厦门大学林子雨编著《大数据技术原理与应用》教材配套实验
- 格式:docx
- 大小:36.34 KB
- 文档页数:13

林子雨大数据技术原理及应用课后题答案大数据第一章大数据概述课后题 (1)大数据第二章大数据处理架构Hadoop课后题 (5)大数据第三章Hadoop分布式文件系统课后题 (10)大数据第四章分布式数据库HBase课后题 (16)大数据第五章NoSQl数据库课后题 (22)大数据第六章云数据库课后作题 (28)大数据第七章MapReduce课后题 (34)大数据第八章流计算课后题 (41)大数据第九章图计算课后题 (50)大数据第十章数据可视化课后题 (53)大数据第一章课后题——大数据概述1.试述信息技术发展史上的3次信息化浪潮及其具体内容。
第一次信息化浪潮1980年前后个人计算机开始普及,计算机走入企业和千家万户。
代表企业:Intel,AMD,IBM,苹果,微软,联想,戴尔,惠普等。
第二次信息化浪潮1995年前后进入互联网时代。
代表企业:雅虎,谷歌阿里巴巴,百度,腾讯。
第三次信息浪潮2010年前后,云计算大数据,物联网快速发展,即将涌现一批新的市场标杆企业。
2.试述数据产生方式经历的几个阶段。
经历了三个阶段:运营式系统阶段数据伴随一定的运营活动而产生并记录在数据库。
用户原创内容阶段Web2.0时代。
感知式系统阶段物联网中的设备每时每刻自动产生大量数据。
3.试述大数据的4个基本特征。
数据量大(Volume)据类型繁多(Variety)处理速度快(Velocity)价值密度低(Value)4.试述大数据时代的“数据爆炸”特性。
大数据摩尔定律:人类社会产生的数据一直都在以每年50%的速度增长,即每两年就增加一倍。
5.科学研究经历了那四个阶段?实验比萨斜塔实验理论采用各种数学,几何,物理等理论,构建问题模型和解决方案。
例如:牛一,牛二,牛三定律。
计算设计算法并编写相应程序输入计算机运行。
数据以数据为中心,从数据中发现问题解决问题。
6.试述大数据对思维方式的重要影响。
全样而非抽样效率而非精确相关而非因果7.大数据决策与传统的基于数据仓库的决策有什么区别?数据仓库以关系数据库为基础,在数据类型和数据量方面存在较大限制。

厦门大学林子雨编著《大数据技术原理与应用》教材配套上机练习图计算框架Hama的基础操作实践(版本号:2016年1月18日版本)主讲教师:林子雨厦门大学数据库实验室二零一六年一月(版权所有,请勿用于商业用途)目录目录1作业题目 (1)2作业目的 (1)3作业性质 (1)4作业考核方法 (1)5作业提交日期与方式 (1)6作业准备 (1)6.1、Hama计算框架的安装配置 (1)6.2、用Hama计算模型实现寻找最大独立集问题算法 (3)7作业内容 (9)8实验报告 (9)附录1:任课教师介绍 (9)附录2:课程教材介绍 (10)《大数据技术原理与应用》图计算框架Hama基础操作实践上机练习说明主讲教师:林子雨E-mail: ziyulin@ 个人主页:/linziyu1作业题目图计算框架Hama基础操作实践。
2作业目的旨在让学生了解Pregel图计算模型,并学会用Pregel的开源实现Hama实现一些基本操作。
3作业性质课后作业,必做,作为课堂平时成绩。
4作业考核方法提交上机实验报告,任课老师根据上机实验报告评定成绩。
5作业提交日期与方式图计算章节内容结束后的下一周周六晚上9点之前提交。
6作业准备请阅读厦门大学林子雨编著的大数据专业教材《大数据技术原理与应用》(官网:/post/bigdata/),了解图计算的概念与意义。
6.1、Hama计算框架的安装配置A pache Hama是Google Pregel的开源实现,与Hadoop适合于分布式大数据处理不同,Hama主要用于分布式的矩阵、graph、网络算法的计算。
简单说,Hama是在HDFS 上实现的BSP(Bulk Synchronous Parallel)计算框架,弥补Hadoop在计算能力上的不足。
(1). 安装好合适版本的jdk和hadoop,并且进行测试,保证他们能用。
