SPSS复习资料
- 格式:docx
- 大小:47.50 KB
- 文档页数:6

SPSS练习题1.某种生产浴皂过程的设计规格为每批平均生产120块肥皂。
超过或低于这个标准都是不合理的。
有10批产品组成的样本中,每批生产的产品数据如下,假定总体服从正态分布。
108 118 120 122 119 113 124 122 120 123显著性水平为α=0.05,检验该样本结果能否表示该生产过程运作正常?解:这是一个单样本的T检验过程,设总体生产的产品数量平均值为μ,提出原假设H0=120。
Analyze→Compare Means→One-Sample T Test命令。
One-Sample Test结果显示,t统计量值为-0.705,相应的双尾显著性概率为0.498>0.05,因此没有理由拒绝原假设。
故认为据此样本数据推断总体,结果表示该生产过程运作正常。
2.公路损失数据研究机构的伤害和碰撞损失实验报告根据事故后的保险索赔数字对轿车型号进行评分,接近100的指数得分被认为是平均水平,较低的得分意味着更好、更安全的轿车型号。
下表所示数据是20款中型轿车和20型小型轿车的得分。
分析要点:(1)分别作出中型和小型轿车的五数概括(2)画出箱线图,并说明以上的汇总里关于中型轿车和小型轿车安全性的比较结果(3)进一步使用独立样本T检验比较中型轿车和小型轿车安全性解:(1)所谓的五数是指:最小值、25%下四分位数、50%的中位数、75%上四分位数和最大值。
首先对数据文件进行拆分,即按车型进行分组。
Data→Split File→Organize output by groups;Analyze→Descriptive Statistics→Frequencies,在Statistics对话框中选中Percentile Values栏目下的Quartiles复选框,并选中Dispersion栏目下的Minimum和Maximum两项,在Frequencies对话框中,单击OK按钮。
Statistics(a)小型a 车型= 小型Statistics(a)中型a ³µÐÍ = ÖÐÐÍ从结果可以看出:小型轿车得分的最小值73,25%的下四分位数为100.5,中位数为108.5,75%的上四分位数为121.5,最大值为140。

SPSS 四种输出结果:枢轴表/ 轻量表、文本格式、统计图表、模型SPSS 四种窗口:语法窗口、输出窗口、数据窗口、脚本窗口SPSS 三种运行方式:命令行方式、批程序方式、菜单对话框SPSS 默认文件类型:数据文件*.sav :此为SPSS 软件默认的数据文件格式,双击可由SPSS 直接读取。
命令文件*.sps :可在语法编辑程序(syntax)中先编写或贴上欲执行之分析指令,并将其存贮起来,供日后重复使用或检查之用。
输出文件 *.spo:允许直接加以编辑或转贴到其他编辑软件,SPSS 16.0版之后将输出文件的默认格式改为*.spv 。
数据文件清洗——多余重复的数据筛选清楚,将确实的数据补充完整,将错误的数据纠正或删除。
数据→标识重复个案标识异常个案问题的答案被称作变量的取值。
将答案转变成可用于统计分析的数据,需要经过一个被称作“编码 coding”的过程。
数据阵 / 数据文件: n 个案例、 m 个变量构成的阵列SPSS 对数据的处理是以变量为基础的。
所以,数据录入前一定先定义变量及其属性,包括指定名称、(存储)类型、宽度、小数、标签、值、缺失、列(宽)、对齐、度量标准和角色。
这也被称作建立数据框架。
变量名必须以字母、汉字或字符@ 开头,数字不可以,其他字符可以是任何字母、数字或_、@、# 、$ 等符号。
变量名中不能有空白字符或其他特殊字符(如“!”、“?” 、“ *”等)。
变量名最后一个字符不能是英文句号(.)。
在 SPSS 中不区分大小写。
例如, HXH 、hxh 或 Hxh 对 SPSS 而言,均被视为同一个变量。
SPSS 的保留字不能作为变量的名称,如ALL 、AND 、BY、EQ、 GE、GT 、LT、NE 、NOT 、OR 、 TO 、WITH 等。
SPSS 中变量有 3 种基本类型:数值型、字符型(区分大小写)和日期型。
但根据不同的显示方式,数值型又被区分成:数值、逗号、圆点、科学计数法、美元、(用户)设定货币等 6 个子类型。

SPSS复习1.变量标签和变量值标签的含义答:变量标签就是变量的解释说明,变量值标签是对变量与实际意义的翻译。
可以使数据显示和分析结果更直观。
2.多选题的录入:多重二分法:在编码的时候,对应每一个选项都要定义一个变量,有几个选项就有几个变量,这些变量均为二分类(二分类变量指该变量只有两个取值,“选中”和“未选”),它们各自代表对一个选项的选择结果。
