hashcode计算方法
- 格式:docx
- 大小:37.18 KB
- 文档页数:3

c语言位运算计算hash码一、概述在计算机科学和信息技术领域中,hash码是一种重要的数据结构,它能够将数据映射到一个固定长度的唯一标识符上。
在实际应用中,hash码常常被用于加速数据存储和查找的速度,因此对于计算hash 码的方法和效率的研究变得尤为重要。
而位运算作为c语言中的一种常用操作,其高效的处理速度,使得它成为计算hash码的一个重要工具。
本文将介绍位运算在c语言中计算hash码的方法及其实际应用。
二、位运算的基础知识1. 位运算的基本操作位运算是指对二进制数进行的一种操作,其基本操作包括与()、或(|)、异或(^)、取反(~)、左移(<<)和右移(>>)等。
这些操作可以对二进制数据进行高效的处理,常用于编写底层的算法和数据结构。
2. 位运算的特点位运算具有处理速度快、空间效率高等特点,适合于对大规模数据进行高效的处理。
在计算hash码中,合理地利用位运算可以大大提高计算速度和节省计算资源。
三、哈希算法1. 哈希算法的概念哈希算法是指将任意长度的输入数据通过哈希函数变换为固定长度的输出数据的过程。
这个输出数据即为哈希码。
哈希算法常常用于数据加密、数据完整性校验、数据查找等方面。
2. 常见的哈希算法常见的哈希算法包括MD5、SHA-1、SHA-256等。
这些算法具有不同的特点和适用范围,但都能够将输入数据映射为固定长度的哈希码。
四、位运算计算哈希码1. 位运算在哈希码计算中的作用位运算可以通过对二进制数据的操作,使得在计算哈希码时可以高效地进行数据处理。
在c语言中,位运算常常被用于哈希码的计算中,尤其适用于处理大规模数据。
2. 位运算计算哈希码的原理位运算在计算哈希码时,通常通过将数据转换为二进制形式,并利用位运算的与、或、异或等操作进行数据处理。
通过合理地设计位运算的规则,可以得到固定长度的哈希码,并保证数据的唯一性和不可逆性。
3. 位运算计算哈希码的实际应用在实际应用中,位运算计算哈希码常常用于大规模数据的处理和存储。

使用shell实现java的hashcode方法使用s h e l l实现J a v a的h a s h C o d e方法在J a v a中,h a s h C o d e方法是O b j e c t类中的一个方法,用于返回对象的哈希码。
哈希码是根据对象内部的状态、属性等计算得出的一个整数值,用于快速定位和比较对象。
默认情况下,h a s h C o d e方法返回的是对象的内存地址的整数表示。
然而,实际上我们可以根据实际需求来重写h a s h C o d e方法,以实现更好的哈希算法。
在本文中,我们将探讨如何使用s h e l l脚本来实现J a v a的h a s h C o d e方法。
我们将以实现一个简单的字符串h a s h C o d e算法为例。
步骤一:创建一个s h e l l脚本文件首先,我们需要创建一个新的s h e l l脚本文件。
可以使用任何文本编辑器,如记事本、V i编辑器等。
假设我们将文件命名为h a s h c o d e.s h。
步骤二:定义输入参数在创建的s h e l l脚本文件中,我们需要定义一个输入参数,即待计算哈希码的字符串。
我们可以使用s h e l l脚本的特殊变量1来获取用户输入的第一个参数。
在脚本文件中,可以通过以下方式获取输入的字符串:获取输入参数i n p u t_s t r i n g=1步骤三:计算字符串长度下一步,我们需要计算待计算字符串的长度。
可以使用s h e l l脚本的内置函数`e x p r l e n g t hi n p u t_s t r i n g`来获取待计算字符串的长度。
在脚本文件中,可以通过以下方式来计算字符串长度:计算字符串长度i n p u t_l e n g t h=`e x p r l e n g t h i n p u t_s t r i n g`步骤四:计算哈希值完成了前面的准备工作后,我们可以开始计算哈希值了。

java hashcode计算方法
Java中的hashcode计算方法是一种将对象映射为整数的算法。
在Java中,hashcode方法是由Object类定义的,并且默认实现是返回对象的地址值的哈希码。
这意味着,如果两个对象在堆中的地址不同,它们的哈希码也不同。
