基于遗传算法的分类器设计
- 格式:ppt
- 大小:144.50 KB
- 文档页数:24

基于改进遗传算法的SVM模型优化研究随着时代的发展和科技的进步,越来越多的数据需要被分析和处理。
其中,支持向量机(Support Vector Machine,SVM)是一种经典的机器学习算法,常用于分类和回归问题。
然而,在实际应用中,SVM面临的最大问题是取得高精度分类结果的时间开销,因此优化SVM模型的效率成为了重要的研究方向。
本文主要讨论基于改进遗传算法的SVM模型优化研究。
一、SVM模型简介支持向量机是一种非线性分类器,它的出现开创了一种新的模式识别和数据挖掘技术。
本质上,SVM是通过在高维空间中将样本划分为不同的类别来进行分类。
相较于传统的分类算法,SVM具有许多优点,例如:可以处理多维度问题;不容易陷入局部最优解;可以处理高维数据;准确率高等等。
因此,SVM在很多领域得到广泛的应用。
二、SVM模型优化方法尽管SVM是一个非常优秀的分类器,但是它的计算复杂度也非常高。
优化SVM模型效率的方法有很多,如分类器参数优化、核选择、特征选择等。
下面,我们将重点介绍基于改进遗传算法的SVM模型优化方法。
1、改进遗传算法遗传算法是一种基于自然进化思想的优化算法。
它通过模拟自然选择、遗传变异等过程来寻找最优解。
对于优化SVM模型而言,遗传算法是一种非常有效的工具。
然而,遗传算法存在一些缺陷,例如:算法收敛速度慢、易受参数设置的影响等。
因此,许多学者提出了改进遗传算法,以提高算法的效率和准确率。
2、SVM模型参数优化SVM模型的效果和参数的选取密切相关,因此,进行SVM参数的优化是提高算法效率的一种重要的手段。
一般有两种方法进行SVM参数优化:网格搜索和遗传算法。
基于改进遗传算法的SVM模型优化研究,就是采用遗传算法进行SVM参数的优化,以达到优化SVM模型性能的目的。
3、实验结果为了验证该算法的优越性,我们在多个数据集上进行测试实验。
通过实验数据的分析,我们可以得出以下结论:使用改进遗传算法进行SVM模型参数优化,可以提高SVM模型的预测精度;与传统的遗传算法相比,改进遗传算法更加有效、更加稳定,并且能够在相同条件下更快地收敛。






遗传算法在人脸识别中的应用案例人脸识别技术是近年来快速发展的一项前沿技术,它在安全领域、智能手机解锁、人脸支付等方面都有广泛的应用。
而遗传算法作为一种优化算法,也被广泛应用于人脸识别中,以提高识别准确率和效率。
本文将介绍一些遗传算法在人脸识别中的应用案例,并探讨其优势和局限性。
一、遗传算法在特征提取中的应用在人脸识别中,特征提取是非常重要的一步。
传统的特征提取方法如主成分分析(PCA)、线性判别分析(LDA)等,都存在一定的局限性。
而遗传算法可以通过优化特征选择的过程,自动地找到最佳的特征子集,从而提高识别准确率。
以基于遗传算法的特征选择方法为例,首先将人脸图像转化为数字矩阵,然后通过遗传算法来选择最佳的特征子集。
遗传算法通过模拟进化过程中的选择、交叉和变异等操作,不断优化特征子集的性能。
通过这种方法,可以减少特征维度,去除冗余信息,提高分类器的性能。
二、遗传算法在分类器设计中的应用分类器是人脸识别中的核心组件,它的设计直接影响到识别准确率。
遗传算法可以应用于分类器的参数优化,以提高分类器的性能。
以基于遗传算法的支持向量机(SVM)参数优化为例,首先通过遗传算法来搜索最佳的SVM参数组合,如核函数类型、惩罚因子等。
然后使用优化后的参数训练SVM分类器,从而提高分类准确率。
三、遗传算法在人脸图像增强中的应用人脸图像质量对于识别准确率有着重要影响。
而遗传算法可以应用于人脸图像增强,以提高图像质量,从而提高识别准确率。
以基于遗传算法的图像增强为例,首先通过遗传算法来寻找最佳的图像增强参数,如对比度、亮度等。
然后使用优化后的参数对人脸图像进行增强处理,从而提高图像质量,增强人脸特征的可辨识度。
遗传算法在人脸识别中的应用具有一定的优势,但也存在一些局限性。
首先,遗传算法的计算复杂度较高,需要大量的计算资源和时间。
其次,遗传算法的结果具有一定的随机性,可能无法保证每次都能找到全局最优解。
此外,遗传算法的参数设置也对结果产生一定的影响,需要经验和调优。
![基于遗传算法的优化设计论文[5篇]](https://uimg.taocdn.com/cad20e2c974bcf84b9d528ea81c758f5f61f2985.webp)
基于遗传算法的优化设计论文[5篇]第一篇:基于遗传算法的优化设计论文1数学模型的建立影响抄板落料特性的主要因素有:抄板的几何尺寸a和b、圆筒半径R、圆筒的转速n、抄板安装角β以及折弯抄板间的夹角θ等[4,9]。
在不同的参数a、β、θ下,抄板的安装会出现如图1所示的情况。
图1描述了不同参数组合下抄板的落料特性横截面示意图。
其中,图1(a)与图1(b)、图1(c)、图1(d)的区别在于其安装角为钝角。
当安装角不为钝角且OB与OC的夹角σ不小于OD与OC夹角ψ时(即σ≥ψ),会出现图1(b)所示的安装情况;当σ<ψ时,又会出现图1(c)与图1(d)所示的情况,而两者区别在于,η+θ是否超过180°,若不超过,则为图1(c)情况,反之则为图1(d)情况。
其中,点A为抄板上物料表面与筒壁的接触点或为物料表面与抄板横向长度b边的交点;点B为抄板的顶点;点C为抄板折弯点;点D为抄板边与筒壁的交点;点E为OB连线与圆筒内壁面的交点;点F为OC连线与圆筒内壁面的交点。
1.1动力学休止角(γ)[4,10]抄板上的物料表面在初始状态时保持稳定,直到物料表面与水平面的夹角大于物料的休止角(最大稳定角)时才发生落料情况。
随着转筒的转动,抄板上物料的坡度会一直发生改变。
当物料的坡度大于最大稳定角时,物料开始掉落。
此时,由于物料的下落,物料表面重新达到最大稳定角开始停止掉落。
然而,抄板一直随着转筒转动,使得抄板内物料的坡度一直发生改变,物料坡度又超过最大休止角。
这个过程一直持续到抄板转动到一定位置(即抄板位置处于最大落料角δL时),此时抄板内的物料落空。
通常,在计算抄板持有量时,会采用动力学休止角来作为物料发生掉落的依据,即抄板内的物料坡度超过γ时,物料开始掉落。
该角主要与抄板在滚筒中的位置δ、动摩擦因数μ和弗劳德数Fr等有关。
1.2抄板持有量的计算随着抄板的转动,一般可以将落料过程划分为3部分(R-1,R-2,R-3),如图1(a)所示。