该方法会出现很多数据为0的现象,录入数据工作量大。
多重分类法(适合选项较多的情况):利用多个变量来对一个多选题的答案进行定义,实际需用多少个变量,由被访者实际可能给出的最多答案而定。
每个变量都有同一套值和值标签(演示)含有“其它,请指出”答案的附加内容的问题,也是先把“其它,请指出”作为问题的一个答案选项,而用另一个变量来表示“其它,请指出”的内容。
在数据录入完毕后再对附加内容根据频次高低进行编码,以进行更为深入的分析。
3.Recode和Automatic Recode有何区别?答:Recode为变量重新编码命令,Automatic Recode为自动重新编码命令。
两者的区别是:Automatic Recode命令是SPSS系统自动设定码为正整数,而Recode可以根据用户的需要指定特别的码值。
4.记录排序和变量编秩(Rank cases)的区别“记录排序”和前面的“变量编秩”不同,“变量编秩”排序后为在数据窗口建立一个新的变量来保存。
并且“记录排序” 可以对多个变量进行,而“变量编秩” 只能对一个变量进行。
5.数据分类汇总分类汇总:按指定的分类变量对观测值进行分组,对每组记录的各变量求指定的描述统计量,结果可以存入新数据文件,也可以替换当前数据文件.分类汇总产生的SPSS数据文件的记录数取决于分类变量的取值个数.多重分类汇总:文件的记录数等于各分类变量类别数的乘积;第一个为主分类变量,其他的依次为第二,第三分类变量。
步骤一:指定分类变量(Break Variables)和汇总变量(Aggregate Variables)步骤二:SPSS自动根据分类变量的取值将记录数据分成若干类,并对每类记录分别计算汇总变量的描述统计量.步骤三:将分类汇总的计算结果保存到一个SPSS数据文件中.6.数据转置(transpose):创建一个新的数据文件,原文件中的行列被转置,使个案(行)成为变量,变量(列)成为个案。

SPSS复习资料国贸1105朱浩1、SPSS的几种基本运行方式:菜单操作方式, 程序运行方式, Include运行方式, Production Facility方式P112、SPSS的5个窗口:数据编辑窗口,结果管理窗口,结果编辑窗口,语法编辑窗口,脚本窗口。
结果管理窗口:也称为结果视图或者结果浏览器,用于存放SPSS软件的分析结果。
整个窗口分为两个区:左边为目录区,是SPSS分析结果的目录;右边是内容区,显示与目录对应的内容。
3、数据管理的特点:SPSS数据编辑器的每一行数据称为一个个案或记录,每一列数据代表个体的属性。
P264、SPSS数据编辑器的2个界面及特点:数据视图界面和变量视图界面. P28数据视图界面的数据编辑区是数据的信息;数据视图可执行工具栏的操作;数据视图左边显示单元格和单元格所在列的变量名,右边显示单元格的内容。
变量视图的数据编辑区是变量的信息;变量试图界面不含编辑区选择栏。
5、变量视图的属性及其作用:P32变量的名称:给出变量或者属性的名称。
变量类型:选择变量的显示方式.a.数值型.常见的尺度变量。
默认的数值宽度为8,小数位为2b.逗号:整数部分用逗号分隔的数值。
在整数部分,从个位算起,每三位数一个逗号,小数点仍然为“.”c.点: 整数部分用点分隔的数值。
在整数部分,从个位算起,每三位数用一个点分隔.小数点为”,”d.科学计数法:表示数值型数据e.日期:显示格式格式为dd-mmm-yyyy;mm/dd/yyyy。
f.美元:数据前有美元符号。
可以选择具体数据的呈现方式g.设定货币:选用客户设定的货币格式。
方法为【编辑】→【选项】→选择“货币标签”h.字符串:由英文字母和数字组成,在输入数据时不应输入双引号变量宽度:对字符型变量,决定能输入的字符串的长度小数位的宽度:设定小数位的宽度变量标签:对变量名含义的进一步解释说明列:设定变量数据视图中列的宽度对齐方式:列数据的对齐方式变量宽度类型:设定变量度量标准,有度量、序号、名义三种选择6、SPSS的文件格式:扩展名为.sav P367、读入数据的3种类型及其方法:P38 P45 P51读入Excel数据:【文件】→【打开】→【数据】→文件类型选Excel→双击.xls 在SPSS 读入Excel文件时,必须先关闭要读的Excel数据文件,否则读入时会报告错误。

第一章SPSS统计分析系统软件简介1)SPSS的几种基本运行方式:①菜单操作方式:这种方法图形用户界面友好、操作简单、形象直观,能够一步步引导用户完成对数据的描述和模型的建立。
②程序运用方式:是在Syntax编辑窗口输入程序。
也可以用任何文本编辑器中输入,也可以在相应菜单操作的对话框中,用“Paste”按钮可以把相应的操作转化为Syntax语言。
