.00元/年,邮发代号12⁃89,全国邮局均可订阅㊂为减轻自费读者负担,对自费个人订户实行8折优惠,16.00元/本(含邮费);中国免疫学会会员订户每本14.5元(免费邮寄)㊂如错过订阅时间可直接汇款到‘中国免疫学杂志“编辑部,请注明所购卷期㊁册数及 自费”字样㊂同时欢迎医药㊁生物制剂㊁医疗器械厂家刊登广告及作者网上投稿㊂本刊目前仅接收在线投稿,为了提高稿件处理速度,希望广大作者在投稿时留下常用的电子邮箱㊁手机或其他联系电话,保证编辑部与作者间的沟通更快捷㊁及时㊂地址:长春市建政路971号‘中国免疫学杂志“编辑部 邮编:130061(传真)电话:0431-******** E⁃mail:zhmizazh@ 网址:。

模式识别发展及现状综述
目前,模式识别已经成为数据处理和分析技术中一个重要的组成部分,它在不同的应用领域中得到了广泛的应用,比如生物识别,自动机器人,
语音识别等。
模式识别是一种使机器获得能力,以识别和理解事物的能力,它把视觉,听觉,触觉等信息的处理过程变成可实现的机器任务,从而从
大量的信息中提取有用的信息,达到其中一种有意义的目的。
模式识别的研究有着悠久的历史,其发展历程大致可分为四个阶段:
传统模式识别,统计机器学习、深度学习和智能,每一阶段都为模式识别
技术的发展奠定了基础。
传统模式识别可以追溯到1900年以前,主要是通过规则来识别特征
或分类样本。
在传统模式识别阶段,主要有基于特征的模式识别、基于模
型的模式识别和基于结构的模式识别。
基于特征的模式识别主要是提取具
有代表性的特征,并根据特征判断类别之间的差异;基于模型的模式识别
则是根据建立的模型,通过最小二乘法或最小化误差函数,识别特征;基
于结构的模式识别则是抽取数据中的空间结构特征,从而实现类样本的聚
类分离。
随着计算机处理速度的不断提高,统计机器学习技术也取得了很大的
进展。

人工智能机器人模式识别与智能控制研究人工智能机器人是当今科技发展的热门领域,其涉及的机器人模式识别与智能控制技术具有广泛的应用前景。
本文将深入探讨人工智能机器人模式识别与智能控制的研究进展和应用。
一、概述人工智能机器人模式识别是指利用计算机视觉和机器学习等技术,使机器人能够从环境中感知、识别并理解各种模式和特征,从而进行智能决策和控制。
智能控制则是指通过对模式识别结果的集成分析和处理,使机器人能够自主地执行各种任务,并根据环境的变化做出相应的调整。
目前,人工智能机器人模式识别与智能控制已经在工业制造、医疗卫生、农业等领域得到广泛应用,并在人机协作、智能交通、智能家居等领域展现出巨大潜力。
二、模式识别技术1. 计算机视觉计算机视觉是人工智能机器人模式识别的关键技术之一,其通过图像和视频的处理与分析,使机器人能够识别和理解周围环境中的各种视觉模式和特征。
计算机视觉技术包括图像预处理、特征提取、目标检测和识别等方法。
在模式识别任务中,计算机视觉技术可以帮助机器人识别并分类不同的物体、人脸等模式,并在后续的智能控制中进行相应的处理。
2. 机器学习机器学习是人工智能机器人模式识别的核心技术之一,其通过对大量训练数据的学习和模型的训练,使机器人能够自动识别和分类各种模式和特征。
机器学习技术包括有监督学习、无监督学习和增强学习等方法。
在模式识别任务中,机器学习技术可以帮助机器人建立分类模型,从而对不同的模式进行分类、识别和理解。
三、智能控制技术1. 基于规则的控制基于规则的控制是人工智能机器人智能控制的一种常用方法,其通过事先定义一系列的规则和条件,使机器人能够根据环境的变化和模式识别结果做出相应的决策和控制。
基于规则的控制方法适用于模式识别任务中简单规则和条件的决策过程,并具有实时性和高效性的优势。
2. 强化学习强化学习是一种通过智能体与环境的交互学习,从而使其能够自主地做出决策和控制的方法。
在智能控制任务中,机器人可以通过强化学习的方式学习和优化其行为策略,从而根据不同的模式识别结果采取不同的动作和控制策略。

药物分析中的模式识别方法研究当代药物分析中的模式识别方法研究摘要:随着科学技术的不断进步和药物需求的增长,药物分析的研究也迎来了重要的发展机遇。
