Oracle数据库的空间数据类型
- 格式:doc
- 大小:41.50 KB
- 文档页数:6

基础概念:Oracle数据库、实例、用户、表空间、表之间的关系数据库:Oracle数据库是数据的物理存储。
这就包括(数据文件ORA或者DBF、控制文件、联机日志、参数文件)。
其实Oracle数据库的概念和其它数据库不一样,这里的数据库是一个操作系统只有一个库。
可以看作是Oracle就只有一个大数据库。
实例:一个Oracle实例(Oracle Instance)有一系列的后台进程(Backguound Processes)和内存结构(Memory Structures)组成。
一个数据库可以有n个实例。
用户:用户是在实例下建立的。
不同实例可以建相同名字的用户。
表空间:表空间是一个用来管理数据存储逻辑概念,表空间只是和数据文件(ORA或者DBF文件)发生关系,数据文件是物理的,一个表空间可以包含多个数据文件,而一个数据文件只能隶属一个表空间。
数据文件(dbf、ora):数据文件是数据库的物理存储单位。
数据库的数据是存储在表空间中的,真正是在某一个或者多个数据文件中。
而一个表空间可以由一个或多个数据文件组成,一个数据文件只能属于一个表空间。
一旦数据文件被加入到某个表空间后,就不能删除这个文件,如果要删除某个数据文件,只能删除其所属于的表空间才行。
注:表的数据,是有用户放入某一个表空间的,而这个表空间会随机把这些表数据放到一个或者多个数据文件中。
由于oracle的数据库不是普通的概念,oracle是有用户和表空间对数据进行管理和存放的。
但是表不是有表空间去查询的,而是由用户去查的。
因为不同用户可以在同一个表空间建立同一个名字的表!这里区分就是用户了!关系示意图:理解1:Oracle数据库可以创建多个实例,每个实例可以创建多个表空间,每个表空间下可以创建多个用户(同时用户也属于表空间对应的实例)和数据库文件,用户可以创建多个表(每个表随机存储在一个或多个数据库文件中),如下图:理解2:理解1MS有误。
实例下有和,授权访问,是管理的,经授权在中创建,随机存储到不同的中。


ORACLE常⽤数据库类型(转)oracle常⽤数据类型1、Char定长格式字符串,在数据库中存储时不⾜位数填补空格,它的声明⽅式如下CHAR(L),L为字符串长度,缺省为1,作为变量最⼤32767个字符,作为数据存储在ORACLE8中最⼤为2000。
不建议使⽤,会带来不必要的⿇烦a、字符串⽐较的时候,如果不注意(char不⾜位补空格)会带来错误b、字符串⽐较的时候,如果⽤trim函数,这样该字段上的索引就失效(有时候会带来严重性能问题)c、浪费存储空间(⽆法精准计算未来存储⼤⼩,只能留有⾜够的空间;字符串的长度就是其所占⽤空间的⼤⼩)2、Varchar2/varchar⽬前VARCHAR是VARCHAR2的同义词。
⼯业标准的VARCHAR类型可以存储空字符串,但是oracle不这样做,尽管它保留以后这样做的权利。
Oracle⾃⼰开发了⼀个数据类型VARCHAR2,这个类型不是⼀个标准的VARCHAR,它将在数据库中varchar列可以存储空字符串的特性改为存储NULL值。
如果你想有向后兼容的能⼒,Oracle建议使⽤VARCHAR2⽽不是VARCHAR。
不定长格式字符串,它的声明⽅式如下VARCHAR2(L),L为字符串长度,没有缺省值,作为变量最⼤32767个字节,作为数据存储在ORACLE8中最⼤为4000。
在多字节语⾔环境中,实际存储的字符个数可能⼩于L值,例如:当语⾔环境为中⽂(SIMPLIFIED CHINESE_CHINA.ZHS16GBK)时,⼀个VARCHAR2(200)的数据列可以保存200个英⽂字符或者100个汉字字符;对于4000字节以内的字符串,建议都⽤该类型a。
VARCHAR2⽐CHAR节省空间,在效率上⽐CHAR会稍微差⼀些,即要想获得效率,就必须牺牲⼀定的空间,这也就是我们在数据库设计上常说的‘以空间换效率’。
b。
VARCHAR2虽然⽐CHAR节省空间,但是如果⼀个VARCHAR2列经常被修改,⽽且每次被修改的数据的长度不同,这会引起‘⾏迁移’(Row Migration)现象,⽽这造成多余的I/O,是数据库设计和调整中要尽⼒避免的,在这种情况下⽤CHAR代替VARCHAR2会更好⼀些。

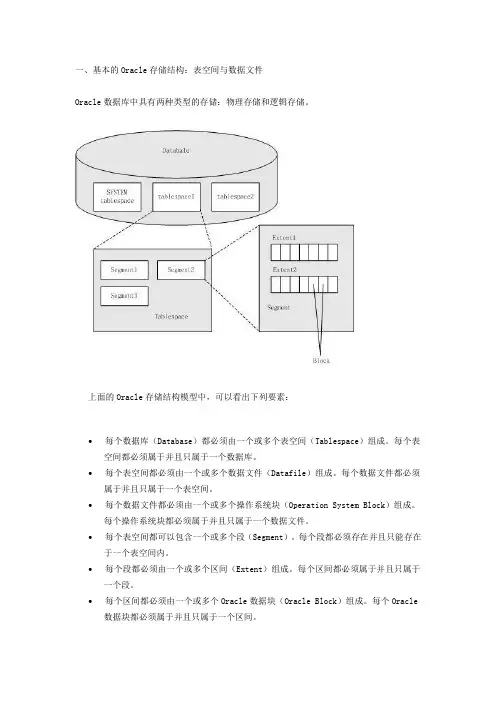
一、基本的Oracle存储结构:表空间与数据文件Oracle数据库中具有两种类型的存储:物理存储和逻辑存储。
上面的Oracle存储结构模型中,可以看出下列要素:∙每个数据库(Database)都必须由一个或多个表空间(Tablespace)组成。
每个表空间都必须属于并且只属于一个数据库。
∙每个表空间都必须由一个或多个数据文件(Datafile)组成。
每个数据文件都必须属于并且只属于一个表空间。
∙每个数据文件都必须由一个或多个操作系统块(Operation System Block)组成。
每个操作系统块都必须属于并且只属于一个数据文件。
∙每个表空间都可以包含一个或多个段(Segment)。
每个段都必须存在并且只能存在于一个表空间内。
∙每个段都必须由一个或多个区间(Extent)组成。
每个区间都必须属于并且只属于一个段。
∙每个区间都必须由一个或多个Oracle数据块(Oracle Block)组成。