(2). 下载hama安装文件,从/downloads.html处下载合适的版本,我当时下的是0.6.4版本的。


第一章1.试述信息技术发展史上的3次信息化浪潮及具体内容。
2.试述数据产生方式经历的几个阶段答:运营式系统阶段,用户原创内容阶段,感知式系统阶段。
3.试述大数据的4个基本特征答:数据量大、数据类型繁多、处理速度快和价值密度低。
4.试述大数据时代的“数据爆炸”的特性答:大数据时代的“数据爆炸”的特性是,人类社会产生的数据一致都以每年50%的速度增长,也就是说,每两年增加一倍。
5.数据研究经历了哪4个阶段答:人类自古以来在科学研究上先后历经了实验、理论、计算、和数据四种范式。
6.试述大数据对思维方式的重要影响答:大数据时代对思维方式的重要影响是三种思维的转变:全样而非抽样,效率而非精确,相关而非因果。
7.大数据决策与传统的基于数据仓库的决策有什么区别答:数据仓库具备批量和周期性的数据加载以及数据变化的实时探测、传播和加载能力,能结合历史数据和实时数据实现查询分析和自动规则触发,从而提供对战略决策和战术决策。
大数据决策可以面向类型繁多的、非结构化的海量数据进行决策分析。
8.举例说明大数据的基本应用答:9.举例说明大数据的关键技术答:批处理计算,流计算,图计算,查询分析计算10.大数据产业包含哪些关键技术。
答:IT基础设施层、数据源层、数据管理层、数据分析层、数据平台层、数据应用层。
11.定义并解释以下术语:云计算、物联网答:云计算:云计算就是实现了通过网络提供可伸缩的、廉价的分布式计算机能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源。
物联网是物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、机器、人类和物等通过新的方式连在一起,形成人与物、物与物相连,实现信息化和远程管理控制。
12.详细阐述大数据、云计算和物联网三者之间的区别与联系。
第二章1.试述hadoop和谷歌的mapreduce、gfs等技术之间的关系答:Hadoop的核心是分布式文件系统HDFS和MapReduce,HDFS是谷歌文件系统GFS的开源实现,MapReduces是针对谷歌MapReduce的开源实现。
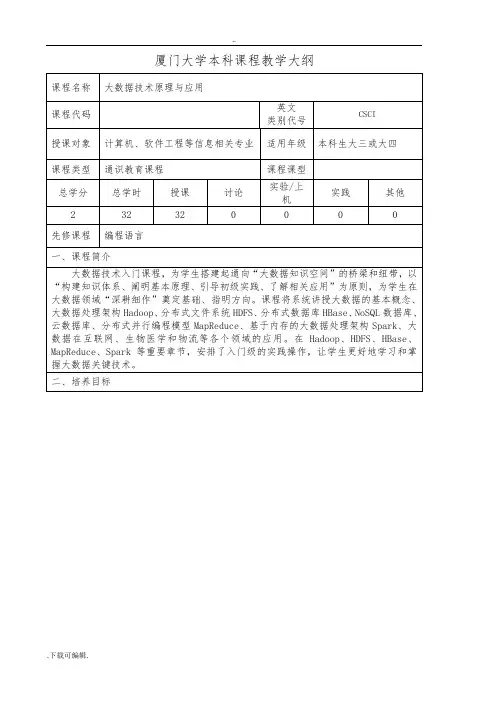
厦门大学本科课程教学大纲
XMU Undergraduate Course Syllabus
厦门大学本科课程大纲填写说明(Notes)
1.须同时填写课程大纲中文版和英文版。
2.课程名称必须准确、规范。
3.课程代码:非任课教师填写。
该课程在教务系统生成后,由学院代为填写。
4.授课对象填写专业。
5.适用年级填写可修读本课程的时间,如本科三年级第一学期。
6.课程类型指公共基本课程、通识教育课程、学科通修课程、专业(或专业方向)课程、其他教学环节。
7.课程课型指理论课、实验课、技能课、实践课。
8.总学时=授课学时+讨论学时+实验学时+上机学时+其他学时
9.先修课程是与该课程具有严格的前后逻辑关系,非先修课程则无法学习该课程。
10.培养目标不少于150字。
11.考核方式包括成绩登记方式、成绩组成、考核标准等。
成绩登记方式包括百分制、
通过/不通过等。
成绩组成指各种考核方式占比。
考核标准指衡量各项考评指标得分的基准。
12.选用教材和主要参考书要求注明作者、书目、出版社、出版年份。
例如,“丹利维
尔:《民主、官僚制组织和公共选择》,中国青年出版社,2001年。
”
13.其它信息指课堂规范要求等,如课上禁止使用手机、缺勤要求等。
14.课程英文类别代号:。
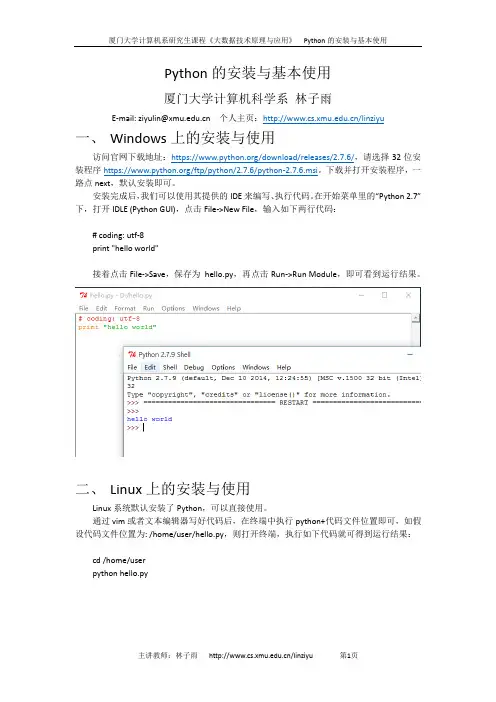
厦门大学计算机系研究生课程《大数据技术原理与应用》Python的安装与基本使用
Python的安装与基本使用
厦门大学计算机科学系林子雨
E-mail: ziyulin@ 个人主页:/linziyu
一、Windows上的安装与使用