选择所有的语法命令行,单击“Run”运行程序。
或者在SPSS的语法编辑器窗口输入语法。
③ Include运行方式:在编写Syntax命令中,如果要调用其他语法文件时,除了复制粘贴现有的资源外,还可以用Include的命令。
④ Production Facility方式:Production Facility生产作业方式提供了以自动化方式运行SPSS Statistics 的功能。
2)SPSS界面提供的五个窗口:①数据编辑窗口:这个窗口主要用来处理数据和定义数据字典,它分为两个视图。
一个是用来显示数据的数据视图(数据视图用来显示数据集中的记录或个案),另外一个是变量视图(变量视图的功能是定义数据集的数据字典)。
②结果管理窗口:也称为结果视图或者结果浏览器,该窗口用于存放SPSS软件的分析结果。
分为左边目录区,是SPSS分析结果的目录;右边是内容区,显示与目录相应的内容。
③结果编辑窗口:是编辑分析结果的窗口。
选中要编辑的内容,双击或者点击右键选择“编辑内容”,选中的图形就会出现在“图表编辑器”中,可以开始编辑。
④语法编辑窗口:语法编程方式,能够完成窗口操作所能完成的所有任务,还可以完成许多窗口操作所不能完成的其他工作。
在这个窗口中,还可以调用开源软件R中的任何程序。
⑤脚本窗口:是用Sax Basic 语言编写的程序。
脚本可以使SPSS内部操作自动化,可以自定义结果格式,可以连接VB和VBA应用程序。
第二章数据文件的建立和管理1)数据管理的特点:数据编辑器的每一行数据称为一个个案,每一列数据代表个体属性,即变量。

第一章:简介变量名首字母必须是中文或字母,不能与保留字相同,保留字:ALL、AND、BY、EQ、GE、GT、LE、LT、NE、NOT、OR、TO、WITH。
String字符型变量,不能进行运算。
Ordinal顺序数据。
排序:Data--Sort Cases转置:Data—Transpose(字符串变量不能转置)第二章:统计描述(只报告表格)频数分布表分析:Analyze---Descriptive Statistics---Frequencies(只有这个可以做频次表)V 方差、R全距、S.E.标准误、Skewness偏度系数、Kurtosis峰度系数。
描述过程:Analyze---Descriptive Statistics----Descriptives(特点是可将原始数据转换成标准评分值,以变量的形式存入数据库供以后分析)平均数分析:Analyze---Compare Means---Means(分组数据分别求某东西的平均数和方差等)第三章:相关分析(报告r、p,结论)六种相关:强正相关、弱正相关、强负相关、弱负相关、非线性相关、不相关(*有95%把握, **有99%把握)二元相关:Analyze---Correlate---Bivariate先做出散点图:Graphs---Scatter(散点图越接近圆,r≈0)为线性再进行相关分析。
Pearson积差相关:连续变量或是等间距变量间的相关分析Spearman等级相关:顺序数据(身高和体重的相关)Kendall等级相关:分列变量间的秩相关(十人的作文,两位老师评价,分析评价是否一致)双尾检验:不知道相关方向(正相关还是负相关)相关系数为0的概率单尾检验:知道相关方向Flag significant Correlations:相关系数右上用*表示显著水平为5%,用**表示显著水平为1% 报告:从上图可知,X和Y呈线性关系,可以进行XX相关分析。

SPSS复习资料一.名词解释(1)有效百分比:总数是剔除可缺失值等过滤因素的百分比.无效假设:是指没有处理效应的假设。
统计量:从样本中计算所得的数值称为统计量。
准确性:指在调查或试验中某一实验指标或性状的重复观测值与真值的接近程度。
方差:各个数据分别与其平均数之差的平方的和的平均数。
相关系数:用以反映变量之间相关关系密切程度的统计指标自由度:自由度指的是计算某一统计量时,取值不受限制的变量个数。
标准差:是方差的算术平方根,反应一个数据集的离散程度。
似然比:反映真实性的一种指标,属于同时反映灵敏度和特异度的复合指标。
卡平方定义:相互独立的多个正态离差平方值的总和。
无效假设:是指没有处理效应的假设。
个案加权:是指对变量,特别是频数变量赋以权重,常用于计数频数表资料,加权后的变量被说明为频数卡方统计量:是指数据的分布与所选择的预期或假设分布之间的差异的度量。
相关分析:相关分析是研究两个或两个以上处于同等地位的随机变量间的相关关系的统计分析方法非参数分析:非参数检验是在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态等进行推断的方法回归分析:指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
