回归分析案例
- 格式:ppt
- 大小:492.50 KB
- 文档页数:18

相关和回归的有趣案例
相关和回归是统计学中的重要概念,用于探索变量之间的关系。
以下是一些有趣的相关和回归案例:
1. 身高和体重:这是一个常见的相关和回归的例子。
一般来说,身高和体重之间存在正相关关系,即身高越高的人通常体重也越重。
通过回归分析,我们可以更精确地预测一个人的体重,给定其身高。
2. 考试分数和努力学习:这是一个典型的线性回归的例子。
一般来说,考试分数和努力学习之间存在正相关关系,即努力学习的人通常考试分数也更高。
通过回归分析,我们可以预测一个人在考试中的表现,给定其努力学习的程度。
3. 股票价格和通货膨胀:股票价格和通货膨胀之间可能存在一定的关系。
当通货膨胀率上升时,股票价格可能会下跌,因为通货膨胀可能导致消费者购买力下降,从而降低对商品和服务的消费需求,进而影响公司的盈利和股票价格。
4. 气候变化和冰川融化:气候变化和冰川融化之间存在相关性。
全球气候变暖可能导致冰川融化,因为温度升高会导致冰川融化。
通过分析气候变化和冰川融化的数据,我们可以更好地了解全球气候变化的趋势和影响。
5. 广告投入和销售额:广告投入和销售额之间可能存在一定的关系。
一般来说,广告投入越多,销售额也可能越高。
通过回归分析,我们可以预测销售额,给定广告投入的金额。
这些案例表明,相关和回归分析可以帮助我们更好地理解数据之间的关系,并为预测、决策提供有用的信息。

一般线性回归分析案例1、案例为了研究钙、铁、铜等人体必需元素对婴幼儿身体健康的影响,随机抽取了30个观测数据,基于多员线性回归分析的理论方法,对儿童体内几种必需元素与血红蛋白浓度的关系进行分析研究。
这里,被解释变量为血红蛋白浓度(y),解释变量为钙(ca)、铁(fe)、铜(cu)。
表一血红蛋白与钙、铁、铜必需元素含量(血红蛋白单位为g;钙、铁、铜元素单位为ug)case y(g)ca fe cu1 7.00 76.90 295.30 0.8402 7.25 73.99 313.00 1.1543 7.75 66.50 350.40 0.7004 8.00 55.99 284.00 1.4005 8.25 65.49 313.00 1.0346 8.25 50.40 293.00 1.0447 8.50 53.76 293.10 1.3228 8.75 60.99 260.00 1.1979 8.75 50.00 331.21 0.90010 9.25 52.34 388.60 1.02311 9.50 52.30 326.40 0.82312 9.75 49.15 343.00 0.92613 10.00 63.43 384.48 0.86914 10.25 70.16 410.00 1.19015 10.50 55.33 446.00 1.19216 10.75 72.46 440.01 1.21017 11.00 69.76 420.06 1.36118 11.25 60.34 383.31 0.91519 11.50 61.45 449.01 1.38020 11.75 55.10 406.02 1.30021 12.00 61.42 395.68 1.14222 12.25 87.35 454.26 1.77123 12.50 55.08 450.06 1.01224 12.75 45.02 410.63 0.89925 13.00 73.52 470.12 1.65226 13.25 63.43 446.58 1.23027 13.50 55.21 451.02 1.01828 13.75 54.16 453.00 1.22029 14.00 65.00 471.12 1.21830 14.25 65.00 458.00 1.0002、回归分析表2 变量说明表输入/移去的变量a模型输入的变量移去的变量方法1 cu, fe,ca b. 输入a. 因变量: yb. 已输入所有请求的变量。

logistic回归分析案例Logistic回归分析案例。
Logistic回归分析是一种常用的统计分析方法,主要用于预测二分类或多分类的结果。
在实际应用中,Logistic回归分析可以帮助我们理解影响某一事件发生的因素,以及对事件发生的概率进行预测。
本文将通过一个实际的案例来介绍Logistic回归分析的应用。
案例背景。
假设我们是一家电商公司的数据分析师,现在我们需要分析用户的购买行为,并预测用户是否会购买某一产品。
我们收集了一些用户的个人信息和他们最近一次购买的产品,希望通过这些数据来预测用户是否会购买新产品。
数据准备。
首先,我们需要收集用户的个人信息和购买行为数据。
个人信息包括年龄、性别、职业等;购买行为数据包括购买的产品类型、购买时间等。
在收集完数据后,我们需要对数据进行清洗和预处理,包括缺失值处理、异常值处理等。
模型建立。
在数据准备完成后,我们可以开始建立Logistic回归模型。
首先,我们需要将数据划分为训练集和测试集,以便对模型进行验证。
然后,我们可以利用训练集来拟合Logistic回归模型,并利用测试集来评估模型的预测效果。
模型评估。
