Bicomb共词可视化分析方法操作过程
- 格式:doc
- 大小:1.66 MB
- 文档页数:21

bibliometrix的使用指南摘要:一、bibliometrix 简介1.bibliometrix 的定义2.bibliometrix 的作用二、bibliometrix 的使用方法1.安装和运行bibliometrix2.准备数据3.运行分析三、bibliometrix 的主要功能1.数据导入与处理2.指标计算与分析3.结果可视化四、bibliometrix 的应用案例1.研究领域的识别2.研究热点分析3.研究合作网络构建五、bibliometrix 的优缺点1.优点a.开源免费b.功能强大c.易于使用2.缺点a.数据处理能力有限b.对计算机性能要求较高正文:bibliometrix 是一款用于科学计量学和科技管理研究的开源软件,它可以帮助用户分析科研文献的引用、关键词、作者等信息,从而揭示研究领域的知识结构、研究热点和发展趋势。
本使用指南将详细介绍bibliometrix 的安装、使用方法和主要功能。
一、bibliometrix 简介bibliometrix 是一个基于R 语言的科学计量学工具,主要用于对科研文献进行引文分析、共词分析、作者合作网络分析等。
它可以为用户提供研究领域的识别、研究热点分析、研究合作网络构建等功能,从而帮助用户更好地理解科研文献的内在联系和演化规律。
二、bibliometrix 的使用方法1.安装和运行bibliometrix首先,用户需要安装R 语言和R 包管理器(如installr 或packrat)。
然后,通过运行以下命令安装bibliometrix:```Rinstall.packages("bibliometrix")```安装完成后,载入bibliometrix 包:```Rlibrary(bibliometrix)```2.准备数据要使用bibliometrix,用户需要准备一份包含文献信息的CSV 文件,文件应包含以下字段:作者、出版物名称、出版年份、卷号、期号、起始页码、结束页码、DOI 等。


bibliometrix的使用指南【实用版】目录1.引言2.bibliometrix 的功能介绍3.使用 bibliometrix 的步骤4.常见问题与解答5.结论正文【引言】bibliometrix 是一款功能强大的文献计量学工具,适用于科研人员、学术编辑和图书馆工作人员等。
它可以帮助用户分析、可视化和比较各种学术文献的指标,为用户提供全面而深入的文献分析结果。
本文将为您介绍如何使用 bibliometrix,让您轻松掌握这一强大的工具。
【bibliometrix 的功能介绍】bibliometrix 主要提供以下功能:1.检索和导入文献:用户可以通过输入关键词、作者、期刊等信息检索文献,并支持从 Web of Science、CNKI 等数据库导入文献数据。
2.文献指标分析:bibliometrix 支持多种文献指标分析,如文章数量、引用次数、H 指数、i10 指数等。
3.文献可视化:用户可以利用 bibliometrix 生成各种可视化图表,如引文分布图、合作网络图、作者分布图等。
4.批量处理:bibliometrix 支持批量处理文献数据,提高分析效率。
【使用 bibliometrix 的步骤】1.安装和登录:首先,您需要访问 bibliometrix 官网下载并安装软件。
安装完成后,用您的账号登录。
2.创建项目:登录后,点击“新建项目”创建一个新的文献分析项目。
3.导入文献:在项目中,点击“导入文献”添加您需要分析的文献。
您可以通过检索或从已有数据库中导入文献。
4.分析文献:在项目中,选择需要分析的文献指标,如文章数量、引用次数等。
bibliometrix 会自动分析并生成结果。
5.可视化分析:在项目中,选择需要可视化的指标,如引文分布、合作网络等。
bibliometrix 会自动生成可视化图表。
6.导出结果:分析和可视化完成后,您可以将结果导出为 Excel、PPT 等格式,方便分享和展示。