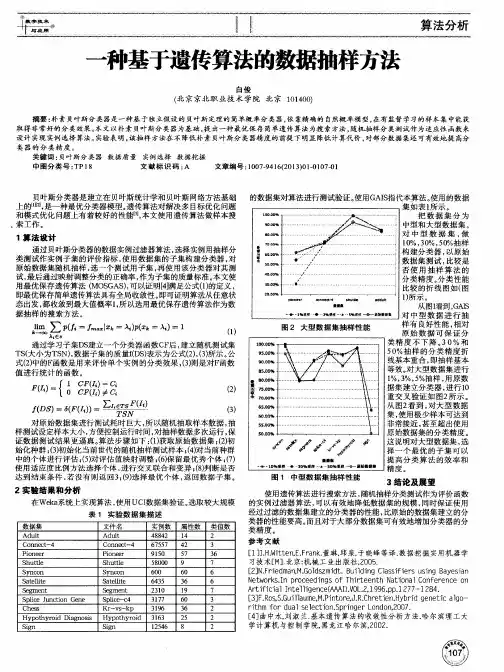

一种基于遗传算法的加权朴素贝叶斯分类算法保玉俊;周莉莉;段鹏【摘要】朴素贝叶斯算法因其分类精度高、模型简单等优点而被得到普遍应用,但因为它需要具备很强的属性之间的条件独立性假设,使得其在实际分类学习中很难实现.针对这个缺点,提出了一种基于遗传算法的加权朴素贝叶斯分类算法(G_WNB).该算法将遗传算法(GA)与加权朴素贝叶斯分类算法(WNB)相结合,首先使用基于Rough Set的加权朴素贝叶斯分类算法,综合信息论与代数论给出的属性权值求解方法,计算出每个属性的权值,以初始权值作为初始种群,加权朴素贝叶斯的分类正确率为适应度函数,采用遗传算法优选,以使适应度函数最高的权值为数据集的最终权值,最后使用G_WNB进行分类.实验表明,该算法提高了分类准确率,同时提高了朴素贝叶斯分类器的性能.【期刊名称】《云南民族大学学报(自然科学版)》【年(卷),期】2018(027)006【总页数】5页(P525-529)【关键词】加权朴素贝叶斯;Rough集;属性重要度;遗传算法;适应度函数;分类【作者】保玉俊;周莉莉;段鹏【作者单位】云南民族大学数学与计算机科学学院,云南昆明650000;云南民族大学数学与计算机科学学院,云南昆明650000;云南民族大学数学与计算机科学学院,云南昆明650000【正文语种】中文【中图分类】TP311.13数据挖掘(data mining)是知识发现的过程.分类是数据挖掘中的重要研究领域之一.分类是通过对样本数据进行分析和学习构造分类器的过程.分类算法的核心部分是构造分类器[1].其中最经典的分类算法有决策树、贝叶斯分类、神经网络等[2].在各个经典分类算法中,朴素贝叶斯算法(简称NBC),因计算高效、模型简单、计算精度高得到广泛应用.然而,由于朴素贝叶斯的条件独立性假设在实际应用中比较难满足,针对朴素贝叶斯的缺点,众多学者[3]通过研究学习贝叶斯网络来改进其性能.国外学者Zhang Harry在文献[4]中提出了5种加权朴素贝叶斯算法(weighted native bayes,简称WNB),分别针对不同的方向,评价每个类属性对分类的影响程度给类属性赋予不同的权重,该算法不仅保留了朴素贝叶斯的分类精度高的优点,又削弱了类属性条件独立性假设,在一定程度上优化了朴素贝叶斯算法的性能,实验证明爬山法和Monte Carlo相结合的权值求解很大程度上提高了分类器的性能[5].文献[6]中基于粗糙集属性重要度理论求解属性权值,提出了一种综合信息论与代数论给出的属性权值求解方法.文献[7]提出了一种基于人工免疫系统(AIS)的自适应属性加权方法用于朴素贝叶斯分类.相比较NBC,上述加权朴素贝叶斯算法在某些数据集上的确提高了分类准确率,但在另外一些数据集上却差强人意.为了在大部分数据集一定程度上都提高WNB分类准确率,我们基于遗传算法(GA)和加权朴素贝叶斯(WNB)相结合,提出了一种基于遗传算法的加权朴素贝叶斯分类算法(G_WNB),使用WNB算法进行属性权值求解,然后以属性权值作为初始种群,WNB的分类正确率为适应度函数,采用遗传算法优选,得到后代中适应度函数最高的权值为数据集的最优权值,提高了分类准确率.对UCI上4个数据集进行实验,分类的结果表明:提出的G_WNB算法有效的结合了遗传算法的全局最优解特性的和WNB算法的高效性,提高了分类准确率.1 系统理论模型描述1.1 遗传算法遗传算法是一种搜索全局最优解的模拟自然进化算法[8-9],它是模仿生物遗传学和自然选择的机理,是一种仿真生物进化过程的计算模型[10],具有较强的鲁棒性、使用简单、应用广泛.遗传操作的基本原理是:在遗传算法中,随机产生所求解问题的数字编码,称为染色体,产生初始化种群后,根据适应度函数评价染色体,采用优胜劣汰、适者生存的原理,挑选适应度高的染色体进行遗传操作.采用遗传操作后的个体集合,形成下一代新的种群,对新种群进行下一代的进化[11].这个过程使后一代种群比前一代种群更加适应环境,后代种群中的最优个体则是问题的近似最优解.其基本遗传操作有:编码与解码、适应度函数选取、选择、交叉、变异[12].1.2 朴素贝叶斯分类算法1.2.1 朴素贝叶斯模型(NBC)定义1 贝叶斯公式(1)P(C|X)称为条件X属于C的后验概率,P(C),P(X)分别为类别C和条件X的先验概率,P(X|C)是C属于X的后验概率.假设A表示属性变量,数据样本集共有m个属性变量,C表示类别属性变量,特征向量X={x1,x2,…,xm}表示m个属性变量(A1,A2,…,Am)的具体取值,类别变量C表示n个不同的取值C1,C2,…,Cn,即n个不同的类别.用Test=<x1,x2,…,xm>表示测试样本集;Traini=<x1,x2,…,xm,ci>表示训练样本集.因为其属性的条件独立性假设,有:(2)由贝叶斯定理可知后验概率公式为:(3)未知样本标号Test属于后验概率最大的类别中,由于P(x)为一常数,于是式(3)修改为下式,称为朴素贝叶斯模型[5]:(4)1.2.2 属性加权朴素贝叶斯模型(WNB)由于朴素贝叶斯条件独立性的假设在实际应用,有学者为了弱化其属性条件独立性假设的影响,根据属性对分类的重要程度大小给属性赋予相应的权重,并提出了属性加权朴素贝叶斯模型[4]:1≤k≤n.(5)其中w(i)代表类属性Ai的权重,属性的权重的大小正比于属性对分类的影响程度高低.加权朴素贝叶斯分类学习的核心在于获得可以提高分类正确率的属性权值[13].2 基于遗传算法的加权朴素贝叶斯分类算法模型(G_WNB)2.1 求解属性权值由于朴素贝叶斯分类自身条件独立性假设在实际情况中大部分无法成立,这缩小了朴素贝叶斯的分类适用范围.所以,根据属性对分类的贡献程度对每个属性赋予合适的权值构造分类器.文献[6]中基于Rough Set的属性重要性理论,综合信息论、代数论角度给出了属性权值求解的方法,提出了改进的属性加权朴素贝叶斯分类方法,并证明了该方法的有效性,优于文献[4]中的爬山法、信息增益法和Mente Carlo方法.所以运用基于Rough Set中的信息论、代数论,综合两方面赋予属性权值.