每个Oracle 数据块都必须属于并且只属于一个区间。
∙每个区间都必须被定位并且只能定位在一个数据文件内。
数据文件中的空间可以被分配为一个或多个区间。
∙每个Oracle数据块都必须由一个或多个操作系统块组成。
每个操作系统块都可以是并且只能是一个Oracle数据块的部分。
1、物理存储结构物理结构是操作系统操作Oracle数据库时能够看见的结构。
1.1、Oracle数据文件数据文件由下列3部分组成:头部、区间(已分配的空间)以及空闲空间(未分配的空间)。
oracle16数据文件的头部(Header)将其标识为数据库的一部分,并且存储了该数据文件的细节,细节包括数据文件所属的表空间以及最后执行的检查点。
这样,Oracle就能够在启动时检查所有相关文件是否同步。
数据文件的剩余部分由区间和空闲空间组成,通过创建、删除和更改Oracle的段(Segment)逻辑存储组件就可以对这些剩余部分进行管理。
每个Oracle数据文件都只属于一个表空间。

Oracle-undo-表空间管理Oracle的Undo表空间管理是Oracle数据库中非常重要而又基础的管理工作之一。
因为数据库中的Undo表空间与事务有着紧密的联系,影响着数据库的性能和稳定性。
本文将对Oracle的Undo表空间管理进行详细介绍,包括Undo表空间的概念、作用、管理方法、优化等方面。
一、Undo表空间的概念Undo表空间是用来存储Oracle数据库中操作的回滚信息,主要的作用是进行事务的回滚和恢复。
在Oracle数据库中,事务的ACID属性可以保证数据的完整性和一致性,而Undo表空间就是为了保证事务的ACID属性而存在的。
在Oracle数据库中,Undo表空间分为两种类型:System Undo表空间和User Undo表空间。
系统Undo表空间是由系统自动创建的一个表空间,用于存储系统级的回滚信息,用户不能自己创建或删除该表空间。
而用户Undo表空间则是由用户自己创建的,用来存储用户级别的回滚信息,一个数据库中可以有多个用户Undo表空间。
二、Undo表空间的作用Undo表空间的作用非常重要,它主要用来完成以下几个方面的功能:1. 事务的回滚当某个事务需要回滚时,Oracle会将该事务所做的修改操作写入到Undo表空间中,然后撤销这些操作来回滚事务。
因此Undo表空间的存储能力和速度直接影响着Oracle数据库回滚事务的性能和效率。
2. 数据库恢复当数据库需要恢复时,Oracle会利用Undo表空间中的回滚信息将数据库恢复到特定的时间点。
因此Undo表空间存储的时间范围和存储能力对数据库恢复能力有着直接的影响。
3. MVCC机制在Oracle数据库中,MVCC(多版本并发控制)机制是一种用来实现并发控制的技术,它需要利用Undo表空间中的回滚信息来实现数据的版本控制。
当多个事务同时对一个数据进行操作时,Undo表空间就派上用场了。
三、Undo表空间的管理方法为了更好地管理Undo表空间,我们需要掌握以下几种管理方法:1. 创建Undo表空间在Oracle数据库中,可以通过语句CREATE UNDO TABLESPACE来创建Undo表空间。

ORACLE 中SCHEMA的概念以及数据库,表空间,数据文件等的区别(转)有的人还是对schema的真正含义不太理解,现在我再次整理了一下,希望对大家有所帮助。
我们先来看一下他们的定义:A schema is a collection of database objects (used by a user.).Schema objects are the logical structures that directly refer to the database’s data.A user is a name defined in the database that can connect to and access objects.Schemas and users help database administrators manage database security.从定义中我们可以看出schema为数据库对象的集合,为了区分各个集合,我们需要给这个集合起个名字,这些名字就是我们在企业管理器的方案下看到的许多类似用户名的节点,这些类似用户名的节点其实就是一个schema,schema里面包含了各种对象如tables, views, sequences, stored procedures, synonyms, indexes, clusters, and database links。
一个用户一般对应一个schema,该用户的schema名等于用户名,并作为该用户缺省schema。
这也就是我们在企业管理器的方案下看到schema 名都为数据库用户名的原因。
Oracle数据库中不能新创建一个schema,要想创建一个schema,只能通过创建一个用户的方法解决(Oracle中虽然有create schema语句,但是它并不是用来创建一个schema的),在创建一个用户的同时为这个用户创建一个与用户名同名的schem并作为该用户的缺省shcema。

oracle数据库体系架构详解在学习oracle中,体系结构是重中之重,⼀开始从宏观上掌握它的物理组成、⽂件组成和各种⽂件组成。
掌握的越深⼊越好。
在实际⼯作遇到疑难问题,其实都可以归结到体系结构中来解释。
体系结构是对⼀个系统的框架描述。