如何进行生物大数据的可视化分析生物大数据的可视化分析是一种强大的工具,可以帮助科研人员和医疗专家更好地理解和解释复杂的生物数据。
通过可视化分析,人们可以从海量的数据中发现模式、趋势、关联和异常,进而提取有价值的信息。
本文将介绍如何进行生物大数据的可视化分析,以帮助读者充分利用这一工具。
首先,进行生物大数据的可视化分析之前,我们需要准备好数据。
生物大数据可以来自各种来源,例如生物芯片、次代测序和蛋白质组学等实验。
我们需要将这些数据整理和处理,以便进行后续的可视化分析。
数据处理的目标是提取和清洗有用的信息,并将其格式转化为适合可视化的数据结构。
一种常用的数据处理工具是Python编程语言中的pandas库。
pandas库提供了强大的数据处理功能,可以用于数据的读取、清洗、转换和整理。
使用pandas库,我们可以对生物大数据进行统计分析、筛选和排序等操作,从而得到我们所需的数据集。
在数据处理过程中,我们还可以利用其他常用的数据分析和机器学习工具,如NumPy和Scikit-learn等,来满足更高级的数据处理需求。
准备好数据后,我们就可以进行生物大数据的可视化分析了。
在可视化分析中,我们可以使用各种图表和图形来展示数据的特征和关系。
下面介绍几种常用的可视化方法:1. 散点图:散点图可以用于显示两个不同变量之间的关系。
通过在图表中绘制各个数据点,我们可以观察到数据的分布、密度和相关性。
散点图可以用来发现变量之间的线性或非线性关系,并进一步分析其统计学意义。
2. 折线图:折线图适用于观察随时间或其他变量变化的趋势。
通过在折线图中绘制各个时间点或其他变量的数据点,我们可以清晰地了解到数据的变化规律。
折线图常用于分析基因表达、蛋白质折叠和代谢路径等生物过程的动态变化。
3. 柱状图:柱状图是一种常见的图表,可以用于比较不同类别之间的数据。
通过在图表中绘制不同类别的柱形,我们可以直观地观察到它们之间的差异和关系。

bibliometrix的使用指南【原创实用版】目录1.引言2.bibliometrix 的功能和特点3.使用 bibliometrix 的步骤4.常见问题与解决方案5.结论正文【引言】bibliometrix 是一款用于科学计量学研究的工具,主要用于分析科研文献的引用情况,帮助研究人员了解某个领域的研究热点和发展趋势。
本文将为您介绍如何使用 bibliometrix。
【bibliometrix 的功能和特点】bibliometrix 具有以下主要功能和特点:1.强大的数据分析能力:可以处理大量的文献数据,提供多维度的分析结果。
2.灵活的筛选条件:可以根据作者、机构、关键词等条件筛选文献,满足不同研究需求。
3.可视化分析:提供多种图表展示分析结果,直观地呈现研究领域的现状。
4.引用网络分析:可以分析文献之间的引用关系,揭示研究领域的知识结构。
【使用 bibliometrix 的步骤】1.安装和登录:首先需要在官方网站下载并安装 bibliometrix,然后用邮箱注册一个账号并登录。
2.数据导入:在主界面选择“新建项目”,导入需要分析的文献数据,支持多种数据格式。
3.筛选条件设置:在“筛选条件”模块设置需要的筛选条件,如作者、机构、关键词等。
4.分析和可视化:在“分析”模块选择需要的分析指标,如引用频次、H 指数等;在“可视化”模块选择图表类型,如散点图、条形图等。
5.引用网络分析:在“网络分析”模块选择需要的分析指标,如网络密度、聚类系数等。
6.导出结果:将分析结果导出为 Excel、CSV 等格式,方便进行进一步的数据处理和分析。
【常见问题与解决方案】1.问题:导入的文献数据无法正常显示。
解决方案:检查数据格式是否正确,或尝试更新软件版本。
2.问题:分析结果与预期不符。
解决方案:检查筛选条件设置是否正确,或尝试更换分析指标。
3.问题:无法正常登录账户。
解决方案:检查账号和密码是否正确,或联系客服寻求帮助。


教育部2012年颁布的《幼儿园教师专业标准(试行)》明确指出,幼儿园教师应以“师德为先”。
