HDF命令行工具
- 格式:doc
- 大小:64.00 KB
- 文档页数:11

hdfview 用法-回复HDFView是用于浏览和编辑HDF(Hierarchical Data Format,分层数据格式)文件的工具。
HDF是一种用于存储大型科学和工程数据的文件格式,它可以存储多种类型的数据和元数据,并以层次结构的方式组织数据。
在本文中,我们将一步一步地介绍如何使用HDFView浏览和编辑HDF 文件。
第一步:安装HDFView首先,我们需要前往HDFView官方网站(第二步:打开HDF文件一旦启动HDFView,我们可以在主界面上看到菜单栏和工具栏。
要打开一个HDF文件,我们可以通过菜单栏中的“File”选项,然后选择“Open File”来打开一个HDF文件。
在文件对话框中,浏览到文件所在的位置,并选择要打开的HDF文件。
点击“打开”按钮后,HDF文件将在HDFView 的主界面中加载并显示。
第三步:浏览数据集在打开的HDF文件中,我们可以看到文件的层次结构。
层次结构以树状形式显示在左侧的“对象视图”窗口中。
我们可以展开不同的节点以查看数据集、组、数据类型等。
当我们选择一个数据集时,该数据集的内容将显示在右侧的“数据集视图”窗口中。
第四步:查看和编辑数据在数据集视图窗口中,我们可以查看数据集的数据内容。
根据数据集的类型,我们可以选择以表格、图表或其他适当的方式显示数据。
同时,我们还可以对数据集进行编辑,包括添加、删除、修改数据。
要编辑数据,我们可以选择一个特定的数据项,然后使用工具栏上的相关按钮执行相应的操作。
第五步:导出数据如果我们想将数据导出到其他格式,如CSV或Excel,HDFView也提供了这样的功能。
通过使用菜单栏中的“File”选项,然后选择“Export”子选项,我们可以选择将数据导出为所需的格式。
在导出对话框中,指定目标文件的名称和保存位置,然后点击“导出”按钮即可完成导出过程。
第六步:保存修改当我们对HDF文件进行修改后,通常需要将修改保存回原始文件中。

HDF操作流程范文一、引言HDF(Hierarchical Data Format)是一种用于存储和组织科学数据的文件格式,广泛应用于各个领域,如气象学、生物学、地球物理学等。
在进行HDF操作之前,需要先安装一些必要的软件和库,如HDF库、Python的h5py库等。
本文将介绍一种基本的HDF操作流程,以帮助读者更好地理解和应用HDF文件。
二、HDF文件的读取1.导入必要的库首先,需要导入h5py库,用于读取和操作HDF文件。
```pythonimport h5py```2.打开HDF文件使用h5py库的`File`函数打开HDF文件,并将其赋值给一个变量。
```pythonfile = h5py.File('example.hdf', 'r')```其中,`example.hdf`是你要读取的HDF文件的路径和文件名。
3.查看HDF文件的结构可以使用`keys(`方法查看HDF文件的结构和层次。
```pythonprint("HDF文件的结构:")print(file.keys()```4.读取HDF文件中的数据根据文件的结构,选择对应的数据集进行读取。
使用`get(`方法读取数据集,并将其赋值给一个变量。
```pythondata_set = file['data1']```其中,`data1`为你要读取的数据集的名称。
5.查看数据使用`shape`属性获取数据的维度和大小,并使用`value`属性获取具体的数据。
```pythonprint("数据的维度和大小:", data_set.shape)print("数据的具体值:", data_set.value)```6.关闭HDF文件读取完数据后,及时关闭HDF文件。
```pythonfile.close```三、HDF文件的写入1.导入必要的库同样地,需要导入h5py库。

hdparm是一个用于检测和设置IDE硬盘参数的命令行工具。
以下是hdparm的一些常见用法:
显示硬盘信息:运行"hdparm -i /dev/sdX"命令,其中"sdX"是硬盘的设备名称,例如/dev/sda。
这将显示硬盘的详细信息,包括型号、序列号、容量等。
检测硬盘电源管理模式:运行"hdparm -C /dev/sdX"命令,这将检测硬盘的电源管理模式。
如果硬盘支持省电模式,该命令将显示相关信息。
设置硬盘多重分区存取的分区数:运行"hdparm -m /dev/sdX"命令,这将设置硬盘多重分区存取的分区数。
评估硬盘的读取效率:运行"hdparm -t /dev/sdX"命令,这将评估硬盘的读取效率。
该命令将显示读取特定数据块时的性能指标。
关闭磁盘写入缓存:运行"hdparm -W0 /dev/sdX"命令,这将关闭磁盘的写入缓存。
这可以提高写入性能,但可能会降低数据安全性。
显示硬盘的相关设定:运行"hdparm -v /dev/sdX"命令,这将显示硬盘的相关设定,包括PIO 模式、DMA模式等。
请注意,使用hdparm需要具有适当的权限。
在大多数情况下,您需要以root用户身份运行该命令。