是设计⼀个系统的宏观⼯作。
这好⽐建⼀栋⼤楼。
你⾸先应该以图纸的⽅式把整个⼤楼的体系架构描述出来。
然后⼀点点的往⾥⾯填充东西。
下⾯我们先以⼀个图解的⽅式对oracle体系结构有⼀个基本了解根据⽰图,便于我们记忆,⽰图分三部分组成,左侧User Process、Server Process、PGA可以看做成Clinet端,上⾯的实例(Instance)和下⾯的数据库(Database)及参数⽂件(parameter file)、密码⽂件(password file)和归档⽇志⽂件(archived logfiles)组成Oracle Server,所以整个⽰图可以理解成⼀个C/S架构。
Oracle Server由两个实体组成:实例(instance)与数据库(database)。
这两个实体是独⽴的,不过连接在⼀起。
在数据库创建过程中,实例⾸先被创建,然后才创建数据库。
在典型的单实例环境中,实例与数据库的关系是⼀对⼀的,⼀个实例连接⼀个数据库,实例与数据库也可以是多对⼀的关系,即不同计算机上的多个实例打开共享磁盘系统上的⼀个公⽤数据库。
这种多对⼀关系被称为实际应⽤群集(Real Application Clusters,RAC)RAC极⼤提⾼了数据库的性能、容错与可伸缩性(可能耗费更多的存储空间)并且是oracle⽹格(grid)概念的必备部分。
下⾯我们来详细看⼀下oracle数据库的体系架构Oracle体系架构主要有两⼤部分组成:数据库实例(Instance)和数据库⽂件(database)数据库实例指数据库服务器的内存及相关处理程序,它是Oracle的⼼脏。
与Oracle性能关系最⼤的是SGA(System Global Area,即系统全局区活共享内存区),SGA包含三个部分:1、数据缓冲区,可避免重复读取常⽤的数据;2、⽇志缓冲区,提升了数据增删改的速度,减少磁盘的读写⽽加快速度;3、共享池,使相同的SQL语句不再编译,提升了SQL的执⾏速度。

表空间(TABLESPACE)表空间(TABLESPACE)是ORACLE数据库中最大的逻辑结构。
ORACLE数据库是由一个或多个表空间组成的。
它在物理上与磁盘上的数据文件相对应(一个表空间由一个或多个数据文件组成,但一个数据文件只能属于一个表空间)。
从物理上说数据库的数据被存放在数据文件中,而从逻辑上说是被存放在表空间中的。
数据库的逻辑配置实际上就是指表空间的配置。
一、表空间概述表空间是ORACLE数据库中最大的逻辑结构。
数据库的所有对象和方案都被逻辑的保存在表空间中。
(一)表空间的特性与作用数据库管理系统(DBMS)是建立在操作系统(OS)基础上的,它的数据也必须存储在各个文件中,如数据文件、重做日志文件、归档日志文件等。
表不是文件,表不是空间。
表空间是组织结构和分配空间的逻辑结构。
除了数据文件之外,控制文件、重做日志文件、归档日志文件等其他文件都不属于任何表空间。
表空间的特性如下:1.一个数据库可以有多个表空间。
可以在数据库中创建、删除表空间;2.一个表空间只属于一个数据库;3.一个表空间必须要有一个数据文件;4.一个表空间的大小等于其中所有数据文件的大小之和。
数据库的大小等于其中所有表空间的大小之和;5.表空间可以被联机和脱机。
SYSTEM表空间不能被脱机;6.表空间可以在读写、只读状态之间切换;7.每个表空间由一个或多个物理存在的操作系统的数据文件组成。
这种数据文件可以具有固定的大小,或允许其自动变大。
可以在表空间中添加、删除数据文件;8.方案对象、表、索引的数据都被存储在表空间的数据文件中。
一个数据文件存储不下,就存储在另一个数据文件中,只要该数据文件是本表空间中的就可以;9.一个用户默认使用一个表空间,但他的不同方案对象的数据可以被存储在不同表空间中;10.一个用户使用的表空间的数量是有一定配额的,不能超出这个配额;11.可以根据使用目的,创建不同类型的表空间,如永久表空间、临时表空间、撤销表空间、大表空间等。

Oracle tablespace (表空间)的创建、删除、修改、扩展及检查等oracle 数据库表空间的作用1.决定数据库实体的空间分配;2.设置数据库用户的空间份额;3.控制数据库部分数据的可用性;4.分布数据于不同的设备之间以改善性能;5.备份和恢复数据。
--oracle 可以创建的表空间有三种类型:1.temporary: 临时表空间,用于临时数据的存放;create temporary tablespace "sample"......2.undo : 还原表空间. 用于存入重做日志文件.create undo tablespace "sample"......3.用户表空间: 最重要,也是用于存放用户数据表空间create tablespace "sample"......--注:temporary 和undo 表空间是oracle 管理的特殊的表空间.只用于存放系统相关数据.--oracle 创建表空间应该授予的权限1.被授予关于一个或多个表空间中的resource特权;2.被指定缺省表空间;3.被分配指定表空间的存储空间使用份额;4.被指定缺省临时段表空间。