在模型建立完成后,我们需要对模型进行评估。
常用的评估指标包括准确率、精确率、召回率等。
这些指标可以帮助我们判断模型的预测效果,并对模型进行调优。
模型应用。
最后,我们可以利用建立好的Logistic回归模型来预测用户是否会购买新产品。
通过输入用户的个人信息和购买行为数据,模型可以给出用户购买新产品的概率,从而帮助我们进行精准营销和推广。
结论。
通过以上实例,我们可以看到Logistic回归分析在预测用户购买行为方面具有很好的应用价值。
通过收集用户数据、建立模型、评估模型和应用模型,我们可以更好地理解用户行为,并做出更精准的预测和决策。
总结。
Logistic回归分析是一种强大的统计工具,可以帮助我们预测二分类或多分类的结果。
在实际应用中,我们可以根据具体情况收集数据、建立模型,并利用模型进行预测和决策。

回归分析数据案例回归分析是一种用来研究变量之间关系的统计方法,在实际情况中有很多可以应用回归分析的案例。
下面以一个销售数据案例为例,详细介绍回归分析的应用。
某电商公司想要分析广告费用与销售额之间的关系,以便确定是否需要增加广告投入来提高销售额。
公司收集了一年的数据,包括每月的广告费用和销售额。
公司使用回归分析来研究广告费用和销售额之间的关系。
首先,需要确定自变量和因变量。
在这个案例中,广告费用是自变量,销售额是因变量。
然后,利用回归模型拟合数据,得到回归方程。
假设回归方程为:销售额= β0+ β1 * 广告费用其中,β0 是截距,表示在广告费用为 0 时的销售额;β1 是斜率,表示每单位广告费用对销售额的影响。
通过计算回归方程的参数,可以得到具体的值。
接下来,用实际数据计算回归方程的参数。
假设公司收集了一年的数据,总共 12 个月的广告费用和销售额。
通过回归分析软件,可以计算得到β0 和β1 的估计值。
假设计算结果为β0= 1000,表示当广告费用为 0 时,销售额约为 1000;β1 = 2,表示每多投入 1 单位的广告费用,销售额约增加 2。
通过计算回归方程的参数,可以预测未来的销售额。
假设公司计划增加下个月的广告费用为 5000,可以利用回归方程计算出销售额的预测值。
根据回归方程:销售额 = 1000 + 2 * 5000 = 11000预测出下个月的销售额为 11000。
公司还可以利用回归方程来评估广告费用对销售额的影响。
根据回归方程的斜率β1,可以计算出每单位广告费用对销售额的影响。
在这个案例中,β1=2,说明每多投入 1 单位的广告费用,销售额平均增加 2。
通过回归分析,公司可以了解广告费用和销售额之间的关系,判断是否需要增加广告投入来提高销售额。
如果回归方程的斜率显著大于 0,说明广告费用对销售额有显著的正向影响,公司可以考虑增加广告投入。
如果回归方程的斜率接近 0 或者小于 0,说明广告费用对销售额的影响较小或者负面,公司就需要重新评估广告策略。

回归分析是统计学中一种重要的分析方法,它用于探讨自变量和因变量之间的关系。
在实际应用中,回归分析可以帮助我们理解变量之间的相互影响,预测未来的趋势,以及解释一些现象背后的原因。
本文将通过几个实际案例,来解读回归分析在现实生活中的应用。
首先,我们来看一个销售数据的案例。
某公司想要了解广告投入对产品销量的影响,于是收集了一段时间内的广告投入和产品销量数据。
通过回归分析,他们得出了一个线性方程,表明广告投入对产品销量有显著的正向影响。
这个结论使得公司更加确定了增加广告投入的决策,并且在后续的实施中也取得了预期的销售增长。
接下来,我们来看一个医疗数据的案例。
一家医院想要探讨患者的年龄、性别、体重指数等因素对疾病治疗效果的影响。
通过回归分析,他们发现年龄和体重指数与治疗效果呈显著的负相关,而性别对治疗效果影响不显著。
这个研究结果为医院提供了重要的临床指导,使得医生们在治疗过程中更加关注患者的年龄和体重指数,以提高治疗效果。
除此之外,回归分析还可以应用在金融领域。
一家投资机构想要了解各种因素对股票价格的影响,于是收集了大量的股票市场数据。
通过回归分析,他们发现了一些关键的影响因素,比如市场指数、行业风险等,这些因素对股票价格都有一定的影响。
这些结论为投资机构提供了重要的决策参考,使得他们在投资过程中能够更加准确地评估风险和收益。
此外,回归分析还可以用于市场调研。
一家公司想要了解产品价格对销量的影响,于是进行了一次调研。
通过回归分析,他们发现产品价格与销量呈负相关关系,即产品价格越高,销量越低。
这个结论使得公司意识到自己的产品定价策略可能存在问题,于是他们调整了产品价格,并且在后续销售中取得了更好的效果。
总的来说,回归分析在实际生活中有着广泛的应用。
通过对一些案例的解读,我们可以看到回归分析在不同领域中的作用,比如市场营销、医疗、金融等。
通过回归分析,我们可以更加深入地了解变量之间的关系,从而为决策提供科学的依据。

回归分析实验案例数据引言:回归分析是一种常用的统计方法,用于探索一个或多个自变量对一个因变量的影响程度。
在实际应用中,回归分析有很多种,例如简单线性回归、多元线性回归、逻辑回归等。
本文将介绍一个回归分析实验案例,并分析其中的数据。
案例背景:一家汽车制造公司对汽车的油耗进行研究。