此外,不同版本的hdparm可能具有不同的选项和功能,因此请查阅特定版本的文档以获取详细信息。

矿产资源开发利用方案编写内容要求及审查大纲
矿产资源开发利用方案编写内容要求及《矿产资源开发利用方案》审查大纲一、概述
㈠矿区位置、隶属关系和企业性质。
如为改扩建矿山, 应说明矿山现状、
特点及存在的主要问题。
㈡编制依据
(1简述项目前期工作进展情况及与有关方面对项目的意向性协议情况。
(2 列出开发利用方案编制所依据的主要基础性资料的名称。
如经储量管理部门认定的矿区地质勘探报告、选矿试验报告、加工利用试验报告、工程地质初评资料、矿区水文资料和供水资料等。
对改、扩建矿山应有生产实际资料, 如矿山总平面现状图、矿床开拓系统图、采场现状图和主要采选设备清单等。
二、矿产品需求现状和预测
㈠该矿产在国内需求情况和市场供应情况
1、矿产品现状及加工利用趋向。
2、国内近、远期的需求量及主要销向预测。
㈡产品价格分析
1、国内矿产品价格现状。
2、矿产品价格稳定性及变化趋势。
三、矿产资源概况
㈠矿区总体概况
1、矿区总体规划情况。
2、矿区矿产资源概况。
3、该设计与矿区总体开发的关系。
㈡该设计项目的资源概况
1、矿床地质及构造特征。
2、矿床开采技术条件及水文地质条件。

hadoop的distcp命令
distcp是Hadoop的一个工具,用于在Hadoop集群之间复制数据。
它的命令格式如下:
hadoop distcp [options] <源路径> <目标路径>
其中,[options]是可选项,用于指定一些额外的配置参数。
常用的选项包括:
- -i:忽略校验和,即不使用CRC校验
- -p:保持文件属性,包括权限、修改时间等信息
- -update:只复制源路径中修改时间较新的文件
- -delete:删除目标路径中存在但源路径中不存在的文件
- -overwrite:覆盖目标路径中已存在的文件
- -bandwidth <带宽限制>:限制网络带宽
示例:
1. 将本地目录/tmp/data1拷贝到Hadoop集群的
/user/hadoop/data1目录下:
hadoop distcp /tmp/data1
hdfs://namenode:8020/user/hadoop/data1
2. 保持文件属性,并限制带宽为100MB/s:
hadoop distcp -p -bandwidth 100 /tmp/data1
hdfs://namenode:8020/user/hadoop/data1。
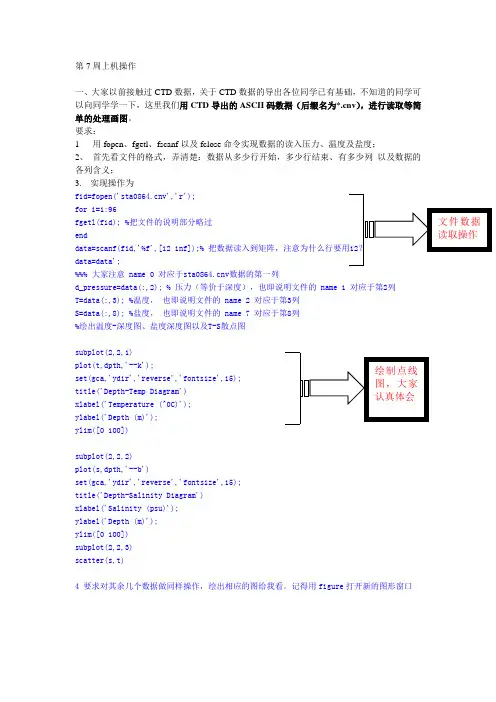
第7周上机操作一、大家以前接触过CTD 数据,关于CTD 数据的导出各位同学已有基础,不知道的同学可以向同学学一下,这里我们用CTD 导出的ASCII 码数据(后缀名为*.cnv ),进行读取等简单的处理画图。
要求:1 用fopen 、fgetl 、fscanf 以及fclose 命令实现数据的读入压力、温度及盐度;2、 首先看文件的格式,弄清楚:数据从多少行开始,多少行结束、有多少列 以及数据的各列含义;3. 实现操作为fid=fopen('v','r');for i=1:96fgetl(fid); %把文件的说明部分略过enddata=scanf(fid,'%f',[12 inf]);%data=data';%%% 大家注意 name 0 对应于v 数据的第一列d_pressure=data(:,2); % 压力(等价于深度),也即说明文件的 name 1 对应于第2列 T=data(:,3); %温度, 也即说明文件的 name 2 对应于第3列S=data(:,8); %盐度, 也即说明文件的 name 7 对应于第8列%绘出温度-深度图、盐度深度图以及T-S 散点图subplot(2,2,1)plot(t,dpth,'--k');set(gca,'ydir','reverse','fontsize',15);title('Depth-Temp Diagram')xlabel('Temperature (^0C)');ylabel('Depth (m)');ylim([0 100])subplot(2,2,2)plot(s,dpth,'--b')set(gca,'ydir','reverse','fontsize',15);title('Depth-Salinity Diagram')xlabel('Salinity (psu)');ylabel('Depth (m)');ylim([0 100])subplot(2,2,3)scatter(s,t)4 要求对其余几个数据做同样操作,绘出相应的图给我看。

HDF数据使用指南HDF(Hierarchical Data Format)是一种用于存储和管理大规模科学和工程数据的格式。
它具有高效、灵活和可扩展的特点,可以存储多种类型的数据和元数据,并以树状结构组织数据,使得数据的访问和读取更加方便和快速。
本文将介绍HDF数据的基本概念、使用方法和应用场景。
一、HDF数据的基本概念和结构1. 数据集(Dataset):HDF数据由一个或多个数据集组成,每个数据集包含一组相关的数据和相应的元数据。
数据集可以是一维数组、多维数组或表格形式的数据。