select tablespace_name "表空间名称",status "状态",extent_management "区管理方式",allocation_type "磁盘扩展管理方式",segment_space_management "段管理方式" from dba_tablespaces;--查询各个表空间的区、段管理方式--1、建立表空间--语法格式:create tablespace 表空间名datafile '文件标识符' 存储参数[...]|[minimum extent n] --设置表空间中创建的最小范围大小|[logging|nologging]|[default storage(存储配置参数)]|[online|offline]; --表空间联机\脱机|[permanent|temporary] --指定该表空间是用于保存永久的对象还是只保存临时对象 |[...]--其中:文件标识符=’文件名’[size整数[k\m][reuse]--实例create tablespace data01datafile '/oracle/oradata/db/data01.dbf' size 500muniform size 128k; --指定区尺寸为128k,如不指定,区尺寸默认为64kcreate tablespace "test"loggingdatafile 'd:\oracle\oradata\oracle\sample.ora' size 5m,'d:\oracle\oradata\oracle\dd.ora' size 5mextent management localuniform segment space managementauto;--详解/*第一: create tablespace "sample"创建一个名为"sample" 的表空间.对表空间的命名,遵守oracle 的命名规范就可了. 第二: logging 有nologging 和logging 两个选项,nologging: 创建表空间时,不创建重做日志.logging 和nologging正好相反, 就是在创建表空间时生成重做日志.用nologging时,好处在于创建时不用生成日志,这样表空间的创建较快,但是没能日志,数据丢失后,不能恢复;但是一般我们在创建表空间时,是没有数据的,按通常的做法,是建完表空间,并导入数据后,是要对数据做备份的;所以通常不需要表空间的创建日志,因此,在创建表空间时,选择nologging,以加快表空间的创建速度.第三: datafile 用于指定数据文件的具体位置和大小.datafile 的文件是建立表空间后创建的,不过文件路径必须存在才是合法的datafile设置如: datafile 'd:\oracle\oradata\ora92\luntan.ora' size 5m说明文件的存放位置是'd:\oracle\oradata\ora92\luntan.ora' , 文件的大小为5m.如果有多个文件,可以用逗号隔开:如:datafile 'd:\oracle\oradata\ora92\luntan.ora' size 5m, 'd:\oracle\oradata\ora92\ dd.ora' size 5m但是每个文件都需要指明大小.单位以指定的单位为准如5m 或500k.对具体的文件,可以根据不同的需要,存放大不同的介质上,如磁盘阵列,以减少io竟争. 指定文件名时,必须为绝对地址,不能使用相对地址.第四: extent management local 存储区管理方法在字典中管理(dictionary):将数据文件中的每一个存储单元做为一条记录,所以在做dm操作时,就会产生大量的对这个管理表的delete和update操作.做大量数据管理时,将会产生很多的dm操作,严得的影响性能,同时,长时间对表数据的操作,会产生很多的磁盘碎片.本地管理(local):用二进制的方式管理磁盘,有很高的效率,同进能最大限度的使用磁盘.同时能够自动跟踪记录临近空闲空间的情况,避免进行空闲区的合并操作。

ST_Geometry教程ArcGIS GeoDatabase ST_Geometry简介1使⽤ST_Geometry存储空间数据(oracle)1.1简介ArcSDE for Oracle提供了ST_Geometry类型来存储⼏何数据。
ST_Geometry是⼀种遵循ISO和OGC规范的,可以通过SQL直接读取的空间信息存储类型。
采⽤这种存储⽅式能够更好的利⽤oracle的资源,更好的兼容oracle的特征,⽐如复制和分区,并且能够更快的读取空间数据。
使⽤ST_Geometry存储空间数据,可以把业务数据和空间数据存储到⼀张表中(使⽤SDENBLOB⽅式业务数据和空间数据是分开存储在B表和F表中的),因此可以很⽅便的在业务数据中增加空间数据(只需要在业务表中增加ST_Geometry列)。
使⽤这种存储⽅式还能够简化多⽤户的读取,管理(只需要管理⼀张表)。
从ArcGIS 9.3开始,新的ArcSDE geodatabases for Oracle 会默认使⽤ST_Geometry ⽅式来存储空间数据。
它实现了SQL3规范中的⽤户⾃定义类型(user-defined data types),允许⽤户使⽤ST_Geometry类型创建列来存储诸如界址点,街道,地块等空间数据。
使⽤ST_Geometry类型存储空间数据,具有以下优势:1)通过SQL函数(ISO SQL/MM 标准)直接访问空间数据;2)使⽤SQL语句存储、检索操纵空间数据,就像其他类型数据⼀样。
3)通过存储过程来进⾏复杂的空间数据检索和分析。