但是,许多Java类都会重写hashcode方法,以便在实际使用中更好地支持哈希表和其他数据结构。
例如,String类的hashcode方法返回字符串中所有字符的乘积,而HashMap类使用类似的算法来分配桶。
通常情况下,hashcode方法应该满足以下几个条件:
1. 如果两个对象相等,则它们的hashcode值必须相等。
2. 如果两个对象不相等,则它们的hashcode值不一定不相等。
3. hashcode值应该在对象的生命周期内保持不变。
4. 如果两个对象的equals()方法返回true,则它们的hashcode 值必须相同。
但是,如果两个对象的hashcode值相同,则它们的equals()方法不一定返回true。
在实际编程中,我们可以使用IDE自动生成的hashcode方法,也可以手动编写自己的hashcode方法,以便更好地满足我们的具体需求。
无论哪种方式,我们都应该了解hashcode计算方法的原理和规则,以便在使用中避免出现不必要的错误。
- 1 -。

equals和hashcode方法嘿,咱今儿就来唠唠这 equals 和 hashcode 方法。
你说这 equals 方法啊,就好比是一个超级侦探,专门负责判断两个东西是不是真的一模一样。
它可精细着呢,能从里到外仔细对比,不放过任何一个小细节。
比如说有两个苹果,它得看看颜色是不是一样红,形状是不是一样圆,有没有斑点啥的,只有完全一样,它才会说“嘿,这俩确实相等”。
那这 hashcode 方法又是啥呢?它就像是给每个东西一个独特的标签。
就像每个人都有自己的身份证号一样,通过这个标签能快速找到对应的东西。
而且啊,它得尽量让不同的东西有不同的标签,不然不就乱套啦?咱来打个比方吧,想象一下图书馆里的书。
每本书都有自己的书名、作者、内容这些特点,这就像是 equals 方法要去比较的东西。
而每本书也都有一个独一无二的编码,这就是 hashcode 方法给它的标记。
工作人员根据这个编码就能快速找到那本书,多方便呀!在编程里,要是咱只重 equals 方法而忽略了 hashcode 方法,那不就像只知道这个人长啥样,却不知道他住哪儿一样,找起来得多费劲呀!反过来,要是只关注 hashcode 方法,那可能会把完全不一样的东西当成一样的,那不就闹笑话啦?你想想看,如果在一个集合里,两个明明不一样的东西,因为hashcode 方法出了问题被当成一样的,那不乱套了吗?就好像把猫和狗当成同一种动物,这多荒唐呀!所以呀,这 equals 和 hashcode 方法可得好好配合。
它们就像一对好搭档,一个负责精确判断,一个负责快速定位。
只有它们齐心协力,咱写的程序才能顺顺利利地运行,不出岔子。
咱在写代码的时候,可不能随便对待这俩方法。
得认真考虑它们的实现,要让它们符合实际需求,别整出些奇奇怪怪的结果来。
这就跟咱过日子一样,得认真对待每一件事,才能过得舒坦,不是吗?你说,要是没有这两个方法,编程得变得多混乱呀!它们就像是编程世界里的秩序维护者,让一切都有条有理。

字符串的hashcode计算方式
字符串的hashCode计算方式是通过将字符串中每个字符的Unicode编码值进行一定的运算得出的一个哈希值。
具体计算方式为,首先将第一个字符的Unicode编码值作为初始的哈希值,然后依次将后面的字符的Unicode编码值与前面计算得出的哈希值进行一定的运算(通常是乘以一个质数然后加上当前字符的编码值),最终得到的结果就是字符串的hashCode值。
在Java中,String类中的hashCode方法就是根据上述方式计算得出的。
这种计算方式可以很好地保证不同的字符串得到的hashCode值尽可能地不相同,减少哈希冲突的概率。
但是也要注意的是,由于哈希值的范围是有限的,因此不同的字符串可能会有相同的哈希值,这就是哈希冲突。
在实际使用中,我们需要根据具体的情况来处理哈希冲突,常见的方法包括开放寻址法和链表法等。
需要注意的是,不同的编程语言和实现可能会有不同的字符串hashCode计算方式,但大体思想是相似的,都是通过对字符串中的字符进行某种运算得出一个哈希值。
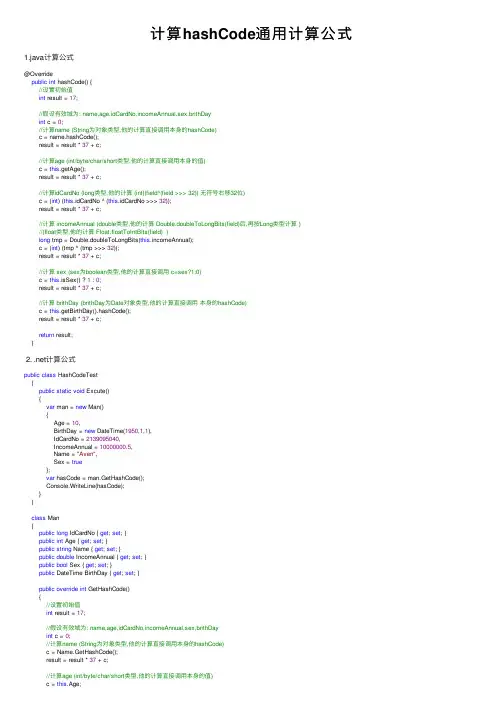
