生物序列联配中的算法学习资料
- 格式:pdf
- 大小:9.43 MB
- 文档页数:71


kmp 序列碱基KMP算法是一种字符串匹配算法,主要应用于字符串匹配和搜索领域,在生物信息学中,KMP序列匹配算法也是一个常用的处理甲基化数据的方法之一。
KMP算法是一种高效的字符串匹配算法,它的核心思想是通过计算匹配串的前缀表格来快速匹配目标串。
同样的,KMP序列匹配算法也是通用的字符串匹配算法。
在生物信息学中,KMP序列匹配算法可以用来处理基因组中的碱基序列,如DNA,RNA等。
KMP序列匹配算法的基本流程是:1.通过计算目标串的匹配表格来快速匹配目标串中的子串。
该表格的计算方式是使用特定的规则来填充每一行,其中每一行代表了目标串中的一个前缀。
2.当我们要查找匹配模式串在目标串中出现的位置时,我们可以通过比对模式串和目标串的每个字符来快速移动模式串,并检查当前字符是否匹配。
如果匹配,我们就继续检查模式串的下一个字符。
3.匹配模式字符串的过程中,如果我们遇到了不匹配的字符,我们可以利用匹配表格来快速移动模式串。
这样,我们就可以避免重复比对不必要的字符,快速地找到目标串中所有匹配模式串的位置。
在生物信息学中,碱基序列是一个重要的概念。
碱基是生物体中最小的化学单元,它们组成了DNA和RNA分子中的基本单元。
每个碱基都包含一个氮原子基团和一个碳基团,它们通过一系列的化学键连接在一起。
序列是由碱基组成的有序排列,它是生物信息学中基本的概念之一。
其中,DNA和RNA序列是生物学研究中最常见的序列类型,这是因为它们在生物体中担任着许多关键的功能,如遗传信息的传递、蛋白质合成等。
KMP序列匹配算法可以用来处理基因组中的碱基序列,其主要步骤是将模式串和目标串中的碱基序列转换为字符串,然后使用KMP算法来快速查找匹配结果。
在生物信息学中,KMP序列匹配算法的应用非常广泛。
例如,我们可以使用KMP算法来查找基因组中的DNA序列中某个特定的碱基片段,或者对不同物种中的DNA序列进行比较等。
总之,KMP序列匹配算法是一种强大的字符串匹配算法,在生物信息学中也是一个重要的工具,在处理DNA、RNA等碱基序列方面有着广泛的应用。



生物序列分析中几个典型算法介绍生物信息学研究背景与方向序列家族的序列谱隐马尔可夫模型(Profile HMMs for sequence families )模体识别(Motif Discovery )刘立芳计算机学院西安电子科技大学生物秀-专心做生物!www.bbioo.com背景知识DNA脱氧核糖核酸1、DNA的分子组成核甘(nucleotides)•磷酸盐(phosphate)•糖(sugar)•一种碱基9腺嘌呤(A denine)9鸟嘌呤(G uanine)9胞嘧啶(C ytosine)9胸腺嘧啶(T hymine) 2、碱基的配对原则•A(腺嘌呤)—T(胸腺嘧啶)•C(鸟嘌呤)—G(胞嘧啶)3、一个嘌呤基与一个嘧啶基通过氢键联结成一个碱基对。
4、DNA分子的方向性5’→3’5、DNA的双螺旋结构RNA、转录和翻译1、RNA(核糖核酸):单链结构、尿嘧啶U代替胸腺嘧啶T、位于细胞核和细胞质中。
2、转录: DNA链→RNA链信使RNA(mRNA),启动子。
3、翻译: mRNA上携带遗传信息在核糖体中合成蛋白质的过程。
变异1、进化过程中由于不正确的复制,使DNA内容发生局部的改变。
2、变异的种类主要有以下三种:9替代(substitution)9插入或删除(insertion or deletion)9重排(rearrangement)基因intronexon基因组任何一条染色体上都带有许多基因,一条高等生物的染色体上可能带有成千上万个基因,一个细胞中的全部基因序列及其间隔序列统称为genomes(基因组)。
人类基因组计划(Human Genome Project)基因的编码1、基因编码是一个逻辑的映射,表明存储在DNA和mRNA中的基因信息决定什么样的蛋白质序列。
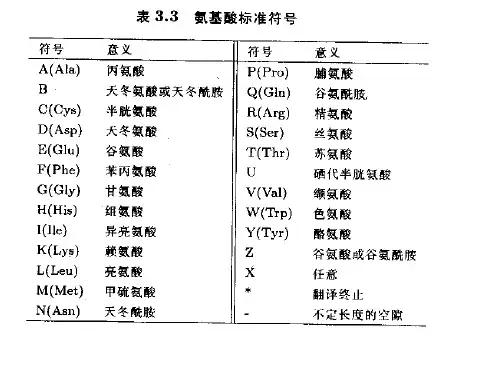
2、每个碱基三元组称为一个密码子(codon)3、碱基组成的三元组的排列共有43=64种,而氨基酸共有20种类型,所以不同的密码子可能表示同一种氨基酸。




匹配DNA序列信息学院08信工雷坚14083901150一、问题背景DNA分子是生物的遗传物质,DNA序列比对生物信息学中基本的信息处理方法,对于发现生物序列中的功能、结构和进化信息具有重要的意义。