2. 元数据(Metadata):元数据是描述数据集的数据,包括数据集的名称、维度、类型、单位等信息。
元数据可以帮助用户理解和使用数据集。
3. 文件(File):HDF数据存储在一个以.h5或.hdf为后缀的文件中,可以包含多个数据集和其他附加信息。
4. 组(Group):组是一种将数据集组织成树状结构的方式。
一个HDF文件可以包含多个组,每个组可以包含数据集和其他组,使得数据集的组织更加灵活和清晰。
二、HDF数据的创建和读取1. 创建HDF数据:可以使用HDF库提供的API或各种科学计算软件(如MATLAB、Python等)来创建HDF数据。
首先需要创建一个HDF文件,然后定义数据集的名称、维度和类型,并将数据写入数据集中。
2.读取HDF数据:可以使用HDF库提供的API或科学计算软件来读取HDF数据。
首先需要打开HDF文件,然后选择要读取的数据集,读取数据集的名称、维度、类型和数据值。
三、HDF数据的应用场景1.大规模科学计算:HDF数据可以存储大规模科学计算产生的数据,如气象数据、地震数据、天文数据等。
由于HDF数据的高效和可扩展性,可以快速存储和读取大量数据,支持复杂的数据分析和可视化。
2.跨平台数据交换:HDF数据可以在不同的平台和操作系统之间进行交换和共享,保证数据的兼容性和一致性。
不同用户可以使用不同的科学计算软件来读写HDF数据,减少了数据转换和处理的复杂性。

第26卷 第6期气象科学Vol.26,No.6 2006年12月SCIEN TIA M ET EOROL O GICA SIN ICA Dec.,2006 Matlab对基于HD F格式的MOD IS1B数据的提取方法与实现陈 林1,3 牛生杰1 仲凌志2(1南京信息工程大学中美合作遥感中心,南京210044)(2南京信息工程大学电子工程系,南京210044)(3中国科学院大气物理研究所,北京100029)摘 要 基于HDF文件格式的MODIS数据的应用越来越广泛,MODIS数据开发应用的前提是对MODIS1B数据的提取。
本文详细介绍了利用Matlab对HDF文件进行读写操作的过程,在此基础上给出了提取MODIS1B数据的流程图,实现了对MODIS1B数据的提取,为MODIS二级产品的开发打下了基础。
关键词 Matlab HDF文件 MODIS 数据提取 分类号 P456.8 文献标识码 A 引 言中分辨率成像光谱仪MODIS是对地观测系统EOS计划中最主要的仪器之一,也是唯一直接广播的对地观测仪器。
经过定标的MODIS1B数据采用HDF(Hierarchical data format)数据格式存储数据,提供了多达36个光谱通道的全球综合信息,可以同时反映陆地表面状况、云边界、云特性、海洋水色、浮游植物、生物地理、化学、大气中水汽、气溶胶、地表温度、云顶温度、大气温度、臭氧和云顶高度等特征的信息[1、2]。
MODIS数据开发应用的前提是要实现对MODIS1B数据的提取。
目前,MODIS的网站上提供了HDF数据格式的说明,以及用于C和Fortran的HDF库函数,通过配置库函数,可以对MODIS1B数据进行操作。
国内一些专家也基于此说明,研究了HDF库函数,实现了在C或者Fort ran下对MODIS1B数据的提取[3]。
但是库函数配置的繁琐、C和Fortran的复杂性,给提取MODIS1B数据带来了不小的困难。

编译HDF5 库通常涉及以下步骤。
以下是一个通用的指南,可能需要根据你的具体操作系统(如Linux、Windows 或macOS)和需求进行调整:在Linux 系统上编译HDF5:1. 安装依赖:首先确保你的系统中已经安装了必要的编译工具和依赖库,如gcc, make, cmake, zlib 等。
2. 下载HDF5 源代码:从HDF Group 官方网站下载最新的HDF5 源代码包。
3. 解压缩源代码:使用tar 命令解压缩下载的源代码包:4. 创建构建目录并进入:创建一个用于编译的目录:进入该目录:5. 配置编译选项:使用cmake 命令配置编译选项。
以下是一些基本选项的例子:根据你的需求,你可能需要调整这些选项。
6. 编译HDF5:使用make 命令开始编译:make7. 安装HDF5:如果编译成功,使用make install 命令进行安装:sudo make install在Windows 系统上编译HDF5:1. 安装依赖:安装Microsoft Visual Studio 和CMake。
下载并安装必要的依赖库,如zlib。
2. 下载HDF5 源代码:从HDF Group 官方网站下载最新的HDF5 源代码包。
3. 解压缩源代码:使用合适的解压缩工具解压下载的源代码包。
4. 配置编译选项:打开CMake GUI,设置源代码路径和构建路径。
配置编译选项,例如选择生成的Visual Studio 版本、是否启用共享库、是否构建工具等。
5. 生成项目文件:点击"Configure",然后"Generate"。
6. 编译HDF5:打开生成的Visual Studio 解决方案文件,选择合适的配置(如Release 或Debug)。
在解决方案explorer 中右键点击"ALL_BUILD",然后选择"Build"。