访问官网下载地址:https:///download/releases/2.7.6/,请选择32位安装程序https:///ftp/python/2.7.6/python-2.7.6.msi。
下载并打开安装程序,一路点next,默认安装即可。
安装完成后,我们可以使用其提供的IDE来编写、执行代码。
在开始菜单里的“Python 2.7”下,打开IDLE (Python GUI),点击File->New File,输入如下两行代码:
# coding: utf-8
print "hello world"
接着点击File->Save,保存为hello.py,再点击Run->Run Module,即可看到运行结果。
二、Linux上的安装与使用
Linux系统默认安装了Python,可以直接使用。
通过vim或者文本编辑器写好代码后,在终端中执行python+代码文件位置即可,如假设代码文件位置为: /home/user/hello.py,则打开终端,执行如下代码就可得到运行结果:
cd /home/user
python hello.py
主讲教师:林子雨/linziyu 第1页。





厦门大学林子雨编著《大数据技术原理与应用》教材配套机房上机实验指南实验3第四章熟悉常用的HBase操作(版本号:2016年5月14日版本)主讲教师:林子雨厦门大学数据库实验室二零一六年五月目录目录1实验目的 (1)2实验平台 (1)3实验内容和要求 (1)4实验报告 (2)附录1:任课教师介绍 (3)附录2:课程教材介绍 (3)附录3:中国高校大数据课程公共服务平台介绍 (4)厦门大学林子雨编著《大数据技术原理与应用》教材配套机房上机实验指南实验3第四章熟悉常用的HBase操作主讲教师:林子雨E-mail: ziyulin@ 个人主页:/linziyu1实验目的1. 理解HBase在Hadoop体系结构中的角色;2. 熟练使用HBase操作常用的Shell命令;3. 熟悉HBase操作常用的Java API。
2实验平台操作系统:LinuxHadoop版本:2.6.0或以上版本HBase版本:1.1.2或以上版本JDK版本:1.6或以上版本Java IDE:Eclipse3实验内容和要求1.编程实现以下指定功能,并用Hadoop提供的HBase Shell命令完成相同任务:(1)列出HBase所有的表的相关信息,例如表名;(2)在终端打印出指定的表的所有记录数据;(3)向已经创建好的表添加和删除指定的列族或列;(4)清空指定的表的所有记录数据;(5)统计表的行数。
2.现有以下关系型数据库中的表和数据,要求将其转换为适合于HBase存储的表并插入数据:学生表(Student)同时,请编程完成以下指定功能:(1)createTable(String tableName, String[] fields)创建表,参数tableName为表的名称,字符串数组fields为存储记录各个域名称的数组。
要求当HBase已经存在名为tableName的表的时候,先删除原有的表,然后再创建新的表。
(2)addRecord(String tableName, String row, String[] fields, String[] values)向表tableName、行row(用S_Name表示)和字符串数组files指定的单元格中添加对应的数据values。
大数据技术原理与应用教学大纲课程概述入门级大数据课程,适合初学者,完备的课程在线服务体系,可以帮助初学者实现“零基础”学习大数据课程。
课程采用厦门大学林子雨老师编著的国内高校第一本系统性介绍大数据知识专业教材《大数据技术原理与应用》。
课程紧紧围绕“构建知识体系、阐明基本原理、引导初级实践、了解相关应用”的指导思想,对大数据知识体系进行系统梳理,做到“有序组织、去粗取精、由浅入深、渐次展开”。
课程由国内高校知名大数据教师厦门大学林子雨副教授主讲。
授课目标课程的定位是入门级课程,本课程的目标是为学生搭建起通向“大数据知识空间”的桥梁和纽带。
本课程将系统梳理总结大数据相关技术,介绍大数据技术的基本原理和大数据主要应用,帮助学生形成对大数据知识体系及其应用领域的轮廓性认识,为学生在大数据领域“深耕细作”奠定基础、指明方向。