卡方检验:非参数检验检验的一种方法,来检验变量的几个取值所占百分比是否和期望的比例有统计学差异。
统计描述:对统计数据集的结构和总体情况进行描述,并不能深入了解统计数据的内部规律。
卡方测验的基本步骤:1.提出假设2.计算卡平方值3.确定显著水平4.确定最后结果单因素方差分析:单因素方差分析测试某一个控制变量的不同水平是否给观察变量造成了显着差异和变动聚类分析:根据事物本身的特征研究个体分类的方法,聚类分析的原则是同一类中的个体有较大的相似性,不同类中的个体差异很大两个相关样本检验:同一个被测对象上测试两个或多个观测值的情况,这样的数据间就不再是相对独立的了,而是彼此相关,这种情况采用两个相关样本检验Ks,检验:检验样本来自正态分布均匀分布或泊松分布,总体的假设游程检验:根据由陈述所做的两分变量的随机性检验简答题1在SPPS中可以使用哪些方法输入数据?(1)通过手工录入数据;(2)可以将其他电子表格软件中的数据整列(行)的复制,然后粘贴到SPSS中;(3)通过读入其他格式文件数据的方式输入数据。

spss期末复习资料SPSS期末复习资料SPSS(Statistical Package for the Social Sciences)是一款广泛应用于社会科学领域的统计分析软件,其强大的功能和易于使用的界面使其成为许多研究人员和学生的首选工具。
在期末考试前夕,为了帮助大家更好地复习SPSS相关知识,本文将提供一些有关SPSS的复习资料和技巧。
1. SPSS的基本操作在使用SPSS进行数据分析之前,我们首先需要了解SPSS的基本操作。
首先,我们需要学会如何导入数据,可以通过直接输入数据或者导入外部文件的方式。
其次,我们需要了解如何对数据进行整理和清洗,包括删除重复数据、处理缺失值等。
最后,我们需要掌握如何进行基本的统计分析,例如描述性统计、频数分析等。
2. SPSS的数据处理与转换SPSS提供了丰富的数据处理和转换功能,可以帮助我们更好地分析数据。
例如,我们可以使用SPSS进行数据的排序和筛选,以便更好地理解数据的分布情况。
此外,我们还可以使用SPSS进行数据的变量转换,例如创建新变量、计算变量等,以满足我们的分析需求。
3. SPSS的统计分析SPSS作为一款统计分析软件,提供了丰富的统计分析方法,可以帮助我们深入挖掘数据背后的规律。
例如,我们可以使用SPSS进行相关分析,以了解变量之间的相关性。
另外,我们还可以使用SPSS进行回归分析,以探究变量之间的因果关系。
此外,SPSS还支持多种假设检验方法,例如t检验、方差分析等,以帮助我们进行统计推断。
4. SPSS的数据可视化数据可视化是数据分析的重要环节,它可以帮助我们更好地理解数据的分布和趋势。
SPSS提供了丰富的数据可视化方法,例如直方图、散点图、折线图等。
通过使用这些图表,我们可以直观地展示数据的特征,并发现其中的规律和异常情况。
5. SPSS的报告输出在完成数据分析后,我们需要将结果整理成报告,以便向他人展示我们的研究成果。
SPSS提供了报告输出的功能,可以将分析结果导出为Word、Excel等格式。

教育统计与测量(SPSS)复习第一章:概述1.什么是信息?简单地讲,通过信息,可以告诉我们某件事情,可以使我们增加一定的知识。
英语中的信息是“information”,表示信息可以让受者产生某种形式的变化,这种变化可以让受者从认识上的不完全、不理解、不确定变为完全、理解和确定。
信息论的奠基者香农将信息定义为熵的减少,即信息可以消除人们对事物认识的不确定性,并将消除不确定程度的多少作为信息量的量度。
信息的价值因人而异。
所谓有用的信息,因人而异。
是否是信息,不是由传者,而是由受者所决定。
2.教育信息数量化的特点表示教育信息的数量与各种物理测量的数量有着明显的不同,在教育信息的统计处理中,应根据教育信息数量化的方法、特点不同,决定对这种信息进行统计处理的具体方法。
这是进行教育信息处理的重要关键。
3.教育信息数量化的尺度(1)名义尺度(nominal scale) :名义尺度的数值仅具符号的意义。
名义尺度的数字多用于表示不同的数别,它为教育信息的表示,存贮带来了很大的方便。
(2)序数尺度(ordinal scale) :序数尺度的数字多用于表示某些现象的排列顺序,可比较其大小,但不能进行四则运算,所以对这类数字的数值群的处理较多。
(3)距离尺度(interval scale,equal unit scale):距离尺度又称间隔尺度,是指数值间的距离(间隔),具有加法性。