4)其他应⽤程序可以通过SQL语句来访问存储在geodatabase中的数据。
从ArcGIS 9.3开始,新的ArcSDE geodatabases for Oracle 要求所以ST 函数调⽤的时候前⾯都要加上SDE schema名称。
例如:要对查询出来的空间数据进⾏union操作,则SQL 函数需要这样写:"sde.ST_Union",在9,2版本之前,可以不加SDE schema名称。
数据库中的空间数据存储与查询方法在数据库中,空间数据存储与查询是一个重要的主题。
随着信息技术的不断发展,空间数据扮演着越来越重要的角色,例如地理信息系统(GIS)、导航应用、位置服务等等。
数据库管理系统(DBMS)因此需要提供专门的存储和查询方法来处理这些空间数据。
本文将重点讨论数据库中的空间数据存储与查询方法,并介绍一些常用的技术和工具。
一、空间数据存储1. 空间数据类型在数据库中存储空间数据,首先需要使用适当的数据类型。
常见的空间数据类型有点(Point)、线(Line)、面(Polygon)等。
这些数据类型可以通过标准的几何模型(如欧几里得几何、曲线几何等)进行表示。
例如,在关系数据库中,可以使用几何对象封装语言(Geometry Object Model)来定义和管理这些空间数据类型。
2. 空间索引由于空间数据的特殊性,常规索引无法满足其存储和查询的需求。
因此,需要使用专门的空间索引来提高查询性能。
常见的空间索引包括四叉树(Quadtree)、R树(R-tree)等。
这些索引结构能够将空间数据按照层次结构进行组织,并高效地支持范围查询、距离查询等操作。
3. 空间数据编码为了有效地存储和传输空间数据,需要对其进行编码。
常见的空间数据编码方式包括Well-Known Text(WKT)、Well-Known Binary (WKB)、GeoJSON等。
这些编码方式能够将空间数据转换为文本或二进制格式,以便于在数据库中进行存储和查询。
二、空间数据查询1. 空间查询语言为了方便用户使用数据库中的空间数据,需要提供一种专门的查询语言。
常见的空间查询语言包括SQL/MM标准中定义的空间查询语言、OGC的Simple Feature Access标准中定义的查询语言等。
这些查询语言能够支持复杂的空间查询操作,如距离查询、相交查询、邻域查询等。
2. 空间查询操作在数据库中进行空间查询,常见的操作包括空间过滤、空间约束、空间连接等。
oracle中varchar2类型一、概述在Oracle数据库中,VARCHAR2是一种常用的数据类型,它用于存储可变长度的字符数据。
VARCHAR2类型可以存储最大长度为4000字节的字符数据,而且它可以动态地增加或减少存储空间。
二、VARCHAR2类型的特点1. 可变长度VARCHAR2类型是可变长度的,这意味着它可以动态地增加或减少存储空间。
当一个VARCHAR2列被定义时,必须指定它的最大长度。
然而,在实际使用中,如果存储的数据不到最大长度,则只会占用实际需要的空间。
2. 存储容量在Oracle数据库中,VARCHAR2类型可以存储最大长度为4000字节的字符数据。
如果要存储更长的字符数据,则需要使用CLOB类型。
3. 存储方式VARCHAR2类型以变长方式存储字符数据。
在Oracle数据库中,每个VARCHAR2值都包含两个字节的前缀信息,该信息描述了该值所占用的字节数。
4. 数据比较在Oracle数据库中,VARCHAR2类型采用二进制排序方式进行比较。
这意味着,在进行字符串比较时会考虑到字符编码和排序规则。
三、VARCHAR2类型的使用方法1. 定义列时指定最大长度在创建表时定义列时可以指定该列所能容纳的最大长度,例如:CREATE TABLE mytable (id NUMBER,name VARCHAR2(20),email VARCHAR2(50));在上面的例子中,name列最多可以容纳20个字符,email列最多可以容纳50个字符。
2. 插入数据时指定长度在插入数据时,可以通过指定字符串的长度来控制该字符串在数据库中所占用的空间大小。
例如:INSERT INTO mytable (id, name, email) VALUES (1, 'John','****************');INSERT INTO mytable (id, name, email) VALUES (2, 'Jane','****************');在上面的例子中,第一条插入语句中的name和email值都不到其最大长度,因此它们只会占用实际需要的空间;而第二条插入语句中的name和email值都达到了其最大长度,因此它们将会占用完整的空间。
oracle交换分区原理Oracle交换分区原理概述在Oracle数据库中,交换分区是一种特殊的分区类型,用于管理和优化数据库的存储和性能。
交换分区可以用于存储临时数据和排序数据,并在需要时动态地分配和释放存储空间。
本文将介绍Oracle 交换分区的原理及其应用。
1. 交换分区的作用交换分区在数据库管理中扮演着重要的角色,其主要作用包括:- 临时存储:交换分区可以用于存储临时数据,如临时表、排序数据等。
通过将这些数据存储在交换分区中,可以避免占用其他分区的存储空间。
- 优化性能:交换分区可以提高查询和排序操作的性能。
由于交换分区是专门设计用于处理临时数据的,所以它们通常会使用更高效的存储结构和算法,从而提高查询和排序的速度。