定义2 (信息论下属性重要度的权值定义)[14] 设I(xi,C)表示条件属性Ai与类别属性C在信息论下的互信息量,则属性Ai权重为:(6)定义3 (代数论下属性属性重要度的权值定义)[14]设SGF(xi,C)表示条件属性Ai对于类别属性C的代数论下属性重要度,则属性Ai的权值为:(7)信息论与代数论下的属性重要度互相互补,因为:代数论下的属性重要度考虑的是该属性对确定分类子集的影响,信息论下的属性重要度考虑的是该属性对于不确定分类子集的影响,并且属性重要度在两种角度下并非具有一致性[15].综合考虑属性对确定分类子集和不确定分类子集的影响,可综合信息论与代数论的属性重要度的均值,所以定义属性权值为:定义4 (综合信息论与代数论的属性权值定义)[6]设w1i和w2i分别代表属性Ai在信息论和代数论下的属性重要性,可得属性Ai在综合信息论和代数论下的权值wi 为:(8)通过定义4可求解条件属性Ai的每个属性权值,将式(8)代入式(5),可得到属性加权的朴素贝叶斯分类器WNB.2.2 最优权值提取改进的加权朴素贝叶斯分类器WNB放松了朴素贝叶斯的条件独立性假设,在实际运用中得以满足.WNB算法在某些数据集上表现很好,但却在另外数据集上的表现差强人意.目前学者J Liu将混合模拟退火和遗传算法相结合对属性集进行优化,提出一种基于遗传算法的朴素贝叶斯算法[16],众多学者遗传算法与贝叶斯算法结合[17-18]并取得较好成果[19-20].所以我们提出基于遗传算法的加权朴素贝叶斯分类算法G_WNB:2.2.1 G_WNB编码方式[10]采用2进制编码方式,每条染色体由一组2进制组成,每条染色体对应条件属性的权值,长度为数据库中随机属性的个数,每个2进位制依次与每个属性的初始权值相对应.2.2.2 G_WNB初始种群首先由WNB算法确定每个条件属性权值,以条件属性权值的数字编码作为初始种群进行搜索,减少解的搜索空间,从而大大提高了效率.2.2.3 G_WNB适应度函数适应度函数为WNB分类器的分类正确率f(x),eval(v)=f(x),v表示染色体.2.2.4 算法参数设置遗传算法的参数有种群规模和算法执行的最大代数目、交叉概率、变异概率等[21].使用了如下参数:最大代数目pop_maxiter=100,种群规模pop_size=50,交叉概率pc=0.8,变异概率pm=0.05.2.2.5 G_WNB算法①使用ChiMerge算法离散化数据集,采用分层随机抽样方法将数据集分成训练集和测试集;②使用WNB算法处理样本集,生成m个条件属性初始权值wi,求解初始权值分类正确率accuracy1;③将初始权重wi作为初始种群,采用遗传算法优选;④终止条件判断:当达到最大代数目时停止,否则转向步骤④;⑤输出遗传种群中,适应度函数最优的染色体作为问题的最优解Wi(最优权值),同时输出最优权值的适应度函数accuracy2.3 实验将提出的基于遗传算法的加权朴素贝叶斯算法应用到4个来自于UCI开源数据集,验证其改进效果.4个数据集分别如下:australian,cleveland,heart,iris.数据集的具体描述为表1;对每个数据集首先采用chimerge算法对连续数据进行离散化处理[22];采用分层随机抽样,训练集占70%,测试集占30%.表1 所用数据集的描述编号数据集条件属性数决策属性数样例数有无缺失属性有无连续属性1australian142690NY2cleveland135302YY3heart132270NN4iris43150NN事先采用上述分层随机抽样将数据进行划分,对每个测试集进行测试.首先将数据集进行WNB分类,得到分类的正确率;然后将数据集进行G_WNB优选,得到最优解,将最优解代入适应度函数得到G_WNB分类算法的正确率;最后将数据集进行朴素贝叶斯、加权朴素贝叶斯、文献[19]的GA_K2、GA_GS算法分类,同样得到分类的正确率;得到的正确率如表2所示:表2 5种分类算法在各数据集上的分类正确率 %编号数据集分类正确率NBCWNB 文献[19]GA_K2文献[19]GA_GSG_WNB1australian86.0189.2586.0985.6590.312cleveland78.5783. 8781.3683.3988.233heart81.3383.1583.7084.4490.324iris92.6896.4194.0095 .3398.72通过仿真实验证明,无论是综合信息论和代数论的属性重要度改进的属性加权朴素贝叶斯算法,还是基于改进的遗传算法属性加权朴素贝叶斯算法,都大部分提高了分类精度,这是之前所预见的,从图1可见,G_WNB模型在大部分数据集上都要好于NBC、WNB、GA_K2、GA_GS模型,说明G_WNB模型的分类效果更优.4 结语针对目前属性加权的朴素贝叶斯的缺点,提出了一种基于遗传算法的加权朴素贝叶斯分类算法,不仅避免了朴素贝叶斯的条件独立性假设,而且以属性权值为遗传算法的最优解、分类正确率为适应度函数,在不同数据集上可以进一步提高分类能力.实验采用UCI中的4个数据集为测试集,比较NBC、WNB、GA_K2、GA_GS、G_WNB五种分类算法的分类精度.实验证明:G_WNB算法可以根据数据本身特点提高属性加权朴素贝叶斯分类的效果.对于加权朴素贝叶斯来说,对属性赋予权值虽然提高了分类性能,但没有考虑到冗余属性这一方面,不相关属性对分类的影响不大,但在加权朴素贝叶斯分类学习中也会赋予冗余属性一个权值,这样不但会影响分类精度,还会影响分类效率.所以如何约简属性,提高分类效果将是下一步研究的方向.参考文献:【相关文献】[1] 乐明明. 数据挖掘分类算法的研究和应用[D]. 成都:电子科技大学, 2017.[2] 魏茂胜. 数据挖掘中的分类算法综述[J]. 网络安全技术与应用, 2017(6):65-66.[3] COOPER G F. The computational complexity of probabilistic inference using Bayesian belief networks (research note)[M]. Amsterdam:Elsevier Science Publishers Ltd. 1990. [4] ZHANG H, SHENG S. Learning weighted naive Bayes with accurate ranking[C]// IEEE International Conference on Data Mining. IEEE, 2005:567-570.