距离尺度要求具有等价的单位,但不要求确定的零点位置。
对距离尺度的数字可以计算算术平均值、计算标准差,求相关系数等各种统计处理。
(4)比例尺度(ratio scale) :比例尺度是一种具有绝对零度的距离尺度值。
表示身长、体重的数值是比例尺度值。
对比例尺度的数字可进行各种统计处理。
4.数据的类型(1)定类数据(也称名义级数据),是数据的最低级。
(性别、编号)(2)定序数据(也称序次级数据),是数据的中间级。
(名次、优秀良好及格、有顺序的)(3)定距数据(也称间距级数据),是具有一定单位的实际测量值。
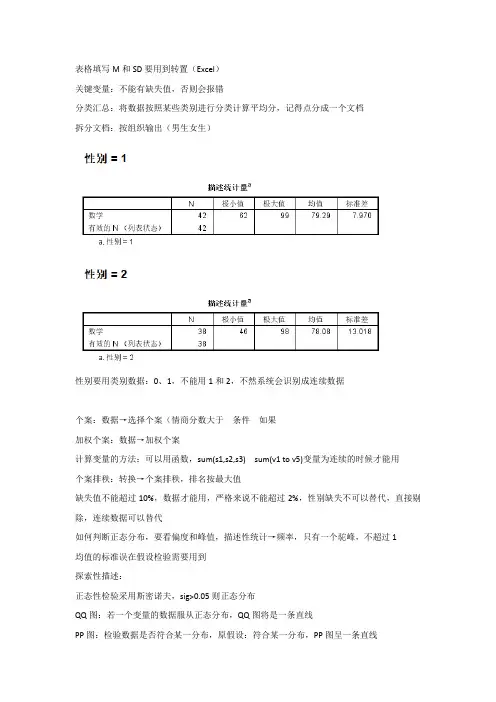
表格填写M和SD要用到转置(Excel)关键变量:不能有缺失值,否则会报错分类汇总:将数据按照某些类别进行分类计算平均分,记得点分成一个文档拆分文档:按组织输出(男生女生)性别要用类别数据:0、1,不能用1和2,不然系统会识别成连续数据个案:数据→选择个案(情商分数大于条件如果加权个案:数据→加权个案计算变量的方法:可以用函数,sum(s1,s2,s3) sum(v1 to v5)变量为连续的时候才能用个案排秩:转换→个案排秩,排名按最大值缺失值不能超过10%,数据才能用,严格来说不能超过2%,性别缺失不可以替代,直接剔除,连续数据可以替代如何判断正态分布,要看偏度和峰值,描述性统计→频率,只有一个驼峰,不超过1均值的标准误在假设检验需要用到探索性描述:正态性检验采用斯密诺夫,sig>0.05则正态分布QQ图:若一个变量的数据服从正态分布,QQ图将是一条直线PP图:检验数据是否符合某一分布,原假设:符合某一分布,PP图呈一条直线检验分布:正态;点击自然对数转换、标准值、差分三线表:上下1.5,中间0.5交叉表的独立性检验:两个类别变量之间是否有关联,sig<0.05则有关联,举例:性别和独生子女情况是否有关联效应量的判断,根据克莱姆V系数,系数在0.1-0.3属于小效应量,一般来说要大于0.2,克莱姆V系数不是统计检验力,需要进行换算,统计检验力(如0.29)说明二者有关联,其可能性大小为29%。
统计检验显著,小效应量:说明统计结论的可靠性较低,还需进一步研究资料佐证。
风险评估:A是B的两倍分层交叉表的独立性检验:分层卡方分析,分层卡方检验,需要大量本数据分层的变量常用人口学变量:性别、年级、职业、地区与期望值越远,相关程度越大因变量为类别数据时,常算比值比一致性卡方检验Kappa值=内部一致性系数取值0-1之间用交叉表分析≥0.75两者一致性较好0.75>kappa≥0.4一致性一般<0.4一致性较差列联表品质相关分析:两个分类变量的相关分析Φ相关系数(2×2列联表)、C相依系数(大于2×2列联表)克莱姆V系数可以算效应量和统计检验力交叉表也可以算相关单样本T检验:①样本均值与总体均值的差异检验。

一、单项选择题:(本大题小题,1分/每小题,共分)1.SPSS的数据文件后缀名是:(A).sav2.对数据的各种统计处理,SPSS是在下面哪一个选项中进行:(A)数据编辑窗口;3.在SPSS中,下面哪一个不是SPSS的运行方式(A)输入运行方式;4.下面哪一个选项不属于SPSS的数据分析步骤:(D)数据扩展;5.在SPSS中,下面哪一个选项不属于对变量(列)的描述:(B)变量名称大小;6.在SPSS的定义中,下面哪一个变量名的定义是错误的:(D)A_BFG_;首字符应以英文字母开头,后面可以跟除了!、?、*之外的字母或数字。
下划线、圆点不能为变量名的最后一个字符。
SPSS允许用汉字作为变量名。
7.在SPSS的定义中,下面哪一个变量名的定义是错误的:(A)AND;SPSS有默认的变量名,以字母“VAR”开头,后面补足5位数字,如VAR00001,VAR00012等。
变量名不能与SPSS内部特有的具有特定含义的保留字同名,如ALL、BY 、 AND 、 NOT 、 OR等。
8.在SPSS数据文件中,下面那一项不属于数据的结构:(D)数据值;9.在SPSS数据文件中,下面那一项属于数据的内容:(D)数据值;10. 通常来说,发放了900份问卷,可直接得到的有效问卷有800份,则SPSS所建立的相关数据文件中的行数为(D)800;11.下面那一项不属于SPSS的基本变量类型:(D)整数型;12.当在SPSS数据文件中输入变量为“职工姓名”,则应选择的变量类型是:(B)字符串型;13.当在SPSS数据文件中输入变量为“职工工资数”,则应选择的变量类型是:(A)数值型;13.当在SPSS数据文件中输入变量为“公司成立日期”,则应选择的变量类型是:(C)日期型;14.在SPSS的数据结构中,下面那一项不是“缺失数据”的定义:(D)数据不是科学计数法;15.