hadoop常⽤命令详细解释hadoop命令分为2级,在linux命令⾏中输⼊hadoop,会提⽰输⼊规则Usage: hadoop [--config confdir] COMMANDwhere COMMAND is one of:namenode -format format the DFS filesystem#这个命令⽤于格式化DFS系统:hadoop namenode -formatesecondarynamenode run the DFS secondary namenode#运⾏第⼆个namenodenamenode run the DFS namenode#运⾏DFS的namenodedatanode run a DFS datanode#运⾏DFS的datanodedfsadmin run a DFS admin client#运⾏⼀个DFS的admin客户端mradmin run a Map-Reduce admin client#运⾏⼀个map-reduce⽂件系统的检查⼯具fsck run a DFS filesystem checking utility#运⾏⼀个DFS⽂件系统的检查⼯具fs run a generic filesystem user client#这个是daoop⽂件的系统的⼀级命令,这个⾮常常见稍后详细讲解这个命令:例如hadoop fs -ls /balancer run a cluster balancing utility#作⽤于让各个datanode之间的数据平衡,例如:sh $HADOOP_HOME/bin/start-balancer.sh –t 15%oiv apply the offline fsimage viewer to an fsimage#将fsimage⽂件的内容转储到指定⽂件中以便于阅读,oiv⽀持三种输出处理器,分别为Ls、XML和FileDistribution,通过选项-p指定 fetchdt fetch a delegation token from the NameNode#运⾏⼀个代理的namenodejobtracker run the MapReduce job Tracker node#运⾏⼀个MapReduce的taskTracker节点pipes run a Pipes job#运⾏⼀个pipes作业tasktracker run a MapReduce task Tracker node#运⾏⼀个MapReduce的taskTracker节点historyserver run job history servers as a standalone daemon#运⾏历史服务作为⼀个单独的线程job manipulate MapReduce jobs#处理mapReduce作业,这个命令可以查看提交的mapreduce状态,杀掉不需要的jobqueue get information regarding JobQueues#队列管理,在后续版本中这个命名取消了version print the version#打印haoop版本jar <jar> run a jar file#运⾏⼀个jar包,⽐如mapreduce可以通过hadoop-streaming-1.2.1.jar进⾏开发distcp <srcurl> <desturl> copy file or directories recursively#distcp⼀般⽤于在两个HDFS集群中传输数据。

hdf数据格式解析
HDF(Hierarchical Data Format)是一种灵活、高效的数据组织格式,被广泛应用于科学计算领域。
以下是HDF数据格式的解析:
1. 层次结构:HDF采用层次结构的方式存储数据,整个数据集被划分为多
个层次,每个层次可以包含多个数据集和数据对象。
这种层次结构的设计使得数据的访问和管理更加方便。
用户可以根据需要创建任意数量和层次的数据集,并在其中存储相关的数据。
2. 大规模数据支持:HDF格式的一个重要特点是对大规模数据的支持。
它
能够高效地处理海量数据,使得数据的存储和读取速度大大提高。
同时,HDF格式还支持数据的压缩和分块存储,进一步节省了存储空间和提高了
数据处理效率。
3. 跨平台兼容性:HDF格式具有很好的跨平台兼容性。
无论是在Windows、Linux还是其他操作系统上,HDF都能够稳定运行,并且保证数据的完整性和一致性。
这使得HDF格式成为数据共享和协作的理想选择,不同科研机
构和个人可以轻松地共享和交换数据。
4. 数据组织和管理工具:HDF格式还提供了丰富的数据组织和管理工具。
用户可以使用HDF的API和库来对数据进行操作和处理,例如读取、写入、追加、删除等操作。
同时,HDF还支持多种数据类型的存储和索引,如整数、浮点数、字符串等,满足不同类型数据的需求。
总的来说,HDF格式作为一种灵活、高效和可靠的数据组织格式,广泛应用于科学计算和数据分析领域。
它的层次结构、大规模数据支持、跨平台兼容性和丰富的数据管理工具,使得科研工作者能够更轻松地进行数据存储、共享和处理,进一步推动了科学研究的进展。