模式识别方法作为一种重要的药物分析手段,在定性和定量分析中发挥着重要作用。
本文将探讨药物分析中的模式识别方法的研究进展,包括其原理、应用和发展趋势。
一、概述模式识别方法是一种基于数学统计的分析技术,通过从大量数据中提取有用的信息,实现对药物样品进行分类、定性和定量分析。
它充分利用了计算机技术和数学模型,能够快速准确地对药物样品进行分析,提高药物分析的效率和精确度。
二、原理模式识别方法主要包括聚类分析、判别分析和主成分分析。
聚类分析是将相似的药物样品归为一类,不同类之间的样品具有明显的差异性。
判别分析根据已有的样品信息,建立分类模型,用于对未知样品进行分类。
主成分分析通过降维处理,将复杂的多维数据转化为少数几个主要成分,以实现对药物样品的分类和比较。
三、应用模式识别方法在药物分析中有着广泛的应用。
首先,它可以用于药物质量控制,通过对大量样品的分析,建立质量标准,确保药品的质量。
其次,模式识别方法在药物鉴别和溯源方面也有重要应用。
通过对药物样品进行特征提取和匹配,可以快速准确地鉴别出真伪药品和来源。
此外,模式识别方法在药物安全性评估和临床疗效研究中也发挥着重要作用。
四、发展趋势目前,随着科学技术的进步,模式识别方法在药物分析领域的应用不断推进。
首先,随着仪器设备的升级和数据采集的改进,模式识别方法在药物分析中的精确度和灵敏度将得到进一步提升。
其次,机器学习和深度学习等人工智能技术的引入,将进一步拓展模式识别方法的应用范围和效果。
最后,模式识别方法与其他药物分析技术的结合,如质谱和色谱技术,将促进药物分析技术的进一步发展。
结论:模式识别方法在当代药物分析中具有重要的地位和作用。
它通过从大量数据中提取信息,实现对药物样品的分类、定性和定量分析。
在药物质量控制、药物鉴别和溯源、药物安全性评估等方面都发挥着重要作用。
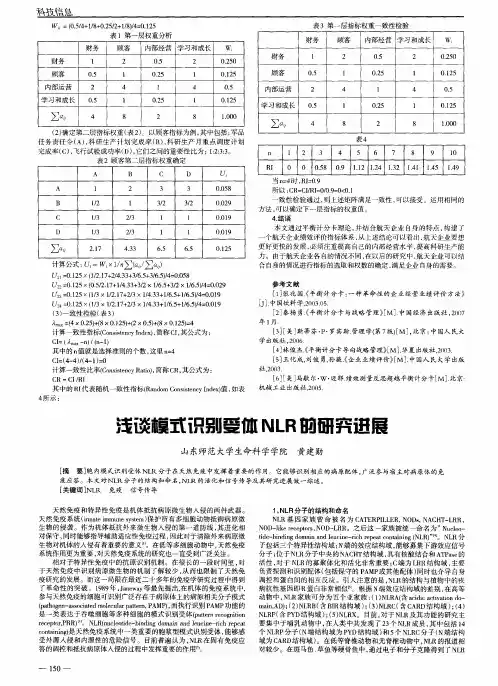
模式识别受体及其信号转导机制的研究进展安华章第二军医大学免疫学教研室医学免疫学国家重点实验室免疫识别--免疫反应发生发展的基础“自我”(self)“非我”(nonself)免疫应答immune response免疫耐受immune tolerance)机体防御系统系统的组成Turvey SE. et al. J Allergy Clin Immunol. Feb 2010; 125(2 Suppl 2): S24–S32固有免疫研究起始于19世纪后叶吞噬细胞(1883)Metchnikoff E开创了固有免疫研究先河, 获1908诺贝尔奖炎症的发生起始于固有免疫细胞对病原的识别固有免疫细胞的活化促进获得性免疫反应的发生Akira S. Proc Jpn Acad Ser B Phys Biol Sci. Apr 2009; 85(4): 143–1567抗原提呈细胞调节获得性免疫反应的类型Anne Cooke. Rev Diabet Stud. 2006 Summer;3(2):72-75免疫细胞如何识别并区分不同种类病原体并发生适当的免疫反应?Pattern recognition非克隆性表达的PRR识别不同种类的PAMP,诱导不同类型的细胞因子产生Ruslan Medzhitov and Charles A Janeway JrCurrent Opinion in Immunology 1997, 9:4-9•“病原相关分子模式”(pathogen associated molecular pattern,PAMP):一类或一群特定的微生物病原体(及其产物)共有的某些非特异性、高度保守的分子结构,可被固有免疫细胞所识别。
如:LPS、LTA、细菌DNA、病毒RNA/DNA•“模式识别受体” (pattern-recognition receptors,PRR)是一类主要表达于天然免疫细胞表面、非克隆性分布的分子,可识别一种或多种PAMP或DAMP并活化免疫细胞、介导固有免疫反应。
航空航天设备故障诊断与故障模式识别研究航空航天设备是现代化社会不可或缺的一部分,其安全、可靠性和稳定性始终受到广泛关注。
因为一旦出现故障,可能会导致严重的后果,包括人员伤亡、物品损失等。