统计学依据变量的计量尺度将变量分为三类,以下哪一类不属于这三类:(D)科学计数类型;16.在统计学中,变量“身高”属于计量尺度中的:(A)数值型变量;身高(定距)、优良中差(定序)、性别(定类)17.在统计学中,将变量“年龄”分为“老年”、“中年”、“青年”三个取值,分别用1、2、3表示,则变量“年龄”属于计量尺度中的:(B)定序型变量;18.在统计学中,将变量“性别”分为“男”、“女”、两个取值,分别用1、2表示,则变量“性别”属于计量尺度中的:(C)定类型变量;19.下面哪一个选项不能被SPSS系统正常打开:(C)文本文件格式;20. 下面哪一个选项不能被SPSS系统正常打开:(D).exe;21.在SPSS数据编辑窗口中,需要定义变量的数据结构,以下哪一项不属于变量的数据结构:(D)变量值;22. 在SPSS数据结构中,下面哪一项不属于数据类型:(D)数值标签型;23.下面哪一个选项不是SPSS中定义的基本描述统计量:(D)回归函数;24.下面哪一个选项不是SPSS中定义的基本描述统计量:D)因子;25.下面那一项刻画了随机变量分布形态的对称性:(D)偏度系数;26.下面那一项刻画了随机变量分布形态陡缓程度:(D)峰度系数;27.对于SPSS来说,下面那一项不包括在变量的频数分布内容中:(D)均值;(频数、百分比、有效百分比、累计百分比)27.对于SPSS来说,下面那一项不包括在变量的频数分布内容中:(C)标准差;28.在SPSS中,下面那一项不是频数分析中常用的统计图形:(D)分类图;29.在SPSS中,当需要对变量进行频数分析时,需要选择下面那一项菜单:(C)分析;30.在进行数据的统计分析之前,一般需要完成数据的预处理,以下哪一项不属于数据的预处理内容:(B)峰度和偏度处理;31.在SPSS中,当我需要对原有某个变量的数据进行取对数运算时,应选取下面那一项进行处理:(A)变量计算;32.在SPSS中,下面那一项不属于数据分组的目的:(D)有利于进行因子分析;33.对于SPSS中的组距分组,下面那一项是正确的说法:(A)分组数与数据本身特点和数据个数有关;34.对于SPSS来说,能够快捷找到变量数据的最大值和最小值的数据预处理方法是:(A)排序;35.对于SPSS来说,能够快捷找到变量数据的异常值的数据预处理方法是:(A)排序;36.在学生的一张数据表中,有平时分数、实验分数和卷面分数,如使用SPSS计算最终得分,则需要使用SPSS预处理中的:(C)变量计算;37.在SPSS中,以下哪个选项可以完成如下功能:由收集的整体数据中抽取出年龄大于30的数据:(A)数据选取;38.下面哪一个选项不是对数据的基本统计分析:(D)实现变量的排序与合并;39.在SPSS中,当变量是数值型时,则频数分析所用图形为:(A)直方图;40.在SPSS中,当需要选取出满足某一个条件的所有个案,则使用下面的那一项:(A)个案选择;41.在SPSS中,均值的计算适合下面那一项:(A)定距型;42.现有一批数据为(0,1,2,-2,3,-3,4),则这批数据的极差为:(A)7;43.以下图是某随机变量的概率密度,请问其峰度是:(B)小于零;右偏大于0;左偏小于0;偏度为0表示对称。
spss复习资料整理1第⼀章1.SPSS是软件英⽂名称的⾸字母缩写,其最初为Statistical Package for the Social Sciences的缩写,即“社会科学统计软件包”。
2.SPSS系统运⾏管理⽅式(SPSS的⼏种基本运⾏⽅式)有:(1)完全窗⼝菜单运⾏⽅式(2)程序运⾏管理⽅式(3)混合运⾏管理⽅式3.SPSS的界⾯提供的五个窗⼝:数据编辑窗⼝、结果管理窗⼝、结果编辑窗⼝、语法编辑窗⼝、脚本窗⼝。
第⼆章1.SPSS的⽂件类型:语法⽂件(*.sps)、数据⽂件(*.sav)、结果输出⽂件(*.spv)。
2.SPSS数据编辑器的每⼀⾏数据称为⼀个个案(Case),每⼀个数据代表个体的属性,即变量(V ariable)。
3.SPSS变量名的命名规则:1)必须以英⽂字母开头,其他部分可以含有字母、数字、下划线(即“-”);2)变量名尽量避免和SPSS已有的关键字重复,例如sum、compute、anova等;3)SPSS13及以后版本⽀持变量名最长为64Byte,即变量名最长为64个英⽂字符,或者32个中⽂字符;4)SPSS变量名不区分⼤⼩写,即SPSS认为Name、name、nAme这三个变量名没有区别。
4.变量度量类型:定量(个数、⾼度、温度等)、定序(“⼗分重要”、“重要”、“⼀般”、“不重要”)、定类(名字、地址、电话等)。
5.列和宽度的区别:变量宽度:对字符型变量,该数值决定了你能输⼊的字符串的长度;列:设定该变量数据视图中列的宽度。