Mac命令行中的磁盘管理使用diskutil和df命令在Mac系统中,命令行是一种强大的工具,可用于管理和维护磁盘。
本文将介绍如何使用diskutil和df命令来管理Mac命令行中的磁盘。
一、diskutil命令diskutil命令是Mac系统中的磁盘管理工具,可以用于创建、删除、格式化磁盘、分区、挂载和卸载磁盘等操作。
1. 查看磁盘信息要查看磁盘信息,可以使用以下命令:```diskutil list```该命令将显示系统中所有磁盘的详细信息,包括磁盘标识符、类型、名称、大小等。
通过查看磁盘信息,您可以确定要管理的磁盘的标识符。
2. 格式化磁盘要格式化磁盘,可以使用以下命令:```diskutil eraseDisk 文件系统磁盘名磁盘标识符```例如,要将磁盘格式化为Mac OS扩展(日志式)文件系统,可以使用以下命令:```diskutil eraseDisk JHFS+ MyDisk disk2```其中,JHFS+是文件系统类型,MyDisk是磁盘名,disk2是磁盘的标识符。
请根据实际情况替换这些值。
3. 创建分区要创建分区,可以使用以下命令:```diskutil partitionDisk 磁盘标识符分区个数分区格式分区名称分区大小```例如,要将磁盘划分为两个分区,一个使用Mac OS扩展(日志式)文件系统,一个使用exFAT文件系统,可以使用以下命令:```diskutil partitionDisk disk2 2 JHFS+ Partition1 50% ExFAT Partition2 50%```其中,disk2是磁盘的标识符,2是分区个数,JHFS+和ExFAT分别是分区的格式,Partition1和Partition2分别是分区的名称,50%表示每个分区的大小为磁盘总大小的50%。
请根据实际情况替换这些值。
4. 挂载和卸载磁盘要挂载磁盘,可以使用以下命令:```diskutil mount 磁盘标识符```要卸载磁盘,可以使用以下命令:```diskutil unmount 磁盘标识符```其中,磁盘标识符是要挂载或卸载的磁盘的标识符。
HDF+数据格式及IDL语言HDF分层数据格式和IDL交互式数据语言*摘要:HDF是一种新型的、有别于传统数据文件格式的分层数据格式,它的数据结构更为复杂,因此可包含更为全面的数据及其数据各项属性的信息。
除利用一般的程序读取语言外,IDL交互式数据语言在读取HDF文件方面具有独到之处。
本文介绍了HDF数据格式,比较了HDF与传统数据格式之间的区别,并举例说明如何用IDL语言程序说明读取HDF文件。
关键词:HDF,IDL,数据格式,程序语言1引言美国国家航空和宇宙航行局NASA(National Aeronautics and Space Administration)地球观测系统EOS(Earth Observation System)中大部分卫星资料均采用分层式数据格式HDF (Hierarchical Data Format)[1],例如搭载在Terra和Aqua卫星上的中分辨率成像光谱仪MODIS(MODerate Resolution Imaging Spectroradiometer)[2],搭载在Aqua卫星上的大气红外探测仪AIRS(Atmospheric InfraRed Sounder),大气臭氧总量测绘光谱仪TOMS(Total Ozone Mapping Spectrometer)、热带降雨测量卫星TRMM(Tropical Rainfall Measuring Mission)等卫星资料产品。
有别于以往常规资料所用到的二进制文件、ASCII文件,HDF 是一种新型的分层式数据文件,这种文件中既可以包含不同维数的二维、多维数组,又可以包含图像等。
目前最为流行的读取HDF文件的语言是交互式数据语言IDL (Interactive Data Language)或创建复杂算法(如矩阵运算和线性代数)的MATLAB的语言。
Fortran、C等传统语言工具也可以读取HDF文件,但程序代码较为复杂。
hdf原理什么是hdf?HDF(Hierarchical Data Format)是一种用于存储和管理大型科学数据集的文件格式。
它可以用于组织和表示多维数组、数据表和元数据等各种类型的数据。
HDF具有高性能、高效的数据压缩和存储能力,支持并行I/O操作,适用于各种科学领域的数据处理和分析。
HDF的层次结构HDF文件有一个层次结构,类似于计算机的文件系统。
它由三个主要组件组成:1.文件:HDF数据存储在一个文件中,该文件可以包含多个数据集和数据对象。
2.数据集:数据集是HDF中存储实际数据的部分。
数据集可以是多维数组,也可以是表格形式的数据。
3.数据对象:数据对象是HDF中的基本组成单元,可以是数据集、组、数据类型等。
HDF的数据模型HDF采用了一种通用的数据模型,可以表示任意类型和形状的数据。
它的数据模型包括以下几个重要的概念:1.数据类型:HDF支持多种数据类型,如整数、浮点数、字符、日期等。
每个数据集都有一个特定的数据类型。
2.数据空间:数据空间定义了数据集的维度和形状。
数据空间可以是任意维度的,可以是简单的一维数组,也可以是多维数组。