在这种情况下,如何快速地诊断和识别故障模式是非常关键的。
因此,航空航天领域的专家一直在研究如何优化和改进故障诊断和识别方法。
本文将介绍航空航天设备故障诊断和故障模式识别的研究进展,并探讨未来的发展趋势。
1. 航空航天设备故障诊断研究航空航天设备的故障诊断是保证其安全、可靠性和稳定性的必要手段。
传统的故障诊断方法主要依靠人工判断。
但由于航空航天设备的复杂性,人工诊断难以保证准确性和速度。
因此,学者们开始探索新的故障诊断方法,如基于机器学习的方法。
机器学习是一种人工智能的方法,它可以通过“学习”已有数据集从而预测新数据。
科学家们发现,应用机器学习方法在航空航天设备故障诊断方面可以显著提高准确度和速度。
其中深度学习是当前广泛研究的一个领域,因为它可以自动学习模式识别特征,不需要过多的人工干预。
以“电动机故障”为例,科学家通过处理现有数据集,训练了深度神经网络。
当设备出现故障时,这个已经训练好的神经网络可以通过数据分析给出一个准确的诊断结果。
2. 故障模式识别的研究除了故障诊断,故障模式识别也是航空航天领域的另一个热点研究方向。
故障模式是指在不同的故障情况下,航空航天设备出现的不同特征。
学者们通过从大量的数据中提取故障特征来识别和分析故障。
例如,他们通过对飞机黑匣子的数据进行分析,可以得出飞机在起飞前是否存在故障。
在故障模式识别方面,机器学习也发挥了至关重要的作用。
与故障诊断类似,科学家们通过处理现有的数据,训练出深度学习模型来进行故障模式识别。
但是,故障模式识别仍然存在一些挑战,如大量的数据预处理、模型选择和优化等。
为了解决这些问题,科学家们正在研究一些新的算法和技术。
3. 未来趋势在未来,航空航天设备故障诊断和故障模式识别将继续得到科学家和工程师们的深入研究。
模式识别研究进展摘要:自20 世纪60年代以来,模式识别的理论与方法研究及在工程中的实际应用取得了很大的进展。
本文先简要回顾模式识别领域的发展历史和主要方法的演变,然后围绕模式分类这个模式识别的核心问题,就概率密度估计、特征选择和变换、分类器设计几个方面介绍近年来理论和方法研究的主要进展,最后简要分析将来的发展趋势。
1. 前言模式识别(Pattern Recognition)是对感知信号(图像、视频、声音等)进行分析,对其中的物体对象或行为进行判别和解释的过程。
模式识别能力普遍存在于人和动物的认知系统,人和动物获取外部环境知识,并与环境进行交互的重要基础。
我们现在所说的模式识别一般是指用机器实现模式识别过程,是人工智能领域的一个重要分支。
早期的模式识别研究是与人工智能和机器学习密不可分的,如Rosenblatt 的感知机和Nilsson 的学习机就与这三个领域密切相关。
后来,由于人工智能更关心符号信息和知识的推理,而模式识别更关心感知信息的处理,二者逐渐分离形成了不同的研究领域。
介于模式识别和人工智能之间的机器学习在20 世纪80 年代以前也偏重于符号学习,后来人工神经网络重新受到重视,统计学习逐渐成为主流,与模式识别中的学习问题渐趋重合,重新拉近了模式识别与人工智能的距离。
模式识别与机器学习的方法也被广泛用于感知信号以外的数据分析问题(如文本分析、商业数据分析、基因表达数据分析等),形成了数据挖掘领域。
模式分类是模式识别的主要任务和核心研究内容。
分类器设计是在训练样本集合上进行优化(如使每一类样本的表达误差最小或使不同类别样本的分类误差最小)的过程,也就是一个机器学习过程。
由于模式识别的对象是存在于感知信号中的物体和现象,它研究的内容还包括信号/图像/ 视频的处理、分割、形状和运动分析等,以及面向应用(如文字识别、语音识别、生物认证、医学图像分析、遥感图像分析等)的方法和系统研究。
本文简要回顾模式识别领域的发展历史和主要方法的演变,介绍模式识别理论方法研究的最新进展并分析未来的发展趋势。
由于Jain 等人的综述[3] 已经全面介绍了2000 年以前模式分类方面的进展,本文侧重于2000 年以后的研究进展。
2. 历史回顾现代模式识别是在20 世纪40 年代电子计算机发明以后逐渐发展起来的。