计算hashCode通⽤计算公式1.java计算公式@Overridepublic int hashCode() {//设置初始值int result = 17;//假设有效域为: name,age,idCardNo,incomeAnnual,sex,brithDayint c = 0;//计算name (String为对象类型,他的计算直接调⽤本⾝的hashCode)c = name.hashCode();result = result * 37 + c;//计算age (int/byte/char/short类型,他的计算直接调⽤本⾝的值)c = this.getAge();result = result * 37 + c;//计算idCardNo (long类型,他的计算 (int)(field^(field >>> 32)) ⽆符号右移32位)c = (int) (this.idCardNo ^ (this.idCardNo >>> 32));result = result * 37 + c;//计算 incomeAnnual (double类型,他的计算 Double.doubleToLongBits(field)后,再按Long类型计算 )//(float类型,他的计算 Float.floatToIntBits(field) )long tmp = Double.doubleToLongBits(this.incomeAnnual);c = (int) (tmp ^ (tmp >>> 32));result = result * 37 + c;//计算 sex (sex为boolean类型,他的计算直接调⽤ c=sex?1:0)c = this.isSex() ? 1 : 0;result = result * 37 + c;//计算 brithDay (brithDay为Date对象类型,他的计算直接调⽤本⾝的hashCode)c = this.getBirthDay().hashCode();result = result * 37 + c;return result;}2. .net计算公式public class HashCodeTest{public static void Excute(){var man = new Man(){Age = 10,BirthDay = new DateTime(1950,1,1),IdCardNo = 2139095040,IncomeAnnual = 10000000.5,Name = "Aven",Sex = true};var hasCode = man.GetHashCode();Console.WriteLine(hasCode);}}class Man{public long IdCardNo { get; set; }public int Age { get; set; }public string Name { get; set; }public double IncomeAnnual { get; set; }public bool Sex { get; set; }public DateTime BirthDay { get; set; }public override int GetHashCode(){//设置初始值int result = 17;//假设有效域为: name,age,idCardNo,incomeAnnual,sex,brithDayint c = 0;//计算name (String为对象类型,他的计算直接调⽤本⾝的hashCode)c = Name.GetHashCode();result = result * 37 + c;//计算age (int/byte/char/short类型,他的计算直接调⽤本⾝的值)c = this.Age;result = result * 37 + c;//计算idCardNo (long类型,他的计算 (int)(field^(field >> 32)) 有符号右移32位,符号位不移动)c = (int)(this.IdCardNo ^ (this.IdCardNo >> 32));result = result * 37 + c;//计算 incomeAnnual (double类型,他的计算 BitConverter.DoubleToInt64Bits(field)后,再按Long类型计算 ) //(float类型,他的计算 BitConverter.ToInt32(BitConverter.GetBytes(this.IncomeAnnual),0) ) long tmp = BitConverter.DoubleToInt64Bits(this.IncomeAnnual);c = (int)(tmp ^ (tmp >> 32));result = result * 37 + c;//计算 sex (sex为boolean类型,他的计算直接调⽤ c=sex?1:0)c = this.Sex ? 