3.数据筛选器:数据筛选器用于对数据进行压缩、解压缩、加密等操作。
HDF支持多种数据筛选器,可以根据需求选择适合的筛选器进行数据处理。
HDF的数据存储方式HDF采用了一种灵活的存储方式,可以根据应用需求进行优化。
它可以将数据集存储为连续的块,也可以存储为分散的块。
此外,HDF还支持数据分块和数据分片,以提高数据读取和写入的效率。
HDF的数据访问HDF提供了一套灵活的API接口,可以进行数据读取、写入和管理。
它支持多种编程语言,如C、C++、Python等。
通过API接口,用户可以对数据进行高级操作,如数据切片、数据过滤、数据统计等。
HDF的应用领域HDF广泛应用于科学领域的数据处理和分析。
它被用于存储和管理气象数据、遥感数据、地理信息数据、生物医学数据等各种类型的科学数据。
hdfview 用法-回复HDFView是一个用于浏览和编辑HDF(Hierarchical Data Format)文件的工具。
HDF是一种用于存储和组织科学数据的格式,广泛应用于大规模数据集、仿真模型等领域。
HDFView 提供了一个用户友好的界面,使得用户可以方便地浏览、查询和修改HDF文件的内容。
本文将逐步介绍HDFView的用法,帮助您更好地了解和使用这个强大的工具。
首先,我们需要下载和安装HDFView。
可以通过访问HDFView的官方网站(一旦打开HDFView,我们将看到一个主界面,其中包含浏览和编辑HDF 文件的各种选项。
接下来,我们将深入了解如何使用这些选项。
第一步是打开HDF文件。
点击顶部工具栏上的“文件”选项,然后选择“打开”,浏览您存储HDF文件的文件夹,并选择要打开的文件。
一旦选择文件,点击“打开”按钮,HDF文件将加载到HDFView的主界面中。
现在,我们可以浏览HDF文件的内容。
在左侧的“对象浏览器”中,我们可以看到HDF文件的层次结构。
每个层级都是一个文件夹,其中包含了组(group)和数据集(dataset)等子对象。
点击这些对象,可以在右侧的“属性浏览器”中查看对象的详细信息。
如果我们想查看组或数据集的具体内容,可以右键点击对象,并选择“显示数据”。
在弹出的对话框中,我们可以选择数据显示的方式(例如以文本形式、以图像形式等),然后点击“显示”按钮。
HDFView将显示所选对象的实际数据,并以选择的方式进行展示。
除了浏览HDF文件的内容,HDFView还提供了编辑和修改HDF文件的功能。
例如,我们可以创建新的组或数据集,修改已存在的对象的属性,以及写入新的数据。
这些功能可以通过顶部工具栏上的相应选项来完成。
点击“编辑”选项,然后选择“添加组”或“添加数据集”来创建新的对象;点击“修改属性”选项来修改对象的属性;点击“写入数据”选项,然后选择要写入的数据集和数据文件,来写入新的数据。
hdf格式气溶胶数据读取清洗pythonHDF格式是一种常用的数据存储格式,常用于存储科学数据,包括气溶胶数据。
在Python中,我们可以使用h5py库来读取和处理HDF格式的数据。
首先,我们需要安装h5py库。
可以使用以下命令在命令行中安装h5py:```bashpip install h5py```安装完成后,我们可以开始读取和清洗HDF格式的气溶胶数据。
首先,我们需要导入h5py库:```pythonimport h5py```然后,我们可以使用h5py库中的File类来打开HDF文件:```pythonwith h5py.File('气溶胶数据.hdf', 'r') as f:# 读取数据data = f['数据集名称'][:]```在上面的代码中,我们使用了`with`语句来打开HDF文件,并使用`[:]`来读取整个数据集。
如果需要读取特定的数据集,可以将数据集名称替换为实际的数据集名称。
接下来,我们可以对读取的数据进行清洗。
清洗数据的具体步骤会根据数据的具体情况而定,通常包括去除缺失值、异常值处理、数据转换等操作。
以下是一个简单的数据清洗示例,假设我们需要去除缺失值:```pythonimport numpy as np# 去除缺失值cleaned_data = data[~np.isnan(data).any(axis=1)]```在上面的代码中,我们使用了NumPy库来去除数据中包含缺失值的行。
根据实际情况,可能需要进行更复杂的数据清洗操作。
最后,我们可以将清洗后的数据保存到新的HDF文件中:```pythonwith h5py.File('清洗后的气溶胶数据.hdf', 'w') as f:f.create_dataset('cleaned_data', data=cleaned_data)```在上面的代码中,我们使用了`create_dataset`方法来创建新的数据集,并将清洗后的数据保存其中。
第八章 HDF命令行工具本章简介本章将介绍HDF命令行实用工具。
在本章中,用户将有机会练习一些最有用的HDF实用命令行工具,如hdp和vshow。
8.2 HDF命令行实用工具介绍HDF软件包提供了一组命令行实用工具。
HDF命令行实用工具是在命令行提示符下执行一些小的应用程序。
这些程序可使用户不用编写自己的程序即可执行普通操作。