在更早的时候,已有用光学和机械手段实现模式识别的例子,如在1929 年Gustav Tauschek 就在德国获得了光学字符识别的专利。
作为统计模式识别基础的多元统计分析和鉴别分析也在电子计算机出现之前提出来了。
1957 年IBM 的C.K. Chow 将统计决策方法用于字符识别。
然而,“模式识别” 这个词被广泛使用并形成一个领域则是在20 世纪60 年代以后。
1966 年由IBM 组织在波多黎各召开了第一次以“模式识别”为题的学术会议。
Nagy 的综述和Kanal 的综述分别介绍了1968 年以前和1968-1974 的研究进展。
70 年代几本很有影响的模式识别教材(如Fukunaga, Duda & Hart )的相继出版和1972 年第一届国际模式识别大会(ICPR)的召开标志着模式识别领域的形成。
同时,国际模式识别协会(IAPR )在1974年的第二届国际模式识别大会上开始筹建,在1978年的第四届大会上正式成立。
统计模式识别的主要方法,包括Bayes 决策、概率密度估计 (参数方法和非参数方法) 、特征提取(变换)和选择、聚类分析等,在20 世纪60 年代以前就已经成型。
由于统计方法不能表示和分析模式的结构,70 年代以后结构和句法模式识别方法受到重视。
尤其是付京荪(K.S. Fu)提出的句法结构模式识别理论在70-80年代受到广泛的关注。
但是,句法模式识别中的基元提取和文法推断 (学习) 问题直到现在还没有很好地解决,因而没有太多的实际应用。
20 世纪80 年代Back-propagation (BP) 算法的重新发现和成功应用推动了人工神经网络研究和应用的热潮。
神经网络方法与统计方法相比具有不依赖概率模型、参数自学习、泛化性能良好等优点,至今仍在模式识别中广泛应用。
然而,神经网络的设计和实现依赖于经验,泛化性能不能确保最优。
90 年代支持向量机(SVM) 的提出吸引了模式识别界对统计学习理论和核方法(Kernel methods)的极大兴趣。
与神经网络相比,支持向量机的优点是通过优化一个泛化误差界限自动确定一个最优的分类器结构,从而具有更好的泛化性能。
而核函数的引入使很多传统的统计方法从线性空间推广到高维非线性空间,提高了表示和判别能力。
结合多个分类器的方法从90 年代前期开始在模式识别界盛行,后来受到模式识别界和机器学习界的共同重视。
多分类器结合可以克服单个分类器的性能不足,有效提高分类的泛化性能。
这个方向的主要研究问题有两个:给定一组分类器的最佳融合和具有互补性的分类器组的设计。
其中一种方法,Boosting ,现已得到广泛应用,被认为是性能最好的分类方法。
进入21 世纪,模式识别研究的趋势可以概括为以下四个特点。
一是Bayes 学习理论越来越多地用来解决具体的模式识别和模型选择问题,产生了优异的分类性能[11]。
二是传统的问题,如概率密度估计、特征选择、聚类等不断受到新的关注,新的方法或改进/混合的方法不断提出。
三是模式识别领域和机器学习领域的相互渗透越来越明显,如特征提取和选择、分类、聚类、半监督学习等问题成为二者共同关注的热点。
四是由于理论、方法和性能的进步,模式识别系统开始大规模地用于现实生活,如车牌识别、手写字符识别、生物特征识别等。
3. 模式识别研究现状3.1 模式识别系统和方法概述模式识别过程包括以下几个步骤:信号预处理、模式分割、特征提取、模式分类、上下文后处理。
预处理通过消除信号/图像/视频中的噪声来改善模式和背景间的可分离性;模式分割是将对象模式从背景分离或将多个模式分开的过程;特征提取是从模式中提取表示该模式结构或性质的特征并用一个数据结构(通常为一个多维特征矢量)来表示;在特征表示基础上,分类器将模式判别为属于某个类别或赋予其属于某些类别的概率;后处理则是利用对象模式与周围模式的相关性验证模式类别的过程。
模式识别系统中预处理、特征提取(这里指特征度量的计算,即特征生成)和后处理的方法依赖于应用领域的知识。
广义的特征提取包括特征生成、特征选择和特征变换(维数削减)两个过程和分类器设计一样,需要在一个样本集上进行学习(训练):在训练样本上确定选用哪些特征、特征变换的权值、分类器的结构和参数。