[5] 孙秀亮. 基于属性加权的选择性朴素贝叶斯分类研究[D]. 哈尔滨:哈尔滨工程大学, 2013.[6] 邓维斌, 王国胤, 王燕. 基于Rough Set的加权朴素贝叶斯分类算法[J]. 计算机科学, 2007,34(2):204-206.[7] WU J, PAN S, ZHU X, et al. Self-adaptive attribute weighting for Naive Bayes classification[J]. Expert Systems with Applications, 2015, 42(3):1487-1502.[8] HOLLAND J H. Adaptation in natural and artificial systems[M]. Cambridge:MIT Press, 1992.[9] GOLDBERG D E. Genetic Algorithms in Search, Optimization and Machine Learning[J]. 1989, xiii(7):2104-2116.[10] 邓曾. 遗传算法和贝叶斯模型在垃圾邮件过滤中的应用[D]. 成都:电子科技大学, 2015.[11] 赵宜鹏, 孟磊, 彭承靖. 遗传算法原理与发展方向综述[J]. 科学技术创新, 2010(13):79-80.[12] 匡佳青. 基于遗传算法和加权极限学习机结合的乳腺癌亚型分类和基因选择[D]. 长春:吉林大学, 2017.[13] 张伟, 王志海, 原继东,等. 一种局部属性加权朴素贝叶斯分类算法[J]. 北京交通大学学报, 2018, 42(2).[14] 王国胤. Rough集理论与知识获取[M]. 西安:西安交通大学出版社, 2001.[15] 王国胤, 于洪, 杨大春. 基于条件信息熵的决策表约简[J]. 计算机学报, 2002, 25(7):759-766.[16] LIU J, SONG B. Naive Bayesian Classifier Based on Genetic Simulated Annealing Algorithm[J]. Procedia Engineering, 2011, 23:504-509.[17] 简敏. 基于GA-K2算法的贝叶斯网络研究及在个人信用评估的应用[D]. 广州:暨南大学, 2016.[18] 张增伟, 吴萍. 基于朴素贝叶斯算法的改进遗传算法分类研究[J]. 计算机工程与设计, 2012,33(2):750-753.[19] 蒋望东. 基于遗传算法的贝叶斯分类器结构学习研究[D]. 桂林:广西师范大学, 2005.[20] 刘宏畅. 改进遗传算法在营养配餐系统中的应用[D]. 北京:北京工业大学, 2015.[21] 李芳, 赵天洋. 遗传算法理论及其应用进展探析[J]. 技术与市场, 2016, 23(1):87-87.[22] GARCíA S, LUENGO J, HERRERA F. Tutorial on practical tips of the most influential data preprocessing algorithms in data mining[J]. Knowledge-Based Systems, 2016, 98:1-29.。

曲靖师范学院学生毕业论文(设计)题目:基于Matlab的遗传算法程序设计及优化问题求解院(系):数学与信息科学学院专业:信息与计算科学班级:20051121班学号:2005112104论文作者:沈秀娟指导教师:刘俊指导教师职称:教授2009年 5月基于Matlab的遗传算法程序设计及优化问题求解摘要遗传算法作为一种新的优化方法,广泛地用于计算科学、模式识别和智能故障诊断等方面,它适用于解决复杂的非线性和多维空间寻优问题,近年来也得到了较为广阔的应用. 本文介绍了遗传算法的发展、原理、特点、应用和改进方法,以及基本操作和求解步骤,再基于Matlab编写程序实现遗传算法并求解函数的优化问题. 程序设计过程表明,用Matlab语言进行优化计算,具有编程语句简单,用法灵活,编程效率高等优点. 经仿真验证,该算法是正确可行的.关键词:遗传算法;Matlab;优化Matlab-based genetic algorithm design and optimization of procedures forproblem solvingAbstract:As a new optimizated method,genetic algorithm is widely used in co mputational science,pattern recognition,intelligent fault diagnosisandsoon. It is suitable to solve complex non-linear and multi-dimensionaloptimizatio n problem.And it has been more widely used in recentyears.This paper descri bes the development of genetic algorithms,principle,features,application an d improvement of methods.At the same time,it in-troduces basic operation and solution steps.And then,it achievesgeneticalgorithm on the matlab programmi ng andsolves the function optimization problem.The program design process sh ows that this optimization calculation has advantages of simple programming language,flexible usage and high efficiency in Matlab language.The algorith m iscorrect and feasible by simulated authentication.Keywords: Genetic algorithm; Matlab;Optimization目录1 引言 (1)2 文献综述 (1)2.1国内外研究现状及评价 (1)2.2提出问题 (2)3 遗传算法的理论研究 (2)3.1遗传算法的产生背景 (2)3.2遗传算法的起源与发展 (3)3.2.1 遗传算法的起源 (3)3.2.2 遗传算法的发展 (3)3.3遗传算法的数学基础研究 (4)3.4遗传算法的组成要素 (6)3.5遗传算法的基本原理 (7)3.6遗传算法在实际应用时采取的一般步骤 (8)3.7遗传算法的基本流程描述 (9)3.8遗传算法的特点 (10)3.9遗传算法的改进 (11)3.10遗传算法的应用领域 (12)4 基于MATLAB的遗传算法实现 (14)5 遗传算法的函数优化的应用举例 (17)6 结论 (18)6.1主要发现 (18)6.2启示 (18)6.3局限性 (19)6.4努力的方向 (19)参考文献 (20)致谢 (21)附录 (22)1引言遗传算法(Genetic Algorithm)是模拟自然界生物进化机制的一种算法即遵循适者生存、优胜劣汰的法则也就是寻优过程中有用的保留无用的则去除. 在科学和生产实践中表现为在所有可能的解决方法中找出最符合该问题所要求的条件的解决方法即找出一个最优解. 这种算法是1960年由Holland提出来的其最初的目的是研究自然系统的自适应行为并设计具有自适应功能的软件系统. 它的特点是对参数进行编码运算不需要有关体系的任何先验知识沿多种路线进行平行搜索不会落入局部较优的陷阱,能在许多局部较优中找到全局最优点是一种全局最优化方法[1-3]. 近年来,遗传算法已经在国际上许多领域得到了应用. 该文将从遗传算法的理论和技术两方面概述目前的研究现状描述遗传算法的主要特点、基本原理以及改进算法,介绍遗传算法的应用领域,并用MATLAB 实现了遗传算法及最优解的求解.2文献综述2.1国内外研究现状及评价国内外有不少的专家和学者对遗传算法的进行研究与改进. 比如:1991年D.WHITEY 在他的论文中提出了基于领域交叉的交叉算子(ADJACENCY BASED CROSSOVER),这个算子是特别针对用序号表示基因的个体的交叉,并将其应用到了TSP问题中,通过实验对其进行了验证. 2002年,戴晓明等应用多种群遗传并行进化的思想,对不同种群基于不同的遗传策略,如变异概率,不同的变异算子等来搜索变量空间,并利用种群间迁移算子来进行遗传信息交流,以解决经典遗传算法的收敛到局部最优值问题. 国内外很多文献都对遗传算法进行了研究. 现查阅到的国内参考文献[1-19]中, 周勇、周明分别在文献[1]、[2]中介绍了遗传算法的基本原理;徐宗本在文献[3]中探讨了包括遗传算法在内的解全局优化问题的各类算法,文本次论文写作提出了明确的思路;张文修、王小平、张铃分别在文献[4]、[5]、[6]从遗传算法的理论和技术两方面概述目前的研究现状;李敏强、吉根林、玄光南分别在文献[7]、[8]、[9]中都不同程度的介绍了遗传算法的特点以及改进算法但未进行深入研究;马玉明、张丽萍、戴晓辉、柴天佑分别在文献[10]、[11]、[12]、[13]中探讨了遗传算法产生的背景、起源和发展;李敏强、徐小龙、林丹、张文修分别在文献[14]、[15]、[16]、[17]探讨了遗传算法的发展现状及以后的发展动向;李敏强,寇纪凇,林丹,李书全在文献[18]中主要论述了遗传算法的具体的实施步1骤、应用领域及特点;孙祥,徐流美在文献[19]中主要介绍了Matlab的编程语句及基本用法.所有的参考文献都从不同角度不同程度的介绍了遗传算法但都不够系统化不够详细和深入.2.2提出问题随着研究的深入,人们逐渐认识到在很多复杂情况下要想完全精确地求出其最优解既不可能,也不现实,因而求出近似最优解或满意解是人们的主要着眼点之一. 很多人构造出了各种各样的复杂形式的测试函数,有连续函数,有离散函数,有凸函数,也有凹函数,人们用这些几何特性各异的函数来评价遗传算法的性能. 而对于一些非线性、多模型、多目标的函数优化问题用其他优化方法较难求解遗传算法却可以方便地得到较好的结果. 鉴于遗传算法在函数优化方面的重要性,该文在参考文献[1-19]的基础上,用Matlab语言编写了遗传算法程序, 并通过了调试用一个实际例子来对问题进行了验证,这对在Matlab环境下用遗传算法来解决优化问题有一定的意义.3遗传算法的理论研究3.1遗传算法的产生背景科学研究、工程实际与国民经济发展中的众多问题可归结作“极大化效益、极小化代价”这类典型模型. 求解这类模型导致寻求某个目标函数(有解析表达式或无解析表达式)在特定区域上的最优解. 而为解决最优化问题目标函数和约束条件种类繁多,有的是线性的,有的是非线性的;有的是连续的,有的是离散的;有的是单峰值的,有的是多峰值的. 随着研究的深入,人们逐渐认识到:在很多复杂情况下要想完全精确地求出其最优解既不可能,也不现实,因而求出近似最优解或满意解是人们的主要着眼点之一. 总的来说,求最优解或近似最优解的方法有三种: 枚举法、启发式算法和搜索算法.(1)枚举法. 枚举出可行解集合内的所有可行解以求出精确最优解. 对于连续函数,该方法要求先对其进行离散化处理,这样就有可能产生离散误差而永远达不到最优解. 另外,当枚举空间比较大时该方法的求解效率比较低,有时甚至在目前最先进的计算工具上都无法求解.(2)启发式算法. 寻求一种能产生可行解的启发式规则以找到一个最优解或近似最优解. 该方法的求解效率虽然比较高,但对每一个需要求解的问题都必须找出其特有的2启发式规则,这个启发式规则无通用性不适合于其它问题.(3)搜索算法. 寻求一种搜索算法,该算法在可行解集合的一个子集内进行搜索操作以找到问题的最优解或近似最优解. 该方法虽然保证了一定能够得到问题的最优解,但若适当地利用一些启发知识就可在近似解的质量和求解效率上达到一种较好的平衡.随着问题种类的不同以及问题规模的扩大,要寻求一种能以有限的代价来解决上述最优化问题的通用方法仍是一个难题. 而遗传算法却为我们解决这类问题提供了一个有效的途径和通用框架开创了一种新的全局优化搜索算法.3.2遗传算法的起源与发展3.2.1 遗传算法的起源50年代末到60年代初,自然界生物进化的理论被广泛接受生物学家Fraser,试图通过计算的方法来模拟生物界“遗传与选择”的进化过程,这是遗传算法的最早雏形. 