他们收集了一些汽车的相关数据,并希望通过回归分析来探究这些数据之间的关系。
数据收集:为了进行回归分析,他们收集了以下数据:1. 汽车型号:不同汽车型号的标识符。
2. 汽车价格:每辆汽车的价格,单位为美元。
3. 汽车速度:以每小时英里的速度来衡量。
4. 引擎大小:汽车引擎的容量大小,以升为单位。
5. 油耗:每加仑汽油行驶的英里数。
数据分析:通过对收集的数据进行回归分析,可以得出以下结论:1. 汽车价格与汽车引擎大小之间存在正相关关系。
即引擎越大,汽车价格越高。
2. 汽车速度与油耗之间呈现负相关。
即速度越高,油耗越大。
3. 汽车引擎大小与油耗之间存在正相关关系。
即引擎越大,油耗越大。
结论:基于以上分析结果,可以得出以下结论:1. 汽车价格受到引擎大小的影响,即引擎越大,汽车价格越高。
这一结论可以帮助汽车制造公司在制定价格策略时做出合理的决策。
2. 汽车速度与油耗之间呈现负相关。
这一结论可以帮助消费者在购买汽车时考虑速度对油耗的影响,从而选择更经济的汽车。
3. 汽车引擎大小与油耗之间存在正相关关系。
这一结论可以帮助汽车制造公司在设计引擎时考虑油耗因素,从而提高汽车的燃油效率。
总结:回归分析是一种有效的统计方法,可以用于探索数据间的关系。
通过对汽车制造公司收集的数据进行回归分析,我们发现了汽车价格、速度和引擎大小与油耗之间的关系。
这些分析结果对汽车制造公司制定价格策略、消费者购车以及提高燃油效率都具有重要的指导意义。

回归分析是一种统计学方法,用于研究自变量和因变量之间的关系。
它可以帮助我们理解和预测变量之间的关联性,对于数据分析和预测具有重要的作用。
在实际应用中,回归分析可以帮助我们解决许多实际问题,比如市场营销、经济预测、医疗研究等领域。
在本文中,我将通过一些案例分析来解读回归分析在实际问题中的应用。
案例一:市场营销假设我们是一家电商平台,我们希望了解用户购买行为与广告投放之间的关系。
我们收集了每位用户的购买金额作为因变量,广告投放金额作为自变量,以及其他可能影响购买行为的因素,比如用户年龄、性别、地理位置等作为控制变量。
通过回归分析,我们可以建立一个模型来预测用户购买金额与广告投放之间的关系。
通过这个模型,我们可以确定投放多少广告才能最大化用户购买金额,以及哪些因素对购买行为有显著的影响。
案例二:经济预测假设我们是一家投资公司,我们希望预测股票价格与宏观经济指标之间的关系。
我们收集了股票价格作为因变量,以及国内生产总值(GDP)、失业率、通货膨胀率等宏观经济指标作为自变量。
通过回归分析,我们可以建立一个模型来预测股票价格与宏观经济指标之间的关系。
通过这个模型,我们可以了解哪些经济指标对股票价格有显著的影响,从而更好地进行投资决策。
案例三:医疗研究假设我们是一家医药公司,我们希望了解药物剂量与治疗效果之间的关系。
我们收集了药物剂量作为自变量,治疗效果作为因变量,以及患者的年龄、性别、疾病严重程度等因素作为控制变量。
通过回归分析,我们可以建立一个模型来预测药物剂量与治疗效果之间的关系。
通过这个模型,我们可以确定最佳的药物剂量,从而更好地指导临床实践。
通过以上案例分析,我们可以看到回归分析在实际问题中的广泛应用。
它不仅可以帮助我们理解变量之间的关系,还可以帮助我们预测未来趋势和制定决策。
当然,回归分析也有一些局限性,比如对数据的假设要求较高,需要充分考虑自变量和因变量之间的因果关系等。
因此,在实际应用中,我们需要结合具体情况,慎重选择合适的回归模型,并进行充分的检验和验证。

一般线性回归分析案例
案例背景:
在本案例中,我们要研究一个公司的运营数据,并探究它们之间的关
联性。
这家公司的运营数据包括:它的营业额(单位:万元)、产品质量
指数(QI)、客户满意度(CSI)和客户数量。
我们的目标是建立营业额
与其他变量之间的关联性模型,来预测公司未来的营业额。
资料收集:
首先,我们需要收集有关营业额、QI、CSI和客户数量的数据,以进
行分析。
从历史记录上可以收集到过去六个月的数据。
数据预处理:
接下来,我们需要对数据进行预处理,可以使用Excel进行格式整理,将数据归类分组,并计算总营业额。
建立模型:
接下来,我们就可以利用SPSS软件来建立一般线性回归模型,模型
表示为:Y=β0+β1X1+β2X2+…+βnXn。
其中,Y代表营业额,X1、
X2…Xn代表QI、CSI和客户数量等因素。
模型检验:
接下,我们要对模型进行检验,确定哪些因素与营业额有关联性,检
验使用R方和显著性检验确定系数的有效性。


案例一:城镇居民收入与支出关系一、研究的目的研究影响各地居民消费水平变动的原因。
影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。
二、模型设定我们研究的对象是各地区居民消费的差异。
居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。
而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较。