2. 交换分区的原理交换分区的原理主要包括以下几个方面:- 动态存储管理:交换分区使用动态存储管理机制,它可以根据需要动态地分配和释放存储空间。
当需要存储临时数据时,数据库会自动分配一块交换分区,并在不再需要时释放它。
- 存储结构优化:交换分区通常使用一种称为“排序堆”的存储结构,这种结构可以提高排序操作的性能。
排序堆通过将临时数据按照特定的排序规则进行排序,从而使查询和排序操作更加高效。
- 数据写入控制:为了提高写入性能,交换分区采用了一种称为“快速写入”的机制。
快速写入可以将数据直接写入交换分区的内存结构中,而不需要进行磁盘IO操作,从而提高写入速度。
3. 交换分区的应用交换分区在实际应用中有广泛的用途,例如:- 临时表空间:交换分区可以用作临时表空间,用于存储临时表和排序数据。
通过将临时表存储在交换分区中,可以避免占用其他表空间的存储空间,并提高查询和排序的性能。
- 索引重建:交换分区可以用于重建索引。
在重建索引时,可以将原始索引的数据存储在交换分区中,从而避免占用其他表空间的存储空间,并提高重建索引的速度。
- 数据导入和导出:交换分区可以用于数据导入和导出操作。
通过将要导入或导出的数据存储在交换分区中,可以提高数据导入和导出的速度。
oracle storage参数Oracle存储参数是在Oracle数据库中用来控制存储结构和存储行为的重要设置。
合理配置这些参数可以提高数据库的性能和可用性。
本文将介绍一些常用的Oracle存储参数,包括数据文件、表空间、日志文件和缓冲区等。
一、数据文件参数1. 数据文件大小(DB_BLOCK_SIZE):指定数据库块的大小,一般为4KB或8KB。
较小的块大小适合处理小型事务,而较大的块大小适合处理大型事务。
2. 数据文件自动扩展(AUTOEXTEND):指定数据文件是否可以自动扩展。
当数据文件满了时,自动扩展可以避免数据库停机。
3. 数据文件增长率(NEXT):指定数据文件每次扩展的大小。
合理设置增长率可以避免频繁的扩展操作,提高数据库性能。
二、表空间参数1. 表空间类型(BIGFILE/SMALLFILE):指定表空间是使用大文件还是小文件。
大文件表空间可以提供更大的存储容量,但可能会影响备份和恢复速度。
2. 表空间大小(SIZE):指定表空间的初始大小。
根据数据库的需求和预估的数据增长率,合理设置表空间大小可以避免空间浪费和频繁的扩展操作。
3. 表空间自动扩展(AUTOEXTEND):指定表空间是否可以自动扩展。
当表空间满了时,自动扩展可以避免数据库停机。
三、日志文件参数1. 日志文件大小(LOG_FILE_SIZE):指定日志文件的大小。
较大的日志文件可以减少频繁的切换操作,提高数据库性能。
2. 日志文件组数(LOG_FILE_GROUPS):指定日志文件的组数。
多个日志文件组可以提高并发写入的能力,增加数据库的容错性。
3. 日志文件切换(LOG_SWITCH_WAIT):指定日志文件切换的时间间隔。
合理设置切换间隔可以平衡日志文件的使用和性能。
四、缓冲区参数1. 数据库缓冲区大小(DB_CACHE_SIZE):指定数据库缓冲区的大小。
较大的缓冲区可以提高数据库的响应速度和查询性能。
2. 共享池大小(SHARED_POOL_SIZE):指定共享池的大小。
oracle数据库面试题Oracle数据库面试题Oracle是一种关系型数据库管理系统,广泛应用于企业级应用程序开发和数据存储。
在面试过程中,掌握Oracle数据库相关知识是非常重要的。
本文将为您总结一些常见的Oracle面试题,帮助您进行面试准备。
问题一:什么是Oracle数据库?它的特点是什么?Oracle数据库是一种关系型数据库管理系统,由美国Oracle公司开发。
它具有以下特点:1. 高度可靠性:Oracle数据库采用多种机制保证数据的可靠性,如日志文件和闪回技术,可以最大程度地防止数据丢失和损坏。
2. 可扩展性:Oracle数据库可以在不同的硬件平台上进行部署,并能够快速适应不断增长的数据量和用户需求。
3. 高性能:Oracle数据库采用了先进的查询优化和并行处理技术,可以高效地处理大量数据,并提供快速的查询响应时间。
4. 数据安全性:Oracle数据库提供了多种安全特性,包括用户权限管理、数据加密和审计功能,可以保护数据免受未经授权的访问和攻击。
5. 丰富的功能:Oracle数据库支持多种数据类型和功能,如分区表、索引、触发器等,满足各种应用程序的需求。
问题二:Oracle数据库的体系结构是什么样的?Oracle数据库的体系结构主要包括以下组件:1. 实例(Instance):实例是Oracle数据库在内存中运行的副本,负责管理数据库的访问和操作。
每个数据库可以拥有一个或多个实例。
2. 数据库(Database):数据库是物理存储设备上的数据文件集合,由数据文件、控制文件和日志文件组成。
一个实例可以管理一个或多个数据库。
3. 数据字典(Data Dictionary):数据字典是Oracle数据库中的元数据信息存储区域,包含了数据库对象的结构和定义信息。
4. 进程(Process):Oracle数据库有多个后台进程和前台进程,它们负责执行数据库的各种任务,如内存管理、I/O操作和查询处理等。
Oracle数据库中空间数据类型随着GIS、CAD/CAM的广泛应用,对数据库系统提出了更高的要求,不仅要存储大量空间几何数据,且以事物的空间关系作为查询或处理的主要内容。