课程大纲第1讲大数据概述1.1 大数据时代1.2 大数据概念和影响1.3 大数据的应用1.4 大数据的关键技术1.5 大数据与云计算、物联网本讲配套讲义PPT-第1讲-大数据概述第1讲大数据概述章节单元测验第2讲大数据处理架构Hadoop本讲实验答疑-第2讲-大数据处理架构Hadoop2.1 概述2.2 Hadoop项目结构2.3 Hadoop的安装与使用2.4 Hadoop集群的部署和使用本讲配套讲义PPT-第2讲-大数据处理架构Hadoop 大数据处理架构Hadoop单元测验第3讲分布式文件系统HDFS3.1 分布式文件系统HDFS简介3.2 HDFS相关概念3.3 HDFS体系结构3.4 HDFS存储原理3.5 HDFS数据读写过程3.6 HDFS编程实践本讲配套讲义PPT-第3讲-分布式文件系统HDFS 分布式文件系统HDFS单元测验第4讲分布式数据库HBase4.1 HBase简介4.2 HBase数据模型4.3 HBase的实现原理4.4 HBase运行机制4.5 HBase应用方案4.6 HBase安装配置和常用Shell命令4.7 HBase常用Java API及应用实例本讲配套讲义PPT-第4讲-分布式数据库HBase 分布式数据库HBase单元测验第5讲NoSQL数据库5.1 NoSQL概述5.2 NoSQL与关系数据库的比较5.3 NoSQL的四大类型5.4 NoSQL的三大基石5.5 从NoSQL到NewSQL数据库5.6 文档数据库MongoDB本讲配套讲义PPT-第5讲-NoSQL数据库NoSQL数据库单元测验第6讲云数据库6.1 云数据库概述6.2 云数据库产品6.3 云数据库系统架构6.4 Amazon AWS和云数据库6.5 微软云数据库SQL Azure6.6 云数据库实践本讲配套讲义PPT-第6讲-云数据库云数据库单元测验第7讲MapReduce7.1 MapReduce概述7.2 MapReduce的体系结构7.3 MapReduce工作流程7.4 Shuffle过程原理7.5 MapReduce应用程序执行过程7.6 实例分析:WordCount7.7 MapReduce的具体应用7.8 MapReduce编程实践本讲配套讲义PPT-第7讲-MapReduce MapReduce单元测验第8讲Hadoop再探讨8.1 Hadoop的优化与发展8.2 HDFS2.0的新特性8.3 新一代资源管理调度框架YARN8.4 Hadoop生态系统中具有代表性的功能组件本讲配套讲义PPT-第9讲-Hadoop再探讨Hadoop再探讨单元测验第9讲数据仓库Hive9.1 数据仓库概念9.2 Hive简介9.3 SQL转换成MapReduce作业的原理9.4 Impala9.5 Hive编程实践本讲配套讲义PPT-第9讲-数据仓库Hive数据仓库Hive单元测验第10讲Spark10.1 Spark概述10.2 Spark生态系统10.3 Spark运行架构10.4 Spark SQL10.5 Spark的部署和应用方式10.6 Spark编程实践本讲配套讲义PPT-第10讲-SparkSpark单元测验第11讲流计算11.1 流计算概述11.2 流计算处理流程11.3 流计算的应用11.4 开源流计算框架Storm11.5 Spark Streaming、Samza以及三种流计算框架的比较11.6 Storm编程实践本讲配套讲义PPT-第11讲-流计算流计算单元测验第12讲Flink12.1Flink简介12.2为什么选择Flink12.3Flink应用场景12.4Flink技术栈、体系架构和编程模型12.5 Flink的安装与编程实践本讲配套讲义PPT-第12讲-FlinkFlink单元测验第13讲图计算13.1 图计算简介13.2 Pregel简介13.3 Pregel图计算模型13.4 Pregel的C++ API13.5 Pregel的体系结构13.6 Pregel的应用实例——单源最短路径13.7 Hama的安装和使用本讲配套讲义PPT-第13讲-图计算图计算单元测验第14讲大数据在不同领域的应用14.1 大数据应用概览14.2 推荐系统14.3 大数据在智能医疗和智能物流领域运用本讲配套讲义PPT-第14讲-大数据在不同领域的应用大数据在不同领域的应用单元测验预备知识面向对象编程(比如Java)、数据库、操作系统参考资料林子雨.大数据技术原理与应用(第3版),人民邮电出版社,2020年9月(教材官网)。