通过比较生物分子序列,发现它们的相似性,找出序列之间共同的区域,同时辨别序列之间的差异。
在分子生物学中,DNA或蛋白质的相似性是多方面的,可能是核酸或氨基酸序列的相似,可能是结构的相似,也可能是功能的相似。
一个普遍的规律是序列决定结构,结构决定功能。
研究序列相似性的目的之一是,通过相似的序列得到相似的结构或相似的功能。
研究序列相似性的另一个目的是通过序列的相似性,判别序列之间的同源性,推测序列之间的进化关系。
二、问题定义基因中的DNA和RNA链是称为核苷酸的小单元组成的序列。
为了回答某些重要的研究问题,研究人员把基因串看作计算机科学的字符串—也就是说,可以忽略基因串的物理和化学性质,而将其想像成字符的序列。
DNA由腺嘌呤(A)、胞嘧啶(C)、胸腺嘧啶(T)和鸟嘌呤(G)组成的核苷酸双螺旋组成。
DNA的双螺旋彼此反向互补。
A和T是互补的碱基对,C和G也是互补的碱基对。
所以,可以将一条DNA链想像成由字母A、C、G和T组成的字符串。
在计算机学科上来说,我们可以把一个DNA序列看成是一个字符串。
说要解决的问题如下:两个字符串序列,要求返回指定长度子序列在两条序列中出现的位置元组,当然由于DNA分子序列数据很大,所以设计的算法应该足够快。
例:a='yabcabcabcz',b='xxabcxxxx',如果指定子序列长度为3,则应返回子字符串abc在两个序列的开始位置的元组:[(1,2),(4,2),(7,2)].三、问题分析问题要求返回的是指定长度(k)的子字符串在两个字符串中出现的开始位置,那么,这个子字符串必须同时属于两个字符串。
所以我们的大致思路可以是先将两个字符串的所以k长度的子字符串全部找出来,然后将两个字符串的子字符串相比较,如果相同,则返回该子字符串在两个字符串中的开始位置。

高中生物遗传计算公式
1. 孟德尔原理:P(纯合)代系与F1(杂合)代系之间,各自
按照1:2:1的比例随机分离基因型,以及随机结合基因的特性。
2. 随机结合基因:适用于两对不同基因且相互独立,同时表现出显性或隐性特征的杂合个体之间的交配,其后代表现不同基因类型时,各基因型之间按照1:1比例分离。
3. 基因连锁:不同染色体上的基因遗传是相互独立的,但同一条染色体上的基因遗传可能产生联锁作用,其发生概率与两个基因间距离的远近成反比。
4. 遗传连锁分析:借助于遗传连锁现象的产生来调查两对基因之间距离的远近,其中一个利用率=重组率×100%。
5. 确定基因给定染色体位置的方法(三点测交法):若以互相紧挨着的三个基因位点为考察物,这三个位点之间的基因序列分别有ABA、BCD,则任何一对基因会联锁发生重组的概率
为p,未联锁发生重组的概率为1-p,得到自乘值和交换值分别为(1-p)2AB、(1-p)2BC、(1-p)2CD、
2pABCD+2pA’B’C’D’,其中A、B、C、D为基因位点上的基因,A′、B′、C′、D′表示同一位点上随机安排的其他基因序列,可据此求出三对基因之间的距离。
基因序列分析的算法和方法基因序列是生命的基础,它是指DNA分子的排列,包含了生物的全部遗传信息。
基因序列分析是指对基因序列进行处理、比较、计算、解释等操作,以揭示与生物物种进化、分子结构与功能、疾病发生等生命科学问题有关的信息。
本文将重点讨论基因序列分析的算法和方法。
一、序列比对算法序列比对是指将两个或多个基因序列进行对比,找出它们之间的相似性和差异性。
序列比对的方法有全局比对和局部比对两种。
1. 全局比对全局比对是将两个序列的整个区间进行比对。
最常用的全局比对算法是Needleman-Wunsch算法,也被称为全局对齐算法。
该算法考虑所有可能的对齐情况,并计算每个对齐方案的得分,从中选择最高得分的方案作为最终结果。
2. 局部比对局部比对是在两个序列的特定区域内进行比对。
最常用的局部比对算法是Smith-Waterman算法,也被称为局部对齐算法。
该算法在全局比对算法的基础上,新增了局部序列区间的搜索。
该算法能够比全局比对算法更加有效地寻找序列的局部相似区域。
二、序列注释序列注释是指对基因序列进行功能和结构信息的标注。
序列注释的方法可以分为以下四种:1. 基于比对算法的注释通过将输入序列与已知数据库中的序列进行比对,可以识别序列中的个体单元,并据此推断其功能。
2. 基于模式匹配的注释基于模式匹配的注释可以通过搜索序列中特定的模式(如启动子、信号肽等)来确定序列的功能。
3. 基于内部特征的注释基于内部特征的注释使用计算机算法来识别序列中的功能元件,如受体结构域、膜蛋白、蛋白质结构元素等。