HDF命令行工具分为三类:查询工具,转换工具和压缩工具。
表8a列出了这些工具的名称和描述。
假如已经安装了HDF4.1r3软件包,就可以在HDF4.1r3/bin子目录里找到这些程序。
设置正确的路径后,能从任何子目录执行这些命令行工具。
完整的HDF命令行工具列表可以在/UG41r3_html/UG_BookTOC15.html中找到。
表8a HDF命令行工具8.3 HDF查询工具8.3.1 hdphdp(HDF dumper)工具是从指定的HDF文件中获取所有对象通用信息最为有用的工具。
它可列出HDF 文件在各层的细节内容。
它还能把倾印出文件中一个或多个特定对象的数据。
hdf提供一组命令,允许用户确定显示何种信息。
下面例子展示怎样使用hdf获得example.hdf的信息,example.hdf是由前面章节的程序创建的。
如果没有创建你自己的example.hdf,可以下载example.hdf。
进入example.hdf文件所在的子目录,确保命令路径包含HDF工具目录,然后键入下列命令:示例输出:hdp list显示HDF文件的内容。
C:\HDF4.1r3\bin>hdp list example.hdfFile: example.hdfFile library version: Major= 4, Minor=1, Release=3String=NCSA HDF Version 4.1 Release 3, May 1999Version Descriptor : (tag 30)Ref nos: 1File Identifier : (tag 100)Ref nos: 1File Description : (tag 101)Ref nos: 1Number type : (tag 106)Ref nos: 1 12Image Dimensions : (tag 300)Ref nos: 1Raster Image Data : (tag 302)Ref nos: 1Raster Image Group : (tag 306)Ref nos: 1SciData dimension record: (tag 701)Ref nos: 12Scientific Data : (tag 702)Ref nos: 5Numeric Data Group : (tag 720)Ref nos: 4Vdata : (tag 1962)Ref nos: 6 8 10 15Vdata Storage : (tag 1963)Ref nos: 6 8 10 15Vgroup : (tag 1965)Ref nos: 2 3 7 9 11 13 14 16示例输出:hdp dumpsds显示HDF文件中科学数据集的内容C:\HDF4.1r3\bin>hdp dumpsds example.hdfFile name: example.hdfVariable Name = my SDSIndex = 0Type= 64-bit floating pointRef. = 4Rank = 3Number of attributes = 0Dim0: Name=fakeDim0Size = 2Scale Type = number-type not setNumber of attributes = 0Dim1: Name=fakeDim1Size = 5Scale Type = number-type not setNumber of attributes = 0Dim2: Name=fakeDim2Size = 3Scale Type = number-type not setNumber of attributes = 0Data :1.0000002.0000003.0000004.0000005.0000006.0000007.000000 8.000000 9.00000010.000000 11.000000 12.00000013.000000 14.000000 15.00000016.000000 17.000000 18.00000019.000000 20.000000 21.00000022.000000 23.000000 24.00000025.000000 26.000000 27.00000028.000000 29.000000 30.000000示例输出:hdp dumpsds显示HDF文件中科学数据集的内容。
C:\HDF4.1r3\bin>hdp dumpgr example.hdfFile name: example.hdfImage Name = My ImageIndex = 0Type= 8朾it unsigned integerwidth=10; height=8Ref. = 2ncomps = 1Number of attributes = 0Interlace= 0Data :0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1920 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 3637 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 5354 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 7071 72 73 74 75 76 77 78 79示例输出:hdp dumpgr显示example.hdf文件中GR对象的内容。