6.变量的值标签:即对数值含义的解释。
例如:值标签1 2 男⼥7.默认的缺失值类型:数值型类型(.)、字符串类型(空格)。
8.数据⽂件的合并包括:纵向合并和横向合并(合并个案和合并变量),合并变量包括⼀对⼀合并和⼀对多合并。
9.SPSS⽤“(*)”表⽰变量来⾃于当前活动数据⽂件中的变量,⽽⽤“(+)”表⽰将要和当前数据⽂件进⾏合并的数据⽂件中的变量。
SPSS复习知识点及题⽬只是分享教育统计与测量(SPSS)复习第⼀章:概述1.什么是信息?简单地讲,通过信息,可以告诉我们某件事情,可以使我们增加⼀定的知识。
英语中的信息是“information”,表⽰信息可以让受者产⽣某种形式的变化,这种变化可以让受者从认识上的不完全、不理解、不确定变为完全、理解和确定。
信息论的奠基者⾹农将信息定义为熵的减少,即信息可以消除⼈们对事物认识的不确定性,并将消除不确定程度的多少作为信息量的量度。
信息的价值因⼈⽽异。
所谓有⽤的信息,因⼈⽽异。
是否是信息,不是由传者,⽽是由受者所决定。
2.教育信息数量化的特点表⽰教育信息的数量与各种物理测量的数量有着明显的不同,在教育信息的统计处理中,应根据教育信息数量化的⽅法、特点不同,决定对这种信息进⾏统计处理的具体⽅法。
这是进⾏教育信息处理的重要关键。
3.教育信息数量化的尺度(1)名义尺度(nominal scale) :名义尺度的数值仅具符号的意义。
名义尺度的数字多⽤于表⽰不同的数别,它为教育信息的表⽰,存贮带来了很⼤的⽅便。
(2)序数尺度(ordinal scale) :序数尺度的数字多⽤于表⽰某些现象的排列顺序,可⽐较其⼤⼩,但不能进⾏四则运算,所以对这类数字的数值群的处理较多。
(3)距离尺度(interval scale,equal unit scale):距离尺度⼜称间隔尺度,是指数值间的距离(间隔),具有加法性。
距离尺度要求具有等价的单位,但不要求确定的零点位置。
对距离尺度的数字可以计算算术平均值、计算标准差,求相关系数等各种统计处理。
(4)⽐例尺度(ratio scale) :⽐例尺度是⼀种具有绝对零度的距离尺度值。
表⽰⾝长、体重的数值是⽐例尺度值。
对⽐例尺度的数字可进⾏各种统计处理。
4.数据的类型(1)定类数据(也称名义级数据),是数据的最低级。
(性别、编号)(2)定序数据(也称序次级数据),是数据的中间级。
(名次、优秀良好及格、有顺序的)(3)定距数据(也称间距级数据),是具有⼀定单位的实际测量值。
1.SPSS全称Statistal Product and Service Solution。
2.数据类型:定距型、定序型、定类型。
3.非参数检验是指在总体不服从正态分布或分布情况不明时,用于检验数据资料是否来自相同总体假设的一类检验方法。
适用于分布类型未知,一端或两端误解,出现少量异常值的小样本数据,以及等级做记录的数据分析。
4.协方差分析是把线性回归和方差分析结合起来应用的一种方法,其目的是把与因变量y 值呈线性关系的自变量x值调成相等后检验两个或多个修正平均值间有无差别的方法。
5.方差分析的前提:正态性独立性方差齐性6.中位数n+12为中为数组M e=L+∑f2+F m−1f m×dL为组下限,∑f为总频数,F m−1为前一组的累计频数,f m为中为数组组次频数,d为组距。
众数M o=L+∆1∆1+∆2×dL为组下限,∆1组频数与其下限组次频数之差,∆2组频数与其下限组次频数之差,d为组距。
平均数x̅=∑M i f iki=1n,M i组中值,f i频数标准差s=√∑(M i−x̅)2f i ki=1n−17.卡方检验计算每个单元格的f e,f e=RT×CT/n,计算X2X2=∑(fo−fe)2fe在2×2单元格内为X2=n(ad−bc)2(a+b)(c+d)(a+c)(b+d)自由度为(R-1)(C-1),大于检验说明拒绝H0,显著相关。
分析-描述统计-交叉表-统计量-卡方8.T检验单样本资料的t检验单样本平均值与已知总体平均值比较的目的是推断样本所代表的未知总体平均值与已知总体平均值有无差别。
分析-比较平均值-单样本T检验两独立样本资料的t检验,常用于检验两个样本分别代表的总体平均值是否相等,具体的假设检验依各种问题的不同而异。
两个总体必须彼此独立也就是说,两个样本的观测值之间不能存在任何的历来关系,此类检验基于t分布,故必须假定两个总体均服从正态分布。
一、单项选择题:(本大题小题,1分/每小题,共分)1.SPSS的数据文件后缀名是:(A).sav2.对数据的各种统计处理,SPSS是在下面哪一个选项中进行:(A)数据编辑窗口;3.在SPSS中,下面哪一个不是SPSS的运行方式(A)输入运行方式;4.下面哪一个选项不属于SPSS的数据分析步骤:(D)数据扩展;5.在SPSS中,下面哪一个选项不属于对变量(列)的描述:(B)变量名称大小;6.在SPSS的定义中,下面哪一个变量名的定义是错误的:(D)A_BFG_;首字符应以英文字母开头,后面可以跟除了!、?、*之外的字母或数字。