厦门大学本科课程教学大纲
XMU Un dergraduate Course Syllabus
厦门大学本科课程大纲填写说明(Notes)
1. 须同时填写课程大纲中文版和英文版。
2. 课程名称必须准确、规范。
3. 课程代码:非任课教师填写。
该课程在教务系统生成后,由学院代为填写。
4. 授课对象填写专业。
5. 适用年级填写可修读本课程的时间,如本科三年级第一学期。
6. 课程类型指公共基本课程、通识教育课程、学科通修课程、专业(或专业方向)课程、
其他教学环节。
7. 课程课型指理论课、实验课、技能课、实践课。
8. 总学时二授课学时+讨论学时+实验学时+上机学时+其他学时
9. 先修课程是与该课程具有严格的前后逻辑关系,非先修课程则无法学习该课程。
10. 培养目标不少于150字。
11. 考核方式包括成绩登记方式、成绩组成、考核标准等。
成绩登记方式包括百分制、
通过/不通过等。
成绩组成指各种考核方式占比。
考核标准指衡量各项考评指标得分的基准。
12. 选用教材和主要参考书要求注明作者、书目、出版社、出版年份。
例如,“丹利维
尔:《民主、官僚制组织和公共选择》,中国青年出版社,2001年。
”
13. 其它信息指课堂规范要求等,如课上禁止使用手机、缺勤要求等。
14. 课程英文类别代号:。
厦门大学林子雨编著《大数据技术原理与应用》教材配套实验实验一:熟悉常用的Linux操作和Hadoop操作一、实验目的Hadoop运行在Linux系统上,因此,需要学习实践一些常用的Linux命令。
.本实验旨在熟悉常用的Linux操作和Hadoop操作,为顺利开展后续其他实验奠定基础。
.二、实验平台●操作系统:Linux(建议Ubuntu16. 04);●Hadoop版本:2. 7. 1。
.三、实验步骤(一)熟悉常用的Linux操作●cd命令:切换目录(1)切换到目录“/usr/local”(2)切换到当前目录的上一级目录(3)切换到当前登录Linux系统的用户的自己的主文件夹●ls命令:查看文件与目录(4)查看目录“/usr”下的所有文件和目录●mkdir命令:新建目录(5)进入“/tmp”目录,创建一个名为“a”的目录,并查看“/tmp”目录下已经存在哪些目录(6)进入“/tmp”目录,创建目录“a1/a2/a3/a4”●rmdir命令:删除空的目录(7)将上面创建的目录a(在“/tmp”目录下面)删除(8)删除上面创建的目录“a1/a2/a3/a4”(在“/tmp”目录下面),然后查看“/tmp”目录下面存在哪些目录●cp命令:复制文件或目录(9)将当前用户的主文件夹下的文件. bashrc复制到目录“/usr”下,并重命名为bashrc1(10)在目录“/tmp”下新建目录test,再把这个目录复制到“/usr”目录下●mv命令:移动文件与目录,或更名(11)将“/usr”目录下的文件bashrc1移动到“/usr/test”目录下(12)将“/usr”目录下的test目录重命名为test2●rm命令:移除文件或目录(13)将“/usr/test2”目录下的bashrc1文件删除(14)将“/usr”目录下的test2目录删除●cat命令:查看文件内容(15)查看当前用户主文件夹下的. bashrc文件内容●tac命令:反向查看文件内容(16)反向查看当前用户主文件夹下的. bashrc文件的内容●more命令:一页一页翻动查看(17)翻页查看当前用户主文件夹下的. bashrc文件的内容●head命令:取出前面几行(18)查看当前用户主文件夹下. bashrc文件内容前20行(19)查看当前用户主文件夹下. bashrc文件内容,后面50行不显示,只显示前面几行●tail命令:取出后