所以模型的被解释变量Y选定为“城市居民每人每年的平均消费支出”因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。
因此建立的是某年截面数据模型。
影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况” 、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。
因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。
为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。
作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立的计量经济模型为如下线性模型:Y =1 pX j U i三、估计参数仁建立工作文件首先,双击EViews图标,进入EViews主页。
销售额影响因素XD是一家大型通讯设备生产公司,在我国主要的大中型城市都设有子公司。
张伟最近被提拔为销售部经理。
在即将召开的全国各地子公司负责人会议上,他想让大家清楚地了解影响销售额的相关因素。
于是,从全国各地的子公司中,随机收集了十五个城市子公司的销售额、促销活动投入额和竞争对手销售额的数据。
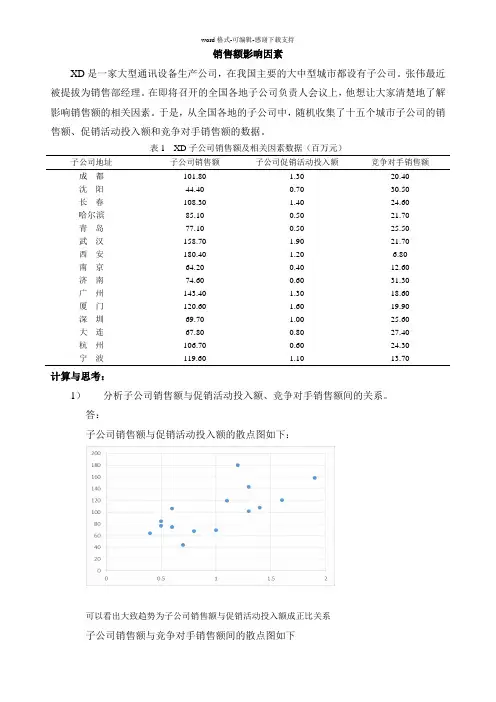
表1 XD子公司销售额及相关因素数据(百万元)子公司地址子公司销售额子公司促销活动投入额竞争对手销售额成都101.80 1.30 20.40沈阳44.40 0.70 30.50长春108.30 1.40 24.60哈尔滨85.10 0.50 21.70青岛77.10 0.50 25.50武汉158.70 1.90 21.70西安180.40 1.20 6.80南京64.20 0.40 12.60济南74.60 0.60 31.30广州143.40 1.30 18.60厦门120.60 1.60 19.90深圳69.70 1.00 25.60大连67.80 0.80 27.40杭州106.70 0.60 24.30宁波119.60 1.10 13.70计算与思考:1)分析子公司销售额与促销活动投入额、竞争对手销售额间的关系。
答:子公司销售额与促销活动投入额的散点图如下:可以看出大致趋势为子公司销售额与促销活动投入额成正比关系子公司销售额与竞争对手销售额间的散点图如下可以看出子公司销售额与竞争对手销售额间成反比关系2)建立子公司促销活动投入额对其销售额的回归方程;解释方程的含义,说明子公司促销活动投入额对其销售额的影响程度;假设某地的子公司促销活动投入额为120万元,预计其销售额及在置信水平95%下的预测区间。
答:设y为销售额,x为促销活动投入额,做回归分析过程如下SUMMARY OUTPUT回归统计Multiple R 0.707693R Square 0.500829Adjusted R Square 0.462431标准误差27.9912观测值15方差分析df SS MS F SignificanceF回归分析 1 10219.42 10219.42 13.04317 0.003161 残差13 10185.59 783.5072总计14 20405.01Coefficients 标准误差t Stat P-value Lower 95% Upper95%下限95.0%Intercept 42.21206 17.93509 2.353601 0.03499 3.465645 80.95847 3.465645 X Variable 1 59.67914 16.5246 3.611532 0.003161 23.9799 95.37837 23.9799子公司促销活动投入额对其销售额的回归方程为:y = 59.679x + 42.212 R² = 0.5008子公司促销活动投入额对其销售额的影响程度:从R² = 0.5008,可以看出回归方程拟合优度不高,子公司促销活动投入额对其销售额的影响程度仅为50%。
回归分析是统计学中一种重要的分析方法,用于探究自变量和因变量之间的关系。
在实际应用中,回归分析常常用于预测、解释和控制变量。
本文将通过几个实际案例,对回归分析进行深入解读和分析。
案例一:销售数据分析某电商平台想要分析不同广告投放对销售额的影响,他们收集了一段时间内的广告投放数据和销售额数据。
为了进行分析,他们利用回归分析建立了一个模型,以广告费用作为自变量,销售额作为因变量。
通过回归分析,他们发现广告费用与销售额之间存在着显著的正相关关系,即广告费用的增加会带动销售额的增加。
通过该分析,电商平台可以更好地制定广告投放策略,优化营销预算,提高销售效益。
案例二:医疗数据分析一家医疗机构收集了一组患者的基本信息、生活习惯以及健康指标等数据,希望通过回归分析来探究生活习惯对健康指标的影响。
他们建立了一个回归模型,以吸烟、饮酒、饮食习惯等自变量,健康指标作为因变量。
通过回归分析,他们发现吸烟和饮酒对健康指标有负向影响,而良好的饮食习惯与健康指标呈正相关关系。
这些发现可以帮助医疗机构更好地进行健康干预和宣教,促进患者的健康改善。