受一些生物学家用计算机对生物系统进行模拟的启发,Holland开始应用模拟遗传算子研究适应性. 在1967年,Bagley关于自适应下棋程序的论文中,他应用遗传算法搜索下棋游戏评价函数的参数集并首次提出了遗传算法这一术语. 1975年,Holland出版了遗传算法历史上的经典著作《自然和人工系统中的适应性》,首次明确提出遗传算法的概念. 该著作中系统阐述了遗传算法的基本理论和方法,并提出了模式(schemat atheorem)[4],证明在遗传算子选择、交叉和变异的作用下具有低阶、短定义距以及平均适应度高于群体平均适应度的模式在子代中将以指数级增长. Holand创建的遗传算法,是基于二进制表达的概率搜索方法. 在种群中通过信息交换重新组合新串;根据评价条件概率选择适应性好的串进入下一代;经过多代进化种群最后稳定在适应性好的串上. Holand最初提出的遗传算法被认为是简单遗传算法的基础,也称为标准遗传算法.3.2.2 遗传算法的发展(1)20世纪60年代,John Holland教授和他的数位博士受到生物模拟技术的启发,认识到自然遗传可以转化为人工遗传算法. 1962年,John Holland提出了利用群体进化模拟适应性系统的思想,引进了群体、适应值、选择、变异、交叉等基本概念.(2)1967年,J.D.Bagely在其博士论文中首次提出了“遗传算法”的概念.(3)1975年,Holland出版了《自然与人工系统中的适应性行为》(Adaptation in Natural and Artificial System).该书系统地阐述了遗传算法的基本理论和方法,提出了遗传算法的基本定理—模式定理,从而奠定了遗传算法的理论基础. 同年De Jong3在其博士论文中,首次把遗传算法应用于函数优化问题对遗传算法的机理与参数进行了较为系统地研究并建立了著名的五函数测试平台.(4)20世纪80年代初,Holland教授实现了第一个基于遗传算法的机器学习系统—分类器系统(Classifier System简称CS),开创了基于遗传算法的机器学习的新概念.(5)1989年,David Goldberg出版了《搜索、优化和机器学习中的遗传算法》(Genetic Algorithms in Search Optimization and Machine Learning).该书全面系统地总结了当时关于遗传算法的研究成果,结合大量的实例完整的论述了遗传算法的基本原理及应用,奠定了现代遗传算法的基础.(6)1992年,John R.Koza出版了专著《遗传编程》(Genetic Programming)提出了遗传编程的概念,并成功地把遗传编程的方法应用于人工智能、机器学习、符号处理等方面. 随着遗传算法的不断深入和发展,关于遗传算法的国际学术活动越来越多,遗传算法已成为一个多学科、多领域的重要研究方向.今天遗传算法的研究已经成为国际学术界跨学科的热门话题之一. 遗传算法是一种有广泛应用前景的算法,但是它的研究和应用在国内尚处于起步阶段. 近年来遗传算法已被成功地应用于工业、经济管理、交通运输、工业设计等不同领域解决了许多问题.例如可靠性优化、流水车间调度、作业车间调度、机器调度、设备布局设计、图像处理以及数据挖掘等.3.3 遗传算法的数学基础研究模式定理及隐含并行性原理被看作遗传算法的两大基石,后来又提出了建筑块假设,但是模式定理无法解释遗传算法实际操作中的许多现象,隐性并行性的论证存在严重漏洞,而建筑块假设却从未得到过证明. 对遗传算法的基础理论的研究主要分三个方面:模式定理的拓广和深入、遗传算法的新模型、遗传算法的收敛性理论.(1)模式定理的拓广和深入. Holland给出模式定理:具有短的定义长度、低阶、并且模式采样的平均适应值在种群平均适应值以上的模式在遗传迭代过程中将按指数增长率被采样模式定理可表达为:m(H,t+1)≥m(H,t).()fHf.()⎪⎭⎫⎝⎛---PHOlP mHc.1.1δ(1)其中m(Ht):在t代群体中存在模式H 的串的个数.4()Hf:在t 代群体中包含模式H 的串的平均适应值. f:t代群体中所有串的平均适应值.l表示串的长度pc 表示交换概率pm表示变异概率.Holland的模式定理奠定了遗传算法的数学基础根据隐性并行性得出每一代处理有效模式的下限值是()l c n2113.其中n是种群的大小c1是小整数. Bertoui和Dorigo进行了深入的研究获得当2βln=,β为任意值时处理多少有效模式的表达式. 上海交通大学的恽为民等获得每次至少产生()21-no数量级的结果. 模式定理中模式适应度难以计算和分析A.D.Berthke首次提出应用Walsh函数进行遗传算法的模式处理并引入模式变换的概念采用Walsh函数的离散形式有效地计算出模式的平均适应度并对遗传算法进行了有效的分析. 1972年Frantz首先发现一种常使GA从全局最优解发散出去的问题,称为GA-欺骗题[5]. Goldberg最早运用Walsh模式转换设计出最小的GA-欺骗问题并进行了详细分析.(2)遗传算法的新模型. 由于遗传算法中的模式定理和隐性并行性存在不足之处,为了搞清楚遗传算法的机理,近几年来人们建立了各种形式的新模型最为典型的是马氏链模型遗传算法的马氏链模型[6-7],主要由三种分别是种群马氏链模型、Vose模型和Cerf 扰动马氏链模型. 种群马氏链模型将遗传算法的种群迭代序列视为一个有限状态马氏链来加以研究,运用种群马氏链模型转移概率矩阵的某些一般性质分析遗传算法的极限行为,但转移概率的具体形式难以表达妨碍了对遗传算法的有限时间行为的研究;Vose 模型是在无限种群假设下利用相对频率导出,表示种群的概率的向量的迭代方程,通过这一迭代方程的研究,可以讨论种群概率的不动点及其稳定性,从而导致对遗传算法的极限行为的刻画,但对解释有限种群遗传算法的行为的能力相对差一些. Cerf扰动模型是法国学者Cerf将遗传算法看成一种特殊形式的广义模拟退火模型,利用了动力系统的随机扰动理论,对遗传算法的极限行为及收敛速度进行了研究. 还有其它改进模型,例如张铃、张钹等人提出的理想浓度模型,它首先引入浓度和家族的概念,通过浓度计算建立理想浓度模型[8-10],其浓度变化的规律为:5c(Hi,t +1)=c(H,t).