由于句法和结构模式识别方法是建立在完全不同于特征矢量的模式表示基础上且还没有得到广泛应用,本文与Jain 等人一样,主要关注统计模式识别(广义地,包括神经网络、支持向量机多分类器系统等)的进展。
模式分类可以在概率密度估计的基础上计算后验概率密度,也可以不需要概率密度而直接近似估计后验概率或鉴别函数(直接划分特征空间)。
基于概率密度估计的分类器被称为生成模型(Generative model),如高斯密度分类器、Bayes 网络等;基于特征空间划分的分类器又被称为判别模型(Discriminative model ),如神经网络、支持向量机等。
生成模型每一类的参数在一类的“特征提取” 在很多时候就是指特征变换或维数削减,有时候也指从模式信号计算特征度量的过程(特征生成)。
这就需要根据语言的上下文来判断它的意思。
训练样本上分别估计,当参数模型符合样本的实际分布或训练样本数比较少时,生成模型的分类性能优良。
判别模型在训练中直接调整分类边界,以使不同类别的样本尽可能分开,在训练样本数较多时能产生很好的泛化性能。
但是,判别模型在训练时每一类参数的估计要同时考虑所有类别的样本,因而训练的计算量较大。
3.2 概率密度估计概率密度估计和聚类一样,是一个非监督学习过程。
研究概率密度估计主要有三个意义:分类、聚类(分割) 、异常点监测(Novelty detection) 。
在估计每个类别概率密度函数的基础上,可以用Bayes 决策规则来分类。
概率密度模型经常采用高斯混合密度模型(Gaussian mixture model, GMM) ,其中每个密度成分可以看作是一个聚类。
异常点监测又称为一类分类(One-class classification) ,由于只有一类模式的训练样本,在建立这类模式的概率密度模型的基础上,根据相对于该模型的似然度来判断异常模式。
高斯混合密度估计常用的Expectation-Maximization (EM) 算法被普遍认为存在三个问题:估计过程易陷于局部极值点,估计结果依赖于初始化值,不能自动确定密度成分的个数。
对于成分个数的确定,提出了一系列的模型选择准则,如Bayes 准则、最小描述长度(MDL) 、Akaike Information Criterion (AIC) 、最小消息长度(MML) 等。
概率密度估计的另一种新方法是稀疏核函数描述(支持向量描述) 。
Scholkopf 等人采用类似支持向量机的方法,用一个核特征空间的超平面将样本分为两类,使超平面外的样本数不超过一个事先给定的比例。
该超平面的函数是一个样本子集 (支持向量) 的核函数的加权平均,可以像支持向量机那样用二次规划算法求得。
Tax 和Duin 的方法是用核空间的一个球面来区分区域内和区域外样本,同样地可以用二次规划进行优化。
3.3 特征选择特征选择和特征变换都是为了达到维数削减的目的,在降低分类器复杂度的同时可以提高分类的泛化性能。
二者也经常结合起来使用,如先选择一个特征子集,然后对该子集进行变换。
近年来由于适应越来越复杂(特征维数成千上万,概率密度偏离高斯分布) 的分类问题的要求,不断提出新的特征选择方法,形成了新的研究热点。
特征选择的方法按照特征选择过程与分类器之间的交互程度可以分为过滤式(Filter) 、Wrapper、嵌入式、混合式几种类型。
过滤式特征选择是完全独立于分类器的,这也是最常见的一种特征选择方式,选择过程计算量小,但是选择的特征不一定很适合分类。
在Wrapper 方法中,特征子集的性能使用一个分类器在验证样本上的正确率来衡量,这样选择的特征比较适合该分类器,但不一定适合其他的分类器。
由于在特征选择过程中要评价很多特征子集 (子集的数量呈指数级增长) ,即使采用顺序前向搜索,Wrapper 的计算量都是很大的,只适合特征维数不太高的情况。
Wrapper 的另一个问题是当训练样本较少时会造成过拟合,泛化性能变差。
特征选择领域大部分的研究工作都集中在过滤式方法。
模式识别领域早期的工作多把关注点放在搜索策略上,特征子集评价准则多采用基于高斯密度假设的距离准则,如Fisher 准则、Mahalanobis 距离等。