1 : 0;result = result * 37 + c;//计算 brithDay (brithDay为Date对象类型,他的计算直接调⽤本⾝的hashCode)c = this.BirthDay.GetHashCode();result = result * 37 + c;return result;}}。

hashcode计算方法
HashCode计算方法即Hash函数,常见的有以下几种:
1. 直接取址法:即将数据的存储位置直接作为它的hash值,适用于地址连续的情况。
2. 数字分析法:将数据的关键字转换为数字,然后分析每一个数字对最终的hash值的贡献,适用于数据的关键字具有统计规律或某些位分布不均匀的情况。
3. 平方取中法:将数据平方后取中间几位作为hash值,可以避免一些数位分布不均匀的问题。
4. 折叠法:将数据拆分成相等位数的几段,每一段相加后折叠成一个数字,最后再取余数作为hash值,适用于关键字位数较多的情况。
5. 随机数法:根据一定的随机函数产生hash值,可以避免出现数据中某些特定的数值分布不均匀的问题,但是需要消耗额外的计算资源。

hashmap计算hashcode的算法
HashMap计算hashcode的算法是使用key的哈希值在哈希表中定位元素位置。
具体步骤如下:
1. 对key对象的hashCode()方法返回的哈希码进行简单处理。
HashMap使用一种称为“扰动函数”的算法,可以将哈希码的高位和低位组合起来,重组成一个新的哈希码。
2. 将新哈希码与哈希表容量-1(mask)进行按位与操作。
由于哈希表容量总是2的幂次方,因此容量-1的二进制形式为全1。
3.返回和操作的结果,即使用哈希值在哈希表中定位元素的位置。
这个算法的核心思想是将key的哈希值分散到哈希表的不同位置上,尽可能避免冲突,提高查询效率。

long类型的hashcodeLong类型的hashCode为标题在计算机编程中,hashCode是一个很常见的概念,它用于表示对象的哈希码。
在Java中,每个对象都有一个hashCode方法,该方法返回一个long类型的哈希码。
本文将探讨Long类型的hashCode,包括其计算方法、用途以及可能遇到的问题。
一、Long类型的hashCode计算方法在Java中,Long类型的hashCode是通过将Long类型的值转换为int类型来计算的。
具体而言,对于一个Long类型的对象l,它的hashCode可以通过以下公式来计算:int hashCode = (int)(l^(l>>>32));其中,^表示按位异或操作符,>>>表示无符号右移操作符。
这个公式的目的是将Long类型的高位和低位混合在一起,以产生一个唯一的哈希码。
二、Long类型的hashCode用途hashCode方法在Java中广泛应用于哈希表、哈希集合等数据结构中。
它可以用来快速判断两个对象是否相等,从而提高程序的效率。
在使用哈希表或哈希集合时,我们通常会重写对象的equals方法和hashCode方法,以确保对象在比较和存储时的正确性。
三、可能遇到的问题在使用Long类型的hashCode时,有一些问题需要注意。
首先,hashCode方法返回的是int类型的值,而不是long类型。
这意味着,如果一个Long类型的对象的值非常大,那么它的hashCode 可能会有一定的冲突风险。
因此,在使用Long类型的hashCode 时,我们应该尽量避免使用过大的数值。
Long类型的hashCode计算方法中使用了位运算符,这可能导致一些误解。
例如,如果我们直接打印Long类型对象的hashCode,可能会得到一个负数。
这是因为在计算hashCode时,为了保持int类型的范围,会将最高位的符号位也考虑在内。

java重写hashcode计算方式Java中的hashCode()方法是Object类中的一个方法,它返回一个对象的哈希码值。