()()()t ftOHfi,(2)c(Hi,t+1)表示模式Hi在t时刻的浓度,并对其进行分析,得出结论:遗传算法本质上是一个具有定向制导的随机搜索技术,其定向制导原则是导向适应度高的模式为祖先的染色体“家族”方向.(3)遗传算法的收敛性理论. 对于遗传算法的马氏链分析本身就是建立遗传算法的收敛性理论[11-12], Eiben等用马尔可夫链证明了保留最优个体的遗传算法的概率性全局收敛,Rudolph用齐次有限马尔可夫链证明了具有复制、交换、突变操作的标准遗传算法收敛不到全局最优解,不适合于静态函数的优化问题,建议改变复制策略以达到全局收敛,Back和Muhlenbein研究了达到全局最优解的算法的时间复杂性问题,近几年,徐宗本等人建立起鞅序列模型,利用鞅序列收敛定理证明了遗传算法的收敛性.3.4遗传算法的组成要素遗传算法所涉及的五大要素:参数编码、初始群体的设定、适应度函数的设计、遗传操作的设计和控制参数的设定,其具体内容如下:(1)参数编码. 遗传算法中常用的编码方法是二进制编码,它将问题空间的参数用字符集{0,1}构成染色体位串,符合最小字符集原则,操作简单,便于用模式定理分析.(2)适应度函数的设计. 适应度函数是评价个体适应环境的能力,使选择操作的依据,是由目标函数变换而成. 对适应度函数唯一的要求是其结果为非负值. 适应度的尺度变换是对目标函数值域的某种映射变换,可克服未成熟收敛和随机漫游现象. 常用的适应度函数尺度变化方法主要有线性变换、幂函数变换和指数变换.[13](3)遗传操作的设计. 包括选择、交叉、变异.①选择(Selection). 选择是用来确定交叉个体,以及被选个体将产生多少个子代个体. 其主要思想是个体的复制概率正比于其适应值,但按比例选择不一定能达到好的效果. 选择操作从早期的轮盘赌选择发展到现在最佳个体保存法、排序选择法、联赛选择法、随机遍历抽样法、局部选择法、柔性分段复制、稳态复制、最优串复制、最优串保留等.②交叉(Crossover). 交叉是指把两个父代个体的部分结构加以替换重组而生成新个体的操作,其作用是组合出新的个体,在串空间进行有效搜索,同时降低对有效模式的破坏概率. 各种交叉算子均包含两个基本内容:确定交叉点的位置和进行部分基因的6交换. 常用的交叉操作方法有单点交叉、双点交叉、一致交叉、均匀交叉、算术交叉、二维交叉、树结构交叉、部分匹配交叉、顺序交叉和周期交叉等等.③变异(Mutation). 变异是指将个体编码串中的某些基因值用其它基因值来替换,形成一个新的个体. 遗传算法中的变异运算是产生新个体的辅助方法,其目的是使遗传算法具有局部的随机搜索能力和保持群体的多样性. 变异算法包括确定变异点的位置和进行基因值替换. 常见的变异算子有基本位变异、均匀变异、高斯变异、二元变异、逆转变异、自适应变异等.(4) 控制参数设定. 遗传算法中需要确定一些参数取值,主要有串长l,群体大小n,交叉概率pc、变异概率pm等,对遗传算法性能影响很大. 目前对参数根据情况进行调整变化研究比较多,而一般确定的参数范围是:n=20~200,pc = 015 ~110,pm =0~0105.3.5遗传算法的基本原理在自然界,由于组成生物群体中各个体之间的差异,对所处环境有不同的适应和生存能力,遵照自然界生物进化的基本原则,适者生存、优胜劣汰,将要淘汰那些最差个体,通过交配将父本优秀的染色体和基因遗传给子代,通过染色体核基因的重新组合产生生命力更强的新的个体与由它们组成的新群体. 在特定的条件下,基因会发生突变,产生新基因和生命力更强的新个体;但突变是非遗传的,随着个体不断更新,群体不断朝着最优方向进化,遗传算法是真实模拟自然界生物进化机制进行寻优的. 在此算法中,被研究的体系的响应曲面看作为一个群体,相应曲面上的每一个点作为群体中的一个个体,个体用多维向量或矩阵来描述,组成矩阵和向量的参数相应于生物种组成染色体的基因,染色体用固定长度的二进制串表述,通过交换、突变等遗传操作,在参数的一定范围内进行随机搜索,不断改善数据结构,构造出不同的向量,相当于得到了被研究的不同的解,目标函数值较优的点被保留,目标函数值较差的点被淘汰.[14]由于遗传操作可以越过位垒,能跳出局部较优点,到达全局最优点.遗传算法是一种迭代算法,它在每一次迭代时都拥有一组解,这组解最初是随机生成的,在每次迭代时又有一组新的解由模拟进化和继承的遗传操作生成,每个解都有一目标函数给与评判,一次迭代成为一代. 经典的遗传算法结构图如下:图1 遗传算法的结构图3.6遗传算法在实际应用时采取的一般步骤(1)根据求解精度的要求,确定使用二进制的长度. 设值域的取值范围为[a i ,b i ],若要求精确到小数点后6位,则由(b i -a i )×106<2m i -1求得m i 的最小长度,进而可求出位于区间的任一数:x i =a i +decimal(1001...0012)×12--m i a b i i [15] (3)其中,i=1,2, ..., Popsize ;Popsize 为种群中染色体的个数;(2)利用随机数发生器产生种群;(3)对种群中每一染色体v i ,计算其对应适应度eval(v i ),i=1,2,… ,Popsize ;(4)计算种群适应度之和F :F=()v eval iPopsizei ∑=1(4) (5)计算每个染色体选择概率Pi :()F v eval p i i =(5) i=1,2, ... ,Popsize ;(6)计算每个染色体的累加概率qi:q i =∑=ijjp1(6)i=1, 2, ...,Popsize ;(7)产生一个位于[0,1]区间的随机数序列,其长度为N,如果其中任意一数r<q1,则选择第一个染色体,若qi1-<r<qi,则选择第i个染色体,i=1,2, ... Popsize,这样可以获得新一代种群;(8)对新一代种群进行交叉运算:设交叉概率为pc,首先产生一个位于区间[0,1]内的随机数序列,其长度为N,如果其中任意一数r<pc,则对应染色体被选中(如果选中奇数个,则可以去掉一个),然后在[1,m-1]区间中产生随机数,个数为选中的染色体数的一半,然后根据随机数在对应位置进行交换操作,从而构成新的染色体;(9)变异操作:设变异概率为pm,产生m×N个位于区间[0,1]上的随机数.