Oracle数据库从9i开始对空间数据提供了较为完备的支持,增加了空间数据类型和相关的操作,以及提供了空间索引功能。
Oracle的空间数据库提供了一组关于如何存储,修改和查询空间数据集的SQL schema与函数。
通过MDSYS schema规定了所支持的地理数据类型的存储、语法和语义,提供了R-tree空间数据索引机制,定义了关于空间的相交查询、联合查询和其他分析操作的操作符、函数和过程,并提供了处理点,边和面的拓扑数据模型及表现网络的点线的网络数据模型。
Oracle中各种关于空间数据库功能主要是通过Spatial组件来实现。
从9i版本开始,Oracle Spatial空间数据库组件对存储和管理空间数据提供了较为完备的支持。
其主要通过元数据表、空间数据字段(即SDO_GEOMETRY字段)和空间索引来管理空间数据,并在此基础上提供一系列空间查询和空间分析的函数,让用户进行更深层次的GIS应用开发。
Oracle Spatial使用空间字段SDO_GEOMETRY存储空间数据,用元数据表来管理具有SDO_GEOMETRY字段的空间数据表,并采用R树索引和四叉树索引技术来提高空间查询和空间分析的速度。
1、元数据表说明。
Oracle Spatial的元数据表存储了有空间数据的数据表名称、空间字段名称、空间数据的坐标范围、坐标参考信息以及坐标维数说明等信息。
用户必须通过元数据表才能知道ORACLE数据库中是否有Oracle Spatial的空间数据信息。
一般可以通过元数据视图(USER_SDO_GEOM_METADATA)访问元数据表。
元数据视图的基本定义为:(TABLE_NAME V ARCHAR2(32),COLUMN_NAME V ARCHAR2(32),DIMINFO MDSYS.SDO_DIM_ARRAY,SRID NUMBER);其中,TABLE_NAME为含有空间数据字段的表名,COLUMN_NAME为空间数据表中的空间字段名称,DIMINFO是一个按照空间维顺序排列的SDO_DIM_ELEMENT对象的动态数组,SRID则用于标识与几何对象相关的空间坐标参考系。
SDO_DIM_ELEMENT对象的定义如下所示:Create Type SDO_DIM_ELEMENT as OBJECT (SDO_DIMNAME V ARCHAR2(64),SDO_LB NUMBER,SDO_UB NUMBER,SDO_TOLERANCE NUMBER);其中,SDO_DIMNAME是空间维名称,SDO_LB为该空间维的左下角坐标,SDO_UB为该空间维的右上角坐标,SDO_TOLERANCE为几何对象的表示精度。
2、空间字段说明Oracle Spatial的空间数据都存储在空间字段SDO_GEOMETRY中,理解SDO_GEOMETRY是编写Oracle Spatial接口程序的关键。
SDO_GEOMETRY是按照OpenGIS规范定义的一个对象,其原始的创建方式如下所示:CREATE TYPE sdo_geometry AS OBJECT (SDO_GTYPE NUMBER,SDO_SRID NUMBER,SDO_POINT SDO_POINT_TYPE,SDO_ELEM_INFO MDSYS.SDO_ELEM_INFO_ARRAY,SDO_ORDINATES MDSYS.SDO_ORDINATE_ARRAY);该对象由五个部分组成,下面分别介绍这五个部分的定义方法。
SDO_GTYPE是一个NUMBER型的数值,用来定义存储对象的类型。
SDO_SRID 也是一个NUMBER型的数值,它用于标识与几何对象相关的空间坐标参考系,Oracle Spatial规定,一个几何字段中的所有几何对象都必须为相同的SDO_SRID 值。
SDO_POINT是一个包含X,Y,Z数值信息的对象,用于表示几何类型为点的几何对象。
SDO_ELEM_INFO是一个可变长度的数组,每3个数作为一个元素单位,用于解释坐标是如何存储在SDO_ORDINATES数组中的。
SDO_ORDINATES是一个可变长度的数组,用于存储几何对象的真实坐标,该数组的类型为NUMBER型,它的最大长度为1048576。
SDO_ORDINATES必须与SDO_ELEM_INFO数组配合使用,才具有实际意义。
3、空间索引技术Oracle Spatial索引主要提供两个功能:找到一个区域中的空间对象,找到两个空间对象的交集。
为此,Spatial提供了R树索引和四叉树索引两种索引机制来提高空间查询和空间分析的速度。
R-Tree索引能代替线性四叉树索引或和其一起使用。
R-Tree索引不仅仅能对2D数据进行索引,同时对3D、4D数据也可进行索引。
空间R-tree索引最高能定位四维空间。
一个R-tree索引近似的使用单个MBR来代表一个地理对象。
它存储在空间索引表(USER_SDO_INDEX_METADATA视图中的SDO_INDEX_TABLE字段所指的空间索引表,如果你去查找那个字段内容,只会看到一堆二进制)。
同时R-tree 索引还维护一个sequence对象(USER_SDO_INDEX_METADATA表中的SDO_RTREE_SEQ_NAME字段)。