哈希码是由对象的地址或者是对象的内容计算得出的一个int类型的整数。
在Java中,哈希码主要用于哈希表、哈希集合和哈希映射等数据结构中。
当我们需要在这些数据结构中存储对象时,需要先计算对象的哈希码,然后根据哈希码来确定对象在数据结构中的位置。
在Java中,hashCode()方法的默认实现是返回对象的内存地址。
但是,如果我们需要在自定义的类中使用哈希表、哈希集合和哈希映射等数据结构,就需要重写hashCode()方法,以便根据对象的内容计算哈希码。
下面是重写hashCode()方法的一般步骤:1. 定义一个int类型的变量result,并初始化为一个非零常数。
2. 对于对象中每个重要的属性,计算出一个int类型的哈希码,然后将其与result进行合并。
3. 对于对象中每个不重要的属性,计算出一个int类型的哈希码,然后将其与result进行合并。
4. 返回result。
以下是一个示例代码,演示如何重写hashCode()方法:```public class Person {private String name;private int age;public Person(String name, int age) { = name;this.age = age;}@Overridepublic int hashCode() {final int prime = 31;int result = 1;result = prime * result + age;result = prime * result + ((name == null) ? 0 : name.hashCode());return result;}}```在上面的代码中,我们重写了Person类的hashCode()方法。

HashCode方法1.把某个非零常数值,比如说17,保存在一个叫result的int类型的变量中。
2.对于对象中每一个关键域f(指equals方法中考虑的每一个域),完成以下步骤:a)为该域计算int类型的散列码c:i.如果该域是boolean类型,则计算(f?0:1)ii.如果该域是byte、char、short或者int类型,则计算(int)f。
iii.如果该域是long类型,则计算(int)(f^(f>>>32))iv.如果该域是float类型,则计算Float.floatToBits(f)。
v.如果该域是double类型,则计算Double.doubleToLongBits(f)得到一个long 类型的值,然后按照步骤2.a.iii,对该long型值计算散列值。
vi.如果该域是一个对象引用,并且该类的equals方法通过递归调用equals的方式来比较这个域,则同样对这个域递归调用hashCode。
如果要求一个更为复杂的比较,则为这个域计算一个“规范表示(canonicalrepresentation)”,然后针对这个范式表示调用hashCode。
如果这个域的值为null,则返回0(或者其他某个常数,但习惯上使用0)。
vii.如果该域是一个数组,则把每一个元素当做单独的域来处理。
也就是说,递归地应用上述规则,对每个重要的元素计算一个散列码,然后根据步骤2.b中的做法把这些散列值组合起来。
b)按照下面的公式,把步骤a中计算得到的散列码c组合到result中:3.返回result。
深刻理解hashcode()方法1. 首先equals()和hashcode()这两个方法都是从object类中继承过来的。
equals()方法在object类中定义如下:public boolean equals(Object obj) {return (this == obj);}很明显是对两个对象的地址值进行的比较(即比较引用是否相同)。
hashcode算法
Hashcode算法通常用于在计算机程序中快速地将一个对象映射为一个整数。
其基本思想是将一个任意长度的输入(例如字符串、文件等)通过哈希函数转换成一个固定长度的输出(通常是一个整数),对于相同输入,哈希函数总是返回相同的输出。
哈希函数的设计需要有以下几个特性:
1. 映射到不同的哈希值的概率应当相等,减少冲突的概率;
2. 哈希函数总是返回相同的哈希值;
3. 输入的改变必须能够正确地反映在哈希值的改变上。
常用的哈希函数有MD5、SHA等。