幼儿园教师专业伦理是幼儿园教师专业发展的重要基石,影响着幼儿园教师的工作态度和专业行为。
〔1〕近年来,有关幼儿园教师专业伦理的研究受到许多研究者的关注。
那么,目前的研究现状如何?研究内容侧重在哪里?研究热点是什么?研究趋势如何?科学知识图谱(Mapping Knowledge Domains)是一种以科学理论学为指导,通过数据挖掘、信息处理、知识计量与图形绘制等现代科学技术来展现现代科学技术知识发展进程与结构关系的图形。
〔2〕它可从宏观、中观、微观等不同角度直观地揭示出某一研究领域的发展概貌、研究热点和重点等信息。
〔3〕本文采用科学知识图谱技术,绘制我国幼儿园教师专业伦理研究的热点知识图谱,并在此基础上进行相应的思考和展望。
一、研究方法1.资料来源2015年5月,在中国学术期刊网络出版总库,以“幼儿园教师”“幼儿教师”“幼儿教育”“专业伦理”“专业道德”“职业道德”为主题词进行检索,剔除无效文献(如无作者文献、重复性文献以及会议信息等),最终得到2000~2014年有效文献174篇。
所得数据使用BICOMB2.0(书目共现分析系统)以及SPSS18.0处理与分析。
2.研究步骤第一,利用BICOMB2.0软件对174篇文章进行关键词统计。
第二,根据研究需要,利用BI⁃COMB2.0软件抽出21个词频大于5的关键词为高频关键词。
第三,利用BICOMB2.0软件中的共现分析功能,建立高频关键词共现矩阵。
第四,通过Ochiai 系数将共现矩阵转化为相似矩阵(O chiai=),将结果导入SPSS18.0,进行系统聚类分析,得出高频关键词聚类树状图。
第五,利用“相异矩阵=1-相似矩阵”公式算出相异矩阵,将结果导入SPSS18.0,进行多维尺度分析,得出高频关键词多维尺度分析图。
第六,在多维尺度分析结果上,结No.10,2015General No.6702015年第10期(总第670期)幼儿教育(教育科学)Early Childhood Education(Educational Sciences)·研究综述·*本文为教育部人文社会科学研究项目“幼儿园教师专业伦理研究”(项目批准号:11YJA880001)和浙江省哲学社会科学重点项目“幼儿园教师专业伦理:缺失与生成”(项目批准号:11JCJY02Z )的研究成果之一。
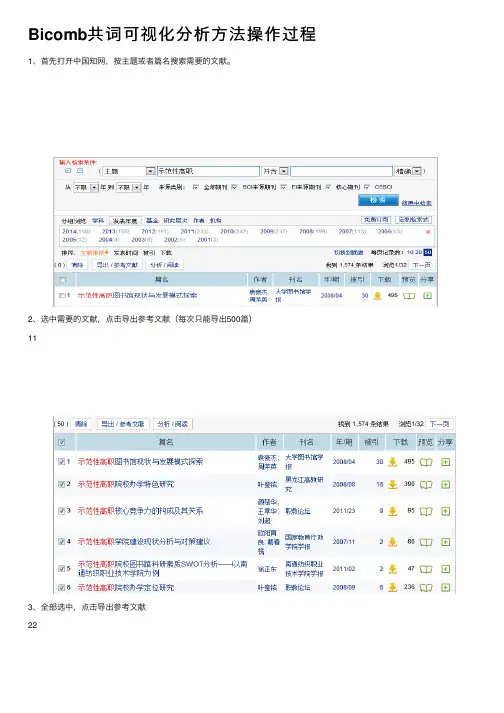
Bicomb共词可视化分析⽅法操作过程1、⾸先打开中国知⽹,按主题或者篇名搜索需要的⽂献。
2、选中需要的⽂献,点击导出参考⽂献(每次只能导出500篇)113、全部选中,点击导出参考⽂献224、点击⾃定义模式。
5、按需要选择相应的输出字段,如图所⽰,然后点击导出,保存在相应的⽂件夹中。
格式为.TXT446、打开导出的⽂本⽂件,如下图,将所有的英⽂去掉,具体做法为编辑—替换。
将英⽂替换为空格,即可去掉英⽂,成为如下版本。
接着根据研究需要进⾏关键词的合并,合并成功后,选择另存为,⽂件编码⼀定要改成ANSI 。
557、打开bicomb,点击增加,建⽴⼀个新的项⽬,编号⾃⼰随意输⼊⼀个数字,格式类型为cnki⾃定义。
668、点击最下⽅的提取,进⼊提取界⾯。
关键字段选择为关键词,点击选择⽂档,打开刚才导出的txt格式的⽂档,打开成功后,点击提取。
77889、点击最下⽅的统计,进⼊统计界⾯。
关键字段选择为关键词。
域值⼀般为6,根据实际情况可调整,然后点击红⾊的统计按钮。
关键词的排位顺序就会统计出来。
991010111110、点击最下⽅的矩阵按钮,进⼊矩阵界⾯。
关键字选择为关键词。
阈值⼀般⼤于之前选择的最低阈值,⽐如12,⼩于统计出来的最多的关键词出现的频次,上图可发现关键词最多出现202.然后点击⽣成按钮,可出现词篇矩阵。
共现矩阵操作⽅法同样。
最后点击导出矩阵TXT。
保存在相应⽂件夹。
121211、打开.点击⽂件—打开—数据,打开刚才导出的词篇矩阵。
13131414注:⼀直点击下⼀步,直到完成。