案例三:金融数据分析一家金融机构收集了一段时间内的股票价格、市场指数等数据,希望通过回归分析来探究市场指数对股票价格的影响。
他们建立了一个回归模型,以市场指数作为自变量,股票价格作为因变量。
通过回归分析,他们发现市场指数与股票价格存在着较强的正相关关系,即市场指数的波动会对股票价格产生显著影响。
这些结果可以帮助金融机构更好地进行投资策略的制定和风险控制。
通过以上案例分析,我们可以看到回归分析在不同领域的应用。
回归分析不仅可以帮助人们理解变量之间的关系,还可以用于预测和控制变量。
在实际应用中,我们需要注意回归分析的假设条件、模型选择和结果解释等问题,以确保分析的准确性和可靠性。
在回归分析中,我们需要注意变量选择、模型拟合度和结果解释等问题。
另外,回归分析也有一些局限性,比如无法确定因果关系、对异常值敏感等问题。
多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析;可以建立因变量y与各自变量x j j=1,2,3,…,n之间的多元线性回归模型:其中:b0是回归常数;b k k=1,2,3,…,n是回归参数;e是随机误差;多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量头;x2为4月上、中旬百束小谷草把累计落卵量块;x3为4月中旬降水量毫米,x4为4月中旬雨日天;预报一代粘虫幼虫发生量y头/m2;分级别数值列成表2-1;预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级;预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~毫米为1级,~毫米为2级,~毫米为3级,毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级;表2-1x1 x2 x3 x4 y年蛾量级别卵量级别降水量级别雨日级别幼虫密度级别1960 1022 4 112 1 1 2 1 10 1 1961 300 1 440 3 1 1 1 4 1 1962 699 3 67 1 1 1 1 9 1 1963 1876 4 675 4 4 7 4 55 4 1965 43 1 80 1 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 2 3 2 28 3 1976 115 1 240 2 1 2 1 7 1 1971 718 3 1460 4 4 4 2 45 4 1972 803 3 630 4 3 3 2 26 3 1973 572 2 280 2 2 4 2 16 2 1974 264 1 330 3 4 3 2 19 2数据保存在“”文件中;1准备分析数据在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”和“幼虫密度”变量,并输入数据;再创建蛾量、卵量、降水量、雨日和幼虫密度的分级变量“x1”、“x2”、“x3”、“x4”和“y”,它们对应的分级数值可以在SPSS数据编辑窗口中通过计算产生;编辑后的数据显示如图2-1;图2-1或者打开已存在的数据文件“”;2启动线性回归过程单击SPSS主菜单的“Analyze”下的“Regression”中“Linear”项,将打开如图2-2所示的线性回归过程窗口;图2-2 线性回归对话窗口3 设置分析变量设置因变量:用鼠标选中左边变量列表中的“幼虫密度y”变量,然后点击“Dependent”栏左边的向右拉按钮,该变量就移到“Dependent”因变量显示栏里;设置自变量:将左边变量列表中的“蛾量x1”、“卵量x2”、“降水量x3”、“雨日x4”变量,选移到“IndependentS”自变量显示栏里;设置控制变量: 本例子中不使用控制变量,所以不选择任何变量;选择标签变量: 选择“年份”为标签变量;选择加权变量: 本例子没有加权变量,因此不作任何设置;4回归方式本例子中的4个预报因子变量是经过相关系数法选取出来的,在回归分析时不做筛选;因此在“Method”框中选中“Enter”选项,建立全回归模型;5设置输出统计量单击“Statistics”按钮,将打开如图2-3所示的对话框;该对话框用于设置相关参数;其中各项的意义分别为:图2-3 “Statistics”对话框①“Regression Coefficients”回归系数选项:“Estimates”输出回归系数和相关统计量;“Confidence interval”回归系数的95%置信区间;“Covariance matrix”回归系数的方差-协方差矩阵;本例子选择“Estimates”输出回归系数和相关统计量;②“Residuals”残差选项:“Durbin-Watson”Durbin-Watson检验;“Casewise diagnostic”输出满足选择条件的观测量的相关信息;选择该项,下面两项处于可选状态:“Outliers outside standard deviations”选择标准化残差的绝对值大于输入值的观测量;“All cases”选择所有观测量;本例子都不选;③其它输入选项“Model