面几行(20)查看当前用户主文件夹下. bashrc文件内容最后20行(21)查看当前用户主文件夹下. bashrc文件内容,并且只列出50行以后的数据●touch命令:修改文件时间或创建新文件(22)在“/tmp”目录下创建一个空文件hello,并查看文件时间(23)修改hello文件,将文件时间整为5天前●chown命令:修改文件所有者权限(24)将hello文件所有者改为root帐号,并查看属性●find命令:文件查找(25)找出主文件夹下文件名为. bashrc的文件●tar命令:压缩命令(26)在根目录“/”下新建文件夹test,然后在根目录“/”下打包成test. tar. gz(27)把上面的test. tar. gz压缩包,解压缩到“/tmp”目录●grep命令:查找字符串(28)从“~/. bashrc”文件中查找字符串'examples'●配置环境变量(29)请在“~/. bashrc”中设置,配置Java环境变量(30)查看JAVA_HOME变量的值(二)熟悉常用的Hadoop操作(31)使用hadoop用户登录Linux系统,启动Hadoop(Hadoop的安装目录为“/usr/local/hadoop”),为hadoop用户在HDFS中创建用户目录“/user/hadoop”(32)接着在HDFS的目录“/user/hadoop”下,创建test文件夹,并查看文件列表(33)将Linux系统本地的“~/. bashrc”文件上传到HDFS的test文件夹中,并查看test (34)将HDFS文件夹test复制到Linux系统本地文件系统的“/usr/local/hadoop”目录下四、实验报告实验二:熟悉常用的HDFS操作一、实验目的●理解HDFS在Hadoop体系结构中的角色;●熟练使用HDFS操作常用的Shell命令;●熟悉HDFS操作常用的Java API。
.二、实验平台●操作系统:Linux(建议Ubuntu16. 04);●Hadoop版本:2. 7. 1;●JDK版本:1. 7或以上版本;●Java IDE:Eclipse。
.三、实验步骤(一)编程实现以下功能,并利用Hadoop提供的Shell命令完成相同任务:(1)向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,则由用户来指定是追加到原有文件末尾还是覆盖原有的文件;(2)从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;(3)将HDFS中指定文件的内容输出到终端中;(4)显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;(5)给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;(6)提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。
.如果文件所在目录不存在,则自动创建目录;(7)提供一个HDFS的目录的路径,对该目录进行创建和删除操作。
.创建目录时,如果目录文件所在目录不存在,则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;(8)向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;(9)删除HDFS中指定的文件;(10)在HDFS中,将文件从源路径移动到目的路径。
.(二)编程实现一个类“MyFSDataInputStream”,该类继承“org. apache. hadoop. fs. FSDat aInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本。
.(三)查看Java帮助手册或其它资料,用“java. net. URL”和“org. apache. hadoop. fs. Fs URLStreamHandlerFactory”编程完成输出HDFS中指定文件的文本到终端中。