12、点击⼯具栏的分析—分类—系统聚类。
出现对话框后,将左边框内的V1选择为标注个案,其他剩下的变量全选,放在右边的变量框中。
13、点击统计量,出现对话框,选择相似性矩阵。
在选择单⼀⽅案,聚类数根据⾃⼰的研究情况选择,⼀般是4到6类,如选择5类。
然后点击继续。
151514、点击绘制按钮。
选择树状图。
然后点击聚类的指定全聚,停⽌聚类树为5,就是你所要聚的类树。



bibliometrix的使用指南(最新版)目录1.引言2.bibliometrix 的功能和特点3.使用 bibliometrix 的步骤4.常见问题与解决方法5.结论正文1.引言bibliometrix 是一款用于处理和分析文献数据的工具,适用于科研工作者、学术编辑和图书馆员等。
它能够帮助用户快速获取文献信息,进行数据分析和可视化,提高科研工作效率。
本文将为您介绍如何使用bibliometrix,让您轻松掌握这一实用工具。
2.bibliometrix 的功能和特点bibliometrix 具有以下主要功能和特点:(1)支持多种文献数据格式,如 Web of Science、Scopus、PubMed 等。
(2)提供丰富的数据分析功能,如合作网络分析、引文分析、关键词提取等。
(3)支持数据可视化,包括合作网络图、引文分布图、关键词云等。
(4)具有灵活的自定义选项,用户可以根据需求选择不同的分析模块和可视化效果。
3.使用 bibliometrix 的步骤使用 bibliometrix 的步骤如下:(1)安装和导入数据:首先,需要在官方网站下载并安装bibliometrix。
然后,通过导入功能将所需文献数据导入到软件中。
(2)选择分析模块:在数据处理界面,根据需求选择不同的分析模块,如合作网络分析、引文分析、关键词提取等。
(3)运行分析:点击“运行”按钮,软件将自动进行分析,并生成相应的结果。
(4)查看和导出结果:在结果界面,可以查看分析结果,如合作网络图、引文分布图、关键词云等。
同时,支持将结果导出为图片或数据表格等格式。
4.常见问题与解决方法在使用 bibliometrix 过程中,可能会遇到以下常见问题:(1)数据导入失败:请确保所使用的文献数据格式与软件支持的格式相匹配,并检查数据文件是否完整。
(2)分析结果不准确:请确保所选分析模块与需求相符,并检查导入的数据是否正确。
(3)结果导出失败:请确保导出格式与软件支持的格式相匹配,并检查导出文件名是否正确。
共词分析法研究共词分析的过程与方式一、本文概述共词分析法是一种广泛应用于信息科学、图书馆学、社会学、管理学等领域的文献计量学方法。
它通过统计和分析一组词汇在特定领域文献中共同出现的频次,揭示这些词汇之间的关联性和聚类性,从而反映该领域的热点主题、研究趋势和知识结构。
本文旨在深入探讨共词分析的过程与方式,包括数据准备、共词矩阵构建、聚类分析、结果解读等关键环节,以期为相关领域的研究者提供一套系统、实用的方法论参考。
在本文中,我们首先将对共词分析法的基本原理进行简要介绍,阐述其相较于其他文献计量学方法的独特优势。
随后,我们将详细介绍共词分析的具体步骤,包括如何从海量文献中筛选和提取关键词,如何构建共词矩阵并计算关键词之间的关联强度,以及如何运用聚类分析等统计方法对共词矩阵进行解读和可视化展示。
我们将通过实例分析,展示共词分析法在实际研究中的应用效果,并探讨其可能存在的局限性和改进方向。
通过本文的阐述,我们期望能够帮助读者更加深入地理解共词分析法的核心思想和操作步骤,掌握其在实际研究中的应用技巧,从而推动该方法在相关领域的研究中得到更广泛的应用和发展。
二、共词分析法的理论基础共词分析法是一种基于文献计量学的方法,它的理论基础主要源自信息科学、文献学和情报学等领域。
该方法通过统计和分析一组关键词或主题词在同一篇文献中共同出现的频次,来揭示这些关键词或主题词之间的关联程度,从而反映某一学科或领域的热点、结构和发展趋势。
共词分析法的理论基础主要包括词频分析理论、共现分析理论和聚类分析理论。