fit”输出相关系数、相关系数平方、调整系数、估计标准误、ANOVA表;“R squared change”输出由于加入和剔除变量而引起的复相关系数平方的变化;“Descriptives”输出变量矩阵、标准差和相关系数单侧显著性水平矩阵;“Part and partial correlation”相关系数和偏相关系数;“Collinearity diagnostics”显示单个变量和共线性分析的公差;本例子选择“Model fit”项;6绘图选项在主对话框单击“Plots”按钮,将打开如图2-4所示的对话框窗口;该对话框用于设置要绘制的图形的参数;图中的“X”和“Y”框用于选择X轴和Y轴相应的变量;图2-4“Plots”绘图对话框窗口左上框中各项的意义分别为:•“DEPENDNT”因变量;•“ZPRED”标准化预测值;•“ZRESID”标准化残差;•“DRESID”删除残差;•“ADJPRED”调节预测值;•“SRESID”学生氏化残差;•“SDRESID”学生氏化删除残差;“Standardized Residual Plots”设置各变量的标准化残差图形输出;其中共包含两个选项:“Histogram”用直方图显示标准化残差;“Normal probability plots”比较标准化残差与正态残差的分布示意图;“Produce all partial plot”偏残差图;对每一个自变量生成其残差对因变量残差的散点图;本例子不作绘图,不选择;7 保存分析数据的选项在主对话框里单击“Save”按钮,将打开如图2-5所示的对话框;图2-5 “Save”对话框①“Predicted Values”预测值栏选项:Unstandardized 非标准化预测值;就会在当前数据文件中新添加一个以字符“PRE_”开头命名的变量,存放根据回归模型拟合的预测值;Standardized 标准化预测值;Adjusted 调整后预测值;. of mean predictions 预测值的标准误;本例选中“Unstandardized”非标准化预测值;②“Distances”距离栏选项:Mahalanobis: 距离;Cook’s”: Cook距离;Leverage values: 杠杆值;③“Prediction Intervals”预测区间选项:Mean: 区间的中心位置;Individual: 观测量上限和下限的预测区间;在当前数据文件中新添加一个以字符“LICI_”开头命名的变量,存放预测区间下限值;以字符“UICI_”开头命名的变量,存放预测区间上限值;Confidence Interval:置信度;本例不选;④“Save to New File”保存为新文件:选中“Coefficient statistics”项将回归系数保存到指定的文件中;本例不选;⑤“Export model information to XML file”导出统计过程中的回归模型信息到指定文件;本例不选;⑥“Residuals” 保存残差选项:“Unstandardized”非标准化残差;“Standardized”标准化残差;“Studentized”学生氏化残差;“Deleted”删除残差;“Studentized deleted”学生氏化删除残差;本例不选;⑦“Influence Statistics” 统计量的影响;“DfBetas”删除一个特定的观测值所引起的回归系数的变化;“Standardized DfBetas”标准化的DfBeta值;“DiFit” 删除一个特定的观测值所引起的预测值的变化;“Standardized DiFit”标准化的DiFit值;“Covariance ratio”删除一个观测值后的协方差矩隈的行列式和带有全部观测值的协方差矩阵的行列式的比率;本例子不保存任何分析变量,不选择;8其它选项在主对话框里单击“Options”按钮,将打开如图2-6所示的对话框;图2-6 “Options”设置对话框①“Stepping Method Criteria”框用于进行逐步回归时内部数值的设定;其中各项为:“Use probability of F”如果一个变量的F值的概率小于所设置的进入值Entry,那么这个变量将被选入回归方程中;当变量的F值的概率大于设置的剔除值Removal,则该变量将从回归方程中被剔除;由此可见,设置“Use probability of F”时,应使进入值小于剔除值;“Ues F value”如果一个变量的F值大于所设置的进入值Entry,那么这个变量将被选入回归方程中;当变量的F值小于设置的剔除值Removal,则该变量将从回归方程中被剔除;同时,设置“Use F value”时,应使进入值大于剔除值;本例是全回归不设置;②“Include constant in equation”选择此项表示在回归方程中有常数项;本例选中“Include constant in equation”选项在回归方程中保留常数项;③“Missing Values”框用于设置对缺失值的处理方法;其中各项为:“Exclude cases listwise”剔除所有含有缺失值的观测值;“Exchude cases