创建R树索引:CREATE INDEX territory_idx ON territories (territory_geom)INDEXTYPE IS MDSYS.SPATIAL_INDEX;创建四叉树索引:CREATE INDEX ROADS_FIXED ON ROADS(SHAPE) INDEXTYPE IS MDSYS.SPATIAL_INDEXPARAMETERS(‘SDO_LEVEL=8’);4、查询模型说明Oracle Spatial使用两层查询模型来解决查询与空间过滤的问题。
模型使用两个不同目的的操作来加快查询过程。
而输出的结果是这两个操作组合结果。
这两个操作为primary与secondary操作:1.primary过滤操作:使用地理上近似的查询操作来减小计算的复杂度。
因为这个查询是近似,所以它产生一个比较大的结果集,这个结果集是给secondary 过滤操作使用。
2.secondary过滤操作:在primary过滤出来的结果集上使用精确的计算来得到最后精度的空间过滤结果集。
因为这个计算过程是很昂贵的,所以它只在primary过滤出来的结果集上计算。
Spatial使用空间索引来实现primary过滤。
Spatial并不强求使用一定要使用primary与secondary过滤组合。
在很多情况下,光一个primary过滤就足够了。
例如一个放大操作中,应用程序只要得到与一个矩形框相交的地理区域中的内容。
这时,primary过滤就可以非常快的返回一个大集合,而应用程序可以使用减切路径来只显示出目标区域来。
Spataial使用secondary过滤器来决定空间关系。
空间关系决定于地理位置。
最通用的空间关系是基于拓扑与距离的。
为了决定空间关系,Spatail有很多secondary过滤器:SDO_RELATE操作指出拓扑关系。
它实现了九个交叠模型在点,线与多边形中间分类两个空间对象的拓扑关系,每个对象都有包含,交叠与不包含三种。
SDO_WITHIN_DISTANCE操作决定两个空间对象是否在某个指定的距离中。
SDO_NN操作指出离某个空间对象最近的对象。
SDO_WITHIN_DISTANCE操作符判断两个对象是否在一个指定的距离内,这个操作在B对象的周围建立一个为指定距离的区域,然后看A是否与这个区域相交。
SDO_NN操作返回在一个对象周围指定数目的最近对象。
下面一个在Oracle中构建空间数据库并对空间数据库进行增、删、改操作的实例。
通过这个实例可以看到Oracle中构建空间数据库功能强大,且实现十分简单。
首先建立一个城市表(用来表示彼此相连的城市)和关系表(用来表示城市之间的公路)。
Create table cities(Location mdsys.sdo_geometry // 城市位置Geom mdsys.sdo_geometry, // 城市边界City varchar2(42), // 城市名State_abrv varhar2(2), // 所属省份Pop number, // 人口数量Poppsqmi number); // 人口密度Create table interstates(Geom mdsys.sdo_geometry, // 城市间地形Highway varchar2(35)); // 高速路名接下来将限制条件插入到USER_SDO_GEOM_METADATA中:Insert into USER_SDO_GEOM_METADATA(table_name, colum_name, diminfo, srid)Values( ‘cities’, ‘location’,Mdsys.sdo_dim_array(mdsys.sdo_dim_element (‘x’, -180.000000000, 180.000000000, 0.000000050),mdsys.sdo_dim_element (‘y’, -90.000000000, 90000000000, 0.000000050),),Null);Insert into USER_SDO_GEOM_METADATA(table_name, colum_name, diminfo, srid)Values( ‘cities’, ‘geom’,Mdsys.sdo_dim_array(mdsys.sdo_dim_element (‘x’, -180.000000000, 180.000000000, 0.000000050),mdsys.sdo_dim_element (‘y’, -90.000000000, 90000000000, 0.000000050),),Null);Insert into USER_SDO_GEOM_METADATA(table_name, colum_name, diminfo, srid)Values( ‘interstates’, ‘geom’,Mdsys.sdo_dim_array(mdsys.sdo_dim_element (‘x’, -180.000000000, 180.000000000, 0.000000050),mdsys.sdo_dim_element (‘y’, -90.000000000, 90000000000, 0.000000050),),Null);现在需要为数据库建立索引:Create indes idx_intestates on interstates(geom)Indextype is mdsys.spatial_indexParameters(‘sdo_level = 9);以上是建立空间数据库的一些工作。