词频分析理论认为,关键词的出现频次能够反映其在某一学科或领域的重要性,频次越高,说明该关键词越受关注,其研究价值也越大。
共现分析理论则强调关键词之间的关联性,认为如果两个关键词在同一篇文献中频繁共现,那么它们之间就存在一定的关联或相似性。
聚类分析理论则是将共现频次较高的关键词进行聚类,形成不同的主题或研究领域,从而揭示学科或领域的结构和发展趋势。
应用BICOMB2处理EXCEL数据软件生成共现矩阵案例东北农业大学翟洪江最近做了一个关于文件计量的研究。
由于本人没有任何基础,所以做起来比较难。
在网上收集了很多资料,发现崔雷老师的BICOMB2软件很适合我的研究。
第一,这个软件针对于中文数据制作,我的数据主要来自于cnki;第二,我已经将所以论文的数据导入到EXCEL之中,这个软件对格式的自定义功能可以让我处理这些数据,不必在从cnki 上重新下数据。
由于本人没有学习过文献计量学的软件,所有用起来比较难,尽管有崔雷老师的指导,但是仍然做了很多次试验才操作成功。
为了让如我这样笨的菜鸟少走弯路,我写下这个案例,供大家参考。
本案例只适合于没有任何文献计量学基础的人使用。
我的文件结构如下图(案例中文献是我在cnki中主题,输入“文献计量学”,被引前150的文章)。
我要做的是作者的共现分析。
由于BICOMB不支持EXCEL格式(好像所有的文献计量学软件都不支持),我们要把它转化成TXT文件,但直接另存为txt文件可不可以呢?答案是否定的。
在转化之前我们要制作节点。
要制作两个节点:一个是文章节点,它要使软件能区分哪些作者是一个文章出现的;一个是字段节点,抽取作者字段从哪里开始。
单独将作者这一列加入到新的表中,在前面加一列,写上抽取字段节点字符,似乎写什么字符都可以,我是按照cnki里面给的代表作者的字符写的。
下一步制作文章节点。
稍微有些复杂。
在c列输入2、4、6、8……等差数列,在d 列输入1、3、5、7……等差数列,在E列输入文章节点字符,我输入的字符就是“文章节点”。
(c、d、e列输入比较简单,只输入前两行,然后点住单元格右下角“黑方点”双机即可。
但也不排除有人不会用EXCEL)将d列和e列整体选中,剪切,将d列数字与c列数字相接。
然后以c列为主要关键字进行排序。
排列完如下图。
C列和d列换一下。
在e列插入函数=CONCATENATE(A1,B1,C1,),这个函数是将所选单元格中的字符串合并,可以学习一下这个函数的相关说明。
数据可视化工具的使用方法与案例分析数据可视化是将数据以图表、图像、地图等可视化形式展示出来,帮助人们更好地理解和分析数据的过程。
在当今大数据时代,数据可视化已经成为了数据分析和决策的重要工具。
数据可视化工具的出现极大地简化了数据可视化的过程,并提供了丰富的功能和选项。
本文将介绍几种常用的数据可视化工具的使用方法,并通过案例分析说明它们在实际应用中的价值。
一、Tableau作为业界领先的数据可视化工具之一,Tableau凭借其强大的功能和友好的界面广受欢迎。
其使用方法如下:1. 数据导入:打开Tableau后,选择“连接到数据”选项,可以导入Excel、CSV、数据库等多种数据源。
选择合适的数据源并进行连接。
2. 数据操作:Tableau提供了丰富的数据操作功能,如筛选、排序、合并等。
通过拖拽字段到维度和度量区域,可以对数据进行细致的操作。
3. 可视化设计:选择合适的图表类型,如柱状图、折线图、饼图等,将字段拖拽到相应的区域,即可生成相应的图表。
可以调整颜色、标签、坐标轴等属性,自定义图表的外观。
4. 交互控制:Tableau允许用户通过交互式操作来控制数据可视化。
比如,可以通过滑块控制时间序列数据的显示,通过筛选器控制数据的子集展示等。
这样,用户可以根据需要进行灵活的数据探索和展示。
Tableau的应用案例非常广泛,以下为一个案例分析:某公司想要了解销售表现情况,需要对销售业绩和区域进行可视化分析。
他们使用Tableau导入销售数据,选择合适的图表类型,如柱状图和地图,将销售额字段拖拽到度量区域,将区域字段拖拽到维度区域。