pairwise”仅剔除参与统计分析计算的变量中含有缺失值的观测量;“Replace with mean”用变量的均值取代缺失值;本例选中“Exclude cases listwise”;9提交执行在主对话框里单击“OK”,提交执行,结果将显示在输出窗口中;主要结果见表2-2至表2-4;10 结果分析主要结果:表2-2表2-2 是回归模型统计量:R 是相关系数;R Square 相关系数的平方,又称判定系数,判定线性回归的拟合程度:用来说明用自变量解释因变量变异的程度所占比例;Adjusted R Square 调整后的判定系数;Std. Error of the Estimate 估计标准误差;表2-3表2-3 回归模型的方差分析表,F值为,显著性概率是,表明回归极显著;表2-4分析:建立回归模型:根据多元回归模型:把表6-9中“非标准化回归系数”栏目中的“B”列系数代入上式得预报方程:预测值的标准差可用剩余均方估计:回归方程的显著性检验:从表6-8方差分析表中得知:F统计量为,系统自动检验的显著性水平为;F,4,11值为,F,4,11 值为,F,4,11 值为;因此回归方程相关非常显著;F值可在Excel中用FINV 函数获得;回代检验需要作预报效果的验证时,在主对话框图6-8里单击“Save”按钮,在打开如图3-6所示对话框里,选中“Predicted Values”预测值选项栏中的“Unstandardized”非标准化预测值选项;这样在过程运算时,就会在当前文件中新添加一个“PRE_1”命名的变量,该变量存放根据回归模型拟合的预测值;然后,在SPSS数据窗口计算“y”与“PRE_1”变量的差值图2-7,本例子把绝对差值大于视为不符合,反之则符合;结果符合的年数为15年,1年不符合,历史符合率为%;图2-7多元回归分析法可综合多个预报因子的作用,作出预报,在统计预报中是一种应用较为普遍的方法;在实际运用中,采取将预报因子和预报量按一定标准分为多级,用分级尺度代换较大的数字,更能揭示预报因子与预报量的关系,预报效果比采用数量值统计方法有明显的提高,在实际应用中具有一定的现实意义;。
1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。
年份Y/千克 X/元 P 1/(元/千克)P 2/(元/千克)P 3/(元/千克)年份Y/千克 X/元 -P 1/(元/千克)P 2/(元/千克)P 3/(元/千克)19803971992 —911 1981413《1993931 1982439 ·199410211983 )459 19951165:1984492 19961349 |19855281997%1449 1986560,19981575 1987624 *199917591988 * 666 20001994)198971720012258 )19907682002!24781991843,(1) 求出该地区关于家庭鸡肉消费需求的如下模型:01213243ln ln ln ln ln Y X P P P u βββββ=+++++(2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。
先做回归分析,过程如下:输出结果如下:所以,回归方程为:]123ln 0.73150.3463ln 0.5021ln 0.1469ln 0.0872ln Y X P P P =-+-++由上述回归结果可以知道,鸡肉消费需求受家庭收入水平和鸡肉价格的影响,而牛肉价格和猪肉价格对鸡肉消费需求的影响并不显著。
验证猪肉价格和鸡肉价格是否有影响,可以通过赤池准则(AIC )和施瓦茨准则(SC )。
若AIC 值或SC 值增加了,就应该去掉该解释变量。
去掉猪肉价格P 2与牛肉价格P 3重新进行回归分析,结果如下:,Variable Coefficient Std. Error t-Statistic% Prob. ]CLOG(X)、LOG(P1)!R-squared Mean dependent var:Adjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid —Schwarz criterionLog likelihood F-statisticDurbin-Watson stat Prob(F-statistic)}…通过比较可以看出,AIC值和SC值都变小了,所以应该去掉猪肉价格P2与牛肉价格P3这两个解释变量。
实验课程案例数据1香烟消费数据:一个国家保险组织想要研究在美国所有50个州和哥伦比亚特区的香烟消费模式,表1给出了研究中所选的变量,表2给出了1970年的数据。