在Java中,Object类提供了一个hashCode方法,该方法返回一个对象的哈希值。
使用哈希函数可以方便地实现很多数据结构,如哈希表、哈希集合等,以及应用于密码学、负载均衡等领域。
由于哈希函数的性质,它也常常被用来检验数据的完整性和真实性。
总之,哈希函数是计算机领域中一个重要的概念,它能够提高程序效率、保护数据安全,具有广泛的应用价值。
hashcode 生成方法hashcode 是一种用于生成数据的哈希值的方法。
哈希值是一个固定长度的数字,用于唯一标识输入数据。
在计算机科学中,哈希函数的作用非常广泛,它可以用于数据的存储、查找、加密等方面。
哈希函数的生成方法有很多种,常见的有MD5、SHA-1、SHA-256等。
这些方法都是通过对输入数据进行一系列的计算和变换,最终生成一个固定长度的哈希值。
下面我们将介绍其中几种常用的哈希函数生成方法。
首先是MD5算法,它是一种常用的哈希函数生成方法。
MD5算法将输入数据进行分块处理,然后对每个分块进行一系列的位运算和异或运算,最后得到一个128位的哈希值。
MD5算法具有较高的安全性和较快的计算速度,但由于其哈希值长度较短,存在碰撞的可能性。
接下来是SHA-1算法,它是一种较为安全的哈希函数生成方法。
SHA-1算法将输入数据进行分块处理,然后对每个分块进行一系列的位运算和加密运算,最后得到一个160位的哈希值。
SHA-1算法具有较高的安全性和较快的计算速度,但由于其哈希值长度较长,计算效率较低。
除了以上两种常见的哈希函数生成方法外,还有一种比较特殊的方法,即自定义哈希函数。
自定义哈希函数是根据具体的需求和数据特点来设计的,可以根据输入数据的某些特征进行变换和计算,最终生成一个符合要求的哈希值。
自定义哈希函数的优势在于可以根据实际情况进行调整和优化,提高哈希值的唯一性和效率。
在实际应用中,哈希函数的生成方法要根据具体的需求和数据特点来选择。
如果对安全性要求较高,可以选择SHA-1或SHA-256算法;如果对计算速度要求较高,可以选择MD5算法;如果需要自定义哈希函数,可以根据实际情况进行设计和优化。
除了生成哈希值外,哈希函数还可以用于数据的查找和存储。
通过将数据的哈希值与存储空间进行映射,可以快速定位到数据的存储位置,提高数据的访问效率。
在数据库中,哈希函数常用于索引的建立和数据的查找,可以大大提高数据检索的速度。
浅谈Java中hashCode的正确求值⽅法本⽂研究的主要是Java中hashCode的正确求值⽅法的相关内容,具体如下。
散列表有⼀项优化,可以将对象的散列码(hashCode)缓存起来,如果散列码不匹配,就不会检查对象的等同性⽽直接认为成不同的对象。
如果散列码(hashCode)相等,才会检测对象是否相等(equals)。
如果对象具有相同的散列码(hashCode),他们会被映射到同⼀个散列桶中。
如果散列表中所有对象的散列码(hashCode)都⼀样,那么该散列表就会退化为链表(linked list),从⽽⼤⼤降低其查询效率。
⼀个好的散列函数通常倾向于“为不想等的对象产⽣不相等的散列码”。
理想情况下,散列函数应该把集合中不想等的实例均匀地分布到所有可能的散列上,但是想要完全达到这种理想的情形是⾮常困难的,下⾯给出⼀个相对简单有效的散列⽅法:1.把某个⾮零的常数值,⽐如说17,保存在⼀个名为result的int类型的变量中。
2.对于对象中的每个关键域f(指equals⽅法中涉及的每个域),完成以下步骤:为该域计算int类型的散列码c如果该域是boolean类型,则计算 ( f ? 1 : 0 )如果该域是byte、char、short或者int类型,则计算 ( ( int ) f )如果该域是long类型,则计算 ( int ) ( f ^ ( f >>> 32 ) )如果该域是float类型,则计算Float.floatToIntBits(f)如果该域是double类型,则计算Double.doubleToLongBits(f),然后按照上述步骤为得到的long类型值再计算散列值如果该域是⼀个对象引⽤,并且该类的equals⽅法通过递归地调⽤equals的⽅式来⽐较它的域,那么同样为这个域按上述⽅法递归地调⽤hashCode如果该域是⼀个数组,则要把每⼀个元素当作单独的域来处理,递归地应⽤上述原则,如果数组中的每⼀个元素都很重要,也可以直接使⽤Arrays.hashCode⽅法。