通过调整颜色和标签等属性,他们可以清晰地看到不同区域的销售额情况。
他们还使用交互式筛选器,通过选择不同的时间范围和产品类别,可以动态地分析销售表现。
二、Power BI作为微软推出的一套商业智能工具,Power BI功能强大且易于使用。
以下是Power BI的使用方法:1. 数据连接:打开Power BI,在“获取数据”选项中选择合适的数据源,如Excel、CSV、数据库等。
一个简单的共词可视化方法及实现———以CNKI数据库文
献信息为例
宗乾进;杜楠楠;吕鑫;章以佥
【期刊名称】《情报杂志》
【年(卷),期】2012(000)011
【摘要】基于社会网络相关理论,提出一个针对中文数据库资源的文献信息可视化方法,以可视化图形的形式来展示学科研究脉络与主题演化。
取CNKI中的文献信息为样本数据,给出具体的处理步骤,利用Ruby和Graphviz等来加以实现,并对生成的图形进行了释读。
【总页数】5页(P136-140)
【作者】宗乾进;杜楠楠;吕鑫;章以佥
【作者单位】南京大学信息管理学院南京 210093;南京大学工程管理学院南京210093;南京大学工程管理学院南京 210093;南京大学工程管理学院南京210093
【正文语种】中文
【中图分类】G301
【相关文献】
1.利用单片机89C52的一个并行I/O口实现多个LED显示的一种简单方法 [J], 刘东红
2.文献题录信息挖掘技术方法及其软件SATI的实现——以中外图书情报学为例
[J], 刘启元;叶鹰
3.如何实现信用信息共享?--一个文献综述 [J], 李子健;耿得科
4.浅析一个表单多个Submit按钮的简单实现方法 [J], 聂常红
5.一个简单可行的实现光逻辑运算的方法 [J], 何永蓉;韩良恺
因版权原因,仅展示原文概要,查看原文内容请购买。
大数据分析中的数据可视化技术的使用教程数据可视化(Data Visualization)是数据分析中至关重要的一环,它利用图表、图形和其他视觉元素将复杂的数据变得易于理解和解释。
在大数据分析中,数据可视化技术的使用是不可或缺的,它能够帮助分析师快速发现数据中的模式、趋势和异常,从而为业务决策提供有力支持。
本文将介绍大数据分析中的数据可视化技术的使用教程,帮助读者快速上手。
首先,选择合适的可视化工具。
在大数据分析中,市场上有很多强大的可视化工具可供选择,如Tableau、Power BI、QlikView等。
在选择之前,我们需要根据自己的需求和要分析的数据类型来进行评估。
同时,了解和熟悉这些工具的功能和界面也是必要的,这样可以更快地上手和使用。
接下来,理解数据并确定可视化目标。
在分析大数据之前,我们首先需要理解数据的背景和含义。
只有对数据有较深的理解,才能更好地决定选择哪种可视化方式来展示数据。
同时,我们还需要确定可视化的目标,即希望通过可视化传达给观众的信息和要解决的问题。
例如,是要展示数据的分布情况,还是要比较不同数据的趋势变化。
然后,选择合适的图表类型。
在进行数据可视化时,选择合适的图表类型非常重要。
不同的数据类型和可视化目标可能需要不同的图表类型来展示。
常见的图表类型有柱状图、折线图、饼图、散点图等。
例如,如果要展示两个变量之间的关系,可以选择散点图;如果要比较不同项目的数据大小,可以选择柱状图。
选择合适的图表类型可以更好地展示数据,提供更清晰的信息。
接下来,调整视觉元素。
在设计数据可视化时,需要注意视觉元素的调整。
视觉元素包括颜色、大小、形状和位置等,在不同的场景中起到不同的作用。
例如,可以使用不同的颜色来区分不同的类别或值;可以改变柱状图的宽度或高度来表示不同的数据大小。
调整视觉元素可以使可视化更加直观和易于理解。
然后,保持简洁和清晰。
在设计数据可视化时,我们要保持简洁和清晰,避免过多的信息和装饰。
国外幼儿体育研究进展及其启示作者:刘献国贾俊杰来源:《体育学刊》2020年第04期摘要:基于共词分析的研究视角,借助于Bicomb、UCINET 6.0、SPASS 22.0软件,对1989—2019年收录在Web of Science数据库的1 289篇国外幼儿体育相关文献进行统计分析。