讨论以下问题:表1. 香烟消费数据的变量表2. 香烟消费数据〔1970年〕州年龄HS 收入黑人比例女性比例价格销量AL272948AK46443AZ36653AR2878CA44937123CO38553CT5649176120DE4524155DC5079FL3738GA3354HI254623148ID3290IL4507IN3772IO593751KA385351114KY3112LA3090ME283302MD4309MA29434041MI418051MN385951MS412626MO3781MT350050NB3789NV456344NH283737NJ4701NM307790NY4712119NC325251ND3086OH4020OK3387OR296037195129157PA3971852RI3959SC2990SD3123TN3119TX36065142UT3227VT3468V A3712WA4053WV303061WI3812WY381550(1)在销量关于6个自变量的回归模型中,检验假设“不需要女性比例这一变量〞;(2)在上面的模型中,检验假设“不需要女性比例和HS这两个变量〞;(3)计算收入变量回归系数的95%的置信区间;(4)去掉收入这个变量后拟合回归方程,其他变量对于销量的解释比例是多少?(5)用价格、年龄和收入作自变量拟合模型,它们对销量的解释比例是多少?(6)仅用收入作自变量拟合模型,它们对销量的解释比例是多少?(7)(8)【本文档内容可以自由复制内容或自由编辑修改内容期待你的好评和关注,我们将会做得更好】(9)(10)。
第四次案例分析----相关回归分析案例1 对某地的12个乡镇的饮水氟含量及中老年人群的骨关节炎患病情况作了调查,数据如下表10-12,初步发现不同乡镇的骨关节炎的患病率高低与本地区饮水的氟含量有关。
于是把氟含量视为变量X,把骨关节炎患病率视为Y,计算出Pearson积矩相关系数,得r=0.827,经检验P<0.01,据此认为骨关节炎的患病率与饮水的氟含量之间有正相关关系。
表10-12 某地12个乡镇饮水氟含量与骨关节炎患病率序号氟含量患病率(mg/L))(%)1 1.20 7.52 0.35 8.93 2.50 9.04 3.18 12.65 0.75 8.26 5.92 15.47 7.97 20.38 2.06 10.19 7.05 30.310 5.30 24.211 3.52 7.512 1.50 10.3讨论:(1)作者以上结论是否正确?原因是什么?(2)线性相关分析的适用条件是什么?如何验证其适用条件?(3)应如何进行分析?本分析方法的适用条件是什么?案例2回顾第八章例8-3,用三种不同药物治疗慢性支气管炎,治疗结果见表10-13所示。
表10-13 三种不同药物治疗慢性支气管炎的疗效第八章曾做过2χ检验,得232.736,0.005pχ=<,按0.05水准,可以认为三种药物治疗效果有效的总体概率有差别。
研究者认为,既然不同药物组有不同的治疗效果,则治疗效果与不同的药物治疗方法必定有关联;其关联的程度可用列联系数来描述:r===0.493讨论:(1)该推理和计算是否正确?(2)应当如何研究治疗效果和药物种类的关联性?案例3现有一份170例某病患者的治疗效果资料,按年龄和疗效两种属性交叉分类,结果见表10-14.ν=,拒绝两种属性分类相互作者进行了独立性2χ检验,得到2χ=23.582,4r==,结论独立的零假设;进一步计算Pearson列联系数r为0.35是疗效和年龄间存在关联性。
《统计学》案例——相关回归分析案例一质量控制中的简单线性回归分析1、问题的提出某石油炼厂的催化装置通过高温及催化剂对原料的作用进行反应,生成各种产品,其中液化气用途广泛、易于储存运输,所以,提高液化气收率,降低不凝气体产量,成为提高经济效益的关键问题。
通过因果分析图和排列图的观察,发现回流温度是影响液化气收率的主要原因,因此,只有确定二者之间的相关关系,寻找适当的回流温度,才能达到提高液化气收率的目的。
经认真分析仔细研究,确定了在保持原有轻油收率的前提下,液化气收率比去年同期增长1个百分点的目标,即达到12.24%的液化气收率。
2、数据的收集序号回流温度(℃)液化气收率(%)序号回流温度(℃)液化气收率(%)1 2 3 4 5 6 7 8 9 10 11 12 13 14 1536 39 43 43 39 38 43 44 37 40 34 39 40 41 4413.1 12.8 11.3 11.4 12.3 12.5 11.1 10.8 13.1 11.9 13.6 12.2 12.2 11.8 11.116 17 18 19 20 21 22 23 24 25 26 27 28 29 3042 43 46 44 42 41 45 40 46 47 45 38 39 44 4512.3 11.9 10.9 10.4 11.5 12.5 11.1 11.1 11.1 10.8 10.5 12.1 12.5 11.5 10.9目标值确定之后,我们收集了某年某季度的回流温度和液化气收率的30组数据(如上表),进行简单直线回归分析。
3.方法的确立设线性回归模型为εββ++=x y 10,估计回归方程为x b b y10ˆ+= 将数据输入计算机,输出散点图可见,液化气收率y 具有随着回流温度x 的提高而降低的趋势。
因此,建立描述y 和x 之间关系的模型时,首选直线型是合理的。
从线性回归的计算结果,可以知道回归系数的最小二乘估计值b 0=21.263和b 1=-0.229,于是最小二乘直线为x y229.0263.21ˆ-= 这就表明,回流温度每增加1℃,估计液化气收率将减少0.229%。