如果某一随机数r<pm,则选中对应位变异,构成新的种群;(10)第一代计算完毕,返回③继续计算,直到达到满意的结果为止.3.7遗传算法的基本流程描述随机初始化种群p(0)={x1,x2,...,xn};t=0;计算p(0)中个体的适应值;while(不满足终止条件){ 根据个体的适应值及选择策略从p(t)中选择下一代生成的父体p(t);执行交叉,变异和再生成新的种群p(t+1) ;计算p(t+1)中个体的适应值;t=t+1;}伪代码为:BEGIN:I=0;Initialize P(I);Fitness P(I);While (not Terminate2Condition){I++;GA2Operation P(I);Fitness P(I);}END.3.8遗传算法的特点遗传算法不同于传统的搜索和优化方法. 主要区别在于:(1)自组织、自适应和自学习性(智能性). 应用遗传算法求解问题时,在编码方案、适应度函数及遗传算子确定后,算法将利用进化过程中获得的信息自行组织搜索. 由于基于自然的选择策略“适者生存、不适者被淘汰”,因而适应度大的个体具有较高的生存概率. 通常适应度大的个体具有更适应环境的基因结构,再通过基因重组和基因突变等遗传操作,就可能产生更适应环境的后代. 进化算法的这种自组织、自适应特征,使它同时具有能根据环境变化来自动发现环境的特性和规律的能力. 自然选择消除了算法设计过程中的一个最大障碍,即需要事先描述问题的全部特点,并要说明针对问题的不同特点算法应采取的措施.因此,利用遗传算法,我们可以解决那些复杂的非结构化问题.(2)遗传算法的本质并行性. 遗传算法按并行方式搜索一个种群数目的点,而不是单点. 它的并行性表现在两个方面,一是遗传算法是内在并行的( inherent paralleli sm),即遗传算法本身非常适合大规模并行. 最简单的并行方式是让几百甚至数千台计算机各自进行独立种群的演化计算,运行过程中甚至不进行任何通信(独立的种群之间若有少量的通信一般会带来更好的结果),等到运算结束时才通信比较,选取最佳个体.这种并行处理方式对并行系统结构没有什么限制和要求,可以说,遗传算法适合在目前所有的并行机或分布式系统上进行并行处理,而且对并行效率没有太大影响. 二是遗传算法的内含并行性. 由于遗传算法采用种群的方式组织搜索,因而可同时搜索解空间内的多个区域,并相互交流信息. 使用这种搜索方式,虽然每次只执行与种群规模N成比例的计算,但实质上已进行了大约O(N3)次有效搜索,这就使遗传算法能以较少的计算。
基于机器学习算法的分类器设计与优化在当今大数据时代,机器学习算法的应用变得越来越广泛。
其中,分类器是一个重要的工具,用于对数据进行分类和预测。
分类器的性能往往取决于其设计和优化。
本文将探讨基于机器学习算法的分类器设计和优化的相关内容。
一、分类器的概述分类器是一种机器学习算法,用于将数据集划分为不同的类别或标签。
分类器通过学习数据的特征和模式,可以对新的未标记数据进行分类预测。
常见的分类器算法包括朴素贝叶斯、支持向量机、决策树、随机森林等。
二、分类器设计的关键步骤1. 数据预处理在设计分类器之前,需要对数据进行预处理。
这包括数据清洗、缺失值处理、特征选择和转换等。
数据预处理的目的是使原始数据适合分类器算法的要求,以提高分类器性能。
2. 特征提取与选择特征提取和选择是分类器设计的关键步骤之一。
合适的特征可以提取数据的关键信息,以区分不同的类别。
常用的特征提取方法包括主成分分析(PCA)、线性判别分析(LDA)等。
特征选择则是从大量的候选特征中选择出最具代表性的特征,以避免过拟合和降低计算复杂度。
3. 模型选择选择适合数据集的分类器模型是分类器设计的重要环节。
不同的分类器模型有不同的假设和适应性,因此需要根据问题的特点选择最合适的模型。
比如,在处理高维数据时,支持向量机可能更为适用;而在处理大规模数据时,随机森林可能更为高效。
三、分类器优化的方法1. 参数调优分类器的性能可以通过调整其参数来进行优化。
每个分类器模型都有一系列的参数,通过优化这些参数可以改善分类器的性能。
例如,在朴素贝叶斯算法中,可以调整平滑参数;在支持向量机中,可以调整核函数和惩罚参数。
2. 数据增强数据增强是一种常用的分类器优化方法。
通过扩充训练数据集,可以增加分类器的鲁棒性和泛化能力。
数据增强的方法包括样本复制、样本生成和样本插值等。
3. 集成学习集成学习是一种有效的分类器优化方法,它通过组合多个分类器的预测结果来提升分类性能。
常用的集成学习方法包括投票法、平均法、堆叠法等。
基于算法的分类器设计与特征选择的关系在机器学习领域中,分类是一项重要的任务,而算法的分类器设计和特征选择是分类问题中必不可少的步骤。
本文将探讨基于算法的分类器设计与特征选择之间的关系,以及它们在提高分类性能方面的作用。
一、算法的分类器设计算法的分类器设计是指通过使用不同的算法模型来进行分类任务。
常见的分类器包括决策树、朴素贝叶斯、支持向量机、神经网络等。
不同的算法分类器具有各自的特点和适用场景。
1. 决策树分类器决策树是一种基于树形结构的分类模型,它通过判断多个特征来对样本进行分类。
决策树分类器的设计可以根据特征的信息增益或基尼系数进行选择分裂特征,以达到最优的分类效果。
2. 朴素贝叶斯分类器朴素贝叶斯分类器是基于贝叶斯定理和特征条件独立性假设的分类算法。
它通过计算样本在每个类别下的条件概率来进行分类。
在设计朴素贝叶斯分类器时,需要估计每个特征在各个类别下的概率分布。
3. 支持向量机分类器支持向量机是一种二分类模型,它通过在特征空间中找到一个最优超平面来进行分类。
在支持向量机分类器的设计中,需要选择合适的核函数和调整正则化参数,以实现最佳的分类性能。
4. 神经网络分类器神经网络是一种模拟人脑神经元网络的分类模型,它通过多个神经元之间的连接和激活函数来进行分类。
神经网络分类器的设计中,需要选择合适的网络结构和调整参数,以优化分类性能。
二、特征选择的作用特征选择是指从原始特征集中选择一部分特征用于分类任务。
特征选择的目的是提高分类性能,减少特征维度和复杂性。
特征选择可以基于过滤、包装或嵌入等方法进行。
1. 过滤式特征选择过滤式特征选择是在特征选择和分类器训练之间进行的独立步骤。
它通过评估特征与类别之间的相关性来选择最相关的特征。
常用的过滤式特征选择方法包括方差选择、互信息和相关系数等。
2. 包装式特征选择包装式特征选择是将特征选择视为一个优化问题,将分类器的性能作为评价指标来进行特征选择。
它通过反复训练不同的特征子集,并评估分类器的性能来选择最佳的特征子集。