.四、实验报告(备注:实验答案请见附录A)实验三:熟悉常用的HBase操作一、实验目的●理解HBase在Hadoop体系结构中的角色;●熟练使用HBase操作常用的Shell命令;●熟悉HBase操作常用的Java API。
.二、实验平台●操作系统:Linux(建议Ubuntu16. 04);●Hadoop版本:2. 7. 1;●HBase版本:1. 1. 5;●JDK版本:1. 7或以上版本;●Java IDE:Eclipse。
.三、实验步骤(一)编程实现以下指定功能,并用Hadoop提供的HBase Shell命令完成相同任务:(1)列出HBase所有的表的相关信息,例如表名;(2)在终端打印出指定的表的所有记录数据;(3)向已经创建好的表添加和删除指定的列族或列;(4)清空指定的表的所有记录数据;(5)统计表的行数。
.(二)HBase数据库操作1. 现有以下关系型数据库中的表和数据,要求将其转换为适合于HBase存储的表并插入数据:2. 请编程实现以下功能:(1)createTable(String tableName, String[] fields)创建表,参数tableName为表的名称,字符串数组fields为存储记录各个字段名称的数组。
.要求当HBase已经存在名为tableName的表的时候,先删除原有的表,然后再创建新的表。
.(2)addRecord(String tableName, String row, String[] fields, String[] values)向表tableName、行row(用S_Name表示)和字符串数组fields指定的单元格中添加对应的数据values。
.其中,fields中每个元素如果对应的列族下还有相应的列限定符的话,用“columnFamily:column”表示。
.例如,同时向“Math”、“Computer Science”、“English”三列添加成绩时,字符串数组fields为{“Score:Math”, ”Score:Computer Science”, ”Score:English”},数组values存储这三门课的成绩。
.(3)scanColumn(String tableName, String column)浏览表tableName某一列的数据,如果某一行记录中该列数据不存在,则返回null。
.要求当参数column为某一列族名称时,如果底下有若干个列限定符,则要列出每个列限定符代表的列的数据;当参数column为某一列具体名称(例如“Score:Math”)时,只需要列出该列的数据。
.(4)modifyData(String tableName, String row, String column)修改表tableName,行row(可以用学生姓名S_Name表示),列column指定的单元格的数据。
.(5)deleteRow(String tableName, String row)删除表tableName中row指定的行的记录。
.四、实验报告(备注:实验答案请见附录A)实验四:NoSQL和关系数据库的操作比较一、实验目的●理解四种数据库(MySQL、HBase、Redis和MongoDB)的概念以及不同点;●熟练使用四种数据库操作常用的Shell命令;●熟悉四种数据库操作常用的Java API。
.二、实验平台●操作系统:Linux(建议Ubuntu16. 04);●Hadoop版本:2. 7. 1;●MySQL版本:5. 6;●HBase版本:1. 1. 2;●Redis版本:3. 0. 6;●MongoDB版本:3. 2. 6;●JDK版本:1. 7或以上版本;●Java IDE:Eclipse;三、实验步骤(一)MySQL数据库操作学生表Student1.根据上面给出的Student表,在MySQL数据库中完成如下操作:(1)在MySQL中创建Student表,并录入数据;(2)用SQL语句输出Student表中的所有记录;(3)查询zhangsan的Computer成绩;(4)修改lisi的Math成绩,改为95。