4. 序列功能预测序列功能预测是通过计算序列特征(如氨基酸组成、二级结构、跨膜结构等)来预测序列的功能。
三、基因家族分析基因家族是指一组具有相似的DNA序列结构和功能的基因。
基因家族分析是通过比对相似的基因序列,来揭示它们之间的进化关系和功能差异。
基因家族分析的方法有以下几种:1. 基于比对的方法这种方法是从多个物种或有相关DNA序列的同一物种的基因组中比对同一基因家族成员的序列,并对差异进行研究。
生物信息学中基因组序列分析的技术要点总结生物信息学是一门结合生物学和计算机科学的交叉学科,它的目的是研究和理解生物学中的各种信息,特别是基因组序列数据。
基因组序列分析是生物信息学中的重要内容,通过对基因组序列的分析和解读,可以揭示基因功能、生物进化和生物多样性等重要信息。
在本文中,我们将总结基因组序列分析的技术要点。
1. 基因组序列数据的质控与预处理基因组测序技术的发展使得大量的基因组序列数据可用于分析。
然而,这些数据通常存在质量差异和噪音,因此在分析之前需要进行质量控制和预处理。
常用的处理步骤包括去除残余的接头序列、低质量序列的剪切和去除低质量的碱基等。
2. 序列比对与配对基因组序列通常非常庞大,对其进行比对与配对可以帮助我们将其与已知的参考基因组对齐。
比对和配对的过程可以通过多种算法和工具来实现,如BLAST、Bowtie和BWA等。
此外,为了提高比对的准确性和速度,还可以使用索引和压缩技术。
3. 基因组注释基因组注释是对基因组序列中的特征进行识别和标注的过程。
特征可以包括基因、转录本、启动子、调节序列等。
基因组注释可以借助于基因组数据库和生物信息学工具来实现。
常用的基因组注释工具包括Ensembl、NCBI和UCSC等。
4. 基因功能预测与注释基因组序列分析可以帮助我们预测和注释基因的功能。
这可以通过比对已知的基因家族、蛋白质结构预测、亚细胞定位预测和基因表达分析等方法来实现。
此外,还可以利用基因组序列的演化信息来预测基因的功能。
5. 基因组结构变异分析基因组序列分析可以帮助我们发现和分析基因组结构变异。
结构变异包括插入、缺失、倒位、重复和复制数变异等。
这些变异对基因功能和表达可能具有重要影响,因此对其进行分析非常重要。
常用的结构变异分析工具包括cnvkit、breakdancer和Pindel等。
6. 基因组表达分析基因组序列分析可以帮助我们理解基因组的转录和表达。
通过对转录本和表达序列标签的分析,我们可以揭示基因表达的调控机制、代谢网络和信号传导通路等。
以RNA序列匹配为基础的计算机核酸结构预测算法核酸是构成生命体的基本分子之一,其中包括DNA和RNA。
在分子生物学和生物医学领域,对核酸结构的预测是非常重要的。
预测核酸结构和功能关系的方法有很多,其中一个重要的方法是通过RNA序列匹配实现的。
本文将介绍RNA序列匹配为基础的计算机核酸结构预测算法。
一、RNA序列匹配的基本原理RNA序列匹配算法的基本原理是在已知的RNA数据库中寻找与待预测RNA序列具有相似序列的RNA分子,然后将其结构信息作为待预测RNA分子的结构信息预测基础,即采用序列比对的方法。
这是目前最为常用的RNA结构预测方法之一。
在RNA序列匹配算法中,RNA序列的比对是至关重要的一步。
RNA分子的序列信息可通过不同途径获取,包括实验测序和计算机模拟等方法。
已知的RNA数据集中包括RNA结构/序列数据库和RNA序列数据库。
RNA结构/序列数据库包括所有已知的并且可行的RNA分子结构和准确的RNA分子序列,RNA序列数据库包括所有已知的但不一定具有已知结构的RNA序列。
比对两个RNA序列的方法主要有全局序列比对和局部序列比对两种。
全局序列比对方法主要是通过 Needleman – Wunsch算法实现,该方法将整个RNA序列与另一个RNA序列比对,得到全局比对的得分,较适用于两个RNA序列长度相近并且具有比较相似信息的情况。
局部序列比对方法主要是通过 Smith-Waterman算法实现,该方法将一个区域的RNA序列与另一个RNA序列比对,得到相似比对的得分,较适用于具有区域相似序列的情况。
二、RNA序列匹配算法的优缺点RNA序列匹配算法具有优缺点。
其优点在于预测RNA结构时具有可靠性和准确性。
通过RNA序列匹配方法所选取的RNA分子与待预测RNA分子具有相似的RNA序列信息和结构空间,并将选择分子的结构信息转化为待预测RNA分子的结构信息,因此在一定程度上提高了预测的准确性。
另外,RNA序列匹配算法比起其他预测RNA结构的算法,在预测RNA结构的速度上具有较大优势。