hashcode原理HashCode原理是计算机科学中一个非常重要的概念,它在很多领域都有广泛的应用。
HashCode是一种将任意长度的数据映射为固定长度值的算法。
在这篇文章中,我将介绍HashCode的原理及其在计算机科学中的应用。
让我们来了解一下HashCode的原理。
HashCode是一种散列函数,它将输入的数据经过计算后转换为一个固定长度的值。
这个计算过程通常是不可逆的,即无法从HashCode的值推导出原始数据。
HashCode的计算过程是基于输入数据的内容进行的,即相同内容的数据应该具有相同的HashCode值,而不同内容的数据则应该具有不同的HashCode值。
HashCode的计算过程通常包括以下几个步骤:1. 初始化一个HashCode值。
2. 遍历输入数据的每个元素,将每个元素的值与当前的HashCode 值进行运算,得到一个新的HashCode值。
3. 将新的HashCode值作为当前的HashCode值。
4. 重复步骤2和步骤3,直到遍历完所有的元素。
5. 返回最终的HashCode值。
HashCode的计算过程可以使用多种算法实现,例如MD5、SHA-1、SHA-256等。
这些算法通常是经过严格设计和测试的,以确保生成的HashCode值具有较低的冲突率。
HashCode在计算机科学中有广泛的应用。
其中一个主要的应用领域是数据结构中的哈希表。
哈希表是一种使用散列函数来存储和查找数据的数据结构。
在哈希表中,数据被存储在一个数组中,通过计算数据的HashCode值来确定其在数组中的位置。
这样可以实现快速的数据存取操作,时间复杂度通常是O(1)。
除了在数据结构中的应用,HashCode还在其他领域有着重要的作用。
例如,在密码学中,HashCode被用于生成消息摘要,用于验证消息的完整性。
在网络通信中,HashCode被用于数据包的校验和计算,以确保数据的正确传输。
总结一下,HashCode是一种将任意长度的数据映射为固定长度值的算法。
多个字段的hashcode哈希(hash)这个术语是信息技术中经常用到的。
哈希(hash)是将任意长度的二进制值(明文)映射成固定长度的二进制值(密文)的一种方法,而这个映射规则就称为哈希算法(Hash Algorithm)。
现在,哈希算法在密码学、数字签名、数据完整性检测、数据检索(如作为关键字的索引)、哈希表等各个领域都得到了广泛的应用,在实际中有着非常重要的作用。
在哈希表中,哈希函数的作用就是将一个大的数据集合映射成一个小的数据集合,从而便于在小的数据集合中查找数据。
在哈希函数中,使用多个字段进行哈希计算是一种常见的做法。
这种方式可以更加准确地表示一个元素的“特征”,从而提升哈希算法的效率。
多个字段的哈希可以分为两部分,首先是如何计算多个字段的哈希值,其次是如何将多个哈希值组合成一个单一的哈希值。
第一部分:如何计算多个字段的哈希值多个字段的哈希值计算可以按照以下几种方式进行:1. 将多个字段的哈希值拼接起来再进行哈希计算。
例如,对于两个字段a和b,它们的哈希值为h1和h2。
我们可以先将h1和h2拼接起来形成一个新的字符串,然后对该字符串进行哈希计算得到最终的哈希值。
这种方式仅适用于字段较少的情况。
经过第一部分的哈希值计算,我们得到了多个哈希值。
为了将它们组合成一个单一的哈希值,我们可以采用以下几种方式:3. 将多个哈希值进行乘法、加法等运算,得到一个新的哈希值作为最终的哈希值。
这种方式可以保证哈希碰撞的概率比异或操作要小。
总结多个字段的哈希可以提高哈希算法的效率,但是在实际应用中需要注意哈希碰撞的问题,因此需要选择适当的哈希计算方式。
在将多个哈希值组合成一个单一的哈希值时,也需要选择适当的运算方式,从而保证哈希碰撞的概率足够小。