研究表明:身体活动、预防肥胖、加速度计、基础运动技能、家庭、干预等是国外幼儿体育的研究热点,阻碍幼儿发展与家庭干预、幼儿健康的生态支持、幼儿运动能力发展、健康促进与医疗融合是国外幼儿体育研究的4个主题,涉及社会学、心理学、教育学、医学等多个领域,研究方法多元,未来家庭的儿童保育、不同性别幼儿运动能力的干预将成为研究重点。
对于我国幼儿体育发展的启示:转变研究范式,由定量、定性研究到混合式研究;加强交叉学科知识的融合;赋值本土话语,增强创新意识。
关键词:幼儿体育;幼儿健康促进;研究进展;共词分析中图分类号:G807.1文献标志码:A 文章编号:1006-7116(2020)04-0127-07Progress in the researchon foreign infant sports and inspirations therefrom——Based on the perspective of co-word analysisLIU Xian-guo,JIA Jun-jie(School of Physical Education,Henan Normal University,Xinxiang 453007,China)Abstract:Based on the research perspectiveof co-word analysis, with the help of software such as Bicomb, UCINET 6.0 and SPASS 22.0,the authors carried out a statistical analysis on 1 289 foreign infant sports related articles collected in the database of Web of Science between 1989 and 2019. The authors revealed the following findings: physical activity, obesity prevention,accelerometer, basic movement skill, family and intervention were foreign infant sports research hot topics; hindering infant development and family intervention, ecological support for infant health, infant movement ability development, as well as health promotion and medical fusion,were 4 topics of foreign infant sports research, involving multiple fields such as sociology,psychology, educationandmedicine; research method diversification,future family’s child care,and the intervention of movement ability of infants of different genders, will become research focuses. Inspirations to Chinese infant sports development: change the research paradigm from quantitative or qualitative research to mixed research; strengthenthe fusion of interdisciplinary knowledge; value local discourse; enhance the innovation awareness.Key words:infant sports;infant health promotion;research progress;co-words analysis辦好幼儿教育、实现幼有所育,关系社会和谐稳定,关系党和国家事业未来。