下划线、圆点不能为变量名的最后一个字符。
SPSS允许用汉字作为变量名。
7.在SPSS的定义中,下面哪一个变量名的定义是错误的:(A)AND;SPSS有默认的变量名,以字母“VAR”开头,后面补足5位数字,如VAR00001,VAR00012等。
变量名不能与SPSS内部特有的具有特定含义的保留字同名,如ALL、BY 、 AND 、 NOT 、 OR等。
8.在SPSS数据文件中,下面那一项不属于数据的结构:(D)数据值;9.在SPSS数据文件中,下面那一项属于数据的内容:(D)数据值;10. 通常来说,发放了900份问卷,可直接得到的有效问卷有800份,则SPSS所建立的相关数据文件中的行数为(D)800;11.下面那一项不属于SPSS的基本变量类型:(D)整数型;12.当在SPSS数据文件中输入变量为“职工姓名”,则应选择的变量类型是:(B)字符串型;13.当在SPSS数据文件中输入变量为“职工工资数”,则应选择的变量类型是:(A)数值型;13.当在SPSS数据文件中输入变量为“公司成立日期”,则应选择的变量类型是:(C)日期型;14.在SPSS的数据结构中,下面那一项不是“缺失数据”的定义:(D)数据不是科学计数法;15.统计学依据变量的计量尺度将变量分为三类,以下哪一类不属于这三类:(D)科学计数类型;16.在统计学中,变量“身高”属于计量尺度中的:(A)数值型变量;身高(定距)、优良中差(定序)、性别(定类)17.在统计学中,将变量“年龄”分为“老年”、“中年”、“青年”三个取值,分别用1、2、3表示,则变量“年龄”属于计量尺度中的:(B)定序型变量;18.在统计学中,将变量“性别”分为“男”、“女”、两个取值,分别用1、2表示,则变量“性别”属于计量尺度中的:(C)定类型变量;19.下面哪一个选项不能被SPSS系统正常打开:(C)文本文件格式;20. 下面哪一个选项不能被SPSS系统正常打开:(D).exe;21.在SPSS数据编辑窗口中,需要定义变量的数据结构,以下哪一项不属于变量的数据结构:(D)变量值;22. 在SPSS数据结构中,下面哪一项不属于数据类型:(D)数值标签型;23.下面哪一个选项不是SPSS中定义的基本描述统计量:(D)回归函数;24.下面哪一个选项不是SPSS中定义的基本描述统计量:D)因子;25.下面那一项刻画了随机变量分布形态的对称性:(D)偏度系数;26.下面那一项刻画了随机变量分布形态陡缓程度:(D)峰度系数;27.对于SPSS来说,下面那一项不包括在变量的频数分布内容中:(D)均值;(频数、百分比、有效百分比、累计百分比)27.对于SPSS来说,下面那一项不包括在变量的频数分布内容中:(C)标准差;28.在SPSS中,下面那一项不是频数分析中常用的统计图形:(D)分类图;29.在SPSS中,当需要对变量进行频数分析时,需要选择下面那一项菜单:(C)分析;30.在进行数据的统计分析之前,一般需要完成数据的预处理,以下哪一项不属于数据的预处理内容:(B)峰度和偏度处理;31.在SPSS中,当我需要对原有某个变量的数据进行取对数运算时,应选取下面那一项进行处理:(A)变量计算;32.在SPSS中,下面那一项不属于数据分组的目的:(D)有利于进行因子分析;33.对于SPSS中的组距分组,下面那一项是正确的说法:(A)分组数与数据本身特点和数据个数有关;34.对于SPSS来说,能够快捷找到变量数据的最大值和最小值的数据预处理方法是:(A)排序;35.对于SPSS来说,能够快捷找到变量数据的异常值的数据预处理方法是:(A)排序;36.在学生的一张数据表中,有平时分数、实验分数和卷面分数,如使用SPSS计算最终得分,则需要使用SPSS预处理中的:(C)变量计算;37.在SPSS中,以下哪个选项可以完成如下功能:由收集的整体数据中抽取出年龄大于30的数据:(A)数据选取;38.下面哪一个选项不是对数据的基本统计分析:(D)实现变量的排序与合并;39.在SPSS中,当变量是数值型时,则频数分析所用图形为:(A)直方图;40.在SPSS中,当需要选取出满足某一个条件的所有个案,则使用下面的那一项:(A)个案选择;41.在SPSS中,均值的计算适合下面那一项:(A)定距型;42.现有一批数据为(0,1,2,-2,3,-3,4),则这批数据的极差为:(A)7;43.以下图是某随机变量的概率密度,请问其峰度是:(B)小于零;右偏大于0;左偏小于0;偏度为0表示对称。