C:\HDF4.1r3\bin>hdp dumpvd 杗 "Simulation Data 1" example.hdfFile name: example.hdfFile Label #0: This is a file labelFile description #0: This is a file descriptionVdata: 3tag = 1962; reference = 15;number of records = 4; interlace = FULL_INTERLACE (0);fields = [X, Y, Temp];record size (in bytes) = 12;name = Simulation Data 1; class = 2D_Temperature_Grid;number of attributes = 0?field index 0: [X], type=5, order=1number of attributes = 0?field index 1: [Y], type=5, order=1number of attributes = 0?field index 2: [Temp], type=5, order=1number of attributes = 0Loc. Data0 2.300000 1.500000 23.500000 3.400000 5.700000 8.0300000.500000 3.500000 1.220000 1.800000 2.600000 0.000000注意:命令“vshow example.hdf +”可用来找出存于“example.hdf”文件中数据对象的名称。
示例输出:hdp dumpvg显示HDF文件中Vgroups的内容。
C:\HDF4.1r3\bin>hdp dumpvg 杗 "My Vgroup" example.hdfFile name: example.hdfFile Label #0: This is a file labelFile description #0: This is a file descriptionVgroup:7tag = 1965; reference = 16;name = My Vgroup; class = Example;number of entries = 2;number of attributes = 0Entries:?/P>#0 (Raster Image Group)tag = 306; reference = 2;#1 (Numeric Data Group)tag = 720; reference = 4;注意:命令“vshow example.hdf +”可用来找出存于“example.hdf”文件中数据对象的名称。
注意:每个hdp命令都提供一个可选标志。
完整信息请参见HDF用户指南。
8.3.2 hdflshdfls工具列出HDF文件中每个数据对象的标记和引用号。
这个命令行与hdp list命令的功能类似。
示例输出:hdfls工具C:\HDF4.1r3\bin>hdfls example.hdfexample.hdf:File library version: Major= 4, Minor=1, Release=3String=NCSA HDF Version 4.1 Release 3, May 1999Version Descriptor : (tag 30)Ref nos: 1File Identifier : (tag 100)Ref nos: 1File Description : (tag 101)Ref nos: 1Number type : (tag 106)Ref nos: 1 12Image Dimensions : (tag 300)Ref nos: 1Raster Image Data : (tag 302)Ref nos: 1Raster Image Group : (tag 306)Ref nos: 1SciData dimension record : (tag 701) Ref nos: 12Scientific Data : (tag 702)Ref nos: 5Numeric Data Group : (tag 720)Ref nos: 4Vdata : (tag 1962)Ref nos: 6 8 10 15Vdata Storage : (tag 1963)Ref nos: 6 8 10 15Vgroup : (tag 1965)Ref nos: 2 3 7 9 11 13 14 168.3.3 vshowvshow 工具显示HDF文件中Vdata对象的信息。