1、首先打开中国知网,按主题或者篇名搜索需要的文献。
2、选中需要的文献,点击导出参考文献(每次只能导出500篇)
11
3、全部选中,点击导出参考文献
22
4、点击自定义模式。
33
5、按需要选择相应的输出字段,如图所示,然后点击导出,保存在相应的文件夹中。
格式为.TXT
44
6、打开导出的文本文件,如下图,将所有的英文去掉,具体做法为编辑—替换。
将英文替换为空格,即可去掉英文,成为如下版本。
接着根据研究需要进行关键词的合并,合并成功后,选择另存为,文件编码一定要改成ANSI。
55
7、打开bicomb,点击增加,建立一个新的项目,编号自己随意输入一个数字,格式类型为cnki自定义。
66
8、点击最下方的提取,进入提取界面。
关键字段选择为关键词,点击选择文档,打开刚才导出的txt格式的文档,打开成功后,点击提取。
77
88
9、点击最下方的统计,进入统计界面。
关键字段选择为关键词。
域值一般为6,根据实际情况可调整,然后点击红色的统计按钮。
关键词的排位顺序就会统计出来。
99
1010
1111
10、点击最下方的矩阵按钮,进入矩阵界面。
关键字选择为关键词。
阈值一般大于之前选择的最低阈值,比如12,小于统计出来的最多的关键词出现的频次,上图可发现关键词最多出现202.然后点击生成按钮,可出现词篇矩阵。
共现矩阵操作方法同样。
最后点击导出矩阵TXT。
保存在相应文件夹。
1212
11、打开.点击文件—打开—数据,打开刚才导出的词篇矩阵。
1313
1414
注:一直点击下一步,直到完成。
12、点击工具栏的分析—分类—系统聚类。
出现对话框后,将左边框内的V1选择为标注个案,其他剩下的变量全选,放在右边的变量框中。
13、点击统计量,出现对话框,选择相似性矩阵。
在选择单一方案,聚类数根据自己的研究情况选择,一般是4到6类,如选择5类。
然后点击继续。
1515
14、点击绘制按钮。
选择树状图。
然后点击聚类的指定全聚,停止聚类树为5,就是你所要聚的类树。
如聚6类,那么停止聚类就输入6。
然后点击继续。
1616
1717
15、然后点击方法按钮,区间选择为Euclidean。
二分类选择为Ochiai,然后点击继续。
1818
1919
16、最后回到主对话框。
点击确定,即可在输出对话框中产生结果。
战略图的制作过程。
【视频】
1、同样的打开,打开导出的TXT文件。
选择分析—分类类—系统聚类。
2、在打开的对话框中,点击工具栏的分析—分类—系统聚类。
出现对话框后,将左边框内的V1选择为标注个案,其他剩下的变量全选,放在右边的变量框中。
3、点击统计量。
选择相似性矩阵,点击继续。
然后点击方法按钮,区间选择为Euclidean。
二分类选择为Ochiai,然后点击继续。
回到主对话框,点击确定,生成相似性矩阵。
2020
4、右击生成的相似性矩阵,选择导出,将其导出到任意文件夹中,格式保存为.excel
5、打开保存的相似性矩阵,将其转换为相异矩阵,方法不在此多说。
然后保存,关闭。
(一定要在保存完毕后关闭excel)
6、在spss里打开刚才保存的相异矩阵,打开后点击分析—度量—多维尺度(ALSCL(M)),在出现的对话框中,将除了V1之外的变量全部选择到右边的变量对话框中。
7、点击选项按钮,选择组图,点击继续。
8、在对话框中距离选项中,首先选择“数据为距离数据”,点击确定,即可生成战略图,如果无法生成战略图,则按照以上步骤再操作一遍,但是最后一步距离选项中,要选择“从数据创建距离”。
注:一般选择选择“数据为距离数据”,实在不行再选择“从数据创建距离”
2121。