字典类型设计相关HashCode计算多项式我们知道字典Dictionary对象是⼀个key到value的映射,如果key为数值型,则计算其hashcode(假设为32位)时,我们可以通过对其的位表⽰(bit representation)进⾏某种计算,⽐如不超过32位的数值,其hashcode为其本⾝(左边填充0即可),超过32位的数值,则每32位分成⼀个部分,表⽰⼀个整型Xi,则可以通过计算所有Xi的和或者依次异或计算,从⽽得到hashcode然⽽对于字符串类型或者某序列⽽⾔,以上hashcode的计算⽅法则不可取,因为对这个序列进⾏置换操作,并不改变hashcode,如"stop", "tops", "pots", "spot"的hashcode将⼀样,那如何计算hashcode?(以上对于数值型的hashcode计算⽅法,理论上也存在这个问题,只不过32位能表⽰的范围在实际应⽤中还是蛮⼤的,故⽽实际中碰撞概率很低,⽽上⾯举得字符串的例⼦,则碰撞概率相对⾼很多)由于这⾥每⼀项的位置很重要,故⽽需要⽤位置影响最终的hashcode值,⼀种⽅式是使⽤多项式计算:加⼊序列中有n项,x0... xn-1, 选择常数a(不等于1),x0a^n-1 + x1a^n-2 + ... + xn-2a + xn-1这⾥,可以忽略32位相加溢出的情况,并且a的取值不宜过⼤。
根据测试,a取33,37,39或者41⽐较好,对于字符串为英⽂单词时,对超过50000的单词测试,每种情况碰撞不超过7。
循环移位前⾯讲到对于序列计算hashcode时,需要引⼊位置信息,使得位置能影响到最终的hashcode值。
那除了计算多项式,还有⼀种⽅法循环移位也可以做到。
考虑,依次相加序列中每⼀项,则项的顺序并不会影响到最终相加的和,but,如果每次加⼀个项后就做⼀次循环移位,显然,最终的和是受到影响的,代码如下,python:def hash_code(s):mask = (1 << 32) -1sum = 0for c in s:sum = (sum << 5 & mask) | (sum >> 27)sum += ord(c)return sum这⾥,将sum的最左边5位移到最右边。
hashcode计算方法
在计算机科学中,Hash Code是一种将数据转换为固定长度数值的技术。
它是一种哈希函数的应用,用于将任意大小的输入数据映射为固定大小的输出,通常是一个较小的整数。
Hash Code的计算方法基于哈希函数的算法。
哈希函数是一个确定性算法,用于将输入数据映射为一个固定长度的哈希值。
这个哈希函数通常是设计师经过深思熟虑后选择的,要保证算法简洁高效,并且满足一定的安全性要求。
Hash Code的计算方法可以根据具体需求来选择不同的哈希函数。
常用的哈希函数有MD5、SHA-1、SHA-256等。
这些哈希函数具有良好的随机性和不可逆性,可以将输入数据均匀地映射到哈希值的范围内,同时确保相同的输入会得到相同的哈希值。
以下是一个常见的Hash Code计算方法示例:
```java
public class HashCodeCalculator
public static int calculateHashCode(String input)
int hashCode = 0;
int prime = 31;
for (int i = 0; i < input.length(; i++)
hashCode = prime * hashCode + input.charAt(i);
}
return hashCode;
}
public static void main(String[] args)
String input = "Hash Code";
int hashCode = calculateHashCode(input);
System.out.println("Hash Code: " + hashCode);
}
```
在这个示例中,我们使用一个简单的算法来计算字符串的Hash Code。
算法通过遍历字符串中的每个字符,并使用一个乘法常数(31)将先前计
算的Hash Code与当前字符的ASCII值相乘,然后再累加。
最后,我们将
得到的结果作为Hash Code返回。
需要注意的是,Hash Code的计算方法可能会存在冲突。
由于Hash Code的输出是一个固定长度的数值,它不可能完美地映射所有可能的输入。
因此,不同的输入可能会得到相同的哈希值。
这种情况被称为冲突。
为了降低冲突的发生率,设计师通常会选择优化的哈希函数,并结合
一些额外的技术来处理冲突,例如链表法或开放寻址法。
这些技术可以提
高Hash Code的性能和可靠性。
总结起来,Hash Code是一种将数据转换为固定长度数值的技术,它
通过哈希函数将任意大小的输入数据映射为一个较小的整数。
Hash Code
的计算方法通常基于哈希函数的算法,选择合适的哈希函数可以提高Hash Code的性能和可靠性,同时需要注意处理冲突的问题。